
引言:一个时代的分水岭
$2012$ 年 $9$ 月 $30$ 日,多伦多大学的研究团队在 ImageNet 大规模视觉识别挑战赛(ILSVRC)上提交了一个卷积神经网络模型。当时,没有人意识到这将是一个历史性的时刻。
这个模型叫做 AlexNet,以第一作者 Alex Krizhevsky 的名字命名。它在图像分类任务上将 Top-5 错误率从上一年的 $25.8%$ 骤降至 $16.4%$——降幅接近 $10$ 个百分点,远超第二名近 $10%$。
这不是一次普通的进步,这是一次范式革命。
在此之前,深度学习经历了漫长的"寒冬"。尽管 $1986$ 年反向传播算法已被提出,$1998$ 年 LeCun 的 LeNet 已经证明了卷积神经网络的潜力,但深层网络的训练一直受困于梯度消失、计算资源匮乏和数据不足等问题。
AlexNet 的突破不仅在于它赢得了比赛,更在于它证明了:深度神经网络可以在大规模数据集上有效训练,并且性能远超传统方法。
这一证明,开启了人工智能的新纪元。
第一章:黎明前的黑暗——深度学习的寒冬
1.1 感知机的兴衰
要理解 AlexNet 的意义,我们需要回溯到神经网络的起源。
$1958$ 年,Frank Rosenblatt 提出了感知机(Perceptron),这是第一个能够学习的神经网络模型。Rosenblatt 乐观地宣称:“感知机最终将能够学习、做出决策和翻译语言。”
然而,$1969$ 年,Marvin Minsky 和 Seymour Papert 在《Perceptrons》一书中证明了感知机的局限性:它无法解决非线性可分问题,比如简单的异或(XOR)问题。
这个打击是致命的。神经网络研究陷入了第一次寒冬。
1.2 反向传播的曙光与困境
$1986$ 年,Rumelhart、Hinton 和 Williams 重新发现了反向传播算法(Backpropagation),为训练多层神经网络提供了理论基础。
反向传播的核心思想:
给定损失函数 $L$,网络参数 $\mathbf{W}$,反向传播通过链式法则计算梯度:
$$\frac{\partial L}{\partial w_{ij}^{(l)}} = \frac{\partial L}{\partial z_i^{(l)}} \cdot \frac{\partial z_i^{(l)}}{\partial w_{ij}^{(l)}} = \delta_i^{(l)} \cdot a_j^{(l-1)}$$
其中 $\delta_i^{(l)}$ 是第 $l$ 层第 $i$ 个神经元的误差信号。
然而,尽管有了理论工具,实际应用仍然受限:
- 梯度消失问题:使用 Sigmoid 或 Tanh 激活函数时,深层网络的梯度会指数级衰减
- 计算资源:$1980$ 年代的计算机无法处理大规模数据
- 数据集太小:没有足够的标注数据来训练深层网络
1.3 LeNet-5:先驱者的尝试
$1998$ 年,Yann LeCun 等人提出了 LeNet-5,这是一个 $5$ 层的卷积神经网络,成功应用于手写数字识别(MNIST 数据集)。
LeNet-5 的架构已经包含了现代 CNN 的核心要素:
- 卷积层(Convolution)
- 池化层(Pooling)
- 全连接层(Fully Connected)
但由于上述限制,LeNet-5 之后,深度学习并没有立即起飞。相反,支持向量机(SVM)和随机森林等传统机器学习方法在 $2000$ 年代占据了主导地位。
第二章:ImageNet——大数据的觉醒
2.1 数据集的重要性
任何机器学习方法的效果都受限于三个因素:
- 算法:模型的表达能力
- 计算:训练和推理的速度
- 数据:训练样本的数量和质量
在 $2010$ 年之前,计算机视觉领域的主流数据集规模很小:
- MNIST:$60,000$ 张 $28 \times 28$ 的手写数字
- Caltech-101:$9,144$ 张图片,$101$ 个类别
- PASCAL VOC:$20$ 个类别,每年约 $10,000$ 张图片
这些数据集对于浅层模型足够,但无法支撑深层网络的训练。
2.2 ImageNet 的诞生
$2009$ 年,斯坦福大学的李飞飞教授团队发布了 ImageNet 数据集。这是一个具有划时代意义的项目:
- 规模:超过 $1,400$ 万张图片
- 类别:$21,841$ 个类别(WordNet 层次结构)
- 标注:每张图片都经过人工标注验证
更重要的是,从 $2010$ 年开始,ImageNet 举办了年度挑战赛(ILSVRC),使用 $1,000$ 个类别的子集,每类约 $1,000$ 张训练图片。
2.3 传统方法的瓶颈
在 AlexNet 出现之前,ILSVRC 的优胜者都使用传统方法:
- SIFT(尺度不变特征变换)提取局部特征
- HOG(方向梯度直方图)描述形状
- Bag of Visual Words 编码
- SVM 或 随机森林 分类
这些方法在 $2010$ 年和 $2011$ 年的 Top-5 错误率分别为 $28.2%$ 和 $25.8%$,改进幅度很小。
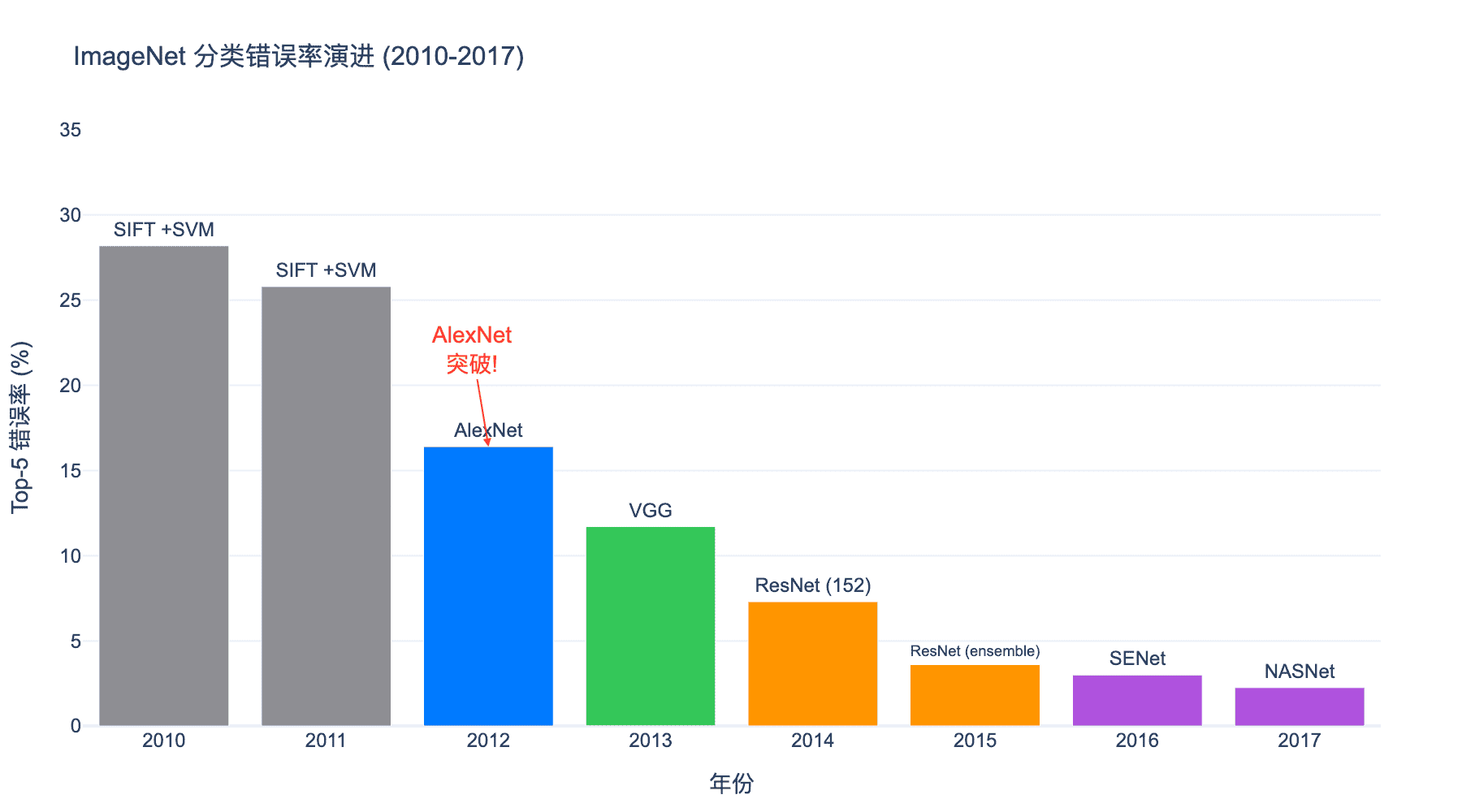
图1:ImageNet 分类错误率演进(2010-2017)。AlexNet 在 2012 年实现了历史性的突破,将错误率从 25.8% 降至 16.4%,开启了深度学习革命。
第三章:AlexNet 架构详解
3.1 网络架构概览
AlexNet 包含 $8$ 层可学习层:$5$ 个卷积层和 $3$ 个全连接层。输入是 $224 \times 224 \times 3$ 的 RGB 图像,输出是 $1,000$ 个类别的 Softmax 概率。

图2:AlexNet 网络架构。包含 5 个卷积层(蓝色)和 3 个全连接层(橙色),使用 GPU 并行训练。
详细架构:
| 层 | 类型 | 核大小 | 步长 | 输出尺寸 | 参数数量 |
|---|---|---|---|---|---|
| 1 | Conv + ReLU + LRN | $11 \times 11$ | 4 | $55 \times 55 \times 96$ | $35,000$ |
| 2 | MaxPool | $3 \times 3$ | 2 | $27 \times 27 \times 96$ | $0$ |
| 3 | Conv + ReLU + LRN | $5 \times 5$ | 1 | $27 \times 27 \times 256$ | $307,000$ |
| 4 | MaxPool | $3 \times 3$ | 2 | $13 \times 13 \times 256$ | $0$ |
| 5 | Conv + ReLU | $3 \times 3$ | 1 | $13 \times 13 \times 384$ | $885,000$ |
| 6 | Conv + ReLU | $3 \times 3$ | 1 | $13 \times 13 \times 384$ | $1,327,000$ |
| 7 | Conv + ReLU | $3 \times 3$ | 1 | $13 \times 13 \times 256$ | $885,000$ |
| 8 | MaxPool | $3 \times 3$ | 2 | $6 \times 6 \times 256$ | $0$ |
| 9 | FC + ReLU + Dropout | - | - | $4096$ | $37,748,000$ |
| 10 | FC + ReLU + Dropout | - | - | $4096$ | $16,777,000$ |
| 11 | FC + Softmax | - | - | $1000$ | $4,097,000$ |
总参数量:约 $6,000$ 万个参数。
3.2 卷积层的数学原理
卷积操作是 CNN 的核心。给定输入特征图 $\mathbf{X}$ 和卷积核 $\mathbf{K}$,输出特征图 $\mathbf{Y}$ 的计算为:
$$Y_{i,j} = \sum_{m=0}^{k-1} \sum_{n=0}^{k-1} K_{m,n} \cdot X_{i+m, j+n} + b$$
其中 $k$ 是核大小,$b$ 是偏置项。
在矩阵形式下,这可以表示为:
$$\mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b}$$
AlexNet 使用较大的初始卷积核($11 \times 11$,步长 $4$)来快速降低特征图尺寸,后续使用较小的核($3 \times 3$ 和 $5 \times 5$)提取更精细的特征。
3.3 GPU 并行架构
AlexNet 的创新之一是使用了两块 GTX 580 GPU 进行并行训练。网络被分成两部分:
- GPU 1 处理下层特征(颜色、纹理)
- GPU 2 处理上层特征(形状、语义)
这种架构设计使得在当时硬件条件下能够训练更大的网络。
第四章:三大技术创新
4.1 ReLU:打破梯度消失的枷锁
传统的激活函数如 Sigmoid 和 Tanh 存在一个致命问题:梯度消失。
Sigmoid 函数定义为:
$$\sigma(z) = \frac{1}{1 + e^{-z}}$$
其导数为:
$$\sigma’(z) = \sigma(z)(1 - \sigma(z))$$
当 $|z|$ 较大时,$\sigma(z)$ 接近 $0$ 或 $1$,导数趋近于 $0$。在反向传播中,这导致梯度逐层衰减,深层网络难以训练。
ReLU(Rectified Linear Unit)的定义非常简单:
$$f(z) = \max(0, z)$$
其导数为:
$$f’(z) = \begin{cases} 1 & \text{if } z > 0 \ 0 & \text{if } z < 0 \ \text{undefined} & \text{if } z = 0 \end{cases}$$
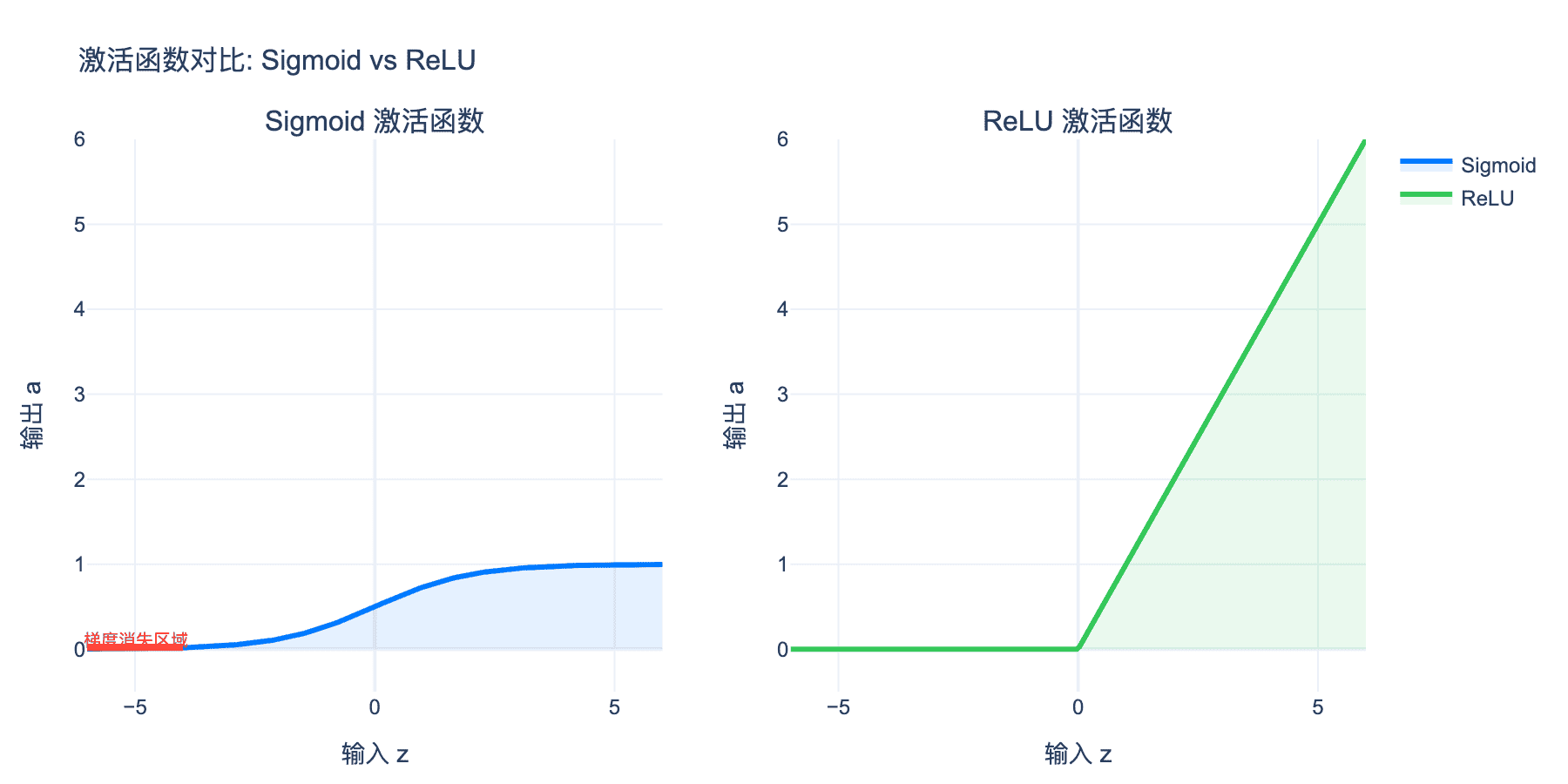
图3:Sigmoid 与 ReLU 激活函数对比。Sigmoid 在两端出现梯度消失(红色区域),而 ReLU 在正区间保持恒定的梯度,有效缓解了梯度消失问题。
ReLU 的优势:
- 计算简单:只需比较和取最大值,无需指数运算
- 缓解梯度消失:正区间梯度恒为 $1$
- 稀疏激活:约 $50%$ 的神经元输出为 $0$,提高计算效率
- 生物学合理性:与生物神经元的激活机制类似
AlexNet 的实验表明,使用 ReLU 可以使训练速度提升约 $6$ 倍!
4.2 Dropout:防止过拟合的武器
深层神经网络面临严重的过拟合风险。AlexNet 有 $6,000$ 万个参数,而训练数据只有 $120$ 万张图片,参数数量远超数据量。
Dropout 是一种简单而有效的正则化技术。在训练过程中,以概率 $p$(通常 $p = 0.5$)随机"丢弃"(设为 $0$)一部分神经元的输出:
$$\tilde{\mathbf{a}}^{(l)} = \mathbf{m}^{(l)} \odot \mathbf{a}^{(l)}$$
其中 $\mathbf{m}^{(l)}$ 是服从 Bernoulli$(p)$ 分布的掩码向量。

图4:Dropout 正则化示意。在训练时随机丢弃部分隐藏层神经元(灰色),测试时使用所有神经元但调整权重。
为什么 Dropout 有效?
- 集成学习视角:每次训练迭代相当于训练一个不同的子网络,最终结果是多个子网络的平均
- 打破共适应:防止神经元过度依赖特定其他神经元
- 稀疏表示:鼓励网络学习更鲁棒的特征
测试时的调整:
训练时丢弃比例为 $p$,测试时需要将权重乘以 $p$ 来补偿:
$$\mathbf{W}{\text{test}} = p \cdot \mathbf{W}{\text{train}}$$
或使用inverted dropout:训练时将保留的神经元输出除以 $p$,测试时无需调整。
AlexNet 在前两个全连接层使用 Dropout,丢弃率设为 $0.5$,显著降低了过拟合。
4.3 数据增强:扩大数据集的艺术
$120$ 万张训练图片对于 $6,000$ 万个参数来说仍然不够。AlexNet 使用了一系列数据增强技术来人工扩大训练集:
随机裁剪与翻转:
- 从 $256 \times 256$ 图片随机裁剪 $224 \times 224$ 区域
- 水平随机翻转
- 每张图片可以生成 $2048$ 个不同的训练样本
PCA 颜色增强:
对 RGB 通道进行主成分分析,然后添加随机扰动:
$$\begin{pmatrix} I_{xy}^R \ I_{xy}^G \ I_{xy}^B \end{pmatrix} = \begin{pmatrix} I_{xy}^R \ I_{xy}^G \ I_{xy}^B \end{pmatrix} + \begin{pmatrix} \mathbf{p}_1 & \mathbf{p}_2 & \mathbf{p}_3 \end{pmatrix} \begin{pmatrix} \alpha_1 \lambda_1 \ \alpha_2 \lambda_2 \ \alpha_3 \lambda_3 \end{pmatrix}$$
其中 $\mathbf{p}_i$ 是特征向量,$\lambda_i$ 是特征值,$\alpha_i$ 是服从 $\mathcal{N}(0, 0.1)$ 的随机变量。
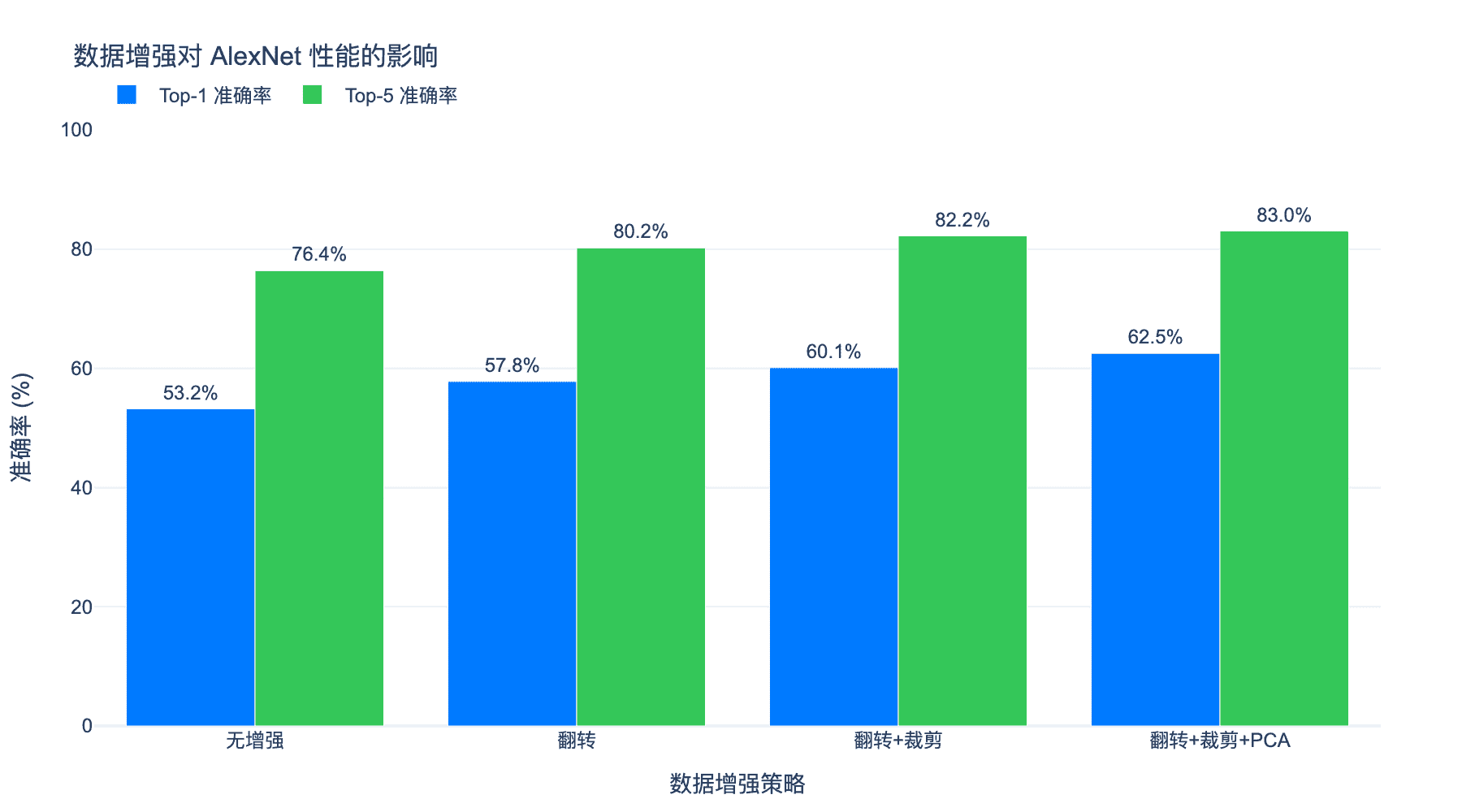
图5:数据增强对 AlexNet 性能的影响。从无增强到完整的增强策略,Top-1 和 Top-5 准确率都有显著提升。
第五章:训练过程与优化
5.1 损失函数
AlexNet 使用 Softmax 交叉熵损失(Cross-Entropy Loss)。对于 $K$ 类分类问题:
$$L = -\frac{1}{N} \sum_{i=1}^{N} \sum_{k=1}^{K} y_{i,k} \log(\hat{y}_{i,k})$$
其中 $\hat{y}{i,k} = \frac{e^{z{i,k}}}{\sum_{j} e^{z_{i,j}}}$ 是 Softmax 输出。
5.2 随机梯度下降
AlexNet 使用带动量的 SGD(Stochastic Gradient Descent):
$$\mathbf{v}_{t+1} = \mu \mathbf{v}_t - \epsilon \nabla L(\mathbf{W}t)$$ $$\mathbf{W}{t+1} = \mathbf{W}t + \mathbf{v}{t+1}$$
参数设置:
- 批量大小(batch size):$128$
- 动量(momentum):$0.9$
- 权重衰减(L2 正则化):$0.0005$
- 初始学习率:$0.01$
学习率调整策略:
每当验证误差停止下降时,将学习率除以 $10$。总共降低了 $3$ 次,学习率从 $0.01$ 降到 $0.0001$。
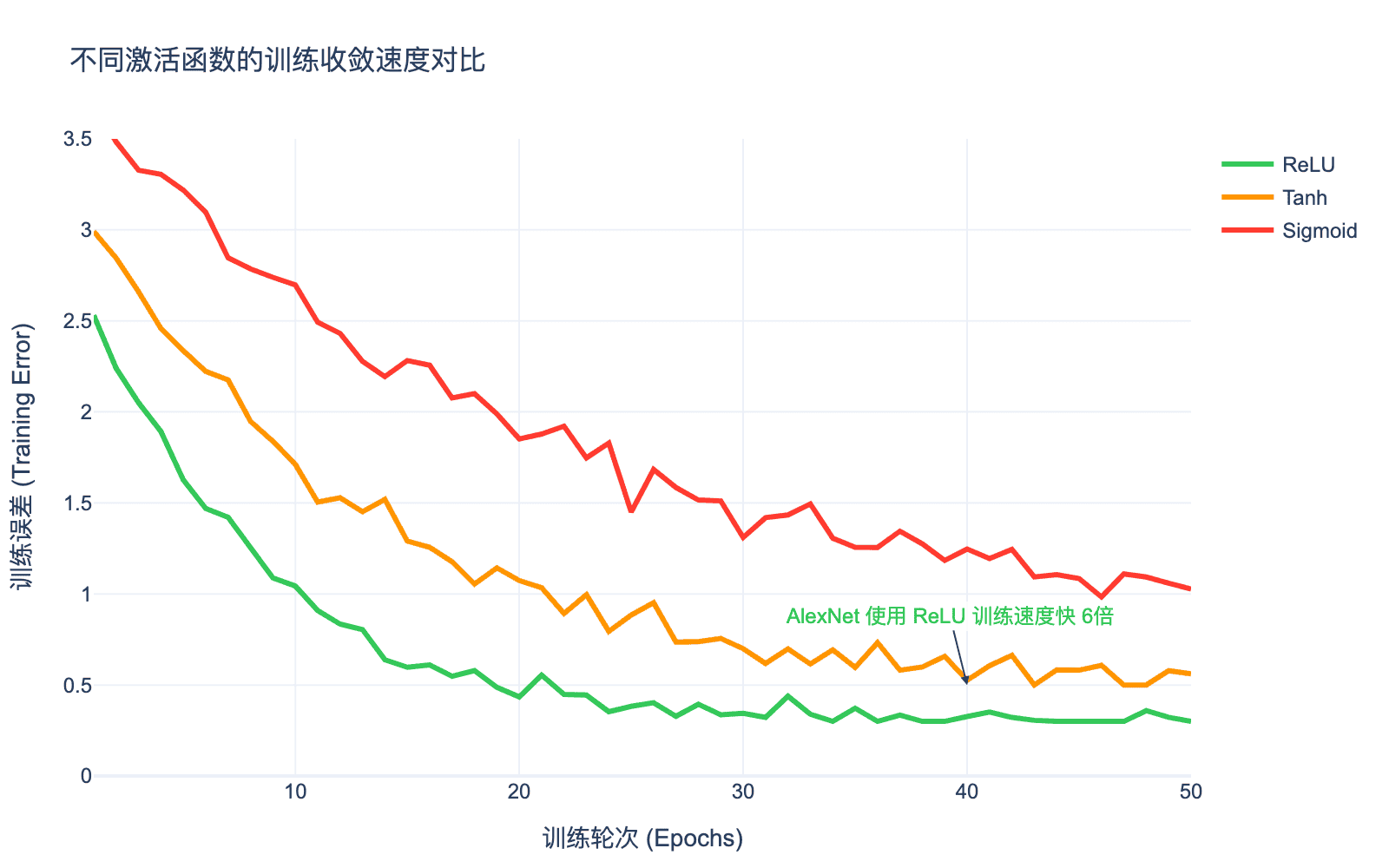
图6:不同激活函数的训练收敛速度对比。ReLU 的收敛速度明显快于 Sigmoid 和 Tanh,这对于训练深层网络至关重要。
5.3 权重初始化
深层网络的权重初始化至关重要。AlexNet 使用:
$$W_{ij} \sim \mathcal{N}(0, 0.01^2)$$
偏置初始化为:
- 第 $2$、$4$、$5$ 卷积层和全连接层:初始化为 $1$(加速早期学习)
- 其他层:初始化为 $0$
5.4 批量归一化的先驱——LRN
虽然 AlexNet 使用了 LRN(Local Response Normalization,局部响应归一化),但后来被批量归一化(Batch Normalization)取代。LRN 的公式为:
$$b_{x,y}^i = \frac{a_{x,y}^i}{\left( k + \alpha \sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)} (a_{x,y}^j)^2 \right)^\beta}$$
参数设置:$k = 2$,$n = 5$,$\alpha = 10^{-4}$,$\beta = 0.75$。
第六章:实验结果与历史影响
6.1 ImageNet 2012 结果
AlexNet 在 ILSVRC-2012 上的表现:
| 指标 | AlexNet | 第二名(传统方法) | 提升 |
|---|---|---|---|
| Top-1 错误率 | $37.5%$ | $45.7%$ | $8.2%$ |
| Top-5 错误率 | $16.4%$ | $26.2%$ | $9.8%$ |
这个差距是压倒性的。更重要的是,错误率的下降趋势表明,深度学习还有巨大的提升空间。
6.2 特征可视化
AlexNet 的一个重要贡献是特征可视化。通过可视化第一层的卷积核,可以看到网络学到了什么:
- 第 $1$ 层:检测边缘、颜色、纹理等低级特征
- 第 $3$、$4$ 层:检测形状、模式等中级特征
- 第 $5$ 层:检测物体部件、语义等高级特征
这验证了深度学习的核心假设:层次化特征提取。
6.3 迁移学习的证明
AlexNet 还展示了迁移学习的潜力。在 ImageNet 上预训练的模型,通过微调(fine-tuning)可以在其他任务上取得优异表现:
- Caltech-101:$91.5%$(之前 $86.5%$)
- Oxford Flowers:$89.5%$(之前 $72.8%$)
- PASCAL VOC:$77.8%$(之前 $59.3%$)
这证明了深度学习学到的特征是通用的、可迁移的。
第七章:后续发展与深度学习浪潮
7.1 紧随其后:ZFNet 和 VGG
ZFNet(2013):
- 调整 AlexNet 的超参数
- 使用反卷积可视化特征
- 错误率降至 $11.7%$
VGGNet(2014):
- 使用更小的 $3 \times 3$ 卷积核
- 网络深度达到 $16$-$19$ 层
- 证明了"深度"的重要性
7.2 ResNet:更深的选择
$2015$ 年,ResNet 将网络深度推向 $152$ 层甚至 $1000$ 层以上,错误率降至 $3.6%$(首次超越人类水平 $5.1%$)。
残差学习的核心思想:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}, {W_i}) + \mathbf{x}$$
通过跳跃连接(skip connection),网络只需要学习残差 $\mathcal{F}(\mathbf{x})$,而非完整映射。
7.3 AlexNet 的遗产
AlexNet 引入的技术至今仍被使用:
- ReLU:所有现代 CNN 的标准激活函数
- Dropout:正则化的标准技术之一
- GPU 训练:深度学习的标准配置
- 数据增强:数据预处理的标准流程
更重要的是,AlexNet 证明了深度学习是可行的,从而引发了:
- 学术界对深度学习的研究热潮
- 工业界对 AI 的大规模投资
- 计算机视觉领域的革命性进展
结语:从寒冬到春天
回顾 AlexNet 的历史,我们看到的是科学发展中常见的模式:
- 理论基础早已存在(反向传播 $1986$ 年,卷积网络 $1998$ 年)
- 技术条件的成熟(GPU 计算能力,ImageNet 数据集)
- 关键创新(ReLU、Dropout、数据增强)
- 一次突破性的演示(ImageNet 2012)
- 范式的转变(从传统方法到深度学习)
AlexNet 不是一夜之间的奇迹,而是几十年研究积累的结果,加上恰到好处的时机和关键的技术创新。
对于今天的我们,AlexNet 的故事有几点启示:
理论不会自动转化为应用:需要工程师的智慧来解决实际问题。
硬件和数据同样重要:好的算法需要合适的土壤才能生长。
简单的想法往往最有效:ReLU 和 Dropout 的原理都很简单,但效果惊人。
科学是累积的:LeCun 的 LeNet、Hinton 的坚持、李飞飞的 ImageNet,都是 AlexNet 成功的基石。
今天,当我们使用 GPT 进行对话、用 Stable Diffusion 生成图像、让自动驾驶汽车识别路况时,都不应该忘记 $2012$ 年那个秋天,一个 $8$ 层的神经网络在 ImageNet 上投下的那颗石子,激起了人工智能的滔天巨浪。
附录:关键公式汇总
卷积操作
$$Y_{i,j} = \sum_{m=0}^{k-1} \sum_{n=0}^{k-1} K_{m,n} \cdot X_{i+m, j+n} + b$$
ReLU 激活函数
$$f(z) = \max(0, z)$$
Softmax 与交叉熵损失
$$\hat{y}k = \frac{e^{z_k}}{\sum{j=1}^{K} e^{z_j}}$$
$$L = -\sum_{k=1}^{K} y_k \log(\hat{y}_k)$$
SGD with Momentum
$$\mathbf{v}_{t+1} = \mu \mathbf{v}_t - \epsilon \nabla L(\mathbf{W}t)$$ $$\mathbf{W}{t+1} = \mathbf{W}t + \mathbf{v}{t+1}$$
Dropout
训练:$\tilde{\mathbf{a}} = \mathbf{m} \odot \mathbf{a}$,其中 $m_i \sim \text{Bernoulli}(p)$
测试:$\mathbf{a}_{\text{test}} = p \cdot \mathbf{a}$
延伸阅读:
- Krizhevsky et al. “ImageNet Classification with Deep Convolutional Neural Networks.” NIPS 2012.
- LeCun et al. “Gradient-Based Learning Applied to Document Recognition.” 1998.
- Simonyan & Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” ICLR 2015.
- He et al. “Deep Residual Learning for Image Recognition.” CVPR 2016.
愿你在深度学习的世界里,找到属于自己的那颗石子。