引言:多维世界的数学语言
想象你正在观察一个正在旋转的陀螺。描述它需要多少参数?
- 位置:$3$ 个坐标 $(x, y, z)$
- 方向:$3$ 个欧拉角
- 角速度:$3$ 个分量
- 转动惯量:$9$ 个数($3 \times 3$ 矩阵)
这些量不仅仅是数字的集合,它们有特定的变换规则。当坐标系旋转时,位置和角速度按向量规则变换,而转动惯量则按更复杂的规则变换——这就是张量。
在物理学中,张量是描述场的通用语言。爱因斯坦的广义相对论用张量写下:
$$G_{\mu\nu} + \Lambda g_{\mu\nu} = \frac{8\pi G}{c^4} T_{\mu\nu}$$
在深度学习中,一张 $224 \times 224$ 的彩色图像是 $224 \times 224 \times 3$ 的三阶张量。一批 $32$ 张这样的图像是 $32 \times 224 \times 224 \times 3$ 的四阶张量。
本文将带你走进张量的世界,从数学定义到物理直觉,从代数运算到现代应用,理解为什么张量成为描述复杂系统的核心工具。
第一章:张量的本质——超越矩阵的多维数组
1.1 从标量到张量
在数学中,我们熟悉不同维度的对象:
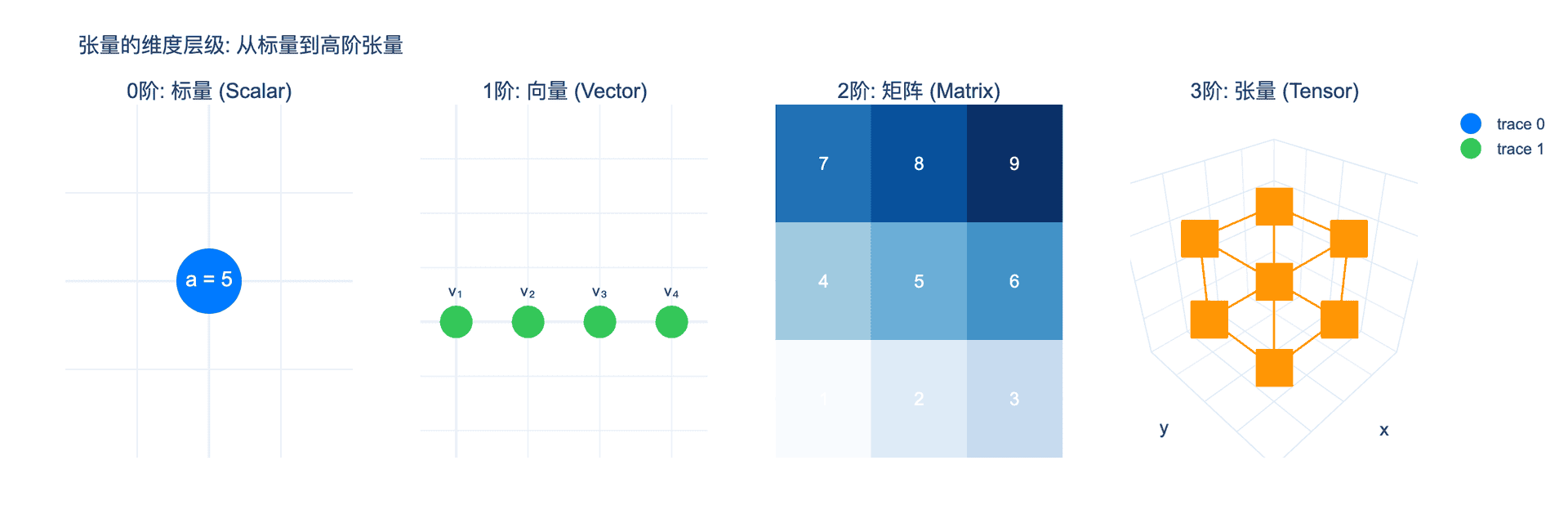
图 1:张量的维度层级。从0阶标量(单个数字)到1阶向量、2阶矩阵,再到3阶及更高阶张量,维度不断增加。
*0阶张量:标量
标量只有一个数值,没有方向:
$$a = 5, \quad T = 300\text{K}, \quad E = mc^2$$
标量在坐标变换下不变——无论你从哪个角度看,温度始终是 $300$K。
*1阶张量:向量
向量有大小和方向:
$$\mathbf{v} = (v_1, v_2, v_3) = v_1 \mathbf{e}_1 + v_2 \mathbf{e}_2 + v_3 \mathbf{e}_3$$
当坐标系旋转时,向量的分量按特定规则变换:
$$v’i = \sum{j=1}^{3} R_{ij} v_j$$
其中 $R_{ij}$ 是旋转矩阵。
*2阶张量:矩阵
矩阵可以看作向量的推广:
$$\mathbf{A} = \begin{pmatrix} a_{11} & a_{12} & a_{13} \ a_{21} & a_{22} & a_{23} \ a_{31} & a_{32} & a_{33} \end{pmatrix}$$
在坐标变换下,矩阵元素变换为:
$$a’{ij} = \sum{k,l} R_{ik} R_{jl} a_{kl}$$
*3阶及以上张量
高阶张量有更多指标。一个 $n$ 阶张量有 $n$ 个指标,在 $d$ 维空间中有 $d^n$ 个分量。
1.2 张量的严格定义
定义:张量是一个多线性映射,它在坐标变换下按特定规则变换。
具体来说,一个 $(r, s)$ 型张量($r$ 个逆变指标,$s$ 个协变指标)的变换规则为:
$$T’^{i_1 \cdots i_r}{j_1 \cdots j_s} = \frac{\partial x’^{i_1}}{\partial x^{k_1}} \cdots \frac{\partial x’^{i_r}}{\partial x^{k_r}} \frac{\partial x^{l_1}}{\partial x’^{j_1}} \cdots \frac{\partial x^{l_s}}{\partial x’^{j_s}} T^{k_1 \cdots k_r}{l_1 \cdots l_s}$$
这个看似复杂的公式其实捕捉了一个简单思想:张量描述的是独立于坐标系的物理/几何对象。
1.3 逆变与协变
为什么需要区分逆变和协变?
考虑速度 $\mathbf{v}$ 和梯度 $\nabla f$:
- 速度是逆变的:当坐标轴伸长时,速度分量变小(走完相同距离需要更少的"单位")
- 梯度是协变的:当坐标轴伸长时,梯度分量变大(相同距离上有更多的"单位"变化)
数学上,逆变向量用上标 $v^i$,协变向量用下标 $v_i$。
第二章:张量运算——代数的力量
2.1 基本运算
加法:同阶张量可以逐元素相加
$$(\mathbf{A} + \mathbf{B}){ijk} = A{ijk} + B_{ijk}$$
数乘:张量可以乘以标量
$$(c \mathbf{A}){ijk} = c \cdot A{ijk}$$
重要性质:张量的阶在加法和数乘下保持不变。
2.2 张量积(外积)
张量积是将两个张量组合成更高阶张量的操作。
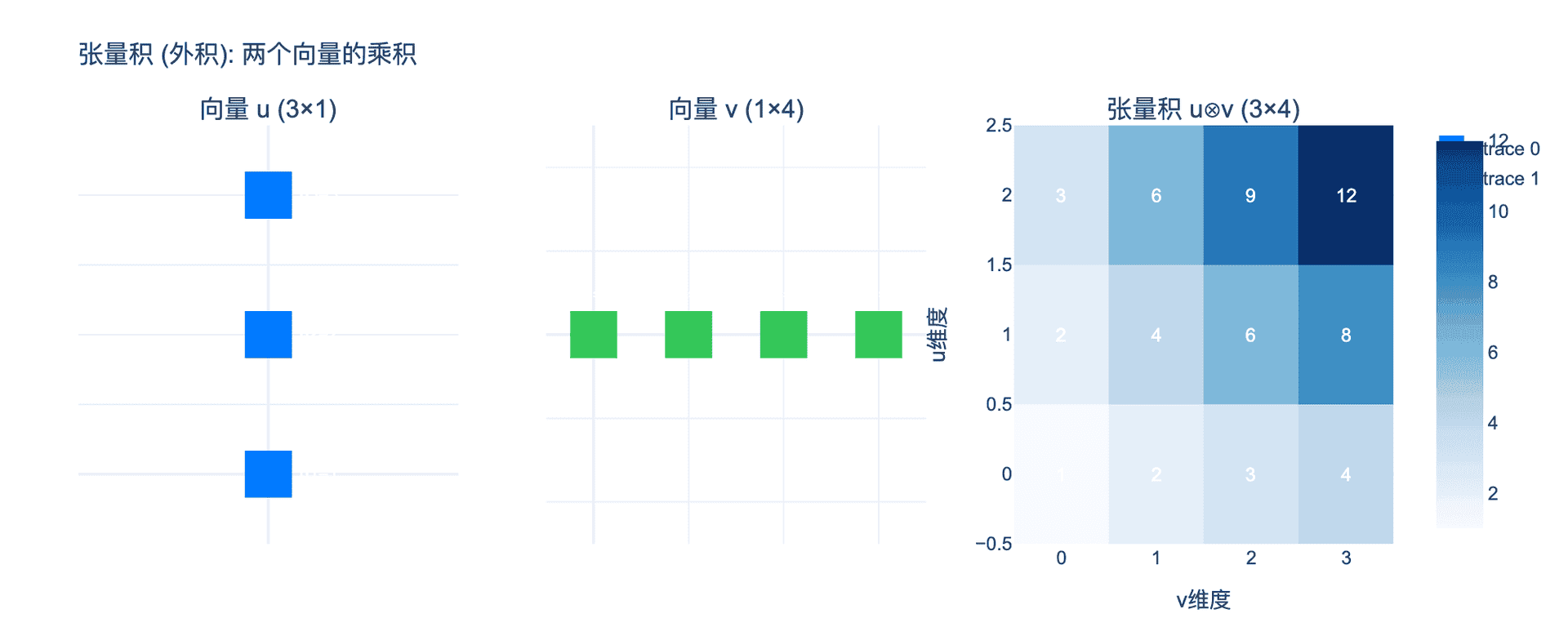
图 2:张量积(外积)的可视化。两个向量的外积产生一个矩阵,其中每个元素是相应向量分量的乘积。
给定两个向量 $\mathbf{u} \in \mathbb{R}^m$ 和 $\mathbf{v} \in \mathbb{R}^n$,它们的外积为:
$$(\mathbf{u} \otimes \mathbf{v})_{ij} = u_i \cdot v_j$$
结果是一个 $m \times n$ 矩阵。
例子:
$$\mathbf{u} = \begin{pmatrix} 1 \ 2 \ 3 \end{pmatrix}, \quad \mathbf{v} = \begin{pmatrix} 4 \ 5 \end{pmatrix}$$
$$\mathbf{u} \otimes \mathbf{v} = \begin{pmatrix} 4 & 5 \ 8 & 10 \ 12 & 15 \end{pmatrix}$$
2.3 缩并(迹的推广)
缩并是对张量的两个指标求和,降低阶数。
对于矩阵,缩并就是迹:
$$\text{tr}(\mathbf{A}) = \sum_{i} A_{ii}$$
对于高阶张量 $\mathbf{T}_{ijk}$,缩并第1和第3指标:
$$S_j = \sum_{i} T_{iji}$$
结果是一个向量(阶数从3降到1)。
2.4 爱因斯坦求和约定
爱因斯坦引入了一个简洁的记号:重复的指标表示求和。
例如,矩阵乘法:
$$c_{ij} = \sum_{k} a_{ik} b_{kj} \quad \text{写成} \quad c_{ij} = a_{ik} b_{kj}$$
向量内积:
$$\mathbf{u} \cdot \mathbf{v} = \sum_{i} u_i v_i = u_i v^i$$
约定规则:
- 上标(逆变)和下标(协变)配对时求和
- 求和指标称为"哑指标",可以任意重命名
- 结果中不再出现的指标是自由指标
2.5 线性变换的张量视角
![]()
图 3:线性变换的可视化。矩阵 $A$ 将向量 $v$ 映射到新的向量 $Av$,同时扭曲了整个空间(网格变形)。
矩阵作为2阶张量,定义了向量空间之间的线性映射:
$$\mathbf{y} = \mathbf{A} \mathbf{x}$$
或指标形式:
$$y_i = A_{ij} x_j$$
特征值与特征向量:
寻找在变换下方向不变的向量:
$$\mathbf{A} \mathbf{v} = \lambda \mathbf{v}$$
这些特殊的向量(特征向量)和对应的缩放因子(特征值)揭示了变换的本质结构。
第三章:张量在深度学习中的应用
3.1 数据表示的张量形式
深度学习处理的是各种形式的数据,它们都可以用张量表示:
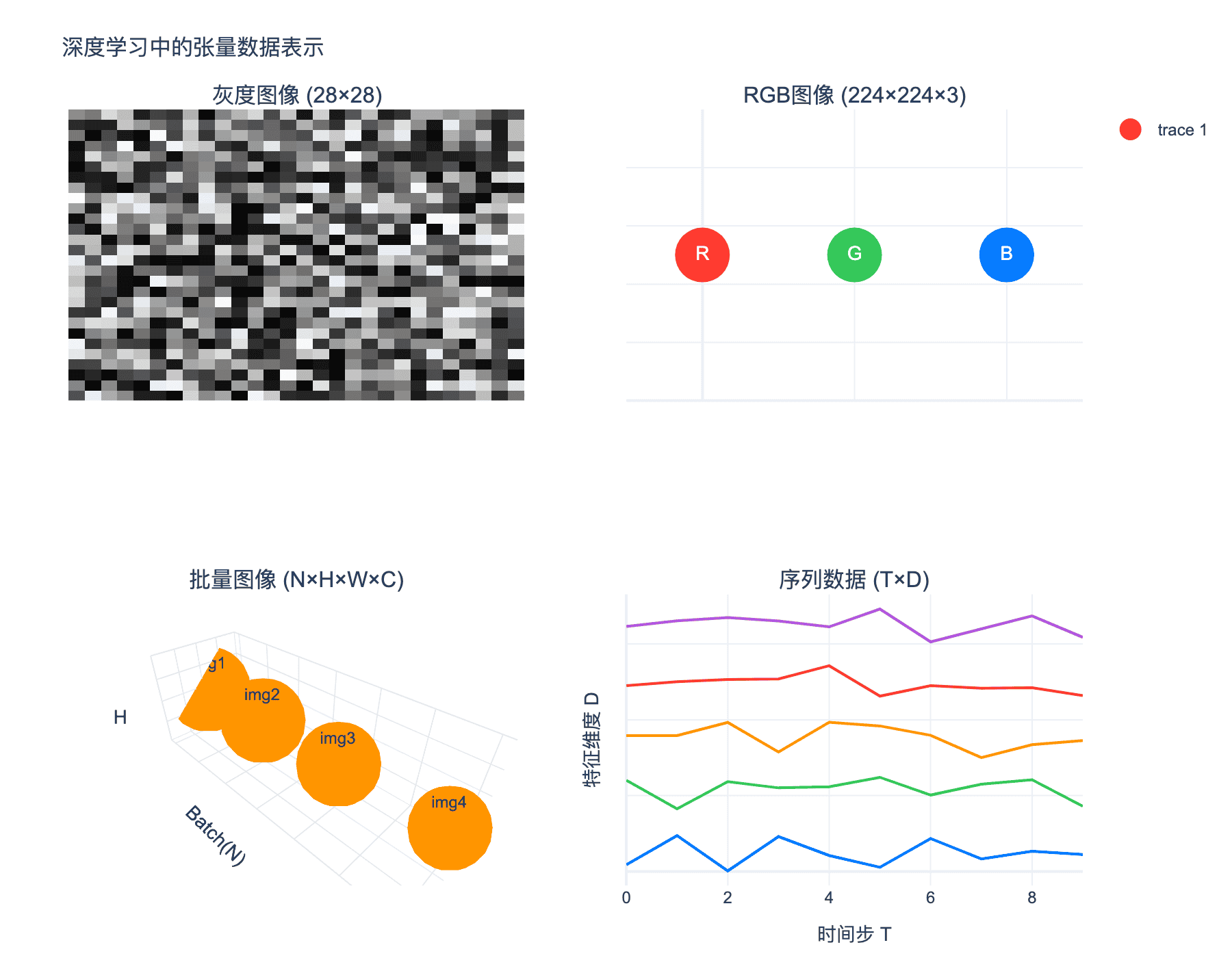
图 4:深度学习中的张量数据表示。从灰度图像(2D)到RGB图像(3D),批量图像(4D),再到序列数据(2D)。
灰度图像:$H \times W$ 的2阶张量
- MNIST:$28 \times 28$
- 医学影像:$512 \times 512$
彩色图像:$H \times W \times C$ 的3阶张量
- $C = 3$(RGB)或 $C = 4$(RGBA)
- ImageNet:$224 \times 224 \times 3$
视频:$T \times H \times W \times C$ 的4阶张量
- $T$ 是时间帧数
- 每秒 $30$ 帧,$10$ 秒视频有 $T = 300$
批量数据:在Batch维度上堆叠
- 一批 $32$ 张RGB图像:$32 \times 224 \times 224 \times 3$
文本数据:
- 词嵌入:$T \times D$(序列长度 × 嵌入维度)
- 批量句子:$B \times T \times D$
3.2 神经网络中的张量运算
神经网络的前向传播本质上是张量的层层变换:
全连接层:
$$\mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b}$$
或:
$$y_i = W_{ij} x_j + b_i$$
卷积层:

图 5:卷积操作的张量视角。卷积核在输入特征图上滑动,进行局部加权求和,生成输出特征图。
卷积是张量的局部线性运算。对于输入 $\mathbf{X}$ 和卷积核 $\mathbf{K}$:
$$(\mathbf{X} * \mathbf{K}){ij} = \sum{m} \sum_{n} X_{i+m, j+n} \cdot K_{m,n}$$
批量矩阵乘法:
Transformer中的注意力机制:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
这里 $Q, K, V$ 都是3阶张量($B \times T \times D$),运算在Batch维度上并行进行。
3.3 张量形状与维度操作
深度学习框架(PyTorch、TensorFlow)提供了丰富的张量操作:
Reshape(重塑):改变张量形状而不改变数据
$$\text{reshape}(\mathbf{X}{2 \times 3 \times 4}) = \mathbf{Y}{6 \times 4} = \mathbf{Z}_{24}$$
Transpose(转置):交换维度
$$(\mathbf{X}^T){ij} = X{ji}$$
对于高阶张量:
$$(\text{permute}(\mathbf{X}, (0, 2, 1))){ijk} = X{ikj}$$
Broadcasting(广播):自动扩展维度进行运算
$$\mathbf{X}{3 \times 1} + \mathbf{y}{1 \times 4} = \mathbf{Z}_{3 \times 4}$$
其中 $Z_{ij} = X_{i0} + y_{0j}$
第四章:张量分解——降维的艺术
4.1 为什么需要张量分解
高阶张量的参数量随阶数指数增长:
- 3阶张量 $100 \times 100 \times 100$:$10^6$ 个参数
- 4阶张量 $100 \times 100 \times 100 \times 100$:$10^8$ 个参数
张量分解用更少的参数近似原始张量,实现:
- 数据压缩:减少存储需求
- 去噪:提取主要成分
- 解释性:发现数据的内在结构
图 6:张量分解的两种主要方法。CP分解将张量表示为秩-1张量的和,Tucker分解使用核心张量和模态矩阵。
4.2 CP分解
CANDECOMP/PARAFAC (CP) 分解将张量表示为秩-1张量的和:
$$\mathbf{X} \approx \sum_{r=1}^{R} \lambda_r \mathbf{a}_r \circ \mathbf{b}_r \circ \mathbf{c}_r$$
其中:
- $\lambda_r$ 是权重
- $\mathbf{a}_r \circ \mathbf{b}_r \circ \mathbf{c}_r$ 是向量外积(秩-1张量)
- $R$ 是秩(rank)
矩阵形式:
$$X_{ijk} \approx \sum_{r=1}^{R} \lambda_r a_{ir} b_{jr} c_{kr}$$
*应用:主题建模
文档-词-时间张量 $\mathbf{X}_{D \times W \times T}$ 的CP分解可以发现有:
- 文档主题分布 $\mathbf{A}$
- 主题-词分布 $\mathbf{B}$
- 主题随时间演变 $\mathbf{C}$
4.3 Tucker分解
Tucker分解使用一个核心张量和模态矩阵:
$$\mathbf{X} \approx \mathbf{G} \times_1 \mathbf{A} \times_2 \mathbf{B} \times_3 \mathbf{C}$$
其中:
- $\mathbf{G}_{P \times Q \times R}$ 是核心张量
- $\mathbf{A}, \mathbf{B}, \mathbf{C}$ 是因子矩阵
- $\times_n$ 表示模态-$n$ 乘积
元素形式:
$$X_{ijk} \approx \sum_{p=1}^{P} \sum_{q=1}^{Q} \sum_{r=1}^{R} G_{pqr} a_{ip} b_{jq} c_{kr}$$
与CP分解的关系:当核心张量 $\mathbf{G}$ 为对角张量时,Tucker分解退化为CP分解。
4.4 张量网络与量子计算
张量网络是张量分解的可视化表示,在量子物理和机器学习中广泛应用。
矩阵乘积态 (MPS):
将高维张量表示为一维链状结构:
这大大减少了参数数量,从 $d^N$ 降到 $N \cdot d \cdot \chi^2$($\chi$ 是键维度)。
第五章:张量的现代应用
5.1 推荐系统
协同过滤可以用张量建模:
用户-物品-时间张量 $\mathbf{X}_{U \times I \times T}$
- $X_{uit} = 1$ 如果用户 $u$ 在时间 $t$ 与物品 $i$ 交互
张量分解用于推荐:
通过CP分解学习用户、物品和时间的低维表示,预测缺失的交互:
$$\hat{X}{uit} = \sum{r=1}^{R} \lambda_r a_{ur} b_{ir} c_{tr}$$
这比矩阵分解(仅用户-物品)能捕捉时间动态。
5.2 计算机视觉
高光谱图像:每个像素有数百个光谱波段
- 数据形式:$H \times W \times B$ 的3阶张量
- 张量分解用于去噪和特征提取
视频分析:
- 背景-前景分离:将视频张量分解为低秩背景 + 稀疏前景
- 动作识别:时空特征的张量表示
5.3 自然语言处理
词嵌入的张量表示:
句子可以表示为 $T \times D$ 的矩阵($T$ 个词,每个词 $D$ 维嵌入)。
文档可以表示为 $D \times T \times B$ 的张量($B$ 个文档)。
Transformer的自注意力:
$$\text{Attention}(Q, K, V){b,t,d} = \sum{t’} \text{softmax}\left(\frac{Q_{b,t,:} \cdot K_{b,t’,:}}{\sqrt{d_k}}\right)t V{b,t’,d}$$
这是张量缩并的典型应用。
5.4 物理学与工程学
应力张量:
连续介质力学中,应力是2阶张量 $\sigma_{ij}$,表示单位面积上的力。
电磁场张量:
相对论电动力学将电场和磁场统一为4维时空中的2阶反对称张量:
$$F_{\mu\nu} = \begin{pmatrix} 0 & -E_x & -E_y & -E_z \ E_x & 0 & B_z & -B_y \ E_y & -B_z & 0 & B_x \ E_z & B_y & -B_x & 0 \end{pmatrix}$$
黎曼曲率张量:
描述时空弯曲的4阶张量 $R^\rho_{\sigma\mu\nu}$,是广义相对论的核心。
第六章:张量计算框架
6.1 NumPy中的张量
Python的NumPy库是张量计算的基础:
import numpy as np
# 创建张量
scalar = np.array(5) # 0阶
vector = np.array([1, 2, 3]) # 1阶
matrix = np.array([[1, 2], [3, 4]]) # 2阶
tensor = np.random.rand(3, 4, 5) # 3阶
# 张量运算
C = np.tensordot(A, B, axes=1) # 张量积
D = np.einsum('ijk,jkl->il', A, B) # 爱因斯坦求和
6.2 PyTorch张量
深度学习框架提供了GPU加速的张量运算:
import torch
# GPU张量
x = torch.randn(1000, 1000, device='cuda')
# 自动微分
x.requires_grad = True
y = x ** 2
y.sum().backward()
# x.grad 现在包含梯度
6.3 张量分解库
TensorLy:Python张量分解库
import tensorly as tl
from tensorly.decomposition import parafac, tucker
# CP分解
factors = parafac(tensor, rank=5)
# Tucker分解
core, factors = tucker(tensor, ranks=[3, 4, 5])
结语:张量的统一力量
回顾张量的旅程,我们看到:
数学上,张量是向量和矩阵的自然推广,用统一的框架描述多线性关系。
物理上,张量提供了坐标系无关的描述,是场论和相对论的语言。
计算上,张量是现代数据科学的基础——图像、视频、文本都是张量。
工程上,张量分解为处理高维数据提供了强大工具。
张量的力量在于统一性:
- 标量、向量、矩阵都是张量的特例
- 张量运算统一了线性代数的各种操作
- Einstein求和约定统一了各种缩并规则
正如物理学家John Wheeler所说:
“物质告诉时空如何弯曲,时空告诉物质如何运动。”
在这个描述中,物质用应力-能量张量 $T_{\mu\nu}$ 表示,时空弯曲用度规张量 $g_{\mu\nu}$ 描述——张量语言统一了物质与几何。
对于深度学习的从业者,理解张量意味着:
- 更好的直觉:理解数据的形状和维度操作
- 更高效的代码:利用张量运算的并行性
- 更深入的理解:从张量角度理解神经网络
张量不仅是数学抽象,它是描述世界的通用语言——从微观粒子到宏观宇宙,从静态图像到时序数据,从经典物理到量子场论。
附录:重要公式汇总
张量变换规则
逆变向量: $$v’^i = \frac{\partial x’^i}{\partial x^j} v^j$$
协变向量: $$v’_i = \frac{\partial x^j}{\partial x’^i} v_j$$
2阶张量: $$T’^{ij} = \frac{\partial x’^i}{\partial x^k} \frac{\partial x’^j}{\partial x^l} T^{kl}$$
张量积
$$(\mathbf{A} \otimes \mathbf{B}){i_1 \cdots i_m j_1 \cdots j_n} = A{i_1 \cdots i_m} \cdot B_{j_1 \cdots j_n}$$
缩并
$$C_{j_2 \cdots j_s}^{i_2 \cdots i_r} = A_{k j_2 \cdots j_s}^{k i_2 \cdots i_r} = \sum_{k} A_{k j_2 \cdots j_s}^{k i_2 \cdots i_r}$$
CP分解
$$X_{ijk} = \sum_{r=1}^{R} \lambda_r a_{ir} b_{jr} c_{kr}$$
Tucker分解
$$X_{ijk} = \sum_{p,q,r} G_{pqr} a_{ip} b_{jq} c_{kr}$$
延伸阅读:
- Bishop & Goldberg. Tensor Analysis on Manifolds. Dover, 1980.
- Kolda & Bader. “Tensor Decompositions and Applications.” SIAM Review, 2009.
- Vasilescu & Terzopoulos. “Multilinear Analysis of Image Ensembles.” CVPR, 2002.
- Cichocki et al. “Tensor Networks for Dimensionality Reduction.” Foundations and Trends in Machine Learning, 2016.
*愿你在张量的多维世界中,发现数据的深层结构。