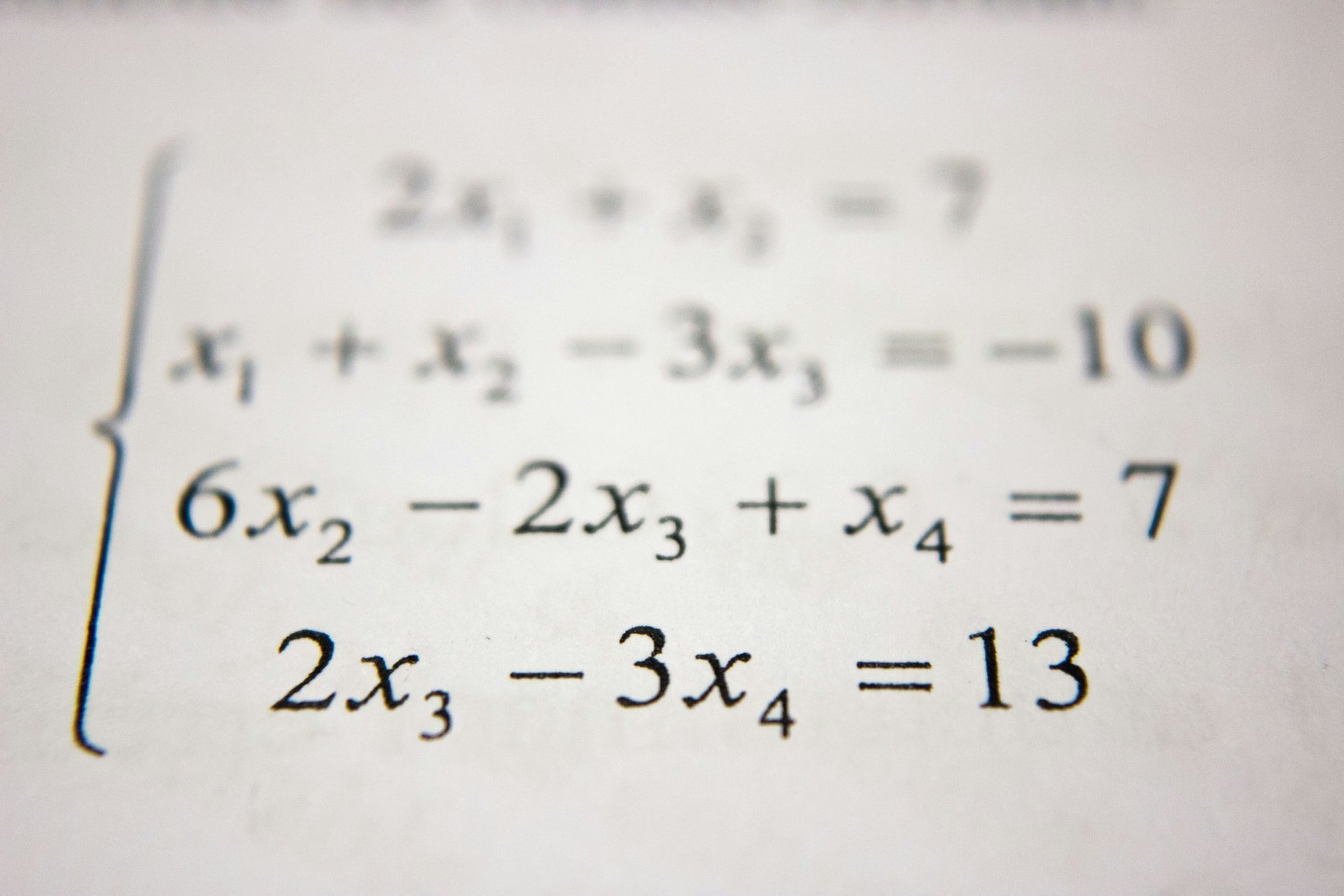
引言:为什么线性代数如此重要?
想象你站在一个开阔的平原上,手中拿着一支箭。这支箭可以指向任何方向,可以伸长或缩短,可以与另一支箭相加。这就是向量的原始概念——一个既有方向又有大小的量。从这样简单的直观出发,人类发展出了一整套描述空间、变换和数据结构的数学语言:线性代数。
线性代数的美妙之处在于它的简洁性和普遍性。在二维平面上,一个点可以用两个坐标 $(x, y)$ 表示;在三维空间中,需要三个坐标 $(x, y, z)$;而在机器学习中处理的数据可能有一千维、一万维,甚至更高。线性代数提供了一套统一的工具来处理这些高维空间,而且它的规律在任意维数下都保持不变。
更令人惊讶的是,当你使用 ChatGPT、看 Netflix 推荐、或在 Google 搜索时,背后都有线性代数的身影。深度学习的神经网络本质上就是一系列线性变换和非线性激活的交替组合;推荐系统中的矩阵分解技术直接源自奇异值分解;而搜索引擎的 PageRank 算法则是特征值问题的经典应用。
在这篇文章中,我们将踏上一段从理论到应用的完整旅程。我们会从向量空间的几何直观出发,理解线性变换的本质,然后逐步深入到机器学习和深度学习的核心算法中。我们不仅会学习"怎么做",更重要的是理解"为什么"——为什么奇异值分解如此强大?为什么梯度下降会收敛?为什么注意力机制能够工作?
让我们开始这段旅程。
第一部分:线性代数基础理论
1. 向量空间的本质
1.1 从几何到抽象
在二维平面上,我们习惯用坐标表示向量。向量 $\mathbf{v} = (3, 2)$ 表示从原点出发,沿 $x$ 轴移动 3 个单位,再沿 $y$ 轴移动 2 个单位。但向量的概念远不止于此。
向量空间的抽象定义只需要 8 条公理:
- 加法封闭性: $\mathbf{u} + \mathbf{v}$ 仍在空间中
- 加法交换律: $\mathbf{u} + \mathbf{v} = \mathbf{v} + \mathbf{u}$
- 加法结合律: $(\mathbf{u} + \mathbf{v}) + \mathbf{w} = \mathbf{u} + (\mathbf{v} + \mathbf{w})$
- 零向量存在: $\mathbf{0} + \mathbf{v} = \mathbf{v}$
- 负向量存在: $\mathbf{v} + (-\mathbf{v}) = \mathbf{0}$
- 数乘封闭性: $c\mathbf{v}$ 仍在空间中
- 数乘分配律: $c(\mathbf{u} + \mathbf{v}) = c\mathbf{u} + c\mathbf{v}$
- 数乘结合律: $c(d\mathbf{v}) = (cd)\mathbf{v}$
这个定义看似抽象,但它统一了各种不同的对象:
- $\mathbb{R}^n$ 中的几何向量
- 多项式 $P_n = {a_0 + a_1x + \cdots + a_nx^n}$
- $m \times n$ 矩阵的集合 $\mathbb{R}^{m \times n}$
- 函数空间 $L^2([a, b])$
1.2 线性相关与线性无关
核心思想:一组向量是线性相关的,如果其中一个向量可以表示为其他向量的线性组合。
考虑二维平面上的两个向量: $$ \mathbf{v}_1 = \begin{pmatrix} 1 \ 0 \end{pmatrix}, \quad \mathbf{v}_2 = \begin{pmatrix} 2 \ 0 \end{pmatrix} $$
显然 $\mathbf{v}_2 = 2\mathbf{v}_1$,所以它们线性相关。几何上,它们指向同一个方向,无法"张成"整个二维平面。
而如果选择: $$ \mathbf{e}_1 = \begin{pmatrix} 1 \ 0 \end{pmatrix}, \quad \mathbf{e}_2 = \begin{pmatrix} 0 \ 1 \end{pmatrix} $$
那么不存在 $c_1, c_2$ 使得 $c_1\mathbf{e}_1 + c_2\mathbf{e}_2 = \mathbf{0}$,除非 $c_1 = c_2 = 0$。这就是线性无关。
线性无关的几何意义:每个向量都贡献了一个"独立的方向",无法用其他向量替代。
1.3 基与维数
基是向量空间中最小的一组线性无关生成元。对于 $\mathbb{R}^3$,标准基是: $$ \mathbf{e}_1 = \begin{pmatrix} 1 \ 0 \ 0 \end{pmatrix}, \quad \mathbf{e}_2 = \begin{pmatrix} 0 \ 1 \ 0 \end{pmatrix}, \quad \mathbf{e}_3 = \begin{pmatrix} 0 \ 0 \ 1 \end{pmatrix} $$
任意向量 $\mathbf{v} = (v_1, v_2, v_3)^\top$ 都可以唯一表示为: $$ \mathbf{v} = v_1\mathbf{e}_1 + v_2\mathbf{e}_2 + v_3\mathbf{e}_3 $$
维数就是基中向量的个数。这是一个内蕴性质,不依赖于坐标系的选择。无论你用直角坐标、极坐标还是斜坐标,三维空间永远是三维的。
2. 线性变换的几何意义
2.1 矩阵即变换
理解线性变换的关键是:矩阵不仅仅是数字的阵列,它是对空间的一种操作。
考虑 $2 \times 2$ 矩阵: $$ A = \begin{pmatrix} 2 & 0 \ 0 & 1 \end{pmatrix} $$
当它作用于向量 $\mathbf{x} = (x, y)^\top$ 时: $$ A\mathbf{x} = \begin{pmatrix} 2 & 0 \ 0 & 1 \end{pmatrix} \begin{pmatrix} x \ y \end{pmatrix} = \begin{pmatrix} 2x \ y \end{pmatrix} $$
这个变换将 $x$ 方向拉伸 2 倍,而 $y$ 方向保持不变。这就是拉伸变换。
再来看旋转矩阵: $$ R_\theta = \begin{pmatrix} \cos\theta & -\sin\theta \ \sin\theta & \cos\theta \end{pmatrix} $$
当 $\theta = 90^\circ$ 时: $$ R_{90^\circ} = \begin{pmatrix} 0 & -1 \ 1 & 0 \end{pmatrix} $$
它将 $(1, 0)^\top$ 变为 $(0, 1)^\top$,将 $(0, 1)^\top$ 变为 $(-1, 0)^\top$,实现了逆时针旋转 90 度。
关键洞察:矩阵的列向量就是基向量变换后的位置。对于 $A = [\mathbf{a}_1, \mathbf{a}_2]$,$\mathbf{a}_1$ 就是 $\mathbf{e}_1$ 变换后的位置, $\mathbf{a}_2$ 是 $\mathbf{e}_2$ 变换后的位置。
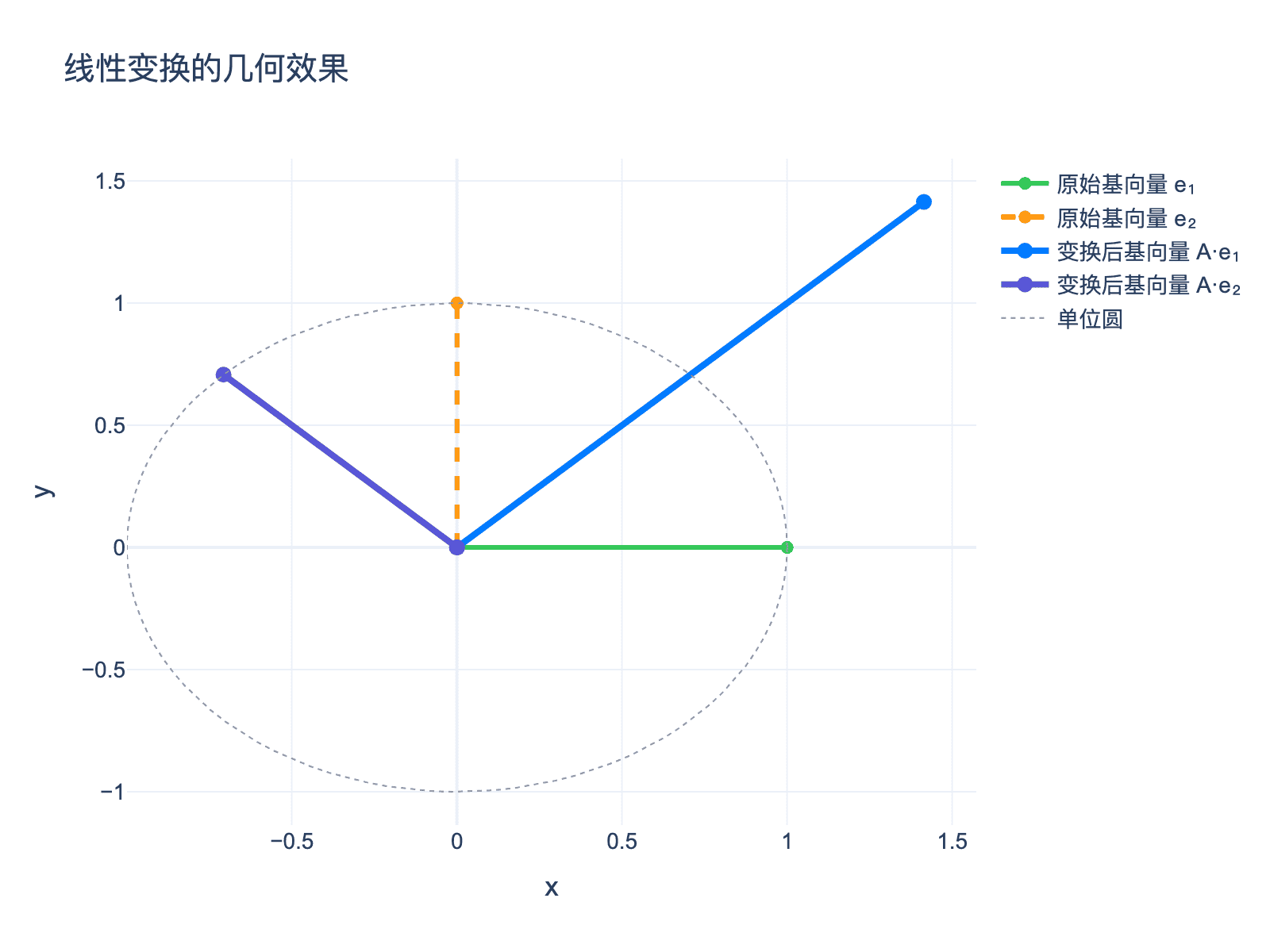
图1:矩阵作为线性变换,展示了基向量的变换效果。蓝色和绿色是原始基向量,紫色和深蓝色是变换后的基向量。
2.2 特征值与特征向量
核心问题:对于一个线性变换 $A$,是否存在某些方向,使得变换后只改变长度,不改变方向?
数学上,我们寻找满足: $$ A\mathbf{v} = \lambda\mathbf{v} $$
的非零向量 $\mathbf{v}$ 和标量 $\lambda$。这样的 $\mathbf{v}$ 称为特征向量,$\lambda$ 称为特征值。
物理意义:
- $|\lambda| > 1$: 沿该方向拉伸
- $|\lambda| < 1$: 沿该方向压缩
- $\lambda < 0$: 沿该方向翻转
- $\lambda = 0$: 将该方向压扁为零
计算方法:特征方程 $$ \det(A - \lambda I) = 0 $$
对于 $2 \times 2$ 矩阵: $$ A = \begin{pmatrix} a & b \ c & d \end{pmatrix} $$
特征方程为: $$ \begin{vmatrix} a-\lambda & b \ c & d-\lambda \end{vmatrix} = (a-\lambda)(d-\lambda) - bc = 0 $$
展开得到: $$ \lambda^2 - (a+d)\lambda + (ad-bc) = 0 $$
其中 $a+d = \operatorname{tr}(A)$ 是迹,$ad-bc = \det(A)$ 是行列式。
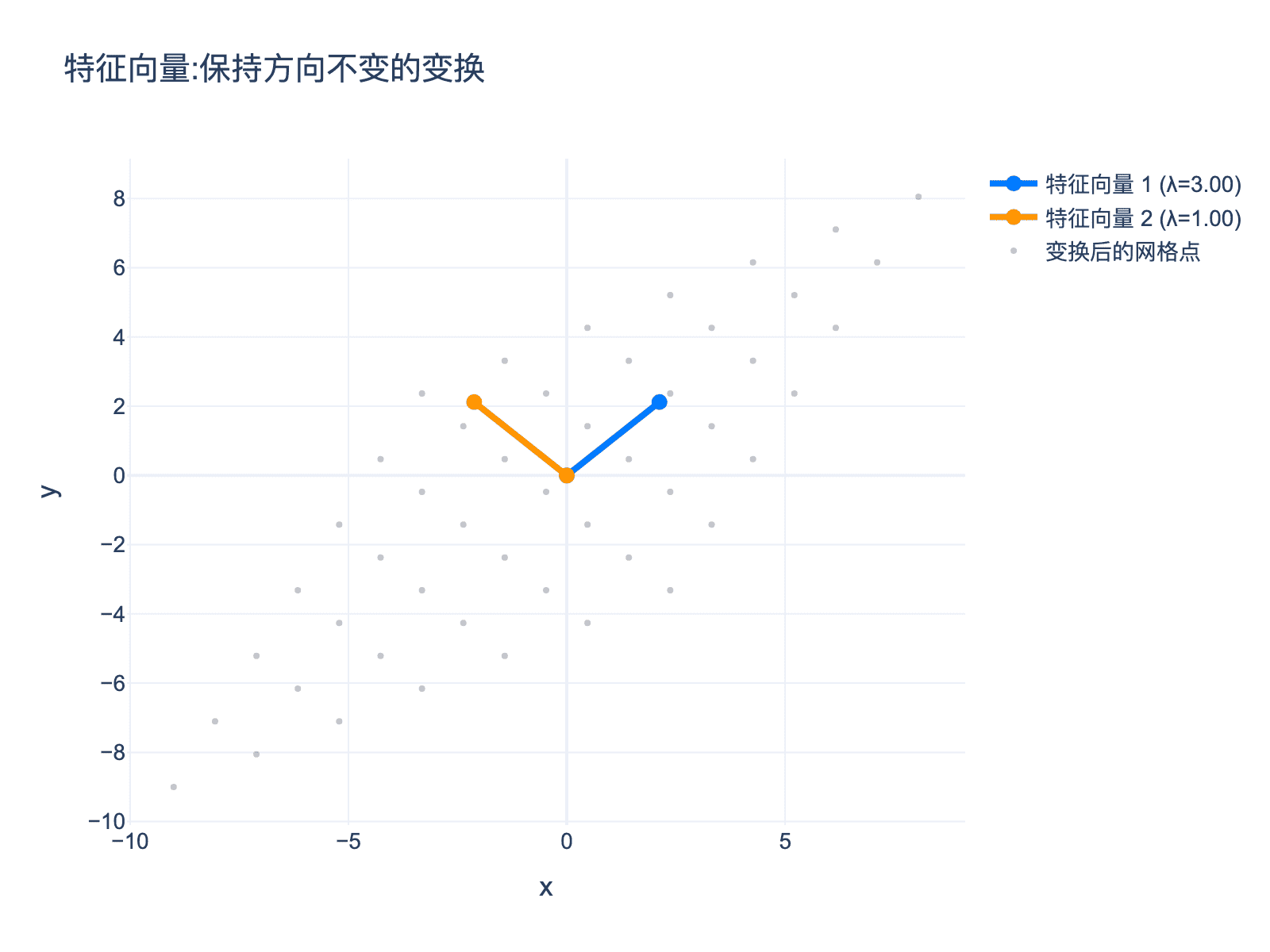
图2:特征向量是保持方向不变的变换方向。图中展示了变换前后的网格点以及特征向量(蓝色和橙色箭头)。
几何应用:如果一个 $3 \times 3$ 矩阵有三个线性无关的特征向量,那么我们可以沿这些特征向量的方向理解变换。例如,应力张量的特征向量表示主应力方向。
2.3 对角化与相似变换
对角化是将矩阵分解为: $$ A = P \Lambda P^{-1} $$
其中 $\Lambda$ 是对角矩阵(对角线上是特征值),$P$ 的列向量是对应的特征向量。
为什么对角化有用?
计算矩阵幂: $$ A^k = P \Lambda^k P^{-1} = P \begin{pmatrix} \lambda_1^k & & \ & \ddots & \ & & \lambda_n^k \end{pmatrix} P^{-1} $$
这在计算 Markov 链的长期行为时至关重要。
解微分方程: 对于 $\frac{d\mathbf{x}}{dt} = A\mathbf{x}$,令 $\mathbf{x} = P\mathbf{y}$,则: $$ \frac{d\mathbf{y}}{dt} = \Lambda \mathbf{y} \implies y_i(t) = y_i(0) e^{\lambda_i t} $$
理解系统演化: 特征值决定稳定性:
- $\operatorname{Re}(\lambda_i) < 0$: 衰减
- $\operatorname{Re}(\lambda_i) > 0$: 增长(不稳定)
相似变换的几何意义: $B = P^{-1}AP$ 表示在另一个坐标系下看同一个变换。如果 $P$ 由特征向量组成,那么在这个坐标系下,变换矩阵是对角的——每个方向独立演化。
3. 内积空间与正交性
3.1 内积的双重性
内积 $\langle \mathbf{u}, \mathbf{v} \rangle$ 有两个等价定义:
代数定义(标准内积): $$ \langle \mathbf{u}, \mathbf{v} \rangle = \mathbf{u}^T \mathbf{v} = \sum_{i=1}^n u_i v_i $$
几何定义: $$ \langle \mathbf{u}, \mathbf{v} \rangle = |\mathbf{u}| |\mathbf{v}| \cos\theta $$
其中 $\theta$ 是两向量夹角。这个等式给出了余弦定理: $$ \cos\theta = \frac{\langle \mathbf{u}, \mathbf{v} \rangle}{|\mathbf{u}| |\mathbf{v}|} $$
关键应用:
- $\cos\theta = 0 \iff \langle \mathbf{u}, \mathbf{v} \rangle = 0$: 正交
- $\cos\theta = 1 \iff \mathbf{u} = c\mathbf{v}, c > 0$: 同向
- $\cos\theta = -1 \iff \mathbf{u} = c\mathbf{v}, c < 0$: 反向
在自然语言处理中,词向量的夹角余弦用于衡量语义相似度。
3.2 正交投影与最小二乘法
投影问题:给定向量 $\mathbf{b}$ 和子空间 $W$,找到 $\mathbf{b}$ 在 $W$ 上的投影 $\mathbf{p}$。
几何直觉:
- $\mathbf{p} \in W$
- 误差 $\mathbf{e} = \mathbf{b} - \mathbf{p}$ 与 $W$ 正交
代数推导:
设 $W$ 由 $\mathbf{a}_1, \ldots, \mathbf{a}_n$ 张成,记 $A = [\mathbf{a}_1, \ldots, \mathbf{a}_n]$。投影为: $$ \mathbf{p} = A\hat{\mathbf{x}} $$
正交条件: $A^ op(\mathbf{b} - A\hat{\mathbf{x}}) = \mathbf{0}$,因此: $$ A^ op A \hat{\mathbf{x}} = A^ op \mathbf{b} $$
这就是正规方程(Normal Equation)。
最小二乘法:当 $A\mathbf{x} = \mathbf{b}$ 无解时(超定方程组),我们寻找使 $|\mathbf{b} - A\mathbf{x}|^2$ 最小的 $\hat{\mathbf{x}}$。这个最小解恰好满足正规方程。
投影矩阵: $$ P = A(A^ op A)^{-1} A^ op $$
它将任意向量投影到 $A$ 的列空间。性质:
- $P^2 = P$(幂等)
- $P^T = P$(对称)
3.3 Gram-Schmidt 正交化
目标:从一组线性无关向量 ${\mathbf{v}_1, \ldots, \mathbf{v}_n}$ 构造标准正交基 ${\mathbf{q}_1, \ldots, \mathbf{q}_n}$。
算法:
$\mathbf{u}_1 = \mathbf{v}_1$, $\mathbf{q}_1 = \frac{\mathbf{u}_1}{|\mathbf{u}_1|}$
$\mathbf{u}_2 = \mathbf{v}_2 - \langle \mathbf{v}_2, \mathbf{q}_1 \rangle \mathbf{q}_1$, $\mathbf{q}_2 = \frac{\mathbf{u}_2}{|\mathbf{u}_2|}$
一般地: $$ \mathbf{u}_k = \mathbf{v}k - \sum{i=1}^{k-1} \langle \mathbf{v}_k, \mathbf{q}_i \rangle \mathbf{q}_i $$
几何解释:每次减去已构造方向的投影,确保新方向与之前所有方向正交。
矩阵分解: $A = QR$,其中 $Q$ 是正交矩阵($Q^T Q = I$),$R$ 是上三角矩阵。这在数值计算中非常稳定。
4. 奇异值分解(SVD)
4.1 SVD 的几何直观
奇异值分解定理:任意 $m \times n$ 矩阵 $A$ 都可以分解为: $$ A = U \Sigma V^ op $$
其中:
- $U$ 是 $m \times m$ 正交矩阵($U^T U = I_m$)
- $V$ 是 $n \times n$ 正交矩阵($V^ op V = I_n$)
- $\Sigma$ 是 $m \times n$ 对角矩阵,对角线元素 $\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r > 0$ 是奇异值
几何意义:任何线性变换都可以分解为三个步骤:
- 旋转/反射($V^ op$)
- 沿坐标轴拉伸/压缩($\Sigma$)
- 再旋转/反射($U$)
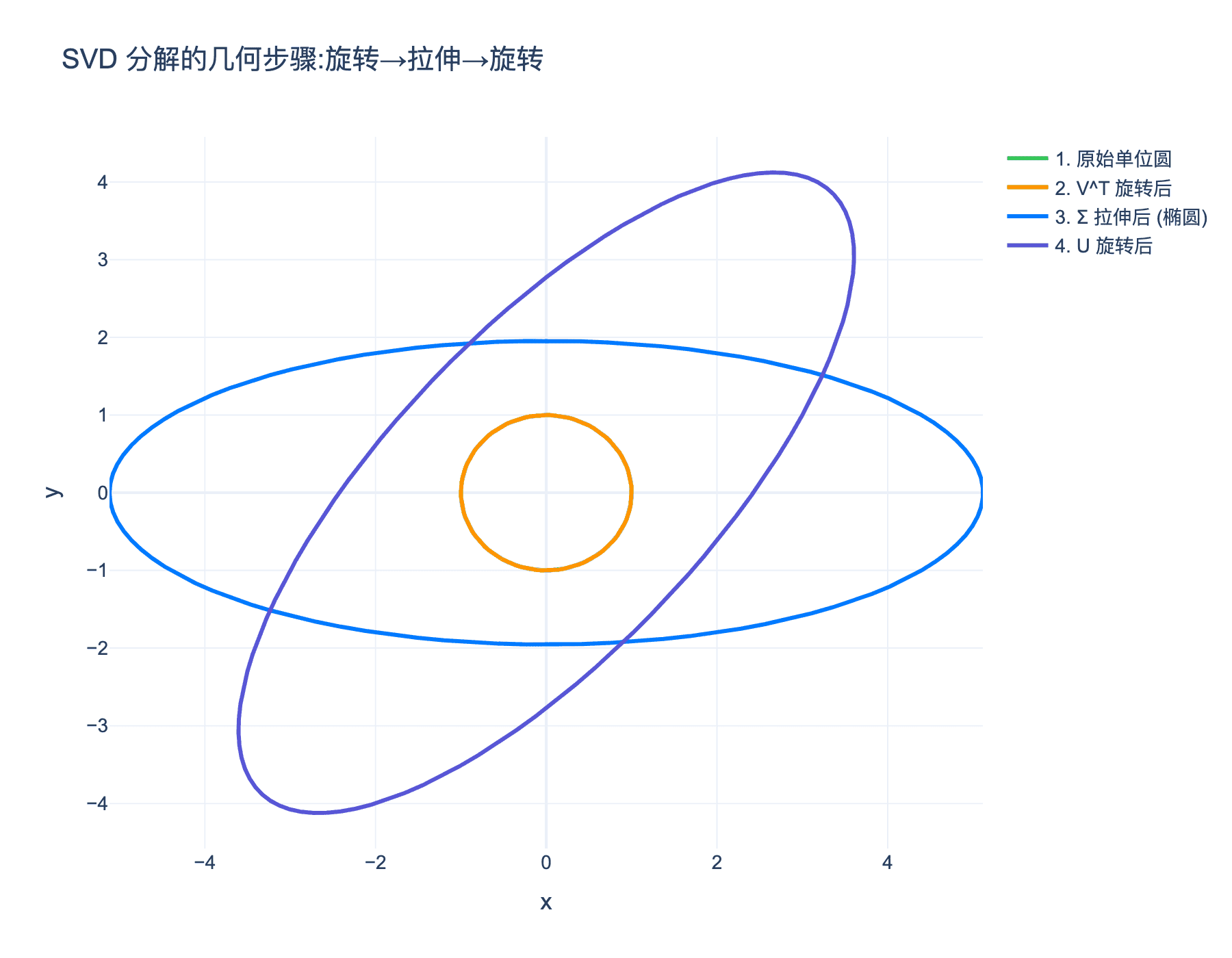
图3:奇异值分解的几何步骤:原始单位圆(绿色)→ 旋转(橙色)→ 拉伸成椭圆(蓝色)→ 再旋转(紫色)。
与特征值分解的关系:
- 对于方阵 $A$,奇异值是特征值的平方根: $\sigma_i = \sqrt{\lambda_i(A^ op A)}$
- 特征值分解要求矩阵可对角化,SVD 对任意矩阵都成立
- SVD 给出两个正交基(输入和输出空间),而特征值分解只给一个
4.2 为什么 SVD 是"瑞士军刀"?
应用 1:低秩近似
取前 $k$ 个奇异值: $$ A_k = \sum_{i=1}^k \sigma_i \mathbf{u}_i \mathbf{v}_i^T $$
这在 Frobenius 范数下是最优的 $k$ 秩近似。图像压缩、推荐系统都基于此。
Eckart-Young 定理: $$ |A - A_k|F = \sqrt{\sum{i=k+1}^r \sigma_i^2} = \min_{\operatorname{rank}(B)=k} |A - B|_F $$
应用 2:伪逆
对于 $A$ 的 Moore-Penrose 伪逆: $$ A^+ = V \Sigma^+ U^T $$
其中 $\Sigma^+$ 将 $\Sigma$ 的非零对角元取倒数后转置。最小二乘解为: $$ \hat{\mathbf{x}} = A^+ \mathbf{b} $$
应用 3:条件数
$$ \kappa(A) = \frac{\sigma_{\max}}{\sigma_{\min}} $$
条件数衡量矩阵对扰动的敏感度。$\kappa(A)$ 大说明病态问题,小误差会被放大。
4.3 SVD 的计算推导
核心思想: $A^ op A$ 和 $AA^ op$ 是对称半正定矩阵,必可对角化。
推导步骤:
$A^ op A = (V \Sigma^T U^T)(U \Sigma V^ op) = V \Sigma^T \Sigma V^ op$
这说明 $V$ 的列向量是 $A^ op A$ 的特征向量。
$AA^ op = (U \Sigma V^ op)(V \Sigma^T U^T) = U \Sigma \Sigma^T U^T$
这说明 $U$ 的列向量是 $AA^ op$ 的特征向量。
$\Sigma^T \Sigma$ 和 $\Sigma \Sigma^T$ 的对角元都是 $\sigma_i^2$。
数值稳定性:实际计算时,先对 $A^ op A$ 做 QR 分解,避免显式构造 $A^ op A$ 以减少误差。
第二部分:机器学习中的线性代数
1. 最小二乘法与回归
1.1 问题设定
给定 $n$ 个样本 $(\mathbf{x}_i, y_i)$,其中 $\mathbf{x}_i \in \mathbb{R}^d$, $y_i \in \mathbb{R}$。线性模型: $$ y = \mathbf{w}^T \mathbf{x} + b $$
令 $\tilde{\mathbf{x}} = (1, \mathbf{x}^\top)^\top$,$\tilde{\mathbf{w}} = (b, \mathbf{w}^\top)^\top$,则: $$ y = \tilde{\mathbf{w}}^T \tilde{\mathbf{x}} $$
写成矩阵形式: $$ \mathbf{y} = X \mathbf{w} $$
其中 $X \in \mathbb{R}^{n \times (d+1)}$ 是设计矩阵。
1.2 正规方程推导
目标:最小化平方误差: $$ J(\mathbf{w}) = |\mathbf{y} - X\mathbf{w}|^2 = (\mathbf{y} - X\mathbf{w})^\top(\mathbf{y} - X\mathbf{w}) $$
展开: $$ J(\mathbf{w}) = \mathbf{y}^T\mathbf{y} - 2\mathbf{w}^T X^ op \mathbf{y} + \mathbf{w}^T X^ op X \mathbf{w} $$
求导: $$ \frac{\partial J}{\partial \mathbf{w}} = -2 X^ op \mathbf{y} + 2 X^ op X \mathbf{w} $$
令导数为零: $$ X^ op X \mathbf{w} = X^ op \mathbf{y} $$
这就是正规方程,解为: $$ \mathbf{w}^* = (X^ op X)^{-1} X^ op \mathbf{y} $$
几何解释: $X\mathbf{w}$ 是 $X$ 列空间中的向量,正规方程确保 $\mathbf{y} - X\mathbf{w}$ 与列空间正交。
1.3 岭回归与几何意义
问题:当 $X^ op X$ 接近奇异时,解不稳定。岭回归加入 $L_2$ 正则: $$ J(\mathbf{w}) = |\mathbf{y} - X\mathbf{w}|^2 + \lambda |\mathbf{w}|^2 $$
推导得到: $$ \mathbf{w}^* = (X^ op X + \lambda I)^{-1} X^ op \mathbf{y} $$
几何意义: $\lambda I$ 确保矩阵正定,等价于:
- 限制解的范数
- 从贝叶斯角度,等价于高斯先验
核回归:通过特征映射 $\phi(\mathbf{x})$,将线性模型扩展到非线性: $$ y = \mathbf{w}^T \phi(\mathbf{x}) $$
使用核技巧,只需计算 $K(\mathbf{x}_i, \mathbf{x}_j) = \langle \phi(\mathbf{x}_i), \phi(\mathbf{x}_j) \rangle$。
2. 主成分分析(PCA)
2.1 方差最大化视角
目标:找到投影方向 $\mathbf{u}$($|\mathbf{u}| = 1$),使投影后方差最大。
给定中心化数据 $X \in \mathbb{R}^{n \times d}$,投影为: $$ \mathbf{z} = X \mathbf{u} $$
方差为: $$ \operatorname{Var}(\mathbf{z}) = \frac{1}{n} \mathbf{u}^T X^ op X \mathbf{u} = \mathbf{u}^T \Sigma \mathbf{u} $$
其中 $\Sigma = \frac{1}{n} X^ op X$ 是协方差矩阵。
优化问题: $$ \max_{\mathbf{u}} \mathbf{u}^T \Sigma \mathbf{u} \quad \text{s.t.} \quad |\mathbf{u}| = 1 $$
使用拉格朗日乘子: $$ \mathcal{L}(\mathbf{u}, \lambda) = \mathbf{u}^T \Sigma \mathbf{u} - \lambda(\mathbf{u}^T \mathbf{u} - 1) $$
求导: $$ 2 \Sigma \mathbf{u} - 2 \lambda \mathbf{u} = 0 \implies \Sigma \mathbf{u} = \lambda \mathbf{u} $$
这说明 $\mathbf{u}$ 是 $\Sigma$ 的特征向量,$\lambda$ 是特征值。目标函数值为: $$ \mathbf{u}^T \Sigma \mathbf{u} = \mathbf{u}^T \lambda \mathbf{u} = \lambda |\mathbf{u}|^2 = \lambda $$
结论:第一主方向是最大特征值对应的特征向量,方差为该特征值。
2.2 SVD 视角下的 PCA
对数据中心化后做 SVD: $$ X = U \Sigma V^ op $$
主成分方向是 $V$ 的列向量,主成分得分是 $U \Sigma$。
优势:
- 避免显式计算协方差矩阵(数值更稳定)
- 同时得到方向、得分、方差
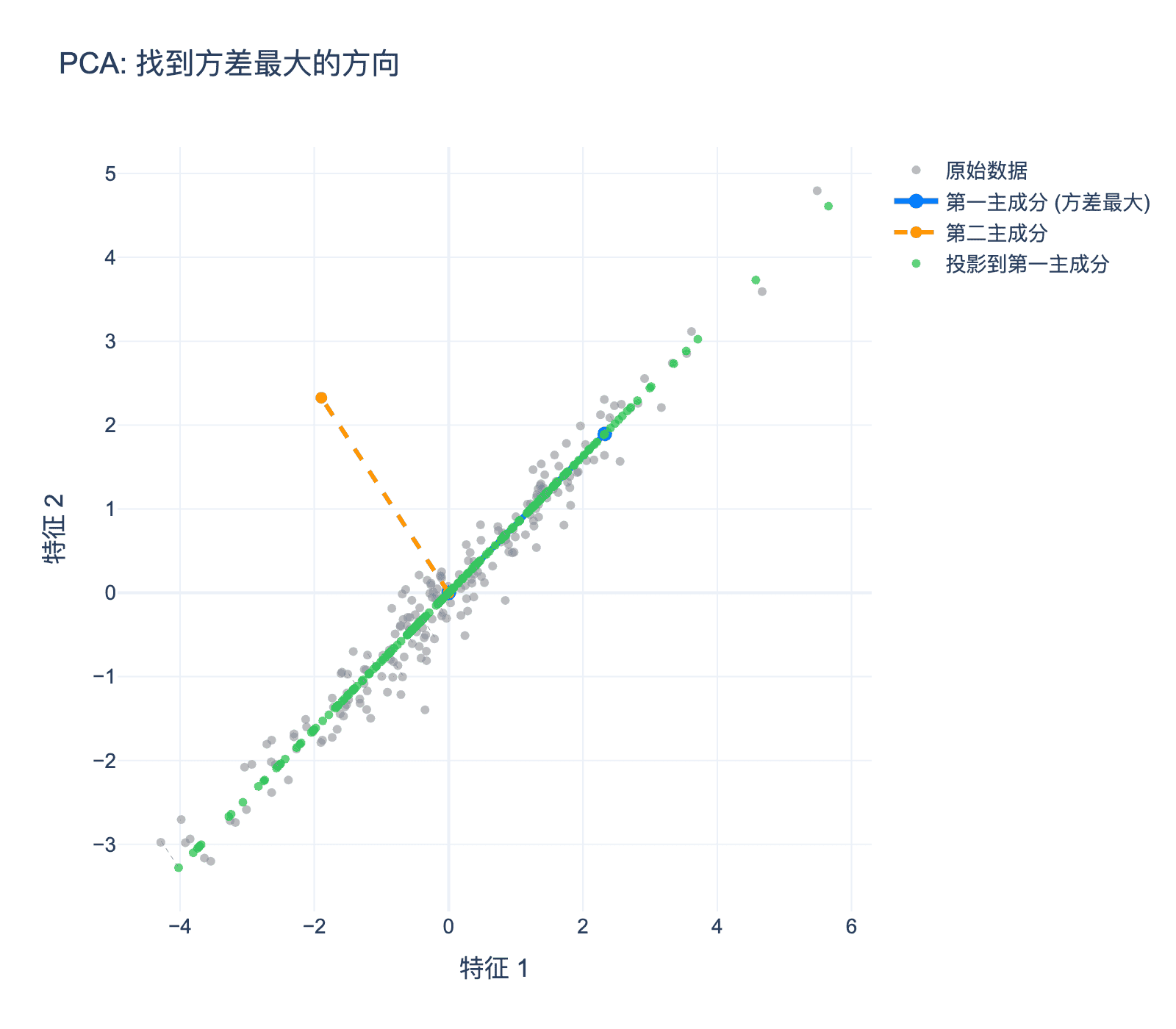
图4:主成分分析找到方差最大的投影方向。灰色点是原始数据,蓝色箭头是第一主成分(方差最大),橙色箭头是第二主成分,绿色点是投影到第一主成分的结果。
降维:保留前 $k$ 个主成分: $$ X \approx U_k \Sigma_k V_k^T $$
低维表示: $Z = X V_k = U_k \Sigma_k$
2.3 数据去相关
原始数据的协方差矩阵 $\Sigma$ 一般不是对角的。PCA 后: $$ \operatorname{Cov}(Z) = \operatorname{Cov}(X V) = V^ op \operatorname{Cov}(X) V = V^ op \Sigma V = \Lambda $$
其中 $\Lambda$ 是对角矩阵,说明主成分之间不相关。
应用:
- 降维可视化(t-SNE 的预处理)
- 去噪(保留大方差成分)
- 特征提取(图像识别)
3. 特征值问题的应用
3.1 PageRank 算法
核心思想:网页的重要性取决于指向它的其他网页的重要性。
数学模型:网页的 PageRank 值是转移矩阵 $M$ 的平稳分布: $$ \mathbf{p} = M \mathbf{p} $$
其中:
- $p_i$ 是网页 $i$ 的 PageRank
- $M_{ij} = \frac{1}{d_j}$ 如果网页 $j$ 链接到 $i$($d_j$ 是 $j$ 的出度)
这本质上是求特征值 1 对应的特征向量。
问题: $M$ 可能不可约,没有唯一平稳分布。Google 使用: $$ G = \alpha M + (1-\alpha) \frac{1}{n}\mathbf{1}\mathbf{1}^T $$
其中 $\alpha \approx 0.85$。 $G$ 是随机矩阵,由 Perron-Frobenius 定理,存在唯一正特征向量。
幂法迭代: $$ \mathbf{p}^{(t+1)} = G \mathbf{p}^{(t)} $$
收敛到最大特征值对应的特征向量。
3.2 谱聚类
目标:将图划分为若干社区,使得社区内连接紧密,社区间连接稀疏。
拉普拉斯矩阵: $$ L = D - A $$
其中 $D$ 是度矩阵($D_{ii} = \sum_j A_{ij}$),$A$ 是邻接矩阵。
性质:
- $L$ 是对称半正定矩阵
- 特征值 $0 = \lambda_1 \leq \lambda_2 \leq \cdots \leq \lambda_n$
- $\lambda_2$ 称为代数连通度(algebraic connectivity)
谱聚类算法:
- 计算拉普拉斯矩阵 $L$ 的前 $k$ 个小特征值对应的特征向量 $\mathbf{u}_1, \ldots, \mathbf{u}_k$
- 构造矩阵 $U \in \mathbb{R}^{n \times k}$
- 在 $\mathbb{R}^k$ 中对 $U$ 的行做 k-means 聚类
几何直觉:特征向量给出了节点在低维空间中的嵌入,相似节点距离近。
3.3 图神经网络
消息传递: $$ \mathbf{h}v^{(t+1)} = \sigma\left(\sum{u \in \mathcal{N}(v)} W^{(t)} \mathbf{h}_u^{(t)}\right) $$
写成矩阵形式: $$ H^{(t+1)} = \sigma(A H^{(t)} W^{(t)}) $$
其中 $A$ 是邻接矩阵(可能加上自环和归一化)。
谱图卷积:通过图傅里叶变换定义卷积: $$ \hat{f} = U^T f, \quad g * f = U (U^T g \odot U^T f) $$
其中 $U$ 是拉普拉斯矩阵的特征向量矩阵。
第三部分:深度学习中的线性代数
1. 前向传播的线性代数
1.1 矩阵乘法的计算效率
全连接层: $$ \mathbf{y} = \sigma(W \mathbf{x} + \mathbf{b}) $$
对于批量数据 $X \in \mathbb{R}^{n \times d_{\text{in}}}$: $$ Z = X W^ op + \mathbf{b} = \begin{pmatrix} \mathbf{x}_1^T \ \vdots \ \mathbf{x}n^T \end{pmatrix} \begin{pmatrix} \mathbf{w}1 & \cdots & \mathbf{w}{d{\text{out}}} \end{pmatrix} + \mathbf{1}\mathbf{b}^T $$
计算复杂度: $O(n \cdot d_{\text{in}} \cdot d_{\text{out}})$
内存布局:现代深度学习框架使用列主序存储,利用缓存局部性加速。
1.2 批量处理的向量化
向量化 vs. 循环:
不高效:
for i in range(batch_size):
for j in range(output_dim):
z[i, j] = np.dot(x[i], w[j]) + b[j]
高效:
Z = X @ W.T + b # 利用 BLAS 优化
GPU 加速:GPU 有数千个核心,适合并行执行大量小运算。矩阵乘法可以分解为:
- 线程块处理子矩阵
- 线程内处理标量运算
- 共享内存减少全局内存访问
1.3 广播机制的数学本质
广播规则:
- 对齐尾部维度
- 维度为 1 时复制
- 缺失维度视为 1
例子: $$ X \in \mathbb{R}^{n \times d}, \quad \mathbf{b} \in \mathbb{R}^d $$
$$ X + \mathbf{b} = X + \mathbf{1}_{n \times 1} \mathbf{b}^T $$
张量广播: $$ X \in \mathbb{R}^{n \times d_1 \times d_2}, \quad \mathbf{b} \in \mathbb{R}^{d_2} $$
$$ X + \mathbf{b} = X + \mathbf{1}{n \times d_1 \times 1} \times \mathbf{b}{1 \times 1 \times d_2} $$
广播本质上是外积的特殊情况。
2. 反向传播与梯度计算
2.1 链式法则的矩阵形式
标量情况: $$ \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial x} $$
向量情况: $$ \frac{\partial L}{\partial \mathbf{x}} = \left(\frac{\partial \mathbf{y}}{\partial \mathbf{x}}\right)^ op \frac{\partial L}{\partial \mathbf{y}} $$
其中 $\frac{\partial \mathbf{y}}{\partial \mathbf{x}}$ 是 Jacobian 矩阵: $$ J_{ij} = \frac{\partial y_i}{\partial x_j} $$
全连接层: $$ \mathbf{z} = W \mathbf{x} + \mathbf{b}, \quad \mathbf{y} = \sigma(\mathbf{z}) $$
梯度计算: $$ \frac{\partial L}{\partial \mathbf{z}} = \frac{\partial L}{\partial \mathbf{y}} \odot \sigma’(\mathbf{z}) $$
$$ \frac{\partial L}{\partial W} = \frac{\partial L}{\partial \mathbf{z}} \mathbf{x}^T $$
$$ \frac{\partial L}{\partial \mathbf{b}} = \frac{\partial L}{\partial \mathbf{z}} $$
$$ \frac{\partial L}{\partial \mathbf{x}} = W^ op \frac{\partial L}{\partial \mathbf{z}} $$
2.2 Jacobian 矩阵的计算
定义:对于 $f: \mathbb{R}^n \to \mathbb{R}^m$, Jacobian 矩阵为: $$ J_f(\mathbf{x}) = \begin{pmatrix} \frac{\partial f_1}{\partial x_1} & \cdots & \frac{\partial f_1}{\partial x_n} \ \vdots & \ddots & \vdots \ \frac{\partial f_m}{\partial x_1} & \cdots & \frac{\partial f_m}{\partial x_n} \end{pmatrix} $$
链式法则: $$ J_{g \circ f}(\mathbf{x}) = J_g(f(\mathbf{x})) \cdot J_f(\mathbf{x}) $$
自动微分:
- 前向模式:计算 $J \mathbf{v}$(适合 $n \ll m$)
- 反向模式:计算 $J^T \mathbf{v}$(适合 $m \ll n$,即损失函数是标量)
深度学习使用反向模式,因为 $L$ 是标量。
2.3 梯度消失/爆炸的线性代数视角
简化模型:考虑 $t$ 层线性网络(忽略激活): $$ \mathbf{h}^{(t)} = W^{(t)} \mathbf{h}^{(t-1)} $$
输出对输入的梯度: $$ \frac{\partial L}{\partial \mathbf{h}^{(0)}} = (W^{(t)})^ op \cdots (W^{(1)})^ op \frac{\partial L}{\partial \mathbf{h}^{(t)}} $$
谱分析:令 $\sigma_{\max}^{(i)}$ 为 $W^{(i)}$ 的最大奇异值。梯度范数为: $$ \left|\frac{\partial L}{\partial \mathbf{h}^{(0)}}\right| \approx \left(\prod_{i=1}^t \sigma_{\max}^{(i)}\right) \left|\frac{\partial L}{\partial \mathbf{h}^{(t)}}\right| $$
- 如果 $\sigma_{\max}^{(i)} > 1$: 梯度爆炸
- 如果 $\sigma_{\max}^{(i)} < 1$: 梯度消失
Xavier 初始化: $$ W_{ij} \sim \mathcal{N}\left(0, \frac{2}{n_{\text{in}} + n_{\text{out}}}\right) $$
保持前向和反向激活的方差稳定。
3. 正则化的几何意义
3.1 L2 正则与欧氏空间投影
目标函数: $$ J(\mathbf{w}) = |\mathbf{y} - X\mathbf{w}|^2 + \lambda |\mathbf{w}|^2 $$
等价约束优化: $$ \min_{\mathbf{w}} |\mathbf{y} - X\mathbf{w}|^2 \quad \text{s.t.} \quad |\mathbf{w}|^2 \leq C $$
几何解释:
- 无约束解 $\mathbf{w}_{\text{LS}} = (X^ op X)^{-1} X^ op \mathbf{y}$
- L2 正则解向原点收缩
- 等价于高斯先验: $\mathbf{w} \sim \mathcal{N}(0, \lambda^{-1} I)$
贝叶斯解释: $$ \text{MAP} = \arg\max_{\mathbf{w}} \log P(\mathbf{y}|X, \mathbf{w}) + \log P(\mathbf{w}) $$
高斯似然 + 高斯先验 = 最小二乘 + L2 正则
3.2 L1 正则与稀疏性
目标函数: $$ J(\mathbf{w}) = |\mathbf{y} - X\mathbf{w}|^2 + \lambda |\mathbf{w}|_1 $$
几何: L1 球是"菱形",角点在坐标轴上。优化倾向于解落在角点,导致某些坐标为零。
次梯度: L1 不可导,使用次梯度: $$ \partial |w_i| = \begin{cases} {1} & w_i > 0 \ {-1} & w_i < 0 \ [-1, 1] & w_i = 0 \end{cases} $$
软阈值算子(ISTA): $$ w_i \leftarrow \operatorname{sign}(w_i) \max(|w_i| - \lambda, 0) $$
应用:特征选择、压缩感知、稀疏编码。
3.3 Dropout 的线性代数解释
训练时: $$ \mathbf{h} = \mathbf{m} \odot \sigma(W \mathbf{x}) $$
其中 $\mathbf{m} \sim \operatorname{Bernoulli}(p)$。
期望: $$ \mathbb{E}[\mathbf{h}] = p \cdot \sigma(W \mathbf{x}) $$
测试时:使用 $p \sigma(W \mathbf{x})$ 或 $\sigma(p W \mathbf{x})$(反向缩放)。
正则化效果:
- 防止共适应
- 等价于集成学习( Bagging)
- 近似贝叶斯推断(高斯过程)
4. 注意力机制
4.1 注意力的矩阵运算
缩放点积注意力: $$ \operatorname{Attention}(Q, K, V) = \operatorname{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V $$
其中:
- $Q \in \mathbb{R}^{n \times d_k}$: Query 矩阵
- $K \in \mathbb{R}^{m \times d_k}$: Key 矩阵
- $V \in \mathbb{R}^{m \times d_v}$: Value 矩阵
计算步骤:
- 计算相似度: $S = QK^T \in \mathbb{R}^{n \times m}$
- 缩放: $S / \sqrt{d_k}$(防止梯度消失)
- Softmax: $A = \operatorname{softmax}(S, \dim=1)$
- 加权求和: $\operatorname{Output} = AV \in \mathbb{R}^{n \times d_v}$
4.2 Query-Key-Value 的线性代数
物理直觉:
- Query: 我在找什么?
- Key: 我有什么标签?
- Value: 我包含什么信息?
内积相似度: $$ S_{ij} = \langle \mathbf{q}_i, \mathbf{k}_j \rangle = |\mathbf{q}_i| |\mathbf{k}j| \cos\theta{ij} $$
Softmax 将相似度转换为概率分布: $$ A_{ij} = \frac{\exp(S_{ij} / \sqrt{d_k})}{\sum_{j’=1}^m \exp(S_{ij’} / \sqrt{d_k})} $$
4.3 自注意力中的矩阵分解
自注意力: $Q = K = V = X W$(其中 $X$ 是输入序列)
多头注意力: $$ \operatorname{MultiHead}(Q, K, V) = \operatorname{Concat}(\text{head}_1, \ldots, \text{head}_h) W^O $$
$$ \text{head}_i = \operatorname{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
线性复杂度:对于序列长度 $n$,标准注意力是 $O(n^2)$。
优化方法:
- 稀疏注意力(只注意局部和全局)
- 线性注意力(使用核技巧)
- 低秩近似(分解注意力矩阵)
低秩注意力: $$ A \approx \tilde{Q} \tilde{K}^T $$
其中 $\tilde{Q} \in \mathbb{R}^{n \times r}$, $\tilde{K} \in \mathbb{R}^{m \times r}$, $r \ll \min(n, m)$。
第四部分:高级主题
1. 张量分解
1.1 张量的定义
张量是多维数组,是向量和矩阵的推广:
- 标量: 0 阶张量
- 向量: 1 阶张量
- 矩阵: 2 阶张量
- 3 阶及更高:高阶张量
符号:
- $\mathcal{X} \in \mathbb{R}^{I_1 \times I_2 \times \cdots \times I_N}$
- 元素: $x_{i_1 i_2 \cdots i_N}$
操作:
模-$n$ 乘法: $\mathcal{X} \times_n U$(沿第 $n$ 维与矩阵 $U$ 相乘)
展开(matricization):将张量重新排列为矩阵
** Tucker 分解**: $$ \mathcal{X} \approx \mathcal{G} \times_1 A^{(1)} \times_2 \cdots \times_N A^{(N)} $$
其中 $\mathcal{G}$ 是核心张量,$A^{(n)}$ 是因子矩阵。
1.2 CP 分解
CANDECOMP/PARAFAC(CP)分解: $$ \mathcal{X} \approx \sum_{r=1}^R \lambda_r \mathbf{a}_r^{(1)} \circ \mathbf{a}_r^{(2)} \circ \cdots \circ \mathbf{a}_r^{(N)} $$
其中 $\circ$ 是外积,$\lambda_r$ 是权重。
矩阵情况的特殊形式: $$ X \approx \sum_{r=1}^R \sigma_r \mathbf{u}_r \mathbf{v}_r^T $$
这就是 SVD!
优点:
- 唯一性(在温和条件下)
- 解释性强
缺点:
- 计算困难(NP-hard)
- 数值不稳定
1.3 张量网络
应用:
- 量子多体系统
- 深度学习压缩
MPS(Matrix Product State): $$ \mathcal{X}{i_1 i_2 \cdots i_N} = A^{(1)}{i_1} A^{(2)}{i_2} \cdots A^{(N)}{i_N} $$
张量列车(Tensor Train): $$ \mathcal{X} \approx \sum_{r_1, \ldots, r_{N-1}} G_1^{r_1} \circ G_2^{r_1 r_2} \circ \cdots \circ G_N^{r_{N-1}} $$
在深度学习中:
- 压缩全连接层
- 张量分解正则化
- 优化参数共享
2. 流形学习
2.1 从欧氏空间到黎曼流形
核心假设:高维数据实际位于低维流形上。
例子:
- 人脸图像:变化的只是姿态、光照、表情(少数自由度)
- 文档:主题空间是低维的
- 基因表达:受少数调控因子控制
数学定义: 流形 $M$ 是局部同胚于欧氏空间的 Hausdorff 空间。在点 $p \in M$ 处,存在邻域 $U$ 和同胚 $\phi: U \to \mathbb{R}^d$。
切空间: $T_p M$ 是 $M$ 在 $p$ 处的线性近似。
2.2 测地线距离
欧氏距离在流形上不准确: $$ d_{\text{Euclidean}}(p, q) = |\phi(p) - \phi(q)| $$
测地线距离是流形上最短路径长度: $$ d_{\text{geodesic}}(p, q) = \min_{\gamma} \int_0^1 |\dot{\gamma}(t)| , dt $$
其中 $\gamma: [0, 1] \to M$ 是连接 $p, q$ 的曲线。
Isomap 算法:
- 构建邻域图( k-NN 或 $\epsilon$-ball)
- 计算图上最短路径(Floyd-Warshall 或 Dijkstra)
- 在测地线距离矩阵上做 MDS
2.3 局部线性嵌入(LLE)
假设:流形局部是线性的。
算法:
对每个点 $\mathbf{x}i$,在邻域内拟合线性组合: $$ \min{W_{ij}} |\mathbf{x}i - \sum{j \in \mathcal{N}(i)} W_{ij} \mathbf{x}_j|^2 $$
约束: $\sum_j W_{ij} = 1$
保持权重,在低维空间中重构: $$ \min_{\mathbf{y}_i} \sum_i \left|\mathbf{y}i - \sum_j W{ij} \mathbf{y}_j\right|^2 $$
数学: $W$ 刻画了局部几何,低维嵌入应保持这些关系。
3. 优化算法的线性代数
3.1 梯度下降的收敛性
目标: $\min_{\mathbf{x}} f(\mathbf{x})$
梯度下降: $$ \mathbf{x}^{(t+1)} = \mathbf{x}^{(t)} - \eta \nabla f(\mathbf{x}^{(t)}) $$
强凸情况:假设 $f$ 是 $L$-光滑且 $\mu$-强凸的,则: $$ \lVert \mathbf{x}^{(t)} - \mathbf{x}^* \rVert^2 \leq \left(1 - \frac{\mu}{L}\right)^{t} \lVert \mathbf{x}^{(0)} - \mathbf{x}^* \rVert^2 $$
收敛速度依赖于条件数 $\kappa = L/\mu$:
- $\kappa \approx 1$: 快速收敛
- $\kappa \gg 1$: 慢收敛(山谷问题)
动量方法: $$ \mathbf{v}^{(t+1)} = \beta \mathbf{v}^{(t)} + \nabla f(\mathbf{x}^{(t)}) $$
$$ \mathbf{x}^{(t+1)} = \mathbf{x}^{(t)} - \eta \mathbf{v}^{(t+1)} $$
几何上,动量抑制震荡,加速收敛。
3.2 牛顿法与 Hessian 矩阵
二阶泰勒展开: $$ f(\mathbf{x} + \Delta \mathbf{x}) \approx f(\mathbf{x}) + \nabla f(\mathbf{x})^ op \Delta \mathbf{x} + \frac{1}{2} \Delta \mathbf{x}^T H(\mathbf{x}) \Delta \mathbf{x} $$
其中 $H(\mathbf{x})$ 是 Hessian 矩阵: $$ H_{ij} = \frac{\partial^2 f}{\partial x_i \partial x_j} $$
牛顿方向: $$ \Delta \mathbf{x} = -H^{-1} \nabla f $$
优点:
- 二阶收敛(接近最优点时)
- 不受条件数影响
缺点:
- 计算 Hessian: $O(d^2)$
- 求解线性系统: $O(d^3)$
- Hessian 可能不正定
拟牛顿法(BFGS, L-BFGS):用一阶信息近似 Hessian。
3.3 二阶优化方法
对角 Hessian 近似(Adagrad, RMSprop): $$ G_{ii} = \sum_t \left(\frac{\partial L}{\partial x_i}\right)^2 $$
$$ x_i \leftarrow x_i - \frac{\eta}{\sqrt{G_{ii} + \epsilon}} \frac{\partial L}{\partial x_i} $$
几何上,自适应学习率补偿不同方向的曲率差异。
Adam:结合动量 + RMSprop: $$ \mathbf{m} = \beta_1 \mathbf{m} + (1-\beta_1) \mathbf{g} $$
$$ \mathbf{v} = \beta_2 \mathbf{v} + (1-\beta_2) \mathbf{g}^2 $$
$$ \mathbf{x} \leftarrow \mathbf{x} - \frac{\eta}{\sqrt{\hat{\mathbf{v}}} + \epsilon} \hat{\mathbf{m}} $$
其中 $\hat{\mathbf{m}}, \hat{\mathbf{v}}$ 是偏差修正后的估计。
自然梯度: $$ \Delta \mathbf{x} = -\eta F^{-1} \nabla f $$
其中 $F$ 是 Fisher 信息矩阵。预条件使得梯度下降对参数重新参数化不变。
结语:线性代数的生命力
回顾这段旅程,我们从向量空间的直观定义出发,经历了线性变换的几何之美,正交投影的代数之巧,奇异值分解的万能之用,最终抵达了深度学习的矩阵运算之实。线性代数之所以成为现代数学和人工智能的基石,正是因为它在抽象与具体之间找到了完美的平衡。
一方面,线性代数的抽象结构——向量空间、线性变换、内积空间——捕捉了"线性"这个数学关系的本质,使得同一种理论可以应用于几何、代数、分析、物理等不同领域。另一方面,线性代数又是极其具体的:矩阵的数值计算、梯度下降的迭代优化、注意力的加权求和,每一项操作都可以在计算机上高效实现,每一步推导都有明确的几何解释。
更重要的是,线性代数的生命力在于它的可扩展性。从二维平面到千万维的词嵌入空间,从简单的最小二乘到复杂的 Transformer,线性代数的规律始终不变。这使得我们可以在理解基本原理的基础上,驾驭复杂系统。
在未来,随着量子计算、神经符号 AI、因果推断等新领域的发展,线性代数将继续扮演关键角色。理解线性代数,不仅是掌握一门数学工具,更是培养一种思维方式——将复杂问题分解为简单部分,将非线性世界线性化处理,将抽象概念转化为具体计算。
正如伟大的数学家 Weyl 所说:“线性代数是所有数学中最重要的部分。“这句话在今天,比以往任何时候都更加真实。
参考文献
- Strang, G. (2016). Introduction to Linear Algebra (5th ed.). Wellesley-Cambridge Press.
- Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins University Press.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
- Boyd, S., & Vandenberghe, L. (2018). Introduction to Applied Linear Algebra: Vectors, Matrices, and Least Squares. Cambridge University Press.
- Trefethen, L. N., & Bau, D. (1997). Numerical Linear Algebra. SIAM.
- Axler, S. (2015). Linear Algebra Done Right (3rd ed.). Springer.
- Parisi, G. (1988). Statistical Field Theory (Vol. 1). Perseus Publishing.
- Horn, R. A., & Johnson, C. R. (2012). Matrix Analysis (2nd ed.). Cambridge University Press.