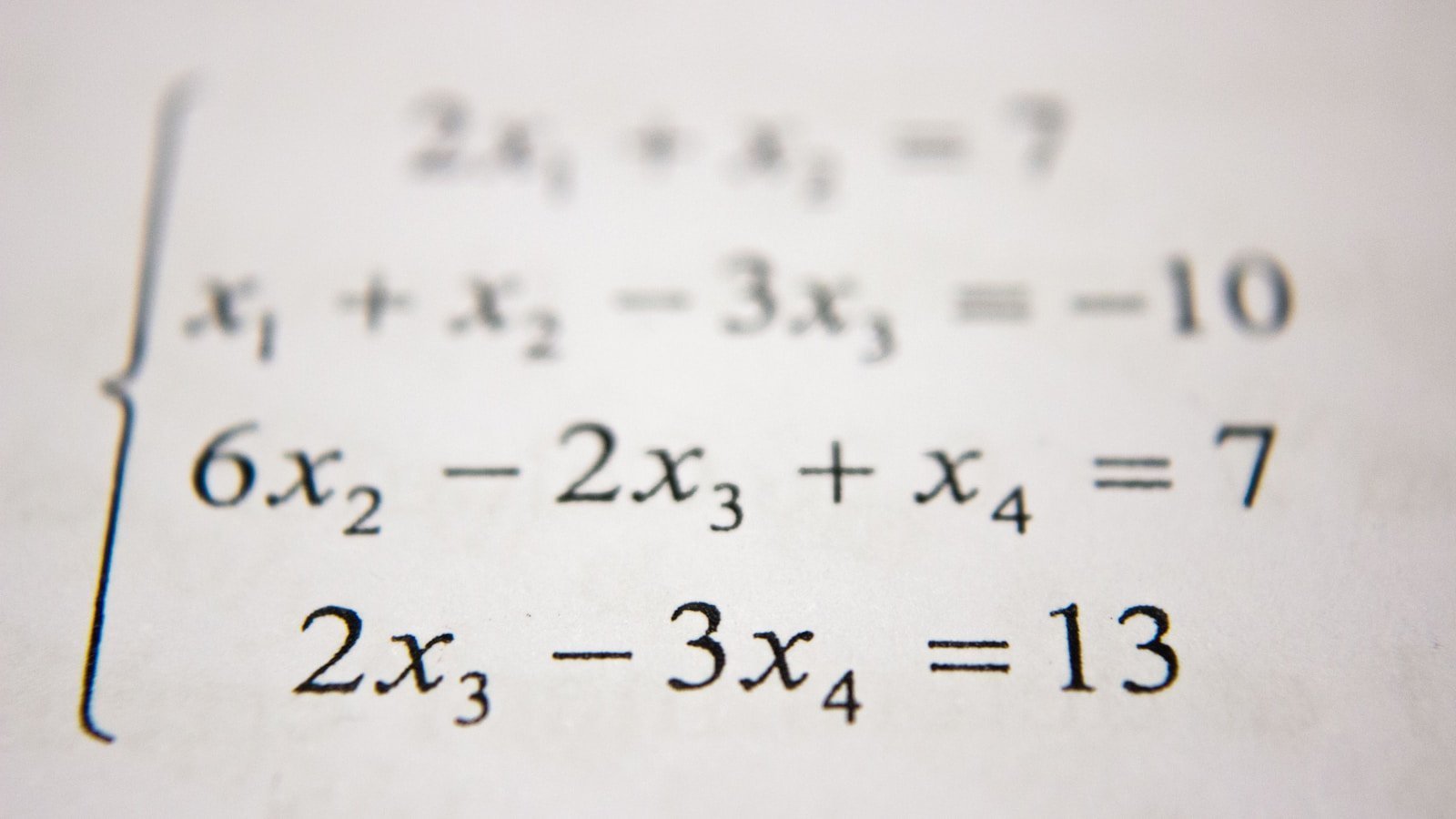
引言:当概率成为空间上的点
想象一下,你站在一个巨大的画廊里。墙上挂着无数幅画,每一幅画都是一张概率分布的直方图。如果你要量化两幅画之间的"距离",你会怎么做?直接比较每个柱子的高度差异?还是考虑某种更本质的、统计学意义上的距离?
这个问题触及了统计学的核心:如何量化两个概率分布之间的差异。传统的做法是使用 KL 散度或互信息,但这些度量缺乏几何直观——它们不是真正的"距离",也不满足三角不等式。
信息几何给出了一种全新的视角:将所有概率分布看作一个黎曼流形,每个分布是流形上的一个点,Fisher 信息矩阵定义了这个流形上的度量张量。在这个框架下,我们可以谈论"两点之间的最短路径"(测地线),可以计算"梯度"(自然梯度),可以定义"曲率"(统计流形的曲率)。
这个领域的诞生可以追溯到 1945 年,印度统计学家 C. R. Rao 提出了 Fisher 信息度量可以作为微分几何的度量张量。此后,法国数学家 Amari 系统性地发展了信息几何的理论,并将其与神经网络、优化算法相结合。
在这篇文章中,我们将从基础概念开始,系统性地介绍信息几何的核心理论,探讨其在深度学习中的应用,并对未来的发展方向做出展望。
第一章:几何概率空间
1.1 概率分布作为流形
考虑一个简单的例子:所有零均值、单位方差的一维高斯分布 $\mathcal{N}(0, \sigma^2)$ 可以用一个参数 $\sigma$ 来表示。但如果我们考虑所有可能的高斯分布 $\mathcal{N}(\mu, \sigma^2)$,这就变成了一个二维的空间。
更一般地,考虑一个参数族 $\mathcal{P} = {p(x \mid \theta) : \theta \in \Theta}$,其中 $\theta \in \mathbb{R}^n$ 是参数。这个参数族可以看作一个 $n$ 维的流形——这就是统计流形。
关键洞察:每个概率分布不是孤立的对象,而是镶嵌在无穷维分布空间中的一个点。信息几何的任务就是给这个流形装备一个自然的几何结构。
1.2 Fisher 信息度量
1945 年,C. R. Rao 发现了一个重要的事实:Fisher 信息矩阵可以定义一个黎曼度量。
定义:对于参数族 $p(x \mid \theta)$,Fisher 信息矩阵定义为:
$$ I(\theta){ij} = \mathbb{E}{p(x \mid \theta)}\left[\frac{\partial \log p(x \mid \theta)}{\partial \theta_i} \frac{\partial \log p(x \mid \theta)}{\partial \theta_j}\right] $$
在正则条件下,这个矩阵是正定的,因此可以定义一个黎曼度量:
$$ ds^2 = \sum_{i,j} I(\theta)_{ij} d\theta_i d\theta_j $$
直观理解:Fisher 信息度量告诉我们,参数空间中的"距离"应该如何衡量。如果两个参数在统计上很难区分(Fisher 信息小),它们之间的"距离"就远;如果容易区分(Fisher 信息大),它们之间的"距离"就近。
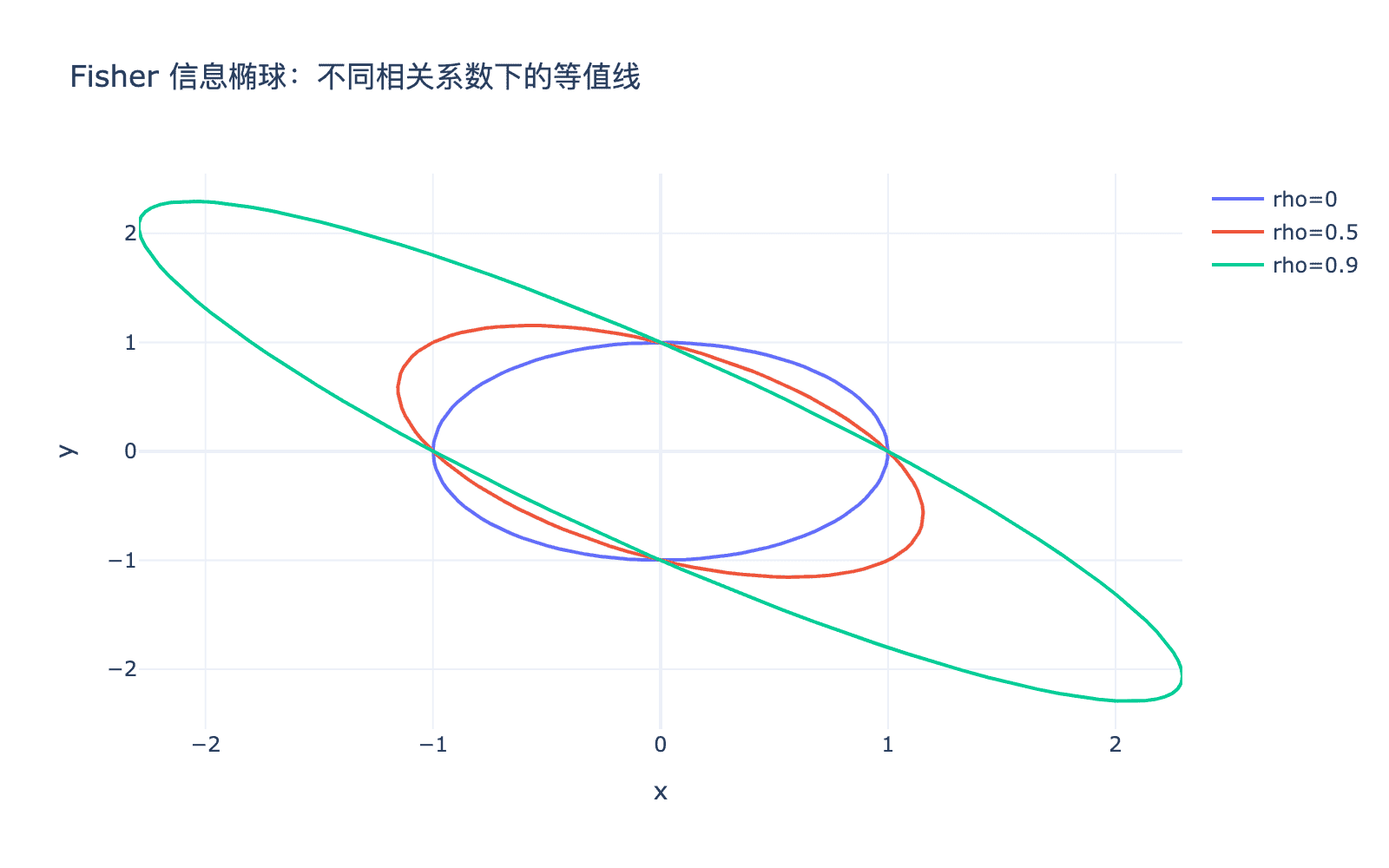
图1:Fisher 信息椭球。不同相关系数下的高斯分布的 Fisher 信息椭球形状不同。椭球的长轴方向对应于方差最大的方向,短轴方向对应于方差最小的方向。
1.3 测地线:概率分布之间的最短路径
在装备了 Fisher 信息度量后,统计流形成为了一个黎曼流形。我们可以计算两点之间的测地线——即概率分布之间的"最短路径"。
对于正态分布的空间,测地线可以通过 Fisher 信息度量显式计算。有趣的是,沿着测地线插值得到的分布,与直接对参数进行线性插值得到的分布是不同的。
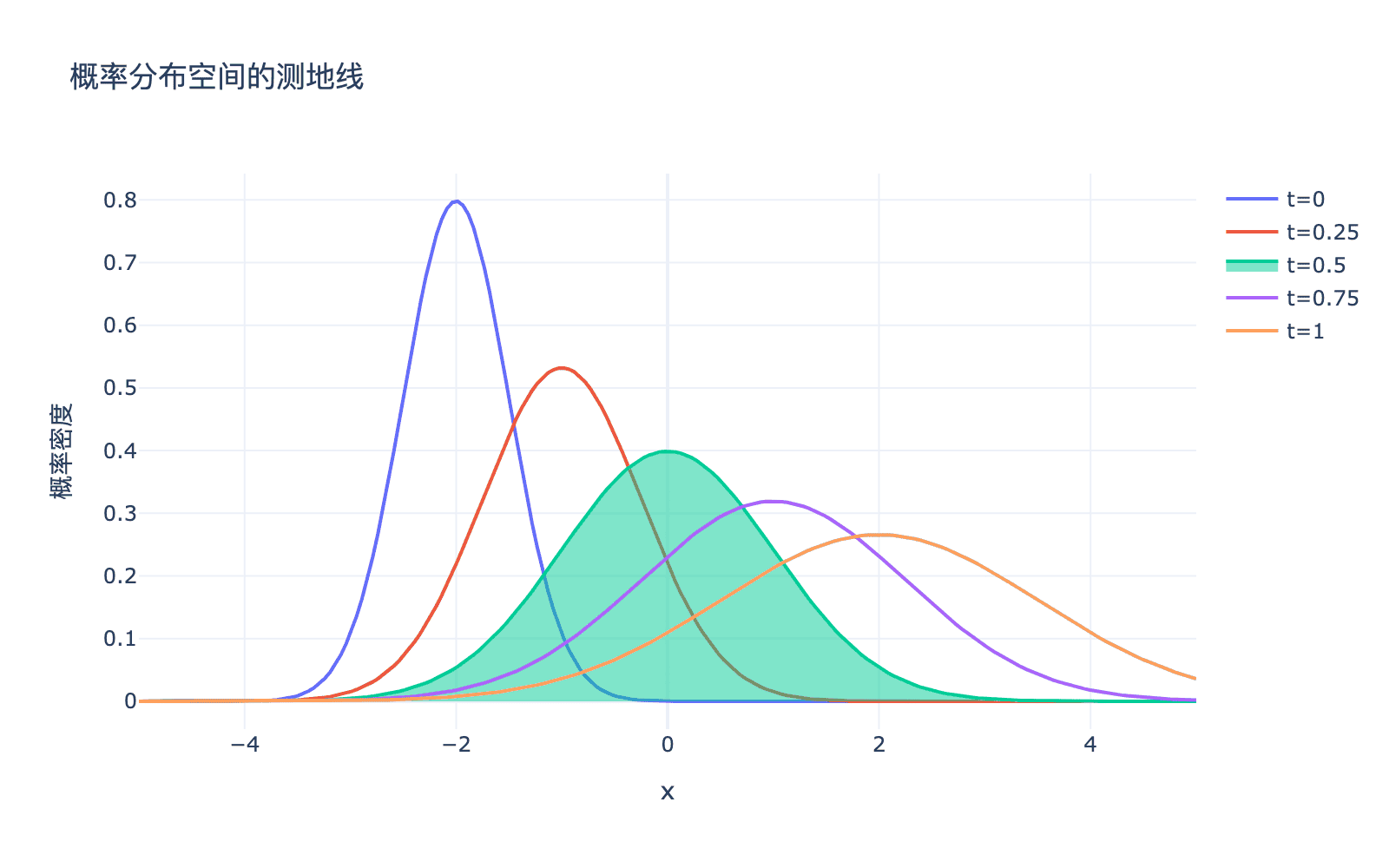
图2:两个高斯分布之间的测地线。注意沿着测地线,分布平滑地从一个"形态"过渡到另一个"形态",而线性插值则会产生不自然的中间分布。
第二章:Fisher 信息度量的性质
2.1 不变性
Fisher 信息度量有一个美妙的性质:它在参数变换下是协变的。
设 $\eta = g(\theta)$ 是一个参数变换,那么在新参数下的 Fisher 信息矩阵为:
$$ I(\eta) = J^{-T} I(\theta) J^{-1} $$
其中 $J$ 是雅可比矩阵。这意味着无论我们选择什么样的参数化,Fisher 信息度量给出的几何结构是内在的、不依赖于参数选择的。
2.2 指数族的平坦性
在信息几何中,指数族(如高斯分布、泊松分布、伯努利分布等)占据着特殊的地位。它们是统计流形中的"平坦空间"——可以像欧几里得空间一样建立整体坐标系,曲率为零。
指数族的形式:
$$ p(x \mid \theta) = \exp\left(\theta^\top T(x) - \psi(\theta)\right) h(x) $$
其中 $T(x)$ 是充分统计量,$\psi(\theta)$ 是势函数。
第三章:自然梯度下降
信息几何在优化中最重要的应用是自然梯度下降。
3.1 标准梯度的问题
考虑优化目标函数 $L(\theta)$。标准梯度下降的更新规则是:
$$ \theta_{t+1} = \theta_t - \alpha \nabla L(\theta_t) $$
这在欧几里得空间中很自然,但在统计流形上就不那么合理了。问题在于:标准梯度假设所有参数方向上的步长是"等价"的,但从统计学的角度来看,不同参数方向的变化对分布的影响是不同的。
3.2 自然梯度的思想
Amari 在 1998 年提出的自然梯度下降解决了这个问题。核心思想是:在统计流形上,梯度应该用 Fisher 信息度量的逆来"预白化":
$$ \theta_{t+1} = \theta_t - \alpha I(\theta_t)^{-1} \nabla L(\theta_t) $$
直观理解:Fisher 信息矩阵的逆告诉我们每个参数方向上的"敏感度"。在敏感的方向上,我们应该用更小的步长;在不敏感的方向上,可以用更大的步长。
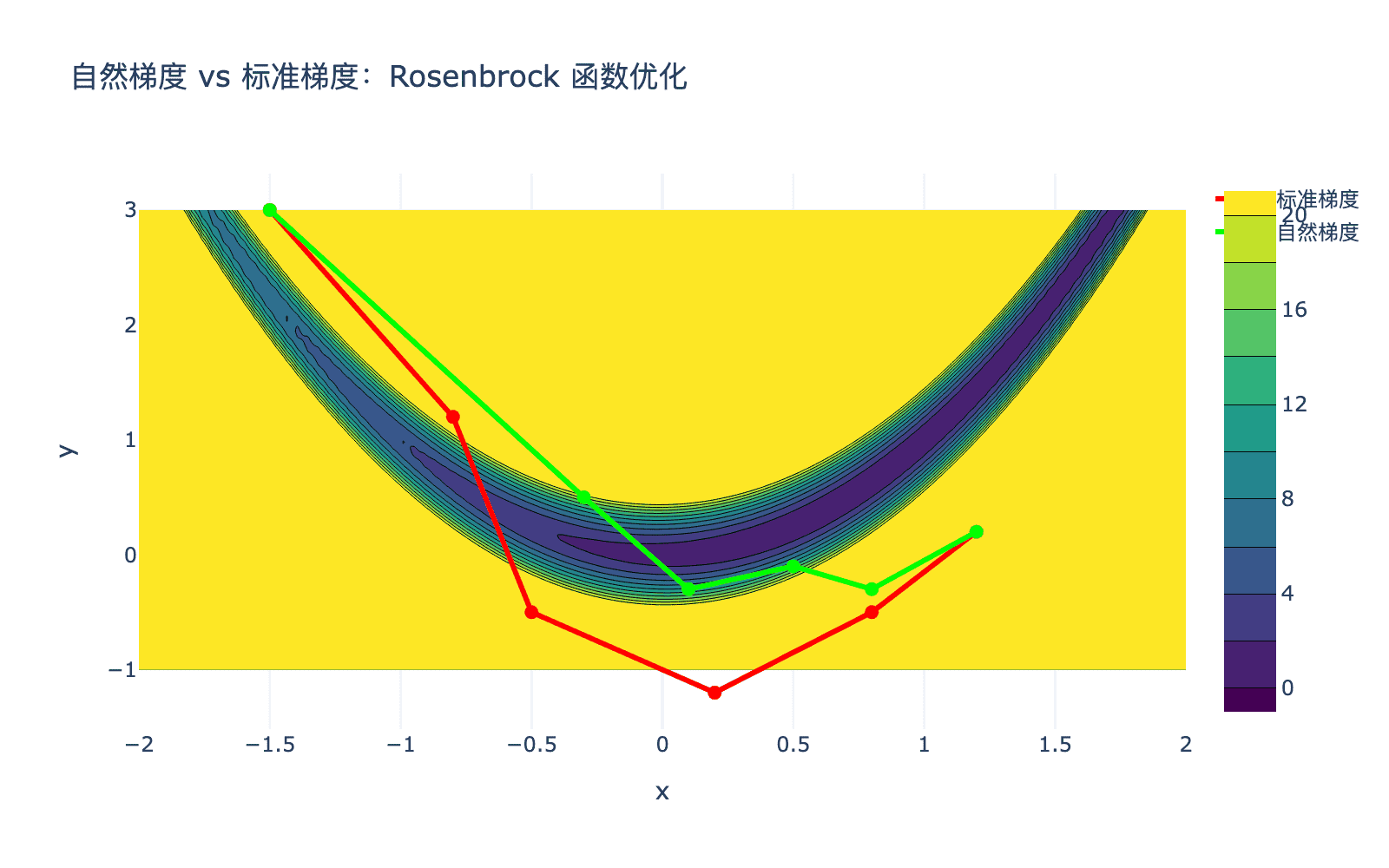
图3:自然梯度下降(绿色)与标准梯度下降(红色)的对比。自然梯度沿着统计流形的测地线方向前进,通常能更快地收敛。
3.3 在深度学习中的应用
自然梯度在深度学习中的应用面临计算 Fisher 信息矩阵的逆的挑战。针对这个问题,研究者们提出了多种近似方法:
- K-FAC(Kronecker-Factored Approximate Curvature):假设 Fisher 信息矩阵可以分解为 Kronecker 乘积的形式
- Adam 及其变种:虽然不是严格的自然梯度,但其自适应学习率的思想与自然梯度一脉相承
- Shampoo:另一种二阶优化的近似方法
第四章:Wasserstein 距离与最优传输
信息几何的另一个重要分支是最优传输理论,以及由此导出的 Wasserstein 距离。
4.1 从 Monge 问题到 Kantorovich 问题
最优传输问题的原始形式是:给定两个概率分布 $P$ 和 $Q$,找到一种"运输方案",将 $P$ 变换成 $Q$,使得运输成本最小。
1781 年,Gaspard Monge 提出了这个问题,但他的 formulations 太过刚性。1942 年,Leonid Kantorovich 放松了约束,允许将质量"拆分"运输,这才使得这个问题变得可解。
4.2 Wasserstein 距离
Wasserstein 距离(也称为 Earth Mover’s Distance)定义为:
$$ W_p(P, Q) = \left(\inf_{\gamma \in \Gamma(P, Q)} \int d(x, y)^p d\gamma(x, y)\right)^{1/p} $$
其中 $\Gamma(P, Q)$ 是所有边际分布分别为 $P$ 和 $Q$ 的联合分布的集合。
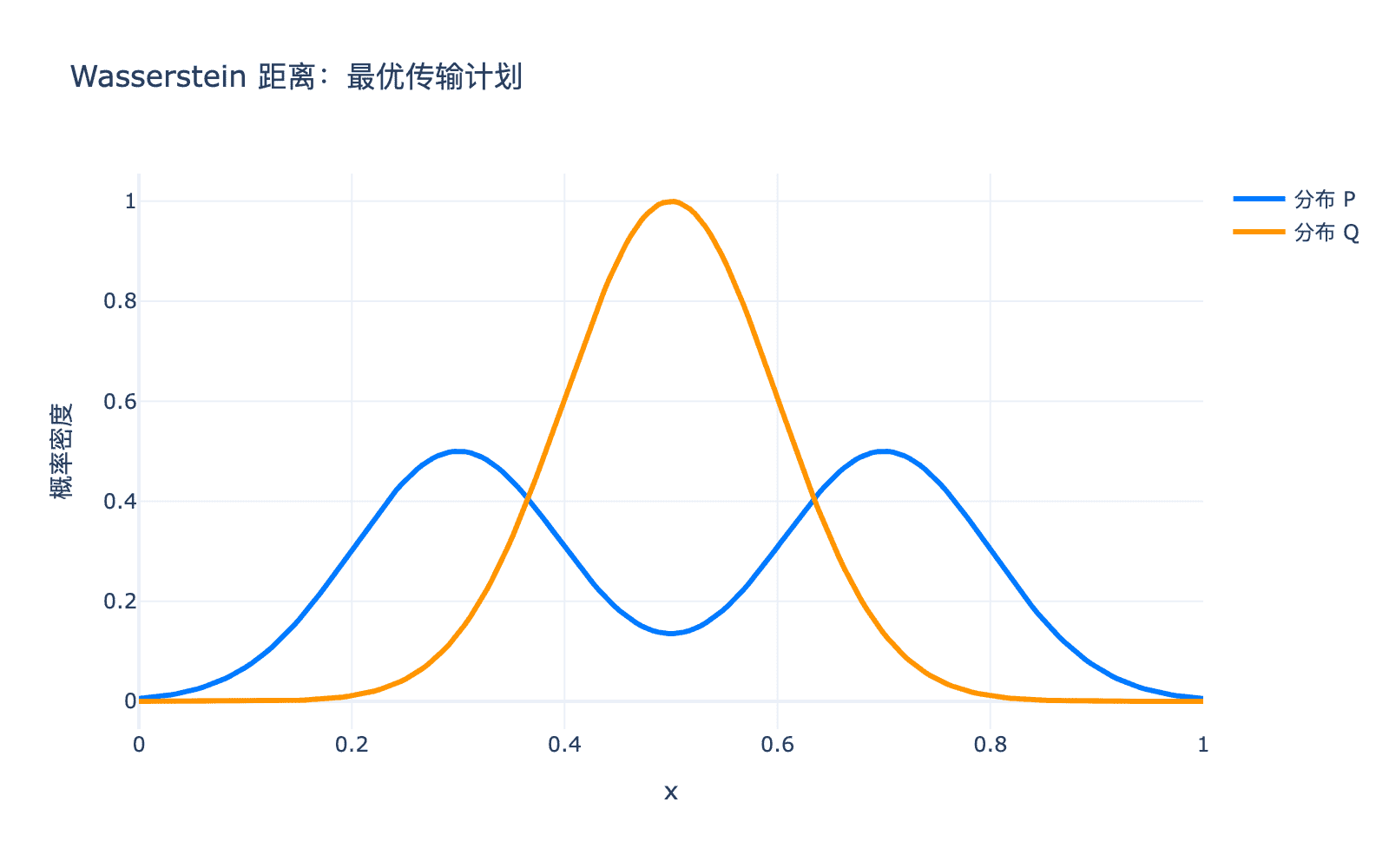
图4:Wasserstein 距离的直观解释。灰色的箭头表示"质量搬运"的计划,箭头的长度表示搬运的距离。目标是找到总成本最小的搬运方案。
4.3 在生成模型中的应用
Wasserstein 距离在生成模型中有重要应用:
- WGAN(Wasserstein GAN):使用 Wasserstein 距离作为损失函数,解决了原始 GAN 的梯度消失问题
- Wasserstein Dropout:通过 Wasserstein 距离正则化 Dropout
- Wasserstein Barycenter:计算多个分布的"平均值"
第五章:信息投影与变分推断
信息几何为变分推断提供了优雅的几何解释。
5.1 信息投影
给定一个复杂的真实分布 $P$,我们想要用一个简单的近似分布族 $Q$ 中的分布来近似它。传统的做法是最小化 KL 散度 $D_{KL}(P | Q)$ 或 $D_{KL}(Q | P)$。
信息几何引入了一种新的视角:信息投影。考虑两个不同的 KL 散度:
- 前向 KL:$D_{KL}(P | Q)$ —— I-投影
- 反向 KL:$D_{KL}(Q | P)$ —— M-投影
这两种投影在几何上有不同的含义。I-投影保持支撑集不变,适合近似多峰分布;M-投影保持模式不变,适合寻找"简单"的近似。
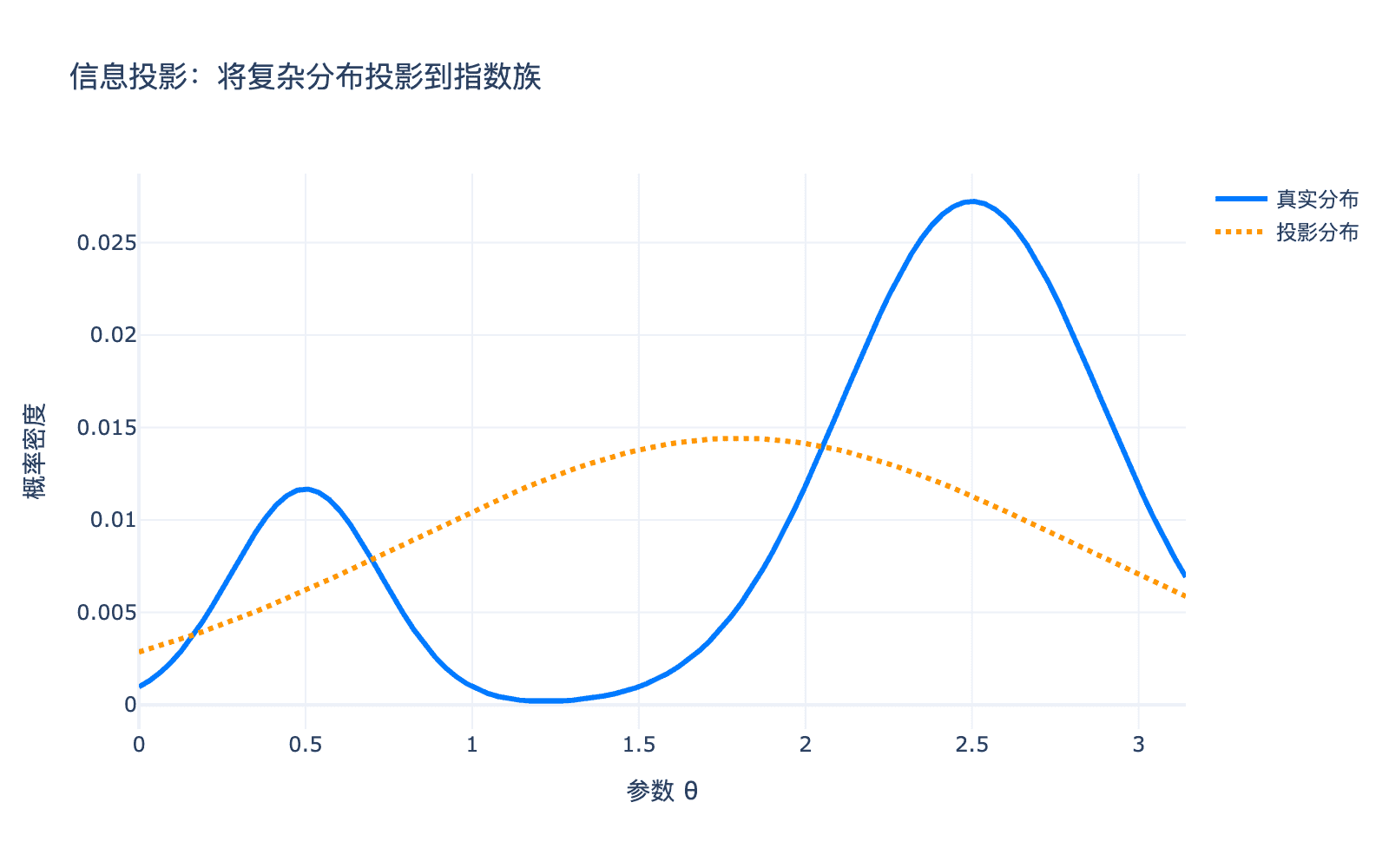
图5:信息投影:将复杂分布(蓝色)投影到指数族(橙色)。注意投影点不是参数空间中的欧几里得投影,而是在 Fisher 信息度量下的投影。
5.2 变分自编码器
VAE 的学习过程可以理解为信息投影:编码器将数据映射到潜在空间,解码器从潜在空间重构数据。ELBO(Evidence Lower BOund)可以解释为自由能的变分近似。
第六章:曲率与神经网络的优化景观
6.1 神经网络的"景观"
神经网络的损失函数曲面是一个非常复杂的高维非凸曲面。信息几何提供了一种工具来分析这个曲面的曲率性质。
Hessian 矩阵与曲率:损失函数的 Hessian 矩阵描述了函数的局部曲率。大的特征值对应于高曲率方向(陡峭的峡谷),小的特征值对应于低曲率方向(平坦的高原)。
6.2 曲率与优化
理解损失函数的曲率有助于设计更好的优化算法:
- 高曲率区域:需要使用较小的学习率,或者使用二阶方法
- 鞍点:高维空间中鞍点比局部最小值更常见,需要特殊的处理策略
- 路径曲率:优化轨迹的曲率可以用来指导学习率的调整
第七章:深度学习中的几何新方向
7.1 几何深度学习
几何深度学习是近年来兴起的领域,它考虑数据的几何结构。
- 图神经网络:数据是图结构,利用图的几何性质进行学习
- 流形学习:假设数据分布在一个低维流形上,试图学习这个流形的结构
- 双曲空间嵌入:利用双曲几何的负曲率性质来建模层级结构
7.2 流形假说再审视
“流形假说"认为真实数据分布在一个低维流形上。信息几何为这个假说提供了严格的数学框架,并提出了新的问题:
- 如何估计数据流形的曲率?
- 如何设计尊重流形几何结构的神经网络?
- 流形的拓扑性质(如贝蒂数)如何影响学习?
7.3 几何正则化
信息几何激发了几何正则化方法:
- 拉普拉斯正则化:要求预测函数在数据流形上平滑变化
- Wasserstein 正则化:保持编码器的雅可比矩阵与正交矩阵接近
- 信息瓶颈:限制信息流,强迫网络学习紧凑的表征
第八章:前沿与展望
8.1 当前挑战
信息几何与深度学习的结合仍面临诸多挑战:
计算复杂性:Fisher 信息矩阵的逆是 $O(n^3)$ 的复杂度,对于深度神经网络来说不可行。当前的近似方法(如 K-FAC、Shampoo)虽然有效,但仍有改进空间。
理论理解:我们对深度网络的损失函数曲率的理解还很有限。为什么随机梯度下降在实践中效果这么好?为什么过参数化的网络不会过拟合?
新型架构:Transformer 等新型架构的几何性质是什么?注意力机制如何改变信息的流动?
8.2 未来方向
几何引导的架构设计:未来的神经网络架构可能会更加注重几何性质。例如,设计具有良好曲率性质的激活函数,或者利用流形结构设计更高效的注意力机制。
量子信息几何:量子力学与信息论的结合产生了量子信息论。量子机器学习中的几何结构是一个前沿方向。
因果推断与几何:因果图可以看作一种特殊的几何结构。将因果推断与信息几何结合,可能产生更强大的推理算法。
生物启发:大脑中的信息处理方式可能遵循某种几何原则。神经科学的发现可能启发新的机器学习算法。
8.3 对几何与深度学习结合的判断
几何方法在深度学习中的重要性将持续增长:
数据理解:几何视角帮助我们理解数据的本质结构,这是设计有效算法的前提
算法设计:自然梯度等几何方法已经在某些任务上显示出超越标准方法的性能
理论保证:几何分析可能为优化算法的收敛性、泛化性能提供理论保证
新兴应用:生成模型、强化学习、因果推断等领域都对几何方法有强烈需求
但同时需要注意:几何方法往往计算复杂度高,需要在理论和实践之间找到平衡。未来的方向可能是设计"几何感知"但计算高效的算法。
结语
在这篇文章中,我们系统性地介绍了信息几何的核心理论,从 Fisher 信息度量到自然梯度,从 Wasserstein 距离到信息投影,最后探讨了与深度学习结合的前沿方向。
信息几何的美在于它将三个看似不相关的领域——统计学、微分几何、信息论——统一在同一个框架下。在这个框架下,概率分布不再是抽象的数学对象,而是流形上的点;优化不再是黑箱算法,而是沿测地线的"自然"运动;两个分布之间的差异不再是单一的数字,而是可以用几何形状来量化的关系。
随着深度学习的发展,几何视角将变得越来越重要。理解数据的几何结构、设计几何感知的算法、分析优化过程的几何性质,这些将是未来研究的重要方向。
希望这篇文章能够帮助读者建立信息几何的整体认识,为更深入的学习和研究打下坚实的基础。
参考文献
- Amari, S. (2016). Information Geometry and Its Applications. Springer.
- Amari, S., & Nagaoka, H. (2000). Methods of Information Geometry. American Mathematical Society.
- Cover, T. M., & Thomas, J. A. (2006). Elements of Information Theory (2nd ed.). Wiley.
- Villani, C. (2009). Optimal Transport: Old and New. Springer.
- Peyré, G., & Cuturi, M. (2019). Computational Optimal Transport. Foundations and Trends in Machine Learning, 11(5-6), 355-607.
- Pascanu, R., et al. (2014). Natural Gradient Descent in Deep Neural Networks. ICML.
- Martens, J. (2020). New Insights and Perspectives on the Natural Gradient Method. Journal of Machine Learning Research, 21, 1-96.