
AI 论文解读系列:ResNet 深度残差学习
引言
2015 年,微软研究院的何恺明等人在 ImageNet 竞赛中提出了一个看似简单却极具革命性的想法:如果神经网络学习的是残差而非直接的映射,会发生什么?这个想法催生了 ResNet(Residual Network),一个拥有 152 层甚至 1000 多层的深度网络,不仅赢得了 ImageNet 2015 的冠军,更重要的是,它解决了困扰深度学习领域多年的一个核心问题——深层网络的退化。
在 ResNet 出现之前,人们普遍认为更深的网络应该具有更强的表达能力。然而实践却给出了反直觉的结果:当网络层数增加到一定程度后,训练准确率反而下降。这不是过拟合,因为在训练集上的表现同样变差了。ResNet 的巧妙之处在于,它通过一个极其简单的跳跃连接(skip connection),让网络可以选择学习残差映射 $\mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x}$,而非直接学习 $\mathcal{H}(\mathbf{x})$。
本文将系统性地解读这篇经典论文,从问题背景、核心思想、数学推导、架构设计到实验验证,循序渐进地揭示 ResNet 为何如此有效。
第一章:深层网络的困境
1.1 从浅层到深层:一个自然的假设
深度学习的成功在很大程度上归功于深层神经网络强大的表示能力。从 LeNet-5 的 5 层,到 AlexNet 的 8 层,再到 VGGNet 的 16-19 层,网络深度的增加似乎与性能提升正相关。这种趋势背后的直觉很简单:更深的网络可以学习更复杂的特征层次结构。
让我们形式化地思考这个问题。假设我们有一个浅层网络,它能够学习某个映射 $\mathcal{H}(\mathbf{x})$。如果我们在其后面添加更多层,直觉上,这些额外的层可以学习恒等映射(identity mapping),即直接输出输入:$\mathbf{y} = \mathbf{x}$。这样,深层网络至少应该和浅层网络表现一样好。
然而,实践观察到的却是另一番景象。
1.2 退化问题:理论与现实的鸿沟
2015 年之前的研究者发现,当网络层数超过 20 层后,出现了一个令人困惑的现象:随着网络加深,训练误差不降反升。
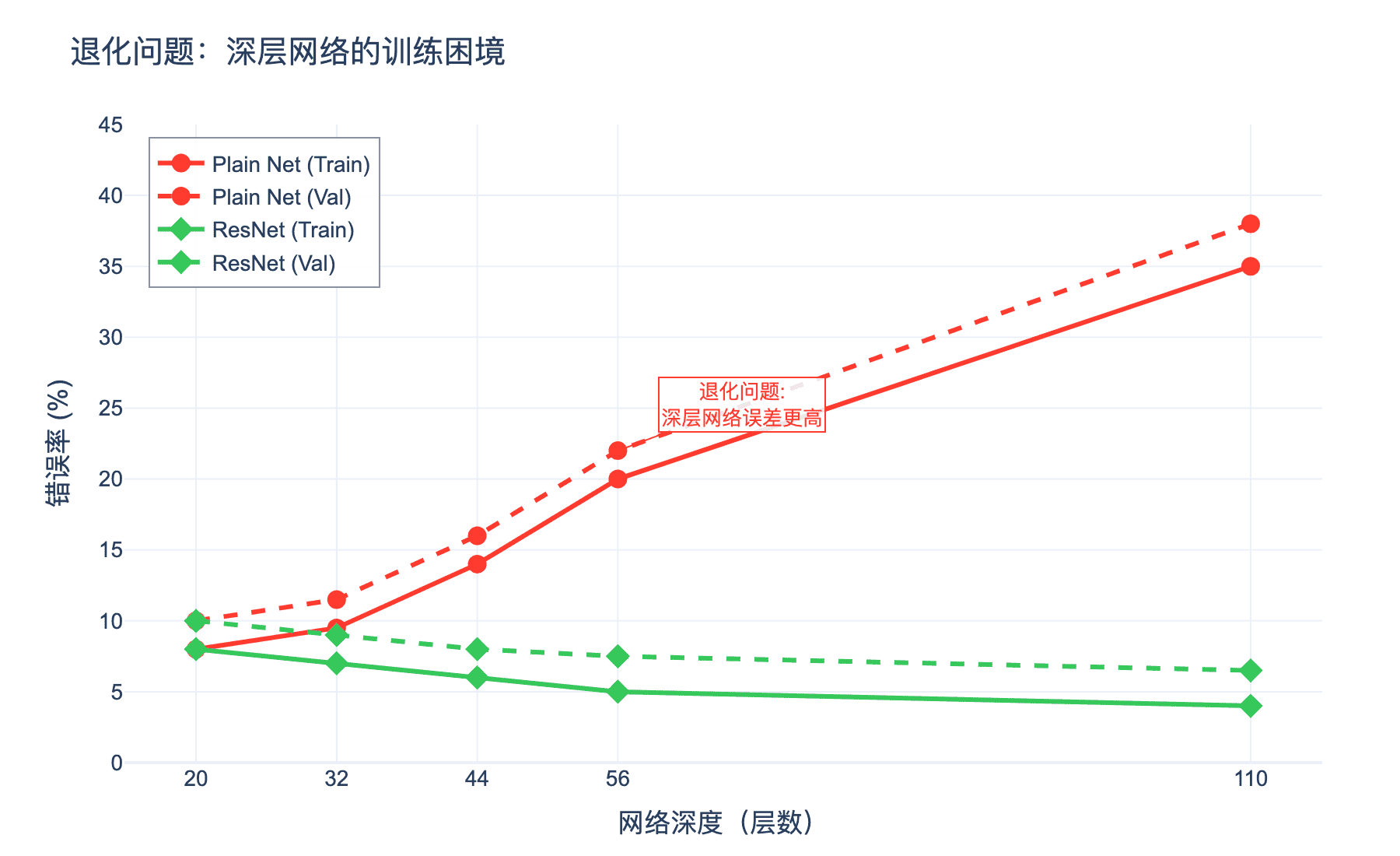
上图展示了在 CIFAR-10 数据集上的典型实验结果。20 层网络的训练误差约为 8%,而 56 层网络的训练误差却上升到了 20%。请注意,这是在训练集上的表现,因此这不是过拟合问题,而是优化问题。
这个现象被称为退化问题(Degradation Problem)。它的存在表明:
- 深层网络更难优化,尽管它拥有更多的参数
- 恒等映射并非那么容易学习
- 简单的堆叠层数并不能保证更好的性能
1.3 梯度消失与退化问题的区别
有人可能会问:这是否是梯度消失(vanishing gradient)问题?毕竟,梯度消失也是深层网络的常见问题。
梯度消失指的是在反向传播过程中,梯度逐层衰减,导致浅层参数几乎得不到更新。这个问题可以通过以下技术缓解:
- 更好的初始化方法(如 Xavier、He 初始化)
- 批归一化(Batch Normalization)
- ReLU 激活函数
然而,即使使用了这些技术,退化问题依然存在。VGGNet 使用 ReLU 和小心初始化,也只能有效训练到 19 层。这说明退化问题有其独特的根源:
多个非线性层很难学习恒等映射。考虑一个两层的非线性网络:
$$\mathbf{y} = \sigma(W_2 \cdot \sigma(W_1 \cdot \mathbf{x}))$$
要让 $\mathbf{y} = \mathbf{x}$,需要 $W_1$ 和 $W_2$ 满足特定的约束,而这种约束在随机初始化和高维空间中很难满足。优化器可能会陷入局部最优,或者需要极长时间才能找到合适的参数。
第二章:残差学习的核心思想
2.1 重新定义学习目标
ResNet 的核心洞察是:与其让网络学习从输入到输出的直接映射,不如让它学习输入与输出之间的差异。这就是"残差"一词的由来。
形式化地,假设我们希望学习一个映射 $\mathcal{H}(\mathbf{x})$。传统网络直接拟合这个映射:
$$\mathbf{y} = \mathcal{H}(\mathbf{x})$$
ResNet 则引入一个残差映射:
$$\mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x}$$
于是,原始映射可以重写为:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{x}$$
这被称为残差学习框架。
2.2 为什么残差更容易学习?
现在问题来了:为什么学习 $\mathcal{F}(\mathbf{x})$ 比学习 $\mathcal{H}(\mathbf{x})$ 更容易?
考虑退化问题的极端情况:如果最优映射就是恒等映射(即 $\mathcal{H}(\mathbf{x}) = \mathbf{x}$),那么:
- 传统网络需要学习 $\mathcal{H}(\mathbf{x}) = \mathbf{x}$
- 残差网络只需要学习 $\mathcal{F}(\mathbf{x}) = \mathbf{0}$
将参数推向零比学习恒等映射要容易得多。在所有可能的参数配置中,零是一个特殊的、容易达到的点。通过 L2 正则化或权重衰减,优化器实际上被鼓励向零靠近。
更一般地,如果最优映射接近恒等映射,残差网络只需要学习一个"小"的扰动,而传统网络需要学习完整的映射。
2.3 跳跃连接的实现
残差学习的实现通过一个极其简单的结构——跳跃连接(skip connection)或快捷连接(shortcut connection):
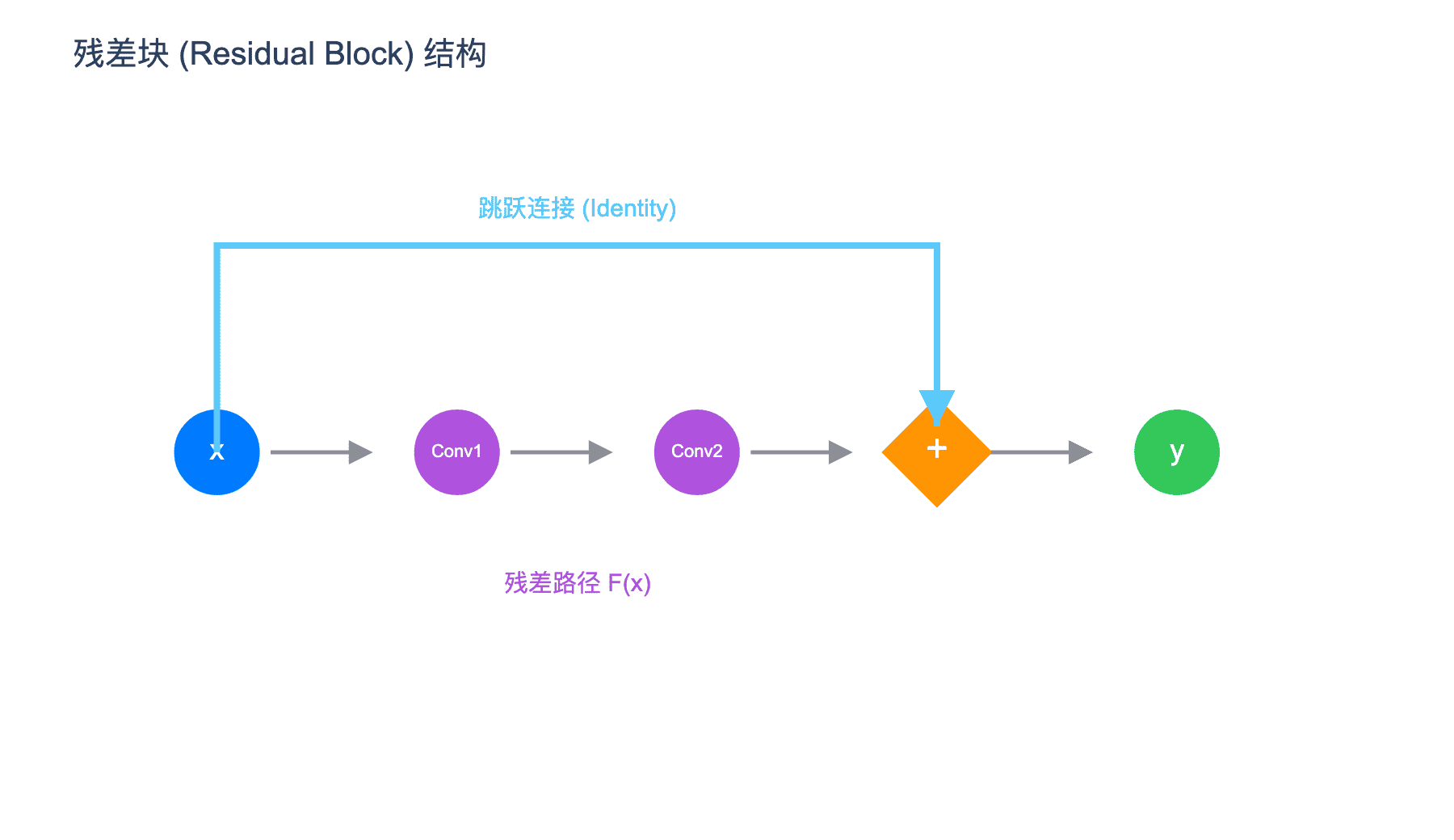
如上图所示,输入 $\mathbf{x}$ 经过几个卷积层(以及 BN、ReLU)产生 $\mathcal{F}(\mathbf{x})$,然后与原始输入 $\mathbf{x}$ 相加,再通过激活函数。
数学上,一个基本的残差块(Residual Block)可以表示为:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}, {W_i}) + \mathbf{x}$$
其中 $\mathcal{F}$ 表示要学习的残差映射。对于图中的两层残差块:
$$\mathcal{F}(\mathbf{x}) = W_2 \cdot \sigma(W_1 \cdot \mathbf{x})$$
注意这里的 $\sigma$ 表示 ReLU,而 $W_1$ 和 $W_2$ 是卷积层的权重。
2.4 维度匹配问题
在实际实现中,还有一个细节需要考虑:当残差路径改变特征图尺寸(如通过步长为 2 的卷积下采样)或通道数时,直接相加 $\mathcal{F}(\mathbf{x}) + \mathbf{x}$ 可能会有维度不匹配的问题。
ResNet 提供了两种解决方案:
方案 A:零填充(Zero-padding)
通过零填充增加通道数,不使用额外参数:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}) + [\mathbf{x}, \mathbf{0}]$$
方案 B:投影 shortcut(Projection shortcut)
使用 $1 \times 1$ 卷积进行投影:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}) + W_s \cdot \mathbf{x}$$
其中 $W_s$ 是 $1 \times 1$ 卷积的权重矩阵。这种方法引入少量额外参数,但性能稍好。
第三章:残差网络的数学分析
3.1 前向传播的动力学
让我们更深入地分析残差连接对前向传播的影响。考虑一个由 $L$ 个残差块组成的网络:
$$\mathbf{x}_{l+1} = \mathbf{x}_l + \mathcal{F}(\mathbf{x}_l, W_l)$$
通过递归展开,第 $L$ 层的输出可以表示为:
$$\mathbf{x}_L = \mathbf{x}l + \sum{i=l}^{L-1} \mathcal{F}(\mathbf{x}_i, W_i)$$
这个公式揭示了一个重要性质:任何一层的特征都可以表示为之前任意一层特征加上一个残差之和。这与传统网络形成鲜明对比——在传统网络中,特征是一系列非线性变换的复合。
3.2 反向传播的梯度流动
残差连接对梯度反向传播的影响更为关键。考虑损失函数 $\mathcal{L}$ 对第 $l$ 层输入的梯度:
$$\frac{\partial \mathcal{L}}{\partial \mathbf{x}_l} = \frac{\partial \mathcal{L}}{\partial \mathbf{x}_L} \cdot \frac{\partial \mathbf{x}_L}{\partial \mathbf{x}_l}$$
由于 $\mathbf{x}_L = \mathbf{x}l + \sum{i=l}^{L-1} \mathcal{F}(\mathbf{x}_i, W_i)$,我们有:
$$\frac{\partial \mathbf{x}_L}{\partial \mathbf{x}_l} = I + \frac{\partial}{\partial \mathbf{x}l} \sum{i=l}^{L-1} \mathcal{F}(\mathbf{x}_i, W_i)$$
因此:
$$\frac{\partial \mathcal{L}}{\partial \mathbf{x}_l} = \frac{\partial \mathcal{L}}{\partial \mathbf{x}_L} + \frac{\partial \mathcal{L}}{\partial \mathbf{x}_L} \cdot \frac{\partial}{\partial \mathbf{x}l} \sum{i=l}^{L-1} \mathcal{F}(\mathbf{x}_i, W_i)$$
这个分解显示了残差连接的关键作用:梯度可以直接从深层流向浅层,而不经过中间层的变换。第一项 $\frac{\partial \mathcal{L}}{\partial \mathbf{x}_L}$ 是梯度的"高速公路",第二项则包含通过残差路径的梯度。
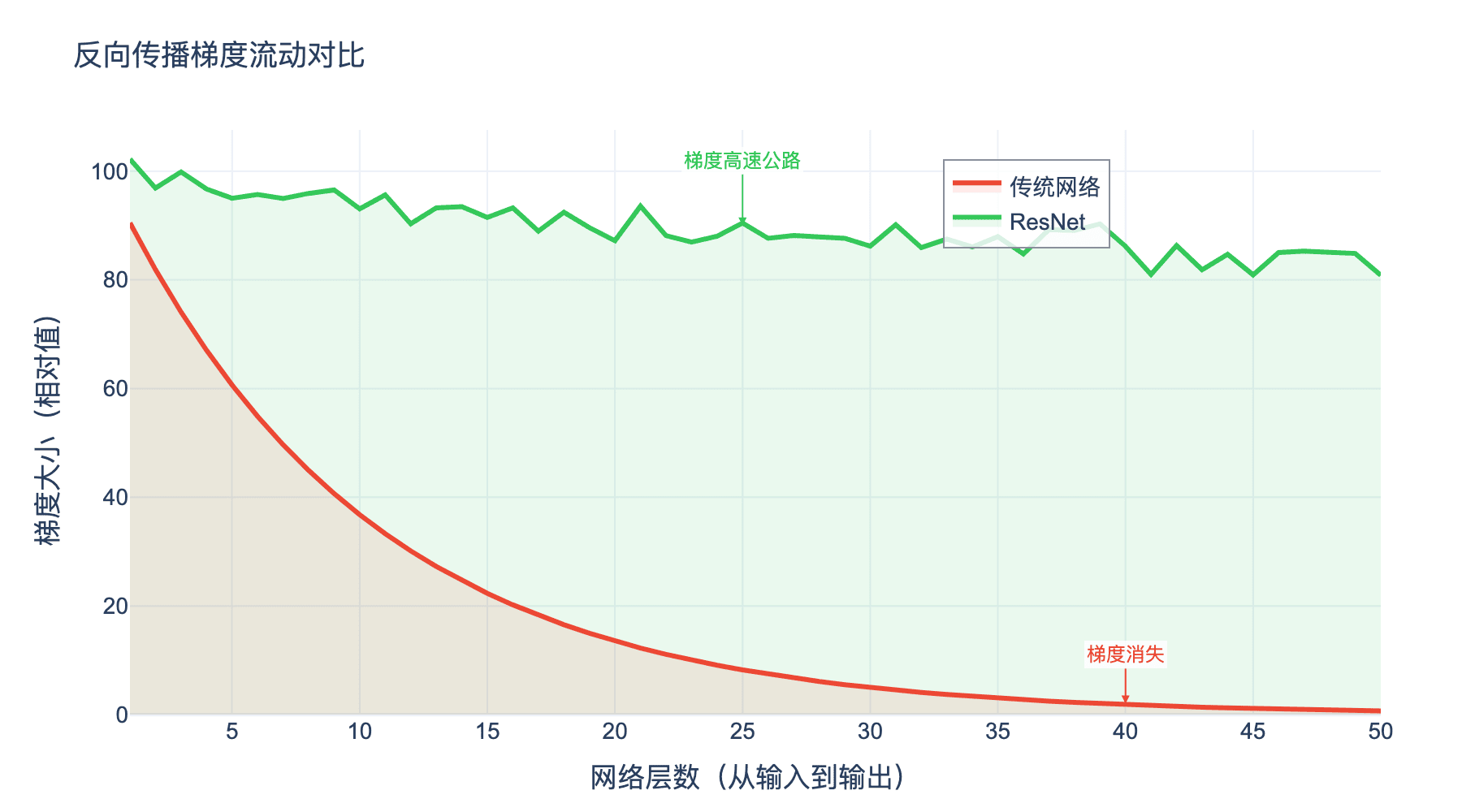
上图展示了传统网络与残差网络的梯度流动对比。在传统网络中,梯度需要经过每一层的链式法则乘法,容易导致梯度消失;而在残差网络中,梯度可以通过跳跃连接直接传播。
3.3 层响应分析
论文中还进行了有趣的层响应分析,即测量每层输出相对于输入的变化程度。结果表明:
- 残差网络通常具有比传统网络更小的层响应
- 随着网络加深,残差函数变得更小
这证实了残差学习的假设:网络确实倾向于学习更小的扰动,而非完全的映射。
第四章:ResNet 架构详解
4.1 基本构建块
ResNet 使用两种基本构建块:
Basic Block(用于 ResNet-18/34):
包含两个 $3 \times 3$ 卷积层:
$$\mathbf{y} = \sigma(W_2 \cdot \sigma(W_1 \cdot \mathbf{x} + b_1) + b_2) + \mathbf{x}$$
Bottleneck Block(用于 ResNet-50/101/152):
包含三个卷积层($1 \times 1$、$3 \times 3$、$1 \times 1$):
$$\mathbf{y} = W_3 \cdot \sigma(W_2 \cdot \sigma(W_1 \cdot \mathbf{x})) + \mathbf{x}$$
其中 $W_1$ 和 $W_3$ 是 $1 \times 1$ 卷积,分别用于降维和升维。这种设计减少了计算量,同时保持了表达能力。
4.2 网络架构概览
以下是不同深度 ResNet 的架构配置:
| 层名称 | 输出尺寸 | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | ResNet-152 |
|---|---|---|---|---|---|---|
| conv1 | $112 \times 112$ | $7 \times 7$, 64, stride 2 | 同上 | 同上 | 同上 | 同上 |
| pool | $56 \times 56$ | $3 \times 3$ max pool, stride 2 | 同上 | 同上 | 同上 | 同上 |
| conv2$_\text{x}$ | $56 \times 56$ | $\begin{bmatrix} 3 \times 3, 64 \ 3 \times 3, 64 \end{bmatrix} \times 2$ | $\times 3$ | $\begin{bmatrix} 1 \times 1, 64 \ 3 \times 3, 64 \ 1 \times 1, 256 \end{bmatrix} \times 3$ | $\times 3$ | $\times 3$ |
| conv3$_\text{x}$ | $28 \times 28$ | $\begin{bmatrix} 3 \times 3, 128 \ 3 \times 3, 128 \end{bmatrix} \times 2$ | $\times 4$ | $\begin{bmatrix} 1 \times 1, 128 \ 3 \times 3, 128 \ 1 \times 1, 512 \end{bmatrix} \times 4$ | $\times 4$ | $\times 8$ |
| conv4$_\text{x}$ | $14 \times 14$ | $\begin{bmatrix} 3 \times 3, 256 \ 3 \times 3, 256 \end{bmatrix} \times 2$ | $\times 6$ | $\begin{bmatrix} 1 \times 1, 256 \ 3 \times 3, 256 \ 1 \times 1, 1024 \end{bmatrix} \times 6$ | $\times 23$ | $\times 36$ |
| conv5$_\text{x}$ | $7 \times 7$ | $\begin{bmatrix} 3 \times 3, 512 \ 3 \times 3, 512 \end{bmatrix} \times 2$ | $\times 3$ | $\begin{bmatrix} 1 \times 1, 512 \ 3 \times 3, 512 \ 1 \times 1, 2048 \end{bmatrix} \times 3$ | $\times 3$ | $\times 3$ |
| 全局平均池化 | $1 \times 1$ | 全局平均池化 | 同上 | 同上 | 同上 | 同上 |
| 全连接层 | 1000 | 1000-d fc, softmax | 同上 | 同上 | 同上 | 同上 |
4.3 架构设计的关键决策
1. 步长设计
每个阶段的第一个残差块使用步长为 2 的卷积进行下采样,将空间维度减半,通道数加倍。
2. 批归一化位置
原始 ResNet 在每个卷积层后、激活函数前使用批归一化。后续改进(Identity Mappings in Deep Residual Networks)建议将 BN 和 ReLU 移到残差路径内部,形成"预激活"结构。
3. 初始卷积层
使用 $7 \times 7$ 的大卷积核和步长 2 快速降低空间维度,提取低级特征。
第五章:实验与结果分析
5.1 ImageNet 分类结果
ResNet 在 ImageNet 2012 分类数据集上取得了突破性成果:
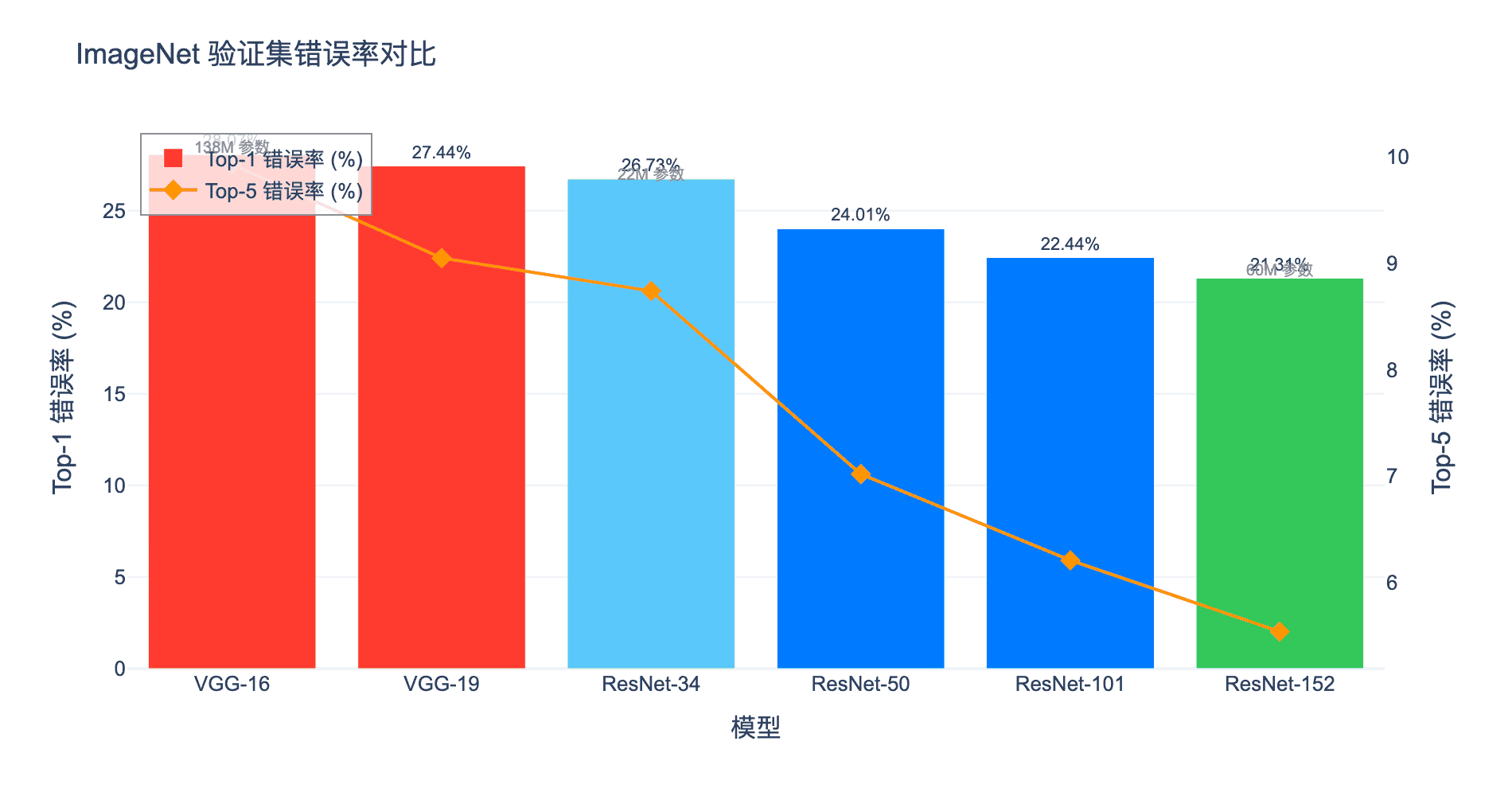
从图中可以看到:
- ResNet-34(使用投影 shortcut)的错误率比 34 层普通网络低约 3.5%
- ResNet-152 的错误率比 VGG-16/19 低约 3.2%
- 更深层的 ResNet-152(60.2M 参数)比 VGG-16(138M 参数)参数量更少但性能更好
5.2 退化问题的解决验证
为了验证残差学习确实解决了退化问题,论文对比了 18 层和 34 层网络:
- 普通网络:34 层比 18 层训练误差更高(退化问题)
- ResNet:34 层比 18 层训练误差更低,验证误差也更好
这直接证明了残差连接的有效性。
5.3 不同 Shortcut 策略的比较
论文比较了三种 shortcut 策略:
A)零填充:增加维度时使用零填充,无额外参数 B)投影 shortcut:增加维度时使用 $1 \times 1$ 卷积 **C)所有 shortcut 都使用投影
结果:B 略优于 A,C 略优于 B,但差距不大。这说明投影 shortcut 并非关键,恒等 shortcut 才是性能提升的主要来源。
5.4 超过 1000 层的网络
论文还尝试了超过 1000 层的极深网络(1202 层):
- 训练误差仍然可以降低
- 但由于参数量过大(19.4M),出现了过拟合
- 使用 maxout 或 dropout 等正则化技术可能进一步改善
第六章:残差网络的影响与拓展
6.1 对其他视觉任务的迁移
ResNet 的成功迅速扩展到其他计算机视觉任务:
目标检测:Faster R-CNN、Mask R-CNN 等使用 ResNet 作为骨干网络
语义分割:FCN、U-Net、DeepLab 等采用 ResNet 提取特征
人体姿态估计:Hourglass、SimpleBaseline 等基于残差思想
6.2 残差思想的变体
ResNet 启发了大量后续研究:
DenseNet:不仅与输入相加,还与之前所有层进行通道拼接
$$\mathbf{x}_l = H_l([\mathbf{x}_0, \mathbf{x}1, \ldots, \mathbf{x}{l-1}])$$
ResNeXt:引入"基数"(cardinality)维度,使用分组卷积:
$$\mathbf{y} = \mathbf{x} + \sum_{i=1}^{C} T_i(\mathbf{x})$$
SENet:在残差块中加入通道注意力机制
EfficientNet:结合残差连接和复合缩放策略
6.3 ResNet 的理论解释
后续研究从理论上解释了 ResNet 的成功:
动态网络视角:残差网络可以看作是一种集成学习,每一层决定是否使用残差路径
常微分方程(ODE)视角:残差块的迭代公式与 Euler 离散化相似:
$$\mathbf{x}_{t+1} = \mathbf{x}_t + f(\mathbf{x}_t, t)$$
这启发了 Neural ODE,将残差网络推广到连续深度。
信息流视角:残差连接创造了信息高速公路,改善了梯度流和特征复用
第七章:深入理解残差学习
7.1 集成学习的视角
2016 年,一项有趣的研究揭示了 ResNet 的另一种解释:一个 ResNet 实际上是一个指数级大小的隐式集成模型。
考虑一个 3 块残差网络,通过递归展开:
$$\mathbf{x}_3 = \mathbf{x}_0 + \mathcal{F}_1(\mathbf{x}_0) + \mathcal{F}_2(\mathbf{x}_1) + \mathcal{F}_3(\mathbf{x}_2)$$
如果每个残差块可以选择"使用"或"不使用",那么 $n$ 个残差块可以产生 $2^n$ 条不同的路径。这解释了为什么删除 ResNet 中的某些层对性能影响很小——网络有其他路径可以补偿。
7.2 动态深度的适应性
残差网络的另一个有趣特性是动态深度。在测试时,网络可以根据输入的复杂度选择"使用"多少层。简单样本可能只需要前几层,复杂样本则会利用深层特征。
这与 Dropout 有相似之处——都是某种形式的模型平均,但 ResNet 的结构化路径选择更加高效。
7.3 与 Highway Networks 的关系
在 ResNet 之前,Highway Networks 也提出了类似的门控机制:
$$\mathbf{y} = T(\mathbf{x}) \cdot \mathcal{F}(\mathbf{x}) + (1 - T(\mathbf{x})) \cdot \mathbf{x}$$
其中 $T(\mathbf{x})$ 是一个门控函数(通常用 sigmoid)。ResNet 可以看作 Highway Network 的特例,其中 $T(\mathbf{x}) = 0.5$(固定不变)。
这种简化带来了两个好处:
- 参数量减半(不需要门控参数)
- 恒等连接始终畅通,梯度流动更直接
结语
ResNet 的提出是深度学习发展史上的一个里程碑。它通过一个简单而优雅的跳跃连接,解决了深层网络的退化问题,使得训练数百层甚至上千层的网络成为可能。
回顾这篇论文的核心贡献:
- 问题识别:明确指出深层网络的退化问题,并区分于梯度消失
- 核心思想:提出残差学习框架,让网络学习残差而非直接映射
- 简洁实现:通过恒等 shortcut 实现,几乎不增加额外计算
- 实验验证:在 ImageNet 等数据集上验证了超深网络的有效性
ResNet 的成功告诉我们:有时候,解决问题的最佳方式不是设计更复杂的模块,而是重新思考问题的本质。学习"差异"比学习"全部"更容易,这个简单却深刻的洞见,至今仍在影响着深度学习的发展。
从 2015 年至今,ResNet 已经成为计算机视觉领域的标准组件。无论是图像分类、目标检测、语义分割还是其他视觉任务,残差连接都是不可或缺的元素。它证明了好的架构设计可以跨越时间和任务,产生持久的影响力。
参考文献
He, K., Zhang, X., Ren, S., & Sun, J. (2016). “Deep Residual Learning for Image Recognition.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). “Identity Mappings in Deep Residual Networks.” European Conference on Computer Vision (ECCV), 630-645.
Veit, A., Wilber, M. J., & Belongie, S. (2016). “Residual Networks Behave Like Ensembles of Relatively Shallow Networks.” Advances in Neural Information Processing Systems (NeurIPS), 29.
Srivastava, R. K., Greff, K., & Schmidhuber, J. (2015). “Highway Networks.” arXiv preprint arXiv:1505.00387.
Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). “Densely Connected Convolutional Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4700-4708.
Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. (2018). “Neural Ordinary Differential Equations.” Advances in Neural Information Processing Systems (NeurIPS), 31.