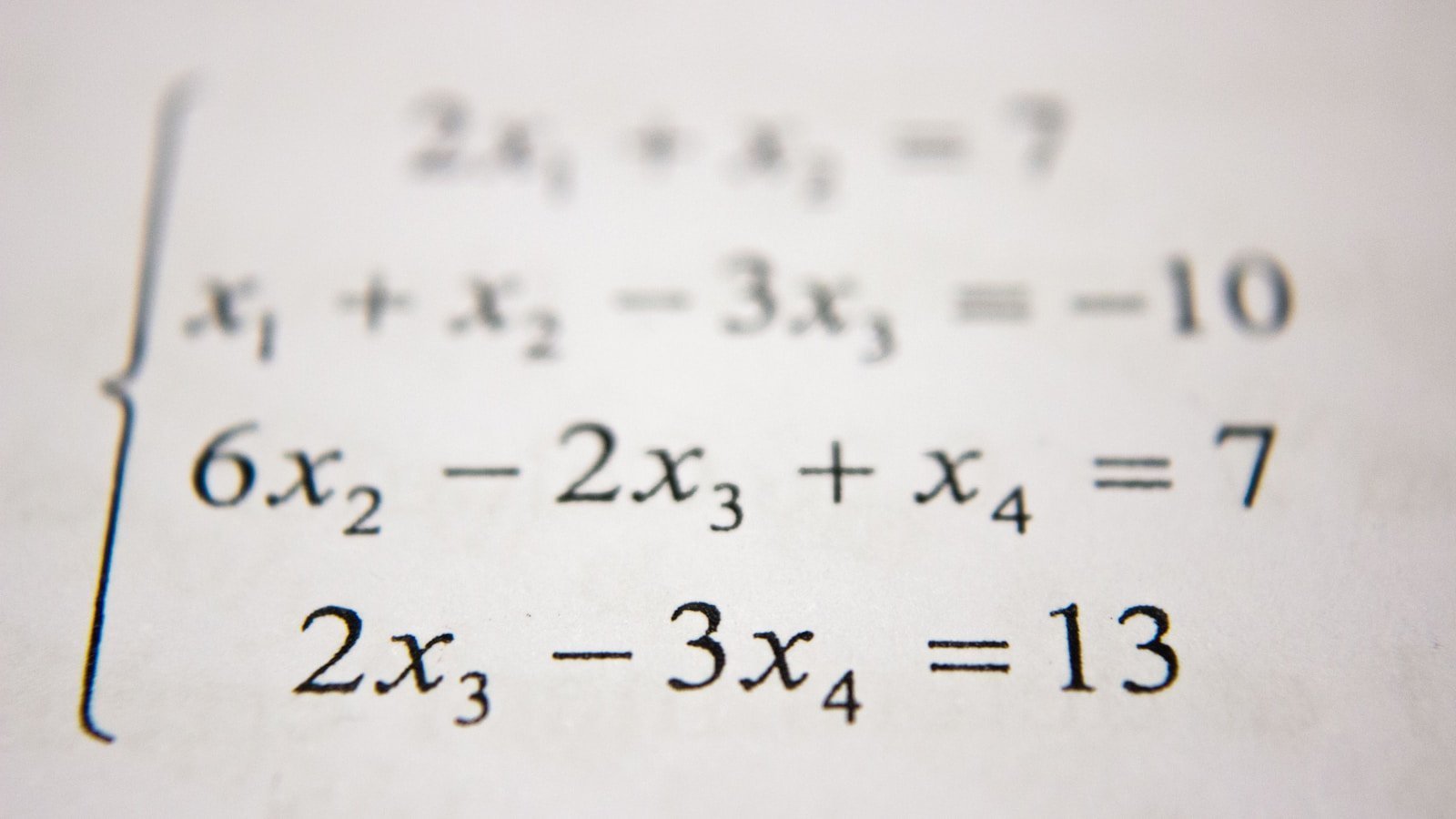
引言:在不确定的世界中寻找确定性
想象一下,你站在一个赌场的轮盘赌桌前。小球在旋转的轮盘上跳跃,最终停在一个数字上。你知道这个结果是完全随机的吗?还是说,如果你能足够精确地测量小球的初始位置、速度、轮盘的摩擦系数等所有参数,你就能预测出最终的结果?
这个思想实验引发了人类对概率本质的深刻思考。17世纪,法国数学家帕斯卡和费马在通信中讨论赌博问题,标志着概率论作为一门数学学科的诞生。随后的几个世纪里,伯努利、拉普拉斯、高斯等数学大师们为概率论的发展做出了巨大贡献。
到了20世纪初,俄罗斯数学家柯尔莫哥洛夫给出了概率论的严格公理化定义,将概率论建立在坚实的数学基础之上。几乎同时,贝叶斯的理论开始重新受到重视,为我们提供了一种全新的思考不确定性的方式。
那么,概率论和机器学习有什么关系呢?
假设你是一名医生,你需要根据患者的症状来诊断疾病。你有体温、血压、血常规等数据,以及过去的诊断记录。你会怎么做?你会综合考虑所有因素,得出一个诊断结论。这个过程本质上就是一个概率推断过程——根据观测到的数据(症状),推断最可能的原因(疾病)。
机器学习也是如此。给定一堆数据,模型需要学习数据背后的规律,然后对新的数据进行预测。在这个过程中,不确定性无处不在:数据可能有噪声,模型可能不完美,预测结果也可能有偏差。概率论为我们提供了处理这些不确定性的数学工具。
在这篇文章中,我们将系统地介绍概率论与数理统计在机器学习中的应用。从基础的概率公理开始,逐步深入到极限定理、统计推断、信息论基础,最后探讨这些理论如何在现代机器学习和深度学习算法中发挥作用。
第一章:概率基础
1.1 概率的公理化定义
1933年,柯尔莫哥洛夫建立了现代概率论的基础。他提出了三条基本公理:
公理1(非负性):对于任何事件 $A$,都有 $P(A) \geq 0$。
公理2(规范性):样本空间 $\Omega$ 的概率为 $1$,即 $P(\Omega) = 1$。
公理3(可加性):对于任意可数个互斥事件 $A_1, A_2, \ldots$,有
$$ P\left(\bigcup_{i=1}^{\infty} A_i\right) = \sum_{i=1}^{\infty} P(A_i) $$
这三条公理看起来很简单,但它们是整个概率论大厦的基石。从这些公理出发,我们可以推导出概率论的所有重要结果。
例如,对于两个事件 $A$ 和 $B$,我们可以推导出并集的概率公式:
$$ P(A \cup B) = P(A) + P(B) - P(A \cap B) $$
这个公式的直观理解是:将 $A$ 的概率和 $B$ 的概率相加时,$A$ 和 $B$ 的交集部分被计算了两次,所以需要减去一次。
1.2 条件概率和贝叶斯公式
条件概率是概率论中最重要的概念之一。直观地说,条件概率 $P(A \mid B)$ 表示"在事件 $B$ 已经发生的条件下,事件 $A$ 发生的概率"。
数学上,条件概率的定义是:
$$ P(A \mid B) = \frac{P(A \cap B)}{P(B)} $$
其中 $P(B) > 0$。
从条件概率的定义出发,我们可以推导出贝叶斯公式:
$$ P(B_i \mid A) = \frac{P(A \mid B_i) \cdot P(B_i)}{P(A)} = \frac{P(A \mid B_i) \cdot P(B_i)}{\sum_{j=1}^{n} P(A \mid B_j) \cdot P(B_j)} $$
贝叶斯公式在机器学习中的重要性怎么强调都不为过。它告诉我们:当我们观察到数据 $A$ 时,应该如何更新我们对假设 $B_i$ 的信念。
这个更新过程可以这样理解:我们从先验分布开始,结合观测到的数据(通过似然函数),得到后验分布。后验分布又成为下一轮推理的先验,如此循环。
让我们用一个医疗诊断的例子来说明贝叶斯公式的应用。
例子:某种疾病在人群中的患病率是 $1%$。一种检测方法能够正确识别 $99%$ 的患病者(真阳性率),但也有 $1%$ 的误报率(假阳性率)。如果一个人的检测结果为阳性,他真正患病的概率是多少?
解:设 $D$ 为"患病",$T$ 为"检测结果为阳性"。
- $P(D) = 0.01$(先验概率)
- $P(\neg D) = 0.99$
- $P(T \mid D) = 0.99$(似然)
- $P(T \mid \neg D) = 0.01$(似然)
我们要求的是 $P(D \mid T)$(后验概率):
$$ \begin{align} P(D \mid T) &= \frac{P(T \mid D) \cdot P(D)}{P(T \mid D) \cdot P(D) + P(T \mid \neg D) \cdot P(\neg D)} \ &= \frac{0.99 \times 0.01}{0.99 \times 0.01 + 0.01 \times 0.99} \ &= \frac{0.0099}{0.0099 + 0.0099} \ &= 0.5 \end{align} $$
这是一个令人惊讶的结果:即使检测方法的准确率达到 $99%$,阳性检测结果也只有 $50%$ 的概率真正患病!这个例子说明了贝叶斯公式的重要性:我们不能只看检测方法的准确性,还要考虑基础患病率(先验概率)。
第二章:常用概率分布
2.1 正态分布(高斯分布)
正态分布是概率论中最重要的分布,也是机器学习中最常用的分布。
概率密度函数:
$$ f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$
其中 $\mu$ 是均值,$\sigma^2$ 是方差。
期望和方差:
$$ \mathbb{E}[X] = \mu, \quad \text{Var}(X) = \sigma^2 $$
标准化:如果 $X \sim \mathcal{N}(\mu, \sigma^2)$,则 $Z = \frac{X-\mu}{\sigma} \sim \mathcal{N}(0, 1)$,即标准正态分布。
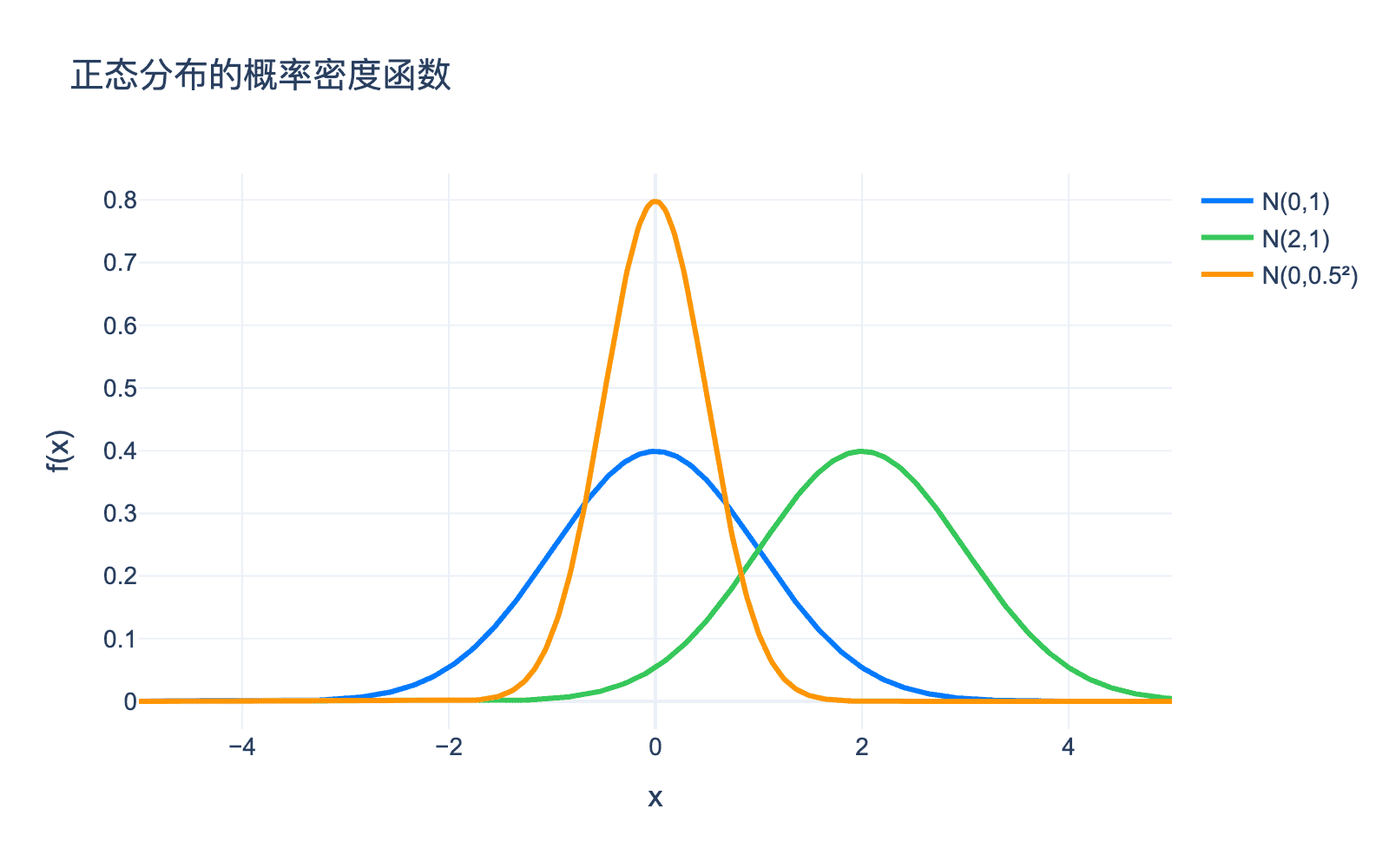
图1:不同均值和方差的正态分布。蓝色曲线是标准正态分布 $\mathcal{N}(0,1)$,绿色曲线的均值为 $2$,橙色曲线的方差更小(更陡峭)。
正态分布在机器学习中有广泛应用:
- 高斯过程回归
- 误差模型
- 神经网络的权重初始化
2.2 二项分布
二项分布描述的是 $n$ 次独立的伯努利试验中成功的次数。
概率质量函数:
$$ P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}, \quad k = 0, 1, \ldots, n $$
其中 $\binom{n}{k} = \frac{n!}{k!(n-k)!}$ 是二项式系数。
期望和方差:
$$ \mathbb{E}[X] = np, \quad \text{Var}(X) = np(1-p) $$
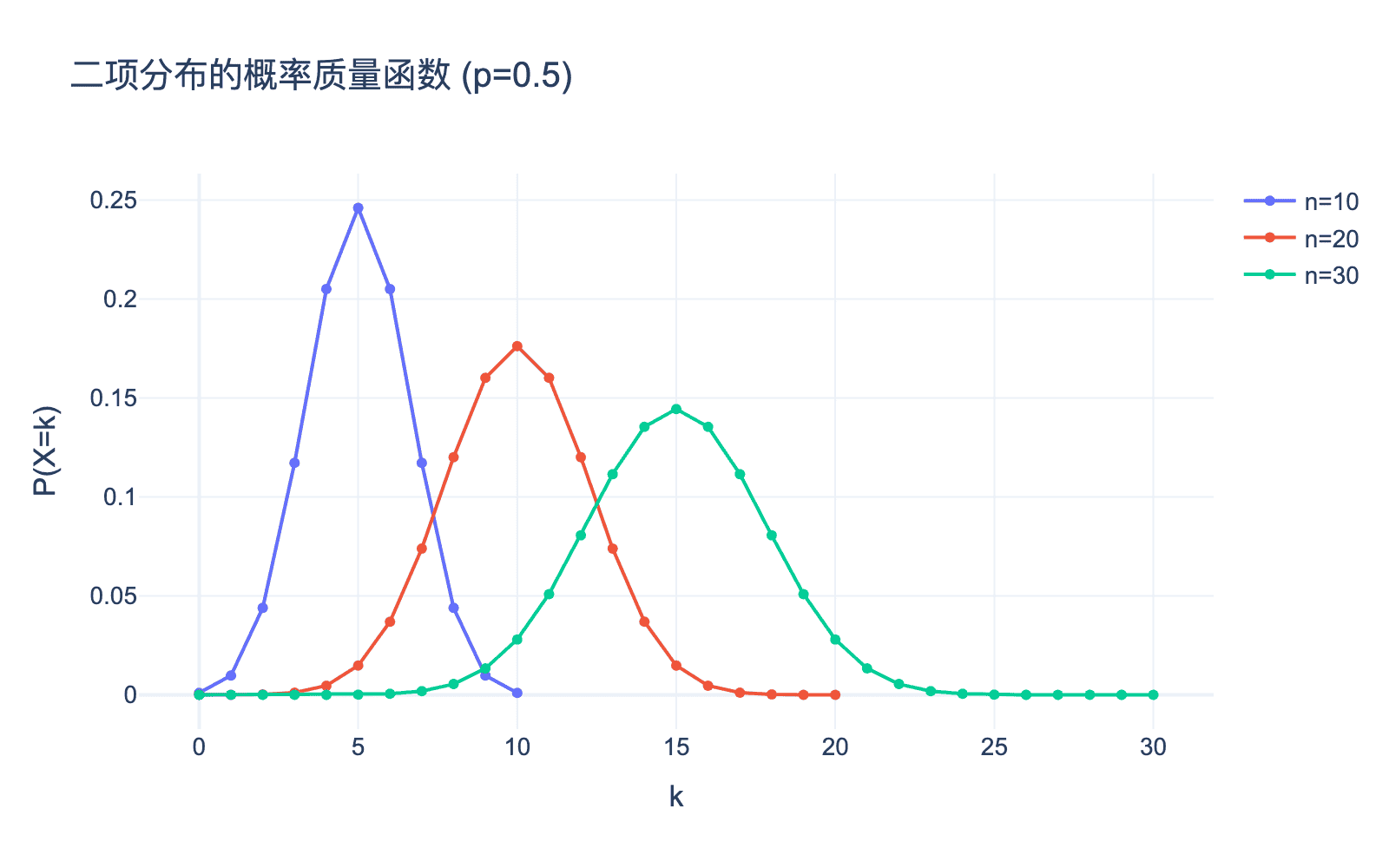
图2:不同参数的二项分布。当 $n$ 增大时,二项分布逐渐趋近于正态分布(中心极限定理)。
2.3 伯努利分布
伯努利分布是最简单的离散型分布,描述的是单次试验的结果(成功或失败)。
概率质量函数:
$$ P(X = x) = p^x (1-p)^{1-x}, \quad x \in {0, 1} $$
其中 $p$ 是成功的概率。
期望和方差:
$$ \mathbb{E}[X] = p, \quad \text{Var}(X) = p(1-p) $$
伯努利分布在机器学习中广泛应用于二分类问题,如垃圾邮件检测。
第三章:统计推断
3.1 最大似然估计(MLE)
最大似然估计的基本思想是:找到使观测数据出现概率最大的参数值。
定义:设 $X_1, X_2, \ldots, X_n$ 是来自分布 $p(x \mid \theta)$ 的独立同分布样本,其中 $\theta$ 是未知参数。似然函数定义为:
$$ L(\theta) = \prod_{i=1}^{n} p(x_i \mid \theta) $$
对数似然函数为:
$$ \ell(\theta) = \log L(\theta) = \sum_{i=1}^{n} \log p(x_i \mid \theta) $$
MLE 是使似然函数最大的参数估计:
$$ \hat{\theta}{\text{MLE}} = \arg\max{\theta} L(\theta) = \arg\max_{\theta} \ell(\theta) $$
例子:正态分布的 MLE
设 $X_1, X_2, \ldots, X_n \sim \mathcal{N}(\mu, \sigma^2)$,求 $\mu$ 和 $\sigma^2$ 的 MLE。
对数似然函数为:
$$ \begin{align} \ell(\mu, \sigma^2) &= \sum_{i=1}^{n} \log \left(\frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right)\right) \ &= \sum_{i=1}^{n} \left(-\frac{1}{2}\log(2\pi) - \frac{1}{2}\log(\sigma^2) - \frac{(x_i-\mu)^2}{2\sigma^2}\right) \ &= -\frac{n}{2}\log(2\pi) - \frac{n}{2}\log(\sigma^2) - \frac{1}{2\sigma^2}\sum_{i=1}^{n} (x_i-\mu)^2 \end{align} $$
对 $\mu$ 求导并令导数为 $0$:
$$ \begin{align} \frac{\partial \ell}{\partial \mu} &= \frac{1}{\sigma^2} \sum_{i=1}^{n} (x_i - \mu) = 0 \ \Rightarrow \sum_{i=1}^{n} (x_i - \hat{\mu}) &= 0 \ \Rightarrow \hat{\mu} &= \frac{1}{n}\sum_{i=1}^{n} x_i \end{align} $$
对 $\sigma^2$ 求导并令导数为 $0$:
$$ \begin{align} \frac{\partial \ell}{\partial \sigma^2} &= -\frac{n}{2\sigma^2} + \frac{1}{2(\sigma^2)^2}\sum_{i=1}^{n} (x_i-\mu)^2 = 0 \ \Rightarrow \frac{1}{\hat{\sigma}^2} &= \frac{1}{n\hat{\sigma}^4}\sum_{i=1}^{n} (x_i-\hat{\mu})^2 \ \Rightarrow \hat{\sigma}^2 &= \frac{1}{n}\sum_{i=1}^{n} (x_i-\hat{\mu})^2 \end{align} $$
应用:逻辑回归、线性回归等监督学习算法本质上都是 MLE 估计。例如,逻辑回归假设 $y_i \mid x_i \sim \text{Bernoulli}(\sigma(w^\top x_i))$,然后通过最大化对数似然来估计参数 $w$。
3.2 最大后验估计(MAP)
最大后验估计结合了先验信息,是贝叶斯推断的一种近似。
贝叶斯公式:
$$ p(\theta \mid D) = \frac{p(D \mid \theta) \cdot p(\theta)}{p(D)} $$
其中:
- $p(\theta \mid D)$ 是后验概率(看到数据后的信念)
- $p(D \mid \theta)$ 是似然(给定参数下数据出现的概率)
- $p(\theta)$ 是先验概率(看到数据前的信念)
- $p(D)$ 是证据(归一化常数)
MAP 估计是使后验概率最大的参数估计:
$$ \hat{\theta}{\text{MAP}} = \arg\max{\theta} p(\theta \mid D) = \arg\max_{\theta} p(D \mid \theta) \cdot p(\theta) $$
MLE 和 MAP 的关系:如果先验是均匀分布,即 $p(\theta) \propto \text{constant}$,则 MAP 等价于 MLE。因此,MAP 可以看作是 MLE 的推广,它在 MLE 的基础上加入了先验信息。
例子:带高斯先验的线性回归
设线性回归模型为 $y = w^\top x + \epsilon$,其中 $\epsilon \sim \mathcal{N}(0, \sigma^2)$。假设参数 $w$ 的先验分布为 $w \sim \mathcal{N}(0, \lambda^{-1} I)$。
似然函数:
$$ p(y \mid X, w) = \prod_{i=1}^{n} \mathcal{N}(y_i \mid w^\top x_i, \sigma^2) $$
后验分布:
$$ p(w \mid X, y) \propto p(y \mid X, w) \cdot p(w) $$
取对数:
$$ \begin{align} \log p(w \mid X, y) &\propto \sum_{i=1}^{n} \log \mathcal{N}(y_i \mid w^\top x_i, \sigma^2) + \log \mathcal{N}(w \mid 0, \lambda^{-1} I) \ &\propto -\frac{1}{2\sigma^2}\sum_{i=1}^{n} (y_i - w^\top x_i)^2 - \frac{\lambda}{2} w^\top w + \text{constant} \end{align} $$
最大化后验等价于最小化负对数后验:
$$ \begin{align} w_{\text{MAP}} &= \arg\min_{w} \left(\sum_{i=1}^{n} (y_i - w^\top x_i)^2 + \lambda \sigma^2 w^\top w\right) \ &= \arg\min_{w} \left(\lVert y - Xw\rVert^2 + \alpha \lVert w\rVert^2\right) \end{align} $$
其中 $\alpha = \lambda \sigma^2$。
这正是岭回归(Ridge Regression)的目标函数!因此,岭回归可以解释为带高斯先验的线性回归的 MAP 估计。
应用:正则化方法本质上都是 MAP 估计。例如:
- L2 正则化(岭回归)$\leftrightarrow$ 高斯先验
- L1 正则化(Lasso)$\leftrightarrow$ 拉普拉斯先验
第四章:信息论基础
4.1 熵
信息论为机器学习提供了度量不确定性和信息量的工具。
香农熵:对于离散型随机变量 $X$,其熵定义为:
$$ H(X) = -\sum_{x \in \mathcal{X}} p(x) \log p(x) $$
熵衡量了随机变量的不确定性:
- 熵越大,不确定性越大
- 熵为 $0$:完全确定
- 熵最大:均匀分布
例子:抛硬币。设 $P(\text{正面}) = p$,则:
$$ H(X) = -p \log p - (1-p) \log (1-p) $$
当 $p = 0.5$ 时,熵最大;当 $p = 0$ 或 $p = 1$ 时,熵为 $0$。
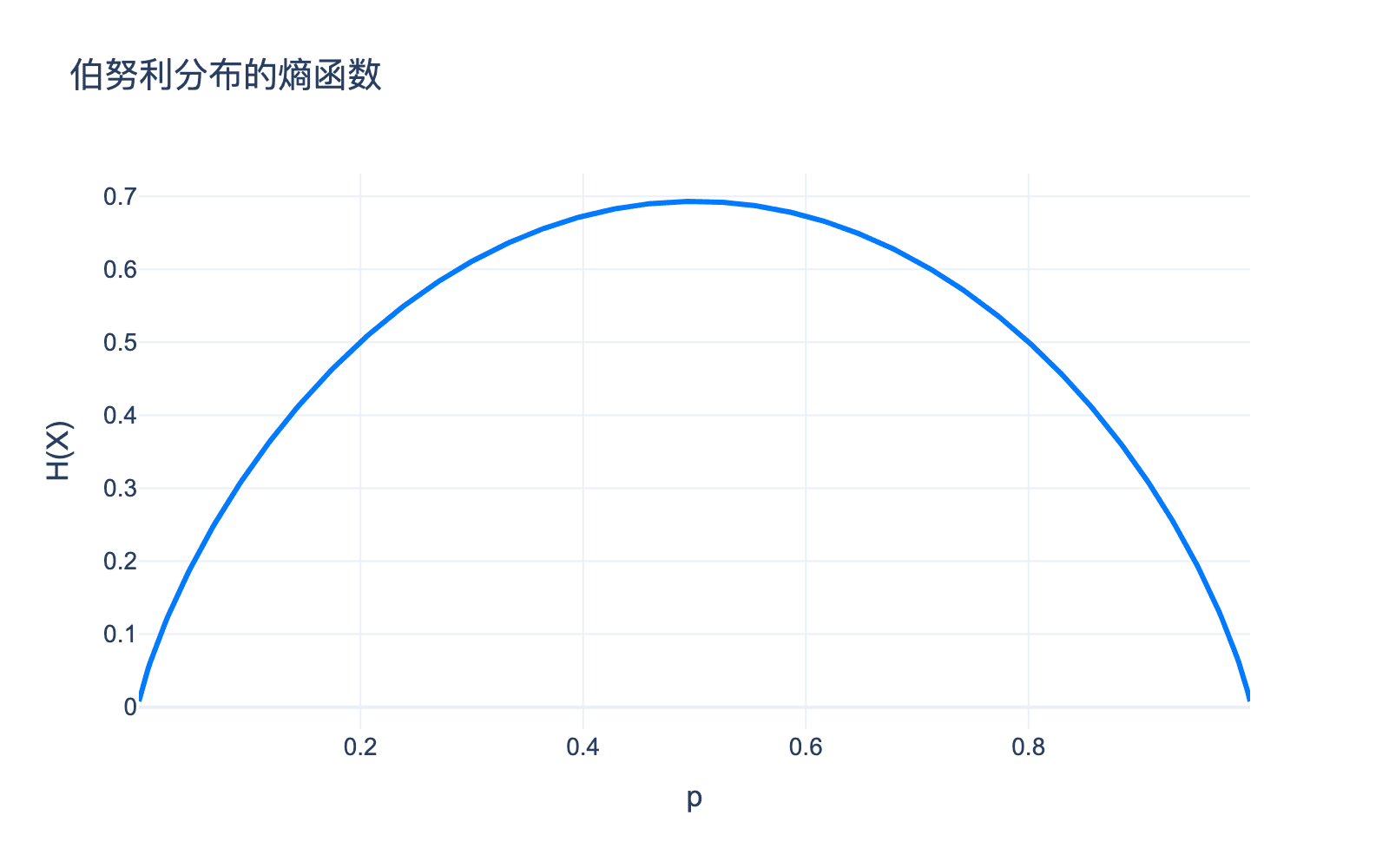
图3:伯努利分布的熵函数。当 $p = 0.5$ 时熵最大,此时不确定性最大。
4.2 相对熵(KL 散度)
相对熵(KL 散度)衡量两个概率分布的差异。
定义:
$$ D_{\text{KL}}(p \parallel q) = \sum_{x \in \mathcal{X}} p(x) \log \frac{p(x)}{q(x)} $$
性质:
- $D_{\text{KL}}(p \parallel q) \geq 0$(Gibbs 不等式)
- $D_{\text{KL}}(p \parallel q) = 0$ 当且仅当 $p(x) = q(x)$ 对所有 $x$ 成立
- KL 散度不对称:$D_{\text{KL}}(p \parallel q) \neq D_{\text{KL}}(q \parallel p)$
直观理解:KL 散度衡量用分布 $q$ 来近似分布 $p$ 时损失的信息量。
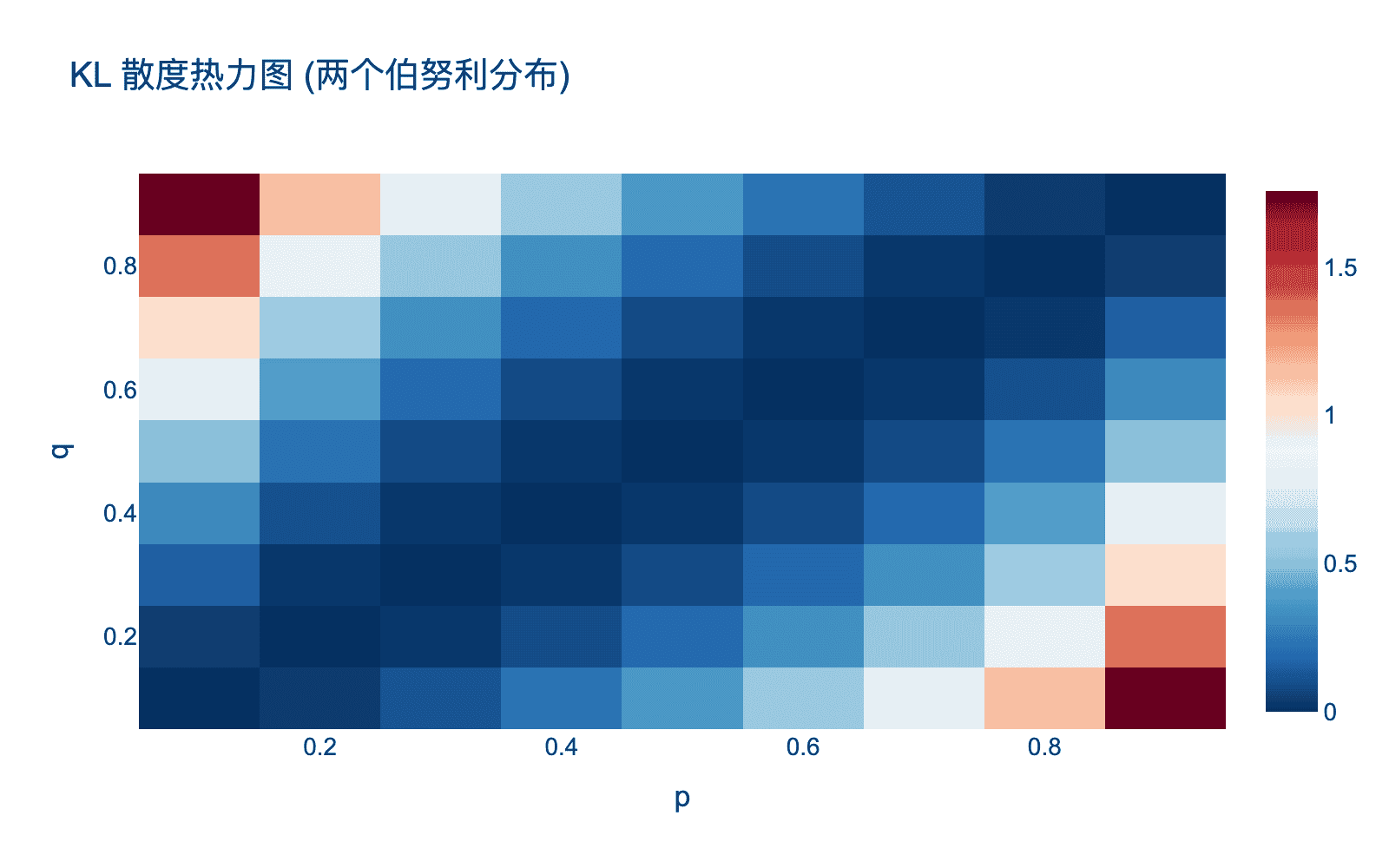
图4:KL 散度热力图。展示了两个伯努利分布之间的 KL 散度,颜色越红表示差异越大。
应用:
- 变分推断:最小化变分分布和真实后验之间的 KL 散度
- 生成模型:最小化生成分布和真实分布之间的 KL 散度
4.3 交叉熵
交叉熵在机器学习中有广泛应用,尤其是在分类问题中。
定义:
$$ H(p, q) = -\sum_{x \in \mathcal{X}} p(x) \log q(x) $$
其中 $p$ 是真实分布,$q$ 是预测分布。
与 KL 散度的关系:
$$ H(p, q) = H(p) + D_{\text{KL}}(p \parallel q) $$
因此,最小化交叉熵等价于最小化 KL 散度(因为 $H(p)$ 是常数)。
应用:逻辑回归和神经网络的交叉熵损失函数。
例子:二分类问题。设 $y \in {0, 1}$ 是真实标签,$\hat{y} = \sigma(w^\top x)$ 是预测概率。交叉熵损失为:
$$ \begin{align} L &= -\sum_{i=1}^{n} [y_i \log \hat{y}_i + (1 - y_i) \log(1 - \hat{y}i)] \ &= -\sum{i=1}^{n} [y_i \log \sigma(w^\top x_i) + (1 - y_i) \log(1 - \sigma(w^\top x_i))] \end{align} $$
这正是逻辑回归的标准损失函数。
第五章:机器学习中的概率模型
5.1 逻辑回归
逻辑回归虽然名字中有"回归",但它实际上是一个分类模型。它使用 sigmoid 函数将线性组合映射到 $[0, 1]$ 区间,然后将其解释为概率。
模型假设:
$$ P(y = 1 \mid x) = \sigma(w^\top x) = \frac{1}{1 + e^{-w^\top x}} $$
其中 $\sigma(z) = \frac{1}{1 + e^{-z}}$ 是 sigmoid 函数。
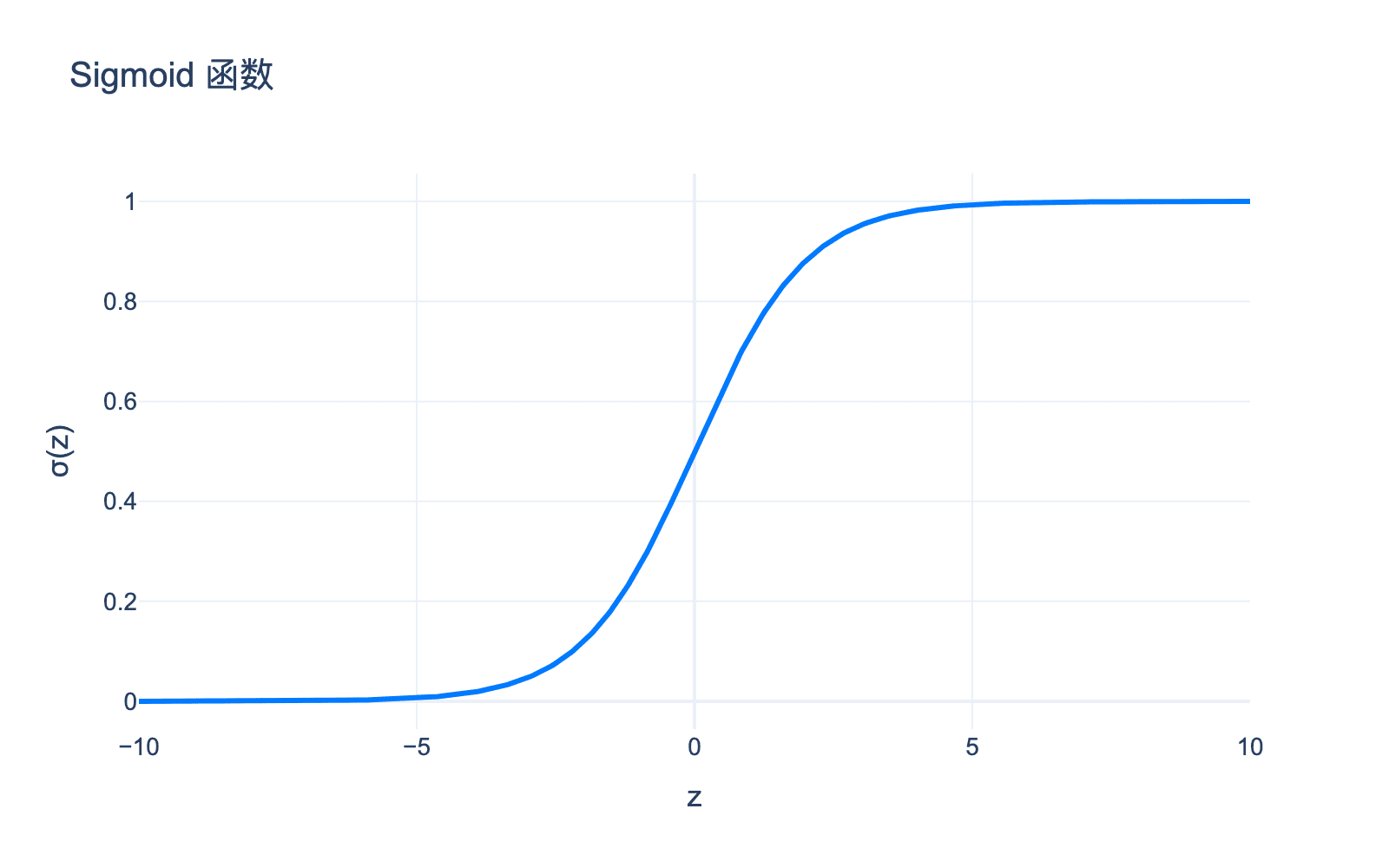
图5:Sigmoid 函数将任意实数映射到 $[0,1]$ 区间,适合表示概率。
似然函数:
$$ \begin{align} L(w) &= \prod_{i=1}^{n} P(y_i \mid x_i, w) \ &= \prod_{i=1}^{n} [\sigma(w^\top x_i)]^{y_i} [1 - \sigma(w^\top x_i)]^{1-y_i} \end{align} $$
对数似然:
$$ \ell(w) = \sum_{i=1}^{n} [y_i \log \sigma(w^\top x_i) + (1 - y_i) \log(1 - \sigma(w^\top x_i))] $$
优化:最大化对数似然等价于最小化负对数似然(交叉熵损失):
$$ w^* = \arg\min_w \sum_{i=1}^{n} [y_i \log \sigma(w^\top x_i) + (1 - y_i) \log(1 - \sigma(w^\top x_i))] $$
结语
在这篇文章中,我们系统地介绍了概率论与数理统计在机器学习中的应用。
核心要点回顾:
贝叶斯公式是机器学习的核心思想,告诉我们如何根据观测数据更新对模型的信念
MLE 和 MAP 是两种主要的参数估计方法。MLE 寻找使观测数据出现概率最大的参数,而 MAP 则结合了先验信息
概率分布为机器学习提供了丰富的建模工具。正态分布、二项分布、伯努利分布等在不同场景中发挥重要作用
信息论为机器学习提供了度量不确定性的工具。熵、KL 散度和交叉熵是许多损失函数的理论基础
概率模型如逻辑回归、高斯过程、EM 算法等为机器学习提供了坚实的理论基础
没有概率论,我们无法理解过拟合现象,无法量化预测的不确定性,也无法设计出鲁棒可靠的算法。
未来的方向:
随着深度学习的发展,贝叶斯深度学习、不确定性量化、主动学习等方向越来越受到关注。这些方向的共同特点是更加重视对不确定性的理解和建模。
希望这篇文章能够帮助读者建立概率论与数理统计在机器学习中的整体认识,为更深入的学习和研究打下坚实的基础。
参考文献
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- MacKay, D. J. (2003). Information Theory, Inference, and Learning Algorithms. Cambridge University Press.
- Cover, T. M., & Thomas, J. A. (2006). Elements of Information Theory (2nd ed.). Wiley.
- Rasmussen, C. E., & Williams, C. K. I. (2006). Gaussian Processes for Machine Learning. MIT Press.