引言:从二十个问题到机器学习
想象你在玩一个经典游戏——“二十个问题”。你需要通过最多二十个 yes/no 问题,猜出对手心中想的一个物体。聪明的玩家会问这样的问题:
- “它是活的吗?”
- “如果活着,它是动物吗?”
- “如果是动物,它会飞吗?”
每一个问题都将可能的答案空间一分为二,逐步缩小范围,直到锁定目标。这种分而治之的策略,正是决策树算法的核心思想。
决策树是机器学习中最直观、最易于解释的算法之一。从医学诊断到信用评估,从游戏 AI 到推荐系统,决策树及其衍生算法无处不在。它的魅力在于:
- 可解释性强:决策路径清晰,非技术人员也能理解
- 非参数化:不需要假设数据的分布形式
- 处理混合数据:能同时处理数值和类别特征
- 捕捉非线性关系:通过分层划分,自动学习复杂的决策边界
从1986年 Ross Quinlan 提出 ID3 算法,到今天 XGBoost、LightGBM 在 Kaggle 竞赛中称霸,决策树算法已经走过了近四十年的演进历程。本文将带你从最基本的树结构出发,逐步深入到现代梯度提升框架的数学原理,揭示这一算法的优雅与力量。
第一章:决策树基础
1.1 什么是决策树?
决策树(Decision Tree)是一种树形结构的预测模型,其中:
- 内部节点表示对某个特征的测试或判断
- 分支表示测试的结果
- 叶节点表示最终的预测结果(类别或数值)
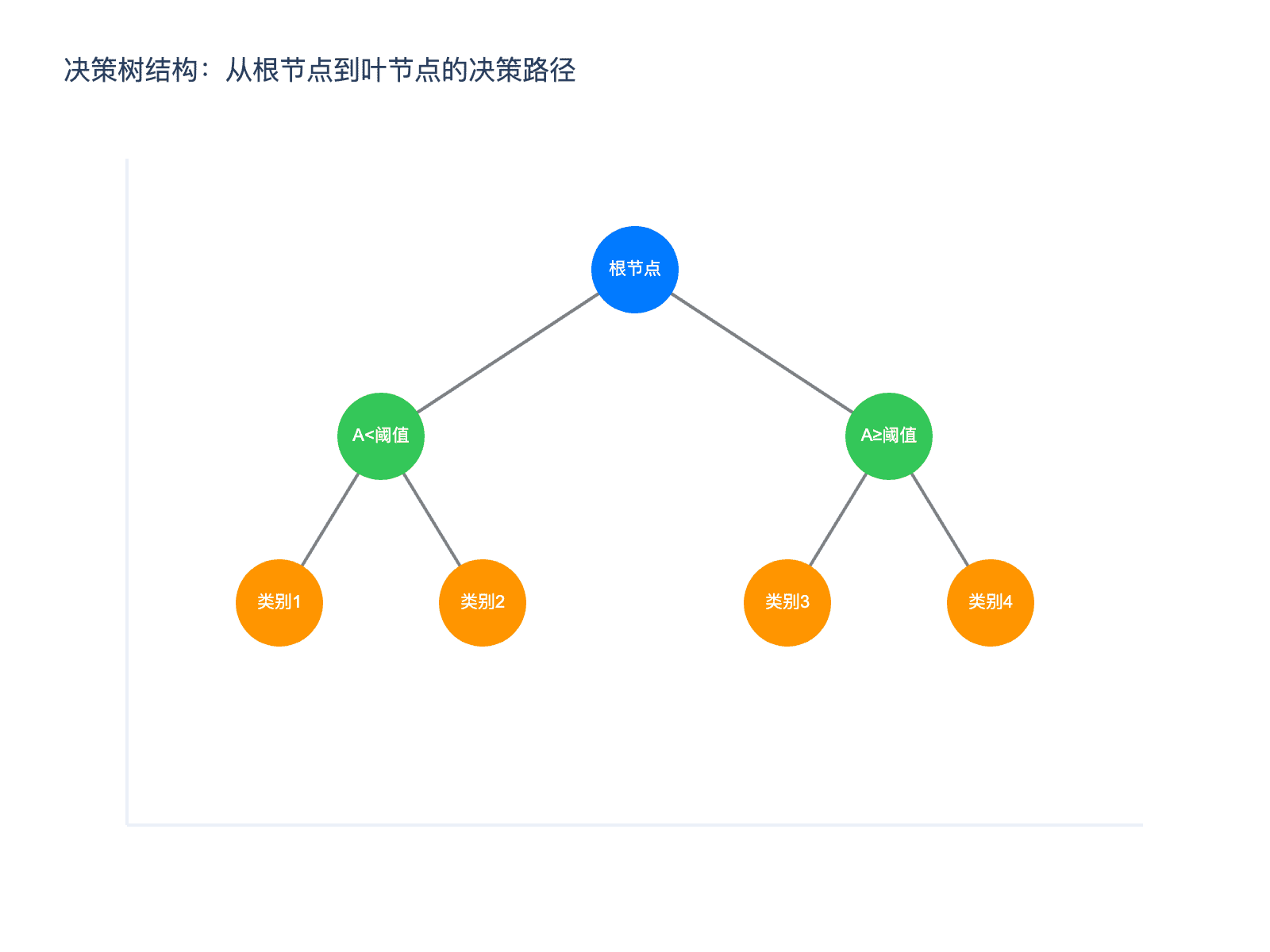 图 1:决策树的基本结构。从根节点开始,根据特征值进行判断,沿着分支走到叶节点得到预测结果。
图 1:决策树的基本结构。从根节点开始,根据特征值进行判断,沿着分支走到叶节点得到预测结果。
决策树既可以用于分类(预测离散类别),也可以用于回归(预测连续数值)。前者的代表是 ID3、C4.5、CART(分类树),后者的代表是 CART(回归树)。
1.2 决策树的学习过程
构建决策树的核心问题是:*如何选择每个节点的分裂特征和分裂点?
这涉及三个关键决策:
*1. 特征选择准则
我们需要一个指标来度量分裂的"好坏"。常用的准则包括:
- 信息增益(Information Gain):基于信息熵的减少
- 基尼指数(Gini Index):基于概率分布的纯度
- 均方误差(MSE):用于回归问题
*2. 分裂点选择
对于数值特征,需要确定最优的分裂阈值。通常采用贪婪搜索:遍历所有可能的分裂点,选择使准则最优化的那个。
*3. 停止条件
递归分裂何时停止?常见的停止条件:
- 节点中样本数少于阈值
- 节点纯度达到阈值
- 树深度达到上限
- 分裂带来的增益小于阈值
1.3 决策树的预测过程
预测一个新样本时,从根节点开始:
- 检查当前节点的分裂特征
- 根据样本在该特征上的取值,选择对应的分支
- 移动到子节点
- 重复直到到达叶节点
- 叶节点的标签(分类)或平均值(回归)即为预测结果
时间复杂度为 $O(\log n)$,其中 $n$ 是树的高度。这意味着即使对于大规模数据集,预测速度也非常快。
第二章:分裂准则的数学原理
2.1 信息熵与信息增益
信息熵(Entropy)是 Claude Shannon 在信息论中提出的概念,用于度量随机变量的不确定性。
对于离散随机变量 $Y$,其熵定义为:
$$H(Y) = -\sum_{i=1}^{k} p_i \log_2 p_i$$
其中 $p_i$ 是第 $i$ 类的概率。
直观理解:
- 当所有样本属于同一类时,$H(Y) = 0$(最确定)
- 当类别均匀分布时,$H(Y)$ 达到最大值(最不确定)
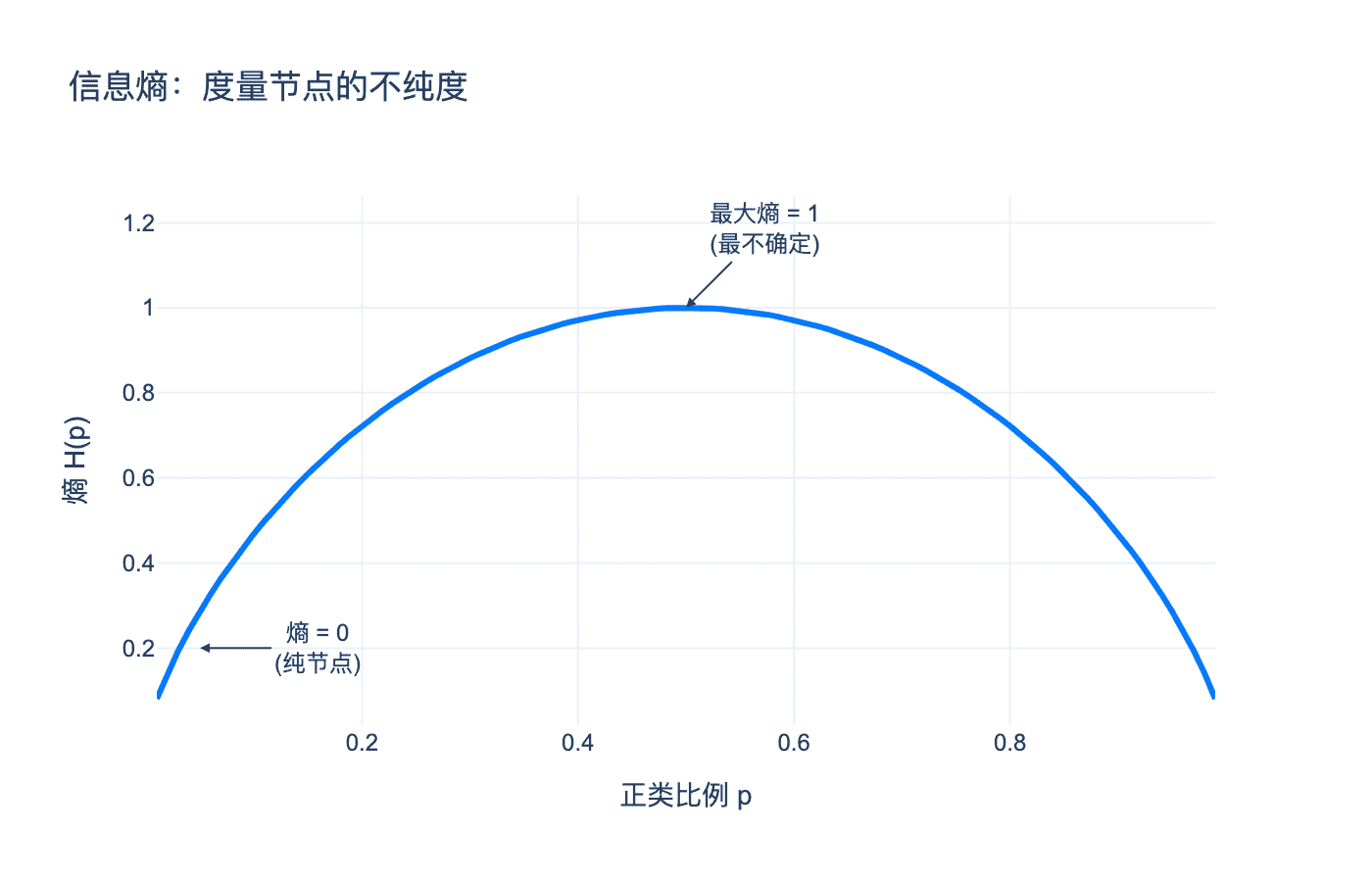 图 2:信息熵函数。当正类比例为0.5时熵最大(最不确定),当比例为0或1时熵为0(纯节点)。
图 2:信息熵函数。当正类比例为0.5时熵最大(最不确定),当比例为0或1时熵为0(纯节点)。
信息增益(Information Gain)度量了使用特征 $X$ 对数据集 $D$ 进行划分后,熵的减少量:
$$\text{IG}(D, X) = H(D) - \sum_{v \in \text{Values}(X)} \frac{|D_v|}{|D|} H(D_v)$$
其中 $D_v$ 是特征 $X$ 取值为 $v$ 的子集。
ID3 算法(Quinlan, 1986)就是基于信息增益的决策树算法。它选择使信息增益最大的特征进行分裂。
信息增益的问题:倾向于选择取值较多的特征。例如,“用户ID"这样的特征会给每个样本一个唯一的分支,信息增益极高,但泛化能力极差。
2.2 信息增益率
为了解决信息增益的偏向问题,C4.5 算法(Quinlan, 1993)引入了信息增益率(Gain Ratio):
$$\text{GainRatio}(D, X) = \frac{\text{IG}(D, X)}{\text{SplitInfo}(X)}$$
其中:
$$\text{SplitInfo}(X) = -\sum_{v \in \text{Values}(X)} \frac{|D_v|}{|D|} \log_2 \frac{|D_v|}{|D|}$$
$\text{SplitInfo}(X)$ 是特征 $X$ 的固有值,度量了将数据集划分为 $v$ 个子集的"代价”。特征的取值越多,$\text{SplitInfo}(X)$ 越大,从而降低了信息增益率。
2.3 基尼指数
CART 算法(Classification and Regression Trees, Breiman et al., 1984)采用基尼指数(Gini Index)作为分裂准则。
对于数据集 $D$,基尼指数定义为:
$$\text{Gini}(D) = 1 - \sum_{i=1}^{k} p_i^2$$
其中 $p_i$ 是第 $i$ 类的概率。
基尼指数可以理解为:从数据集中随机抽取两个样本,它们属于不同类别的概率。
- 当所有样本属于同一类时,$\text{Gini}(D) = 0$(最纯)
- 当类别均匀分布时,$\text{Gini}(D) = 1 - \frac{1}{k}$(最不纯)
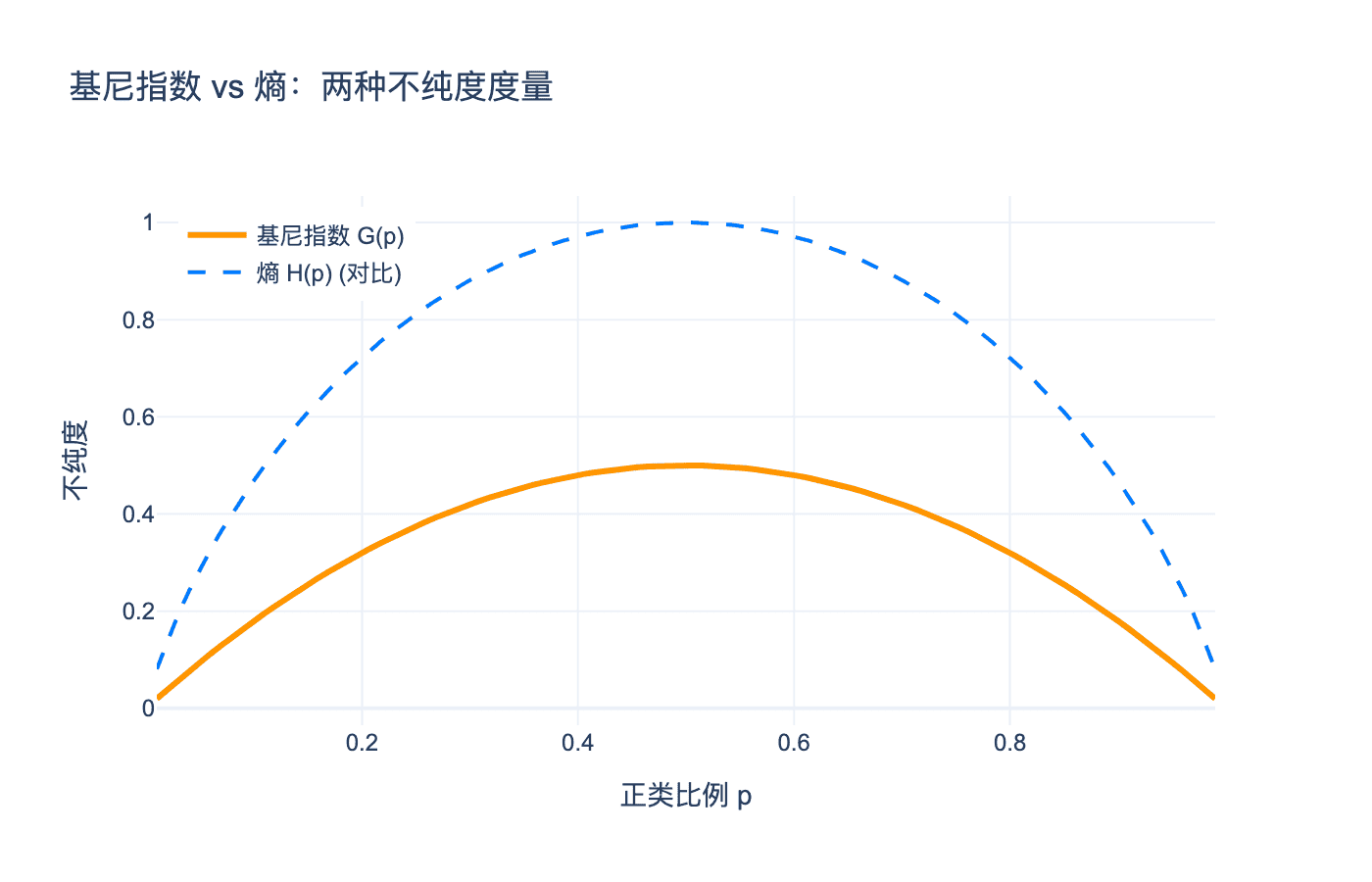 图 3:基尼指数与熵的比较。两者形状相似,都是关于正类比例的凹函数,在0.5处取得最大值。
图 3:基尼指数与熵的比较。两者形状相似,都是关于正类比例的凹函数,在0.5处取得最大值。
特征 $X$ 的基尼指数定义为:
$$\text{Gini}(D, X) = \sum_{v \in \text{Values}(X)} \frac{|D_v|}{|D|} \text{Gini}(D_v)$$
CART 选择使基尼指数减少最多的特征和分裂点。
基尼指数 vs 信息增益:
- 基尼指数计算更简单(不需要对数运算)
- 两者在实际应用中通常给出相似的结果
- 基尼指数对纯度更敏感(在 $p \approx 0$ 或 $p \approx 1$ 时梯度更大)
2.4 回归树的均方误差
对于回归问题,CART 使用均方误差(Mean Squared Error, MSE)作为分裂准则。
对于节点 $D$,其 MSE 定义为:
$$\text{MSE}(D) = \frac{1}{|D|} \sum_{i \in D} (y_i - \bar{y})^2$$
其中 $\bar{y} = \frac{1}{|D|} \sum_{i \in D} y_i$ 是节点中目标值的均值。
分裂准则选择使子节点加权 MSE 最小的特征和分裂点:
$$\min_{X, t} \left[ \frac{|D_L|}{|D|} \text{MSE}(D_L) + \frac{|D_R|}{|D|} \text{MSE}(D_R) \right]$$
其中 $D_L = {i \in D: X_i \leq t}$,$D_R = {i \in D: X_i > t}$。
第三章:决策树算法的演进
3.1 ID3:信息增益的开创者
ID3(Iterative Dichotomiser 3)由 Ross Quinlan 于1986年提出,是首个广泛使用决策树学习算法。
算法特点:
- 使用信息增益选择分裂特征
- 只能处理类别特征(数值特征需要离散化)
- 递归构建树直到所有叶节点纯或无法继续分裂
- 没有剪枝机制,容易过拟合
算法流程:
函数 BuildTree(D, features):
如果 D 中所有样本属于同一类别 C:
返回 叶节点(类别=C)
如果 features 为空:
返回 叶节点(类别=D的多数类)
选择使信息增益最大的特征 A
对于 A 的每个取值 v:
D_v = {样本 ∈ D: A = v}
如果 D_v 为空:
添加叶节点(类别=D的多数类)作为子节点
否则:
子树 = BuildTree(D_v, features - {A})
添加子树作为子节点
3.2 C4.5:信息增益率与连续特征
C4.5(Quinlan, 1993)是 ID3 的改进版本,引入了许多重要特性:
1. 信息增益率:解决 ID3 对多值特征的偏向
2. 连续特征处理:
- 对于数值特征,先排序
- 考虑相邻不同取值的中点作为候选分裂点
- 选择使信息增益率最大的分裂点
3. 缺失值处理:
- 使用概率权重处理缺失值
- 样本按特征取值分布加权分配到子节点
4. 后剪枝:
- 通过悲观误差估计进行剪枝
- 将树转化为规则集,进行规则剪枝
3.3 CART:二叉树与基尼指数
CART(Breiman et al., 1984)与 ID3/C4.5 有显著不同:
1. 二叉树结构:
- CART 总是生成二叉树
- 每个节点只有一个分裂条件($X \leq t$ 或 $X \in {v_1, v_2, \ldots}$)
- 类别特征需要进行二元划分
2. 基尼指数:用于分类任务
3. 回归支持:使用 MSE 准则
4. 代价复杂度剪枝(Cost-Complexity Pruning):
- 定义代价复杂度:$R_\alpha(T) = R(T) + \alpha |T|$
- $R(T)$ 是树的预测误差
- $|T|$ 是叶节点数
- $\alpha$ 是复杂度参数
- 通过交叉验证选择最优的 $\alpha$
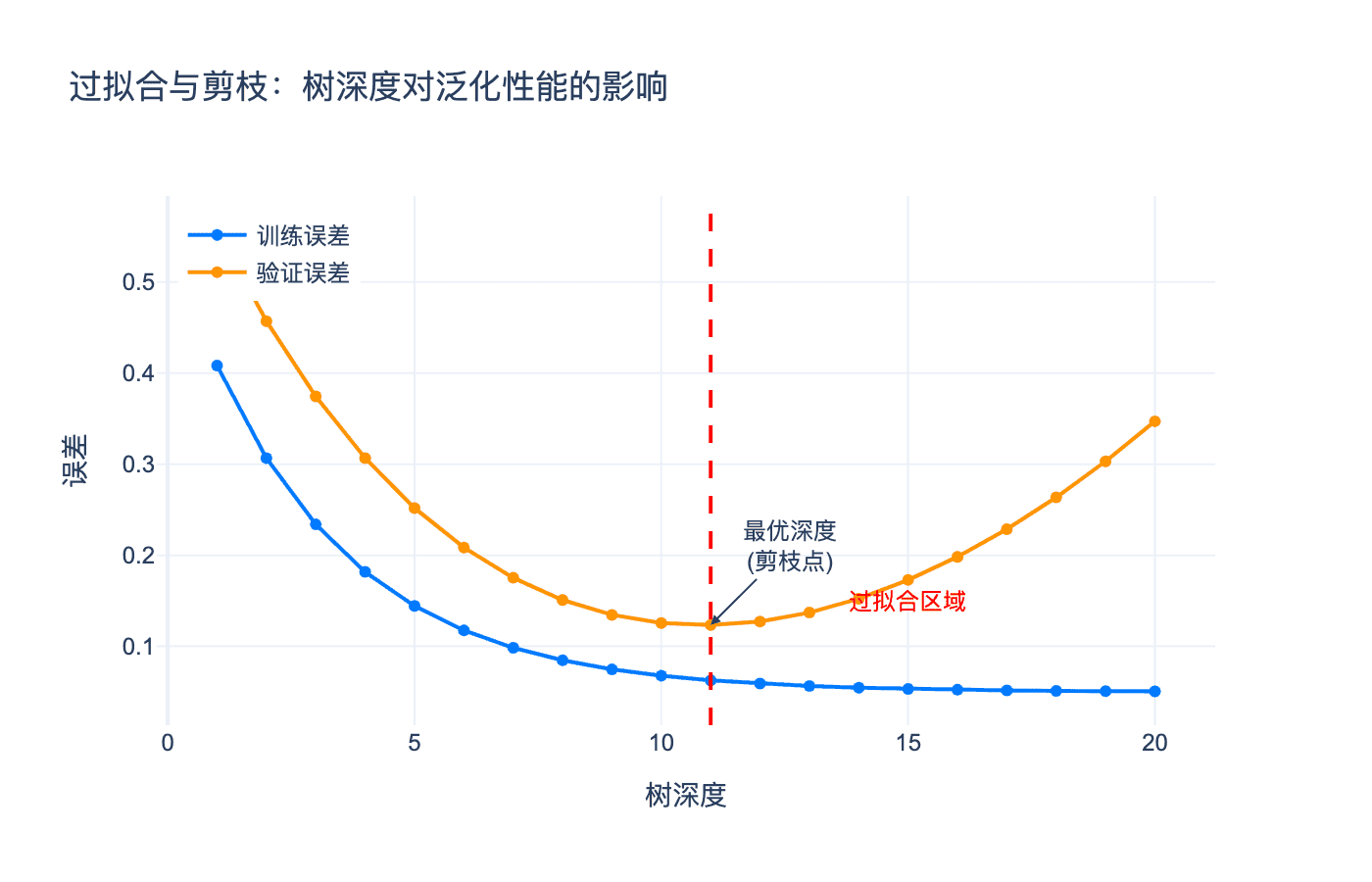 图 4:决策树深度对训练误差和验证误差的影响。随着深度增加,训练误差持续下降,但验证误差先降后升,存在最优深度。
图 4:决策树深度对训练误差和验证误差的影响。随着深度增加,训练误差持续下降,但验证误差先降后升,存在最优深度。
3.4 特征空间划分
决策树对特征空间的划分具有轴平行(axis-parallel)的特点。每个分裂都平行于某个坐标轴。
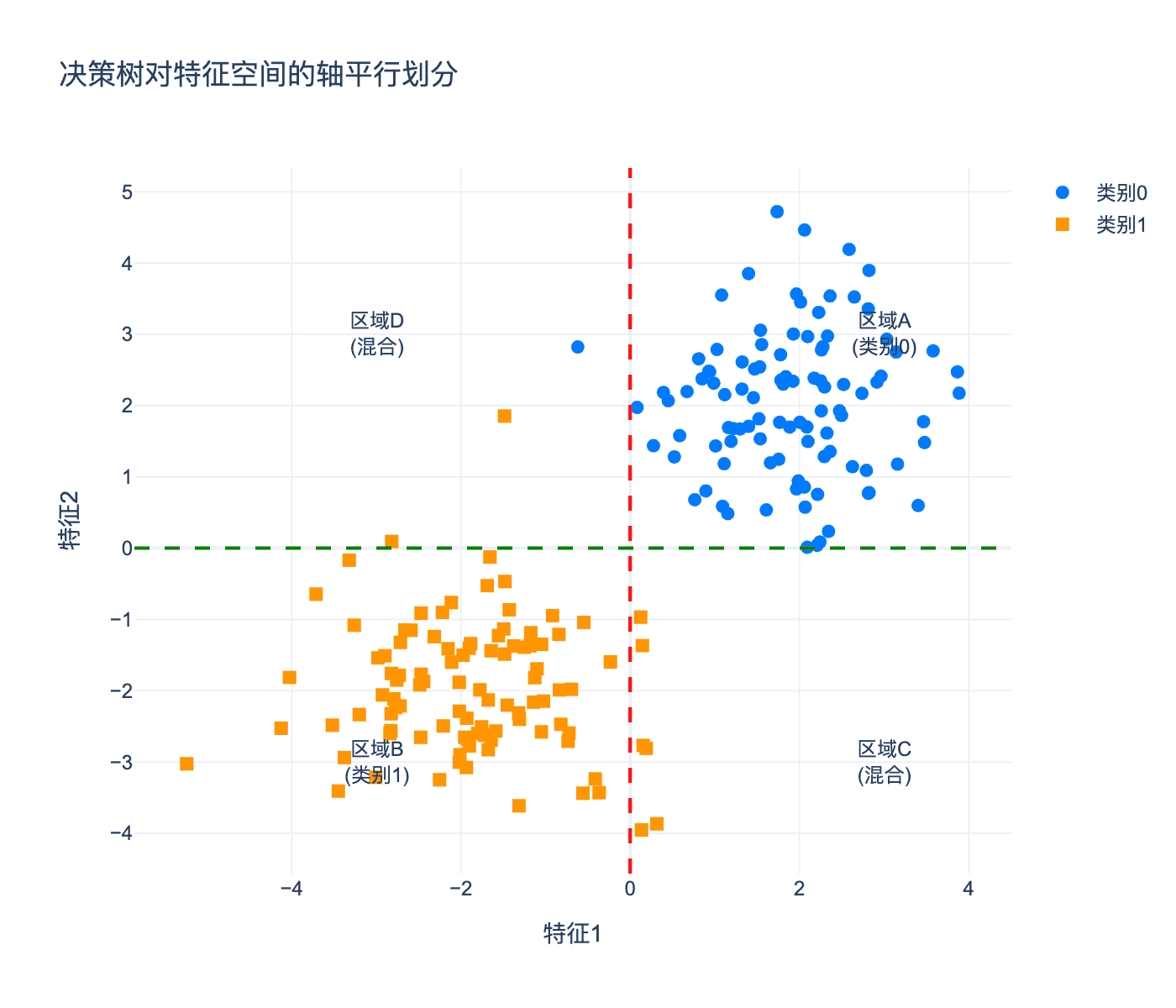 图 5:决策树对二维特征空间的划分。每个分裂都平行于坐标轴,形成矩形区域的决策边界。
图 5:决策树对二维特征空间的划分。每个分裂都平行于坐标轴,形成矩形区域的决策边界。
这种划分的优缺点:
- 优点:简单直观,易于解释
- 缺点:对于倾斜的决策边界,需要很多分裂来近似
改进方法:
- 斜决策树(Oblique Decision Trees):允许斜向分裂(如 $aX_1 + bX_2 \leq t$)
- 多变量决策树:在每个节点使用线性组合
第四章:集成学习——从单棵树到森林
单棵决策树虽然直观,但存在明显局限:方差大,容易过拟合。集成学习方法通过组合多棵树的预测,显著提高了模型的稳定性和准确性。
4.1 Bagging 与随机森林
Bagging(Bootstrap Aggregating,Breiman, 1996)是一种并行集成方法:
- 从原始数据集 $D$ 中有放回地随机抽取 $B$ 个自助样本(bootstrap samples)$D_1, D_2, \ldots, D_B$
- 对每个样本 $D_b$ 训练一棵决策树 $T_b$
- 预测时,对所有树的预测进行投票(分类)或平均(回归)
自助采样(Bootstrap)的核心思想:
- 每次从 $n$ 个样本中有放回地抽取 $n$ 个样本
- 约 $63.2%$ 的原始样本会被抽到(因为 $(1 - 1/n)^n \approx e^{-1} \approx 0.368$)
- 剩下的 $36.8%$ 称为袋外样本(Out-of-Bag, OOB),可用于估计泛化误差
随机森林(Random Forest,Breiman, 2001)在 Bagging 基础上增加了特征随机性:
- 对每个节点,从所有 $p$ 个特征中随机选择 $m$ 个特征(通常 $m = \sqrt{p}$ 或 $m = p/3$)
- 只在这 $m$ 个特征中选择最优分裂
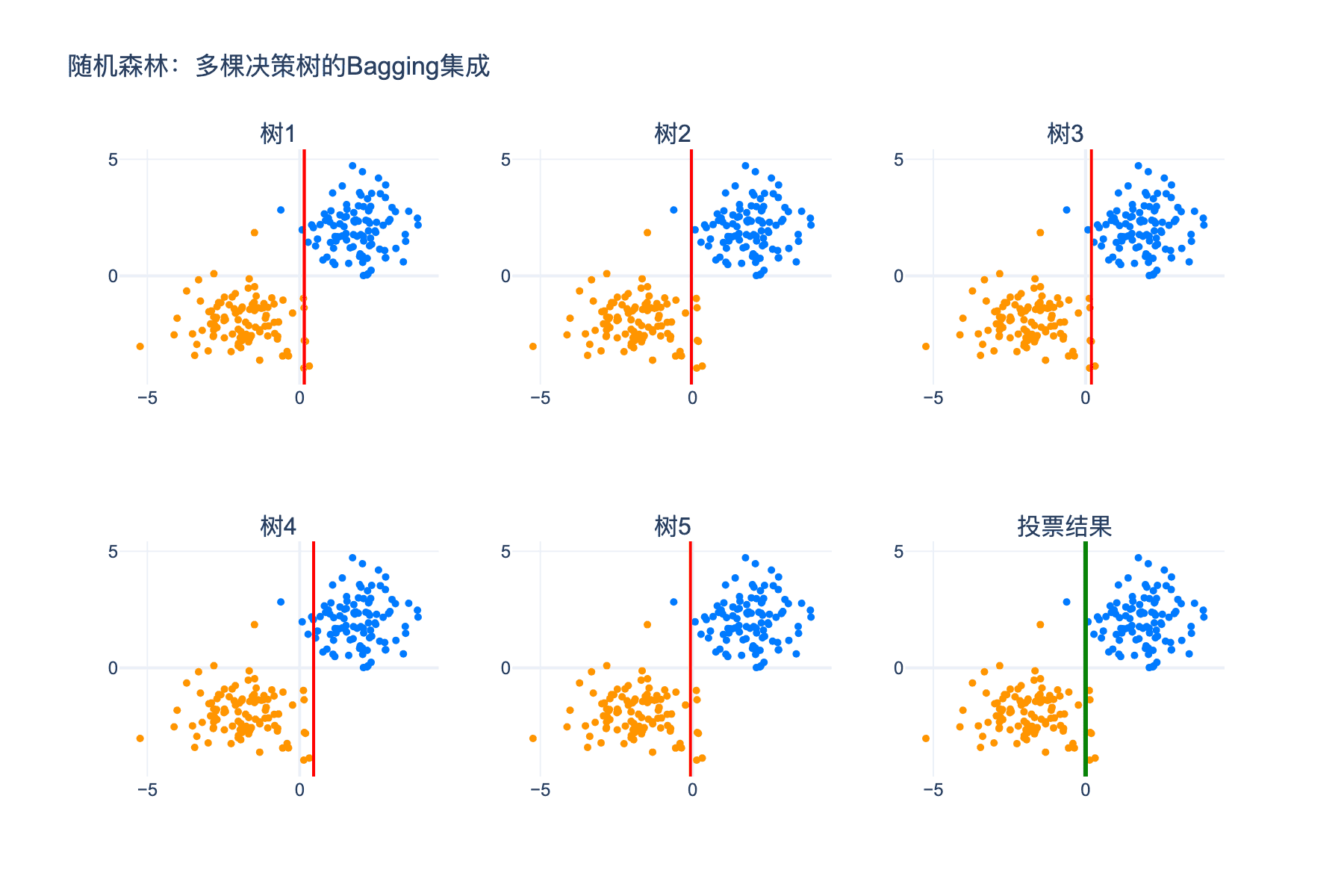 图 6:随机森林的Bagging集成机制。每棵树在不同的自助样本上训练,预测时通过投票得到最终结果。
图 6:随机森林的Bagging集成机制。每棵树在不同的自助样本上训练,预测时通过投票得到最终结果。
随机森林的优点:
- 通过样本随机性和特征随机性,降低了树之间的相关性
- 泛化误差小,不易过拟合
- 可以并行训练,效率高
- 提供特征重要性评估
- OOB 误差估计无需交叉验证
特征重要性:
随机森林通过置换重要性(Permutation Importance)评估特征:
- 对于每棵树,计算 OOB 误差
- 随机置换某个特征的取值,再次计算 OOB 误差
- 两次误差的差值反映了该特征的重要性
4.2 Boosting 与 AdaBoost
Boosting 是一种串行集成方法,核心思想是:让后续的模型关注前面模型分错的样本。
AdaBoost(Adaptive Boosting,Freund & Schapire, 1997)是 Boosting 的代表算法:
算法流程:
初始化样本权重:$w_i^{(1)} = \frac{1}{n}$,$i = 1, 2, \ldots, n$
对于 $m = 1, 2, \ldots, M$:
- 在加权样本上训练弱分类器 $G_m(x)$
- 计算加权错误率:$\text{err}m = \frac{\sum{i=1}^n w_i^{(m)} \cdot \mathbb{1}(y_i \neq G_m(x_i))}{\sum_{i=1}^n w_i^{(m)}}$
- 计算分类器权重:$\alpha_m = \ln\left(\frac{1 - \text{err}_m}{\text{err}_m}\right)$
- 更新样本权重:$w_i^{(m+1)} = w_i^{(m)} \cdot \exp(\alpha_m \cdot \mathbb{1}(y_i \neq G_m(x_i)))$
- 归一化权重
最终预测:$G(x) = \text{sign}\left(\sum_{m=1}^M \alpha_m G_m(x)\right)$
指数损失函数视角:
AdaBoost 最小化指数损失函数:
$$L(y, f(x)) = \exp(-y \cdot f(x))$$
其中 $f(x) = \sum_{m=1}^M \alpha_m G_m(x)$ 是加法模型。
通过前向分步算法,每一步添加一个新的弱分类器,最小化当前模型的损失。
4.3 梯度提升树(GBDT)
梯度提升(Gradient Boosting,Friedman, 2001)将 Boosting 推广到任意可微损失函数。
核心思想:在函数空间中使用梯度下降。
算法流程:
初始化:$F_0(x) = \arg\min_c \sum_{i=1}^n L(y_i, c)$
对于 $m = 1, 2, \ldots, M$:
- 计算伪残差(负梯度):$r_{im} = -\left[\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\right]{F=F{m-1}}$
- 用决策树 $h_m(x)$ 拟合伪残差
- 通过线搜索确定步长:$\rho_m = \arg\min_\rho \sum_{i=1}^n L(y_i, F_{m-1}(x_i) + \rho h_m(x_i))$
- 更新模型:$F_m(x) = F_{m-1}(x) + \nu \cdot \rho_m \cdot h_m(x)$
其中 $\nu \in (0, 1]$ 是学习率(shrinkage),控制每棵树的贡献。
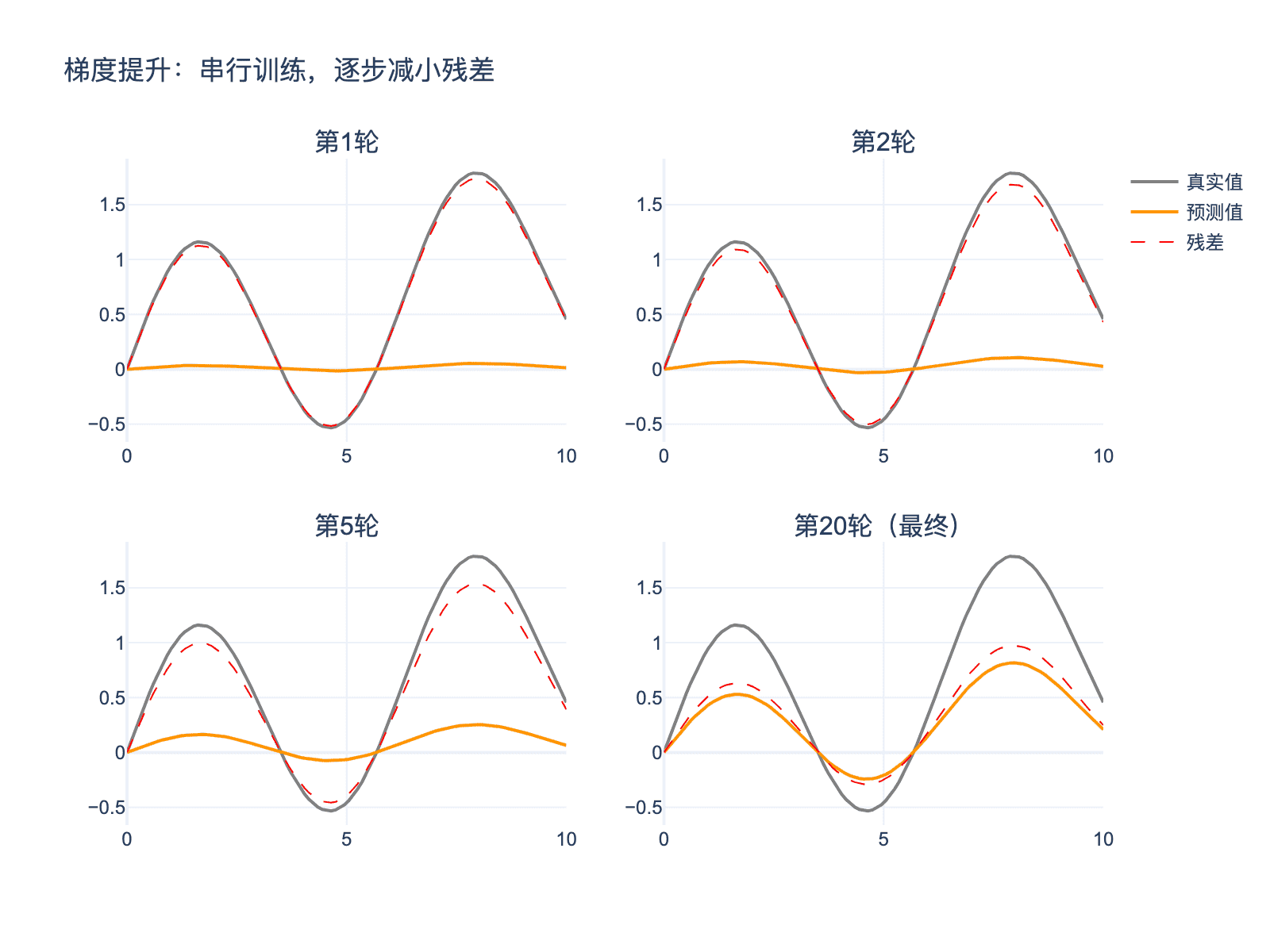 图 7:梯度提升的训练过程。每棵新树拟合前面模型的残差,逐步减小预测误差。
图 7:梯度提升的训练过程。每棵新树拟合前面模型的残差,逐步减小预测误差。
损失函数选择:
- 回归:平方损失 $L(y, F) = \frac{1}{2}(y - F)^2$,伪残差为 $y - F$
- 分类:对数损失(Log Loss),对应逻辑回归
- 稳健回归:Huber 损失
正则化策略:
- 学习率(Shrinkage):减小每棵树的贡献,需要更多的树
- 子采样(Stochastic Gradient Boosting):每次只使用部分样本
- 列子采样:每次只使用部分特征
- 树复杂度限制:限制叶子节点数、最小叶节点样本数、最小分裂增益
第五章:现代梯度提升框架
5.1 XGBoost:eXtreme Gradient Boosting
XGBoost(Chen & Guestrin, 2016)是梯度提升的工程优化版本,在 Kaggle 竞赛中大放异彩。
核心优化:
1. 目标函数的二阶泰勒展开:
XGBoost 同时利用损失函数的一阶导数(梯度)和二阶导数(Hessian):
$$\text{Obj}^{(t)} = \sum_{i=1}^n \left[g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)\right] + \Omega(f_t)$$
其中:
- $g_i = \partial_{\hat{y}^{(t-1)}} l(y_i, \hat{y}^{(t-1)})$ 是一阶梯度
- $h_i = \partial^2_{\hat{y}^{(t-1)}} l(y_i, \hat{y}^{(t-1)})$ 是二阶梯度
- $\Omega(f) = \gamma T + \frac{1}{2} \lambda \sum_{j=1}^T w_j^2$ 是正则化项
2. 分裂点查找算法:
- 贪心算法:遍历所有特征和分裂点
- 近似算法:对特征值分桶,在桶边界上寻找分裂点,适用于大数据
- 加权分位数草图(Weighted Quantile Sketch):处理带权数据的分位数计算
3. 缺失值处理:
XGBoost 自动学习缺失值的最优分裂方向(左或右)。
4. 系统优化:
- 列块存储(Column Block Structure):数据按列存储,支持并行计算
- 缓存感知访问(Cache-aware Access):优化非连续内存访问
- 核外计算(Blocks for Out-of-core Computation):处理超大数据集
5.2 LightGBM:基于直方图的快速训练
LightGBM(Ke et al., 2017)由微软开发,专注于训练速度和内存效率。
核心创新:
1. 基于直方图的决策树算法:
- 将连续特征离散化为 $k$ 个桶(默认255个)
- 在离散值上寻找最优分裂点
- 时间复杂度从 $O(n_{samples} \times n_{features})$ 降到 $O(n_{bins} \times n_{features})$
- 内存占用大幅减少
2. 带深度限制的 Leaf-wise 生长策略:
传统决策树使用 Level-wise(按层生长),LightGBM 使用 Leaf-wise(按叶子生长):
- 每次选择分裂增益最大的叶子进行分裂
- 增加深度限制防止过拟合
- 在相同分裂次数下通常能达到更低的损失
3. 梯度单边采样(GOSS):
- 保留梯度较大的样本(对模型影响大)
- 随机采样梯度较小的样本
- 保持数据分布的同时减少计算量
4. 互斥特征捆绑(EFB):
- 将互斥的特征(不会同时取非零值)捆绑在一起
- 减少特征数量,加速训练
- 特别适用于高维稀疏数据
5.3 CatBoost:处理类别特征
CatBoost(Prokhorenkova et al., 2017)由 Yandex 开发,专注于高效处理类别特征。
核心特性:
1. 有序提升(Ordered Boosting):
传统梯度提升存在预测偏移(Prediction Shift)问题:训练时使用的统计信息与预测时不一致。
CatBoost 采用有序提升:
- 将训练数据随机排列
- 对于每个样本,只使用排在它前面的样本计算统计信息
- 消除预测偏移,减少过拟合
2. 类别特征处理:
对于类别特征,CatBoost 使用目标统计量(Target Statistics):
$$\hat{x}{ik} = \frac{\sum{j=1}^n \mathbb{1}(x_{jk} = x_{ik}) \cdot y_j + a \cdot P}{\sum_{j=1}^n \mathbb{1}(x_{jk} = x_{ik}) + a}$$
其中 $P$ 是先验概率,$a$ 是先验权重。
通过有序提升,防止目标泄露(Target Leakage)。
3. 对称树(Oblivious Trees):
- 所有叶子使用相同的分裂条件
- 预测速度快(可以使用位运算)
- 减少过拟合
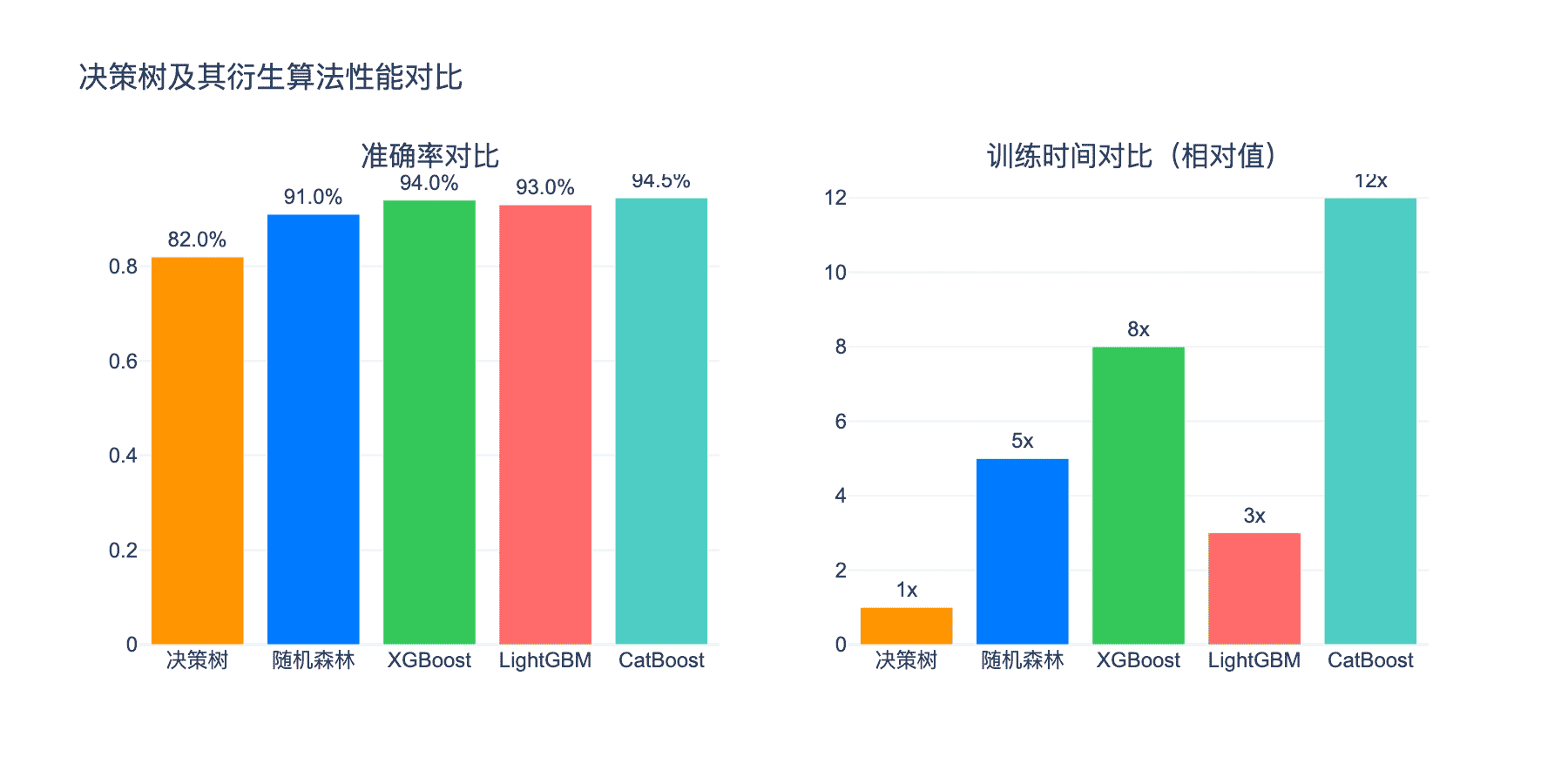 图 8:决策树及其衍生算法的性能对比。现代梯度提升框架(XGBoost、LightGBM、CatBoost)在准确率上都有显著提升,但训练时间有所增加。
图 8:决策树及其衍生算法的性能对比。现代梯度提升框架(XGBoost、LightGBM、CatBoost)在准确率上都有显著提升,但训练时间有所增加。
第六章:数学深入与理论分析
6.1 偏差-方差分解
决策树的误差可以通过偏差-方差分解来理解:
$$E[(y - \hat{f}(x))^2] = \text{Bias}^2(\hat{f}(x)) + \text{Var}(\hat{f}(x)) + \sigma^2$$
单棵决策树:
- 高方差:对训练数据敏感,小的数据变化可能导致完全不同的树
- 低偏差:如果树足够深,可以拟合任意复杂的模式
Bagging/随机森林:
- 通过平均多棵树的预测,降低方差(假设树之间相关性低)
- 保持偏差不变
Boosting:
- 通过串行训练,逐步减小**偏差*
- 如果树太复杂,可能增加方差
6.2 树的复杂度与正则化
决策树的复杂度可以用以下因素衡量:
- 树的深度 $d$
- 叶节点数 $T$
- 叶节点中的最小样本数
正则化策略:
预剪枝(Pre-pruning):
- 限制最大深度
- 限制最小分裂样本数
- 限制最小分裂增益
后剪枝(Post-pruning):
- 先构建完整的树
- 自底向上剪枝,如果剪枝后验证误差降低或不变
代价复杂度剪枝(CART):
$$R_\alpha(T) = R(T) + \alpha |T|$$
通过交叉验证选择最优的 $\alpha$。
6.3 梯度提升的收敛性
在适当的条件下,梯度提升算法收敛:
定理(Zhang & Yu, 2005):
如果损失函数是凸的且满足一定的光滑性条件,步长足够小,则梯度提升收敛到最优解。
收缩(Shrinkage)的重要性:
学习率 $\nu$ 的选择影响收敛速度和质量:
- $\nu$ 太大:可能震荡或不收敛
- $\nu$ 太小:收敛慢,需要更多的树
实践中,通常选择 $\nu \in [0.01, 0.1]$,并增加树的数量来补偿。
6.4 特征交互与树深度
决策树天然捕捉特征交互。深度为 $d$ 的树可以捕捉最多 $d$ 阶的特征交互。
例如,对于特征 $X_1$ 和 $X_2$:
- 深度为2的树可以学习 $X_1 > a$ 且 $X_2 > b$ 的模式
- 这种交互是逻辑与(AND)关系
高阶交互:
- 深度为 $d$ 的树可以学习 $d$ 个特征的交互
- 但每增加一层,叶节点数翻倍,样本数减半,可能导致统计不显著
梯度提升中的交互:
多棵树的加法组合可以捕捉更复杂的交互模式。例如,两棵深度为2的树可以捕捉:
$$f(x) = f_1(X_1, X_2) + f_2(X_3, X_4)$$
这是一种可加交互,不同树处理不同的特征子集。
第七章:实践指南与应用
7.1 算法选择
*何时使用决策树?
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 需要可解释性 | 单棵决策树/CART | 可视化决策路径 |
| 大数据集 | LightGBM | 训练速度快,内存效率高 |
| 高基数类别特征 | CatBoost | 原生支持类别特征 |
| 特征重要性分析 | 随机森林 | 稳定的特征重要性估计 |
| 竞赛/追求最高精度 | XGBoost/LightGBM/CatBoost | 调参空间大,精度高 |
| 实时预测 | 单棵决策树/LightGBM | 预测速度快 |
7.2 超参数调优
通用超参数:
| 超参数 | 作用 | 典型范围 |
|---|---|---|
max_depth | 树的最大深度 | 3-10 |
min_samples_leaf | 叶节点最小样本数 | 1-20 |
n_estimators | 树的数量 | 100-1000 |
learning_rate | 学习率 | 0.01-0.3 |
subsample | 样本采样比例 | 0.6-1.0 |
colsample_bytree | 特征采样比例 | 0.6-1.0 |
调优策略:
- 先粗调后细调:先用较大的网格搜索,再在最佳区域细化
- 学习率与树数量的权衡:较小的学习率通常需要更多树
- 早停(Early Stopping):在验证集上监控性能,停止不再提升的训练
7.3 特征工程
数值特征:
- 决策树对特征的单调变换不敏感(如 log、sqrt)
- 但异常值可能影响力分裂点选择
- 分箱(Binning)可能有助于捕捉非线性关系
类别特征:
- 低基数:One-hot 编码或 Label 编码
- 高基数:目标编码(Target Encoding)、CatBoost 的原生处理
缺失值:
- XGBoost/LightGBM/CatBoost 原生支持
- 或者使用单独的"缺失"类别/数值
7.4 典型应用
金融风控:
- 信用评分:可解释的违约概率预测
- 反欺诈:基于规则+树模型的混合系统
医疗健康:
- 疾病诊断:基于症状和检查结果的决策支持
- 生存分析:Cox 模型的扩展
推荐系统:
- 点击率预测:GBDT + LR 的经典组合
- 特征交叉:树模型自动学习特征交互
自然语言处理:
- 文本分类:结合 TF-IDF 特征
- 命名实体识别:序列标注任务
计算机视觉:
- 通常不是首选(CNN 更适合),但可用于:
- 特征选择:基于随机森林的特征重要性
- 与深度学习的结合:如 DeepForest
结语:从规则到智能
决策树算法的发展历程,是机器学习从简单规则到复杂模型的缩影。
从1986年 Quinlan 的 ID3 算法,到今天的 XGBoost、LightGBM、CatBoost,我们看到了几个重要的演进方向:
数学基础的深化:从简单的信息增益到二阶泰勒展开、有序提升,理论工具越来越精密。
工程优化的极致:列块存储、直方图算法、GPU 加速,让算法能够处理海量数据。
实用性的提升:原生类别特征支持、自动缺失值处理、内置交叉验证,降低了使用门槛。
但核心思想始终如一:通过分层划分,将复杂问题分解为简单决策的组合。
这种"分而治之"的策略,不仅是决策树的精髓,也是人类解决问题的基本方式。从二十个问题的游戏,到现代医学的诊断流程,再到人工智能的决策系统,树形结构的思维无处不在。
正如统计学家 Leo Breiman 所说:
“有两种文化:数据建模文化和算法建模文化。决策树和集成方法代表了算法建模文化的胜利。”
在这个数据驱动的时代,掌握决策树及其衍生算法,不仅是学习一种技术,更是理解一种思维方式——如何在不确定性中做出最优决策。
愿你在数据的森林中,找到属于自己的那棵决策树。
参考文献
Quinlan, J. R. (1986). “Induction of decision trees.” Machine Learning, 1(1), 81-106.
Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. Morgan Kaufmann.
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and Regression Trees. CRC Press.
Breiman, L. (1996). “Bagging predictors.” Machine Learning, 24(2), 123-140.
Breiman, L. (2001). “Random forests.” Machine Learning, 45(1), 5-32.
Freund, Y., & Schapire, R. E. (1997). “A decision-theoretic generalization of on-line learning and an application to boosting.” Journal of Computer and System Sciences, 55(1), 119-139.
Friedman, J. H. (2001). “Greedy function approximation: A gradient boosting machine.” Annals of Statistics, 1189-1232.
Chen, T., & Guestrin, C. (2016). “XGBoost: A scalable tree boosting system.” KDD, 785-794.
Ke, G., et al. (2017). “LightGBM: A highly efficient gradient boosting decision tree.” NeurIPS, 3146-3154.
Prokhorenkova, L., et al. (2018). “CatBoost: Unbiased boosting with categorical features.” NeurIPS, 6638-6648.
*本文旨在为有一定数学和编程基础的读者提供决策树算法的系统综述。实践建议配合 scikit-learn、XGBoost、LightGBM、CatBoost 等库进行动手实验。