
引言:对称性的数学之美
在数学的众多分支中,有一个深刻的原理反复出现:对称性带来简化。在物理学中,空间的对称性意味着守恒量;在群论中,对称结构导致简单的表示;在线性代数中,对称矩阵拥有最优雅的对角化理论——这就是谱定理。
想象你站在一个椭圆中心。如果你沿任意方向看出去,椭圆的"宽度"各不相同。但有两个特殊的方向——椭圆的长轴和短轴——沿这些方向,椭圆的形状最简单,只是一个被拉伸的圆。这两个正交的方向,就是椭圆的"主轴",它们对应的拉伸倍数,就是"特征值"。
这个直观的几何图像,正是谱定理的核心。谱定理告诉我们:任何实对称矩阵都可以通过正交变换对角化。换句话说,在适当的坐标系下,对称矩阵描述的线性变换只是沿某些正交方向的简单拉伸。
在机器学习和深度学习中,谱定理无处不在。从主成分分析(PCA)到奇异值分解(SVD),从谱聚类到图神经网络,谱定理提供了理解数据和算法的理论基础。
在这篇文章中,我们将系统性地介绍谱定理的核心理论,从实对称矩阵的正交对角化到一般的奇异值分解,从PCA到谱聚类,深入浅出地推导每一个公式,并通过可视化图形直观理解这些概念。
第一章:谱定理的基础理论
1.1 特征值与特征向量:不变的方向
给定一个 $n \times n$ 矩阵 $A$,如果存在非零向量 $v \in \mathbb{R}^n$ 和标量 $\lambda \in \mathbb{R}$,使得
$$ Av = \lambda v $$
则称 $\lambda$ 是 $A$ 的特征值,$v$ 是对应的特征向量。
几何意义:特征向量 $v$ 是线性变换 $A$ 下的"不变方向"——变换后,这个向量只是被拉伸或压缩了 $\lambda$ 倍,方向保持不变。
特征多项式:特征值是特征方程的根
$$ \det(A - \lambda I) = 0 $$
对于 $n \times n$ 矩阵,这是一个 $n$ 次多项式,在复数域上有 $n$ 个根(计入重数)。
1.2 对称矩阵的特殊性质
实对称矩阵 $A \in \mathbb{R}^{n \times n}$(即 $A^\top = A$)拥有三个重要性质:
性质1:所有特征值都是实数
证明:设 $\lambda$ 是 $A$ 的特征值,$v \neq 0$ 是对应的特征向量(可能是复向量)。则
$$ Av = \lambda v $$
取共轭转置:$\overline{v}^\top A = \overline{\lambda} \overline{v}^\top$(因为 $A$ 是实矩阵)
右乘 $v$:$\overline{v}^\top A v = \overline{\lambda} \overline{v}^\top v$
但 $\overline{v}^\top A v = \overline{v}^\top (\lambda v) = \lambda \overline{v}^\top v$
因此 $\lambda \overline{v}^\top v = \overline{\lambda} \overline{v}^\top v$
由于 $\overline{v}^\top v = \sum |v_i|^2 > 0$,我们得到 $\lambda = \overline{\lambda}$,即 $\lambda$ 是实数。
性质2:不同特征值对应的特征向量正交
证明:设 $Av_1 = \lambda_1 v_1$,$Av_2 = \lambda_2 v_2$,且 $\lambda_1 \neq \lambda_2$。
计算 $v_2^\top A v_1$ 两种方式:
$v_2^\top A v_1 = v_2^\top (\lambda_1 v_1) = \lambda_1 v_2^\top v_1$
$v_2^\top A v_1 = v_2^\top A^\top v_1 = (Av_2)^\top v_1 = (\lambda_2 v_2)^\top v_1 = \lambda_2 v_2^\top v_1$
因此 $\lambda_1 v_2^\top v_1 = \lambda_2 v_2^\top v_1$,即 $(\lambda_1 - \lambda_2) v_2^\top v_1 = 0$
由于 $\lambda_1 \neq \lambda_2$,必须有 $v_2^\top v_1 = 0$,即 $v_1 \perp v_2$。
性质3:可正交对角化
这是谱定理的核心内容,我们在下一节详细讨论。
1.3 正交矩阵与正交对角化
定义:矩阵 $Q \in \mathbb{R}^{n \times n}$ 是正交矩阵,如果
$$ Q^\top Q = Q Q^\top = I $$
等价地,$Q$ 的列向量构成 $\mathbb{R}^n$ 的一组标准正交基。
几何意义:正交矩阵表示旋转或反射变换,保持向量的长度和夹角。
定理:矩阵 $A$ 可正交对角化当且仅当 $A$ 是实对称矩阵。即存在正交矩阵 $Q$ 和对角矩阵 $\Lambda$,使得
$$ A = Q \Lambda Q^\top $$
其中 $\Lambda = \operatorname{diag}(\lambda_1, \ldots, \lambda_n)$,$\lambda_i$ 是 $A$ 的特征值,$Q$ 的列是对应的特征向量。
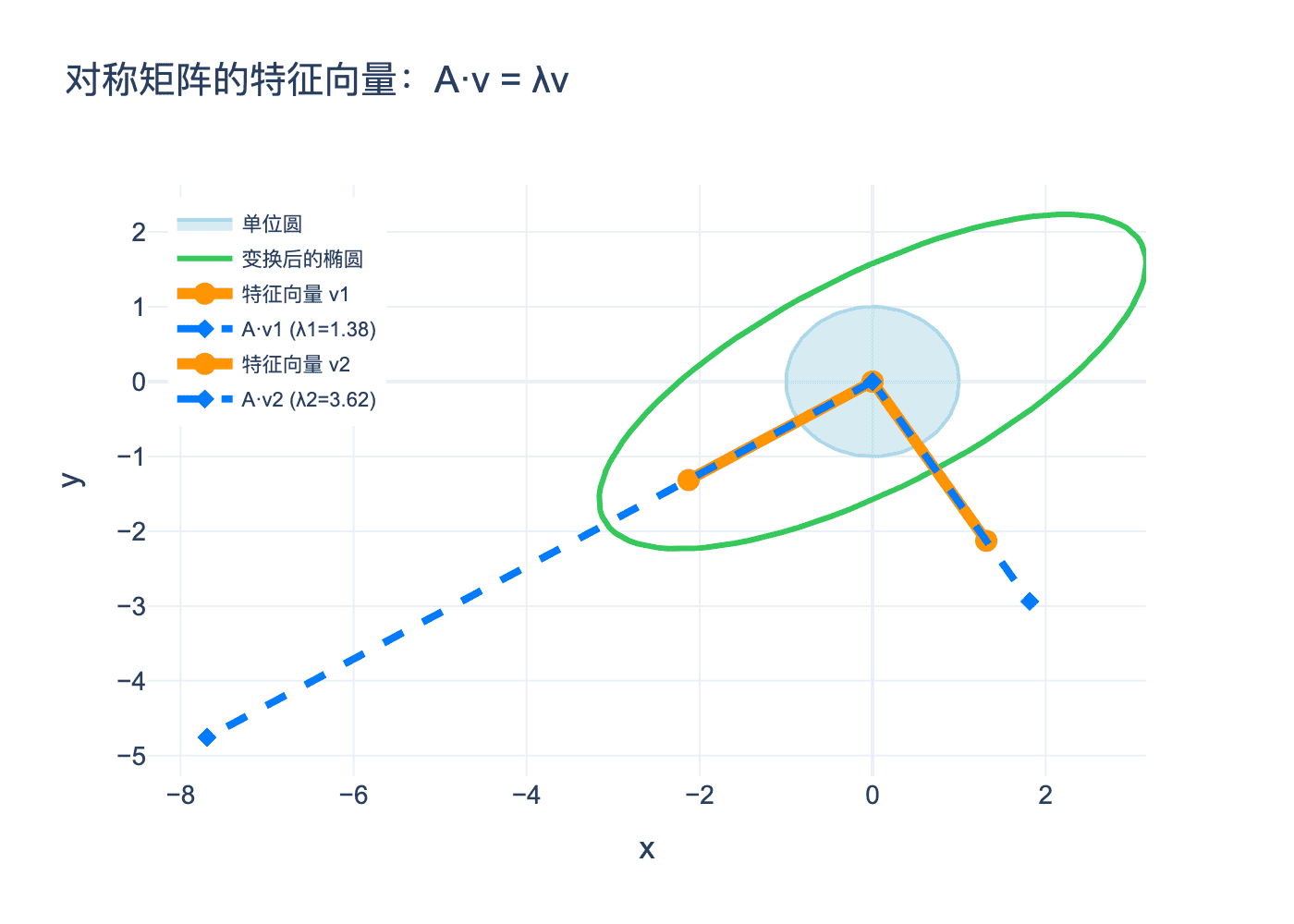
图1:对称矩阵的特征向量。橙色线是特征向量方向,蓝色虚线是变换后的特征向量(仍在同一直线上)。椭圆显示单位圆经变换 A 后的形状,长轴和短轴恰好沿特征向量方向。
第二章:谱定理的证明与深入理解
2.1 谱定理的完整表述
谱定理(实对称矩阵版本):
设 $A \in \mathbb{R}^{n \times n}$ 是对称矩阵,则:
- $A$ 有 $n$ 个实特征值 $\lambda_1, \ldots, \lambda_n$(计入重数)
- 存在 $\mathbb{R}^n$ 的一组标准正交基 ${q_1, \ldots, q_n}$,其中每个 $q_i$ 都是 $A$ 的特征向量
- $A$ 可以表示为 $A = \sum_{i=1}^n \lambda_i q_i q_i^\top$
2.2 谱定理的证明
我们使用归纳法证明谱定理。
基础情况($n=1$):平凡成立。
归纳步骤:假设对 $(n-1) \times (n-1)$ 对称矩阵成立。设 $A$ 是 $n \times n$ 对称矩阵。
步骤1:由于特征多项式在复数域上总有根,取 $A$ 的一个特征值 $\lambda_1$(由性质1,$\lambda_1$ 是实数)和对应的单位特征向量 $q_1$。
步骤2:将 $q_1$ 扩展为 $\mathbb{R}^n$ 的标准正交基 ${q_1, q_2, \ldots, q_n}$。令 $Q = [q_1 ; q_2 ; \cdots ; q_n]$,则 $Q$ 是正交矩阵。
步骤3:考虑 $Q^\top A Q$。计算其第一列:
$(Q^\top A Q)_{:,1} = Q^\top A q_1 = Q^\top (\lambda_1 q_1) = \lambda_1 Q^\top q_1 = \lambda_1 e_1$
其中 $e_1 = (1, 0, \ldots, 0)^\top$。
由于 $Q^\top A Q$ 也是对称矩阵($(Q^\top A Q)^\top = Q^\top A^\top Q = Q^\top A Q$),它的第一行也必须是 $(\lambda_1, 0, \ldots, 0)$。
因此
$$ Q^\top A Q = \begin{pmatrix} \lambda_1 & 0 \ 0 & B \end{pmatrix} $$
其中 $B$ 是 $(n-1) \times (n-1)$ 对称矩阵。
步骤4:由归纳假设,$B$ 可正交对角化:存在 $(n-1) \times (n-1)$ 正交矩阵 $Q_B$ 使得 $Q_B^\top B Q_B = \Lambda_B$ 是对角矩阵。
步骤5:令
$$ \widetilde{Q} = \begin{pmatrix} 1 & 0 \ 0 & Q_B \end{pmatrix}, \quad \widetilde{Q}^\top (Q^\top A Q) \widetilde{Q} = \begin{pmatrix} \lambda_1 & 0 \ 0 & \Lambda_B \end{pmatrix} $$
则 $\widetilde{Q} Q$ 是正交矩阵,且
$$ (\widetilde{Q} Q)^\top A (\widetilde{Q} Q) = \operatorname{diag}(\lambda_1, \lambda_2, \ldots, \lambda_n) $$
证毕。
2.3 谱分解的谱系解释
谱定理的另一种表达方式是谱分解:
$$ A = \sum_{i=1}^n \lambda_i q_i q_i^\top = \sum_{i=1}^n \lambda_i P_i $$
其中 $P_i = q_i q_i^\top$ 是到特征空间 $\operatorname{span}{q_i}$ 的正交投影算子。
性质:
- $P_i^2 = P_i$(幂等性)
- $P_i P_j = 0$($i \neq j$,正交性)
- $\sum_{i=1}^n P_i = I$(完备性)
直观理解:对称矩阵 $A$ 可以分解为沿各个正交方向的"拉伸"的组合,每个方向上的拉伸倍数就是对应的特征值。
第三章:奇异值分解(SVD)——推广到任意矩阵
3.1 从谱定理到SVD
谱定理适用于对称方阵。但实际应用中,我们经常遇到非方阵(如数据矩阵 $X \in \mathbb{R}^{n \times p}$)。奇异值分解(SVD)是谱定理的自然推广。
定理(SVD):任何矩阵 $A \in \mathbb{R}^{m \times n}$ 都可以分解为
$$ A = U \Sigma V^\top $$
其中:
- $U \in \mathbb{R}^{m \times m}$ 是正交矩阵(左奇异向量)
- $V \in \mathbb{R}^{n \times n}$ 是正交矩阵(右奇异向量)
- $\Sigma \in \mathbb{R}^{m \times n}$ 是对角矩阵,对角元素 $\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r > 0$ 是奇异值,$r = \operatorname{rank}(A)$
3.2 SVD的推导
步骤1:考虑 $A^\top A \in \mathbb{R}^{n \times n}$,这是一个对称半正定矩阵。
由谱定理,$A^\top A$ 可正交对角化:
$$ A^\top A = V \Lambda V^\top $$
其中 $V$ 的列 $v_1, \ldots, v_n$ 是特征向量,$\Lambda = \operatorname{diag}(\lambda_1, \ldots, \lambda_n)$。
由于 $A^\top A$ 半正定,所有 $\lambda_i \geq 0$。
步骤2:定义奇异值 $\sigma_i = \sqrt{\lambda_i}$。
步骤3:定义 $u_i = \frac{Av_i}{\sigma_i}$(当 $\sigma_i > 0$)。
验证 $u_i$ 是单位向量:
$$ \lVert u_i \rVert^2 = \frac{v_i^\top A^\top A v_i}{\sigma_i^2} = \frac{v_i^\top (\lambda_i v_i)}{\lambda_i} = v_i^\top v_i = 1 $$
且 $u_i$ 两两正交:
$$ u_i^\top u_j = \frac{v_i^\top A^\top A v_j}{\sigma_i \sigma_j} = \frac{\lambda_j v_i^\top v_j}{\sigma_i \sigma_j} = 0 \quad (i \neq j) $$
步骤4:将 $u_i$ 扩展为 $\mathbb{R}^m$ 的标准正交基,得到 $U$。
步骤5:验证 $A = U \Sigma V^\top$。
对于任意 $v_j$:
$$ A v_j = \sigma_j u_j = U (\Sigma e_j) = U \Sigma (V^\top v_j) $$
由于 ${v_1, \ldots, v_n}$ 是基,对任意 $x \in \mathbb{R}^n$,$A x = U \Sigma V^\top x$。
3.3 SVD的几何意义
SVD告诉我们,任何线性变换 $A : \mathbb{R}^n \to \mathbb{R}^m$ 都可以分解为三个步骤:
- 旋转/反射($V^\top$):在 $\mathbb{R}^n$ 中改变坐标系
- 伸缩($\Sigma$):沿各坐标轴方向伸缩
- 旋转/反射($U$):在 $\mathbb{R}^m$ 中改变坐标系
直观理解:$A$ 将单位球映射为一个椭球,奇异值给出椭球的主轴长度,左、右奇异向量给出主轴方向。
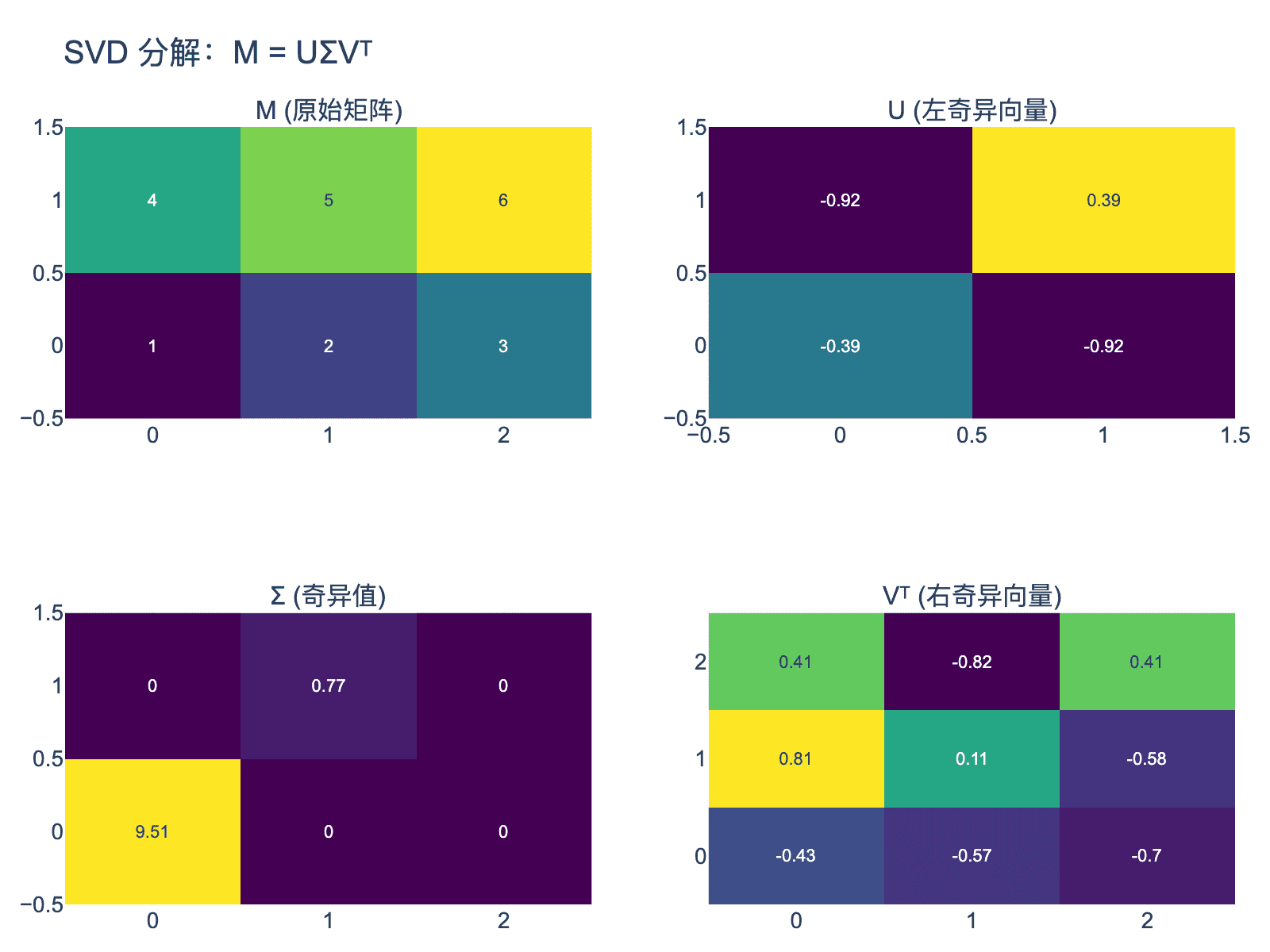
图2:SVD分解的矩阵形式。M被分解为U、Σ、Vᵀ三个矩阵的乘积,其中U和V是正交矩阵,Σ是对角矩阵(非方阵时补零)。
第四章:主成分分析(PCA)的谱定理视角
4.1 PCA的问题设定
给定中心化数据矩阵 $X \in \mathbb{R}^{n \times p}$($n$ 个样本,$p$ 个特征,每列均值为零),PCA的目标是找到一组正交方向,使得数据在这些方向上的方差最大化。
问题:最大化方差
$$ \max_{w \in \mathbb{R}^p, \lVert w \rVert = 1} \operatorname{Var}(Xw) = \frac{1}{n} \sum_{i=1}^n (x_i^\top w)^2 = \frac{1}{n} \lVert Xw \rVert^2 = \frac{1}{n} w^\top X^\top X w $$
4.2 PCA的谱定理推导
定义样本协方差矩阵 $C = \frac{1}{n} X^\top X$,这是一个 $p \times p$ 对称半正定矩阵。
由谱定理,$C$ 可正交对角化:
$$ C = V \Lambda V^\top $$
其中 $\Lambda = \operatorname{diag}(\lambda_1, \ldots, \lambda_p)$,$\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_p \geq 0$。
关键观察:PCA问题的解恰好是 $C$ 的特征向量。
证明:对于单位向量 $w$,令 $v = V^\top w$。由于 $V$ 正交,$\lVert v \rVert = \lVert w \rVert = 1$。
$$ w^\top C w = w^\top V \Lambda V^\top w = v^\top \Lambda v = \sum_{i=1}^p \lambda_i v_i^2 \leq \lambda_1 \sum_{i=1}^p v_i^2 = \lambda_1 $$
当 $v = e_1$(即 $w = v_1$,$C$ 的第一特征向量)时等号成立。
4.3 PCA的几何解释
PCA寻找的是数据的"主轴"——数据变化最大的方向。这些方向恰好是协方差矩阵的特征向量,特征值大小表示沿该方向的方差大小。
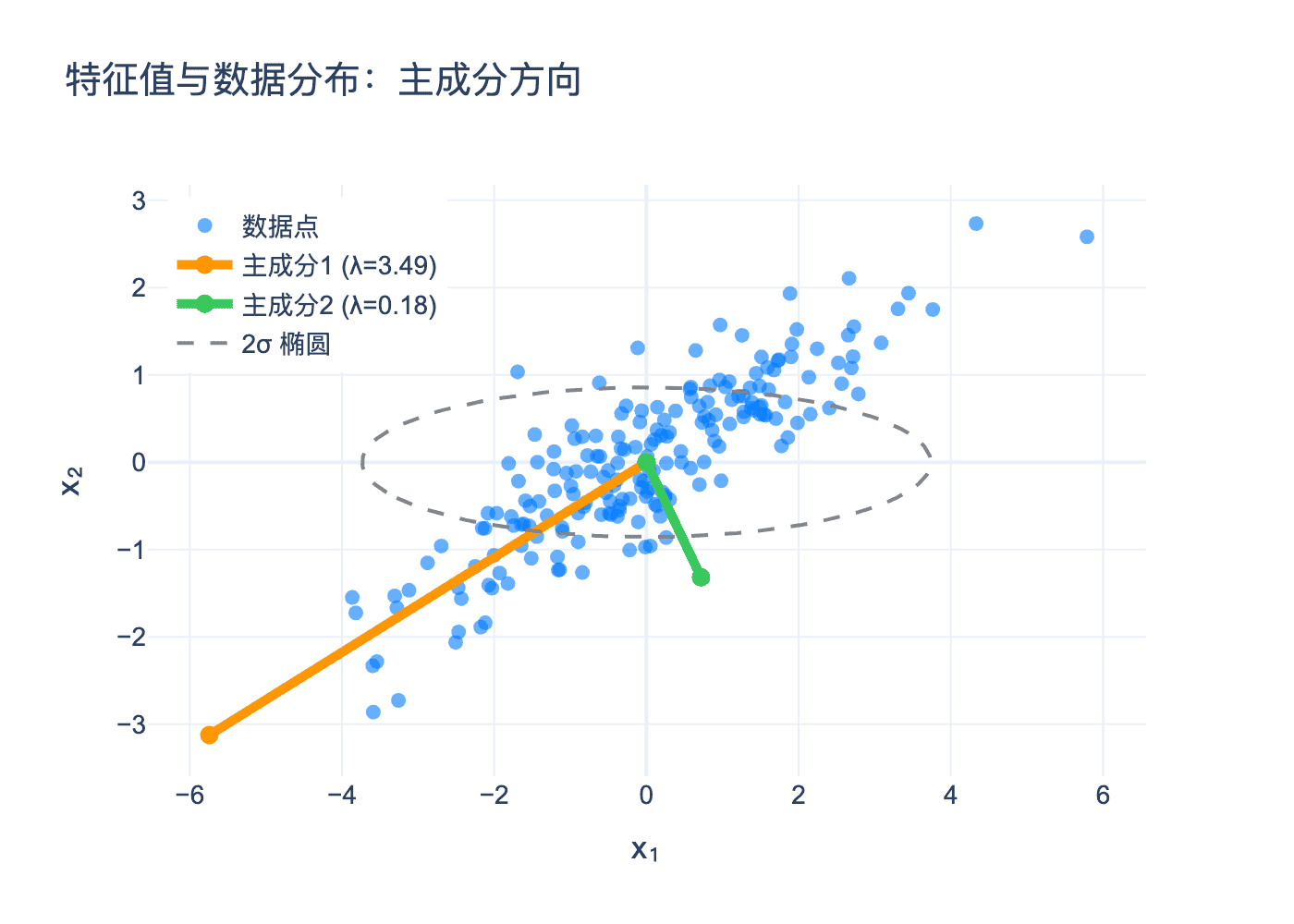
图3:PCA的几何意义。数据点的椭圆轮廓显示了数据的分布,橙色箭头是第一主成分(最大方差方向),绿色箭头是第二主成分。虚线椭圆是2σ置信椭圆。
4.4 降维与重建
保留前 $k$ 个主成分,将数据投影到 $k$ 维子空间:
$$ X_{\text{projected}} = X V_k $$
其中 $V_k = [v_1 ; v_2 ; \cdots ; v_k]$ 包含前 $k$ 个特征向量。
重建(近似)原始数据:
$$ X_{\text{reconstructed}} = X_{\text{projected}} V_k^\top = X V_k V_k^\top $$
误差分析:重建误差(Frobenius范数)等于被舍弃特征值的和:
$$ \lVert X - X V_k V_k^\top \rVert_F^2 = n \sum_{i=k+1}^p \lambda_i $$
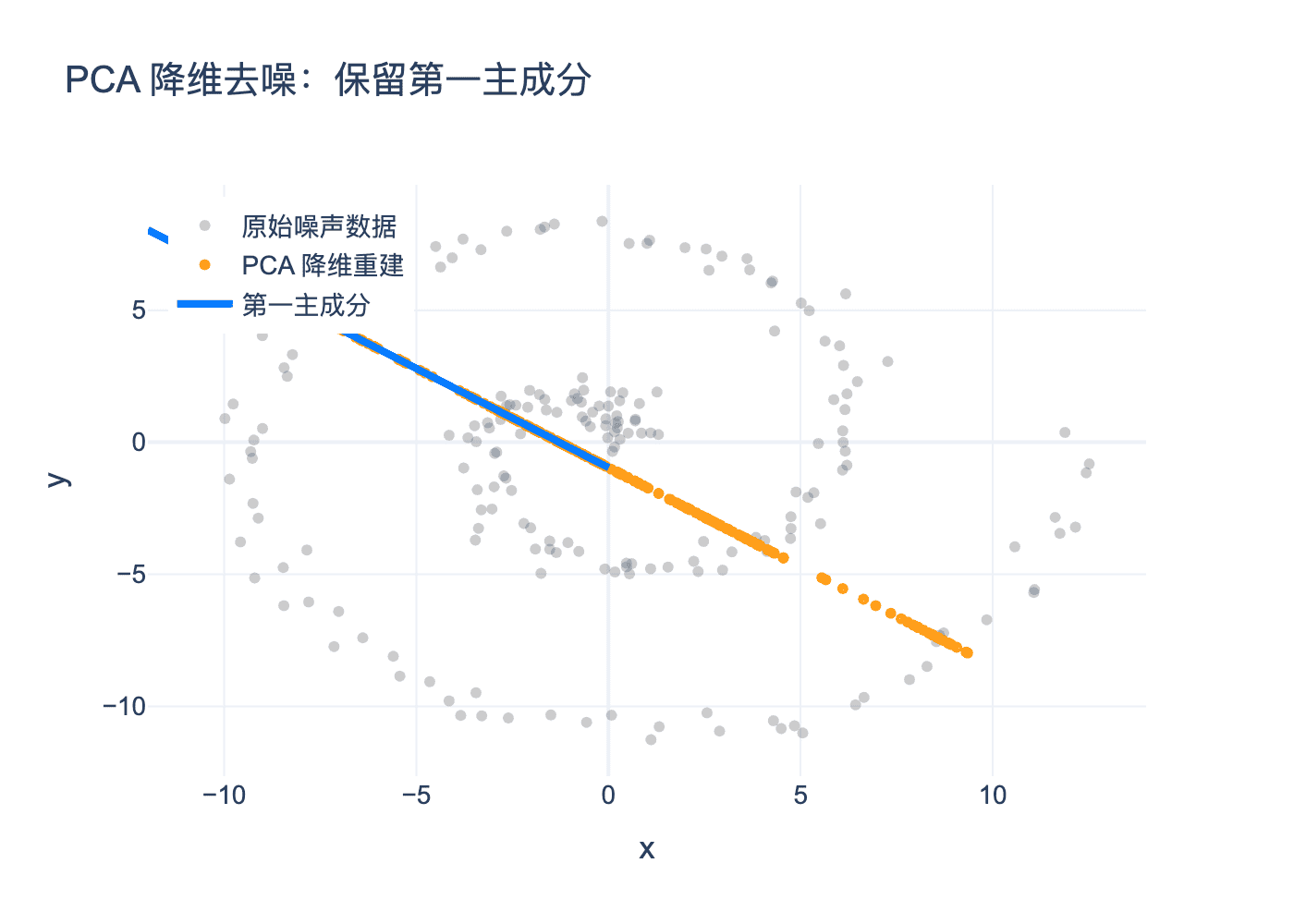
图4:PCA降维去噪效果。灰色点是原始噪声数据,橙色点是保留第一主成分后重建的数据,蓝色箭头是第一主成分方向。噪声被有效过滤。
4.5 解释方差比
第 $k$ 主成分的解释方差比为:
$$ \frac{\lambda_k}{\sum_{i=1}^p \lambda_i} $$
前 $k$ 个主成分的累积解释方差比为:
$$ \frac{\sum_{i=1}^k \lambda_i}{\sum_{i=1}^p \lambda_i} $$
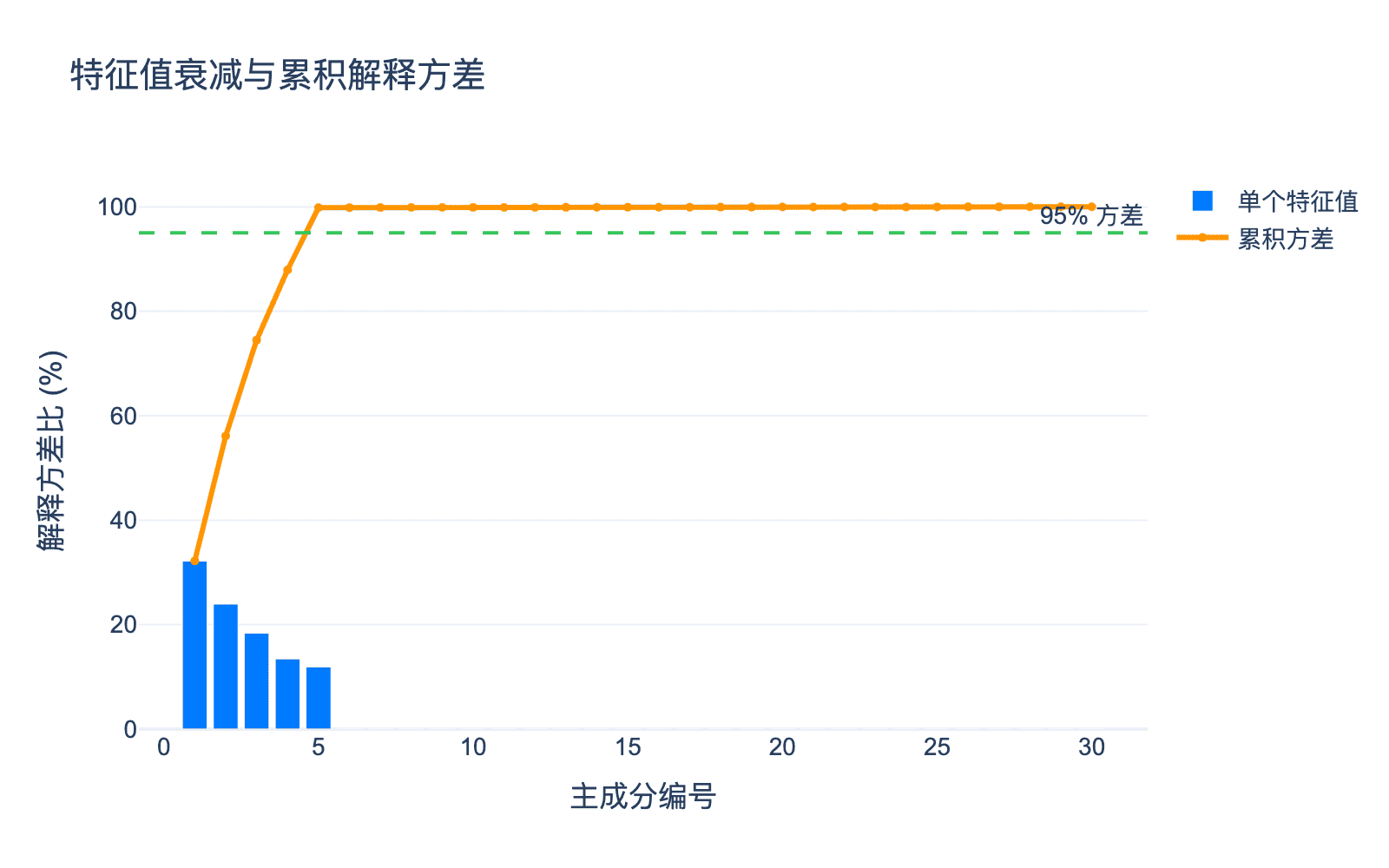
图5:特征值衰减与累积解释方差。蓝色条形是各主成分的解释方差比,橙色线是累积解释方差比。可以看到,前5个主成分解释了超过95%的方差。
第五章:谱聚类与拉普拉斯矩阵
5.1 图的谱理论
给定无向加权图 $G = (V, E, W)$,其中 $W_{ij}$ 是节点 $i$ 和 $j$ 之间的边权重。
度矩阵:$D = \operatorname{diag}(d_1, \ldots, d_n)$,其中 $d_i = \sum_{j=1}^n W_{ij}$
图拉普拉斯矩阵:$L = D - W$
性质:
- $L$ 是对称半正定矩阵
- $L$ 的最小特征值是 $0$,对应的特征向量是全 $1$ 向量
- 第二小特征值称为代数连通度或Fiedler值,对应的特征向量称为Fiedler向量
5.2 谱聚类算法
谱聚类利用拉普拉斯矩阵的特征向量进行聚类:
算法:
- 构建相似度图(如k近邻图、全连接图)
- 计算拉普拉斯矩阵 $L$
- 计算 $L$ 的前 $k$ 个特征向量 $u_1, \ldots, u_k$
- 将节点嵌入到 $\mathbb{R}^k$:节点 $i$ 映射为 $(u_1(i), \ldots, u_k(i))$
- 在嵌入空间中运行k-means聚类
为什么有效:拉普拉斯矩阵的特征向量捕获了图的"全局结构"。Fiedler向量的正负性自然地将图分成两个连接紧密的部分。
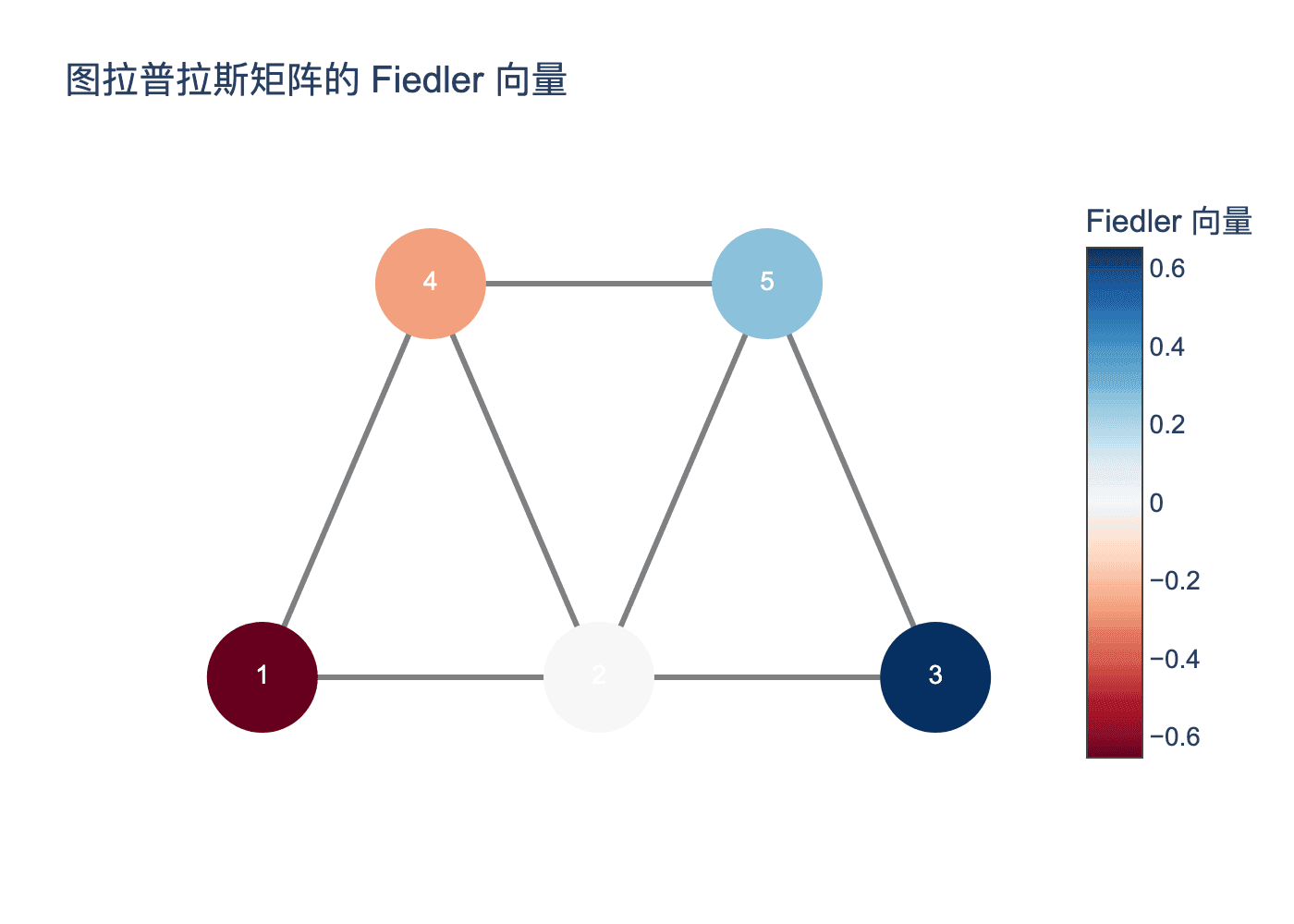
图6:图拉普拉斯矩阵的Fiedler向量可视化。节点颜色代表Fiedler向量的值,蓝色为负,红色为正。可以看到Fiedler向量自然地将图分成了两组。
5.3 谱聚类的直观例子
考虑两个月牙形数据集:传统的基于距离的聚类(如k-means)无法正确分离,但谱聚类可以。
关键在于:谱聚类不是在原始空间中聚类,而是在"谱空间"中聚类。在谱空间中,原本纠缠的数据点被正确分离。
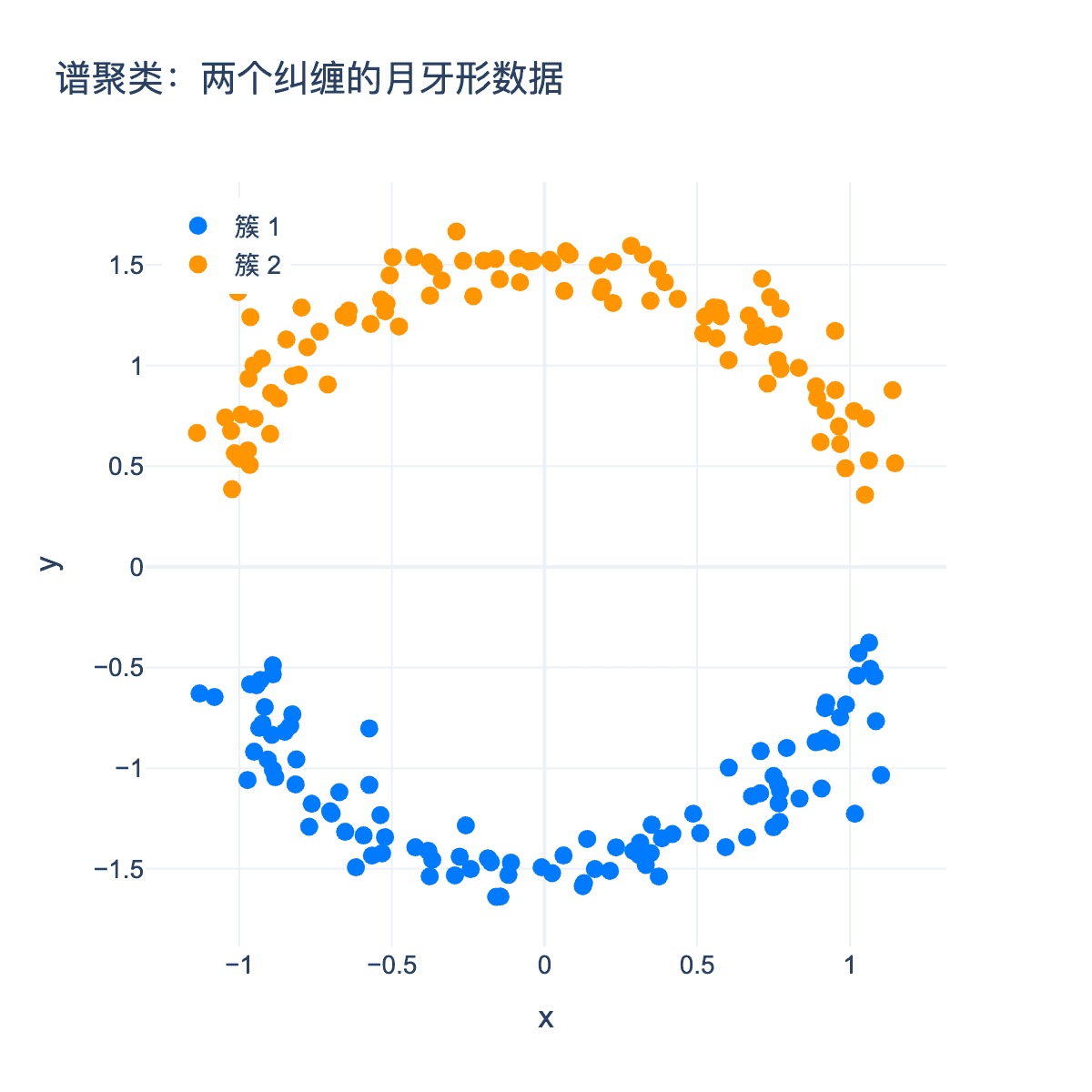
图7:谱聚类对两个月牙形数据的聚类结果。蓝色和橙色代表两个不同的簇,谱聚类成功分离了这两个纠缠的月牙形数据。
5.4 归一化割(Normalized Cut)
谱聚类与归一化割优化问题密切相关:
$$ \min_{A \subset V} \operatorname{Ncut}(A) = \frac{\operatorname{cut}(A)}{\operatorname{vol}(A)} + \frac{\operatorname{cut}(A)}{\operatorname{vol}(\overline{A})} $$
其中 $\operatorname{cut}(A) = \sum_{i \in A, j \notin A} W_{ij}$ 是分割的代价,$\operatorname{vol}(A) = \sum_{i \in A} d_i$ 是节点集合的"体积"。
定理:归一化割问题的松弛解恰好是拉普拉斯矩阵的第二小特征向量。
第六章:神经网络中的谱方法
6.1 图神经网络(GNN)中的谱卷积
图卷积网络(GCN)的核心思想是在图上进行卷积操作。经典的卷积定义在欧几里得空间(如图像),但图没有规则的网格结构。
谱图卷积利用图拉普拉斯矩阵的特征分解定义卷积:
设 $L = U \Lambda U^\top$ 是拉普拉斯矩阵的谱分解,信号 $x \in \mathbb{R}^n$ 的傅里叶变换是 $\hat{x} = U^\top x$。
图上的卷积定义为:
$$ y = g_\theta * x = U g_\theta(\Lambda) U^\top x $$
其中 $g_\theta(\Lambda) = \operatorname{diag}(\theta(\lambda_1), \ldots, \theta(\lambda_n))$ 是频域滤波器。
ChebNet近似:直接计算特征分解太昂贵($O(n^3)$),使用切比雪夫多项式近似:
$$ g_\theta(\Lambda) \approx \sum_{k=0}^K \theta_k T_k(\widetilde{L}) $$
其中 $T_k$ 是第 $k$ 阶切比雪夫多项式,$\widetilde{L} = \frac{2}{\lambda_{\max}} L - I$ 是缩放的拉普拉斯矩阵。
6.2 GCN的一阶近似
Kipf & Welling (2017) 提出了更简单的一阶近似:
$$ y = D^{-1/2} \widetilde{A} D^{-1/2} X \Theta $$
其中 $\widetilde{A} = A + I$ 是加入自环的邻接矩阵。
这个公式可以理解为:每个节点的表示是其邻居表示的加权平均,权重由图的度决定。
6.3 注意力机制的谱视角
Transformer中的注意力机制也可以从谱的角度理解。自注意力矩阵 $S \in \mathbb{R}^{n \times n}$ 定义为:
$$ S_{ij} = \frac{\exp(q_i^\top k_j)}{\sum_{l=1}^n \exp(q_i^\top k_l)} $$
这可以看作是在动态构建的图上的消息传递,图的权重由注意力得分决定。
谱归一化:为了稳定训练,可以对注意力矩阵的奇异值进行约束:
$$ S \leftarrow \frac{S}{\sigma_{\max}(S)} $$
6.4 激活函数的谱分析
ReLU激活函数 $f(x) = \max(0, x)$ 的谱性质很重要。考虑其在正交变换下的行为:
如果 $W$ 是随机正交矩阵,则 $\operatorname{E}[\lVert f(Wx) \rVert^2] = \frac{1}{2}\lVert x \rVert^2$(假设 $x$ 的各分量独立对称分布)。
这解释了为什么需要He初始化:$W \sim \mathcal{N}(0, \frac{2}{n_{in}})$,以保持信号在通过ReLU后方差不变。
第七章:数值方法与应用案例
7.1 特征值计算算法
幂法:计算最大特征值和对应特征向量
初始化:随机向量 b(0)
重复:b(k+1) = A b(k) / ||A b(k)||
收敛:b(k) → 主特征向量,||A b(k)|| → 主特征值
收敛速度:取决于 $|\lambda_2 / \lambda_1|$(次大特征值与最大特征值的比值之比)。
QR算法:计算所有特征值
通过QR迭代将矩阵逐步上三角化:
$$ A_0 = A \ A_k = Q_k R_k \quad \text{(QR分解)} \ A_{k+1} = R_k Q_k $$
对于对称矩阵,$A_k$ 收敛到对角矩阵(特征值在主对角线上)。
7.2 SVD在图像压缩中的应用
图像可以看作矩阵 $I \in \mathbb{R}^{m \times n}$(像素值)。SVD的低秩近似:
$$ I \approx I_k = \sum_{i=1}^k \sigma_i u_i v_i^\top $$
其中 $k \ll \min(m, n)$。
压缩比:存储 $I_k$ 需要 $k(m + n + 1)$ 个数,而原始图像需要 $mn$ 个数。
当 $k = \frac{mn}{m+n}$ 时,压缩比约为 50%。
7.3 协同过滤中的矩阵分解
推荐系统中的用户-物品评分矩阵 $R \in \mathbb{R}^{m \times n}$ 通常非常稀疏。协同过滤假设 $R$ 可以分解为:
$$ R \approx U V^\top $$
其中 $U \in \mathbb{R}^{m \times k}$ 是用户隐因子矩阵,$V \in \mathbb{R}^{n \times k}$ 是物品隐因子矩阵。
这与截断SVD密切相关,但需要处理缺失值(通常通过交替最小二乘或随机梯度下降求解)。
7.4 PageRank算法
PageRank是谷歌早期的核心算法,用于衡量网页的重要性。可以理解为马尔可夫链的稳态分布。
设 $A$ 是网页的邻接矩阵($A_{ij} = 1$ 如果页面 $j$ 链接到页面 $i$),归一化后得到转移矩阵 $P$。
PageRank向量 $r$ 满足:
$$ r = (1-d) \frac{1}{n} \mathbf{1} + d P^\top r $$
其中 $d \approx 0.85$ 是阻尼因子。
这等价于求矩阵 $M = d P^\top + \frac{1-d}{n} \mathbf{1} \mathbf{1}^\top$ 的主特征向量。
第八章:总结与展望
8.1 核心要点回顾
谱定理是连接线性代数、几何分析和机器学习的桥梁:
- 谱定理:实对称矩阵可正交对角化,特征向量构成标准正交基
- SVD:谱定理向任意矩阵的推广,奇异值是"信息的强度"
- PCA:从谱定理视角看,PCA就是协方差矩阵的特征分解
- 谱聚类:利用拉普拉斯矩阵的特征向量发现图的社区结构
- 图神经网络:谱卷积是图上卷积的理论基础
8.2 理论与实践的平衡
在理论层面,谱定理提供了优美的数学结构:对称性导致可对角化,特征值编码了变换的本质信息。
在实践层面,我们需要考虑:
- 计算复杂度:特征分解是 $O(n^3)$
- 数值稳定性:病态矩阵需要特殊处理
- 近似方法:随机SVD、Lanczos算法、幂迭代
8.3 前沿方向
深度学习的理论理解:
- 为什么深度网络可以学习?可能与特征值衰减有关
- 梯度消失/爆炸与雅可比矩阵的谱性质密切相关
- 谱归一化作为正则化手段
图神经网络的新方向:
- 超过一阶的图卷积(但容易过平滑)
- 自适应图结构学习
- 结合注意力机制
大规模特征值计算:
- 随机算法(如Halko等人的随机SVD)
- 分布式特征值分解
- 量子计算在谱分析中的应用
8.4 结语
谱定理之所以优雅,是因为它揭示了线性代数的一个核心真理:对称性带来简化。在机器学习和深度学习的复杂算法背后,谱定理提供了坚实的数学基础。
从PCA降维到谱聚类,从图像压缩到PageRank,从图神经网络到注意力机制,谱定理的身影无处不在。理解谱定理,就是理解了数据结构的"骨架"——那些不随坐标系变化而变化的本质特征。
希望这篇文章能帮助读者建立对谱定理的系统认识,为进一步学习机器学习理论和算法打下坚实基础。记住:在复杂的数据世界中,谱定理是我们的指南针,指引我们找到最本质的结构。
参考文献
- Strang, G. (2016). Introduction to Linear Algebra (5th ed.). Wellesley-Cambridge Press.
- Trefethen, L. N., & Bau, D. (1997). Numerical Linear Algebra. SIAM.
- Boyd, S., & Vandenberghe, L. (2018). Introduction to Applied Linear Algebra. Cambridge University Press.
- Von Luxburg, U. (2007). A Tutorial on Spectral Clustering. Statistics and Computing, 17(4), 395-416.
- Kipf, T. N., & Welling, M. (2017). Semi-Supervised Classification with Graph Convolutional Networks. ICLR.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.). Springer.
- Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins University Press.
- Belkin, M., & Niyogi, P. (2003). Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Computation, 15(6), 1373-1396.