引言:从混沌中发现结构
想象你是一个天文学家,正在观测夜空中的恒星。这些恒星并非均匀分布,而是呈现出明显的"聚集"现象:有些恒星形成了紧密的星团,有些则稀疏地散布在广阔的空间中。你的任务是理解这些恒星是如何分布的——它们属于哪些星团,每个星团的形状和位置是什么。
这就是一个典型的聚类问题:将数据点分组成若干个有意义的组。
最直观的聚类方法是 K-means:将每个数据点分配到最近的簇中心,然后更新簇中心,迭代直至收敛。但 K-means 有一个致命的限制:它假设每个簇是"圆形"的(在二维)或"球形"的(在高维)。这意味着它只能捕捉硬边界的簇,无法处理更复杂的形状,也无法表示一个数据点可能"部分地"属于多个簇。
这时,一个更强大的工具出现了:高斯混合模型(Gaussian Mixture Model, GMM)。GMM 不再做非此即彼的硬分类,而是给每个数据点一个"软"的归属概率——它有多大可能性属于每个簇。这种软聚类的方法不仅更灵活,而且能捕捉更复杂的数据分布。
更重要的是,GMM 引入了机器学习中最深刻的算法之一:EM 算法(Expectation-Maximization,期望最大化)。EM 算法是一种优雅的迭代算法,用于解决含有隐变量的概率模型的参数估计问题。
本文将带你深入 GMM 的世界。我们将从高斯分布的复习开始,理解从 K-means 到 GMM 的自然演进,推导 EM 算法的每一步,探索几何直观,最后了解它在现实世界的应用。准备好了吗?让我们开始这场从数据中发现隐藏结构的旅程。
高斯分布的回顾:多元正态分布
在深入 GMM 之前,我们需要先熟悉多元高斯分布(Multivariate Gaussian Distribution)的数学形式。
一元高斯分布
回忆一下,一元高斯分布的概率密度函数是:
$$ f(x | \mu, \sigma^2) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$
其中:
- $\mu$ 是均值(期望)
- $\sigma^2$ 是方差
- $\sigma > 0$ 是标准差
这个分布的形状是经典的"钟形曲线":在 $\mu$ 处达到峰值,向两侧对称衰减。
多元高斯分布
多元高斯分布是上述概念的推广。设 $\mathbf{x} \in \mathbb{R}^d$ 是一个 $d$ 维随机向量,$\mathbf{\mu} \in \mathbb{R}^d$ 是均值向量,$\mathbf{\Sigma} \in \mathbb{R}^{d \times d}$ 是协方差矩阵(对称正定)。
多元高斯分布的概率密度函数是:
$$ f(\mathbf{x} | \mathbf{\mu}, \mathbf{\Sigma}) = \frac{1}{(2\pi)^{d/2} |\mathbf{\Sigma}|^{1/2}} \exp\left(-\frac{1}{2} (\mathbf{x} - \mathbf{\mu})^\top \mathbf{\Sigma}^{-1} (\mathbf{x} - \mathbf{\mu})\right) $$
这里需要解释几个符号:
- 行列式 $|\mathbf{\Sigma}|$:协方差矩阵的行列式
- 逆矩阵 $\mathbf{\Sigma}^{-1}$:协方差矩阵的逆矩阵
- 二次型 $(\mathbf{x} - \mathbf{\mu})^\top \mathbf{\Sigma}^{-1} (\mathbf{x} - \mathbf{\mu})$:这给出了点 $\mathbf{x}$ 到均值 $\mathbf{\mu}$ 的"距离"
协方差矩阵的意义
协方差矩阵 $\mathbf{\Sigma}$ 捕捉了数据的分布形状。对角线元素 $\Sigma_{ii}$ 是第 $i$ 个特征的方差,非对角线元素 $\Sigma_{ij}$ 是第 $i$ 个和第 $j$ 个特征的协方差:
$$ \Sigma_{ij} = \text{Cov}(X_i, X_j) = E[(X_i - \mu_i)(X_j - \mu_j)] $$
如果 $\Sigma_{ij} = 0$,说明第 $i$ 个和第 $j$ 个特征不相关。
等高线:高斯分布的"轮廓"
多元高斯分布的等高线(即 $f(\mathbf{x})$ 取常数的曲面)是椭圆(在二维)或椭球(在高维)。这些椭球的长轴方向由 $\mathbf{\Sigma}$ 的特征向量给出,轴的长度由特征值给出。
这个几何理解非常重要:每个高斯分布可以看作一个"数据云",其形状由均值(位置)和协方差矩阵(形状)决定。
从 K-means 到 GMM:硬聚类 vs 软聚类
K-means 的局限性
K-means 算法可以用一个简单的概率模型来解释:假设数据由 $K$ 个点源生成,每个点源以等概率生成数据点,且每个数据点服从以该点源为中心的各向同性高斯分布(方差在所有方向上相等)。
数学上,这等价于假设每个簇的协方差矩阵是 $\sigma^2 \mathbf{I}$($\sigma^2$ 乘以单位矩阵),即"圆形"或"球形"的分布。
这个假设有两个问题:
- 形状限制:现实中的数据簇往往不是球形的。例如,考虑二维数据,如果簇是椭圆形的,K-means 可能会将一个椭圆簇分成两个球形簇。
- 硬分配:每个数据点只能完全属于一个簇。但很多情况下,数据点确实"介于"两个簇之间。
GMM 的核心思想
GMM 的核心思想是:用 $K$ 个高斯分布的线性组合来建模数据。每个数据点以一定的概率来自每个高斯分布,而且这个概率是我们需要学习的。
数学上,GMM 的概率密度函数是:
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \mathcal{N}(\mathbf{x} | \mathbf{\mu}_k, \mathbf{\Sigma}_k) $$
其中:
- $K$ 是高斯分量(簇)的数量
- $\pi_k$ 是混合系数(mixing coefficient),满足 $\sum_{k=1}^{K} \pi_k = 1$ 且 $\pi_k \geq 0$
- $\mathbf{\mu}_k$ 是第 $k$ 个高斯分量的均值
- $\mathbf{\Sigma}_k$ 是第 $k$ 个高斯分量的协方差矩阵
- $\mathcal{N}(\mathbf{x} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)$ 是均值为 $\mathbf{\mu}_k$、协方差矩阵为 $\mathbf{\Sigma}_k$ 的高斯分布
软聚类:责任(Responsibility)
在 GMM 中,我们引入一个隐变量 $\mathbf{z}$,表示数据点来自哪个高斯分量。$\mathbf{z}$ 是一个 $K$ 维的 one-hot 向量,如果 $\mathbf{z} = \mathbf{e}_k$(第 $k$ 个元素为 1,其余为 0),则表示 $\mathbf{x}$ 来自第 $k$ 个高斯分量。
后验概率(responsibility)$\gamma_{nk}$ 定义为:
$$ \gamma_{nk} = p(z_k = 1 | \mathbf{x}_n, \mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma}) = \frac{\pi_k \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_k, \mathbf{\Sigma}k)}{\sum{j=1}^{K} \pi_j \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_j, \mathbf{\Sigma}_j)} $$
这个公式的解释是:给定数据点 $\mathbf{x}_n$,它来自第 $k$ 个高斯分量的后验概率,正比于第 $k$ 个高斯分量的先验概率 $\pi_k$ 乘以该高斯分量生成 $\mathbf{x}_n$ 的似然。
$\gamma_{nk}$ 可以理解为数据点 $\mathbf{x}n$ 对第 $k$ 个高斯分量的"责任"或"软分配"。与 K-means 的硬分配不同,$\gamma{nk}$ 是一个 $[0, 1]$ 之间的概率值。
完整的 GMM 模型
GMM 的完整模型包含:
生成过程:
- 从混合分布 $\text{Categorical}(\pi_1, \ldots, \pi_K)$ 中采样一个分量 $z$
- 从 $\mathcal{N}(\mathbf{\mu}_z, \mathbf{\Sigma}_z)$ 中采样 $\mathbf{x}$
参数集:
- $\mathbf{\pi} = (\pi_1, \pi_2, \ldots, \pi_K)$:混合系数
- $\mathbf{\mu} = (\mathbf{\mu}_1, \mathbf{\mu}_2, \ldots, \mathbf{\mu}_K)$:均值向量
- $\mathbf{\Sigma} = (\mathbf{\Sigma}_1, \mathbf{\Sigma}_2, \ldots, \mathbf{\Sigma}_K)$:协方差矩阵
隐变量:
- $\mathbf{z}_1, \mathbf{z}_2, \ldots, \mathbf{z}_N$:每个数据点的分量归属
EM 算法:从随机到最优的优雅迭代
现在,我们面临一个关键问题:给定数据集 ${\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_N}$,如何估计 GMM 的参数 $\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma}$?
这是一个经典的含有隐变量的参数估计问题。直接使用最大似然估计会得到一个极其复杂的优化问题,无法解析求解。
EM 算法提供了一种优雅的解决方案:通过迭代地优化下界来逐步改进参数估计。
下界:对数似然函数的期望
设观测数据为 $\mathbf{X} = {\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_N}$,隐变量为 $\mathbf{Z} = {\mathbf{z}_1, \mathbf{z}_2, \ldots, \mathbf{z}_N}$。
完全数据(观测+隐变量)的对数似然函数是:
$$ \mathcal{L}c(\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma} | \mathbf{X}, \mathbf{Z}) = \sum{n=1}^{N} \sum_{k=1}^{K} z_{nk} \left[\log \pi_k + \log \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\right] $$
但 $\mathbf{Z}$ 是未知的,我们无法直接优化 $\mathcal{L}_c$。EM 算法的思路是:在给定当前参数的条件下,计算隐变量的后验期望,然后用这个期望来更新参数。
定义 $Q$ 函数:
$$ Q(\mathbf{\theta}, \mathbf{\theta}^{\text{old}}) = E_{\mathbf{Z}|\mathbf{X}, \mathbf{\theta}^{\text{old}}}[\log p(\mathbf{X}, \mathbf{Z} | \mathbf{\theta})] $$
其中 $\mathbf{\theta} = (\mathbf{\pi}, \mathbf{\mu}, \mathbf{\Sigma})$ 是所有参数。
EM 算法的核心保证是:$Q$ 函数的增加意味着对数似然函数的增加(或至少不减少)。
E 步:计算后验期望
给定当前参数 $\mathbf{\theta}^{\text{old}}$,计算后验概率 $\gamma_{nk}^{(t)}$:
$$ \gamma_{nk}^{(t)} = \frac{\pi_k^{(t)} \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_k^{(t)}, \mathbf{\Sigma}k^{(t)})}{\sum{j=1}^{K} \pi_j^{(t)} \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_j^{(t)}, \mathbf{\Sigma}_j^{(t)})} $$
然后,计算 $Q$ 函数的期望。经过一些代数运算(这里我们略去繁琐的推导),$Q$ 函数可以写成:
$$ Q(\mathbf{\theta}, \mathbf{\theta}^{(t)}) = \sum_{n=1}^{N} \sum_{k=1}^{K} \gamma_{nk}^{(t)} \left[\log \pi_k + \log \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_k, \mathbf{\Sigma}_k)\right] $$
M 步:最大化 $Q$ 函数
现在,我们需要对 $\mathbf{\theta}$ 最大化 $Q$ 函数。这可以分成三个独立的问题。
1. 更新混合系数 $\pi_k$
对 $\pi_k$ 最大化 $Q$ 函数,带有约束 $\sum_{k=1}^{K} \pi_k = 1$ 和 $\pi_k \geq 0$。
使用拉格朗日乘数法:
$$ \frac{\partial}{\partial \pi_k} \left[Q + \lambda \left(\sum_{j=1}^{K} \pi_j - 1\right)\right] = \sum_{n=1}^{N} \frac{\gamma_{nk}^{(t)}}{\pi_k} + \lambda = 0 $$
解得:
$$ \pi_k^{(t+1)} = \frac{1}{N} \sum_{n=1}^{N} \gamma_{nk}^{(t)} $$
直观上,新的混合系数是所有数据点对第 $k$ 个分量的平均责任。
2. 更新均值 $\mathbf{\mu}_k$
对 $\mathbf{\mu}_k$ 最大化 $Q$ 函数,我们得到:
$$ \mathbf{\mu}k^{(t+1)} = \frac{\sum{n=1}^{N} \gamma_{nk}^{(t)} \mathbf{x}n}{\sum{n=1}^{N} \gamma_{nk}^{(t)}} $$
直观上,新的均值是所有数据点的加权平均,权重是数据点对该分量的责任。
3. 更新协方差矩阵 $\mathbf{\Sigma}_k$
对 $\mathbf{\Sigma}_k$ 最大化 $Q$ 函数,我们得到:
$$ \mathbf{\Sigma}k^{(t+1)} = \frac{\sum{n=1}^{N} \gamma_{nk}^{(t)} (\mathbf{x}_n - \mathbf{\mu}_k^{(t+1)})(\mathbf{x}n - \mathbf{\mu}k^{(t+1)})^\top}{\sum{n=1}^{N} \gamma{nk}^{(t)}} $$
直观上,新的协方差矩阵是加权样本协方差,权重是责任。
EM 算法的完整流程
综合起来,EM 算法的流程是:
初始化:
- 随机初始化参数 $\mathbf{\mu}^{(0)}, \mathbf{\Sigma}^{(0)}, \mathbf{\pi}^{(0)}$
- 或使用 K-means++ 进行更好的初始化
迭代: 对于 $t = 0, 1, 2, \ldots$:
E 步:计算后验责任 $$ \gamma_{nk}^{(t)} = \frac{\pi_k^{(t)} \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_k^{(t)}, \mathbf{\Sigma}k^{(t)})}{\sum{j=1}^{K} \pi_j^{(t)} \mathcal{N}(\mathbf{x}_n | \mathbf{\mu}_j^{(t)}, \mathbf{\Sigma}_j^{(t)})} $$
M 步:更新参数
$$ \pi_k^{(t+1)} = \frac{1}{N} \sum_{n=1}^{N} \gamma_{nk}^{(t)} $$
$$ \mathbf{\mu}k^{(t+1)} = \frac{\sum{n=1}^{N} \gamma_{nk}^{(t)} \mathbf{x}n}{\sum{n=1}^{N} \gamma_{nk}^{(t)}} $$
$$ \mathbf{\Sigma}k^{(t+1)} = \frac{\sum{n=1}^{N} \gamma_{nk}^{(t)} (\mathbf{x}_n - \mathbf{\mu}_k^{(t+1)})(\mathbf{x}n - \mathbf{\mu}k^{(t+1)})^\top}{\sum{n=1}^{N} \gamma{nk}^{(t)}} $$
检查收敛:如果参数变化很小或对数似然函数变化很小,停止迭代
EM 算法的收敛性:单调递增的保证
EM 算法有一个非常重要的性质:单调性保证。具体来说,每次迭代后,对数似然函数都会增加(或至少不减少):
$$ \mathcal{L}(\mathbf{\theta}^{(t+1)}) \geq \mathcal{L}(\mathbf{\theta}^{(t)}) $$
这个性质可以通过以下步骤证明:
下界关系:对于任何参数 $\mathbf{\theta}$,有 $$ \mathcal{L}(\mathbf{\theta}) \geq Q(\mathbf{\theta}, \mathbf{\theta}^{(t)}) $$ 这是因为 $Q$ 函数是 $\log p(\mathbf{X}, \mathbf{Z} | \mathbf{\theta})$ 对 $\mathbf{Z}$ 的期望,而对数似然函数是 $\log \sum_{\mathbf{Z}} p(\mathbf{X}, \mathbf{Z} | \mathbf{\theta})$。根据 Jensen 不等式,$\log E[X] \geq E[\log X]$,所以不等式成立。
E 步保持相等:$Q(\mathbf{\theta}^{(t)}, \mathbf{\theta}^{(t)}) = \mathcal{L}(\mathbf{\theta}^{(t)})$,因为我们在 E 步中是用后验分布计算期望的。
M 步最大化 $Q$:$\mathbf{\theta}^{(t+1)} = \arg\max_{\mathbf{\theta}} Q(\mathbf{\theta}, \mathbf{\theta}^{(t)})$
综合: $$ \mathcal{L}(\mathbf{\theta}^{(t+1)}) \geq Q(\mathbf{\theta}^{(t+1)}, \mathbf{\theta}^{(t)}) \geq Q(\mathbf{\theta}^{(t)}, \mathbf{\theta}^{(t)}) = \mathcal{L}(\mathbf{\theta}^{(t)}) $$
这个单调性保证意味着 EM 算法会收敛到局部最优解,但需要注意:
- 收敛速度:开始快,后期慢
- 局部最优:可能陷入局部最优,取决于初始化
- 数值稳定性:协方差矩阵可能出现奇异性问题,需要正则化
几何直观:椭圆与等高线
GMM 的几何直观非常优美。每个高斯分量可以看作一个"数据云",其形状是椭球。
二维 GMM 的可视化
在二维情况下,每个高斯分量的等高线是椭圆。椭圆的长轴方向是协方差矩阵 $\mathbf{\Sigma}$ 的特征向量方向,轴的长度与特征值的平方根成正比。
下图展示了一个简单的二维 GMM:
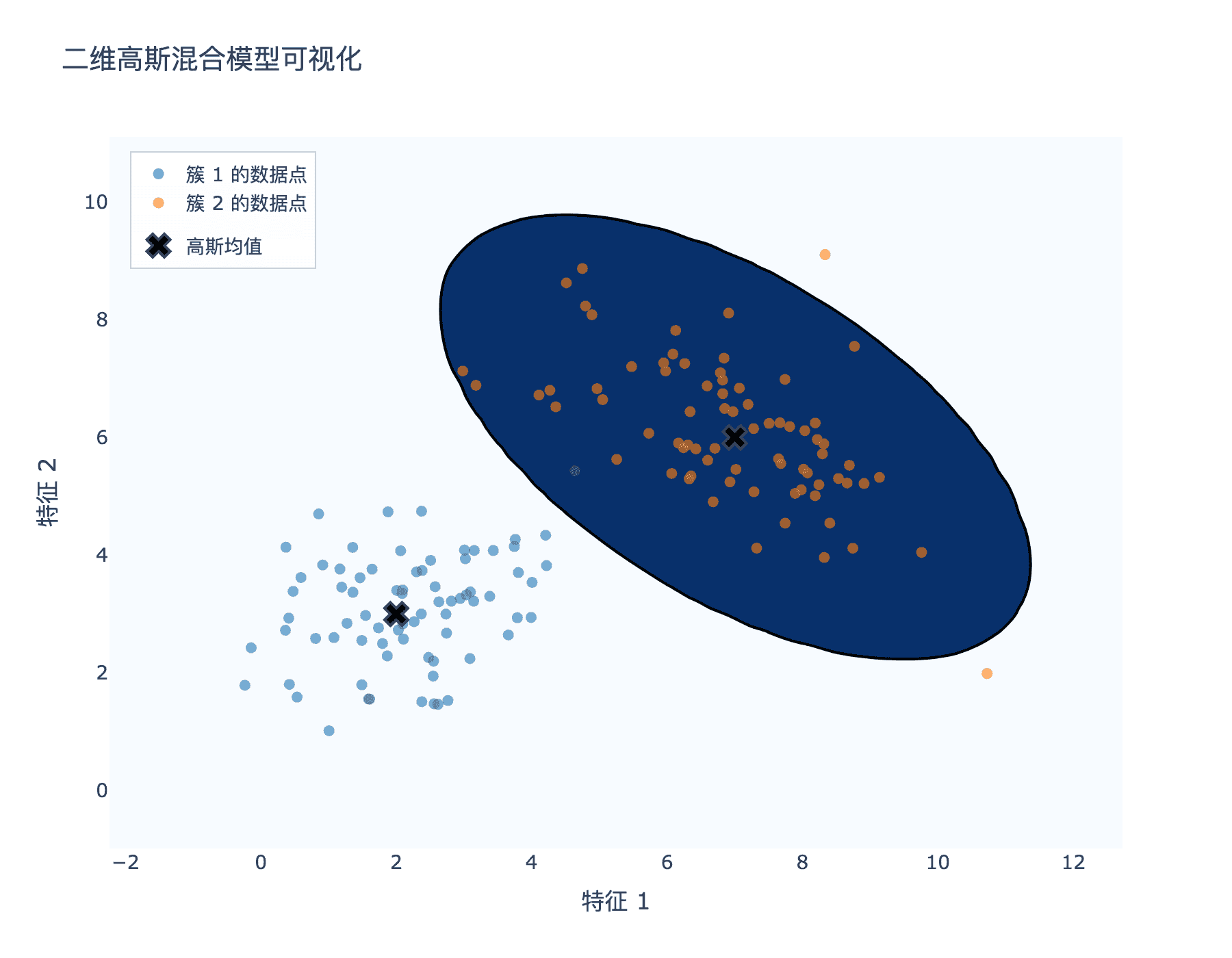
图 1:二维 GMM 可视化。红色椭圆表示第一个高斯分量,蓝色椭圆表示第二个高斯分量。数据点用不同的颜色表示它们对每个分量的责任(颜色越深表示责任越大)
软聚类的直观解释
想象每个数据点是一滴墨水,每个高斯分量是一片吸收墨水的海绵。$\gamma_{nk}$ 表示墨水滴被第 $k$ 个海绵吸收的比例。
在 E 步中,我们计算每滴墨水被每个海绵吸收的比例。在 M 步中,我们调整每个海绵的位置和形状,以便更好地吸收分配给它的墨水。
与 K-means 的对比
K-means 可以看作 GMM 的一个特例:
- 每个高斯分量的协方差矩阵是 $\mathbf{\Sigma}_k = \sigma^2 \mathbf{I}$(球形)
- 责任 $\gamma_{nk}$ 硬化为 0 或 1(硬分配)
下图对比了 K-means 和 GMM 的差异:
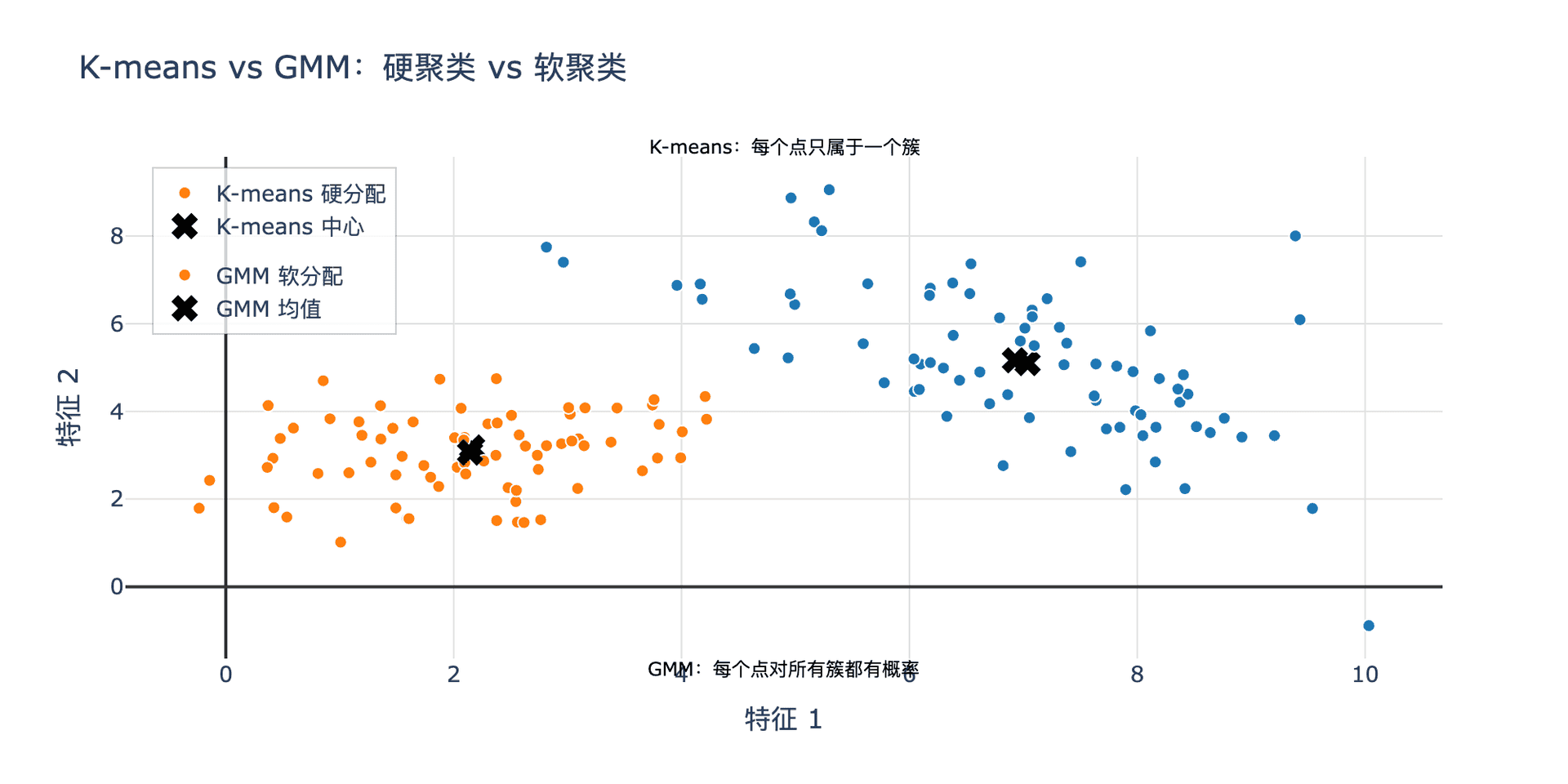
图 2:K-means vs GMM。K-means(左)进行硬分配,每个数据点只属于一个簇。GMM(右)进行软分配,每个数据点对所有簇都有责任值,颜色越深表示责任越大
EM 算法的初始化:避免局部最优
EM 算法的一个关键问题是对数似然函数可能有多个局部最大值,而 EM 算法只能保证收敛到最近的局部最大值。初始化的好坏严重影响最终结果。
随机初始化
最简单的方法是随机初始化:
- 随机选择 $K$ 个数据点作为初始均值
- 将协方差矩阵初始化为单位矩阵
- 混合系数初始化为 $\pi_k = 1/K$
这种方法简单但可能收敛到次优解。
K-means++ 初始化
K-means++ 是一种更好的初始化方法:
- 随机选择第一个中心
- 对于 $k = 2$ 到 $K$:
- 计算每个数据点到最近已选中心的距离平方 $d_k(\mathbf{x}_n)$
- 选择下一个中心的概率与 $d_k(\mathbf{x}_n)^2$ 成正比
- 用这 $K$ 个中心初始化 K-means,运行直到收敛
- 用 K-means 的结果初始化 GMM 的均值
- 计算每个簇的样本协方差作为 GMM 的初始协方差矩阵
- 计算每个簇的样本比例作为初始混合系数
这种方法能显著提高初始质量。
实际应用:从语音到图像
GMM 在许多实际领域有广泛应用。
应用一:语音识别
在语音识别中,GMM 用于建模声学模型。每个音素(如 /a/, /e/, /m/)可以用多个高斯分量建模,以捕捉不同的发音方式和说话人特征。
例如,音素 /a/ 可能有 3-5 个高斯分量,分别对应不同说话人、不同口音或不同上下文。
应用二:异常检测
GMM 可以用于异常检测:如果一个数据点对所有高斯分量都有很低的似然,则可能是异常点。
方法:
- 用正常数据训练 GMM
- 计算新数据点的似然 $p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \mathcal{N}(\mathbf{x} | \mathbf{\mu}_k, \mathbf{\Sigma}_k)$
- 如果 $p(\mathbf{x}) < \text{threshold}$,标记为异常
这在金融欺诈检测、网络入侵检测等领域有广泛应用。
应用三:图像分割
在图像分割中,GMM 可以用于将像素聚类到不同的颜色区域。例如:
- 将每个像素表示为一个三维向量 $(R, G, B)$
- 用 GMM 对所有像素建模,选择 $K$ 个高斯分量
- 每个像素分配到责任最大的分量
- 结果是图像被分割成 $K$ 个颜色区域
这种方法简单但有效,常作为复杂图像分割算法的预处理步骤。
应用四:文本建模
在自然语言处理中,GMM 可以用于建模词向量的分布,或者用于主题模型的变体。例如,可以用 GMM 将文档聚类到不同的主题。
GMM 的优缺点与扩展
GMM 的优点
- 灵活性:能建模任意形状的数据分布(多个高斯分量的线性组合)
- 软聚类:提供概率分配,而非硬分配
- 理论基础完备:有坚实的统计理论支持
- 可解释性:每个高斯分量都有明确的物理意义
GMM 的缺点
- 局部最优:EM 算法可能陷入局部最优
- 初始化敏感:不同的初始化可能导致不同的结果
- 模型选择困难:如何选择 $K$(高斯分量数量)是一个开放问题
- 数值稳定性:协方差矩阵可能出现奇异性
模型选择:如何选择 $K$?
选择高斯分量数量 $K$ 的常用方法:
BIC (Bayesian Information Criterion): $$ \text{BIC}(K) = -2\mathcal{L}_{\text{max}}(K) + \frac{p}{2} \log N $$ 其中 $p$ 是参数数量。选择 BIC 最小的 $K$。
AIC (Akaike Information Criterion): $$ \text{AIC}(K) = -2\mathcal{L}_{\text{max}}(K) + 2p $$
交叉验证:将数据分为训练集和验证集,选择在验证集上表现最好的 $K$。
扩展:贝叶斯 GMM
传统 GMM 的一个问题是过拟合:过多的高斯分量会导致模型过于复杂。贝叶斯 GMM 通过为每个高斯分量放置先验分布来解决过拟合问题。
贝叶斯 GMM 使用变分推断或 MCMC 来计算后验分布,而非点估计。这提供了更完整的不确定性量化。
总结:从数据中学习隐藏的艺术
GMM 是一个美丽而强大的算法。它用概率的语言描述了数据的隐藏结构,用 EM 算法优雅地解决了参数估计问题。
从 K-means 到 GMM,我们看到了从硬聚类到软聚类的自然演进。从单一的球形簇,我们到了灵活的椭圆数据云。从简单的距离度量,我们到了复杂的概率模型。
EM 算法的优雅之处在于:它不直接优化难以处理的似然函数,而是通过迭代地优化下界来逐步改进。这种方法在机器学习中有广泛应用,不仅在 GMM 中,还在隐马尔可夫模型、潜在狄利克雷分配等模型中。
GMM 的哲学也值得思考:它假设数据是由简单的概率模型生成的,即使真实的数据生成过程可能更复杂。这种"简约性假设"是统计学的核心思想之一——我们用简单的模型来拟合复杂的数据,然后检查模型是否足够好。
在实际应用中,GMM 与其他技术的结合往往能产生更好的效果。例如,GMM 可以用作更复杂模型的基础,或者在预处理阶段帮助理解数据结构。
从观测数据中学习隐藏的结构,这是机器学习的终极目标之一。GMM 为我们提供了一个强有力的工具,让我们能够从混沌的数据中发现秩序,从噪声中提取信号。这不仅是数学的胜利,更是理解世界的艺术。