引言:当深度学习遇见弯曲的空间
2012年,AlexNet 在 ImageNet 竞赛中以压倒性优势获胜,深度学习正式进入大众视野。此后,神经网络在各种任务上展现出惊人能力:图像识别、语音识别、机器翻译、游戏对战……但有一个问题始终困扰着研究者:为什么神经网络能够如此有效地学习?
答案或许藏在数据的本质结构中。想象你正在看一张人脸照片——1000 $\times$ 1000 像素的图像意味着这是一个百万维的空间中的点。但所有人脸照片都分布在这个百万维空间的一个极小子集上。为什么?因为真实的人脸受到物理规律的约束:两只眼睛在鼻子两侧,嘴巴在鼻子下方,等等。
这个子集不是随机的散点集合,而是一个流形(manifold)——一个局部看起来像欧几里得空间,但整体上可能弯曲、扭转的几何对象。
流形假设(Manifold Hypothesis)是连接微分几何与深度学习的桥梁:
真实世界的高维数据往往分布在一个低维流形上。
这个假设解释了为什么深度学习能够成功,也指明了改进的方向。从流形学习的早期算法,到现代的几何深度学习,微分几何正在成为理解神经网络本质的重要语言。
让我们从最基本的流形概念开始,逐步揭开这层神秘的面纱。
第一章:流形假设——数据的几何本质
1.1 什么是流形?
在正式定义之前,让我们从一个直观的例子开始。
想象一只蚂蚁生活在地球表面。对于这只蚂蚁来说,地面看起来是平的——它可以向前、向后、向左、向右移动。只有当它旅行了很长距离后,才会意识到这个世界是弯曲的(比如绕地球一圈回到原点)。
流形正是这种"局部平坦,整体弯曲"的空间。数学上,一个 $n$ 维流形 $\mathcal{M}$ 是一个拓扑空间,其中每一点 $p \in \mathcal{M}$ 都有一个邻域,同胚于 $\mathbb{R}^n$。
关键特性:
- 局部坐标:在任何小区域内,我们可以用 $n$ 个坐标 $(x^1, x^2, \ldots, x^n)$ 描述位置
- 过渡函数:不同坐标系统之间的变换必须是光滑的
- 全局结构:局部坐标片可以"缝合"成复杂的整体结构
 图1:流形学习的核心思想——高维数据(如瑞士卷)实际上分布在一个低维流形上,学习的目标就是"展开"这个流形,发现其内在的低维结构。
图1:流形学习的核心思想——高维数据(如瑞士卷)实际上分布在一个低维流形上,学习的目标就是"展开"这个流形,发现其内在的低维结构。
1.2 数据流形:从高维到低维
现在回到深度学习。考虑以下例子:
MNIST 手写数字:每个图像是 $28 \times 28 = 784$ 维的向量。但所有"3"的图像并不随机分布在 784 维空间中——它们形成了一个高度结构化的集合。写下"3"的方式虽然变化多端,但受到人体解剖学和书写习惯的约束。
人脸图像:如引言所述,人脸图像分布在由身份、表情、光照、角度等参数控制的低维流形上。这些参数可能有几十个,但远小于百万级的像素维度。
词向量:自然语言处理中的词嵌入将词汇映射到连续向量空间。语义相近的词在向量空间中也相近,形成某种几何结构。
流形维数的估计:如何确定数据流形的维数?这是一个活跃的研究领域。常用方法包括:
- 主成分分析(PCA):线性估计
- 本征维数估计:基于最近邻距离的统计方法
- 分形维数:对于复杂结构的数据
1.3 为什么流形结构重要?
理解数据的流形结构对深度学习有多方面的意义:
1. 维度灾难的缓解
在 $d$ 维欧几里得空间中,要覆盖单位立方体到精度 $\epsilon$,需要 $O(\epsilon^{-d})$ 个样本。这就是维度灾难。
但如果数据分布在一个 $k$ 维流形上($k \ll d$),所需样本量降至 $O(\epsilon^{-k})$。这解释了为什么神经网络能够在高维输入空间有效学习——它们实际上只需要学习低维流形上的函数。
2. 归纳偏置的设计
神经网络的设计需要引入适当的归纳偏置(inductive bias)。知道数据具有流形结构,我们可以设计相应的网络架构:
- 卷积神经网络:假设数据具有平移不变性(图像的流形结构)
- 循环神经网络:假设序列数据具有时间平移不变性
- 图神经网络:假设数据具有图结构(非欧几里得流形)
3. 理解泛化能力
神经网络的泛化能力与损失景观的几何性质密切相关——我们将在第四章详细讨论。
第二章:流形学习——展开弯曲的数据
在深度学习兴起之前,数学家们就已经发展了一套"流形学习"(Manifold Learning)的技术,用于从高维数据中发现低维结构。
2.1 经典算法巡礼
多维尺度分析(MDS, Multidimensional Scaling)
MDS 的目标是:给定数据点之间的距离矩阵,在低维空间中重构这些点,使得重构点之间的距离尽可能接近原始距离。
给定距离矩阵 $D = (d_{ij})$,MDS 寻找低维嵌入 ${ \mathbf{x}i }{i=1}^n$,使得:
$$\min_{\mathbf{x}_1, \ldots, \mathbf{x}n} \sum{i<j} (|\mathbf{x}_i - \mathbf{x}j| - d{ij})^2$$
MDS 的经典版本使用欧氏距离,但数据的内在距离可能不同——这就引出了 ISOMAP。
等距映射(ISOMAP)
ISOMAP 的核心洞见:在高维空间中应该使用测地距离(geodesic distance)而非欧氏距离。
测地距离是沿着流形测量的距离。对于地球表面的两个点,测地距离是沿着地球表面的大圆弧长,而不是穿过地心的直线距离。
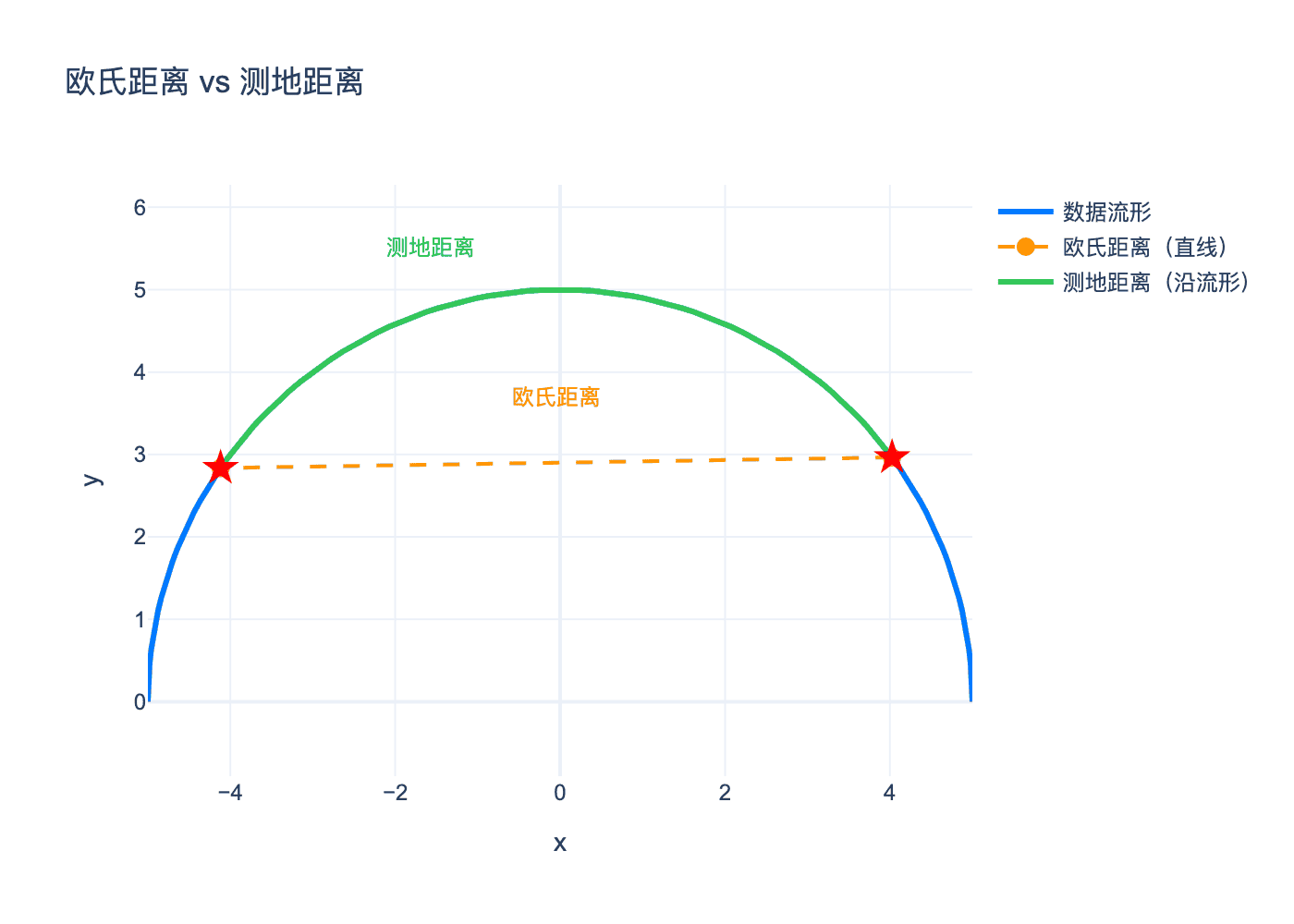 图2:欧氏距离(橙色虚线)穿过空间,而测地距离(绿色实线)沿着流形测量。对于弯曲的数据流形,测地距离更能反映数据的内在结构。
图2:欧氏距离(橙色虚线)穿过空间,而测地距离(绿色实线)沿着流形测量。对于弯曲的数据流形,测地距离更能反映数据的内在结构。
ISOMAP 算法步骤:
- 构建 $k$ 近邻图或 $\epsilon$ 邻域图
- 在图上计算最短路径(近似测地距离)
- 对测地距离矩阵应用 MDS
局部线性嵌入(LLE, Locally Linear Embedding)
LLE 的核心思想:局部来看,流形可以用线性空间近似。因此,每个数据点可以表示为近邻点的线性组合,这种关系应该在低维空间中保持。
算法步骤:
- 为每个点找到 $k$ 个近邻
- 计算权重 $W_{ij}$,使得 $\mathbf{x}i \approx \sum_j W{ij} \mathbf{x}_j$
- 在低维空间中寻找 $\mathbf{y}_i$,使得 $\mathbf{y}i \approx \sum_j W{ij} \mathbf{y}_j$
t-SNE 与 UMAP
这两种方法在现代数据可视化中广泛使用。
t-SNE(t-Distributed Stochastic Neighbor Embedding):
- 在高维空间中定义概率分布:$p_{j|i} \propto \exp(-|\mathbf{x}_i - \mathbf{x}_j|^2 / 2\sigma_i^2)$
- 在低维空间中定义类似分布:$q_{ij} \propto (1 + |\mathbf{y}_i - \mathbf{y}_j|^2)^{-1}$
- 最小化两个分布的 KL 散度
UMAP(Uniform Manifold Approximation and Projection):
- 基于模糊拓扑表示的理论框架
- 既保留局部结构,也保留全局结构
- 计算速度更快,适合大规模数据
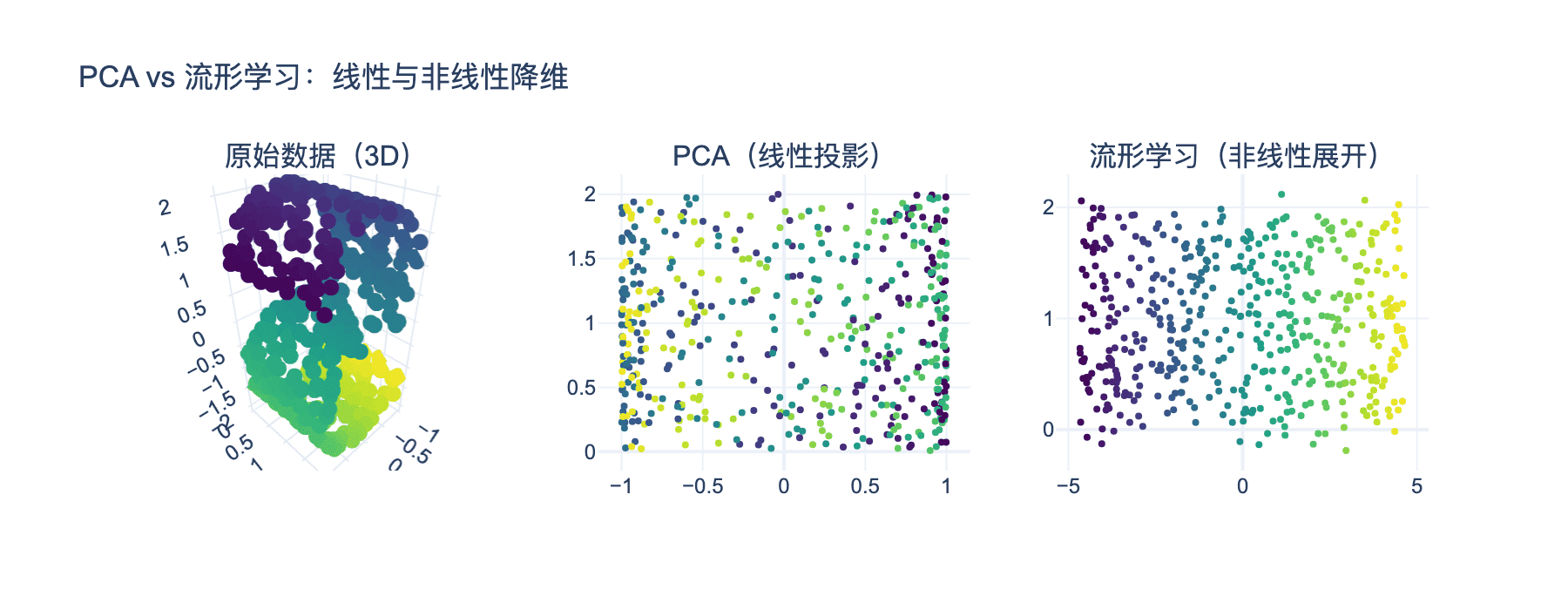 图3:PCA(线性投影)无法展开非线性流形,而流形学习方法能够发现数据的内在低维结构。
图3:PCA(线性投影)无法展开非线性流形,而流形学习方法能够发现数据的内在低维结构。
2.2 流形学习的数学本质
这些看似不同的算法,实际上都基于一个共同的几何洞察:
数据流形局部可以用切空间近似,全局则通过邻域图的连通性捕获。
用微分几何的语言:
- 局部:在点 $p$ 处的切空间 $T_p\mathcal{M}$ 提供了局部的线性近似
- 全局:邻域图定义了一个离散化的联络(connection),告诉我们在不同切空间之间如何"移动"向量
这种几何视角不仅统一了不同的流形学习算法,也启发了更现代的方法。
第三章:黎曼几何与优化
神经网络训练本质上是一个优化问题:在参数空间中寻找使损失函数最小的点。当参数具有几何约束(如正交矩阵、概率分布)时,我们需要在流形上进行优化。
3.1 黎曼梯度下降
在欧几里得空间中,梯度下降的更新规则是:
$$\theta_{k+1} = \theta_k - \alpha \nabla f(\theta_k)$$
但当参数 $\theta$ 约束在流形 $\mathcal{M}$ 上时,简单的减法可能使参数离开流形!
黎曼梯度下降的解决方案:
- 计算黎曼梯度:$\text{grad} f(\theta_k)$(在切空间 $T_{\theta_k}\mathcal{M}$ 中)
- 沿着测地线或收缩映射(retraction)更新:
$$\theta_{k+1} = \mathcal{R}_{\theta_k}(-\alpha , \text{grad} f(\theta_k))$$
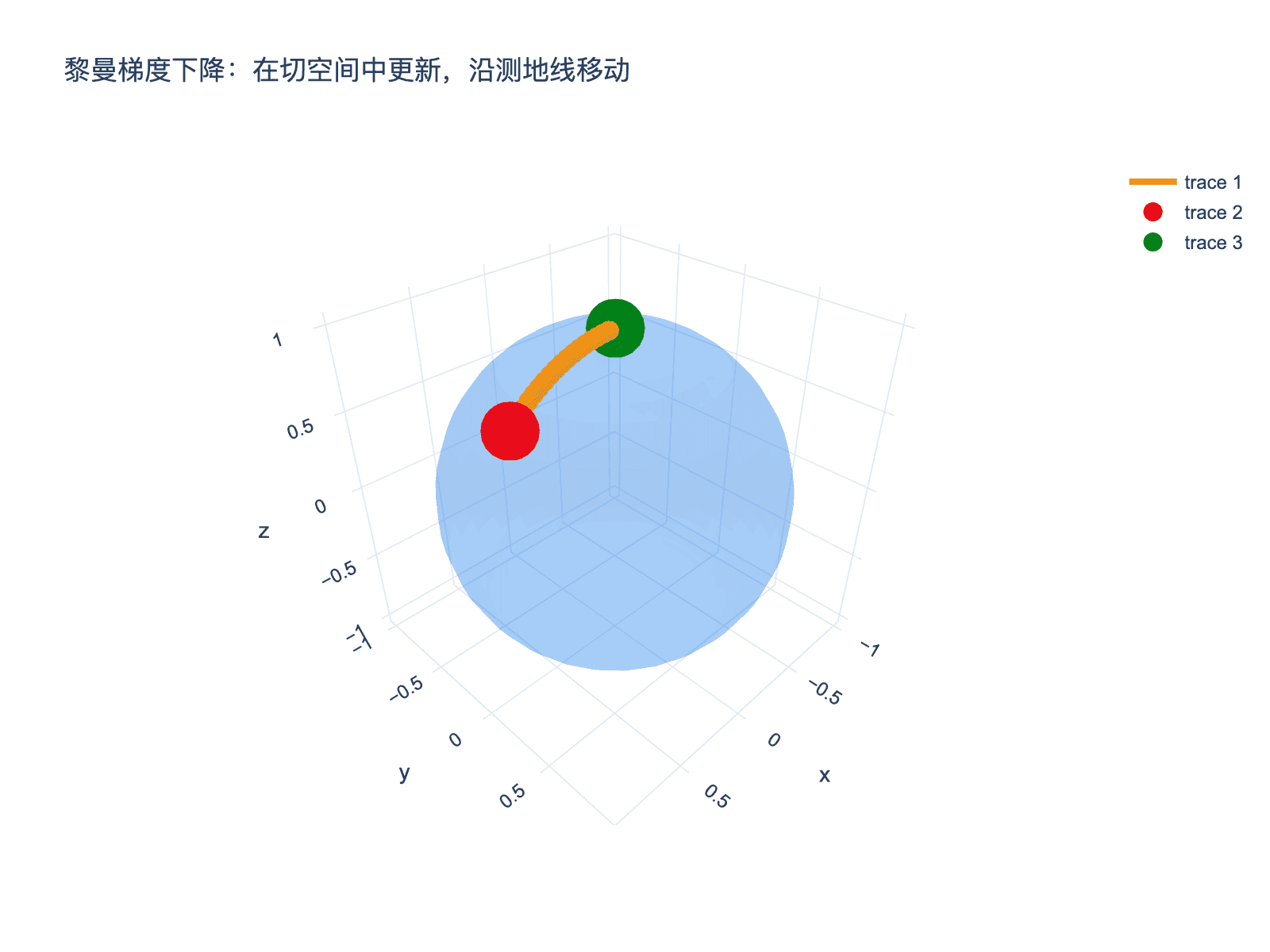 图4:黎曼梯度下降在切空间中计算更新方向,然后通过指数映射(沿测地线)回到流形。
图4:黎曼梯度下降在切空间中计算更新方向,然后通过指数映射(沿测地线)回到流形。
3.2 常见流形上的优化
球面 $S^{n-1}$:
归一化权重、正交约束常见于各种神经网络。
黎曼梯度投影:$\text{grad} f(\mathbf{x}) = \nabla f(\mathbf{x}) - \langle \nabla f(\mathbf{x}), \mathbf{x} \rangle \mathbf{x}$
收缩映射:$\mathcal{R}_{\mathbf{x}}(\mathbf{v}) = \frac{\mathbf{x} + \mathbf{v}}{|\mathbf{x} + \mathbf{v}|}$
Stiefel 流形 $\text{St}(n, k)$:
由所有 $n \times k$ 列正交矩阵组成:$\mathbf{X}^T \mathbf{X} = I_k$
应用于:
- 主成分分析的子空间迭代
- 正交权重的神经网络
- 低秩矩阵补全
对称正定矩阵流形 $\text{SPD}(n)$:
协方差矩阵、扩散张量成像(DTI)等应用。
几何性质:
- 具有自然的仿射不变度量
- 两点间的测地距离与对数欧氏度量相关
3.3 自然梯度下降
信息几何提供了一个深刻的洞察:参数空间不应该被视为平坦的欧几里得空间,而应该用Fisher 信息矩阵定义度量。
对于概率分布 $p(x; \theta)$,Fisher 信息矩阵为:
$$G_{ij}(\theta) = \mathbb{E}_{p(x;\theta)} \left[ \frac{\partial \log p(x;\theta)}{\partial \theta_i} \frac{\partial \log p(x;\theta)}{\partial \theta_j} \right]$$
自然梯度:
$$\tilde{\nabla} f = G^{-1} \nabla f$$
自然梯度下降考虑了参数空间的内在几何,通常具有更快的收敛速度和更好的泛化能力。
第四章:损失景观的几何
神经网络训练的非凸优化问题曾被认为难以处理。但实践发现,随机梯度下降(SGD)通常能找到高质量的解。理解这一现象需要研究损失景观(Loss Landscape)的几何性质。
4.1 损失景观的可视化
想象神经网络的参数空间是一个高维空间,每个点对应一组参数值。损失函数 $L(\theta)$ 在这个空间上定义了一个"景观":有山峰(高损失)、山谷(低损失)、鞍点等。
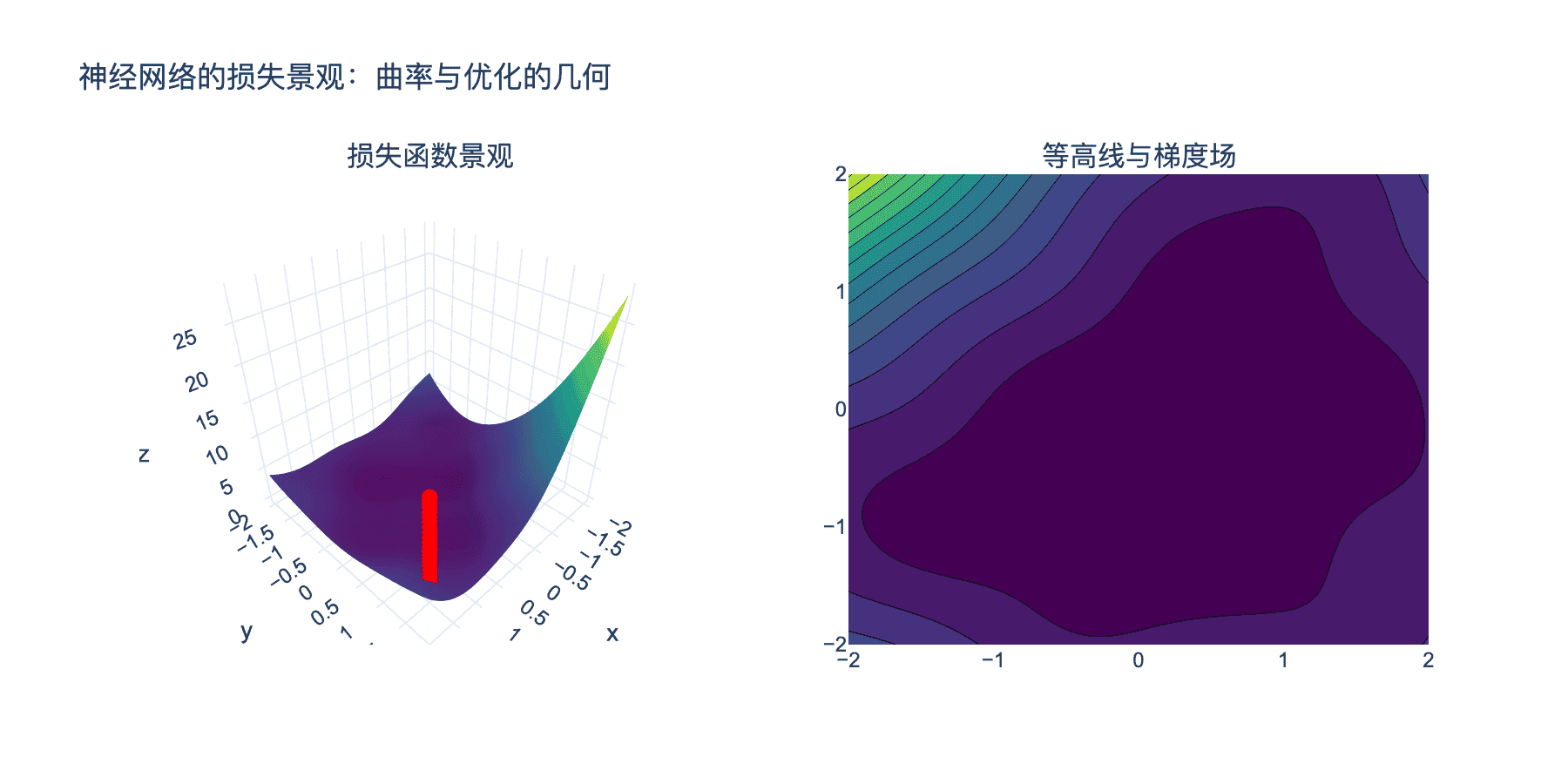 图5:神经网络的损失景观具有复杂的结构,包含多个局部最小值、鞍点和高原区域。优化算法需要在这个景观中找到通往低损失区域的路径。
图5:神经网络的损失景观具有复杂的结构,包含多个局部最小值、鞍点和高原区域。优化算法需要在这个景观中找到通往低损失区域的路径。
关键观察:
- 局部最小值并不像想象的那样多
- 大量存在的是鞍点
- 低损失区域往往是连通的(形成"山谷")
4.2 平坦最小值与泛化
一个重要的发现:损失景观的平坦程度与泛化能力相关。
直观理解:
- 平坦最小值:损失函数在最小值附近变化缓慢
- 尖锐最小值:损失函数在最小值附近变化剧烈
如果训练数据和测试数据有微小差异(分布偏移),平坦最小值处的模型表现更稳定。
量化平坦度:
- Hessian 矩阵的特征值:最大特征值越小,景观越平坦
- 有效维数:基于 Hessian 谱的度量
- 锐度(Sharpness):在局部邻域内的最大损失值
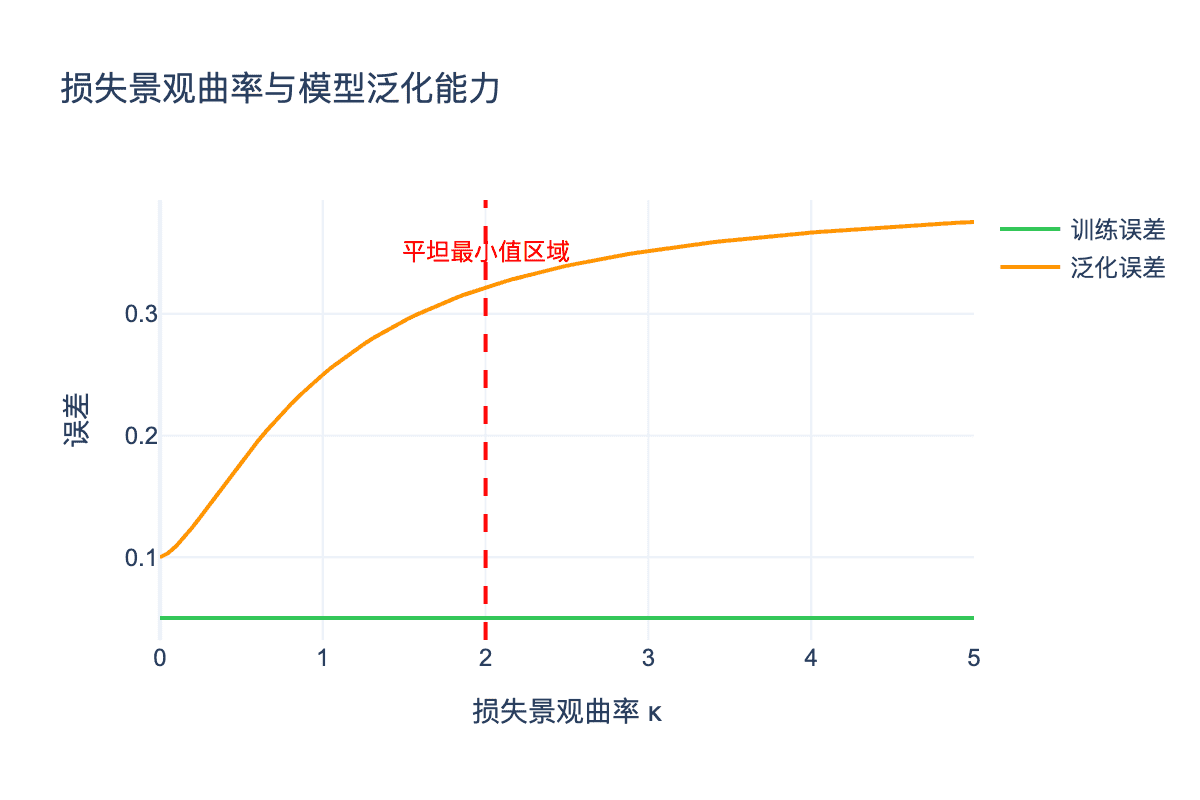 图6:损失景观的曲率与泛化误差的关系。平坦最小值(低曲率区域)通常对应更好的泛化能力。
图6:损失景观的曲率与泛化误差的关系。平坦最小值(低曲率区域)通常对应更好的泛化能力。
4.3 批量大小与景观探索
批量大小(batch size)影响 SGD 的噪声水平,从而影响探索损失景观的方式:
- 小批量:噪声大,有助于逃离尖锐最小值,找到平坦区域
- 大批量:噪声小,收敛快,但可能陷入尖锐最小值
学习率与批量大小的缩放律:
研究表明,要保持相似的泛化性能,学习率 $\eta$ 应该与批量大小 $B$ 成正比:$\eta \propto B$。
4.4 神经网络宽度的影响
神经正切核(NTK, Neural Tangent Kernel)理论揭示了一个惊人的事实:当神经网络足够宽时,其在初始化附近的动态可以用核方法描述。
在这一极限下:
- 损失景观在高维空间中变得简单
- 梯度下降几乎线性收敛到全局最小值
- 神经网络的函数空间变为一个再生核希尔伯特空间(RKHS)
虽然实际的有限宽度网络偏离这一极限,但 NTK 理论提供了重要的理论洞察。
第五章:几何深度学习
几何深度学习(Geometric Deep Learning)是一个新兴的框架,旨在将深度学习的成功从欧几里得数据(如图像、序列)推广到非欧几里得数据(如图、流形、点云)。
5.1 对称性与表示学习
几何深度学习的核心洞见:数据的对称性应该反映在神经网络的结构中。
对称群与等变性:
- 平移对称性(图像):卷积神经网络
- 置换对称性(点集、图):图神经网络
- 旋转对称性(3D 形状):$SO(3)$ 等变网络
- 规范对称性(物理系统):规范等变网络
等变性定义:
函数 $f$ 对群 $G$ 是等变的,如果对于所有 $g \in G$:
$$f(g \cdot x) = g \cdot f(x)$$
这意味着:先对输入进行变换再通过网络,与先通过网络再对输出进行变换,结果相同。
5.2 图神经网络
图是最普遍的非欧几里得数据结构之一。社交网络、分子结构、知识图谱都可以用图表示。
图卷积网络(GCN):
$$\mathbf{H}^{(l+1)} = \sigma\left(\tilde{\mathbf{D}}^{-1/2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1/2} \mathbf{H}^{(l)} \mathbf{W}^{(l)}\right)$$
其中:
- $\tilde{\mathbf{A}} = \mathbf{A} + \mathbf{I}$ 是添加自环的邻接矩阵
- $\tilde{\mathbf{D}}$ 是度矩阵
- $\mathbf{H}^{(l)}$ 是第 $l$ 层的节点特征
几何解释:
图卷积等价于在图上的拉普拉斯算子的谱域操作。从微分几何的角度,图是连续流形的离散近似,图拉普拉斯是拉普拉斯-贝尔特拉米算子的离散版本。
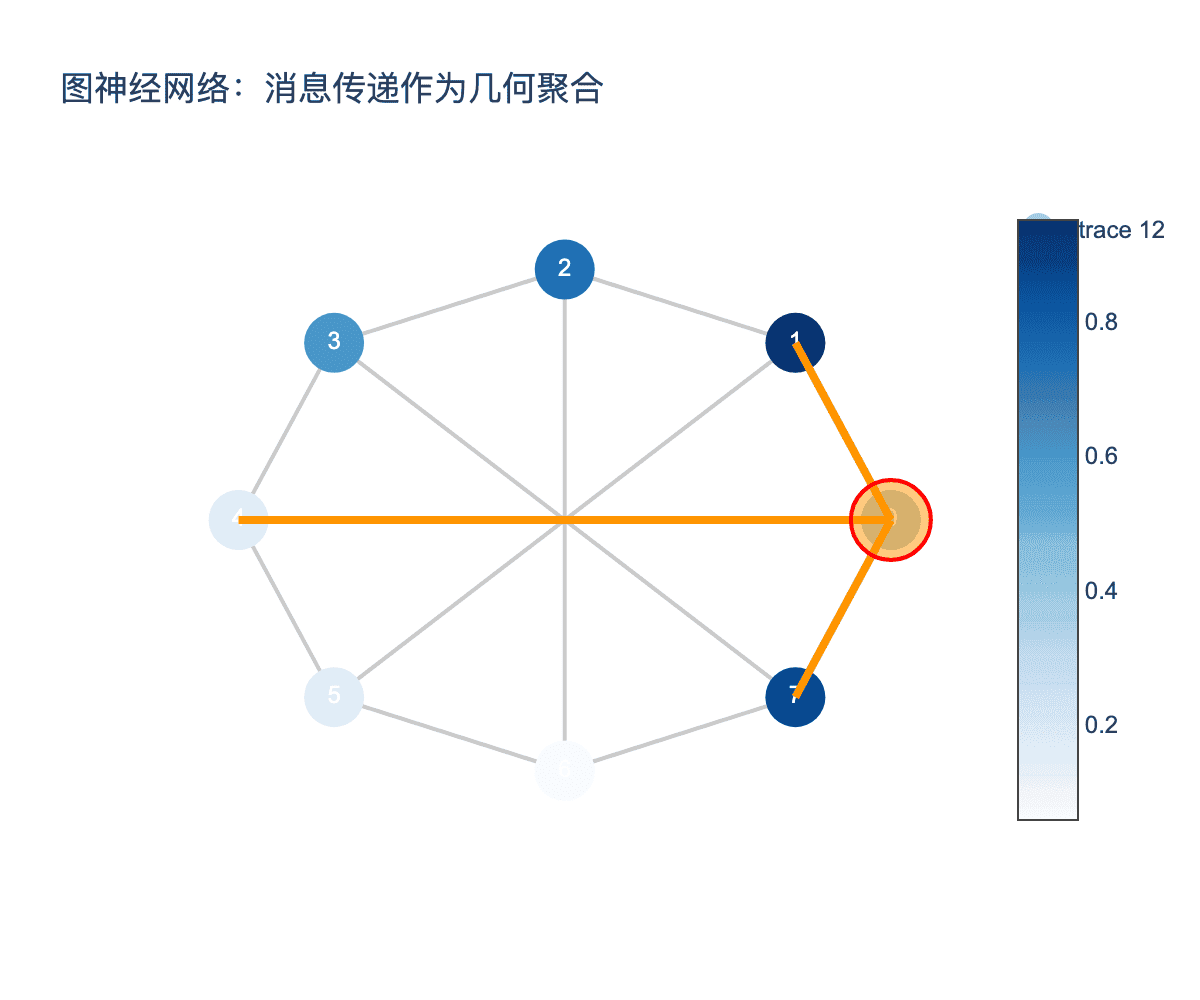 图7:图神经网络的消息传递机制可以看作是在图结构上进行几何聚合,每个节点收集邻居信息并更新自身表示。
图7:图神经网络的消息传递机制可以看作是在图结构上进行几何聚合,每个节点收集邻居信息并更新自身表示。
5.3 点云处理
激光雷达(LiDAR)输出的点云是三维空间中无序的点集合。处理点云的关键挑战是置换不变性:改变点的顺序不应改变输出。
PointNet:
$$f({ \mathbf{x}_1, \ldots, \mathbf{x}n }) = \gamma \left( \max{i} { h(\mathbf{x}_i) } \right)$$
通过共享的多层感知机 $h$ 和对称函数(max pooling),实现了置换不变性。
DGCNN(Dynamic Graph CNN):
在特征空间中构建动态图,捕获局部几何结构。
5.4 等变神经网络
对于具有连续对称性的数据(如 3D 旋转),需要设计等变网络。
$SO(3)$ 等变网络:
- 使用球谐函数作为基函数
- 特征为 $SO(3)$ 表示的直和
- 卷积核为可学习的径向函数与球谐函数的乘积
TFN(Tensor Field Networks)和 Cormorant 是这一方向的代表工作。
第六章:生成模型与微分几何
生成模型学习数据的分布,从而能够生成新样本。从几何角度看,这是学习从高维噪声空间到数据流形的映射。
6.1 流形学习与生成模型
变分自编码器(VAE):
VAE 学习编码器 $q_\phi(\mathbf{z}|\mathbf{x})$ 和解码器 $p_\theta(\mathbf{x}|\mathbf{z})$。隐变量 $\mathbf{z}$ 通常假设服从标准正态分布。
几何视角:
- 解码器定义了一个从隐空间到数据空间的嵌入映射
- 数据流形是隐空间在解码器下的像
- 后验坍缩(posterior collapse)可以理解为映射的病态几何
生成对抗网络(GAN):
GAN 的生成器 $G: \mathcal{Z} \to \mathcal{X}$ 学习从简单分布(如高斯噪声)到数据分布的映射。
几何挑战:
- 模式坍缩(mode collapse):生成器只覆盖了数据流形的子集
- 训练不稳定:与最优传输理论的深层联系
6.2 标准化流与可逆映射
标准化流(Normalizing Flows)通过一系列可逆变换,将简单分布(如高斯分布)变换为复杂的数据分布。
$$\mathbf{x} = f_K \circ f_{K-1} \circ \cdots \circ f_1(\mathbf{z})$$
由于变换可逆,密度可以通过变量替换公式精确计算:
$$p(\mathbf{x}) = p(\mathbf{z}) \left| \det \frac{\partial f^{-1}}{\partial \mathbf{x}} \right|$$
几何意义:
标准化流学习的是数据流形与隐空间之间的微分同胚(diffeomorphism)。这要求数据流形与隐空间具有相同的拓扑结构。
6.3 扩散模型与随机微分几何
扩散模型(Diffusion Models)是近年来生成模型领域的重大突破。
基本思想:
- 前向过程:向数据逐步添加噪声,直到变成纯噪声
- 反向过程:学习从噪声恢复数据的逆向过程
前向过程可以用随机微分方程(SDE)描述:
$$d\mathbf{x} = \mathbf{f}(\mathbf{x}, t) dt + g(t) d\mathbf{w}$$
几何视角:
- 前向过程将数据流形"模糊"到整个空间
- 反向过程在概率测度的空间中构造一条路径
- 得分匹配(score matching)学习的是对数密度的梯度,即得分函数
第七章:前沿方向与展望
微分几何与深度学习的交叉仍在快速发展。以下是几个激动人心的前沿方向。
7.1 信息几何与深度学习
信息几何研究概率分布空间的几何结构。Fisher 信息矩阵定义了自然的黎曼度量,$\alpha$-联络提供了丰富的几何结构。
应用方向:
- 自然梯度优化:利用几何信息加速训练
- 贝叶斯神经网络:在概率分布空间中进行推断
- 元学习:学习学习算法本身的几何
7.2 曲率与神经网络架构
最近的研究发现,神经网络的训练动态与Ricci 曲率有关:
- 正曲率区域可能导致梯度消失
- 负曲率区域有助于探索
这一发现启发新的架构设计和优化策略。
7.3 拓扑数据分析
拓扑数据分析(TDA)使用代数拓扑的工具研究数据的形状特征。
持续同调(Persistent Homology)可以检测数据中的拓扑特征(连通分支、洞、空洞等),无论数据如何变形。
与深度学习的结合:
- 使用拓扑特征增强网络输入
- 拓扑约束的正则化
- 理解神经网络的表示空间拓扑
7.4 因果推断的几何
因果推断旨在从观测数据中发现因果关系。几何方法提供了新的视角:
- 因果结构可以用因果图(DAG)表示
- 因果模型构成一个统计流形
- 因果发现等价于在这个流形中寻找特定的几何结构
结语:几何思维的力量
回顾我们的旅程,从流形假设的直觉洞察,到黎曼优化和损失景观的几何分析,再到现代的几何深度学习,微分几何为理解深度学习提供了强大的语言和工具。
核心洞察总结:
数据的流形结构:真实数据往往分布在低维流形上,这解释了深度学习在高维空间中的有效性。
优化的几何:损失景观的几何性质(平坦性、曲率)与泛化能力密切相关;黎曼优化提供了在约束流形上训练的方法。
对称性与等变性:数据的对称性应该反映在神经网络的结构中,这是几何深度学习的核心原则。
生成模型的几何:学习数据分布等价于学习流形的参数化和测度。
展望未来:
随着深度学习从感知任务走向推理、规划和决策,对结构化数据的处理需求将越来越迫切。微分几何——这门研究形状、结构和弯曲空间的数学——将在这一进程中扮演越来越重要的角色。
“几何学是数学中最古老的分支之一,但它正在人工智能时代焕发新的生机。理解几何不仅是理解数学,更是理解智能本身。”
希望这篇文章为你打开了通往几何深度学习的大门。在这个弯曲而美丽的数学世界中,还有无数宝藏等待发掘。
参考文献
LeCun, Y., Bengio, Y., & Hinton, G. (2015). “Deep learning.” Nature, 521(7553), 436-444.
Bronstein, M. M., Bruna, J., Cohen, T., & Veličković, P. (2021). “Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.” arXiv:2104.13478.
Amari, S. (2016). Information Geometry and Its Applications. Springer.
do Carmo, M. P. (1992). Riemannian Geometry. Birkhäuser.
Tenenbaum, J. B., De Silva, V., & Langford, J. C. (2000). “A global geometric framework for nonlinear dimensionality reduction.” Science, 290(5500), 2319-2323.
Roweis, S. T., & Saul, L. K. (2000). “Nonlinear dimensionality reduction by locally linear embedding.” Science, 290(5500), 2323-2326.
Absil, P. A., Mahony, R., & Sepulchre, R. (2008). Optimization Algorithms on Matrix Manifolds. Princeton University Press.
Hochreiter, S., & Schmidhuber, J. (1997). “Flat minima.” Neural Computation, 9(1), 1-42.
McInnes, L., Healy, J., & Melville, J. (2018). “UMAP: Uniform manifold approximation and projection for dimension reduction.” arXiv:1802.03426.
Kipf, T. N., & Welling, M. (2017). “Semi-supervised classification with graph convolutional networks.” ICLR.
本文旨在为有一定数学基础的读者提供微分几何在深度学习中应用的系统综述。如需更深入的理解,建议参考相关教材和最新研究论文。