
AI 论文解读系列:Vision Transformer 视觉 Transformer
引言
2020 年,Google Research 发表了一篇极具颠覆性的论文《An Image is Worth 16$\times$16 Words: Transformers for Image Recognition at Scale》。这篇论文提出了 Vision Transformer(ViT),一个纯粹基于 Transformer 架构的视觉模型,在 ImageNet 分类任务上取得了与最先进的卷积神经网络(CNN)相媲美甚至超越的成绩。
这个成果的震撼之处在于:在计算机视觉领域统治了整整十年的卷积神经网络,终于遇到了真正的挑战者。CNN 凭借其归纳偏置(局部性、平移等变性)在视觉任务中表现出色,而 Transformer 原本是为自然语言处理设计的序列模型。ViT 的成功证明,只要有足够的数据和计算资源,纯粹的注意力机制同样可以在视觉任务中大放异彩。
本文将从注意力机制的基础出发,循序渐进地剖析 ViT 的架构设计、数学原理和训练策略,揭示为何"一张图片相当于 16$\times$16 个单词"这一简单想法能够改变计算机视觉的格局。
第一章:从 CNN 到 Transformer 的范式转移
1.1 卷积神经网络的统治时代
自 2012 年 AlexNet 在 ImageNet 竞赛中取得突破性成果以来,卷积神经网络(CNN)一直是计算机视觉领域的主流架构。CNN 的成功建立在几个关键设计之上:
局部感受野(Local Receptive Fields):每个神经元只与输入的局部区域连接,捕捉局部特征如边缘、纹理。
权重共享(Weight Sharing):同一个卷积核在整个输入上滑动,检测相同特征的不同位置。
平移等变性(Translation Equivariance):输入图像平移,特征图也相应平移,保持空间关系。
这些归纳偏置(Inductive Bias)使 CNN 非常适合处理图像数据,但也带来了一些限制:
- 感受野有限,需要堆叠多层才能获取全局信息
- 对长距离依赖的建模能力较弱
- 难以直接捕捉空间上相距较远的像素之间的关系
1.2 Transformer 在自然语言处理中的成功
2017 年,Google 在论文《Attention Is All You Need》中提出了 Transformer 架构,彻底改变了自然语言处理(NLP)领域。Transformer 完全基于自注意力机制(Self-Attention),摒弃了循环和卷积结构。
Transformer 的核心优势:
全局上下文建模:每个位置都可以直接关注序列中的任意其他位置,不受距离限制。
并行计算:不像 RNN 需要顺序处理,Transformer 可以并行处理整个序列。
可扩展性:随着数据量和计算资源的增加,Transformer 的性能持续提升。
在 NLP 领域,从 BERT 到 GPT 系列,Transformer 架构不断刷新各项任务的基准。一个自然的问题浮现:能否将这一成功迁移到计算机视觉领域?
1.3 将 Transformer 应用于图像的挑战
直接将 NLP 中的 Transformer 应用于图像面临几个挑战:
尺度问题:在 NLP 中,输入是离散的单词或子词单元,序列长度通常为几百到几千。而图像是连续的像素网格,即使是 $224 \times 224$ 的小图像也有 50,176 个像素。
如果直接将每个像素作为一个 token,自注意力的计算复杂度是 $O(n^2)$,其中 $n$ 是序列长度。对于 $224 \times 224$ 的图像:
$$n = 224 \times 224 = 50,176$$
自注意力矩阵的大小将是 $50,176 \times 50,176 \approx 25$ 亿个元素,内存和计算开销都是不可接受的。
归纳偏置的缺失:CNN 的局部性和平移等变性是处理图像的强大先验。纯粹的 Transformer 缺乏这些归纳偏置,需要从数据中从头学习空间关系。
ViT 的解决方案既优雅又简单:将图像分割成固定大小的块(patches),将每个块视为一个"视觉单词"。
第二章:Vision Transformer 的核心思想
2.1 图像块嵌入:从像素到序列
ViT 的第一步是将二维图像转换为序列形式。具体做法如下:
给定一张图像 $\mathbf{x} \in \mathbb{R}^{H \times W \times C}$,其中 $H$ 和 $W$ 是高和宽,$C$ 是通道数(RGB 图像中 $C=3$)。
将图像划分为 $N$ 个固定大小的块(patches),每个块的大小为 $P \times P$:
$$N = \frac{H \times W}{P^2}$$
对于标准的 ViT 配置,输入图像为 $224 \times 224$,块大小 $P = 16$,则:
$$N = \frac{224 \times 224}{16 \times 16} = \frac{50176}{256} = 196$$
这就是论文标题"An Image is Worth 16$\times$16 Words"的由来——一张图像被转换为 196 个"视觉单词"的序列。
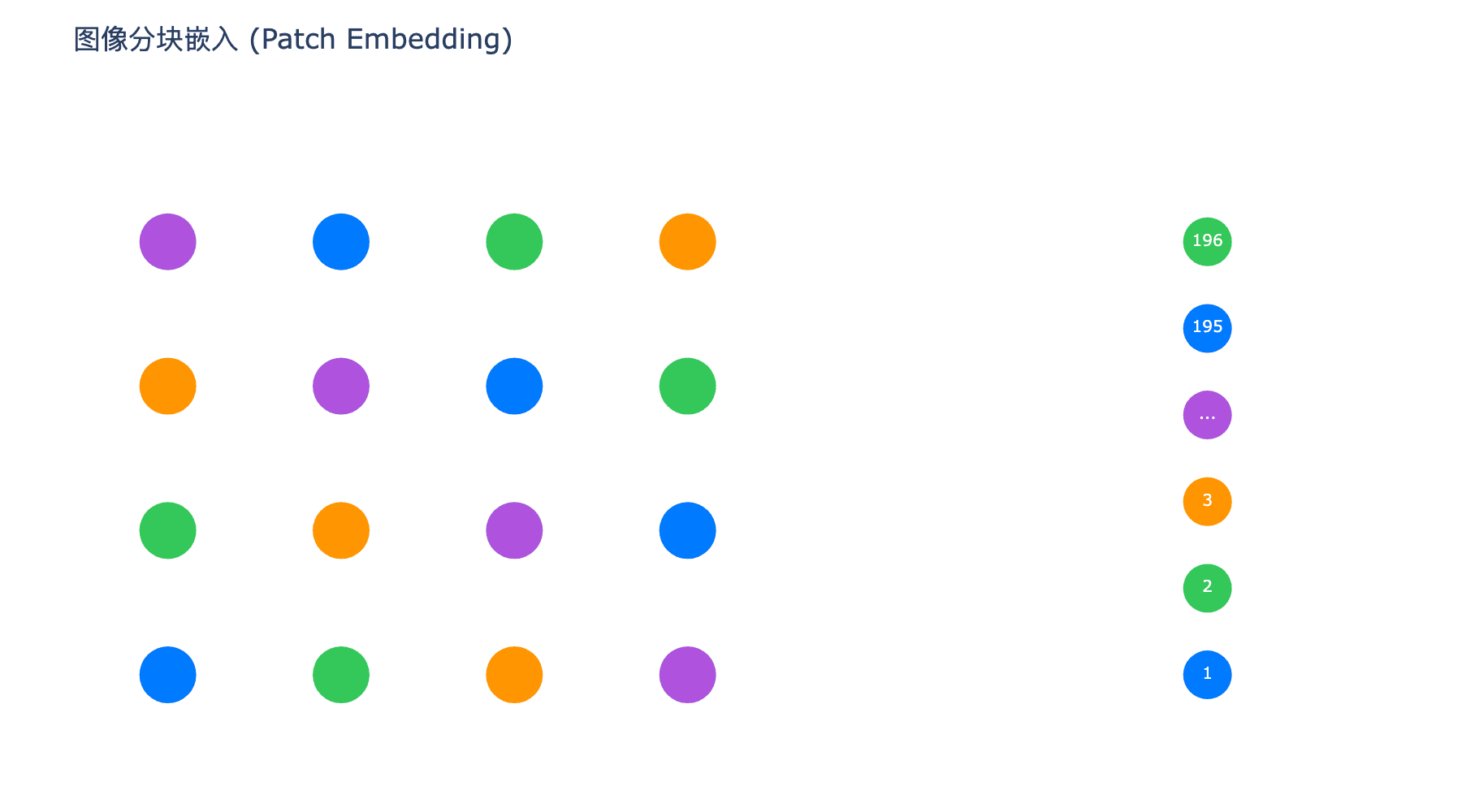
每个图像块被展平并通过一个可训练的线性投影层映射到维度 $D$:
$$\mathbf{z}0 = [\mathbf{x}{class}; \mathbf{x}_p^1\mathbf{E}; \mathbf{x}_p^2\mathbf{E}; \cdots; \mathbf{x}p^N\mathbf{E}] + \mathbf{E}{pos}$$
其中:
- $\mathbf{x}_p^i \in \mathbb{R}^{P^2 \cdot C}$ 是第 $i$ 个展平的图像块
- $\mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}$ 是块嵌入矩阵(Patch Embedding Matrix)
- $\mathbf{E}_{pos} \in \mathbb{R}^{(N+1) \times D}$ 是位置嵌入(Position Embedding)
- $\mathbf{x}_{class}$ 是可学习的类别 token
2.2 类别 Token 与位置编码
类别 Token(Class Token):
ViT 借鉴了 BERT 的做法,在序列开头添加一个特殊的可学习嵌入 $\mathbf{x}_{class}$。这个 token 的输出状态将被用作图像的聚合表示,输入到分类头进行预测:
$$y = \text{LN}(\mathbf{z}_L^0)$$
其中 $\mathbf{z}_L^0$ 是 Transformer 最后一层输出的第一个位置(类别 token)的状态。
位置编码(Position Embedding):
由于 Transformer 本身不具有序列顺序的概念,需要添加位置信息。ViT 使用标准的可学习 1D 位置编码:
$$\mathbf{E}{pos} = [\mathbf{e}{pos}^0; \mathbf{e}{pos}^1; \cdots; \mathbf{e}{pos}^N]$$
实验表明,使用 2D 感知的位置编码或相对位置编码并没有显著提升性能,说明 Transformer 可以从数据中学习空间关系。
2.3 Transformer Encoder 架构
ViT 使用标准的 Transformer Encoder,由交替的多头自注意力(MSA)和多层感知机(MLP)块组成,每个块之前应用 Layer Normalization(LN):
其中 $\ell = 1, \ldots, L$,$L$ 是 Transformer 层的数量。
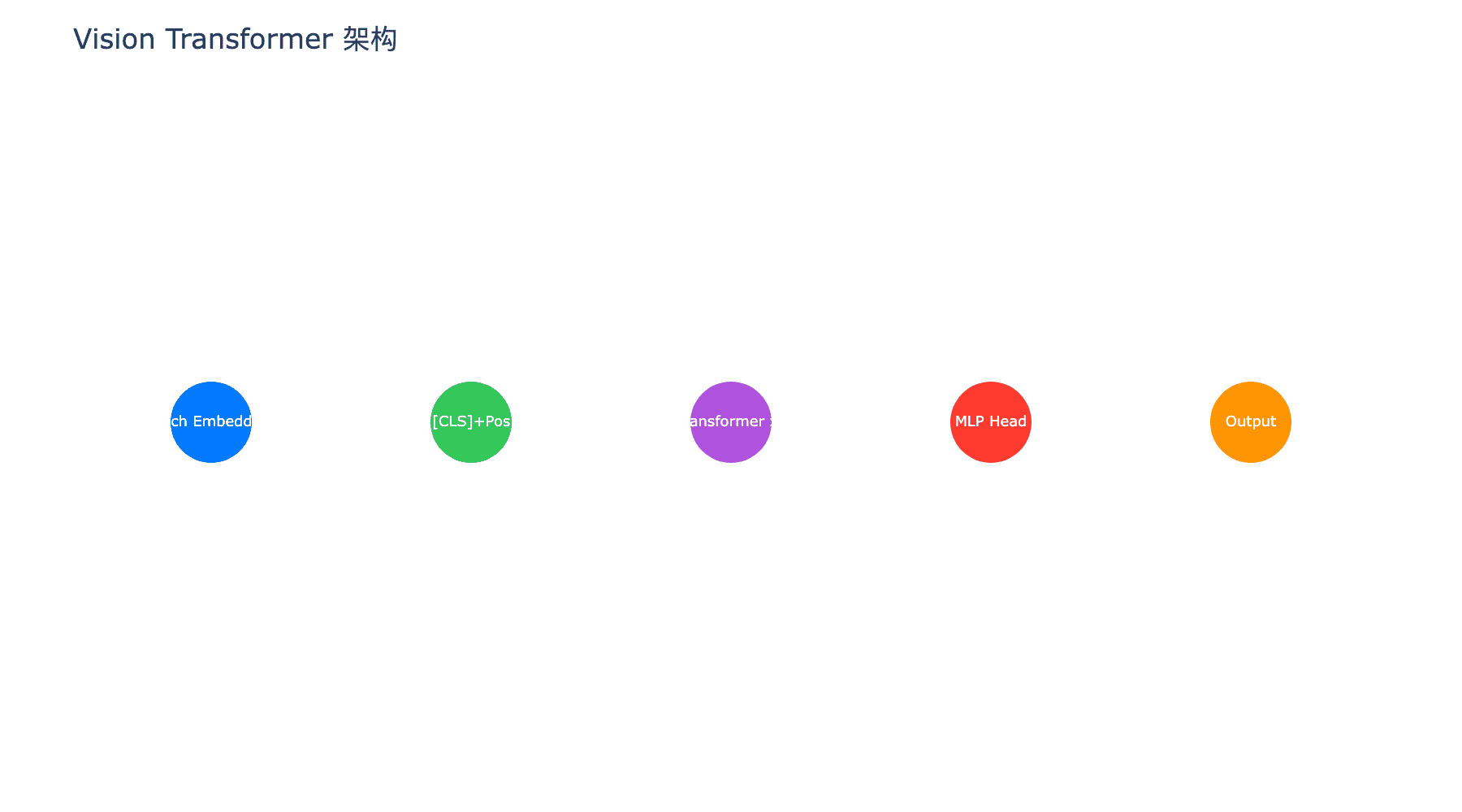
多头自注意力(Multi-Head Self-Attention, MSA):
对于输入 $\mathbf{Z} \in \mathbb{R}^{N \times D}$,首先通过三个线性投影得到查询(Query)、键(Key)和值(Value):
其中 $\mathbf{W}^Q, \mathbf{W}^K, \mathbf{W}^V \in \mathbb{R}^{D \times d_k}$,通常 $d_k = D/h$,$h$ 是注意力头的数量。
缩放点积注意力定义为:
$$\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^T}{\sqrt{d_k}}\right)\mathbf{V}$$
除以 $\sqrt{d_k}$ 是为了防止点积过大导致 softmax 梯度消失。
多头注意力将输入投影到多个子空间,并行计算注意力:
多层感知机(MLP):
每个 Transformer 块包含一个两层的 MLP,使用 GELU 激活函数:
$$\text{MLP}(\mathbf{z}) = \text{GELU}(\mathbf{z}\mathbf{W}_1 + \mathbf{b}_1)\mathbf{W}_2 + \mathbf{b}_2$$
其中 $\mathbf{W}_1 \in \mathbb{R}^{D \times 4D}$,$\mathbf{W}_2 \in \mathbb{R}^{4D \times D}$,中间维度通常扩展为输入的 4 倍。
第三章:ViT 的变体与架构细节
3.1 不同规模的 ViT 模型
ViT 论文提出了多个不同规模的模型,从 Base 到 Huge:
| 模型 | 层数 $L$ | 隐藏维度 $D$ | MLP 维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
此外,还有针对较小输入设计的变体:
- ViT-Tiny/16:$L=12, D=192$,参数量约 5.7M
- ViT-Small/16:$L=12, D=384$,参数量约 22M
3.2 混合架构:CNN + Transformer
除了纯粹的 ViT,论文还探索了混合架构:使用 CNN 提取特征图,然后将特征图块输入 Transformer。
具体做法是:使用 ResNet 的中间特征图(如 ResNet-50 的最后一个阶段输出 $14 \times 14$)代替原始图像块。特征图的每个"像素"对应原始图像的一个区域,可以直接作为序列输入 Transformer。
混合架构的优势:
- 利用 CNN 的局部特征提取能力
- 保持 Transformer 的全局建模优势
- 在中小数据集上表现更好
3.3 高分辨率微调策略
ViT 在预训练时通常使用较低分辨率(如 $224 \times 224$),但在微调时可以使用更高分辨率(如 $384 \times 384$ 或 $512 \times 512$)。
当分辨率改变时,图像块数量 $N$ 发生变化,但位置编码需要保持一致。ViT 采用双线性插值(Bilinear Interpolation)调整预训练的位置编码:
$$\mathbf{E}{pos}^{new} = \text{Interpolate}(\mathbf{E}{pos}^{pretrain}, (N_{new}, D))$$
这使得模型可以迁移到不同分辨率的任务上,无需从头训练。
第四章:训练策略与规模化
4.1 大规模预训练的重要性
ViT 的一个关键发现是:Transformer 在视觉任务中需要比 CNN 更多的数据才能发挥优势。
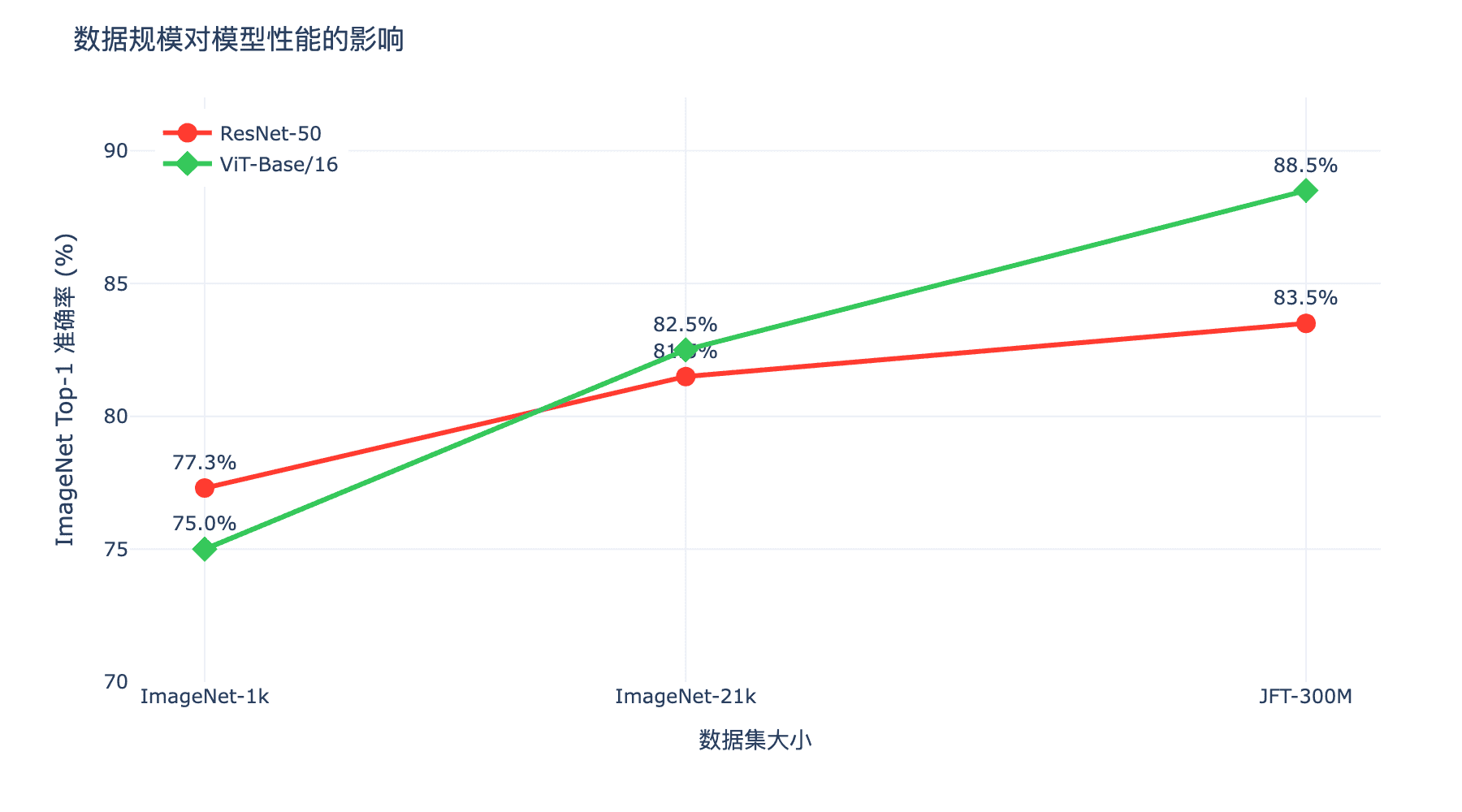
上图展示了不同规模数据集上的性能对比:
- ImageNet-1k(130 万张图像):ResNet 表现优于 ViT
- ImageNet-21k(1400 万张图像):ViT 与 ResNet 性能相当
- JFT-300M(3 亿张图像):ViT 显著超越 ResNet
这一现象的原因在于归纳偏置的差异:
- CNN 具有局部性和平移等变性等强归纳偏置,在数据量较小时可以利用这些先验知识
- Transformer 的归纳偏置较弱,更依赖数据来学习空间关系,但在大规模数据上可以学到更通用的表示
4.2 训练超参数与正则化
ViT 使用以下训练策略:
优化器:AdamW(Adam 的权重衰减修正版本)
学习率调度:
- 热身阶段(Warmup):前 10k 步线性增加学习率
- 余弦退火(Cosine Decay):之后按余弦曲线衰减
数据增强:
- RandAugment:随机组合多种图像变换
- Mixup:将两张图像按比例混合
- Cutmix:将一张图像的裁剪区域粘贴到另一张
- Dropout:注意力 dropout 和 MLP dropout
随机深度(Stochastic Depth):以一定概率随机丢弃整个 Transformer 块,作为正则化手段。
4.3 知识蒸馏:DeiT 的改进
由于 ViT 需要大量数据才能发挥优势,Facebook Research 提出了 Data-efficient Image Transformer(DeiT),通过知识蒸馏(Knowledge Distillation)减少数据依赖。
DeiT 在 ViT 的基础上添加了一个蒸馏 token(Distillation Token),与类别 token 并行:
$$\mathbf{z}0 = [\mathbf{x}{class}; \mathbf{x}_{distill}; \mathbf{x}_p^1\mathbf{E}; \cdots; \mathbf{x}p^N\mathbf{E}] + \mathbf{E}{pos}$$
教师网络(通常是预训练的 CNN)的软标签用于训练蒸馏 token,使学生网络学习教师的知识。
第五章:注意力可视化与可解释性
5.1 自注意力的可视化
ViT 的一个优势是其可解释性。通过可视化注意力权重,可以观察模型关注图像的哪些区域。
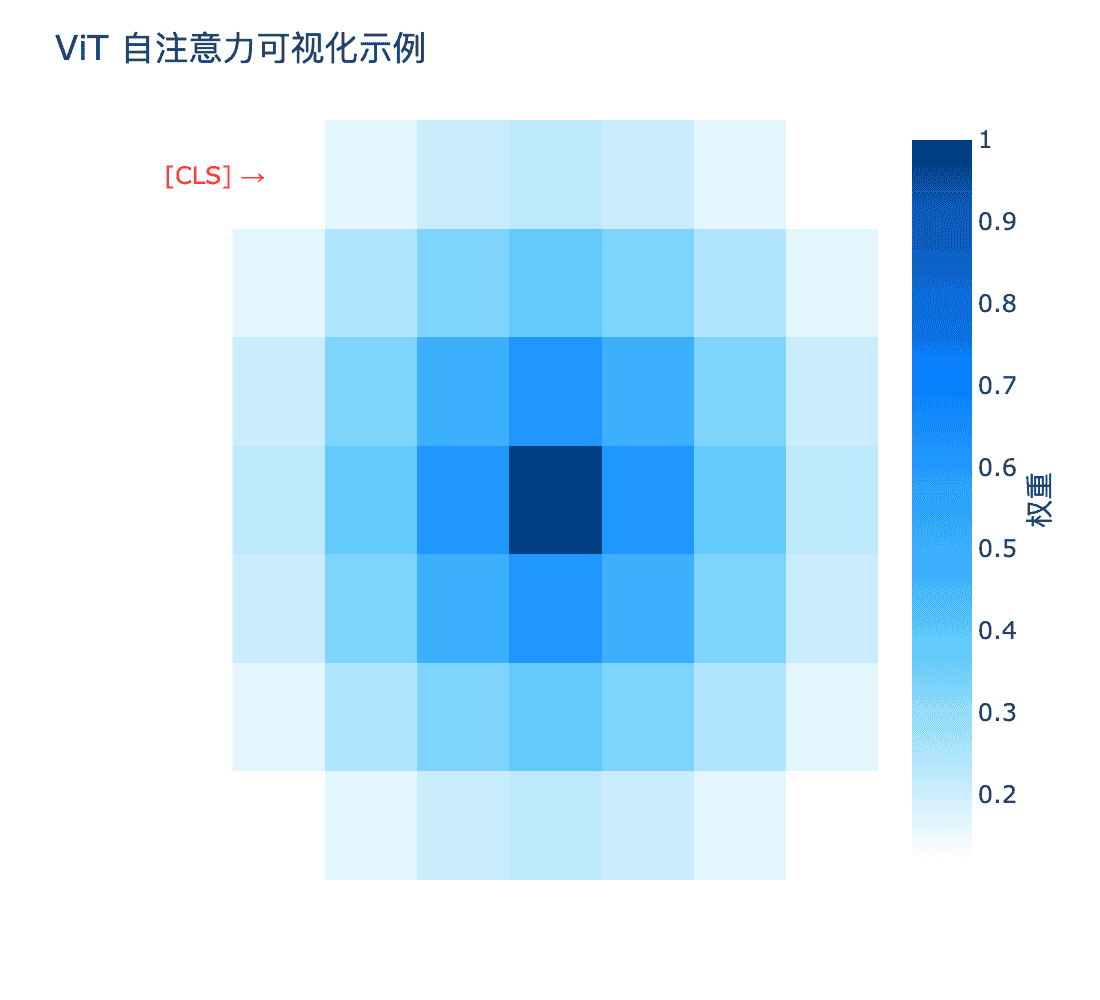
上图展示了 ViT 最后一层的注意力图。可以看到,尽管没有显式的卷积结构,Transformer 依然能够关注到与分类任务相关的语义区域(如狗的面部特征)。
注意力 rollout 是一种聚合多层注意力的技术,可以追踪信息如何在网络中流动:
$$\mathbf{A}^{rollout} = \prod_{\ell=1}^{L} \mathbf{A}^{\ell}$$
其中 $\mathbf{A}^{\ell}$ 是第 $\ell$ 层的平均注意力矩阵。
5.2 位置编码学到的内容
可视化位置编码的相似性矩阵,可以观察到模型学到了 2D 的空间关系:
$$\text{Similarity}(i, j) = \mathbf{e}{pos}^i \cdot \mathbf{e}{pos}^j$$
靠近的图像块具有较高的相似度,远离的图像块相似度较低,说明模型自发学到了位置概念。
5.3 不同层的注意力模式
浅层和深层的注意力模式有所不同:
- 浅层:注意力较为分散,关注局部纹理和边缘
- 中层:开始关注物体部分和语义区域
- 深层:高度集中在判别性特征上,如物体关键部位
第六章:ViT 的拓展与应用
6.1 目标检测与分割
ViT 的成功催生了基于 Transformer 的视觉模型在检测和分割任务中的应用。
DETR(Detection Transformer):将目标检测视为集合预测问题,使用 Transformer Encoder-Decoder 架构直接输出边界框集合,无需锚框(Anchor)和非极大值抑制(NMS)。
Segmenter:将 ViT 拓展到语义分割,使用 Transformer Decoder 或线性投影从 patch 特征恢复像素级预测。
Mask2Former:统一了语义分割、实例分割和全景分割的 Transformer 架构。
6.2 高效 Transformer 变体
标准 ViT 的 $O(N^2)$ 自注意力复杂度在高分率图像上开销较大,研究者提出了多种高效变体:
Swin Transformer:使用窗口注意力(Window Attention)和移位窗口(Shifted Window)机制,将复杂度降至线性,同时保持跨窗口连接。
PVT(Pyramid Vision Transformer):引入金字塔结构,逐步下采样特征图,适应密集预测任务。
Deformable Attention:借鉴可变形卷积思想,只关注参考点周围的关键采样点,减少计算量。
6.3 自监督学习与掩码建模
ViT 也推动了视觉领域的自监督学习发展:
MAE(Masked Autoencoder):随机掩码 75% 的图像块,让模型根据可见块重建被掩码的部分。这种简单的掩码自编码器预训练在下游任务上取得了优异性能。
BEiT:借鉴 BERT 的掩码语言建模,使用离散变分自编码器(dVAE)将图像块转换为视觉 token,然后进行掩码预测。
DINO:通过自蒸馏(Self-Distillation)学习视觉特征,无需标签即可学到可迁移的表示。
第七章:理论分析与深度理解
7.1 归纳偏置的权衡
ViT 引发了对深度学习模型归纳偏置的重新思考:
CNN 的强归纳偏置:
- 局部性:特征只与邻近区域有关
- 平移等变性:特征检测器在空间上共享
- 优点:样本效率高,小数据集表现好
- 缺点:可能限制模型的表达能力
Transformer 的弱归纳偏置:
- 全局注意力:任意位置可直接交互
- 内容自适应:注意力权重取决于输入内容
- 优点:表达能力强,大数据集潜力大
- 缺点:需要更多数据学习空间先验
现代架构(如 ConvNeXt、Swin)尝试融合两者的优点,在保持效率的同时提升表达能力。
7.2 从核方法看注意力
注意力机制可以从核方法的角度理解。自注意力实际上定义了一个数据相关的核函数:
$$\kappa(\mathbf{q}, \mathbf{k}) = \exp\left(\frac{\mathbf{q}^T\mathbf{k}}{\sqrt{d_k}}\right)$$
输出是值向量的核加权平均:
$$\mathbf{o} = \frac{\sum_i \kappa(\mathbf{q}, \mathbf{k}_i)\mathbf{v}_i}{\sum_j \kappa(\mathbf{q}, \mathbf{k}_j)}$$
这与核 PCA、高斯过程等方法有深刻联系,说明 Transformer 可以学习复杂的非线性映射。
7.3 表达能力与优化景观
研究表明,Transformer 的表达能力随着深度和宽度指数增长。与 CNN 相比,Transformer 更容易优化深层网络,因为残差连接和层归一化提供了更好的梯度流。
此外,自注意力的排列等变性(Permutation Equivariance)使得 Transformer 对输入顺序敏感但结构灵活,适合处理不规则数据结构。
结语
Vision Transformer 的提出标志着计算机视觉领域的一个重要转折点。它证明了 Transformer 架构不仅适用于自然语言处理,在视觉任务上同样可以达到甚至超越 CNN 的性能。
回顾 ViT 的核心贡献:
- 简单的图像分块策略:将图像划分为 16$\times$16 的块,转换为序列输入 Transformer
- 大规模预训练的重要性:揭示了 Transformer 需要更多数据才能发挥优势
- 纯粹注意力架构的可行性:证明无需卷积,仅靠注意力即可实现强大的视觉理解
ViT 的影响远远超出了图像分类任务。它催生了 DETR、Segmenter、Swin Transformer 等一系列后续工作,推动了目标检测、语义分割、自监督学习等领域的进步。
更重要的是,ViT 统一了 NLP 和 CV 的架构范式。现在,无论是处理文本、图像还是多模态数据,Transformer 都成为了首选架构。这种统一不仅简化了研究和开发,也为多模态学习(如 CLIP、DALL-E)铺平了道路。
正如论文标题所言——“一张图片相当于 16$\times$16 个单词”——ViT 用最简单的方式回答了视觉与语言的统一表示问题,开启了一个全新的时代。
参考文献
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2020). “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” International Conference on Learning Representations (ICLR).
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). “Attention Is All You Need.” Advances in Neural Information Processing Systems (NeurIPS), 30.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., & Jegou, H. (2021). “Training Data-efficient Image Transformers & Distillation through Attention.” International Conference on Machine Learning (ICML), 10347-10357.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). “End-to-End Object Detection with Transformers.” European Conference on Computer Vision (ECCV), 213-229.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., … & Guo, B. (2021). “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 10012-10022.
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). “Masked Autoencoders Are Scalable Vision Learners.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16000-16009.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021). “Learning Transferable Visual Models From Natural Language Supervision.” International Conference on Machine Learning (ICML), 8748-8763.