
引言:最后的堡垒
2016年1月27日,伦敦。DeepMind 团队在《自然》杂志上发表了一篇注定要载入人工智能史册的论文:“Mastering the game of Go with deep neural networks and tree search”。这篇论文介绍了 AlphaGo——一个结合了深度神经网络和蒙特卡洛树搜索的计算机围棋程序。
就在论文发表两个月后,AlphaGo 以 4:1 的比分击败了世界围棋冠军李世石。这是人工智能历史上的一个转折点。在此之前,围棋被普遍认为是人工智能难以攻克的"最后的堡垒"。
为什么围棋如此困难?让我们从这个问题开始,逐步揭开 AlphaGo 的神秘面纱。
第一章:围棋——人工智能的终极挑战
1.1 搜索空间的爆炸性增长
围棋起源于中国,已有超过 2500 年的历史。它的规则极其简单:黑白双方轮流在 $19 \times 19$ 的棋盘交叉点上落子,以围地多者为胜。然而,这种简单规则却孕育出了近乎无穷的复杂性。
从数学角度分析,围棋的复杂度体现在两个维度:
分支因子:平均每步有约 250 种合法着法。相比之下,国际象棋约为 35。
对局长度:典型围棋对局约有 150 步。国际象棋约为 80 步。
游戏树的规模可以用 $b^d$ 来估计,其中 $b$ 是分支因子,$d$ 是深度。围棋的游戏树复杂度约为 $250^{150} \approx 10^{360}$,而国际象棋约为 $35^{80} \approx 10^{123}$。
为了理解这个数字的庞大程度,可以对比:
- 宇宙中估计的原子数量:约 $10^{80}$ 个
- 可观测宇宙的体积(以普朗克体积计):约 $10^{185}$
这意味着,即使使用穷举搜索——即使我们拥有由宇宙中所有原子构成的超级计算机,每颗原子每秒能进行 $10^{20}$ 次运算——也无法在宇宙年龄(约 138 亿年)内遍历完围棋的所有可能局面。
1.2 局面评估的困难
比搜索空间更棘手的是局面评估。在国际象棋中,程序员可以编写明确的评估函数:王的安全性、子力价值、控制中心等。这些启发式规则可以被形式化为可计算的函数。
但在围棋中,局面评估极其微妙。一个看似被围困的棋子群可能在 20 步后"起死回生";一片看似稳固的领地可能因为一个隐蔽的劫争而化为乌有。人类棋手依靠直觉和"棋感"来判断局面优劣,而这种直觉很难被编码为显式规则。
早在 1997 年,IBM 的 Deep Blue 击败了国际象棋世界冠军卡斯帕罗夫。但围棋专家当时预测,计算机要在围棋上战胜人类顶尖棋手,至少还需要十年——甚至可能永远无法实现。
第二章:深度神经网络——从像素到直觉
AlphaGo 的突破在于使用深度神经网络来模仿人类的"直觉"。但神经网络如何学会评估围棋局面呢?我们需要从基础开始理解。
2.1 卷积神经网络:捕捉空间模式
围棋棋盘的结构天然适合使用卷积神经网络(Convolutional Neural Network, CNN)。棋盘可以看作是一个 $19 \times 19$ 的图像,每个交叉点有不同的"像素值":空点、黑子或白子。
卷积层通过在棋盘上滑动小型滤波器(卷积核)来检测局部模式。例如,一个 $3 \times 3$ 的卷积核可以识别"征子"模式、“断点"或"眼形”。随着网络加深,低层特征被组合成更复杂的抽象概念:
$$ \mathbf{h}^{(l+1)} = \sigma\left( \mathbf{W}^{(l)} * \mathbf{h}^{(l)} + \mathbf{b}^{(l)} \right) $$
其中 $\mathbf{W}^{(l)}$ 是第 $l$ 层的卷积核,$*$ 表示卷积操作,$\sigma$ 是激活函数(通常是 ReLU),$\mathbf{b}^{(l)}$ 是偏置项。
2.2 策略网络:预测人类高手的着法
AlphaGo 包含两个核心神经网络。第一个是策略网络(Policy Network),记为 $p_\sigma(a|s)$,它接收当前棋盘状态 $s$,输出在所有合法着法上的概率分布。
策略网络的目标是模仿人类高手的下棋风格。给定棋盘状态 $s$,它预测人类专家会选择动作 $a$ 的概率:
$$ p_\sigma(a|s) = \frac{\exp(f_\sigma(s, a))}{\sum_{b} \exp(f_\sigma(s, b))} $$
这是一个典型的 softmax 输出,$f_\sigma(s, a)$ 是网络为动作 $a$ 输出的原始分数。
训练数据:DeepMind 使用了 KGS 围棋服务器的 16 万盘人类高手对局,总计约 3000 万个局面-动作对 $(s, a)$。
训练目标:最小化预测分布与专家动作之间的交叉熵损失:
$$ \mathcal{L}{\text{SL}}(\sigma) = -\mathbb{E}{(s,a) \sim \mathcal{D}}\left[ \log p_\sigma(a|s) \right] $$
经过监督学习训练后,策略网络能够以约 57% 的准确率预测人类专家的下法。这意味着,只看一眼棋盘,它就能猜出人类高手超过一半的着法选择。
2.3 价值网络:评估局面胜率
第二个神经网络是价值网络(Value Network),记为 $v_\theta(s)$。它输出一个标量值,估计当前玩家在局面 $s$ 下的获胜概率。
价值网络的作用类似于人类棋手的"局面判断能力"。不同于需要搜索到终局的穷举方法,价值网络可以直接对任意局面给出胜率估计。
训练价值网络面临一个挑战:需要大量带有"真实价值"的局面。DeepMind 的解决方案是使用强化学习自对弈生成数据。策略网络与自己下棋,每一局都会产生一个明确的胜负结果。这些对局被用来训练价值网络,使其预测最终获胜者。
价值网络的训练目标是最小化预测值与实际结果之间的均方误差:
$$ \mathcal{L}{\text{V}}(\theta) = \mathbb{E}{s \sim \mathcal{G}}\left[ (v_\theta(s) - z)^2 \right] $$
其中 $z \in {-1, +1}$ 是实际对局结果(黑胜或白胜)。
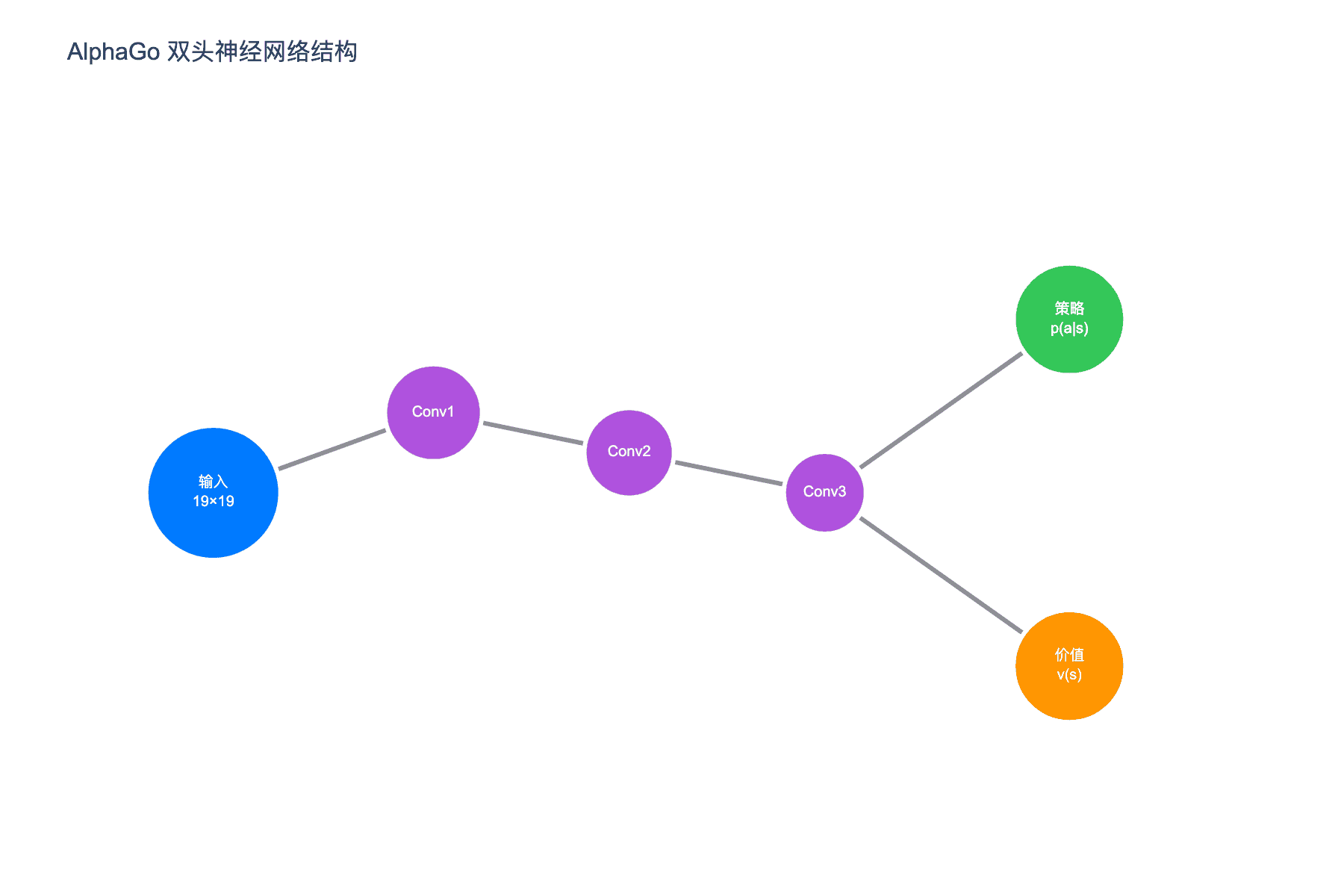
图 1:AlphaGo 的双头神经网络结构。共享卷积层提取特征后,分为策略头(输出 361 个动作概率)和价值头(输出胜率估计)
第三章:蒙特卡洛树搜索——智慧的搜索策略
仅靠神经网络还不足以下出完美的围棋。AlphaGo 的第二个关键组件是蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。这是一种在巨大搜索空间中进行高效决策的算法。
3.1 从随机采样到智能搜索
传统的蒙特卡洛方法通过随机模拟来估计期望值。在围棋中,可以从当前局面开始,随机落子直到终局,统计胜负比例作为局面评估。这种方法被称为朴素蒙特卡洛搜索。
然而,完全随机的模拟效率太低。AlphaGo 使用了一种更智能的搜索策略:上限置信界树搜索(Upper Confidence Bound applied to Trees, UCT)。
3.2 UCT 算法:平衡探索与利用
UCT 算法的核心思想来源于多臂老虎机(Multi-Armed Bandit)问题。想象你面前有多台老虎机,每台有不同的期望收益但未知。你的目标是用有限次数的拉杆最大化总收益。
这个问题的最优策略是平衡探索(尝试不确定的机器)和利用(选择当前估计最好的机器)。UCB 公式给出了理论最优的选择策略:
$$ a_t = \arg\max_a \left[ Q(s,a) + c \sqrt{\frac{\ln N(s)}{N(s,a)}} \right] $$
其中:
- $Q(s,a)$ 是动作 $a$ 的平均收益(利用项)
- $N(s)$ 是状态 $s$ 的总访问次数
- $N(s,a)$ 是动作 $a$ 的访问次数
- $c$ 是控制探索程度的常数
第二项 $\sqrt{\ln N(s) / N(s,a)}$ 鼓励探索被访问较少的动作。随着访问次数增加,探索项递减,算法逐渐收敛到最优动作。
3.3 AlphaGo 的改进:结合神经网络先验
AlphaGo 对传统 UCT 进行了关键改进:使用策略网络 $p_\sigma$ 提供先验概率,指导搜索优先考虑更有希望的动作。
修改后的 UCB 公式为:
$$ U(s,a) = c_{\text{puct}} \cdot P(a|s) \cdot \frac{\sqrt{N(s)}}{1 + N(s,a)} $$
其中 $P(a|s)$ 是策略网络输出的先验概率。这意味着,即使在搜索初期没有统计信息,算法也会优先探索策略网络认为好的着法。
在搜索过程中,每个树节点存储以下信息:
- $N(s,a)$:访问计数
- $W(s,a)$:总动作价值
- $Q(s,a) = W(s,a)/N(s,a)$:平均动作价值
- $P(a|s)$:先验概率
3.4 MCTS 的四个阶段
每次模拟包含四个阶段:
选择(Selection):从根节点开始,使用 UCB 公式递归选择子节点,直到到达叶节点。
扩展(Expansion):如果叶节点未被完全扩展,添加一个新子节点,用策略网络初始化其先验概率。
评估(Evaluation):使用价值网络评估叶节点,或者通过快速走子(Rollout)模拟到终局。AlphaGo 结合两者:
$$ V(s_L) = (1 - \lambda) v_\theta(s_L) + \lambda z_L $$
其中 $z_L$ 是快速走子的结果,$\lambda$ 是混合参数(实验中约为 0.5)。
回溯(Backup):将评估值沿搜索路径反向传播,更新所有相关节点的统计信息:
$$ N(s,a) \leftarrow N(s,a) + 1, \quad W(s,a) \leftarrow W(s,a) + V(s_L) $$
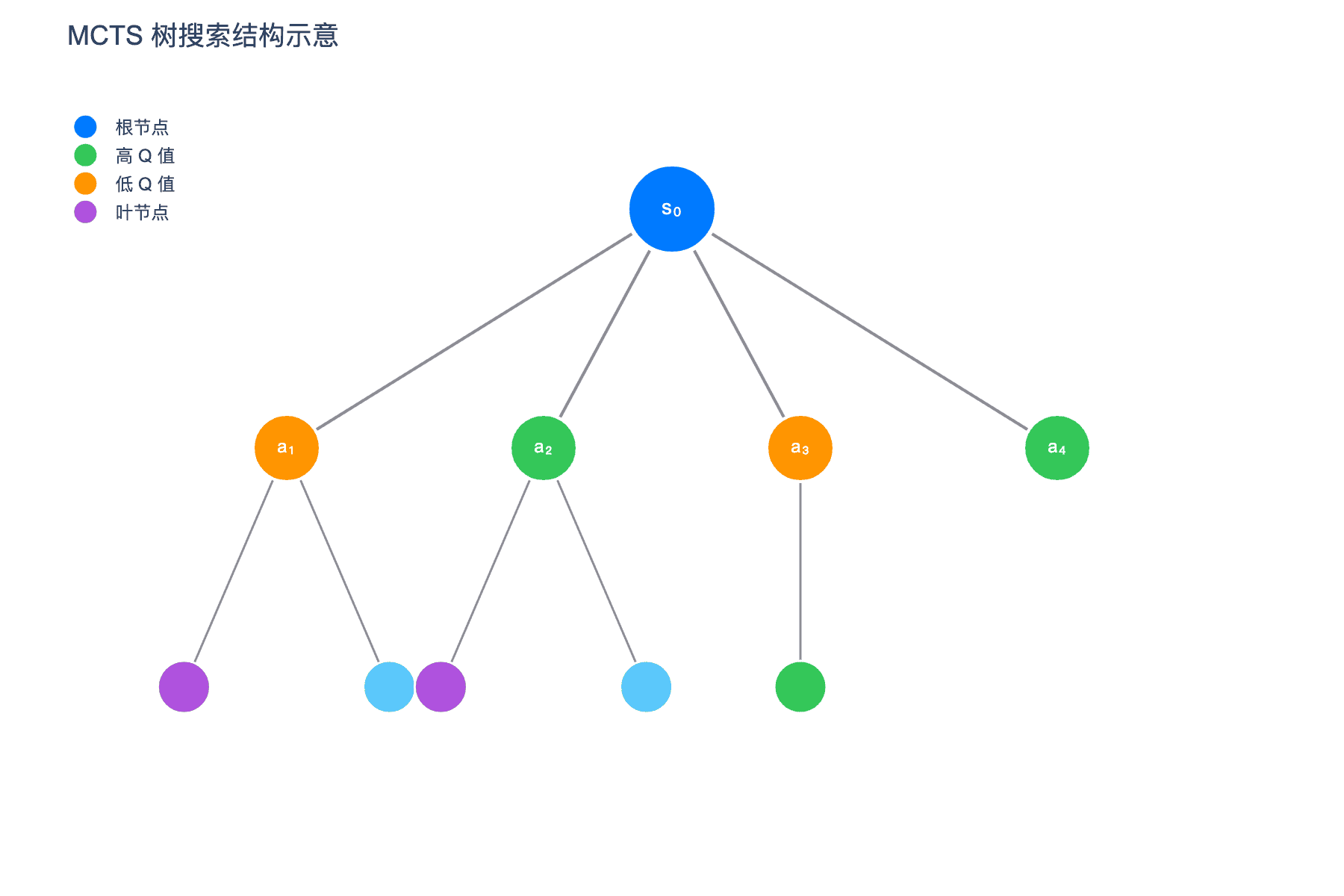
图 2:MCTS 树搜索结构示意。根节点 s₀ 展开多个子节点,每个节点维护 N(访问次数)和 Q(平均价值)统计信息
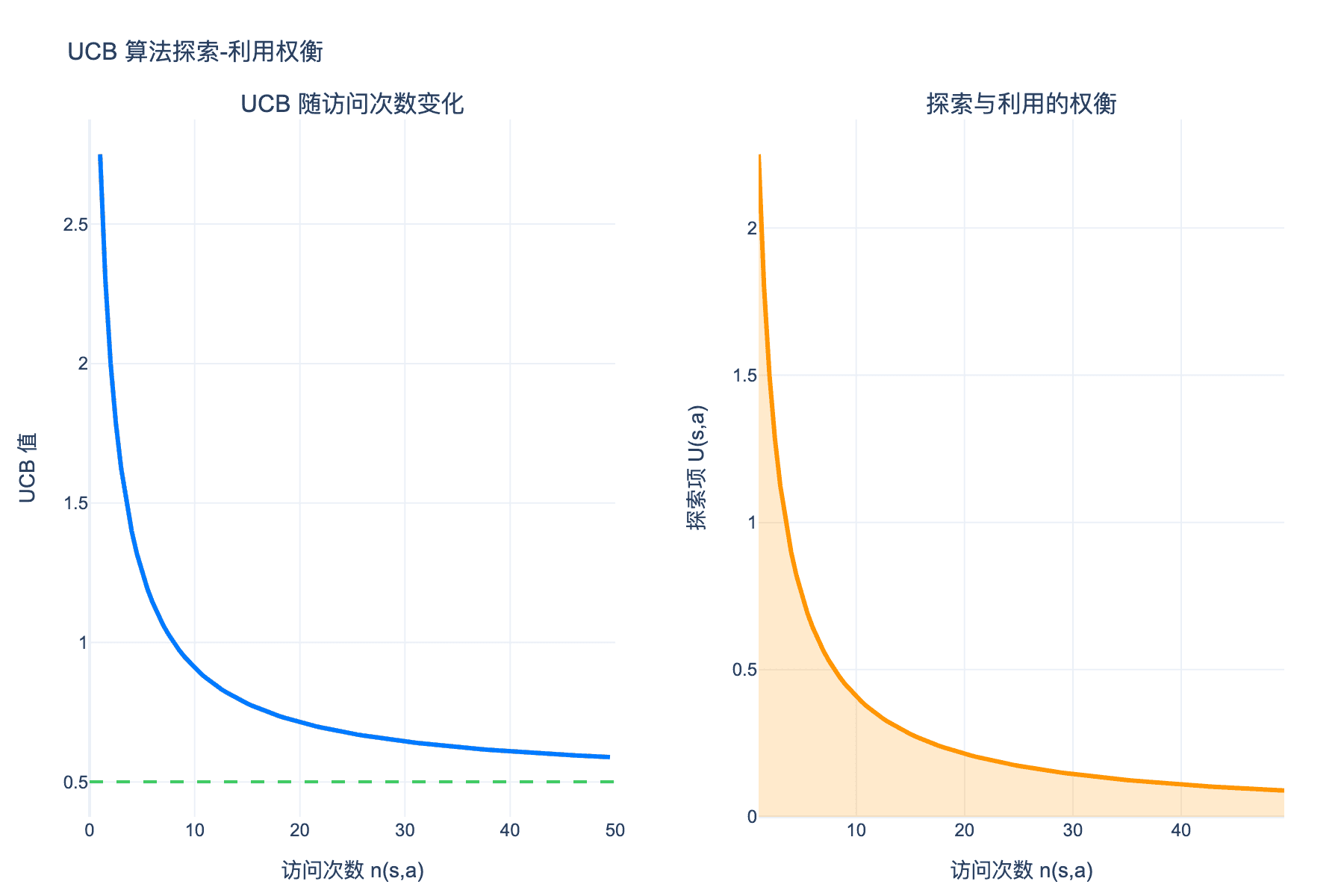
图 3:UCB 公式的探索-利用权衡。左图显示 UCB 值随访问次数递减收敛到 Q 值;右图显示探索项 U 随访问次数衰减
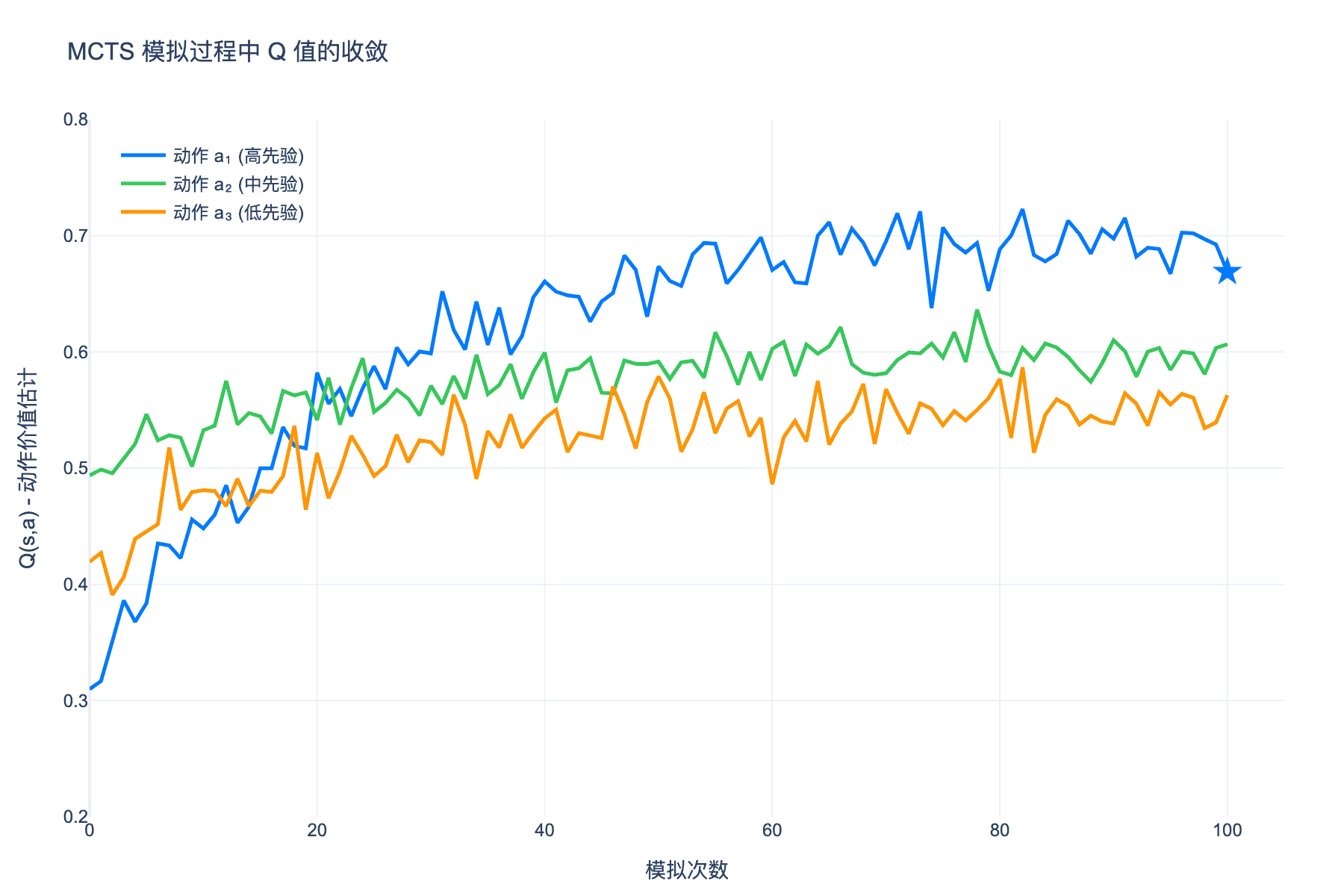
图 4:MCTS 模拟过程中各动作的 Q 值收敛曲线。经过足够多的模拟,最优动作会脱颖而出
第四章:从模仿到超越——强化学习的力量
仅使用人类棋谱训练的 AlphaGo 虽然强大,但受限于人类棋力的天花板。DeepMind 的下一个创新是强化学习(Reinforcement Learning, RL),让 AlphaGo 通过与自己对弈来超越人类水平。
4.1 策略梯度:优化获胜概率
强化学习的目标不是模仿人类,而是最大化获胜概率。这通过策略梯度方法实现。
想象 AlphaGo 的策略网络为 $p_\rho$,其中 $\rho$ 是网络参数。它与自己对弈一局,结果为 $z = +1$(获胜)或 $z = -1$(失败)。策略梯度更新规则为:
$$ \Delta \rho \propto \frac{\partial \log p_\rho(a|s)}{\partial \rho} \cdot z $$
这个公式的直观意义是:如果赢了,增加这局棋中走过的着法的概率;如果输了,降低这些着法的概率。
4.2 自我对弈的流水线
AlphaGo 的强化学习流程如下:
- 当前策略 $p_\rho$ 与随机选择的过去版本对弈
- 记录每局棋的局面、动作和结果
- 使用这些数据进行策略梯度更新
- 定期将当前策略保存到版本库中
与过去版本而非当前版本对弈很重要:这避免了"自我强化"的恶性循环,确保对手风格的多样性。
经过强化学习,策略网络 $p_\rho$ 显著超越了监督学习版本 $p_\sigma$。在对阵其他围棋程序的测试中,$p_\rho$ 达到了 80% 的胜率,而 $p_\sigma$ 仅为 55%。
4.3 价值网络的训练
强化学习生成的对局也用于训练价值网络。策略网络 $p_\rho$ 生成局面 $s$,然后通过快速走子或完整对局得到结果 $z$。价值网络学习预测:
$$ v_\theta(s) \approx \mathbb{E}[z | s] $$
注意这里的一个关键细节:为了防止过拟合,价值网络只在不同对局的局面-结果对上训练,而不是在同一对局的连续局面上训练。这是因为围棋局面高度相关(相邻局面非常相似),在同一条轨迹上训练会导致严重的过拟合。
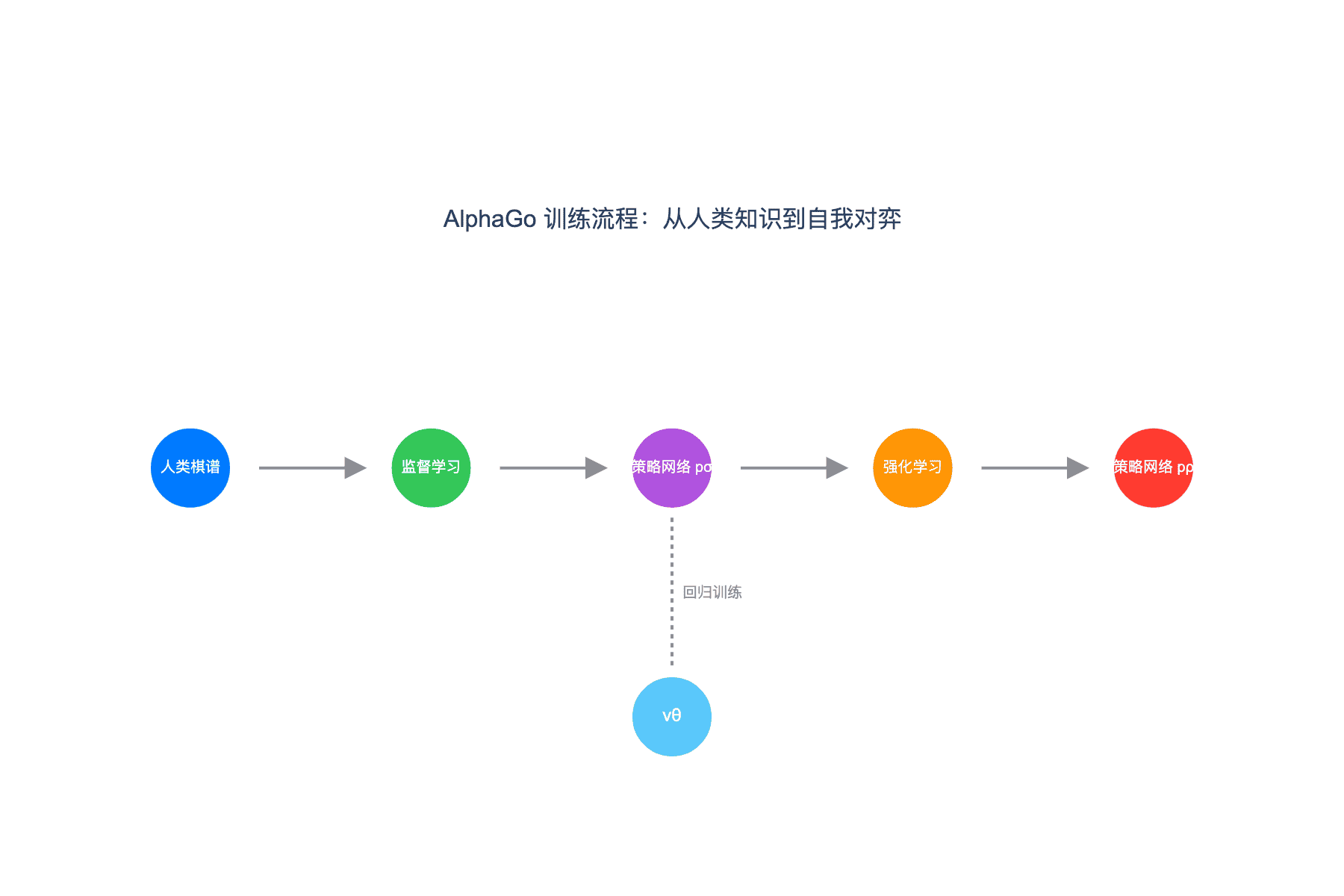
图 5:AlphaGo 的完整训练流程。从人类棋谱开始,经过监督学习得到策略网络 p-sigma,再通过强化学习自我对弈优化为 p-rho,同时训练价值网络 v-theta
第五章:系统架构与分布式计算
5.1 完整系统组成
AlphaGo 的最终版本整合了多个组件:
策略网络:
- 快速策略 $p_\pi$:轻量级卷积网络,用于快速走子(每步 2 微秒)
- 监督学习策略 $p_\sigma$:13 层网络,用于 MCTS 的先验概率
- 强化学习策略 $p_\rho$:与 $p_\sigma$ 结构相同,通过 RL 训练更强
价值网络:
- $v_\theta$:与策略网络共享卷积层,输出局面胜率
搜索算法:
- 异步 MCTS:在多个线程/机器上并行执行搜索
- 结合价值网络和快速走子的混合评估
5.2 分布式 AlphaGo
在与李世石对战的最终版本中,AlphaGo 使用了分布式架构:
- 40 个搜索线程
- 1202 个 CPU 和 176 个 GPU
- 每个位置进行约 10 万次 MCTS 模拟
即使在这种配置下,AlphaGo 平均每步思考时间约为 1-2 分钟——与人类职业棋手的用时相当。
单机版本的 AlphaGo(使用 48 个 CPU 和 8 个 GPU)仍然达到了 95% 的对其他围棋程序胜率。
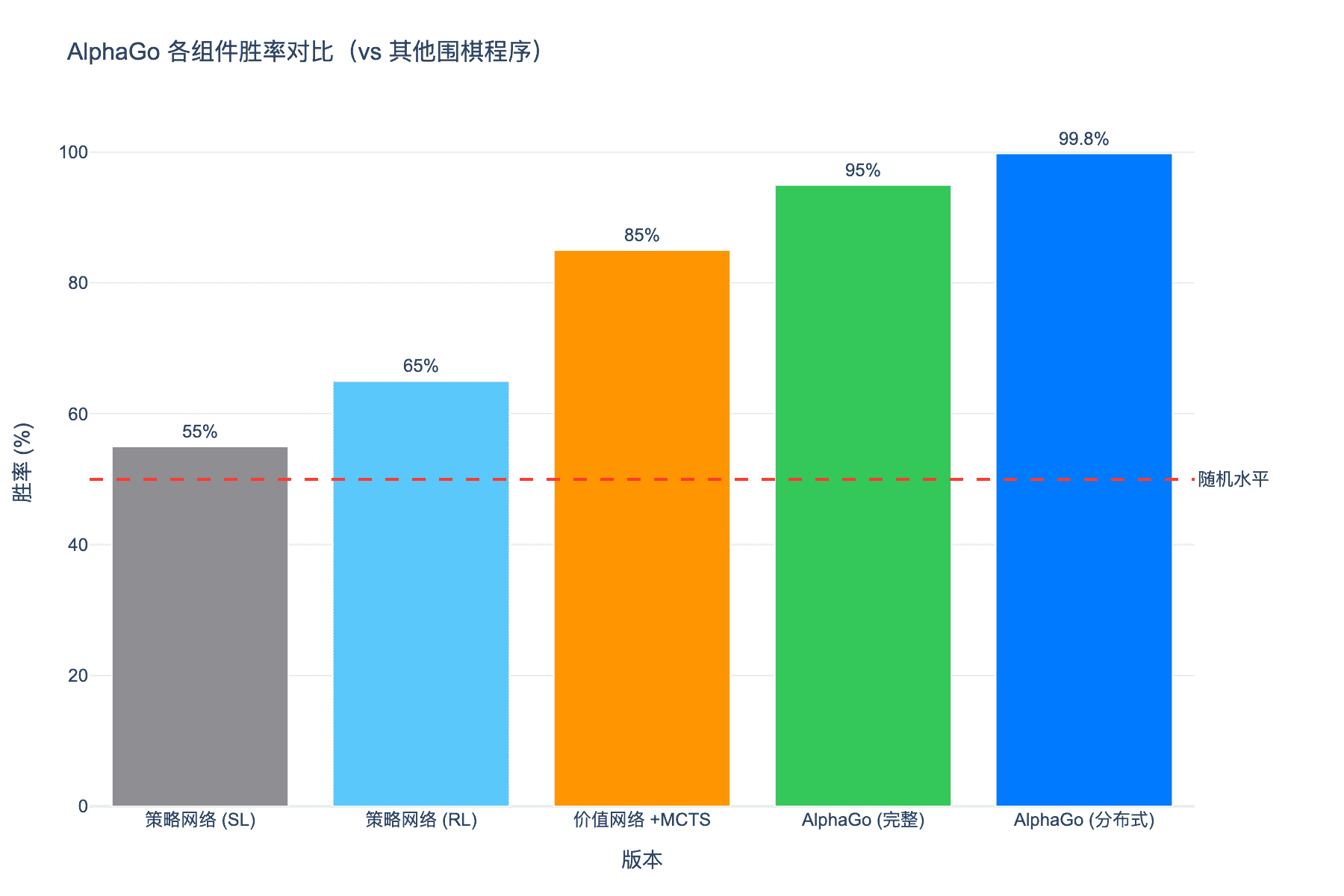
图 6:AlphaGo 各组件与其他围棋程序的胜率对比。完整分布式版本达到了 99.8% 的胜率
第六章:历史性的对局
6.1 与 Fan Hui 的测试
2015 年 10 月,在论文发表前,AlphaGo 与欧洲围棋冠军樊麾(Fan Hui,职业二段)进行了正式比赛。在五番棋比赛中,AlphaGo 以 5:0 完胜。
这是计算机程序首次在正式比赛中击败人类职业围棋棋手。比赛的棋谱后来被作为补充材料与论文一同发布。
6.2 与李世石的巅峰对决
2016 年 3 月,AlphaGo 挑战韩国九段棋手李世石——公认的过去十年最顶尖的围棋选手之一。
比赛在韩国首尔举行,全球数亿人通过直播观看。最终比分为 AlphaGo 4:1 李世石。
第四局中,李世石下出了被称为"神之一手"的 78 手"挖",这步棋让 AlphaGo 的胜率估计出现大幅波动,最终导致 AlphaGo 输掉了这局。这步棋展示了人类创造力的巅峰,也揭示了 AlphaGo 在某些特定局面下的弱点。
但 AlphaGo 在第五局中重新调整,赢得了最终胜利。
第七章:技术贡献与影响
7.1 核心创新
AlphaGo 论文的主要技术贡献包括:
深度神经网络与 MCTS 的深度融合:不仅用神经网络指导搜索,还用搜索结果改进神经网络,形成良性循环。
策略与价值的双网络架构:共享卷积特征提取器,但分别输出策略分布和价值估计。
强化学习自我对弈:通过与自己对弈不断提升,突破人类棋谱的天花板。
异步并行 MCTS:高效利用现代计算硬件,实现大规模并行搜索。
7.2 后续发展
AlphaGo 之后,DeepMind 继续推出了更强大的版本:
AlphaGo Master:2017 年在中国乌镇击败世界排名第一的柯洁,使用与李世石版本类似的架构但训练更充分。
AlphaGo Zero(2017):完全不使用人类棋谱,完全通过自我对弈从零学习。仅训练 40 天就超越了之前击败李世石的版本。
AlphaZero(2017):将算法推广到国际象棋和日本将棋,证明这种方法的通用性。
MuZero(2019):甚至不需要游戏规则,通过模型学习环境的动态,实现了 Atari 游戏和棋类游戏的统一算法。
7.3 对 AI 研究的影响
AlphaGo 的成功标志着多个重要转变:
从显式知识到隐式表示:不再依赖人工编写的规则,而是让神经网络从数据中学习。
从单一算法到系统整合:成功结合了深度学习、强化学习和树搜索三种技术。
从专家系统到通用方法:同样的思路后来被应用到蛋白质折叠(AlphaFold)、数学定理证明等领域。
结语:新的起点
AlphaGo 的故事不仅仅是一个关于游戏的故事。它展示了当深度学习、强化学习和传统搜索算法巧妙结合时,能够产生多么强大的智能。
围棋曾被视为人类智慧的堡垒,因为直觉和创造力在其中扮演着关键角色。AlphaGo 证明,这些看似神秘的能力也可以被神经网络捕捉和学习。正如论文作者所说:
“围棋是最复杂的经典游戏之一,它的挑战性和美学价值吸引了人类数千年。现在,通过将神经网络与树搜索结合,我们不仅攻克了这个难题,也为我们理解智能本身开辟了新的道路。”
AlphaGo 之后,人工智能进入了新的时代。但这只是一个开始——在围棋的 361 个交叉点上,在 $10^{360}$ 种可能性中,我们看到了智能的无限可能。
参考文献
Silver, D., Huang, A., Maddison, C. J., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
Silver, D., et al. (2017). Mastering the game of Go without human knowledge. Nature, 550(7676), 354-359.
Silver, D., et al. (2017). Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. arXiv:1712.01815.
Schrittwieser, J., et al. (2020). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature, 588(7839), 604-609.
本文是 AI 论文解读系列的第一篇,后续将继续深入探讨人工智能领域的经典论文。