引言:从混沌中寻找秩序
想象你是一个天文学家,正在观测一群恒星的位置。这些恒星在三维空间中分布,你记录了每颗恒星到地球的距离、赤经和赤纬——这就是一个典型的三维数据集。但是,你想理解这些恒星的分布规律,三维空间太复杂了。你突然意识到:这些恒星实际上分布在一个接近平面的薄层上!如果能找到这个平面,你就可以用二维坐标来描述每颗恒星的位置,大大简化问题。
这个看似简单的思想——在高维数据中找到最能代表数据的低维子空间——就是主成分分析(Principal Component Analysis, PCA)的核心。
在机器学习、数据科学和统计学中,我们经常面临"维度灾难":数据维度越高,计算越复杂,噪声越多,模型越容易过拟合。PCA 提供了一种优雅的解决方案:它不丢弃任何原始特征的信息,而是将数据投影到新的坐标系中,在这个新坐标系中,前几个坐标轴(主成分)包含了数据的大部分信息。
本文将带你深入 PCA 的世界。我们从直观的几何理解开始,穿越历史的长河,探索两种等价的数学推导视角,最终抵达实际应用的海岸。准备好了吗?让我们开始这场降维之旅。
PCA 的直观理解:投影的智慧
为什么需要降维?
在深入数学之前,让我们先理解为什么降维如此重要。
假设你有一个包含 $1000$ 个人的数据集,每个人有 $100$ 个特征(身高、体重、血压、血糖、血细胞计数等)。这些特征之间往往存在相关性:身高和体重相关,血压和血糖相关。如果我们直接用 $100$ 个特征来分析,会遇到以下问题:
- 计算复杂度:随着维度增加,算法的运行时间呈指数级增长。
- 过拟合风险:特征越多,模型越容易记住训练数据,泛化能力下降。
- 存储压力:$1000$ 个人 $\times$ $100$ 个特征 $= 100,000$ 个数据点,存储和传输成本高。
- 可视化困难:我们只能在三维空间中直接观察数据,超过三维就无法直观理解。
PCA 的目标是找到一个低维表示,保留数据的大部分信息。关键问题是:如何衡量"信息保留"?答案是方差。
方差作为信息度量
在一个数据集中,方差大的方向包含更多的信息。考虑一个简单的例子:假设我们有一个二维数据集,点的分布如图所示。
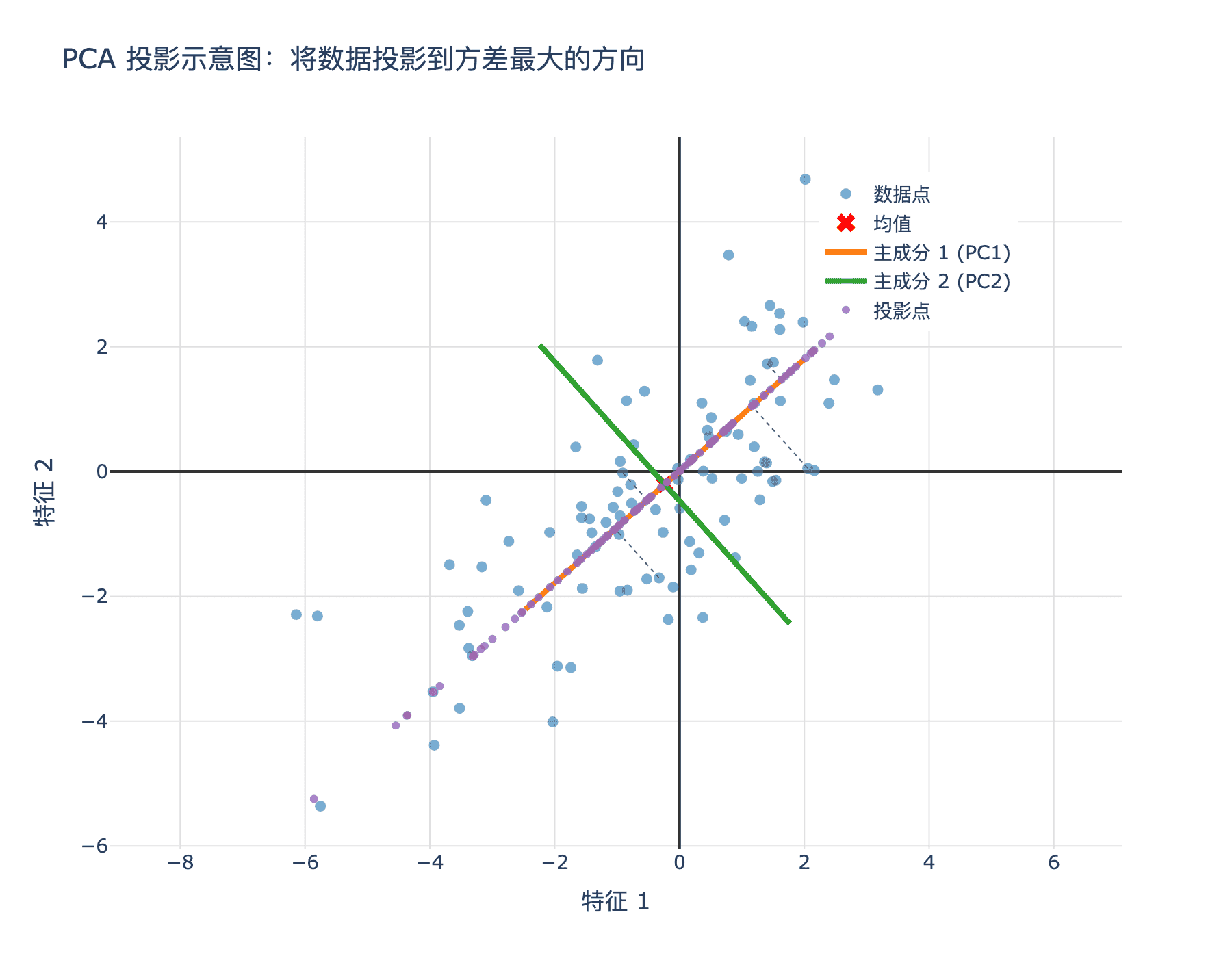
图 1:PCA 的核心思想:将数据投影到方差最大的方向
如果我们把这些点投影到不同的直线上,哪种投影方式能最好地保留原始数据的信息?
直觉告诉我们:应该投影到数据"伸展"最厉害的方向上。在这个方向上,投影点的分布范围最广,方差最大,这意味着投影后保留了更多的原始信息。
让我们用数学语言来表述这个直觉。设 $n$ 个 $d$ 维数据点 $\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n \in \mathbb{R}^d$,我们想找到一个单位向量 $\mathbf{w} \in \mathbb{R}^d$($|\mathbf{w}| = 1$),使得数据投影到 $\mathbf{w}$ 上的方差最大。
数据点 $\mathbf{x}_i$ 投影到 $\mathbf{w}$ 上的值是:
$$ z_i = \mathbf{w}^{\top} \mathbf{x}_i $$
投影值的均值是:
$$ \bar{z} = \frac{1}{n}\sum_{i=1}^{n} z_i = \mathbf{w}^{\top} \bar{\mathbf{x}} $$
其中 $\bar{\mathbf{x}} = \frac{1}{n}\sum_{i=1}^{n} \mathbf{x}_i$ 是数据的均值。
投影的方差是:
$$ \text{Var}(z) = \frac{1}{n}\sum_{i=1}^{n} (z_i - \bar{z})^2 = \frac{1}{n}\sum_{i=1}^{n} (\mathbf{w}^{\top} (\mathbf{x}_i - \bar{\mathbf{x}}))^2 $$
让我们定义中心化的数据 $\tilde{\mathbf{x}}_i = \mathbf{x}_i - \bar{\mathbf{x}}$,则:
$$ \text{Var}(z) = \frac{1}{n}\sum_{i=1}^{n} (\mathbf{w}^{\top} \tilde{\mathbf{x}}i)^2 = \frac{1}{n}\sum{i=1}^{n} \mathbf{w}^{\top} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}i^{\top} \mathbf{w} = \mathbf{w}^{\top} \left(\frac{1}{n}\sum{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}_i^{\top}\right) \mathbf{w} $$
注意到 $\frac{1}{n}\sum_{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}_i^{\top}$ 正是数据的协方差矩阵:
$$ \mathbf{\Sigma} = \frac{1}{n}\sum_{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}_i^{\top} $$
因此,PCA 的优化问题是:
$$ \max_{\mathbf{w}} \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w}, \quad \text{约束:} \mathbf{w}^{\top} \mathbf{w} = 1 $$
这就是 PCA 的第一个视角:寻找使投影方差最大的方向。
历史背景:从 Pearson 到 Hotelling
PCA 的历史可以追溯到 20 世纪初的统计学领域,两位数学家的贡献奠定了这个算法的基础。
Karl Pearson:几何解释的开创者
1901 年,英国统计学家 Karl Pearson 发表了一篇题为"On lines and planes of closest fit to systems of points in space"(论空间点系的最优拟合线和面)的论文。Pearson 从几何角度思考:给定一组散布在空间中的点,如何找到一条直线或一个平面,使得这些点到这条线或平面的距离平方和最小?
这个看似纯粹的几何问题,实际上等价于我们刚才讨论的"最大化投影方差"问题!Pearson 证明了,最优的投影方向正是数据的"主轴"——数据"伸展"最厉害的方向。
Pearson 的贡献不仅在于问题的表述,更在于他发现这个问题的解可以通过特征值分解来获得。虽然当时线性代数的理论还不像今天这样成熟,但 Pearson 已经直觉地抓住了问题的本质。
Harold Hotelling:统计视角的完善
1933 年,美国数学家和统计学家 Harold Hotelling 独立地重新发现了 PCA,但从一个不同的角度。他将这个问题命名为"主成分分析"(Principal Component Analysis),并给出了完整的统计学解释。
Hotelling 的论文"Analysis of a complex of statistical variables into principal components"(将统计变量复合体分解为主成分)不仅解决了如何找到主成分的问题,还给出了一个清晰的解释:每个主成分都是原始变量的线性组合,这些主成分按照解释数据方差的大小排序,且彼此之间不相关。
Hotelling 的贡献使得 PCA 从一个纯粹的几何方法发展成为一个完整的统计工具,并广泛应用于实际数据分析中。
值得一提的是,Hotelling 的 $T^2$ 统计量——一种多变量检验方法——至今仍在质量控制中广泛应用。
PCA 的数学推导(视角一):最大化方差
现在,让我们严谨地推导 PCA 的数学公式。我们将从"最大化投影方差"这个视角出发,逐步建立完整的理论框架。
优化问题的建立
我们有 $n$ 个 $d$ 维数据点 $\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n \in \mathbb{R}^d$。首先,对数据进行中心化:
$$ \tilde{\mathbf{x}}_i = \mathbf{x}i - \bar{\mathbf{x}}, \quad \bar{\mathbf{x}} = \frac{1}{n}\sum{i=1}^{n} \mathbf{x}_i $$
计算协方差矩阵:
$$ \mathbf{\Sigma} = \frac{1}{n}\sum_{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}_i^{\top} \in \mathbb{R}^{d \times d} $$
注意:$\mathbf{\Sigma}$ 是一个对称半正定矩阵。
我们要找到第一个主成分的方向 $\mathbf{w}_1$,使得投影方差最大:
$$ \mathbf{w}1 = \arg\max{\mathbf{w}} \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w}, \quad \text{s.t. } \mathbf{w}^{\top} \mathbf{w} = 1 $$
使用拉格朗日乘数法
这是一个带约束的优化问题,我们可以使用拉格朗日乘数法求解。定义拉格朗日函数:
$$ \mathcal{L}(\mathbf{w}, \lambda) = \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w} - \lambda (\mathbf{w}^{\top} \mathbf{w} - 1) $$
其中 $\lambda$ 是拉格朗日乘数。
对 $\mathbf{w}$ 求梯度并设为零:
$$ \frac{\partial \mathcal{L}}{\partial \mathbf{w}} = 2\mathbf{\Sigma}\mathbf{w} - 2\lambda \mathbf{w} = 0 $$
简化得到:
$$ \mathbf{\Sigma} \mathbf{w} = \lambda \mathbf{w} $$
这正是特征值问题!$\mathbf{w}$ 是 $\mathbf{\Sigma}$ 的特征向量,$\lambda$ 是对应的特征值。
理解特征值的含义
让我们计算投影方差的值。将特征方程 $\mathbf{\Sigma} \mathbf{w} = \lambda \mathbf{w}$ 代入方差表达式:
$$ \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w} = \mathbf{w}^{\top} \lambda \mathbf{w} = \lambda \mathbf{w}^{\top} \mathbf{w} = \lambda $$
因为 $\mathbf{w}$ 是单位向量,$\mathbf{w}^{\top} \mathbf{w} = 1$。
这说明:投影方差等于对应的特征值!
因此,要使投影方差最大,我们需要选择 $\mathbf{\Sigma}$ 的最大特征值对应的特征向量。
第二个主成分及后续主成分
找到第一个主成分 $\mathbf{w}_1$ 后,我们希望找到第二个主成分 $\mathbf{w}_2$,它应该满足:
- 最大化投影方差
- 与 $\mathbf{w}_1$ 正交(不相关)
数学表述为:
$$ \mathbf{w}2 = \arg\max{\mathbf{w}} \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w}, \quad \text{s.t. } \mathbf{w}^{\top} \mathbf{w} = 1, \mathbf{w}^{\top} \mathbf{w}_1 = 0 $$
同样使用拉格朗日乘数法:
$$ \mathcal{L}(\mathbf{w}, \lambda, \mu) = \mathbf{w}^{\top} \mathbf{\Sigma} \mathbf{w} - \lambda (\mathbf{w}^{\top} \mathbf{w} - 1) - \mu \mathbf{w}^{\top} \mathbf{w}_1 $$
对 $\mathbf{w}$ 求梯度:
$$ 2\mathbf{\Sigma}\mathbf{w} - 2\lambda \mathbf{w} - \mu \mathbf{w}_1 = 0 $$
左乘 $\mathbf{w}_1^\top$:
$$ 2\mathbf{w}_1^{\top} \mathbf{\Sigma}\mathbf{w} - 2\lambda \mathbf{w}_1^{\top} \mathbf{w} - \mu \mathbf{w}_1^{\top} \mathbf{w}_1 = 0 $$
由于 $\mathbf{\Sigma}\mathbf{w}_1 = \lambda_1 \mathbf{w}_1$(其中 $\lambda_1$ 是最大特征值):
$$ 2\lambda_1 \mathbf{w}_1^{\top} \mathbf{w} - 2\lambda \mathbf{w}_1^{\top} \mathbf{w} - \mu = 0 $$
但 $\mathbf{w}_1^{\top} \mathbf{w} = 0$(正交约束),所以 $\mu = 0$。
因此,我们得到:
$$ \mathbf{\Sigma}\mathbf{w} = \lambda \mathbf{w} $$
这说明 $\mathbf{w}_2$ 也必须是 $\mathbf{\Sigma}$ 的特征向量!但由于 $\mathbf{w}_2$ 必须与 $\mathbf{w}_1$ 正交,$\mathbf{w}_2$ 只能选择第二大特征值对应的特征向量。
同理,第 $k$ 个主成分 $\mathbf{w}_k$ 是 $\mathbf{\Sigma}$ 的第 $k$ 大特征值 $\lambda_k$ 对应的特征向量。
总结
从"最大化方差"的视角,我们得出:
- 协方差矩阵 $\mathbf{\Sigma}$ 的特征向量是 PCA 的主成分方向
- 特征值 $\lambda_k$ 是投影到第 $k$ 个主成分的方差
- 主成分排序:按特征值从大到小排列
- 主成分正交:不同特征值对应的特征向量相互正交
这个推导优雅而简洁,将 PCA 的几何直觉与线性代数的特征值理论完美地结合在一起。
PCA 的数学推导(视角二):最小化重构误差
现在,我们从另一个角度理解 PCA:最小化重构误差。这个视角虽然与前一个等价,但提供了不同的物理直觉。
重构问题的建立
假设我们想将 $d$ 维数据降维到 $k$ 维($k < d$)。设我们找到了 $k$ 个正交单位向量 $\mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_k$,作为新坐标系的基。
对于数据点 $\mathbf{x}_i$,它的降维表示(编码)是:
$$ \mathbf{z}i = (z{i1}, z_{i2}, \ldots, z_{ik})^\top $$
其中 $z_{ij} = \mathbf{w}_j^{\top} \tilde{\mathbf{x}}_i$ 是 $\tilde{\mathbf{x}}_i$ 在 $\mathbf{w}_j$ 上的投影。
从低维表示重构(解码)回原始空间:
$$ \hat{\mathbf{x}}i = \bar{\mathbf{x}} + \sum{j=1}^{k} z_{ij} \mathbf{w}_j $$
这就是将中心化数据投影到前 $k$ 个主成分张成的子空间,然后再加回均值。
重构误差定义为原始数据与重构数据的欧氏距离平方:
$$ \text{Error} = \sum_{i=1}^{n} |\mathbf{x}i - \hat{\mathbf{x}}i|^2 = \sum{i=1}^{n} |\tilde{\mathbf{x}}i - \sum{j=1}^{k} z{ij} \mathbf{w}_j|^2 $$
我们的目标是最小化这个误差:
$$ \min_{\mathbf{w}_1, \ldots, \mathbf{w}k} \sum{i=1}^{n} \left|\tilde{\mathbf{x}}i - \sum{j=1}^{k} \mathbf{w}_j (\mathbf{w}_j^{\top} \tilde{\mathbf{x}}_i)\right|^2 $$
利用正交投影的性质
记 $\mathbf{W} = [\mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_k] \in \mathbb{R}^{d \times k}$,则重构误差可以写成:
$$ \text{Error} = \sum_{i=1}^{n} |\tilde{\mathbf{x}}_i - \mathbf{W}\mathbf{W}^{\top} \tilde{\mathbf{x}}_i|^2 $$
利用矩阵迹的性质 $\sum_{i=1}^{n} |\mathbf{a}i|^2 = \text{tr}\left(\sum{i=1}^{n} \mathbf{a}_i \mathbf{a}_i^{\top}\right)$:
$$ \text{Error} = \sum_{i=1}^{n} \text{tr}\left((\tilde{\mathbf{x}}_i - \mathbf{W}\mathbf{W}^\top \tilde{\mathbf{x}}_i)(\tilde{\mathbf{x}}_i - \mathbf{W}\mathbf{W}^\top \tilde{\mathbf{x}}_i)^\top\right) $$
$$ = \text{tr}\left(\sum_{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}i^\top\right) - 2\text{tr}\left(\mathbf{W}^\top \sum{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}i^\top \mathbf{W}\right) + \text{tr}\left(\mathbf{W}^\top \sum{i=1}^{n} \tilde{\mathbf{x}}_i \tilde{\mathbf{x}}_i^\top \mathbf{W}\right) $$
$$ = \text{tr}(n\mathbf{\Sigma}) - \text{tr}(\mathbf{W}^\top n \mathbf{\Sigma} \mathbf{W}) $$
$$ = n \left[\text{tr}(\mathbf{\Sigma}) - \text{tr}(\mathbf{W}^\top \mathbf{\Sigma} \mathbf{W})\right] $$
这里我们利用了 $\mathbf{W}^{\top} \mathbf{W} = \mathbf{I}$(正交矩阵)。
两种视角的等价性
最小化重构误差等价于最大化 $\text{tr}(\mathbf{W}^{\top} \mathbf{\Sigma} \mathbf{W})$。
展开:
$$ \text{tr}(\mathbf{W}^{\top} \mathbf{\Sigma} \mathbf{W}) = \sum_{j=1}^{k} \mathbf{w}_j^{\top} \mathbf{\Sigma} \mathbf{w}_j $$
这正是前 $k$ 个主成分的投影方差之和!
因此,“最小化重构误差"等价于"最大化投影方差”,两种视角殊途同归。
为什么这是等价的?
从物理直觉上理解:
- 最大化方差视角:我们想找到一个方向,使得数据在这个方向上"展开"得最厉害,这样才能尽可能多地保留原始信息。
- 最小化重构误差视角:我们想找到一个低维子空间,使得将数据投影到这个子空间后,重构的误差最小。
这两个目标是互补的:如果投影方差大,说明数据在这个方向上的变化范围广,自然重构误差就小(因为大部分信息都保留在这个方向上了)。
数学上,这体现了投影定理:在欧氏空间中,一个向量到子空间的最近点,就是它在该子空间上的正交投影。最小化重构误差找到的子空间,正是使得数据在这个子空间上的投影方差最大的子空间。
PCA 算法的完整步骤
现在,我们已经从两个等价的视角完整推导了 PCA 的理论基础。让我们总结 PCA 的算法步骤。
步骤 1:数据标准化(可选但推荐)
对于不同的特征,它们的单位和量纲可能不同。例如,身高的单位是厘米,体重的单位是千克,如果直接计算协方差,方差大的特征会主导主成分。
有两种常见的标准化方法:
中心化(必须有):
$$ \tilde{\mathbf{x}}_i = \mathbf{x}_i - \bar{\mathbf{x}} $$
归一化(推荐):
$$ \mathbf{x}_i’ = \frac{\mathbf{x}_i - \bar{\mathbf{x}}}{\sqrt{\text{Var}(\mathbf{x}_i)}} $$
其中 $\text{Var}(\mathbf{x}_i)$ 是第 $i$ 个特征的方差。
步骤 2:计算协方差矩阵
对于中心化数据 $\tilde{\mathbf{X}} = [\tilde{\mathbf{x}}_1, \tilde{\mathbf{x}}_2, \ldots, \tilde{\mathbf{x}}_n]^{\top} \in \mathbb{R}^{n \times d}$:
$$ \mathbf{\Sigma} = \frac{1}{n}\tilde{\mathbf{X}}^{\top} \tilde{\mathbf{X}} \in \mathbb{R}^{d \times d} $$
协方差矩阵的元素 $\Sigma_{ij}$ 表示第 $i$ 个特征和第 $j$ 个特征的协方差:
$$ \Sigma_{ij} = \frac{1}{n}\sum_{k=1}^{n} \tilde{x}{ki} \tilde{x}{kj} $$
对角线元素 $\Sigma_{ii}$ 是第 $i$ 个特征的方差。
步骤 3:特征值分解
求解协方差矩阵的特征值分解:
$$ \mathbf{\Sigma} \mathbf{w}_k = \lambda_k \mathbf{w}_k, \quad k = 1, 2, \ldots, d $$
将特征值按从大到小排序:
$$ \lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_d \geq 0 $$
对应的特征向量 $\mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_d$ 就是主成分方向。
步骤 4:选择前 $k$ 个主成分
选择前 $k$ 个主成分,通常有以下几种方法:
方法一:方差贡献率
前 $k$ 个主成分解释的方差占总方差的比例:
$$ \text{贡献率} = \frac{\sum_{i=1}^{k} \lambda_i}{\sum_{i=1}^{d} \lambda_i} $$
选择最小的 $k$,使得贡献率达到某个阈值(如 $90%$ 或 $95%$)。
方法二:肘部法则
绘制特征值随主成分数量的变化图,找到曲线"肘部"的位置。
方法三:交叉验证
在实际任务中,用不同 $k$ 值训练模型,选择性能最佳的 $k$。
步骤 5:降维投影
构造投影矩阵 $\mathbf{W} = [\mathbf{w}_1, \mathbf{w}_2, \ldots, \mathbf{w}_k] \in \mathbb{R}^{d \times k}$。
将原始数据投影到 $k$ 维:
$$ \mathbf{Z} = \tilde{\mathbf{X}} \mathbf{W} \in \mathbb{R}^{n \times k} $$
每行 $\mathbf{z}_i$ 是 $\mathbf{x}_i$ 的 $k$ 维表示。
步骤 6:数据重构(可选)
如果需要从低维表示重构回原始空间:
$$ \hat{\mathbf{X}} = \mathbf{Z} \mathbf{W}^{\top} = \tilde{\mathbf{X}} \mathbf{W} \mathbf{W}^{\top} $$
加上均值:
$$ \hat{\mathbf{X}}’ = \hat{\mathbf{X}} + \bar{\mathbf{X}} $$
几何直观:椭圆与投影
PCA 有一个优美的几何解释:数据的主成分方向,就是拟合数据分布的椭圆的长轴和短轴方向。
椭圆方程
考虑二维数据,协方差矩阵 $\mathbf{\Sigma} = \begin{pmatrix} \sigma_x^2 & \sigma_{xy} \ \sigma_{xy} & \sigma_y^2 \end{pmatrix}$。
数据分布的等密度椭圆(假设数据服从高斯分布)是:
$$ \mathbf{x}^{\top} \mathbf{\Sigma}^{-1} \mathbf{x} = c $$
其中 $c$ 是常数。
椭圆的长轴方向是 $\mathbf{\Sigma}$ 的最大特征值对应的特征向量,短轴方向是最小特征值对应的特征向量。
3D 椭球面的例子
下图展示了三维数据的主成分方向:
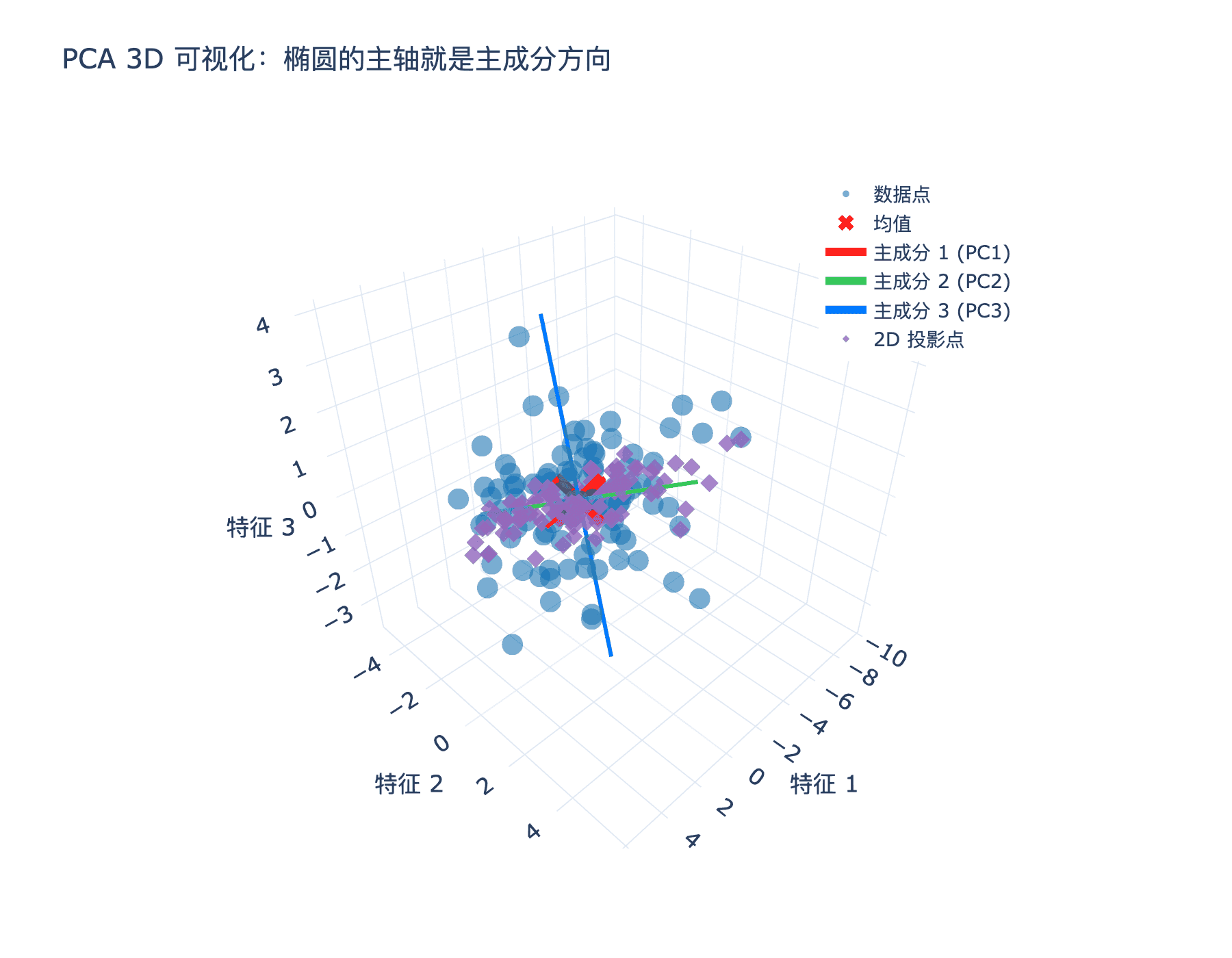
图 2:三维数据的 PCA:椭圆的主轴就是主成分方向
在这个图中,红色箭头表示第一个主成分(数据"伸展"最厉害的方向),绿色箭头表示第二个主成分(垂直于第一个主成分,且方差次大),蓝色箭头表示第三个主成分(方差最小)。
投影的几何意义
当我们把数据投影到前两个主成分张成的平面上时,实际上是做了一个正交投影。这个投影可以理解为:从第三个主成分的方向"看"数据,看到的"影子"就是降维后的数据。
投影后的数据保留了前两个主成分的信息,但丢失了第三个主成分方向的变异。不过,由于第三个主成分的方差最小,丢失的信息通常不多。
PCA 的实际应用
PCA 在实际中有广泛的应用,让我们看几个具体的例子。
应用一:数据可视化
高维数据难以直接观察。PCA 可以将高维数据投影到二维或三维,使我们能够直观地看到数据的分布。
例子:鸢尾花数据集
鸢尾花数据集有四个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。我们可以用 PCA 将其降维到二维:
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
import numpy as np
# 加载数据
iris = load_iris()
X = iris.data
# PCA 降维到 2 维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 查看解释方差
print(f"前两个主成分解释的方差比例: {sum(pca.explained_variance_ratio_):.2%}")
输出结果可能是:
前两个主成分解释的方差比例: 95.81%
这意味着用两个主成分就能保留原始数据 $95.81%$ 的信息!
可视化后,我们会发现不同品种的鸢尾花在二维平面上的分布有明显差异,这有助于分类。
应用二:图像压缩
数字图像可以看作高维数据。一张 $m \times n$ 的灰度图像是一个 $m \times n$ 维向量。PCA 可以用于图像压缩。
例子:人脸图像压缩
假设我们有 $100$ 张 $100 \times 100$ 的人脸图像,每张图像看作 $10000$ 维向量。PCA 找到的主成分(在人脸识别中称为"特征脸")反映了人脸的主要变化模式。
前几个主成分可能对应:整体亮度、水平对比度、面部对称性等。
压缩过程:
- 计算所有人脸图像的 PCA
- 选择前 $k$ 个主成分(如 $k = 50$)
- 每张人脸图像用 $50$ 个系数表示,而不是 $10000$ 个像素值
- 压缩比为 $10000 : 50 = 200 : 1$
重构时,用这 $50$ 个系数和对应的特征脸重建图像。
应用三:噪声过滤
如果数据中包含噪声,且噪声在所有方向上的方差大致相等,而信号只存在于少数主成分方向上,那么 PCA 可以用于噪声过滤。
方法:
- 对含噪数据进行 PCA
- 只保留前 $k$ 个主成分(假设信号主要在前 $k$ 个主成分中)
- 用前 $k$ 个主成分重构数据
- 重构后的数据会去除噪声
这个方法等价于低通滤波:保留低频(变化缓慢、方差大)成分,去除高频(快速变化、方差小但包含噪声)成分。
应用四:特征提取与降维
在机器学习中,高维特征会导致计算复杂度高、过拟合等问题。PCA 可以用于降维,提取最重要的特征。
例子:手写数字识别
MNIST 数据集中的每张数字图像是 $28 \times 28 = 784$ 维。如果直接用原始像素作为特征,维度太高。
使用 PCA 降维:
- 保留 $95%$ 的方差可能只需要 $50$-$100$ 个主成分
- 这样可以将 $784$ 维降到 $50$-$100$ 维,大大降低计算复杂度
- 同时保留了数字的主要形状信息
应用五:金融风险建模
在金融领域,股票收益率之间存在相关性。PCA 可以用于:
- 识别市场因子:第一个主成分通常对应"市场整体走势",后续主成分可能对应特定行业或因子的风险。
- 降维建模:将数百只股票的收益率降维到少数几个因子,用因子模型建模。
- 风险分散:通过分析主成分的分布,构建多元化的投资组合。
PCA 的优缺点与改进
PCA 的优点
- 简单高效:算法只涉及矩阵运算,计算复杂度主要是特征值分解。
- 可解释性:主成分是原始特征的线性组合,可以通过载荷分析理解。
- 无监督:不需要标签数据,适用于各种场景。
- 理论基础完备:从几何、统计、优化等多个角度都有清晰的解释。
PCA 的缺点
- 线性变换:PCA 只能捕获线性关系。如果数据中有非线性结构,PCA 可能失效。
- 方差不等于信息:在某些情况下,方差小的方向可能包含重要信息(如类别信息)。
- 对尺度敏感:不同特征的量纲会影响主成分。
- 可解释性有限:虽然主成分是线性组合,但高维情况下理解主成分的物理意义仍然困难。
改进方法
针对 PCA 的局限性,有许多改进方法:
核 PCA(Kernel PCA): 将数据映射到高维空间(使用核函数),在高维空间中做 PCA。这样可以捕获非线性关系。
t-SNE: 用于数据可视化,特别擅长保持数据的局部结构。
UMAP: 类似 t-SNE,但计算更快,且能更好地保持全局结构。
独立成分分析(ICA): 假设成分是统计独立的(而 PCA 只要求不相关),在某些任务中效果更好。
总结:从数据中提取智慧
PCA 是一个美丽而强大的算法。它用简单的线性代数工具,解决了高维数据分析中的一个核心问题:如何找到数据的"主轴"。
我们从两个等价的视角理解了 PCA:
- 最大化投影方差:找到数据"伸展"最厉害的方向,使得降维后保留最多的信息。
- 最小化重构误差:找到最优的低维子空间,使得降维再重构的误差最小。
这两种视角殊途同归,都指向了同一个数学核心:协方差矩阵的特征值分解。
PCA 的优雅在于它的通用性。从天文学中的恒星分布,到生物学中的基因表达,从金融学中的股票收益,到计算机视觉中的人脸识别,PCA 都有广泛应用。它的核心思想——从复杂的高维数据中提取主要的变化模式——是数据分析的一个永恒主题。
但 PCA 也有局限性:它是线性的,对尺度敏感,且不能保证方差大的方向包含所有重要信息。因此,在实际应用中,我们需要根据具体问题选择合适的方法,或者将 PCA 与其他技术结合使用。
从 Pearson 的几何直觉,到 Hotelling 的统计完善,PCA 已经发展了一个多世纪。但它的核心思想依然闪耀着智慧的光芒:在复杂的混沌中寻找简洁的秩序,在冗余的信息中提取本质的模式。这不仅是 PCA 的哲学,也是所有数据科学方法的终极目标。
当我们面对海量数据时,PCA 提醒我们:不要被复杂性所淹没,寻找隐藏在数据背后的主轴,那些主轴将引导我们走向理解和洞察的彼岸。