引言:为什么需要微积分?
想象你在山上,想找到最低点。你会怎么做?你会观察脚下的坡度,选择最陡峭的方向迈出一步,然后重复这个过程。这个简单的直觉——沿着负梯度方向走——正是现代人工智能的核心算法。
从ChatGPT的语言模型到AlphaGo的围棋策略,从图像识别到语音合成,所有这些技术背后都有一个共同的数学基础:微积分。
微积分研究的是变化。而机器学习本质上是关于优化——通过不断调整参数来减少错误。当我们在高维空间中优化复杂的神经网络时,微积分提供了描述和计算这种变化的精确语言。
这篇文章将带你深入理解微积分如何驱动现代人工智能。我们不会停留在表面,而是会深入到数学推导的核心,揭示梯度下降、反向传播等算法的数学本质。这是一次从17世纪牛顿和莱布尼茨的发明,到21世纪深度学习革命的完整旅程。
第一部分:微积分基础理论
1. 导数的本质:从变化率到瞬时变化率
1.1 变化率的直观理解
变化率是人类最早思考的数学问题之一。如果一辆车2小时行驶100公里,平均速度是50公里/小时。但它某一时刻的瞬时速度是多少?
微积分的答案是:用极限。考虑函数 $f(x)$ 在 $x_0$ 附近的平均变化率: $$ \frac{f(x_0 + \Delta x) - f(x_0)}{\Delta x} $$
当 $\Delta x \to 0$ 时,这个平均变化率的极限就是导数: $$ f^{\prime}(x_0) = \lim_{\Delta x \to 0} \frac{f(x_0 + \Delta x) - f(x_0)}{\Delta x} $$
1.2 导数的几何意义
几何直观:导数是切线的斜率。在 $x_0$ 处,曲线 $f(x)$ 可以用直线(切线)逼近: $$ f(x) \approx f(x_0) + f^{\prime}(x_0)(x - x_0) $$
这就是一阶泰勒公式,也是线性化的思想:局部用简单的线性函数逼近复杂的非线性函数。
严格定义($\epsilon-\delta$ 语言): $$ \forall \epsilon > 0, \exists \delta > 0 \text{ s.t. } |\Delta x| < \delta \implies \left|\frac{f(x_0 + \Delta x) - f(x_0)}{\Delta x} - f^{\prime}(x_0)\right| < \epsilon $$
1.3 导数的计算规则
基本法则:
- 线性性:$(af + bg)^{\prime} = af^{\prime} + bg^{\prime}$
- 乘积法则:$(fg)^{\prime} = f^{\prime}g + fg^{\prime}$
- 商法则:$\left(\frac{f}{g}\right)^{\prime} = \frac{f^{\prime}g - fg^{\prime}}{g^2}$
链式法则(复合函数): $$ \frac{d}{dx}f(g(x)) = f^{\prime}(g(x)) \cdot g^{\prime}(x) $$
这个看似简单的公式是反向传播算法的数学基础!
2. 微分与线性化
2.1 微分的几何意义
微分 $dy = f^{\prime}(x)dx$ 是函数变化的线性近似。在几何上,它是切线纵坐标的变化量。
关键思想:对于微小的 $\Delta x$: $$ \Delta f = f(x + \Delta x) - f(x) \approx f^{\prime}(x)\Delta x $$
近似误差是 $\Delta x$ 的高阶无穷小: $$ \lim_{\Delta x \to 0} \frac{\Delta f - f^{\prime}(x)\Delta x}{\Delta x} = 0 $$
2.2 多元函数的微分
对于多元函数 $f(\mathbf{x})$,其中 $\mathbf{x} = (x_1, x_2, \ldots, x_n)^\top$,我们需要描述它在所有方向上的变化率。
偏导数是沿坐标轴方向的变化率: $$ \frac{\partial f}{\partial x_i} = \lim_{\Delta x_i \to 0} \frac{f(\mathbf{x} + \Delta x_i \mathbf{e}_i) - f(\mathbf{x})}{\Delta x_i} $$
全微分: $$ df = \sum_{i=1}^n \frac{\partial f}{\partial x_i} dx_i = \nabla f^\top d\mathbf{x} $$
2.3 梯度:多维的导数
梯度将所有偏导数组合成向量: $$ \nabla f(\mathbf{x}) = \begin{pmatrix} \dfrac{\partial f}{\partial x_1} \ \vdots \ \dfrac{\partial f}{\partial x_n} \end{pmatrix} $$
关键性质:梯度指向函数增长最快的方向。因此,负梯度方向是最速下降方向。
证明(方向导数): $$ \frac{\partial f}{\partial \mathbf{u}} = \nabla f^\top \mathbf{u} = \lVert \nabla f \rVert \lVert \mathbf{u} \rVert \cos\theta $$
当 $\theta = 0$ 时($\mathbf{u}$ 与 $\nabla f$ 同向),方向导数最大。因此 $\nabla f$ 指向最速上升方向。
2.4 雅可比矩阵与链式法则
对于向量值函数 $\mathbf{f}: \mathbb{R}^n \to \mathbb{R}^m$,雅可比矩阵是所有偏导数组成的矩阵: $$ J_{\mathbf{f}}(\mathbf{x}) = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_n} \ \vdots & \ddots & \vdots \ \frac{\partial f_m}{\partial x_1} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} $$
多元链式法则(矩阵形式): $$ \frac{\partial \mathbf{z}}{\partial \mathbf{x}} = \frac{\partial \mathbf{z}}{\partial \mathbf{y}} \cdot \frac{\partial \mathbf{y}}{\partial \mathbf{x}} $$
其中 $\mathbf{z} = \mathbf{f}(\mathbf{y})$ 且 $\mathbf{y} = \mathbf{g}(\mathbf{x})$。
3. 积分与累积
3.1 从求和到黎曼积分
积分是微分的逆运算,也是累积的工具。从黎曼和开始: $$ \int_a^b f(x)dx = \lim_{n \to \infty} \sum_{i=1}^n f(x_i^{\ast})\Delta x_i $$
其中 $\Delta x_i = x_i - x_{i-1}$,$x_i^{\ast} \in [x_{i-1}, x_i]$。
3.2 微积分基本定理
牛顿-莱布尼茨公式: $$ \int_a^b f(x)dx = F(b) - F(a) $$
其中 $F^{\prime}(x) = f(x)$。这个公式连接了微分和积分,是微积分的核心定理。
3.3 多重积分与变量替换
二重积分: $$ \iint_D f(x,y)dxdy = \int_{y_1}^{y_2} \int_{x_1(y)}^{x_2(y)} f(x,y)dxdy $$
变量替换公式(雅可比行列式): $$ \iint_{D^{\ast}} f(x,y)dxdy = \iint_D f(x(u,v), y(u,v)) \left|\frac{\partial(x,y)}{\partial(u,v)}\right| dudv $$
其中雅可比行列式: $$ \frac{\partial(x,y)}{\partial(u,v)} = \det \begin{pmatrix} \frac{\partial x}{\partial u} & \frac{\partial x}{\partial v} \ \frac{\partial y}{\partial u} & \frac{\partial y}{\partial v} \end{pmatrix} $$
4. 级数与逼近
4.1 泰勒展开:用多项式逼近函数
泰勒公式是线性化的自然推广。在 $x_0$ 附近,$f(x)$ 可以用多项式逼近: $$ f(x) = f(x_0) + f^{\prime}(x_0)(x - x_0) + \frac{f^{\prime\prime}(x_0)}{2!}(x - x_0)^2 + \cdots + \frac{f^{(n)}(x_0)}{n!}(x - x_0)^n + R_n(x) $$
余项形式(拉格朗日型): $$ R_n(x) = \frac{f^{(n+1)}(\xi)}{(n+1)!}(x - x_0)^{n+1} $$
其中 $\xi$ 在 $x_0$ 和 $x$ 之间。
泰勒级数(当 $n \to \infty$): $$ f(x) = \sum_{n=0}^{\infty} \frac{f^{(n)}(x_0)}{n!}(x - x_0)^n $$
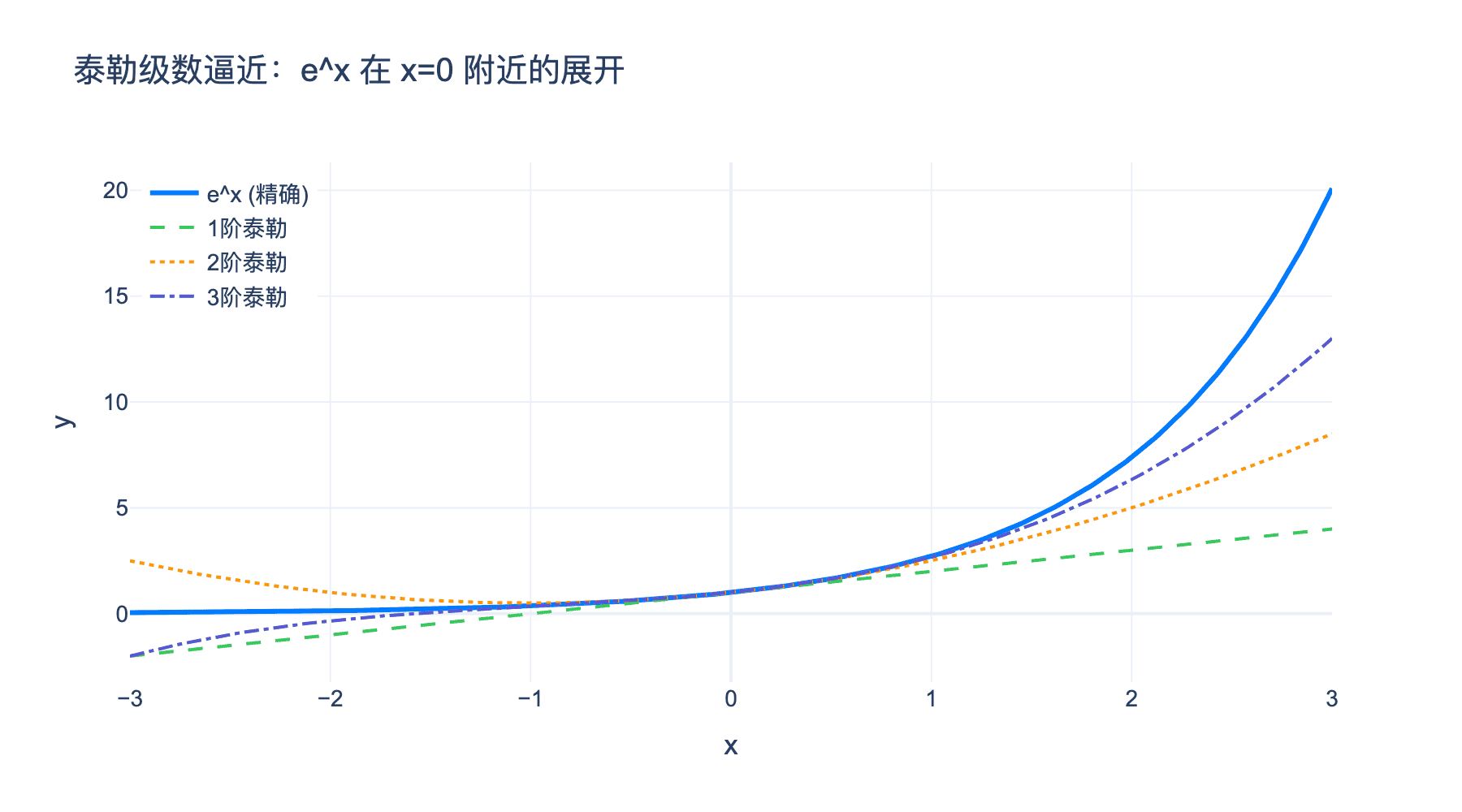
图1:泰勒级数用多项式逼近函数 $e^x$。阶数越高,逼近范围越广,误差越小。
4.2 多元泰勒展开
对于多元函数 $f: \mathbb{R}^n \to \mathbb{R}$,在 $\mathbf{x}_0$ 附近: $$ f(\mathbf{x}_0 + \Delta \mathbf{x}) = f(\mathbf{x}_0) + \nabla f(\mathbf{x}_0)^\top \Delta \mathbf{x} + \frac{1}{2}\Delta \mathbf{x}^\top H(\mathbf{x}_0) \Delta \mathbf{x} + \mathcal{O}(\lVert \Delta \mathbf{x} \rVert^3) $$
其中 $H_{ij} = \frac{\partial^2 f}{\partial x_i \partial x_j}$ 是Hessian矩阵(二阶导数矩阵)。
4.3 在优化中的应用
一阶条件(必要条件): $$ \nabla f(\mathbf{x}^{\ast}) = \mathbf{0} $$
二阶条件(充分条件,对于凸函数): $$ H(\mathbf{x}^{\ast}) \succ 0 \quad (\text{正定}) $$
泰勒展开是理解优化算法(如牛顿法)的数学基础。
第二部分:机器学习中的微积分
1. 梯度下降法
1.1 算法推导
考虑无约束优化问题: $$ \min_{\mathbf{x} \in \mathbb{R}^n} f(\mathbf{x}) $$
核心思想:在当前点 $\mathbf{x}_k$,计算梯度 $\nabla f(\mathbf{x}k)$,然后沿负梯度方向移动: $$ \mathbf{x}{k+1} = \mathbf{x}_k - \eta \nabla f(\mathbf{x}_k) $$
其中 $\eta$ 是学习率(learning rate),控制步长大小。
1.2 为什么这样走是正确的?
泰勒展开证明:
在 $\mathbf{x}_k$ 附近对 $f$ 做一阶近似: $$ f(\mathbf{x}_k + \Delta \mathbf{x}) \approx f(\mathbf{x}_k) + \nabla f(\mathbf{x}_k)^\top \Delta \mathbf{x} $$
我们要找到 $\Delta \mathbf{x}$ 使 $f$ 减小最多。设步长固定:$\lVert \Delta \mathbf{x} \rVert = \epsilon$。
由柯西-施瓦茨不等式: $$ \nabla f^\top \Delta \mathbf{x} \geq -\lVert \nabla f \rVert \cdot \lVert \Delta \mathbf{x} \rVert = -\epsilon \lVert \nabla f \rVert $$
当且仅当 $\Delta \mathbf{x}$ 与 $-\nabla f$ 同向时取等号。因此,负梯度方向是最速下降方向。
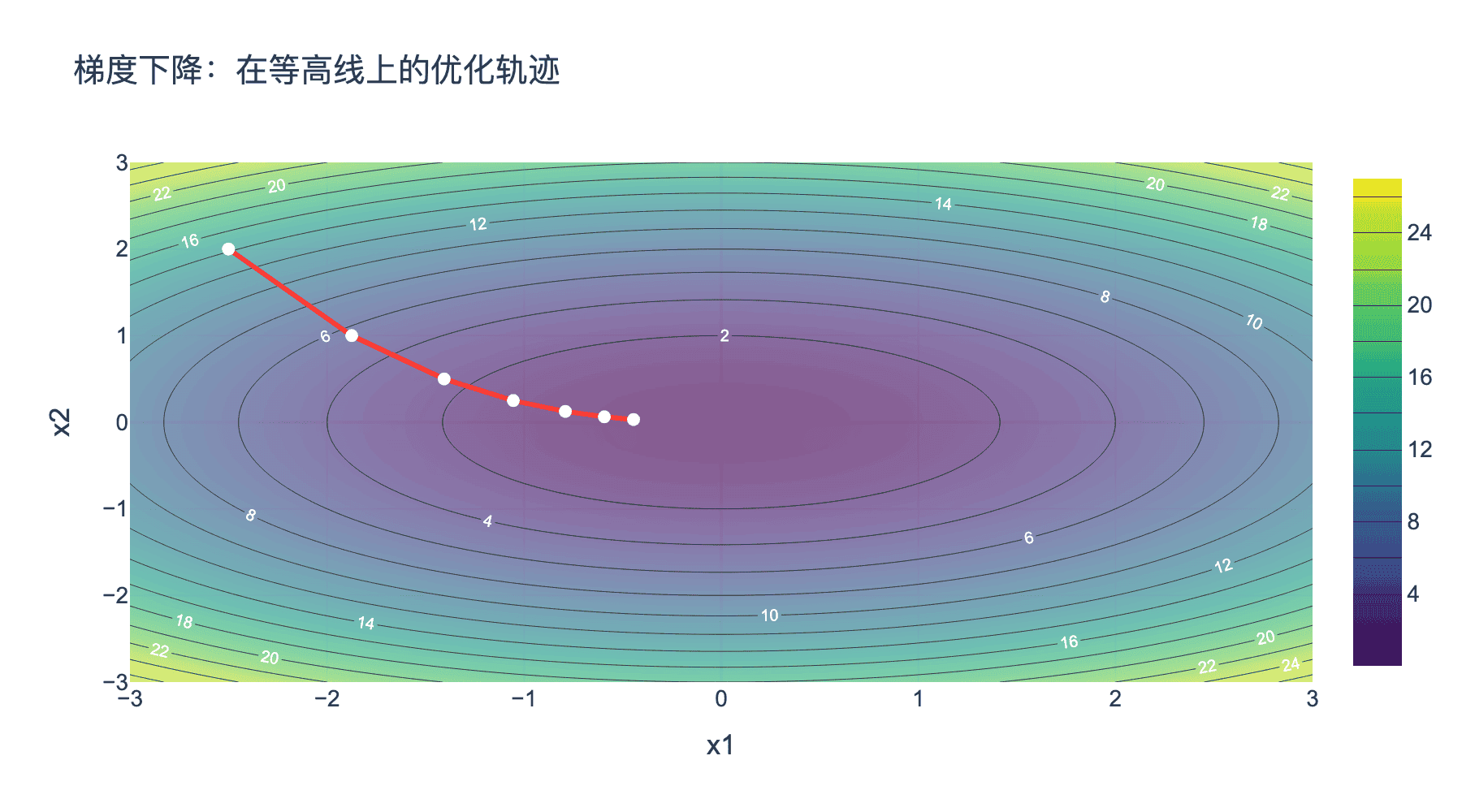
图2:梯度下降在等高线上的优化轨迹。红色箭头显示每次迭代沿负梯度方向移动,最终收敛到最小值(中心点)。
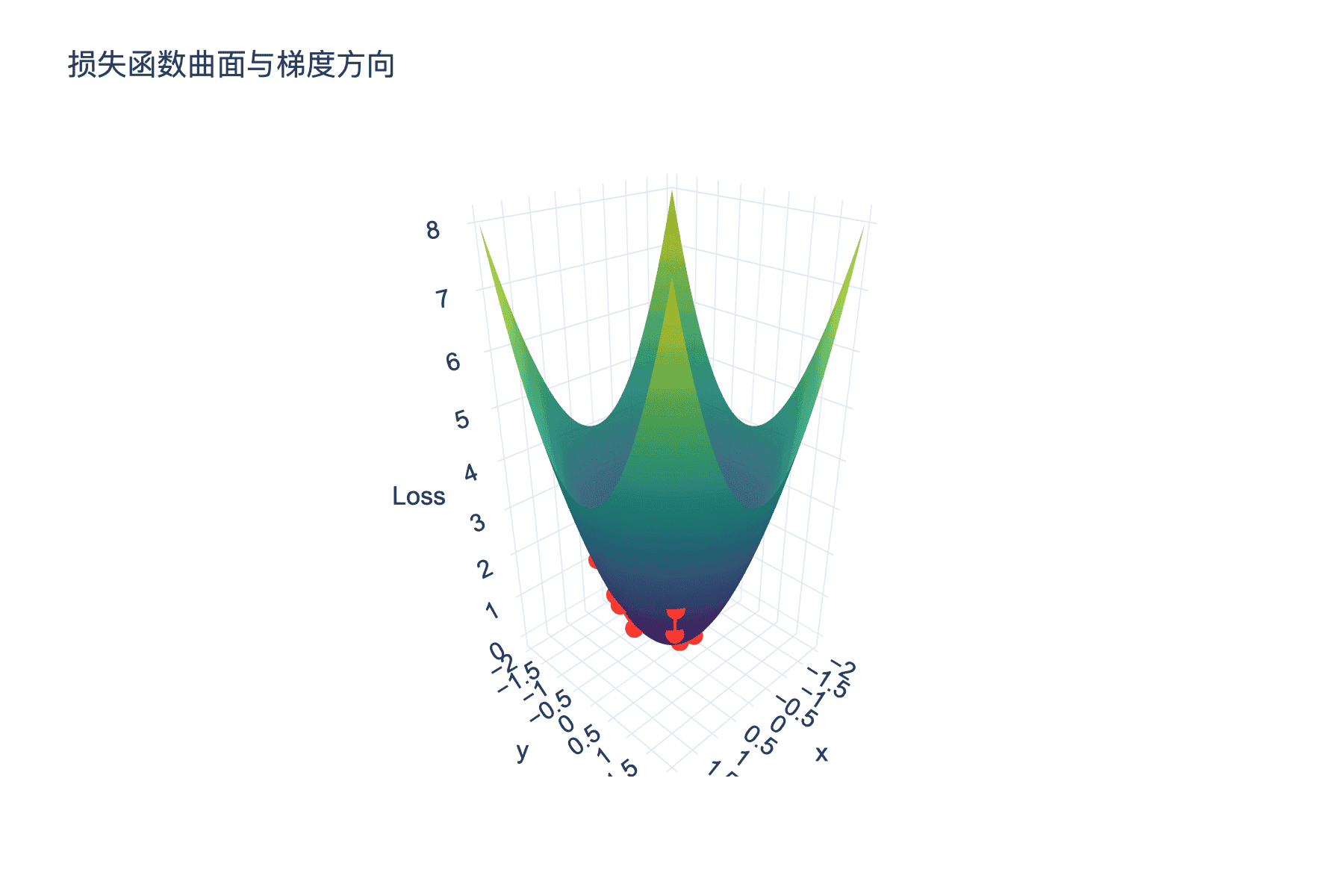
图3:损失函数曲面上的梯度方向。红色向量显示负梯度方向,指向函数值下降最快的方向。
1.3 收敛性分析(强凸情况)
假设 $f$ 是 $\mu$-强凸的,且梯度是 $L$-Lipschitz连续的: $$ \mu I \preceq H(\mathbf{x}) \preceq LI $$
收敛率: $$ f(\mathbf{x}^{(t)}) - f(\mathbf{x}^{\ast}) \leq \left(1 - \frac{\mu}{L}\right)^{t} [f(\mathbf{x}^{(0)}) - f(\mathbf{x}^{\ast})] $$
这是线性收敛(几何收敛)。
1.4 学习率的选择
学习率 $\eta$ 太小:收敛慢,需要很多步 学习率 $\eta$ 太大:可能"冲过"最优点,甚至发散
经验法则:对于 $L$-光滑函数,选择 $\eta < \frac{2}{L}$。
1.5 动量方法
问题:梯度下降在"峡谷"形状的损失函数上振荡。
解决方案:加入动量项,利用历史梯度信息: $$ \mathbf{v}t = \beta \mathbf{v}{t-1} + (1 - \beta)\nabla L(\mathbf{w}t) $$ $$ \mathbf{w}{t+1} = \mathbf{w}_t - \eta \mathbf{v}_t $$
动量相当于"惯性",可以帮助算法穿越平坦区域,减少振荡。
1.6 自适应学习率
AdaGrad:为每个参数使用不同的学习率: $$ \mathbf{w}{t+1, i} = \mathbf{w}{t, i} - \frac{\eta}{\sqrt{G_{t, ii} + \epsilon}} \nabla L(\mathbf{w}_t)_i $$
其中 $G_{t, ii} = \sum_{j=1}^t (\nabla L(\mathbf{w}_j)_i)^2$ 是历史梯度的平方和。
RMSProp:使用移动平均代替累积求和: $$ G_{t, ii} = \beta G_{t-1, ii} + (1 - \beta)(\nabla L(\mathbf{w}_t)_i)^2 $$
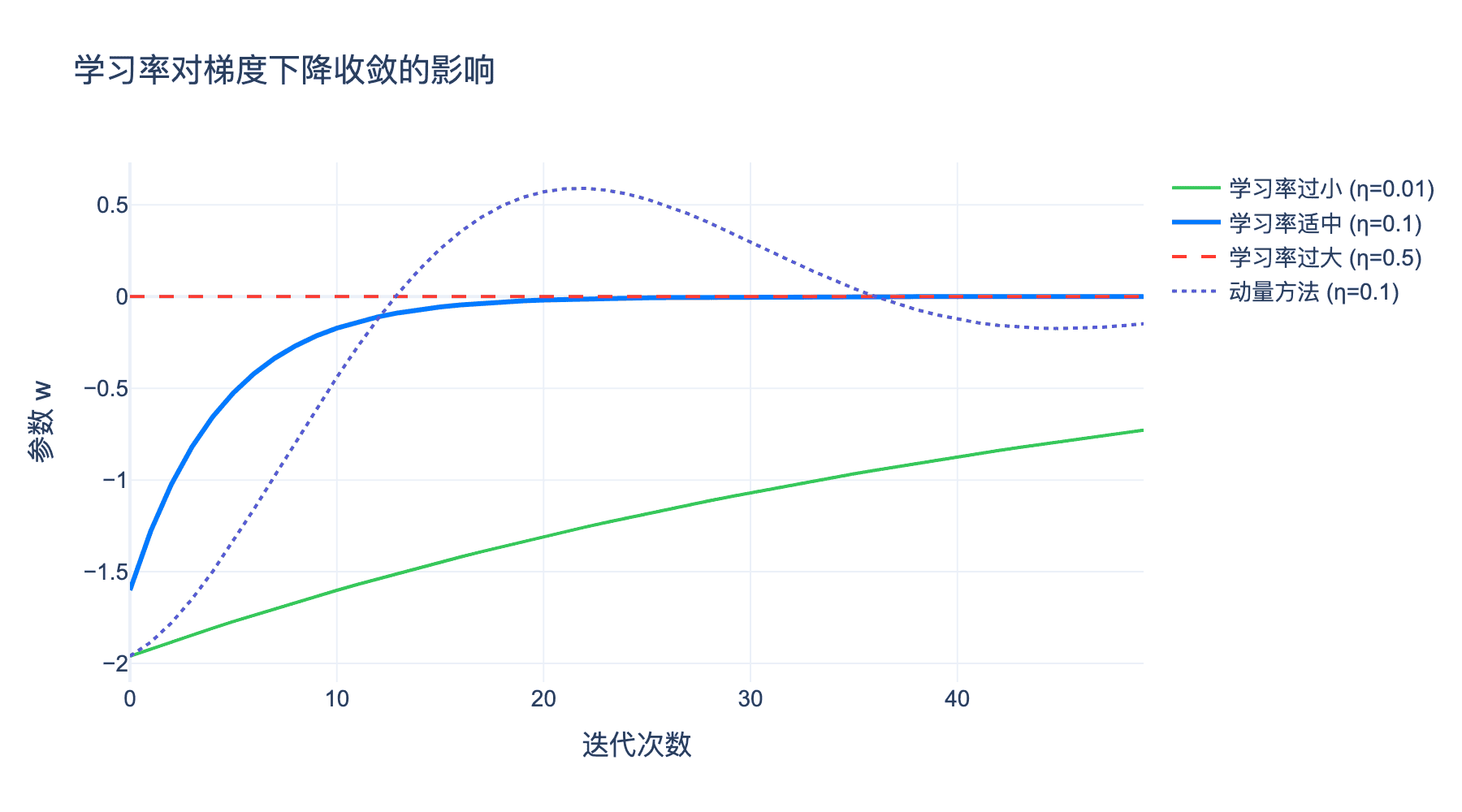
图4:不同学习率对梯度下降收敛的影响。绿色线(学习率过小)收敛慢;蓝色线(学习率适中)快速收敛;红色线(学习率过大)振荡;紫色线(动量方法)加速收敛。
2. 拉格朗日乘数法
2.1 约束优化问题
考虑等式约束优化: $$ \min f(\mathbf{x}) \quad \text{s.t.} \quad g(\mathbf{x}) = 0 $$
拉格朗日函数: $$ \mathcal{L}(\mathbf{x}, \lambda) = f(\mathbf{x}) + \lambda g(\mathbf{x}) $$
KKT条件(Karush-Kuhn-Tucker): $$ \nabla_{\mathbf{x}} \mathcal{L} = \mathbf{0}, \quad g(\mathbf{x}) = 0 $$
2.2 几何解释
在最优解处,$\nabla f$ 必须与 $\nabla g$ 平行(否则可以沿约束曲面移动以降低 $f$): $$ \nabla f = -\lambda \nabla g $$
2.3 在SVM中的应用
硬间隔SVM: $$ \min_{\mathbf{w}, b} \frac{1}{2}\lVert \mathbf{w} \rVert^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \geq 1 $$
对偶问题: $$ \max_{\alpha_i} \sum_i \alpha_i - \frac{1}{2}\sum_{i,j} \alpha_i \alpha_j y_i y_j \mathbf{x}_i^\top \mathbf{x}_j $$
3. 信息论中的微积分
3.1 熵的定义与微分
信息熵: $$ H(p) = -\sum_{i=1}^n p_i \log p_i $$
微分熵(连续变量): $$ h(p) = -\int p(x)\log p(x)dx $$
3.2 交叉熵与KL散度
交叉熵: $$ H(p, q) = -\sum_i p_i \log q_i $$
KL散度(Kullback-Leibler divergence): $$ D_{KL}(p | q) = \sum_i p_i \log \frac{p_i}{q_i} $$
性质:$D_{KL}(p | q) \geq 0$,等号成立当且仅当 $p = q$。
证明(使用Jensen不等式): $$ D_{KL}(p | q) = \mathbb{E}_p\left[\log \frac{p}{q}\right] = -\mathbb{E}_p\left[\log \frac{q}{p}\right] \geq -\log \mathbb{E}_p\left[\frac{q}{p}\right] = -\log 1 = 0 $$
3.3 最大熵原理
原理:在所有满足约束的概率分布中,选择熵最大的分布。
应用:高斯分布是给定方差下熵最大的分布。
第三部分:深度学习中的微积分
1. 反向传播算法
1.1 神经网络的前向传播
考虑一个简单的两层神经网络: $$ \mathbf{z}^{(1)} = W^{(1)} \mathbf{x} + \mathbf{b}^{(1)} $$ $$ \mathbf{a}^{(1)} = \sigma(\mathbf{z}^{(1)}) $$ $$ \mathbf{z}^{(2)} = W^{(2)} \mathbf{a}^{(1)} + \mathbf{b}^{(2)} $$ $$ \hat{\mathbf{y}} = \sigma(\mathbf{z}^{(2)}) $$
损失函数:$L = \frac{1}{2}\lVert \hat{\mathbf{y}} - \mathbf{y} \rVert^2$
1.2 反向传播的数学推导
我们需要计算损失函数对参数的梯度。
输出层梯度: $$ \frac{\partial L}{\partial \mathbf{z}^{(2)}} = (\hat{\mathbf{y}} - \mathbf{y}) \odot \sigma^{\prime}(\mathbf{z}^{(2)}) $$
其中 $\odot$ 是逐元素乘法,$\sigma^{\prime}(z) = \sigma(z)(1 - \sigma(z))$ 是Sigmoid的导数。
隐藏层梯度(链式法则): $$ \frac{\partial L}{\partial \mathbf{z}^{(1)}} = \left[(W^{(2)})^\top \frac{\partial L}{\partial \mathbf{z}^{(2)}}\right] \odot \sigma^{\prime}(\mathbf{z}^{(1)}) $$
权重梯度: $$ \frac{\partial L}{\partial W^{(2)}} = \frac{\partial L}{\partial \mathbf{z}^{(2)}} (\mathbf{a}^{(1)})^\top $$ $$ \frac{\partial L}{\partial W^{(1)}} = \frac{\partial L}{\partial \mathbf{z}^{(1)}} \mathbf{x}^\top $$
这就是反向传播:从输出层反向传播到输入层,使用链式法则计算每一层的梯度。
1.3 计算图与自动微分
计算图将计算表示为有向无环图(DAG)。每个节点是一个操作,边表示数据流。
自动微分(Automatic Differentiation):
- 前向模式:从输入到输出计算导数
- 反向模式:从输出到输入计算导数(反向传播)
优势:精确计算导数(无截断误差),复杂度与输出维度成正比。
1.4 梯度消失问题
在深层网络中,梯度可能指数级衰减。考虑 $L$ 层线性网络: $$ \frac{\partial L}{\partial \mathbf{x}} = (W^{(L)})^\top \cdots (W^{(1)})^\top \frac{\partial L}{\partial \mathbf{y}} $$
如果权重矩阵的奇异值都小于1,梯度会指数级衰减 → 梯度消失。
解决方案:
- ReLU激活:导数为0或1,不会衰减
- 残差连接:提供"梯度高速公路"
- 层归一化:规范化激活值分布
2. 激活函数的导数
2.1 Sigmoid函数
定义:$\sigma(z) = \frac{1}{1 + e^{-z}}$
导数:$\sigma^{\prime}(z) = \sigma(z)(1 - \sigma(z))$
问题:
- 梯度消失:当 $\lvert z \rvert$ 很大时,$\sigma^{\prime}(z) \approx 0$
- 输出不以零为中心
2.2 Tanh函数
定义:$\tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}$
导数:$\tanh^{\prime}(z) = 1 - \tanh^2(z)$
优势:输出以零为中心。
2.3 ReLU函数
定义:$\text{ReLU}(z) = \max(0, z)$
导数:$\text{ReLU}^{\prime}(z) = \begin{cases} 1 & z > 0 \ 0 & z \leq 0 \end{cases}$
优势:
- 缓解梯度消失
- 计算简单
- 稀疏激活
问题:Dead ReLU(神经元"死亡")。
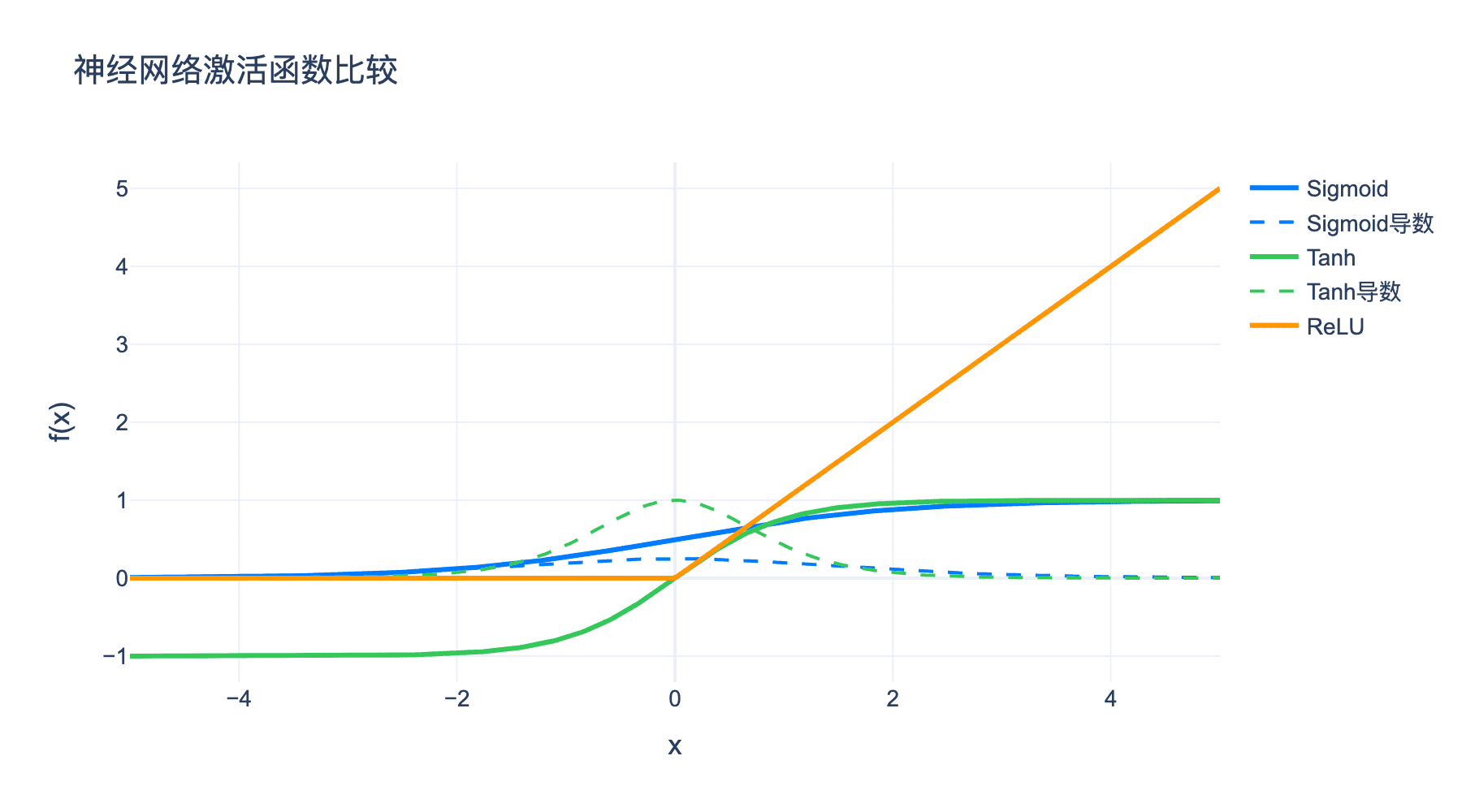
图5:常见激活函数及其导数的比较。Sigmoid和Tanh的导数在两端趋于0(梯度消失),ReLU的导数恒为0或1(避免梯度消失)。
3. 正则化的微积分视角
3.1 L2正则(权重衰减)
目标: $$ \min_{\mathbf{w}} L(\mathbf{w}) + \frac{\lambda}{2}\lVert \mathbf{w} \rVert^2 $$
梯度: $$ \nabla_{\mathbf{w}} = \nabla L(\mathbf{w}) + \lambda \mathbf{w} $$
几何意义:限制参数空间,防止过拟合。
3.2 L1正则
目标: $$ \min_{\mathbf{w}} L(\mathbf{w}) + \lambda \lVert \mathbf{w} \rVert_1 $$
次梯度: $$ \partial_{\mathbf{w}} = \nabla L(\mathbf{w}) + \lambda \cdot \text{sign}(\mathbf{w}) $$
几何意义:产生稀疏解(特征选择)。
4. 优化算法的演进
4.1 从SGD到Adam
SGD(随机梯度下降): $$ \mathbf{w}_{t+1} = \mathbf{w}_t - \eta \nabla L(\mathbf{w}_t) $$
Momentum(动量): $$ \mathbf{v}t = \beta \mathbf{v}{t-1} + (1 - \beta)\nabla L(\mathbf{w}t) $$ $$ \mathbf{w}{t+1} = \mathbf{w}_t - \eta \mathbf{v}_t $$
Adam(Adaptive Moment Estimation):结合动量和自适应学习率: $$ \mathbf{m}t = \beta_1 \mathbf{m}{t-1} + (1 - \beta_1)\nabla L(\mathbf{w}_t) $$ $$ \mathbf{v}t = \beta_2 \mathbf{v}{t-1} + (1 - \beta_2)(\nabla L(\mathbf{w}t))^2 $$ $$ \mathbf{w}{t+1} = \mathbf{w}_t - \frac{\eta}{\sqrt{\hat{\mathbf{v}}_t + \epsilon}} \hat{\mathbf{m}}_t $$
其中 $\hat{\mathbf{m}}_t = \frac{\mathbf{m}_t}{1 - \beta_1^t}$ 和 $\hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1 - \beta_2^t}$ 是偏差修正后的估计。
Adam是现代深度学习的默认优化器。
4.2 二阶优化:牛顿法
牛顿法使用二阶导数(Hessian矩阵): $$ \mathbf{w}_{t+1} = \mathbf{w}_t - H^{-1} \nabla L(\mathbf{w}_t) $$
其中 $H_{ij} = \frac{\partial^2 L}{\partial w_i \partial w_j}$。
优点:二阶收敛(接近最优点时非常快) 缺点:计算Hessian矩阵代价高($O(d^2)$),可能不正定
L-BFGS:拟牛顿法,用一阶信息近似Hessian,避免显式计算二阶导数。
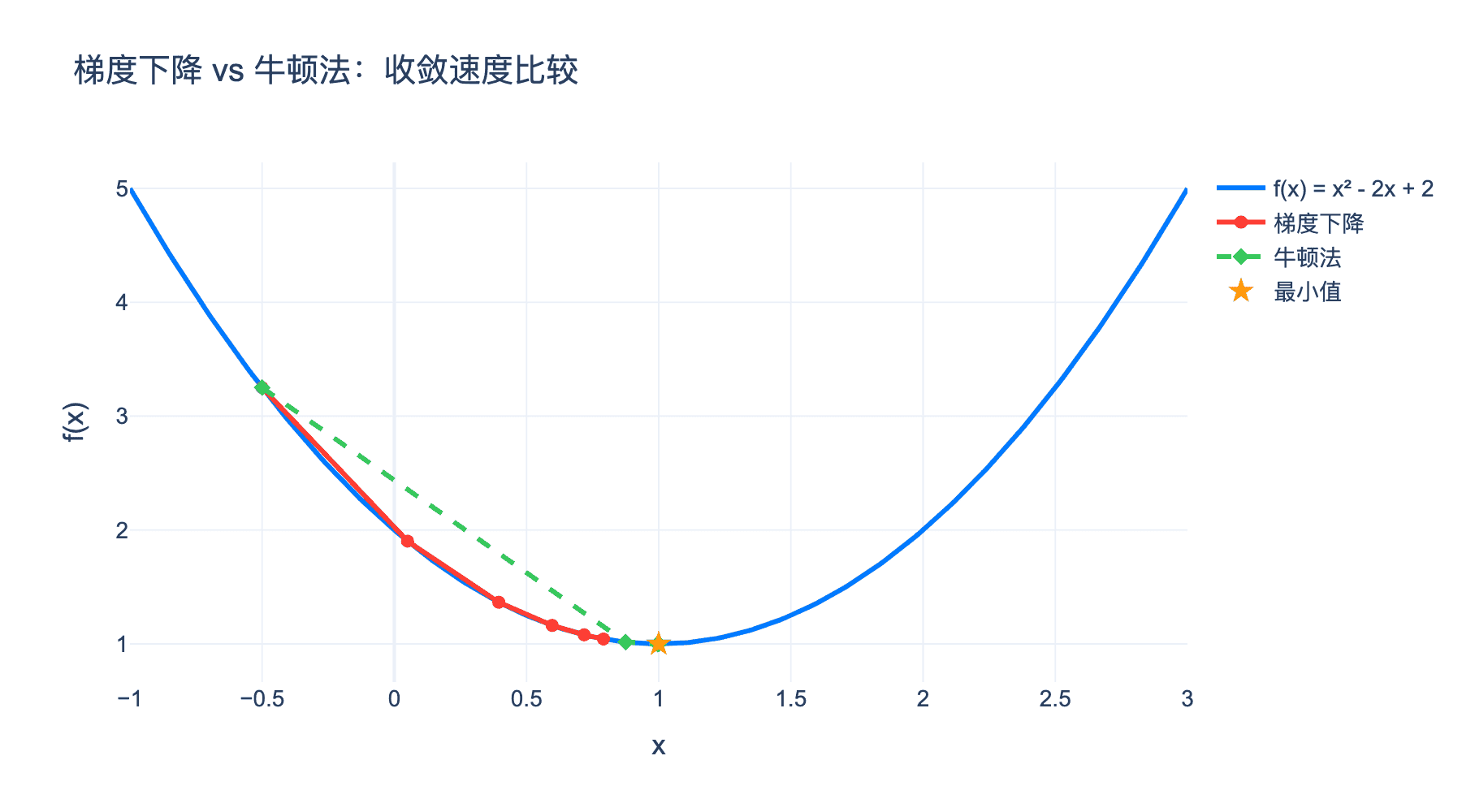
图6:梯度下降与牛顿法的收敛速度比较。红色线(梯度下降)线性收敛,绿色线(牛顿法)二次收敛,快速到达最小值。
第四部分:高级主题
1. 变分法
1.1 泛函的极值问题
泛函是函数的函数:$J[y] = \int_{x_1}^{x_2} F(x, y, y^{\prime})dx$
变分(Variation):$\delta y = \epsilon \eta(x)$,其中 $\eta(x_1) = \eta(x_2) = 0$
欧拉-拉格朗日方程: $$ \frac{\partial F}{\partial y} - \frac{d}{dx}\left(\frac{\partial F}{\partial y^{\prime}}\right) = 0 $$
推导: $$ \delta J = \int \left(\frac{\partial F}{\partial y}\delta y + \frac{\partial F}{\partial y^{\prime}}\delta y^{\prime}\right)dx = \int \left(\frac{\partial F}{\partial y} - \frac{d}{dx}\frac{\partial F}{\partial y^{\prime}}\right)\delta y,dx = 0 $$
由于 $\delta y$ 任意,被积函数必须为零。
1.2 在变分自编码器(VAE)中的应用
ELBO(Evidence Lower Bound): $$ \mathcal{L} = \mathbb{E}{q{\phi}(z|x)}[\log p_{\theta}(x|z)] - D_{KL}(q_{\phi}(z|x) | p(z)) $$
通过变分推断优化 $\phi$ 和 $\theta$。
2. 矩阵微积分
2.1 矩阵求导法则
标量对向量: $$ \frac{\partial f}{\partial \mathbf{x}} = \begin{pmatrix} \frac{\partial f}{\partial x_1} \ \vdots \ \frac{\partial f}{\partial x_n} \end{pmatrix} $$
标量对矩阵: $$ \frac{\partial f}{\partial X} = \begin{pmatrix} \frac{\partial f}{\partial X_{11}} & \cdots \ \vdots & \ddots \end{pmatrix} $$
常用公式:
- $\frac{\partial}{\partial \mathbf{x}} \mathbf{a}^\top \mathbf{x} = \mathbf{a}$
- $\frac{\partial}{\partial \mathbf{x}} \mathbf{x}^\top A \mathbf{x} = (A + A^\top)\mathbf{x}$
- $\frac{\partial}{\partial X} \text{tr}(AX) = A^\top$
2.2 Kronecker乘积
定义: $$ A \otimes B = \begin{pmatrix} a_{11}B & \cdots \ \vdots & \ddots \end{pmatrix} $$
性质:
- $(A \otimes B)(C \otimes D) = (AC) \otimes (BD)$
- $\text{vec}(ABC) = (C^\top \otimes A)\text{vec}(B)$
3. 微分几何初步
3.1 流形与切空间
流形:局部像欧几里得空间的拓扑空间。
切空间 $T_pM$:流形在点 $p$ 处的"线性化"。
切向量:$\mathbf{v} = \frac{d}{dt}\big|_{t=0} \gamma(t)$,其中 $\gamma(t)$ 是曲线。
3.2 黎曼度量
度量张量 $g_p$:定义切空间上的内积: $$ \langle \mathbf{u}, \mathbf{v} \rangle_p = g_p(\mathbf{u}, \mathbf{v}) $$
测地线:“最短路径"曲线,满足测地线方程: $$ \frac{d^2 x^\mu}{dt^2} + \Gamma^\mu_{\alpha\beta} \frac{dx^\alpha}{dt} \frac{dx^\beta}{dt} = 0 $$
其中 $\Gamma^\mu_{\alpha\beta}$ 是Christoffel符号。
3.3 梯度流
在黎曼流形上,梯度下降变为梯度流: $$ \frac{d\mathbf{x}}{dt} = -\text{grad } f(\mathbf{x}) $$
其中 $\text{grad } f$ 由度量定义: $$ g(\text{grad } f, \mathbf{v}) = df(\mathbf{v}) = \nabla f^\top \mathbf{v} $$
4. 随机微积分
4.1 随机过程的微分
布朗运动 $W_t$:高斯随机过程,满足:
- $W_0 = 0$
- 独立增量
- $W_t - W_s \sim \mathcal{N}(0, t-s)$
4.2 伊藤积分
定义: $$ I_T = \int_0^T H_t , dW_t $$
伊藤公式(链式法则的随机版本): $$ df(X_t) = f^{\prime}(X_t)dX_t + \frac{1}{2}f^{\prime\prime}(X_t)d\langle X \rangle_t $$
其中 $d\langle X \rangle_t$ 是二次变差。
4.3 在扩散模型中的应用
SDE(随机微分方程): $$ d\mathbf{x} = \mathbf{f}(\mathbf{x}, t)dt + g(t)d\mathbf{w}_t $$
扩散过程:前向过程逐渐添加噪声,反向过程去噪生成样本。
第五部分:关键洞察与展望
1. 微积分与几何
微积分本质上是几何:
- 导数是切线的斜率
- 梯度指向最速上升方向
- 二阶导数描述曲率
- 积分计算曲线下的面积
理解这些几何直观有助于理解优化算法的行为。
2. 线性化的重要性
现代人工智能的核心思想是局部线性化:
- 神经网络是复杂的非线性函数
- 但在每个参数点附近,可以用线性函数逼近
- 通过不断的线性近似和迭代,找到全局最优
泰勒展开是线性化的数学工具: $$ f(\mathbf{x} + \Delta \mathbf{x}) \approx f(\mathbf{x}) + \nabla f(\mathbf{x})^\top \Delta \mathbf{x} + \frac{1}{2}\Delta \mathbf{x}^\top H \Delta \mathbf{x} $$
3. 链式法则的威力
链式法则使得我们可以计算任意复合函数的导数。神经网络本质上是一个巨大的复合函数,反向传播算法就是链式法则的高效实现。
现代深度学习框架(PyTorch, TensorFlow)使用自动微分(automatic differentiation)来自动计算梯度,让开发者专注于模型架构而非数学细节。
4. 优化的艺术
梯度下降看似简单,但有许多改进空间:
- 动量:利用历史信息加速收敛
- 自适应学习率:为每个参数定制步长
- 二阶方法:利用曲率信息更快收敛
- 随机性:SGD的噪声有助于跳出局部最优
5. 未来展望
扩散模型的随机微积分:理解SDE的解对改进扩散模型至关重要。
神经符号AI:结合神经网络和符号推理,需要新的微积分工具。
优化理论:非凸优化、分布式优化的理论仍在发展中。
量子机器学习:量子微积分可能带来新的优化方法。
结语:微积分与AI的未来
从17世纪牛顿和莱布尼茨发明微积分,到21世纪的深度学习革命,微积分一直是描述变化的数学语言。
在这篇文章中,我们深入探讨了:
- 导数与微分:从变化率到梯度,从线性化到链式法则
- 梯度下降:最优化算法的基础,几何直观与数学严格
- 反向传播:链式法则的矩阵形式,计算图与自动微分
- 优化算法:从SGD到Adam,从一阶到二阶方法
- 高级主题:变分法、矩阵微积分、微分几何、随机微积分
微积分不仅提供了计算梯度的方法,更重要的是,它培养了一种思维方式:用局部变化理解全局行为,用线性逼近处理非线性问题。
在未来,随着人工智能的发展,微积分将继续发挥核心作用。无论是扩散模型的随机微积分,还是神经符号AI的微积分基础,都需要深厚的微积分功底。
理解微积分,不仅是掌握一门数学工具,更是培养一种分析问题、解决问题、创新思考的能力。正如伟大的数学家柯西所说:“微积分是人类智慧的结晶。”
参考文献
- Spivak, M. (2008). Calculus On Manifolds (4th ed.). Publish or Perish.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Boyd, S., & Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press.
- Nielsen, M. A. (2015). Neural Networks and Deep Learning. Determination Press.
- Rudin, W. (1976). Principles of Mathematical Analysis (3rd ed.). McGraw-Hill.
- Lee, J. M. (2018). Introduction to Riemannian Manifolds (2nd ed.). Springer.
- Oksendal, B. (2003). Stochastic Differential Equations (6th ed.). Springer.
- Nocedal, J., & Wright, S. J. (2006). Numerical Optimization (2nd ed.). Springer.
- Petersen, K. B., & Pedersen, M. S. (2012). The Matrix Cookbook. Technical University of Denmark.