
引言:试错的智慧
想象一下,你第一次玩《超级马里奥》这款游戏。屏幕上的小人在管道和蘑菇之间跳跃,你必须不断尝试:有时候跳得太早撞到了蘑菇,有时候跳得太晚掉进了坑里。但随着尝试次数的增多,你逐渐掌握了时机——你知道什么时候该加速,什么时候该按跳跃键。
这种通过试错来学习的过程,就是强化学习(Reinforcement Learning, RL)的核心思想。不同于监督学习从标注好的数据中学习,强化学习通过与环境的交互来获取反馈,并逐渐优化自己的行为策略。
从数学的角度看,强化学习可以被视为一个优化问题:智能体(Agent)需要在环境中选择动作(Action),以最大化累积奖励(Reward)。这个过程可以用概率论和微积分的语言来精确描述。
强化学习的本质可以用一个简洁的公式概括:最优决策 = 即时奖励 + γ × 未来价值的期望。这个公式贯穿了从 Q-learning 到 Actor-Critic 的所有算法,它告诉我们:当下的最优选择,不仅要考虑眼前的收益,更要权衡未来的可能性。这种思维方式不仅适用于机器学习,也适用于人生规划、企业战略和投资决策。
本文将带你踏上这段数学之旅,从马尔可夫决策过程(MDP)的基础框架出发,逐步推导经典的Q-learning、Policy Gradient和Actor-Critic算法,最后探讨强化学习的应用场景和未来前景。
第一章:强化学习的基本框架
1.1 核心概念
在正式进入数学推导之前,让我们先建立一个直观的图像。想象一只老鼠在迷宫中寻找奶酪:
- 智能体(Agent):这只老鼠
- 环境(Environment):迷宫
- 状态(State):老鼠在迷宫中的位置
- 动作(Action):老鼠可以向前后左右移动
- 奖励(Reward):找到奶酪+10分,撞墙-1分,每走一步-0.1分(鼓励快速找到)
智能体的目标是学习一个策略(Policy),即在不同状态下选择最优的动作,以最大化长期累积奖励。
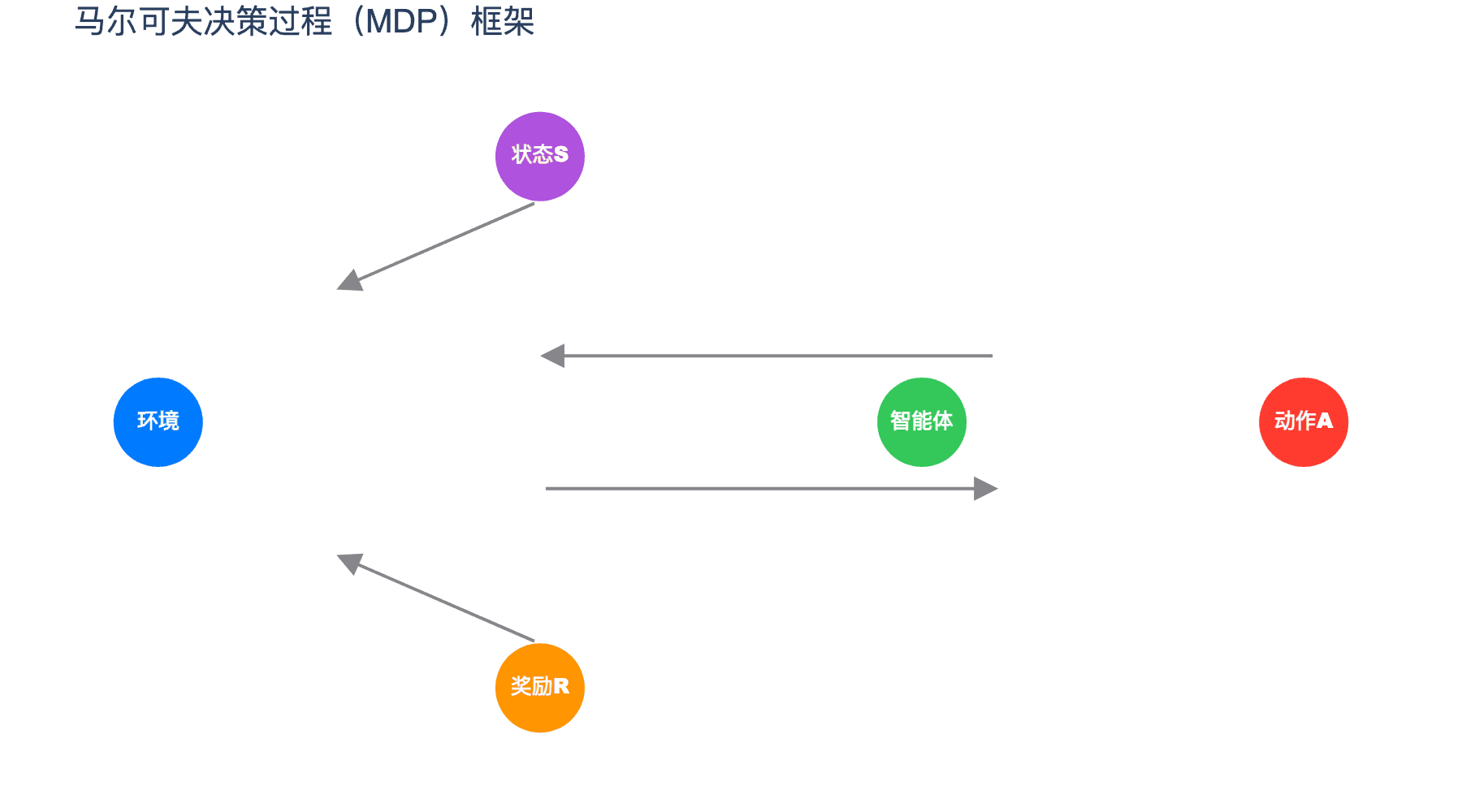
图1:马尔可夫决策过程的基本框架。智能体在状态 $s_t$ 执行动作 $a_t$,环境返回奖励 $r_{t+1}$ 并转移到新状态 $s_{t+1}$。
1.2 数学表示
现在让我们用数学语言来描述这个框架。一个强化学习问题通常由以下元组表示:
$$ (S, A, P, R, \gamma) $$
其中:
- $S$:状态空间(State Space)
- $A$:动作空间(Action Space)
- $P$:状态转移概率(Transition Probability)
- $R$:奖励函数(Reward Function)
- $\gamma$:折扣因子(Discount Factor),$\gamma \in [0,1]$
状态空间与动作空间
状态空间 $S$ 可以是离散的或连续的:
- 离散状态空间:例如棋盘游戏中的每个棋局配置,$S = {s_1, s_2, \ldots, s_n}$
- 连续状态空间:例如机器人的关节角度和速度,$S \subseteq \mathbb{R}^n$
动作空间 $A$ 同样可以是离散或连续的:
- 离散动作空间:例如围棋中的每个落子位置,$A = {a_1, a_2, \ldots, a_m}$
- 连续动作空间:例如机械臂的关节扭矩,$A \subseteq \mathbb{R}^m$
状态转移概率
状态转移概率 $P(s’|s,a)$ 表示在状态 $s$ 执行动作 $a$ 后,转移到状态 $s’$ 的概率:
$$ P(s’|s,a) = \mathbb{P}[S_{t+1} = s’ | S_t = s, A_t = a] $$
这个概率分布完全描述了环境的动态特性。在许多实际问题中,我们并不知道 $P(s’|s,a)$ 的具体形式,这就是为什么需要免模型(model-free)算法。
奖励函数
奖励函数 $R(s,a)$ 可以定义为:
$$ R(s,a) = \mathbb{E}[R_{t+1} | S_t = s, A_t = a] $$
更一般地,奖励可以依赖于三元组 $(s, a, s’)$:
$$ R(s,a,s’) = \mathbb{E}[R_{t+1} | S_t = s, A_t = a, S_{t+1} = s’] $$
奖励函数是强化学习中最关键的设计要素之一。一个好的奖励函数应该:
- 明确目标:清晰地表达我们希望智能体达成的目标
- 可塑性(Shaping):提供中间反馈,而不仅仅是终局奖励
- 避免奖励黑客(Reward Hacking):防止智能体找到意外的捷径
实践启示:在实际应用中,奖励函数的设计往往比算法选择更重要。一个精心设计的奖励函数,即使用简单的 Q-learning 也能取得好效果;而一个糟糕的奖励函数,即使用最先进的算法也难以成功。这就像教育孩子:正确的激励机制(奖励函数)比严格的规则(算法)更能引导出期望的行为。
折扣因子的深入理解
折扣因子 $\gamma$ 的作用是权衡短期奖励和长期奖励。$\gamma$ 越接近 1,智能体越看重长期回报;$\gamma$ 越接近 0,智能体越关注即时奖励。
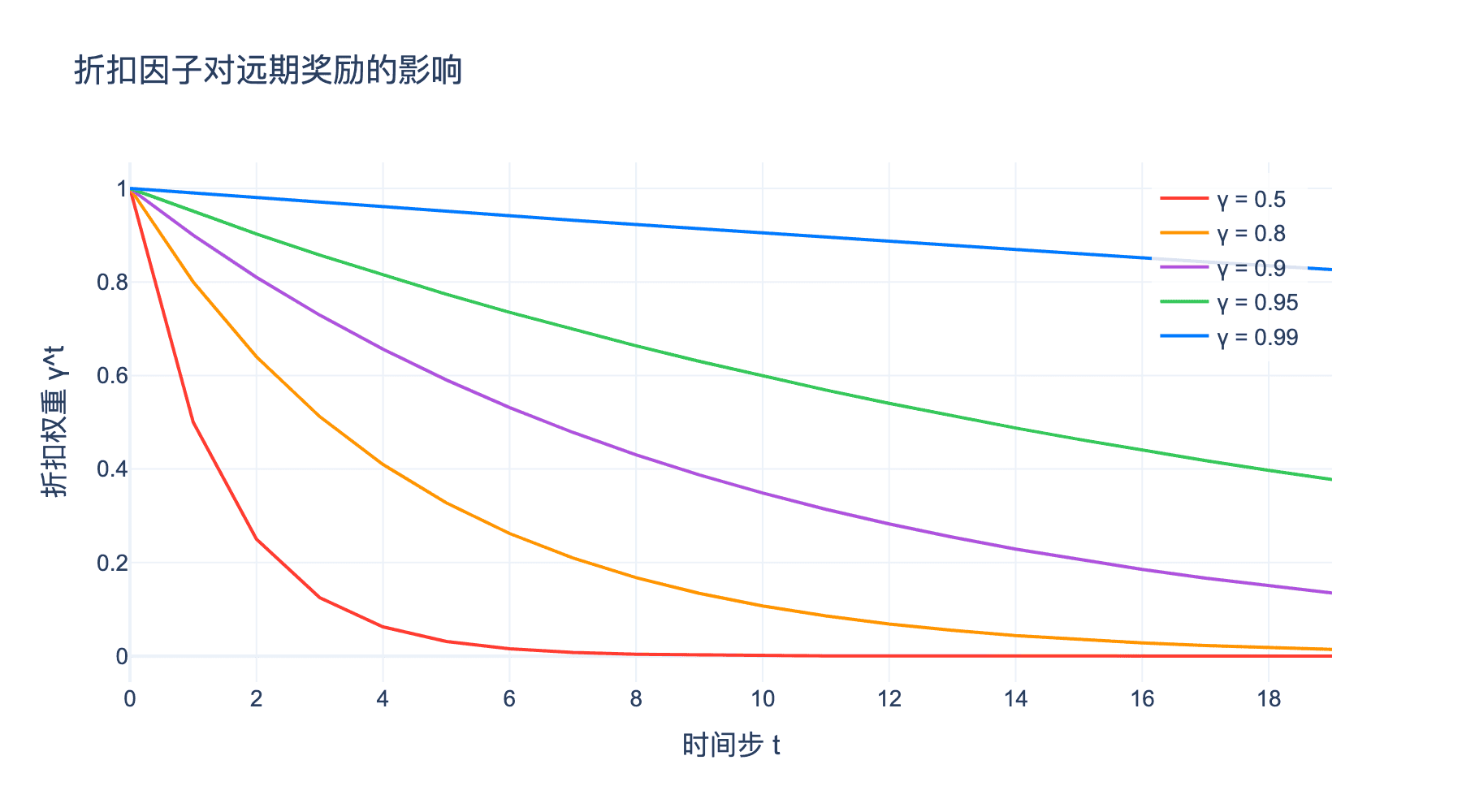
图2:不同折扣因子 $\gamma$ 对累积奖励的影响。$\gamma = 0.9$ 时,10步后的奖励权重降至约35%;$\gamma = 0.99$ 时,权重仍保持约90%。
从数学角度看,折扣因子有几个重要作用:
数学收敛性:当 $\gamma < 1$ 时,无限累积奖励 $\sum_{t=0}^{\infty} \gamma^t r_t$ 有界,保证了价值函数的收敛性。
不确定性建模:$\gamma$ 可以理解为每一步继续的概率。如果智能体在每一步有 $(1-\gamma)$ 的概率终止,那么折扣累积奖励等价于期望总奖励。
时间偏好:在经济学中,$\gamma$ 反映了对未来收益的时间偏好(time preference)。
定理(折扣累积奖励的有界性):如果奖励有界,即 $|r_t| \leq R_{\max}$,且 $\gamma < 1$,那么累积奖励有界:
$$ \left| \sum_{t=0}^{\infty} \gamma^t r_t \right| \leq \sum_{t=0}^{\infty} \gamma^t R_{\max} = \frac{R_{\max}}{1-\gamma} $$
证明:利用几何级数求和公式 $\sum_{t=0}^{\infty} \gamma^t = \frac{1}{1-\gamma}$(当 $|\gamma| < 1$ 时)。
第二章:马尔可夫决策过程(MDP)
2.1 马尔可夫性质
马尔可夫决策过程(Markov Decision Process, MDP)的核心假设是马尔可夫性(Markov Property),即"未来只依赖于现在,与过去无关":
$$ \mathbb{P}[S_{t+1} | S_t, A_t, S_{t-1}, A_{t-1}, \ldots, S_0, A_0] = \mathbb{P}[S_{t+1} | S_t, A_t] $$
这个假设看似简单,但它大大简化了问题。如果状态转移满足马尔可夫性,我们就不需要记住整个历史轨迹,只需要知道当前状态即可做出决策。
这里隐藏着一个深刻的认知转变:从"给定规则执行"到"通过试错发现规则"。传统的程序设计是人类定义规则,机器执行;而强化学习是机器通过与环境交互,自己发现最优的行为规则。这种范式转变,让人工智能从"被动执行"走向"主动学习"。
2.2 策略(Policy)
策略 $\pi(a|s)$ 是一个概率分布,表示在状态 $s$ 下选择动作 $a$ 的概率:
$$ \pi(a|s) = \mathbb{P}[A_t = a | S_t = s] $$
策略可以是确定性的(deterministic),即 $\pi(s)$ 直接给出一个确定动作;也可以是随机性的(stochastic),即 $\pi(a|s)$ 给出选择各个动作的概率。
一个反直觉的发现:最优策略不一定是确定性的。在某些情况下,随机策略反而能获得更高的累积奖励。这是因为随机性本身就是一种探索机制,它帮助智能体避免陷入局部最优。这个思想在后续的策略梯度方法中会得到充分体现。
2.3 价值函数(Value Function)
为了评估一个策略的好坏,我们需要定义价值函数。
状态价值函数 $V^\pi(s)$ 表示从状态 $s$ 开始,遵循策略 $\pi$ 所能获得的期望累积奖励:
$$ V^\pi(s) = \mathbb{E}\pi \left[ \sum{t=0}^{\infty} \gamma^t R_{t+1} \Big| S_0 = s \right] $$
这里 $\mathbb{E}_\pi$ 表示遵循策略 $\pi$ 的期望。
动作价值函数 $Q^\pi(s,a)$ 表示在状态 $s$ 执行动作 $a$,然后遵循策略 $\pi$ 所能获得的期望累积奖励:
$$ Q^\pi(s,a) = \mathbb{E}\pi \left[ \sum{t=0}^{\infty} \gamma^t R_{t+1} \Big| S_0 = s, A_0 = a \right] $$
这两个函数密切相关。从状态价值函数的定义出发,我们可以推导出:
$$ V^\pi(s) = \sum_{a \in A} \pi(a|s) Q^\pi(s,a) $$
这个公式很直观:状态 $s$ 的价值,等于在该状态下所有可能动作价值的加权平均,权重由策略 $\pi$ 决定。
2.4 贝尔曼方程
现在我们进入强化学习的核心部分——贝尔曼方程(Bellman Equation)。这个方程以数学家理查德·贝尔曼(Richard Bellman)命名,他在1950年代提出了动态规划理论。
贝尔曼期望方程的推导
贝尔曼期望方程(Bellman Expectation Equation)描述了价值函数的递归结构。让我们从定义出发推导这个方程。
状态价值函数的定义是:
$$ V^\pi(s) = \mathbb{E}\pi \left[ \sum{t=0}^{\infty} \gamma^t R_{t+1} \Big| S_0 = s \right] $$
我们可以将这个无限求和分解为第一步和后续步骤:
$$ V^\pi(s) = \mathbb{E}_\pi [R_1 + \gamma R_2 + \gamma^2 R_3 + \cdots | S_0 = s] $$
$$ V^\pi(s) = \mathbb{E}\pi [R_1 | S_0 = s] + \gamma \mathbb{E}\pi [R_2 + \gamma R_3 + \cdots | S_0 = s] $$
注意到后半部分实际上是从状态 $S_1$ 开始的价值函数:
$$ V^\pi(s) = \mathbb{E}\pi [R_1 | S_0 = s] + \gamma \mathbb{E}\pi [V^\pi(S_1) | S_0 = s] $$
现在展开期望,对所有可能的动作和下一状态求和:
$$ V^\pi(s) = \sum_{a} \pi(a|s) \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma V^\pi(s’)] $$
这就是贝尔曼期望方程。它告诉我们:当前状态的价值等于所有可能动作的价值加权平均,而每个动作的价值包括即时奖励和下一状态的折扣价值。
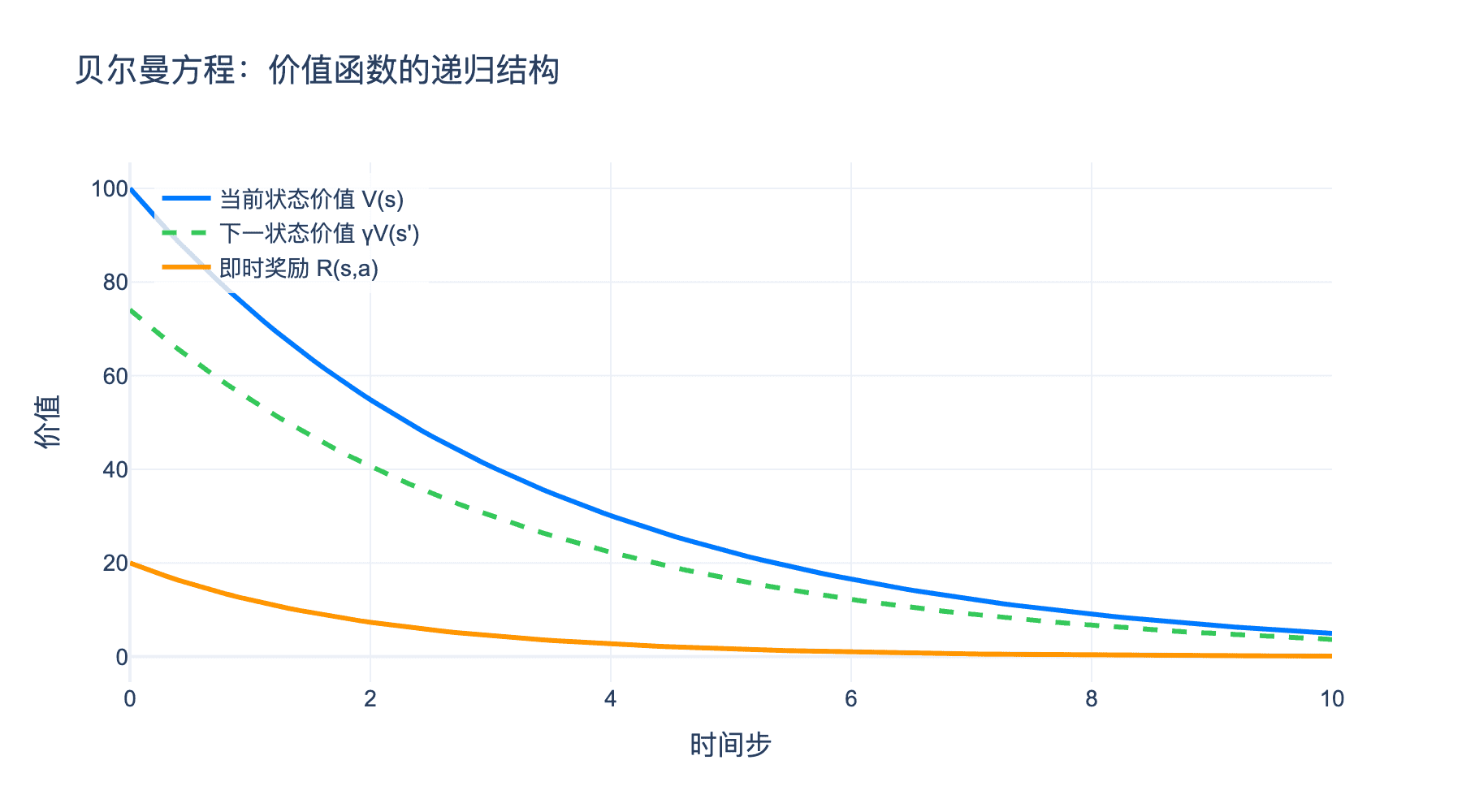
图3:贝尔曼方程的递归结构。当前状态的价值通过即时奖励和后续状态的价值递归定义。
Q函数的贝尔曼方程
同样,我们可以写出 Q 函数的贝尔曼期望方程:
$$ Q^\pi(s,a) = \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma V^\pi(s’)] $$
将 $V^\pi(s’) = \sum_{a’} \pi(a’|s’) Q^\pi(s’,a’)$ 代入,我们得到:
$$ Q^\pi(s,a) = \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma \sum_{a’} \pi(a’|s’) Q^\pi(s’,a’)] $$
贝尔曼方程的矩阵形式
对于有限状态空间,贝尔曼期望方程可以写成矩阵形式。定义:
- $V^\pi \in \mathbb{R}^{|S|}$:价值向量
- $R^\pi \in \mathbb{R}^{|S|}$:期望奖励向量,$(R^\pi)_s = \sum_a \pi(a|s) R(s,a)$
- $P^\pi \in \mathbb{R}^{|S| \times |S|}$:转移矩阵,$(P^\pi)_{ss’} = \sum_a \pi(a|s) P(s’|s,a)$
那么贝尔曼期望方程可以写成:
$$ V^\pi = R^\pi + \gamma P^\pi V^\pi $$
这是一个线性方程组,可以直接求解:
$$ V^\pi = (I - \gamma P^\pi)^{-1} R^\pi $$
其中 $I$ 是单位矩阵。当 $\gamma < 1$ 时,$(I - \gamma P^\pi)$ 可逆。
贝尔曼方程的不动点性质
贝尔曼期望方程定义了一个贝尔曼期望算子 $T^\pi$:
$$ (T^\pi V)(s) = \sum_{a} \pi(a|s) \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma V(s’)] $$
价值函数 $V^\pi$ 是这个算子的不动点,即 $T^\pi V^\pi = V^\pi$。
定理(贝尔曼期望算子的收缩性):贝尔曼期望算子 $T^\pi$ 是一个 $\gamma$-收缩映射,即对于任意两个价值函数 $V_1$ 和 $V_2$:
$$ |T^\pi V_1 - T^\pi V_2|\infty \leq \gamma |V_1 - V_2|\infty $$
其中 $|V|_\infty = \max_s |V(s)|$ 是无穷范数。
证明:对于任意状态 $s$:
$$ \begin{aligned} |(T^\pi V_1)(s) - (T^\pi V_2)(s)| &= \left| \sum_{a} \pi(a|s) \sum_{s’} P(s’|s,a) \gamma [V_1(s’) - V_2(s’)] \right| \\ &\leq \sum_{a} \pi(a|s) \sum_{s’} P(s’|s,a) \gamma |V_1(s’) - V_2(s’)| \\ &\leq \gamma |V_1 - V_2|\infty \sum{a} \pi(a|s) \sum_{s’} P(s’|s,a) \\ &= \gamma |V_1 - V_2|_\infty \end{aligned} $$
由于这对所有状态 $s$ 成立,我们有 $|T^\pi V_1 - T^\pi V_2|\infty \leq \gamma |V_1 - V_2|\infty$。
根据巴拿赫不动点定理(Banach Fixed Point Theorem),收缩映射有唯一的不动点,且可以通过迭代 $V_{k+1} = T^\pi V_k$ 收敛到这个不动点。这就是策略评估(Policy Evaluation)算法的理论基础。
2.5 最优价值函数
我们的目标是找到最优策略 $\pi^{\ast}$,即最大化累积奖励的策略。对应地,我们定义最优状态价值函数和最优动作价值函数:
$$ V^{\ast}(s) = \max_\pi V^\pi(s) $$ $$ Q^{\ast}(s,a) = \max_\pi Q^\pi(s,a) $$
这两个函数满足贝尔曼最优方程(Bellman Optimality Equation):
$$ V^{\ast}(s) = \max_a \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma V^{\ast}(s’)] $$
$$ Q^{\ast}(s,a) = \sum_{s’} P(s’|s,a) [R(s,a,s’) + \gamma \max_{a’} Q^{\ast}(s’,a’)] $$
注意与期望方程的区别:这里我们用了 $\max_a$ 而不是 $\sum_a \pi(a|s)$,因为我们不再是对策略求期望,而是直接选择最优动作。
从最优价值函数,我们可以直接得到最优策略:
$$ \pi^{\ast}(s) = \arg\max_a Q^{\ast}(s,a) $$
也就是说,最优策略在每个状态下都选择价值最大的动作。
第三章:基于价值的算法——Q-learning
3.1 Q-learning 的核心思想
Q-learning 是基于价值的算法的代表,它的核心思想是直接学习 Q 函数,然后通过 $Q(s,a)$ 得到最优策略。
Q-learning 是一个免模型(model-free)算法,这意味着它不需要知道状态转移概率 $P(s’|s,a)$ 和奖励函数 $R(s,a,s’)$,只需要通过与环境的交互来学习。
探索与利用的权衡
在学习 Q 函数的过程中,智能体面临一个根本性的困境:探索-利用权衡(Exploration-Exploitation Tradeoff)。
- 利用(Exploitation):选择当前已知的最优动作,以获得最大即时奖励
- 探索(Exploration):尝试未知或不确定的动作,以发现可能更好的策略
这个困境在生活中无处不在:选择熟悉的餐厅还是尝试新餐厅?坚持现有职业还是探索新领域?在企业战略中,是深耕现有市场(利用)还是开拓新业务(探索)?强化学习告诉我们:最优策略是让探索随时间衰减——早期广泛探索,后期精准利用。这种"先探索后利用"的智慧,适用于几乎所有需要在不确定性中做决策的场景。
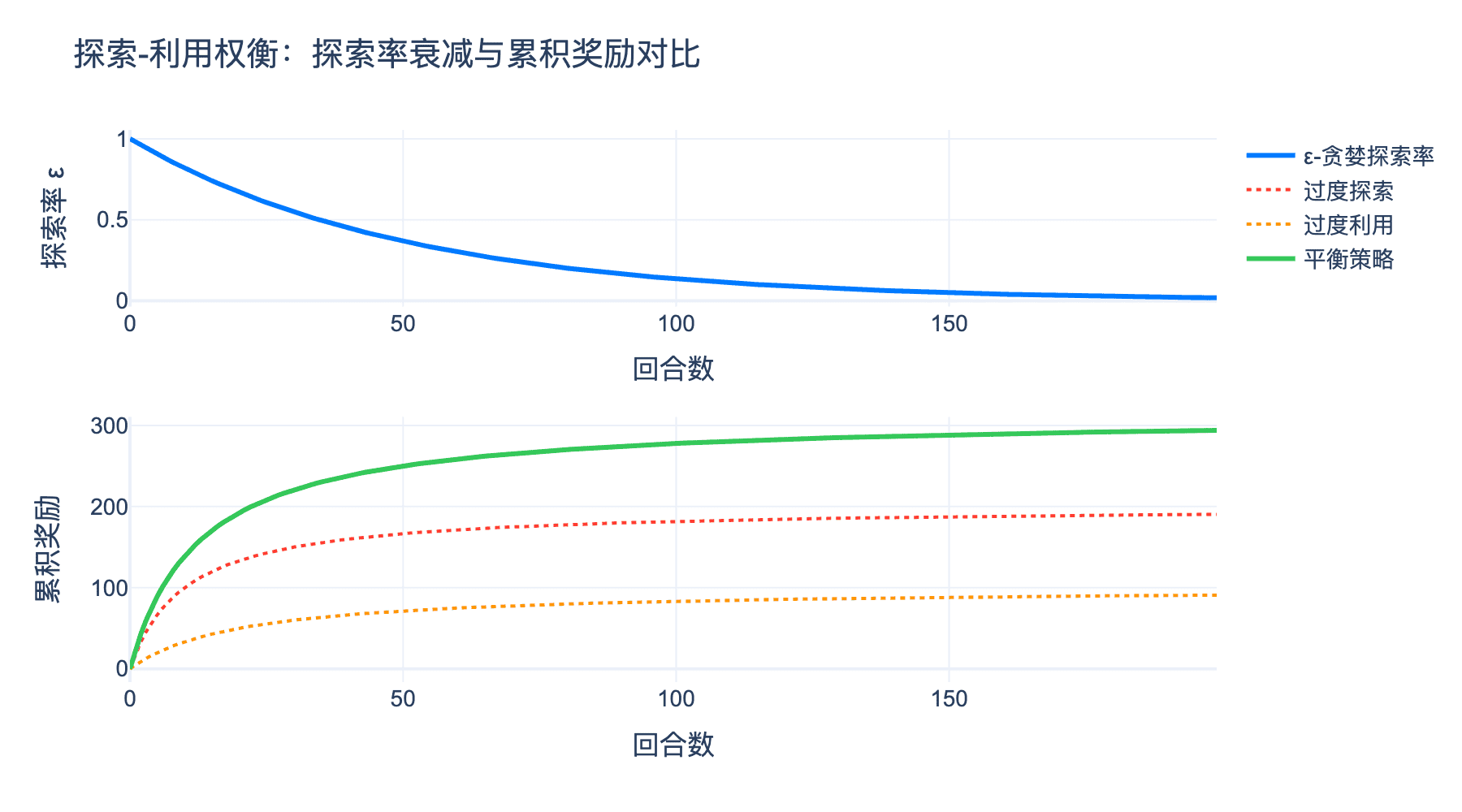
图4:探索-利用权衡。纯利用可能陷入局部最优,纯探索效率低下,需要在两者之间找到平衡。
常用的探索策略包括:
ε-贪心策略(ε-greedy):以概率 $\epsilon$ 随机选择动作,以概率 $1-\epsilon$ 选择最优动作 $$ a_t = \begin{cases} \arg\max_a Q(s_t,a) & \text{with probability } 1-\epsilon \ \text{random action} & \text{with probability } \epsilon \end{cases} $$
Boltzmann探索(Softmax):根据 Q 值的 softmax 分布选择动作 $$ \pi(a|s) = \frac{\exp(Q(s,a)/\tau)}{\sum_{a’} \exp(Q(s,a’)/\tau)} $$ 其中 $\tau$ 是温度参数,$\tau \to 0$ 时趋向贪心,$\tau \to \infty$ 时趋向均匀随机。
UCB探索(Upper Confidence Bound):选择具有最高上界置信区间的动作 $$ a_t = \arg\max_a \left[ Q(s_t,a) + c\sqrt{\frac{\ln t}{N(s_t,a)}} \right] $$ 其中 $N(s_t,a)$ 是动作 $a$ 在状态 $s_t$ 被选择的次数,$c$ 是探索系数。
3.2 Q-learning 的更新规则
假设我们在时间步 $t$ 观察到状态 $s_t$,执行动作 $a_t$,获得奖励 $r_t$,并转移到状态 $s_{t+1}$。Q-learning 的更新规则如下:
$$ Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha [r_t + \gamma \max_{a’} Q(s_{t+1},a’) - Q(s_t,a_t)] $$
其中 $\alpha \in (0,1]$ 是学习率(learning rate)。
让我们分析这个公式。定义TD 误差(Temporal Difference error):
$$ \delta_t = r_t + \gamma \max_{a’} Q(s_{t+1},a’) - Q(s_t,a_t) $$
TD 误差可以理解为"我们期望得到的"与"我们当前估计的"之间的差异。Q-learning 的更新就是根据这个差异来调整 Q 值。
3.3 Q-learning 的收敛性证明
Q-learning 的一个重要性质是:在满足一定条件下,Q 值会收敛到最优 Q 函数 $Q^{\ast}(s,a)$。
定理(Q-learning收敛性):如果满足以下条件:
- 所有状态-动作对 $(s,a)$ 都被无限次访问
- 学习率 $\alpha_t$ 满足 Robbins-Monro 条件:
- $\sum_{t=0}^{\infty} \alpha_t(s,a) = \infty$ (保证收敛)
- $\sum_{t=0}^{\infty} \alpha_t^2(s,a) < \infty$ (保证方差有界)
- 折扣因子 $\gamma < 1$(或者问题是有限折扣的)
那么 Q-learning 的 Q 值以概率 1 收敛到 $Q^{\ast}$。
详细证明
证明:我们将使用随机逼近理论(Stochastic Approximation Theory)来证明这个定理。
步骤1:定义贝尔曼最优算子
首先定义贝尔曼最优算子 $T^{\ast}$:
$$ (T^{\ast} Q)(s,a) = \mathbb{E}{s’ \sim P(\cdot|s,a)}[R(s,a,s’) + \gamma \max{a’} Q(s’,a’)] $$
最优 Q 函数 $Q^{\ast}$ 是这个算子的不动点:$T^{\ast} Q^{\ast} = Q^{\ast}$。
步骤2:证明 $T^{\ast}$ 是收缩映射
对于任意两个 Q 函数 $Q_1$ 和 $Q_2$,我们有:
$$ |(T^{\ast} Q_1)(s,a) - (T^{\ast} Q_2)(s,a)| = \left| \mathbb{E}{s’}[\gamma \max{a’} Q_1(s’,a’) - \gamma \max_{a’} Q_2(s’,a’)] \right| $$
$$ \leq \mathbb{E}{s’}[\gamma |\max{a’} Q_1(s’,a’) - \max_{a’} Q_2(s’,a’)|] $$
$$ \leq \gamma \mathbb{E}{s’}[\max{a’} |Q_1(s’,a’) - Q_2(s’,a’)|] $$
$$ \leq \gamma |Q_1 - Q_2|_\infty $$
第三个不等号使用了 $|\max_a f(a) - \max_a g(a)| \leq \max_a |f(a) - g(a)|$。
因此 $T^{\ast}$ 是 $\gamma$-收缩映射:
$$ |T^{\ast} Q_1 - T^{\ast} Q_2|\infty \leq \gamma |Q_1 - Q_2|\infty $$
步骤3:将Q-learning写成随机逼近形式
Q-learning 的更新可以写成:
$$ Q_{t+1}(s_t,a_t) = Q_t(s_t,a_t) + \alpha_t [r_t + \gamma \max_{a’} Q_t(s_{t+1},a’) - Q_t(s_t,a_t)] $$
定义 TD 目标:
$$ y_t = r_t + \gamma \max_{a’} Q_t(s_{t+1},a’) $$
那么更新可以写成:
$$ Q_{t+1}(s_t,a_t) = (1-\alpha_t) Q_t(s_t,a_t) + \alpha_t y_t $$
注意 $\mathbb{E}[y_t | s_t, a_t] = (T^{\ast} Q_t)(s_t,a_t)$,因此:
$$ Q_{t+1}(s,a) = Q_t(s,a) + \alpha_t [(T^{\ast} Q_t)(s,a) - Q_t(s,a) + \epsilon_t] $$
其中 $\epsilon_t = y_t - (T^{\ast} Q_t)(s_t,a_t)$ 是噪声项,满足 $\mathbb{E}[\epsilon_t | \mathcal{F}_t] = 0$。
步骤4:应用随机逼近收敛定理
根据 Robbins-Monro 随机逼近定理,如果:
- $T^{\ast}$ 是收缩映射(已证明)
- 学习率满足 $\sum_t \alpha_t = \infty$ 且 $\sum_t \alpha_t^2 < \infty$
- 噪声项有界:$\mathbb{E}[\epsilon_t^2 | \mathcal{F}_t] < C$
- 所有状态-动作对被无限次访问
那么 $Q_t \to Q^{\ast}$ 以概率 1。
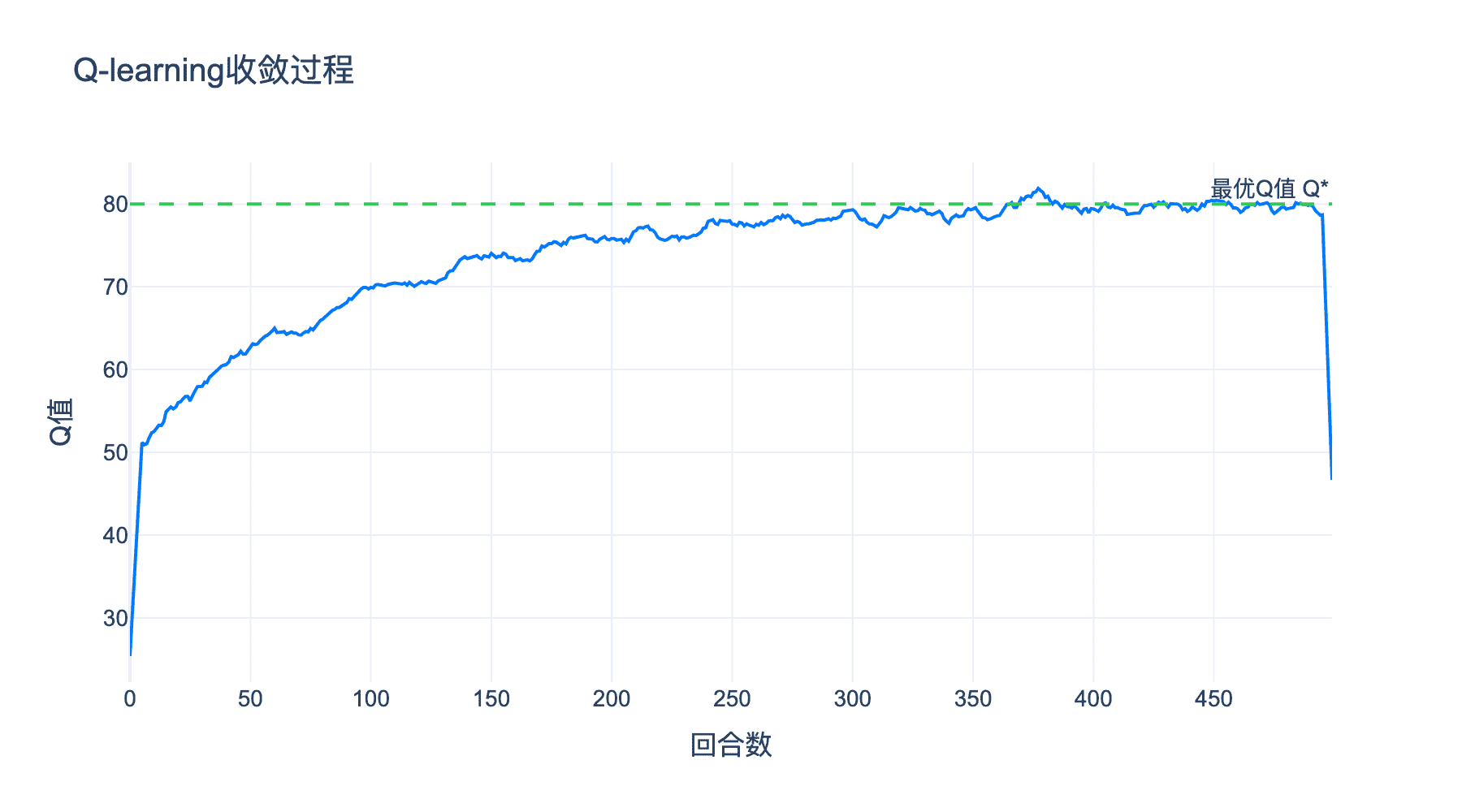
图5:Q-learning在简单网格世界中的收敛过程。随着迭代次数增加,Q值逐渐收敛到最优值。
学习率的选择
Robbins-Monro 条件对学习率的要求看似严格,但实际上有很多满足条件的选择:
调和级数:$\alpha_t = \frac{1}{t}$
- 满足 $\sum_t \frac{1}{t} = \infty$ 和 $\sum_t \frac{1}{t^2} < \infty$
- 但收敛速度较慢
多项式衰减:$\alpha_t = \frac{1}{t^\beta}$,其中 $0.5 < \beta \leq 1$
- $\beta = 0.6$ 是常用选择
状态-动作对计数:$\alpha_t(s,a) = \frac{1}{N_t(s,a)}$
- 其中 $N_t(s,a)$ 是状态-动作对 $(s,a)$ 被访问的次数
在实践中,常常使用固定的小学习率(如 $\alpha = 0.01$),虽然不满足理论收敛条件,但在非平稳环境中表现更好。
这个定理保证了 Q-learning 的理论基础,但在实际应用中,我们需要考虑状态空间的问题。
3.4 Q-learning 的局限性:维数灾难
Q-learning 需要为每个状态-动作对存储一个 Q 值,这意味着空间复杂度是 $O(|S| \times |A|)$。对于离散状态空间,这可能是一个巨大的数字。
例如,考虑一个简单的棋盘游戏,棋盘是 $8 \times 8$ 的,每个格子可能是空的或被占据的,那么状态空间大小是 $2^{64} \approx 1.8 \times 10^{19}$,这完全无法用表格存储。
这就是著名的维数灾难(Curse of Dimensionality)。解决这个问题的方法是使用函数近似(function approximation),即用一个函数来表示 Q 值:
$$ Q(s,a;\theta) \approx Q^{\ast}(s,a) $$
其中 $\theta$ 是函数的参数。在深度强化学习中,我们用神经网络作为函数近似器,这就是 DQN(Deep Q-Network)的核心思想。
第四章:基于策略的算法——Policy Gradient
4.1 Policy Gradient 的动机
Q-learning 是基于价值的方法,它先学习 Q 函数,再从 Q 函数推导策略。Policy Gradient 则直接优化策略 $\pi(a|s;\theta)$,其中 $\theta$ 是策略的参数。
Policy Gradient 的优势在于:
- 可以处理连续动作空间
- 策略的随机性有助于探索
- 策略梯度方法在某些情况下收敛速度更快
4.2 目标函数
Policy Gradient 的目标是最优化策略的期望累积奖励:
$$ J(\theta) = \mathbb{E}{\tau \sim \pi\theta}[R(\tau)] $$
其中 $\tau = (s_0, a_0, s_1, a_1, \ldots, s_T)$ 是一条轨迹,$R(\tau) = \sum_{t=0}^{T-1} \gamma^t r_t$ 是轨迹的累积奖励。
我们的目标是找到 $\theta^{\ast} = \arg\max_\theta J(\theta)$。
4.3 策略梯度定理
现在进入 Policy Gradient 的核心——如何计算 $\nabla_\theta J(\theta)$。
策略梯度定理(Policy Gradient Theorem):
$$ \nabla_\theta J(\theta) = \mathbb{E}{\pi\theta} \left[ \nabla_\theta \log \pi_\theta(a|s) Q^\pi(s,a) \right] $$
这个定理告诉我们,策略的梯度等于对数策略的梯度与动作价值的乘积的期望。
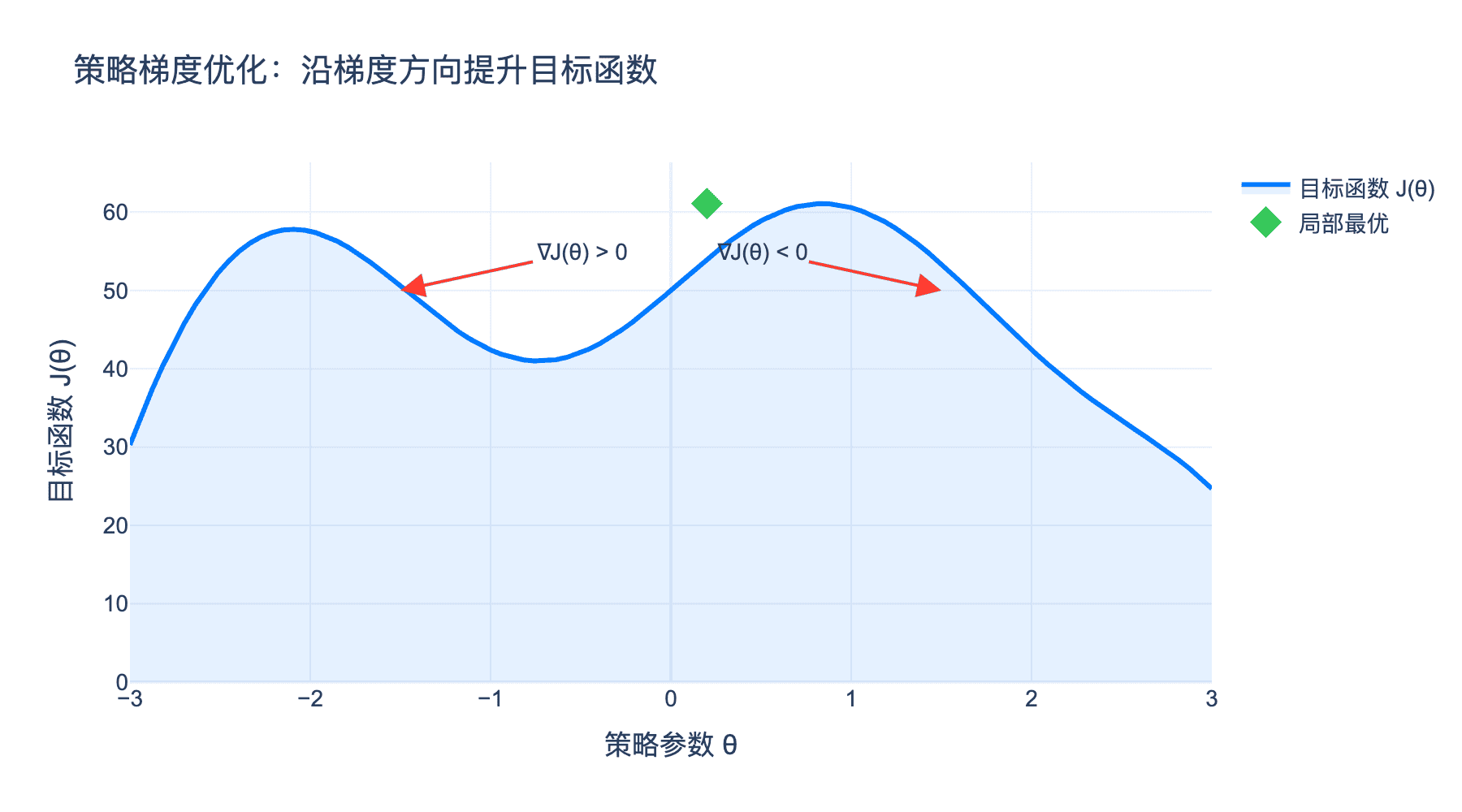
图6:策略梯度方法的直观理解。通过增加高回报动作的概率,减少低回报动作的概率,策略逐渐优化。
为什么使用对数梯度?
策略梯度定理中使用 $\nabla_\theta \log \pi_\theta(a|s)$ 而不是 $\nabla_\theta \pi_\theta(a|s)$ 有几个重要原因:
数值稳定性:对数函数将乘法转换为加法,避免了概率连乘导致的数值下溢。
似然比技巧(Likelihood Ratio Trick):利用恒等式 $\nabla_\theta \pi_\theta = \pi_\theta \nabla_\theta \log \pi_\theta$,我们可以将梯度写成期望形式,便于蒙特卡洛估计。
自然梯度解释:$\nabla_\theta \log \pi_\theta(a|s)$ 可以理解为参数空间中的"得分函数"(score function),它指向使动作 $a$ 概率增加最快的方向。
与最大似然估计的联系:策略梯度可以看作加权的最大似然估计,权重由 Q 值决定。
证明:
首先,我们将 $J(\theta)$ 写成对所有轨迹的求和:
$$ J(\theta) = \sum_\tau P(\tau;\theta) R(\tau) $$
其中 $P(\tau;\theta)$ 是轨迹的概率:
$$ P(\tau;\theta) = P(s_0) \prod_{t=0}^{T-1} \pi_\theta(a_t|s_t) P(s_{t+1}|s_t,a_t) $$
注意,$\pi_\theta(a_t|s_t)$ 是唯一依赖于 $\theta$ 的项。
现在计算梯度:
$$ \nabla_\theta J(\theta) = \sum_\tau \nabla_\theta P(\tau;\theta) R(\tau) $$
利用恒等式 $\nabla P = P \nabla \log P$:
$$ \nabla_\theta J(\theta) = \sum_\tau P(\tau;\theta) \nabla_\theta \log P(\tau;\theta) R(\tau) $$
$$ \nabla_\theta J(\theta) = \mathbb{E}{\tau \sim \pi\theta}[\nabla_\theta \log P(\tau;\theta) R(\tau)] $$
现在计算 $\nabla_\theta \log P(\tau;\theta)$:
$$ \nabla_\theta \log P(\tau;\theta) = \nabla_\theta \sum_{t=0}^{T-1} \log \pi_\theta(a_t|s_t) = \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) $$
因此:
$$ \nabla_\theta J(\theta) = \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) R(\tau) \right] $$
这里 $R(\tau)$ 可以替换为从时间步 t 开始的累积奖励 $G_t$,因为对于时间步 t,后续的动作不会影响前面的奖励:
$$ \nabla_\theta J(\theta) = \mathbb{E}{\tau \sim \pi\theta} \left[ \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) G_t \right] $$
其中 $G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_k$。
这个公式可以写成单个时间步的形式:
$$ \nabla_\theta J(\theta) = \mathbb{E}{s \sim \pi\theta, a \sim \pi_\theta(\cdot|s)}[\nabla_\theta \log \pi_\theta(a|s) Q^\pi(s,a)] $$
这就完成了策略梯度定理的证明。
4.4 REINFORCE 算法
基于策略梯度定理,我们可以得到 REINFORCE 算法的更新规则:
$$ \theta \leftarrow \theta + \alpha \sum_{t=0}^{T-1} \nabla_\theta \log \pi_\theta(a_t|s_t) G_t $$
其中 $\alpha$ 是学习率。
算法步骤:
- 初始化策略参数 $\theta$
- 对于每个回合: a. 采样一条轨迹 $\tau = (s_0, a_0, s_1, a_1, \ldots, s_T)$ b. 计算每个时间步的累积奖励 $G_t = \sum_{k=t}^{T-1} \gamma^{k-t} r_k$ c. 更新参数 $\theta$
- 重复直到收敛
REINFORCE 是一个蒙特卡洛(Monte Carlo)算法,它使用完整的轨迹来更新策略。这意味着它的方差较高,但偏差较低(无偏)。
4.5 基线(Baseline)的引入
为了降低方差,我们可以引入一个基线 $b(s)$:
$$ \nabla_\theta J(\theta) = \mathbb{E}{\pi\theta} \left[ \nabla_\theta \log \pi_\theta(a|s) (Q^\pi(s,a) - b(s)) \right] $$
引入基线不会改变梯度的期望,因为:
$$ \mathbb{E}{a \sim \pi\theta(\cdot|s)}[\nabla_\theta \log \pi_\theta(a|s) b(s)] = b(s) \mathbb{E}{a \sim \pi\theta(\cdot|s)}[\nabla_\theta \log \pi_\theta(a|s)] = 0 $$
最后一个等号是因为 $\sum_a \pi_\theta(a|s) = 1$,所以:
$$ \sum_a \nabla_\theta \pi_\theta(a|s) = \nabla_\theta \sum_a \pi_\theta(a|s) = 0 $$
常用的基线选择是状态价值函数 $V^\pi(s)$,这样我们得到优势函数(Advantage Function):
$$ A^\pi(s,a) = Q^\pi(s,a) - V^\pi(s) $$
优势函数表示在状态 $s$ 选择动作 $a$ 相比于平均动作的优势。
第五章:Actor-Critic 算法
5.1 Actor-Critic 的动机
Policy Gradient(如 REINFORCE)使用蒙特卡洛方法,需要完整的轨迹,方差较高。Q-learning 使用时序差分(Temporal Difference, TD)方法,每次只更新一步,偏差较高。
Actor-Critic 算法结合了两者的优点:
- Actor:负责选择动作,使用策略梯度方法
- Critic:负责评估动作价值,使用值函数方法
Critic 为 Actor 提供低方差的梯度估计,而 Actor 利用这个梯度更新策略。
图7:Actor-Critic架构。Actor根据当前策略选择动作,Critic评估动作的价值,两者协同优化。
偏差-方差权衡
在强化学习中,我们面临偏差-方差权衡(Bias-Variance Tradeoff):
蒙特卡洛方法(如REINFORCE):
- 使用完整轨迹的实际回报 $G_t = \sum_{k=t}^{T} \gamma^{k-t} r_k$
- 无偏:$\mathbb{E}[G_t] = Q^\pi(s_t,a_t)$
- 高方差:不同轨迹的回报差异很大
时序差分方法(如Q-learning):
- 使用单步估计 $r_t + \gamma V(s_{t+1})$
- 有偏:依赖于 $V(s_{t+1})$ 的估计误差
- 低方差:只依赖单步转移
n步TD方法:
- 使用 n 步回报 $G_t^{(n)} = \sum_{k=0}^{n-1} \gamma^k r_{t+k} + \gamma^n V(s_{t+n})$
- 在偏差和方差之间取得平衡
Actor-Critic 通过使用 Critic 的价值估计来降低方差,同时保持相对较低的偏差。
TD(λ):统一的视角
TD(λ) 算法通过引入资格迹(Eligibility Trace)统一了蒙特卡洛和时序差分方法。
定义 λ-回报:
$$ G_t^\lambda = (1-\lambda) \sum_{n=1}^{\infty} \lambda^{n-1} G_t^{(n)} $$
其中 $G_t^{(n)}$ 是 n 步回报。当 $\lambda = 0$ 时,$G_t^\lambda = G_t^{(1)}$(TD方法);当 $\lambda = 1$ 时,$G_t^\lambda = G_t$(蒙特卡洛方法)。
资格迹 $e_t(s)$ 记录了状态 $s$ 对当前时刻的"贡献":
$$ e_t(s) = \gamma \lambda e_{t-1}(s) + \mathbb{1}[s_t = s] $$
TD(λ) 的更新规则为:
$$ V(s) \leftarrow V(s) + \alpha \delta_t e_t(s), \quad \forall s $$
其中 $\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)$ 是 TD 误差。
5.2 Advantage Actor-Critic (A2C)
A2C(Advantage Actor-Critic)使用优势函数来更新 Actor,同时使用 TD 误差来更新 Critic。
Critic 更新: $$ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) $$ $$ \theta \leftarrow \theta + \alpha \delta_t \nabla_\theta V(s_t) $$
Actor 更新: $$ \theta \leftarrow \theta + \alpha \nabla_\theta \log \pi_\theta(a_t|s_t) A(s_t,a_t) $$
其中优势函数可以用 TD 误差近似:
$$ A(s_t,a_t) \approx \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) $$
5.3 A2C 的数学推导
让我们从策略梯度出发,推导 A2C 的更新规则。
策略梯度可以写成:
$$ \nabla_\theta J(\theta) = \mathbb{E}[\nabla_\theta \log \pi_\theta(a|s) A^\pi(s,a)] $$
优势函数可以表示为:
$$ A^\pi(s,a) = \mathbb{E}[G_t | s_t = s, a_t = a] - V^\pi(s) $$
其中 $G_t$ 是从时间 t 开始的累积奖励。
现在用 TD 目标近似 $G_t$:
$$ G_t \approx r_t + \gamma V^\pi(s_{t+1}) $$
因此:
$$ \delta_t = r_t + \gamma V^\pi(s_{t+1}) - V^\pi(s_t) $$
$\delta_t$ 是 TD 误差,它是 $A^\pi(s_t,a_t)$ 的无偏估计(因为 $\mathbb{E}[\delta_t | s_t, a_t] = A^\pi(s_t,a_t)$)。
现在我们可以用 $\delta_t$ 来近似优势函数,从而得到 Actor 的更新:
$$ \theta \leftarrow \theta + \alpha \delta_t \nabla_\theta \log \pi_\theta(a_t|s_t) $$
同时,Critic 用均方误差损失来学习价值函数:
$$ L(\theta_v) = \mathbb{E}[(r_t + \gamma V(s_{t+1}) - V(s_t))^2] $$
这就是 A2C 的完整更新规则。
5.4 A3C:异步的优势 Actor-Critic
A3C(Asynchronous Advantage Actor-Critic)是 A2C 的并行版本,它使用多个并行的智能体与环境交互,异步地更新全局网络。
A3C 的优势在于:
- 并行探索,样本效率更高
- 异步更新打破了样本之间的相关性,有助于收敛
- 不需要经验回放(Experience Replay)
第六章:深度强化学习
6.1 Deep Q-Network (DQN)
DQN 是第一个成功将深度学习与强化学习结合的算法,它在 Atari 游戏上达到了人类水平的性能。
DQN 的核心创新:
- 经验回放(Experience Replay):将经验存储在缓冲区,随机采样进行训练,打破样本相关性
- 目标网络(Target Network):使用稳定的 Q 值估计,提高训练稳定性
经验回放: $$ D = {(s_t, a_t, r_t, s_{t+1})} $$ $$ \text{Loss} = \mathbb{E}{(s,a,r,s’) \sim D}[(r + \gamma \max{a’} Q(s’,a’;\theta^-) - Q(s,a;\theta))^2] $$
其中 $\theta^-$ 是目标网络的参数,定期与主网络同步。
6.2 Double DQN
DQN 存在高估问题:max 操作会导致 Q 值被高估。Double DQN 通过解耦选择和评估来解决这个问题:
$$ y = r + \gamma Q(s’, \arg\max_{a’} Q(s’,a’;\theta);\theta^-) $$
即用主网络选择动作,用目标网络评估 Q 值。
6.3 Dueling DQN
Dueling DQN 将 Q 函数分解为价值函数和优势函数:
$$ Q(s,a;\theta) = V(s;\theta) + (A(s,a;\theta) - \mathbb{E}_{a}[A(s,a;\theta)]) $$
这样网络可以更好地学习哪些状态是有价值的,而不仅仅是关注动作的优势。
第七章:应用场景
强化学习已经在多个领域取得了显著成果:
7.1 游戏
- AlphaGo:结合蒙特卡洛树搜索和深度神经网络,在围棋上击败人类世界冠军
- Dota 2:OpenAI Five 在 Dota 2 上击败世界冠军
- Atari 游戏:DQN 在 49 个 Atari 游戏上达到人类水平
7.2 机器人控制
- 机械臂抓取:学习精确的抓取策略
- 机器人行走:学习平衡和移动
- 自动驾驶:学习复杂的驾驶策略
7.3 推荐系统
- 用户行为预测:预测用户下一步可能的行为
- 个性化推荐:根据用户历史行为优化推荐策略
- 广告投放:优化广告投放策略以提高点击率
7.4 金融
- 投资组合管理:动态调整资产配置
- 算法交易:学习高频交易策略
- 风险管理:优化风险对冲策略
7.5 自然语言处理
- 对话系统:学习生成自然语言回复
- 文本摘要:学习生成摘要的策略
- 机器翻译:优化翻译质量
第八章:未来前景与挑战
8.1 样本效率
强化学习的主要挑战之一是样本效率。与监督学习不同,强化学习需要大量的交互才能学到有效的策略。
解决方案:
- 模仿学习(Imitation Learning):从专家演示中学习,加速学习过程
- 离线强化学习(Offline RL):从静态数据集中学习,不需要与环境交互
- 元学习(Meta-Learning):学习如何快速学习新任务
8.2 探索与利用
探索(探索未知)与利用(利用已知)的权衡是强化学习的核心问题。
解决方案:
- 内在动机(Intrinsic Motivation):基于好奇心和信息增益进行探索
- 不确定性估计(Uncertainty Estimation):优先探索不确定性高的状态
- 分层强化学习(Hierarchical RL):在不同时间尺度上进行探索和利用
8.3 泛化能力
强化学习算法在训练环境中表现良好,但在测试环境中性能下降,缺乏泛化能力。
解决方案:
- 领域随机化(Domain Randomization):在训练时随机化环境参数
- 领域自适应(Domain Adaptation):在测试环境上快速适应
- 因果强化学习(Causal RL):学习因果关系,提高泛化能力
8.4 多智能体强化学习
在多智能体环境中,每个智能体不仅要适应环境,还要适应其他智能体的策略。
挑战:
- 非平稳性(Non-stationarity):其他智能体的策略不断变化
- 信用分配(Credit Assignment):如何分配团队的奖励给个体
- 通信协调(Communication):智能体之间如何有效通信
解决方案:
- 集中训练,分散执行(Centralized Training, Decentralized Execution):训练时使用全局信息,执行时只使用局部信息
- 多智能体演员-评论家(Multi-Agent Actor-Critic):为每个智能体维护独立的策略和价值函数
- 通信协议学习(Communication Protocol Learning):学习智能体之间的通信方式
8.5 安全性与鲁棒性
强化学习在现实世界应用中必须考虑安全性和鲁棒性。
挑战:
- 安全约束(Safety Constraints):在满足安全约束的前提下优化奖励
- 对抗攻击(Adversarial Attacks):对抗样本可能导致智能体行为异常
- 故障恢复(Failure Recovery):在发生故障时如何快速恢复
解决方案:
- 安全强化学习(Safe RL):在奖励函数中加入安全约束
- 鲁棒性训练(Robust Training):在训练时加入对抗样本
- 应急策略(Emergency Policies):学习应对紧急情况的策略
结语
强化学习通过试错和探索,让智能体在与环境的交互中逐步学习最优策略。从马尔可夫决策过程的数学基础,到 Q-learning、Policy Gradient 和 Actor-Critic 等经典算法,再到深度强化学习的突破,我们见证了一个领域的蓬勃发展。
强化学习的核心思想——通过交互和反馈来学习——不仅适用于人工智能,也为我们理解自然智能和学习本身提供了新的视角。从老鼠在迷宫中寻找奶酪,到 AlphaGo 在围棋盘上的精妙布局,强化学习的数学之美在于它将复杂的决策问题转化为可计算的优化问题。
未来,随着样本效率、泛化能力和安全性等问题的解决,强化学习有望在更多领域发挥重要作用,从智能制造到智慧城市,从个性化教育到精准医疗。强化学习的数学之旅才刚刚开始,更多的挑战和机遇等待着我们去探索和发现。
参考文献:
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
- Mnih, V., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
- Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
- Schulman, J., et al. (2015). High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438.
- Schulman, J., et al. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.