引言:从掷骰子到高尔顿板
想象一下,你站在 19 世纪的英国街头,看着弗朗西斯·高尔顿展示他的发明——高尔顿板。成千上万的小珠子从上方落下,穿过钉子的阵列,最终在底部堆积成一条平滑的曲线。这条曲线就是我们熟知的钟形曲线,也就是正态分布的直观体现。高尔顿站在那里,向观众解释一个深刻的真理:看似混乱的随机现象背后,隐藏着惊人的秩序。
但在理解正态分布之前,我们需要回到更基础的问题。当你掷一枚硬币,正面朝上的概率是多少?如果你掷十次,恰好五次正面的概率又是多少?这些看似简单的问题,引导我们进入概率论的核心领域——概率分布。
概率分布是描述随机变量取值规律的数学工具。就像地图告诉我们哪里有山、哪里有河一样,概率分布告诉我们一个随机变量取不同值的可能性大小。在本文中,我们将踏上一段穿越时间和数学的旅程,探索概率统计中最重要的几个分布:二项分布、泊松分布、正态分布和指数分布。
这不是一本枯燥的教科书,而是一次探索。我们将从简单的硬币投掷开始,逐渐走向描述稀有事件的泊松分布,最终抵达连接万物的正态分布。准备好了吗?让我们开始这段旅程。
二项分布:从伯努利到组合数学
历史的种子
二项分布的起源可以追溯到 17 世纪的欧洲,那是一个赌博和数学碰撞的时代。当时,一位名叫布莱兹·帕斯卡的年轻法国数学家收到了朋友的来信。朋友是一位赌博爱好者,遇到了一个困扰他的问题:两个玩家在赌博中断后,应该如何公平地分配赌注?
这个问题现在被称为"点数问题",它点燃了概率论的火花。帕斯卡与另一位数学天才皮埃尔·德·费马通信讨论,他们的信件往来奠定了现代概率论的基础。
但二项分布的真正数学形式要归功于雅各布·伯努利(Jacob Bernoulli)。这位瑞士数学家在他去世后于 1713 年出版的巨著《猜度术》(Ars Conjectandi)中,系统性地研究了独立重复试验的问题。伯努利提出的问题很简单:如果你重复做 $n$ 次独立的伯努利试验(每次只有成功或失败两种结果),恰好得到 $k$ 次成功的概率是多少?
数学定义与推导
让我们从最基本的概念开始。一个伯努利试验是指只有两个可能结果的随机试验:成功(用 $1$ 表示)或失败(用 $0$ 表示)。假设成功的概率是 $p$,失败的概率就是 $1-p$。
现在,我们重复进行 $n$ 次独立的伯努利试验,设 $X$ 为成功的次数。我们要求的是 $P(X = k)$,即恰好 $k$ 次成功的概率。
为了理解这个概率,让我们考虑一个具体的例子:$n = 3$ 次试验,恰好 $k = 2$ 次成功。所有可能的结果有:
- 成功、成功、失败(SSF)
- 成功、失败、成功(SFS)
- 失败、成功、成功(FSS)
每种结果的概率是相同的:$p \cdot p \cdot (1-p) = p^2(1-p)$。因为有 $3$ 种不同的排列方式,所以总概率是 $3 \cdot p^2(1-p)$。
这个数字 $3$ 是什么?它是从 $3$ 个位置中选择 $2$ 个位置放成功的组合数。一般地,从 $n$ 个位置中选择 $k$ 个位置放成功的组合数是:
$$ C_n^k = \binom{n}{k} = \frac{n!}{k!(n-k)!} $$
因此,二项分布的概率质量函数是:
$$ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}, \quad k = 0, 1, 2, \ldots, n $$
这个公式告诉我们,恰好 $k$ 次成功的概率等于:选择哪 $k$ 次成功的方式数,乘以 $k$ 次成功和 $n-k$ 次失败的概率。
期望与方差的推导
二项分布的期望值和方差有优雅的推导方法。我们使用一个巧妙的思想:将二项分布看作 $n$ 个独立的伯努利随机变量的和。
设 $X_i$ 表示第 $i$ 次试验的结果,$X_i = 1$ 表示成功,$X_i = 0$ 表示失败。那么:
$$ X = \sum_{i=1}^{n} X_i $$
对于单个伯努利变量 $X_i$:
- 期望:$E[X_i] = 1 \cdot p + 0 \cdot (1-p) = p$
- 方差:$\text{Var}(X_i) = E[X_i^2] - (E[X_i])^2 = p - p^2 = p(1-p)$
利用期望和方差的线性性质(独立性保证了方差的可加性),我们得到:
- 期望:$E[X] = E\left[\sum_{i=1}^{n} X_i\right] = \sum_{i=1}^{n} E[X_i] = np$
- 方差:$\text{Var}(X) = \text{Var}\left(\sum_{i=1}^{n} X_i\right) = \sum_{i=1}^{n} \text{Var}(X_i) = np(1-p)$
这个结果非常直观:如果你投掷 $n$ 次硬币,每次成功的概率是 $p$,你平均会得到 $np$ 次成功,而实际结果会在 $np$ 附近波动,波动幅度由 $np(1-p)$ 决定。
几何直观与图像
让我们用图形来直观理解二项分布。下图展示了不同参数下的二项分布:
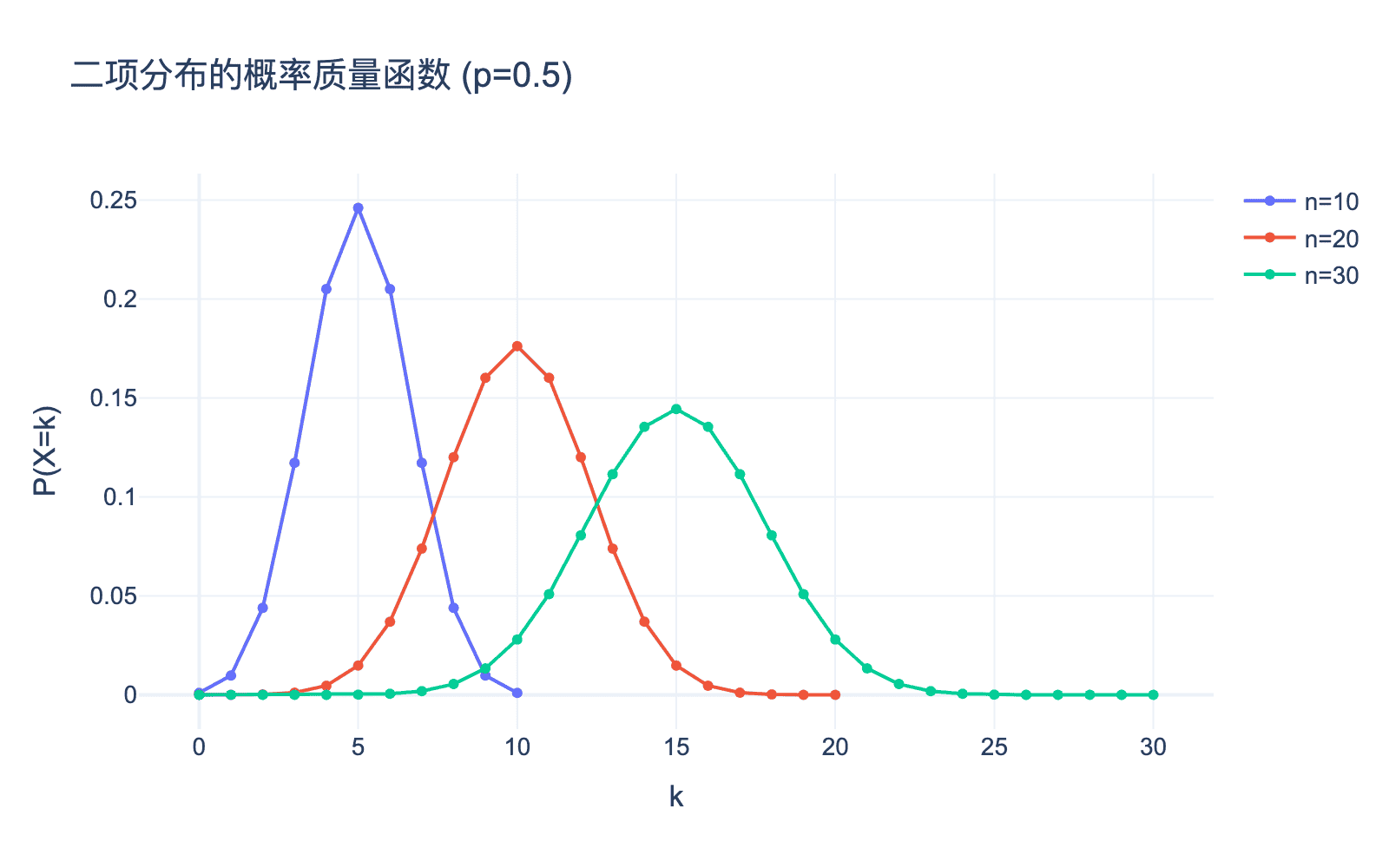
图 1:不同参数下的二项分布
从图像中可以观察到几个有趣的性质:
- 对称性:当 $p = 0.5$ 时,分布是对称的,峰值位于 $n/2$ 处。
- 偏态性:当 $p \neq 0.5$ 时,分布呈现偏态。如果 $p < 0.5$,分布向右偏;如果 $p > 0.5$,分布向左偏。
- 峰值位置:分布的峰值大约在 $np$ 处,这与期望值一致。
- 离散性:二项分布是离散分布,只在整数点上有定义。
实际应用
二项分布在实际中有着广泛的应用:
质量控制:在工厂生产中,如果每个产品有概率 $p$ 是次品,那么 $n$ 个产品中恰好 $k$ 个次品的概率就服从二项分布。这帮助质检人员设置合理的抽样方案。
民意调查:假设总统候选人的支持率是 $p$,随机调查 $n$ 个人,支持该候选人的人数服从二项分布。这解释了为什么民意调查总是有误差范围。
医学测试:一种检测方法有 $95%$ 的准确率,对 $n$ 个样本进行检测,正确检测的数量服从二项分布。
金融投资:如果你进行 $n$ 次独立投资,每次成功的概率是 $p$,成功的总次数也服从二项分布。
二项分布教会我们一个深刻的道理:即使每个事件都是独立的、简单的,当它们累积起来时,会涌现出复杂的统计规律。
泊松分布:稀有事件的计数艺术
从物理学到数学的跨越
泊松分布的名字来自法国数学家兼物理学家西梅翁·德尼·泊松(Siméon Denis Poisson)。他在 1837 年的一本著作中研究了这个分布,但有趣的是,泊松最初并不是想研究"稀有事件",而是作为二项分布的一个极限情况推导出来的。
然而,真正让泊松分布声名鹊起的是一个有趣的历史事件。在 19 世纪末的普鲁士骑兵部队中,每年都有相当数量的士兵死于马踢。一位名叫拉迪斯劳斯·博尔凯维奇(Ladislaus Bortkiewicz)的统计学家在 1898 年研究了这些数据,发现马踢导致的死亡人数惊人地服从泊松分布。这个例子成为了说明泊松分布如何描述稀有事件的最著名案例。
另一个经典例子发生在二战期间的伦敦。德国对伦敦进行了猛烈的空袭,人们猜测德国人瞄准了特定区域。但统计学家 R.D. 克拉克(R.D. Clarke)仔细分析了炸弹落点的分布,发现不同区域的炸弹数量也完美服从泊松分布。这说明炸弹的落点是随机的,而非有目标的。
从二项分布到泊松分布
泊松分布的一个重要特征是它可以从二项分布推导出来。让我们从二项分布开始,并做一些假设:
假设我们有 $n$ 次伯努利试验,每次成功的概率是 $p$。我们要计算恰好 $k$ 次成功的概率。二项分布的公式是:
$$ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k} $$
现在,假设我们让 $n \to \infty$,但同时让 $p \to 0$,使得 $np = \lambda$ 保持为一个常数。这模拟了"很多次试验,每次成功概率很小"的情况,比如一个小时内电话呼叫中心的来电数。
让我们逐步推导:
$$ \begin{align} P(X = k) &= \frac{n!}{k!(n-k)!} p^k (1-p)^{n-k} \\ &= \frac{n(n-1)(n-2)\cdots(n-k+1)}{k!} \left(\frac{\lambda}{n}\right)^k \left(1 - \frac{\lambda}{n}\right)^{n-k} \\ &= \frac{n(n-1)(n-2)\cdots(n-k+1)}{n^k} \cdot \frac{\lambda^k}{k!} \cdot \left(1 - \frac{\lambda}{n}\right)^{n-k} \\ \end{align} $$
现在,我们让 $n \to \infty$:
第一部分: $$ \lim_{n \to \infty} \frac{n(n-1)(n-2)\cdots(n-k+1)}{n^k} = 1 $$ 因为分子和分母的最高次项都是 $n^k$,系数都是 $1$。
第三部分: $$ \lim_{n \to \infty} \left(1 - \frac{\lambda}{n}\right)^{n-k} = \lim_{n \to \infty} \left(1 - \frac{\lambda}{n}\right)^n \cdot \left(1 - \frac{\lambda}{n}\right)^{-k} = e^{-\lambda} \cdot 1 = e^{-\lambda} $$ 这里我们使用了著名的极限 $\lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n = e^x$。
因此,我们得到泊松分布的概率质量函数:
$$ P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \ldots $$
其中 $\lambda > 0$ 是泊松分布的参数,它表示在给定时间或空间内事件发生的平均次数。
期望与方差的推导
泊松分布的期望和方差有简洁的推导方法。首先,计算期望:
$$ \begin{align} E[X] &= \sum_{k=0}^{\infty} k \cdot \frac{\lambda^k e^{-\lambda}}{k!} \\ &= e^{-\lambda} \sum_{k=0}^{\infty} k \cdot \frac{\lambda^k}{k!} \\ &= e^{-\lambda} \sum_{k=1}^{\infty} \frac{\lambda^k}{(k-1)!} \quad (\text{注意 } k=0 \text{ 项为零}) \\ &= e^{-\lambda} \lambda \sum_{k=1}^{\infty} \frac{\lambda^{k-1}}{(k-1)!} \\ \end{align} $$
令 $j = k-1$,则:
$$ E[X] = e^{-\lambda} \lambda \sum_{j=0}^{\infty} \frac{\lambda^j}{j!} = e^{-\lambda} \lambda \cdot e^{\lambda} = \lambda $$
这里我们使用了泰勒展开 $e^{\lambda} = \sum_{j=0}^{\infty} \frac{\lambda^j}{j!}$。
接下来计算 $E[X^2]$:
$$ \begin{align} E[X^2] &= \sum_{k=0}^{\infty} k^2 \cdot \frac{\lambda^k e^{-\lambda}}{k!} \\ &= e^{-\lambda} \sum_{k=0}^{\infty} k^2 \cdot \frac{\lambda^k}{k!} \\ &= e^{-\lambda} \sum_{k=0}^{\infty} k(k-1+1) \cdot \frac{\lambda^k}{k!} \\ &= e^{-\lambda} \left[\sum_{k=0}^{\infty} k(k-1) \cdot \frac{\lambda^k}{k!} + \sum_{k=0}^{\infty} k \cdot \frac{\lambda^k}{k!}\right] \\ &= e^{-\lambda} \left[\sum_{k=2}^{\infty} \frac{\lambda^k}{(k-2)!} + \sum_{k=0}^{\infty} k \cdot \frac{\lambda^k}{k!}\right] \\ \end{align} $$
第一个求和: $$ \sum_{k=2}^{\infty} \frac{\lambda^k}{(k-2)!} = \lambda^2 \sum_{k=2}^{\infty} \frac{\lambda^{k-2}}{(k-2)!} = \lambda^2 e^{\lambda} $$
第二个求和我们已经计算过,是 $\lambda e^{\lambda}$。
因此: $$ E[X^2] = e^{-\lambda} (\lambda^2 e^{\lambda} + \lambda e^{\lambda}) = \lambda^2 + \lambda $$
方差为: $$ \text{Var}(X) = E[X^2] - (E[X])^2 = (\lambda^2 + \lambda) - \lambda^2 = \lambda $$
泊松分布有一个独特的性质:期望等于方差,都等于 $\lambda$。
几何直观与图像
下图展示了不同参数下的泊松分布:
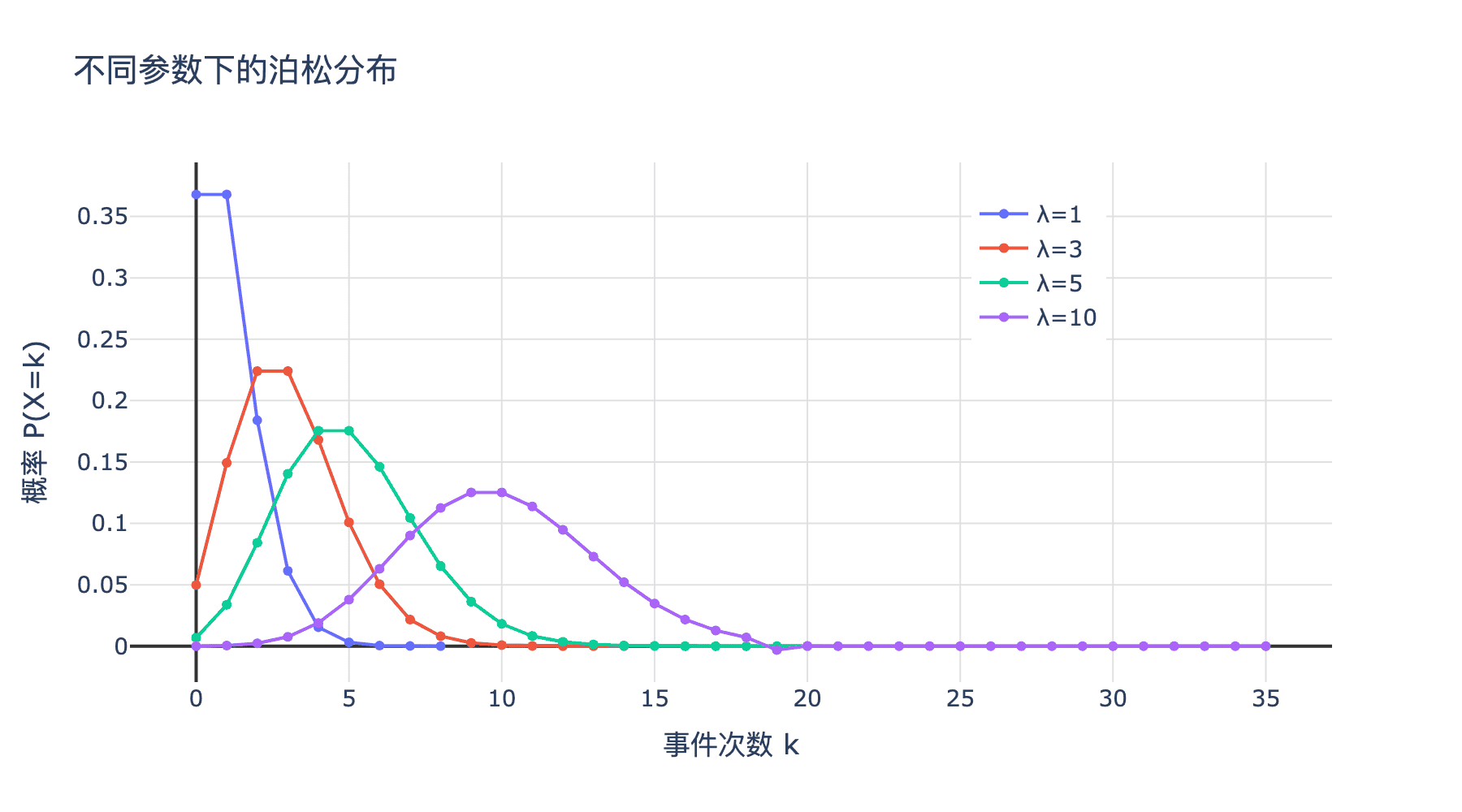
图 2:不同参数下的泊松分布
从图像中可以观察到:
- 偏态性:当 $\lambda$ 较小时,分布呈现明显的右偏态。当 $\lambda$ 增大时,分布逐渐变得对称,接近正态分布。
- 峰值位置:分布的峰值大约在 $\lfloor \lambda \rfloor$ 或 $\lceil \lambda \rceil$ 处。
- 离散性:泊松分布也是离散分布,只在非负整数点上有定义。
实际应用
泊松分布的适用场景非常广泛,特别是在描述稀有事件时:
呼叫中心:一个小时内来电的数量。即使每个瞬间来电的概率极小,但一小时内累积起来的来电数服从泊松分布。
交通流量:通过特定路口的车辆数。每辆车通过的概率很小,但一天内通过的总车辆数服从泊松分布。
放射性衰变:一定时间内放射性物质发射的粒子数。这是一个经典的物理应用,泊松分布在这里有深刻的理论基础。
网页访问:服务器每秒接收的请求数量。这对负载测试和容量规划非常重要。
遗传学:基因突变的发生次数。在 DNA 复制过程中,每个碱基突变的概率很小,但总体突变次数服从泊松分布。
缺陷计数:产品表面的缺陷数量。比如一块屏幕上的坏点数量。
泊松分布的威力在于它的简洁性和普适性。只要满足一些基本条件(独立性、稀有性、平稳性),它就能准确地描述现象。这提醒我们,自然界中的很多"巧合"其实是数学规律的自然结果。
正态分布:万物归一的奇迹
从棣莫弗到高斯
正态分布,也叫高斯分布,是概率论和统计学中最重要的分布,被称为"分布之王"。它的发现之旅跨越了三个世纪,见证了数学思想的演进。
故事始于 18 世纪初的法国。亚伯拉罕·棣莫弗(Abraham de Moivre)正在研究赌博问题,特别是如何计算大量二项试验的概率。他发现,当试验次数 $n$ 很大时,二项分布可以用一个近似的公式来计算。这个近似公式包含了一个我们今天熟悉的函数:
$$ \frac{1}{\sqrt{2\pi}} e^{-x^2/2} $$
这就是正态分布的雏形。但棣莫弗本人并没有意识到这个发现的重要性,他只是把它当作一个实用的计算技巧。
正态分布的真正王者地位是在 19 世纪初确立的。德国数学家卡尔·弗里德里希·高斯(Carl Friedrich Gauss)在研究天文学中的误差问题时,系统地发展了这个分布。高斯发现,测量误差服从这个钟形曲线,这个结果如此完美,以至于人们开始称这个分布为"高斯分布"。
高斯提出了一个关键思想:如果误差服从正态分布,那么最小二乘法估计就是最优的。这个思想彻底改变了科学测量的方法,从天文学到大地测量学,都受到了深远影响。
中心极限定理:连接万物的桥梁
如果说高斯发现了正态分布,那么拉普拉斯、李亚普诺夫和林德伯格等人则解释了为什么正态分布如此普遍。答案就是概率论中最深刻的定理之一:中心极限定理(Central Limit Theorem, CLT)。
中心极限定理的陈述很简单但深刻:如果你有 $n$ 个独立的随机变量 $X_1, X_2, \ldots, X_n$,它们有相同的期望 $\mu$ 和方差 $\sigma^2$(甚至不需要相同的分布,只要满足一些温和的条件),那么当 $n \to \infty$ 时,这些变量的和近似服从正态分布。
具体地,设 $S_n = X_1 + X_2 + \cdots + X_n$,标准化后得到:
$$ Z_n = \frac{S_n - n\mu}{\sigma\sqrt{n}} $$
中心极限定理告诉我们:
$$ Z_n \xrightarrow{d} N(0, 1) $$
其中 $N(0, 1)$ 表示标准正态分布。
这个定理的证明相当复杂,但我们可以用一个简单的例子来理解它为什么成立。考虑 $n$ 个独立的伯努利随机变量,它们服从参数为 $p$ 的二项分布。我们已经知道,二项分布可以看作这些变量的和。当 $n$ 很大时,二项分布的图形看起来越来越像正态分布。这实际上是中心极限定理的一个特例。
更一般地,我们可以通过特征函数(或矩母函数)来证明中心极限定理。随机变量 $X$ 的特征函数定义为:
$$ \phi_X(t) = E[e^{itX}] $$
利用特征函数的性质,独立随机变量和的特征函数等于各自特征函数的乘积。通过一些复杂的分析(泰勒展开、极限等),可以证明标准化和的特征函数收敛于标准正态分布的特征函数 $e^{-t^2/2}$。
正态分布的数学定义
正态分布的概率密度函数是:
$$ f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$
其中 $\mu$ 是均值,$\sigma^2$ 是方差,$\sigma > 0$ 是标准差。我们记作 $X \sim N(\mu, \sigma^2)$。
标准正态分布 $N(0, 1)$ 的密度函数是:
$$ \phi(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2} $$
正态分布的累积分布函数没有封闭形式,必须用积分表示:
$$ \Phi(x) = \int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}} e^{-t^2/2} dt $$
这个积分无法用初等函数表示,但可以通过数值方法计算,或者使用查表法(在现代,当然是直接用软件计算)。
归一化常数的推导
你可能好奇,为什么正态分布的归一化常数是 $\frac{1}{\sqrt{2\pi}\sigma}$?这需要计算一个困难的积分:
$$ I = \int_{-\infty}^{\infty} e^{-x^2/2} dx $$
我们可以使用一个巧妙的技巧——二重积分和极坐标变换:
$$ \begin{align} I^2 &= \left(\int_{-\infty}^{\infty} e^{-x^2/2} dx\right) \left(\int_{-\infty}^{\infty} e^{-y^2/2} dy\right) \\ &= \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} e^{-(x^2+y^2)/2} dx dy \end{align} $$
转换为极坐标:$x = r\cos\theta$, $y = r\sin\theta$, $dx dy = r dr d\theta$:
$$ \begin{align} I^2 &= \int_{0}^{2\pi} \int_{0}^{\infty} e^{-r^2/2} r dr d\theta \\ &= \int_{0}^{2\pi} \left[-e^{-r^2/2}\right]{0}^{\infty} d\theta \\ &= \int{0}^{2\pi} 1 \cdot d\theta \\ &= 2\pi \end{align} $$
因此,$I = \sqrt{2\pi}$。这解释了为什么归一化常数包含 $\sqrt{2\pi}$。
期望与方差的计算
对于标准正态分布 $Z \sim N(0, 1)$,期望为:
$$ E[Z] = \int_{-\infty}^{\infty} x \cdot \frac{1}{\sqrt{2\pi}} e^{-x^2/2} dx = 0 $$
这是因为被积函数是奇函数($x \cdot e^{-x^2/2}$ 在 $x$ 和 $-x$ 处取相反值),在对称区间上积分为零。
方差为:
$$ \begin{align} \text{Var}(Z) &= E[Z^2] - (E[Z])^2 = E[Z^2] \\ &= \int_{-\infty}^{\infty} x^2 \cdot \frac{1}{\sqrt{2\pi}} e^{-x^2/2} dx \\ \end{align} $$
使用分部积分:设 $u = x$, $dv = x e^{-x^2/2} dx$,则 $du = dx$, $v = -e^{-x^2/2}$:
$$ \begin{align} E[Z^2] &= \frac{1}{\sqrt{2\pi}} \left[-x e^{-x^2/2}\right]{-\infty}^{\infty} + \int{-\infty}^{\infty} e^{-x^2/2} dx \\ &= 0 + \sqrt{2\pi} \cdot \frac{1}{\sqrt{2\pi}} \\ &= 1 \end{align} $$
对于一般正态分布 $X = \sigma Z + \mu$,我们有:
- $E[X] = \sigma E[Z] + \mu = \mu$
- $\text{Var}(X) = \sigma^2 \text{Var}(Z) = \sigma^2$
几何直观与图像
正态分布的钟形曲线是其最显著的特征。下图展示了不同参数下的正态分布:
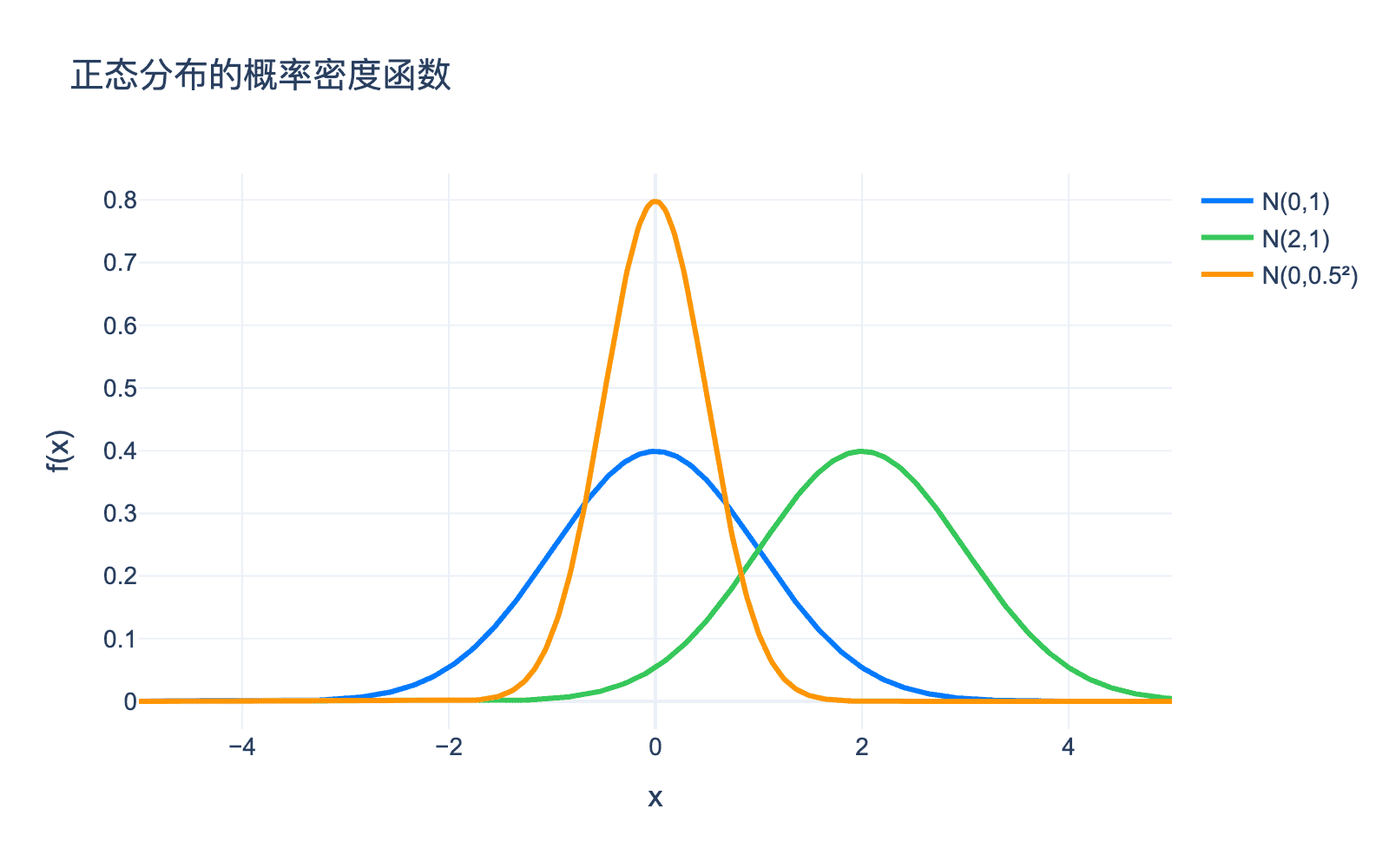
图 3:不同参数下的正态分布
从图像中可以观察到:
- 对称性:正态分布关于均值 $\mu$ 对称。
- 峰值:在 $x = \mu$ 处达到最大值,值为 $\frac{1}{\sqrt{2\pi}\sigma}$。
- 尾部:尾部快速衰减,但永不为零。这解释了为什么极端事件虽然罕见,但并非不可能。
- 参数影响:$\mu$ 控制位置,$\sigma$ 控制形状(宽度)。$\sigma$ 越小,分布越集中;$\sigma$ 越大,分布越分散。
68-95-99.7 规则
正态分布有一个著名的经验规则:
- 约 $68%$ 的数据落在 $\mu \pm \sigma$ 范围内
- 约 $95%$ 的数据落在 $\mu \pm 2\sigma$ 范围内
- 约 $99.7%$ 的数据落在 $\mu \pm 3\sigma$ 范围内
这个规则在实践中非常有用,比如在质量控制中设定可接受的范围。
实际应用
正态分布的应用几乎渗透到了所有科学和工程领域:
自然科学:测量误差、实验结果的统计分析。 社会科学:智商分数、身高、体重等生物特征。 金融:股票收益率(虽然不完全符合,但常用正态分布作为近似)。 工程:产品尺寸的分布、材料强度的变异。 机器学习:作为许多算法的基础假设,如高斯混合模型、高斯过程。
正态分布的普遍性之所以令人惊叹,是因为它不是自然界"刻意选择"的分布,而是大量独立随机效应累积的必然结果。这就像熵增定律一样,是一个深刻的统计规律。
指数分布:等待时间的艺术
与泊松过程的深刻联系
指数分布与泊松分布有着密不可分的关系。回想一下,泊松分布描述的是在固定时间间隔内事件发生的次数。如果我们反问:两个连续事件之间的等待时间是多少?答案就是指数分布。
具体地,考虑一个泊松过程:事件以速率 $\lambda$ 随机发生。设 $T$ 为从开始到第一个事件发生的时间,那么 $T$ 服从参数为 $\lambda$ 的指数分布。
让我们用泊松分布的性质来推导这个结果。第一个事件在时间 $t$ 之后发生的概率,等价于在时间 $[0, t]$ 内没有事件发生的概率:
$$ P(T > t) = P(\text{在 } [0, t] \text{ 内零事件}) = e^{-\lambda t} $$
这里我们使用了泊松分布中 $k=0$ 的公式:$P(X=0) = \frac{\lambda^0 e^{-\lambda t}}{0!} = e^{-\lambda t}$。
因此,$T$ 的累积分布函数是:
$$ F_T(t) = P(T \leq t) = 1 - P(T > t) = 1 - e^{-\lambda t} $$
概率密度函数是:
$$ f_T(t) = F_T’(t) = \lambda e^{-\lambda t}, \quad t \geq 0 $$
这就是指数分布的概率密度函数。
无记忆性:一个深刻的性质
指数分布有一个独特的性质——无记忆性(Memoryless Property)。这个性质用数学语言表达是:
$$ P(T > s + t \mid T > s) = P(T > t) $$
换句话说,如果你已经等待了 $s$ 时间还没有事件发生,那么再等待 $t$ 时间才有事件发生的概率,与你刚开始等待 $t$ 时间才有事件发生的概率是相同的。
这个性质可能有些违反直觉。想象你等公交车,如果公交车到达时间服从指数分布,那么无论你已经等了多久,公交车的"剩余等待时间"分布都是一样的。
让我们验证这个性质:
$$ \begin{align} P(T > s + t \mid T > s) &= \frac{P(T > s + t)}{P(T > s)} \\ &= \frac{e^{-\lambda(s+t)}}{e^{-\lambda s}} \\ &= e^{-\lambda t} \\ &= P(T > t) \end{align} $$
指数分布是唯一具有无记忆性的连续分布(几何分布是唯一具有无记忆性的离散分布)。
期望与方差的推导
指数分布的期望:
$$ \begin{align} E[T] &= \int_{0}^{\infty} t \cdot \lambda e^{-\lambda t} dt \\ &= \lambda \cdot \frac{1}{\lambda^2} \quad (\text{利用 } \int_{0}^{\infty} t e^{-\lambda t} dt = \frac{1}{\lambda^2}) \\ &= \frac{1}{\lambda} \end{align} $$
这个结果很直观:如果事件以速率 $\lambda$ 发生,那么平均等待时间就是 $\frac{1}{\lambda}$。
计算 $E[T^2]$:
$$ \begin{align} E[T^2] &= \int_{0}^{\infty} t^2 \cdot \lambda e^{-\lambda t} dt \\ &= \lambda \cdot \frac{2}{\lambda^3} \quad (\text{利用 } \int_{0}^{\infty} t^2 e^{-\lambda t} dt = \frac{2}{\lambda^3}) \\ &= \frac{2}{\lambda^2} \end{align} $$
方差为:
$$ \text{Var}(T) = E[T^2] - (E[T])^2 = \frac{2}{\lambda^2} - \frac{1}{\lambda^2} = \frac{1}{\lambda^2} $$
有趣的是,指数分布的标准差等于期望:$\sigma_T = \frac{1}{\lambda} = E[T]$。
几何直观与图像
下图展示了不同参数下的指数分布:
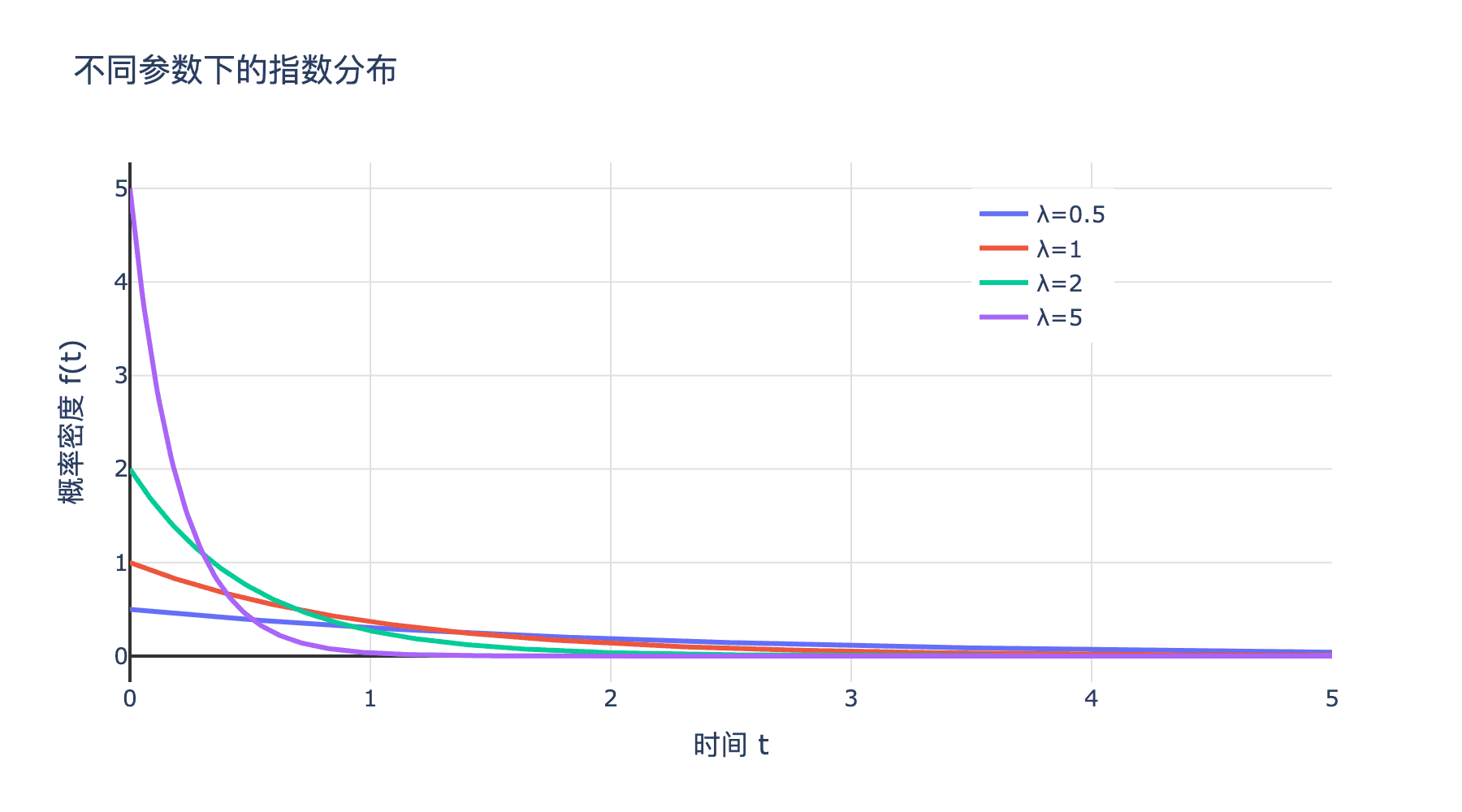
图 4:不同参数下的指数分布
从图像中可以观察到:
- 单调递减:指数分布的密度函数在 $t=0$ 处取最大值 $\lambda$,然后单调递减到零。
- 参数影响:$\lambda$ 越大,事件发生得越快,等待时间越短。这体现在密度函数衰减得更快。
- 长尾:指数分布有明显的右尾,表示有时等待时间会很长。
实际应用
指数分布在描述"等待时间"方面有着广泛的应用:
可靠性工程:电子元件的寿命分布。如果一个元件失效后立即被替换,那么失效间隔时间服从指数分布。
排队论:顾客到达的间隔时间、服务时间。这是分析银行、呼叫中心、医院等系统性能的基础。
放射性衰变:原子核衰变的时间间隔。这与泊松分布描述粒子发射数形成互补。
网络流量:数据包到达的间隔时间、网络延迟。
风险管理:金融市场中极端事件的发生时间(如股市崩盘)。
指数分布和泊松分布的关系是一个美丽的对称:泊松分布回答"在固定时间内发生了多少事件",指数分布回答"等待固定事件需要多少时间"。这种对偶关系在概率论中反复出现,体现了数学的和谐与统一。
总结:从混沌到秩序
我们的旅程从简单的硬币投掷开始,经过二项分布的离散世界,穿越泊松分布的稀有事件,最终抵达连接万物的正态分布,又在指数分布中体会等待时间的哲学。这不仅仅是四个概率分布的故事,更是从混沌中发现秩序的史诗。
概率分布告诉我们:即使世界充满了随机性和不确定性,这些随机性本身遵循着深刻的规律。二项分布展示了独立事件的累积效应;泊松分布揭示了稀有事件的统计规律;正态分布体现了中心极限定理的普适性;指数分布则描述了时间的流逝和等待的艺术。
这些分布不是孤立的数学概念,而是紧密相连的。二项分布在极限情况下趋向泊松分布;大量独立二项分布的和趋向正态分布;泊松过程的等待时间服从指数分布。这种网络般的联系,展示了数学的内在统一性。
更重要的是,这些分布不仅仅是理论工具,它们描述了我们世界的真实面貌。从工厂的质量控制到宇宙的粒子衰变,从股市的波动到基因的突变,概率分布无处不在。
高尔顿板上的小珠子从上方落下,看似随机地穿过钉子,最终堆积成一条平滑的曲线。这条曲线——正态分布——是秩序的象征。它告诉我们,在混沌的表面之下,隐藏着美丽的数学秩序。这正是概率论的魅力所在:在不确定性中寻找确定性,在混沌中发现秩序。
当你在生活中遇到随机现象时,不妨停下来想一想:这背后可能隐藏着怎样的概率分布?理解这些分布,就是理解我们这个世界运行的基本规律。正如高勋曾经说过的:“概率论,是测量无知的唯一真正的科学。”
从硬币投掷到高尔顿板,从二项分布到正态分布,我们已经见证了从混沌到秩序的奇迹。而这段旅程,远未结束。