
引言:超越人类知识
2017年12月,一个历史性的事件发生在伦敦 DeepMind 的实验室里。一个名为 AlphaZero 的算法,在仅接受游戏规则、没有任何人类棋谱输入的情况下,通过短短 24 小时的自我对弈训练,不仅掌握了国际象棋,还击败了当时世界最强的国际象棋程序 Stockfish。
这不是科幻小说。2018 年 12 月,DeepMind 团队在《科学》杂志上发表了题为"Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm"的论文,向世界展示了这一突破。
AlphaZero 的意义远超它击败的对手。它证明了:一个通用的学习算法可以从随机初始状态开始,仅通过自我博弈,就能达到超越人类数千年积累的专业知识水平。这一成就不仅震撼了棋类世界,更深刻地影响了我们对机器学习和人工智能的认知。
第一章:从 AlphaGo 到 AlphaZero
1.1 AlphaGo 的局限
要理解 AlphaZero 的革命性,我们需要先回顾它的前辈 AlphaGo。
AlphaGo 在 2016 年击败了围棋世界冠军李世石,这是人工智能史上的里程碑。但 AlphaGo 的训练过程依赖于人类专家的知识:
- 监督学习阶段:使用 16 万盘人类高手棋谱训练策略网络
- 强化学习阶段:在监督学习基础上进一步优化
- 价值网络:需要人类棋谱数据进行训练
这种对人类数据的依赖带来了几个问题:
- 知识瓶颈:模型的上限受限于人类棋谱的质量
- 领域限制:针对围棋设计的架构难以迁移到其他游戏
- 数据成本:获取高质量人类棋谱需要大量资源
1.2 完全自主学习的愿景
AlphaZero 的核心突破在于:完全抛弃人类棋谱,从零开始学习。
这一想法的理论基础来自强化学习的一个核心洞察:如果环境是确定的,且我们能够模拟环境的动态,那么一个智能体可以通过与环境的交互来学习最优策略,而无需任何外部示范。
在棋类游戏中,这个条件完美满足:
- 规则完全已知且确定
- 可以完美模拟任意棋局的发展
- 胜负结果是明确的奖励信号
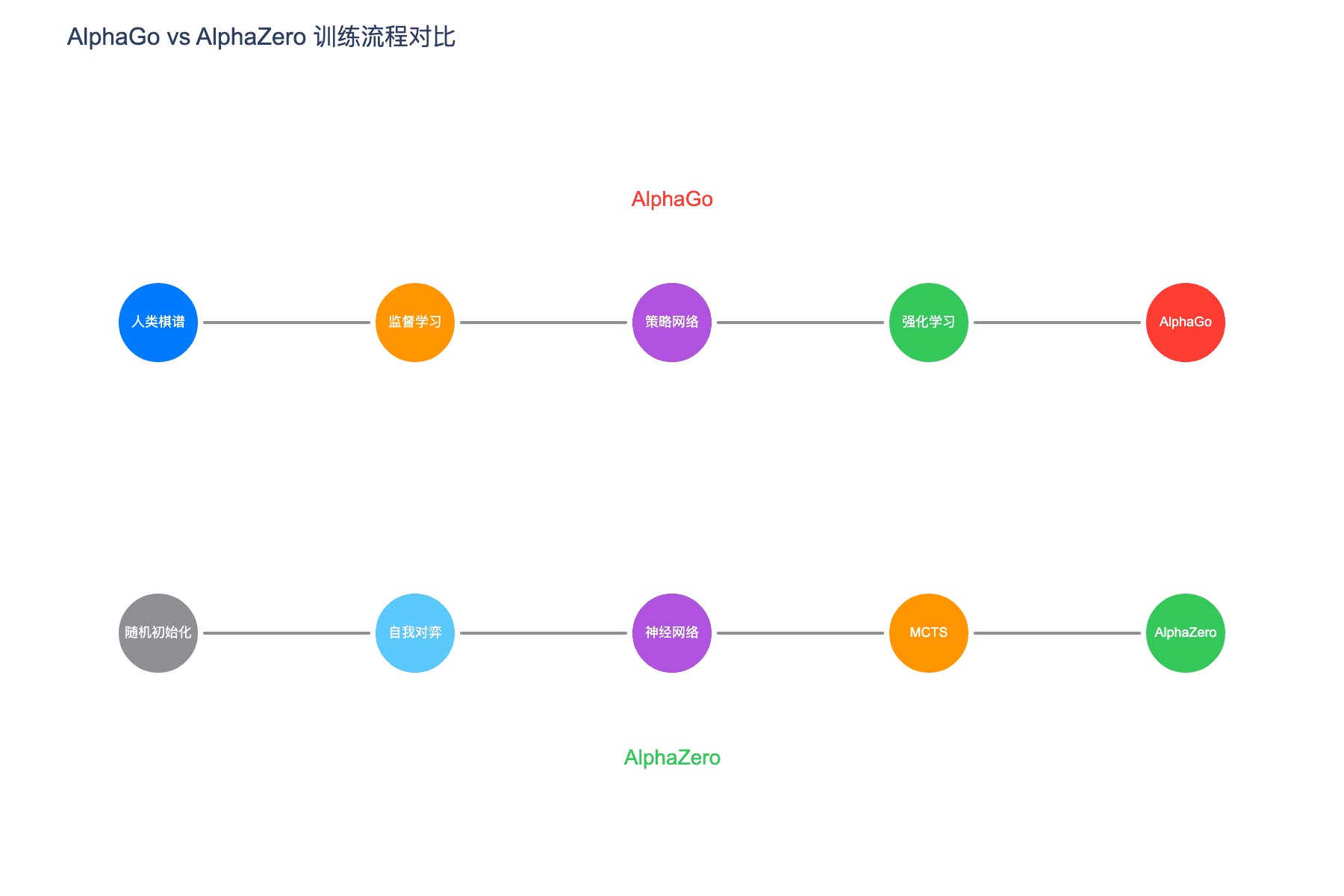
图 1:AlphaGo 与 AlphaZero 训练流程对比。AlphaGo 从人类棋谱开始,AlphaZero 则从随机初始化开始纯自我博弈
第二章:通用算法的三大支柱
AlphaZero 的成功建立在三个关键技术的精妙结合之上:
2.1 深度神经网络
AlphaZero 使用一个深度残差网络(ResNet),接收当前棋盘状态作为输入,同时输出两个关键信息:
策略输出 $p$:一个向量,表示所有合法动作的概率分布
价值输出 $v$:一个标量,估计当前玩家在局势下的胜率(范围 $[-1, +1]$)
网络架构采用双头设计,共享卷积层提取特征,然后分支为策略头和价值头:
$$ (p, v) = f_\theta(s) $$
其中 $s$ 是棋盘状态,$\theta$ 是网络参数。
对于不同游戏,网络规模有所不同:
- 围棋:19 个残差块,256 个滤波器
- 国际象棋:19 或 39 个残差块,256 个滤波器
- 将棋:与围棋相同配置
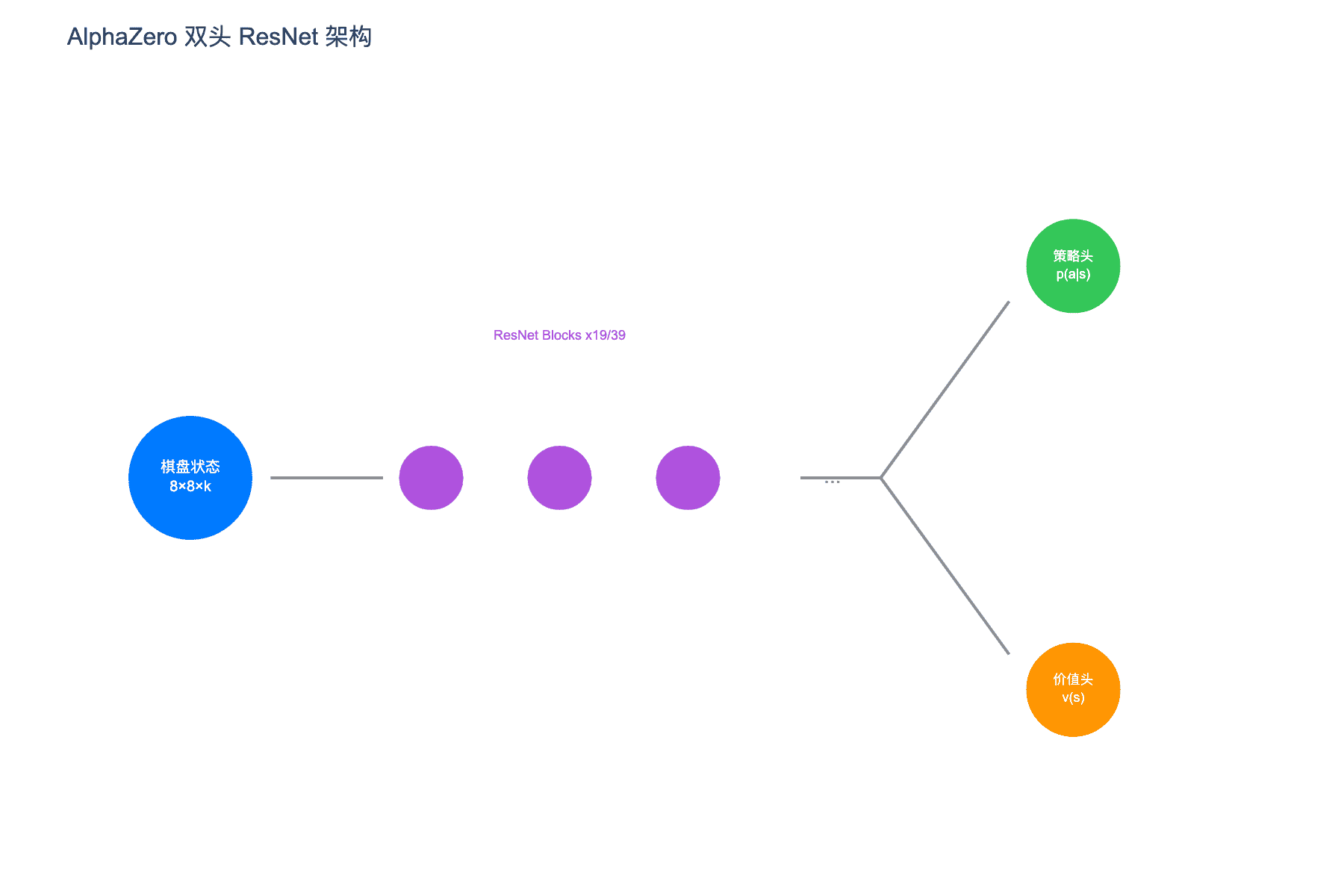
图 2:AlphaZero 双头 ResNet 架构。输入棋盘状态,经过多个残差块处理后,分别输出策略分布 p(a|s) 和价值估计 v(s)
2.2 蒙特卡洛树搜索(MCTS)
AlphaZero 使用 MCTS 作为其"思考引擎"。与 AlphaGo 相比,AlphaZero 的 MCTS 更加简洁优雅。
搜索树中的每个节点存储以下统计信息:
- $N(s, a)$:访问计数,记录动作 $a$ 在状态 $s$ 被选择的次数
- $W(s, a)$:总动作价值
- $Q(s, a) = W(s, a) / N(s, a)$:平均动作价值
- $P(s, a)$:先验概率,由神经网络提供
MCTS 包含四个阶段:
选择(Selection):从根节点开始,使用 PUCT 算法递归选择子节点,直到到达叶节点。
扩展(Expansion):如果叶节点不是终止状态,使用神经网络评估该节点,并扩展其子节点。
评估(Evaluation):使用神经网络 $f_\theta$ 对叶节点进行评估,得到 $(p, v)$。
回溯(Backup):将评估值沿搜索路径反向传播,更新所有相关节点的统计信息。
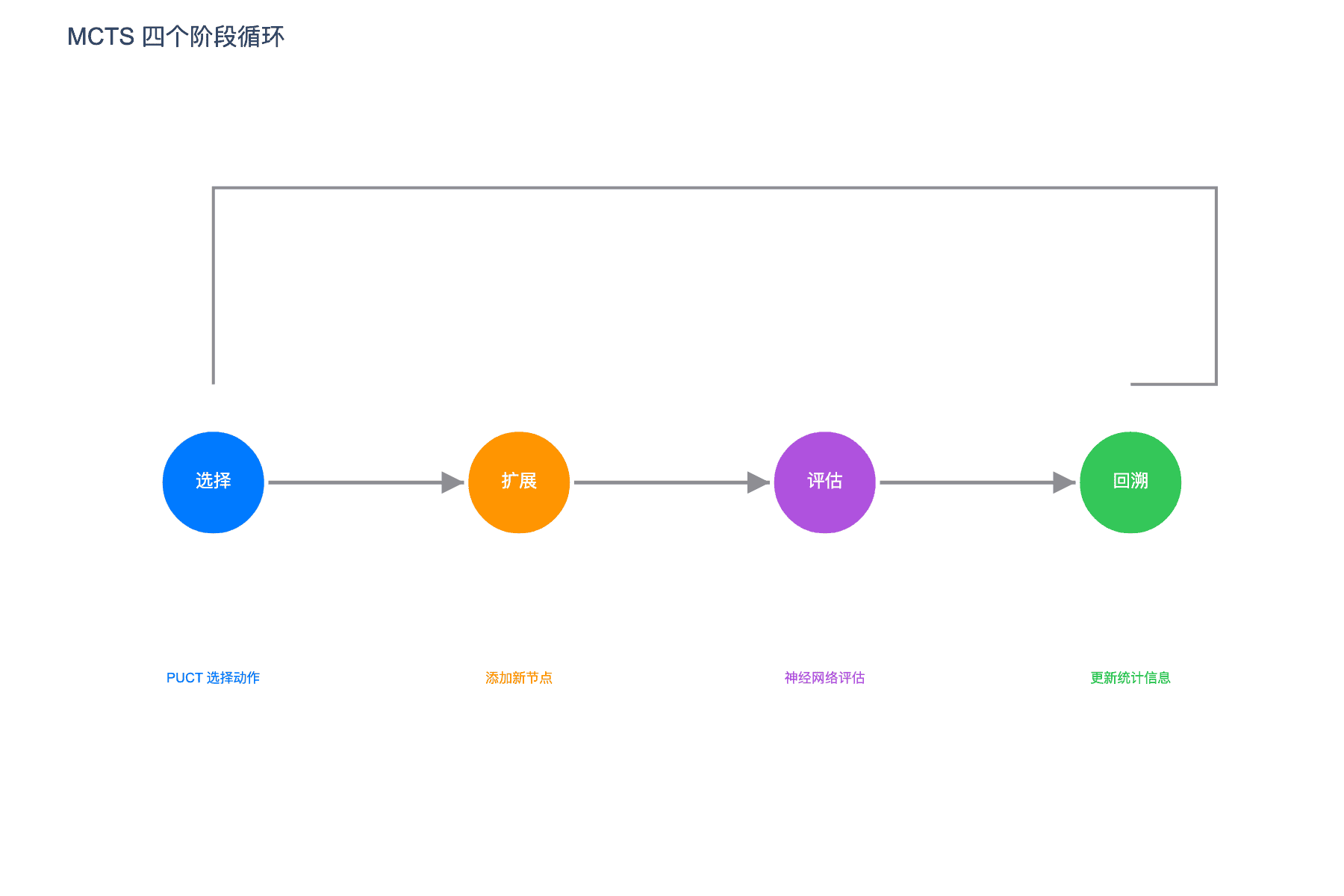
图 3:MCTS 四个阶段循环。选择 → 扩展 → 评估 → 回溯,不断迭代优化搜索树
2.3 PUCT 选择算法
AlphaZero 使用 PUCT(Predictor + UCB applied to Trees)算法选择动作:
$$ U(s, a) = c_{\text{puct}} \cdot P(s, a) \cdot \frac{\sqrt{N(s)}}{1 + N(s, a)} $$
$$ a^\ast = \arg\max_a \left[ Q(s, a) + U(s, a) \right] $$
其中:
- $Q(s, a)$ 是利用项,表示当前对动作价值的估计
- $U(s, a)$ 是探索项,鼓励访问计数少的动作
- $c_{\text{puct}}$ 是控制探索程度的常数
- $P(s, a)$ 是神经网络提供的先验概率
这个公式的精妙之处在于:神经网络提供的 $P(s, a)$ 指导搜索优先考虑更有希望的分支,而统计信息 $N(s, a)$ 和 $Q(s, a)$ 则提供了实际的搜索反馈。两者结合,实现了"直觉"与"计算"的完美平衡。
第三章:自我博弈学习循环
AlphaZero 的学习过程是一个美妙的闭环系统:
3.1 生成训练数据
AlphaZero 通过自我对弈生成训练数据。每局游戏的生成过程如下:
MCTS 模拟:在当前棋盘状态 $s_t$ 下,执行 800 次(或 1600 次)MCTS 模拟
动作选择:根据访问计数选择动作。在训练早期,使用更随机的选择以鼓励探索:
$$ \pi(a | s_t) = \frac{N(s_t, a)^{1/\tau}}{\sum_b N(s_t, b)^{1/\tau}} $$
其中 $\tau$ 是温度参数。当 $\tau = 1$ 时,按访问计数比例选择;当 $\tau \to 0$ 时,选择访问次数最多的动作。
执行动作:在棋盘上执行选中的动作,得到新状态 $s_{t+1}$
记录数据:存储 $(s_t, \pi_t)$ 对,其中 $\pi_t$ 是 MCTS 生成的策略分布
重复直到终局:继续直到游戏结束,得到最终结果 $z \in {-1, 0, +1}$(输、平、赢)
3.2 训练神经网络
每完成一局游戏,将记录的 $(s, \pi, z)$ 数据加入训练队列。神经网络的训练目标是最小化以下损失函数:
$$ \mathcal{L} = (z - v)^2 - \pi^T \log p + c |\theta|^2 $$
这个损失函数包含三个部分:
价值损失 $(z - v)^2$:均方误差,使价值估计 $v$ 接近实际结果 $z$
策略损失 $-\pi^T \log p$:交叉熵,使策略输出 $p$ 接近 MCTS 生成的策略 $\pi$
L2 正则化 $c|\theta|^2$:防止过拟合
神经网络使用随机梯度下降进行优化,批量大小为 2048 或 4096,学习率采用余弦退火策略从初始值逐渐降到 0。
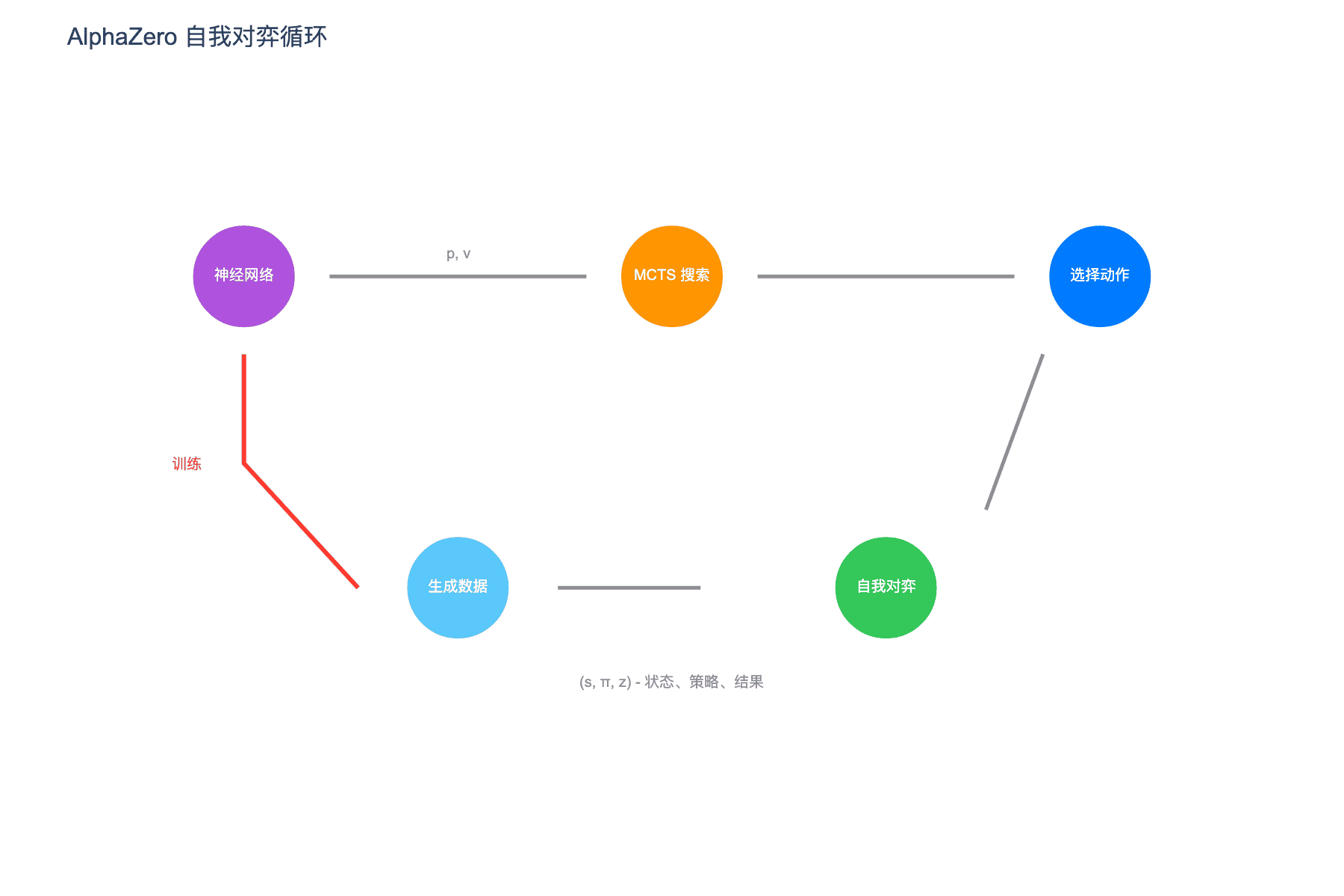
图 4:AlphaZero 自我对弈循环。神经网络指导 MCTS,MCTS 生成训练数据,数据用于训练神经网络,形成闭环
第四章:从零到大师——训练过程
4.1 训练规模
AlphaZero 的训练规模令人印象深刻:
国际象棋:
- 700,000 个训练批次(mini-batches)
- 每批次 4096 个位置
- 总训练步数约 9 小时(在 5000 个 TPU v1 上)
将棋:
- 相同配置,训练约 12 小时
围棋:
- 700,000 个训练批次
- 总训练时间约 34 小时
4.2 性能提升曲线
训练过程中,AlphaZero 的棋力呈现指数级增长。以国际象棋为例:
- 1 小时后:达到业余爱好者水平
- 4 小时后:超过普通国际象棋引擎
- 9 小时后:击败 Stockfish(当时世界最强国际象棋程序)
更惊人的是,AlphaZero 不仅强大,还展现出了人类从未见过的下棋风格。它愿意牺牲大量子力换取长远的战略优势,这种"动态平衡"的棋风与传统引擎截然不同。
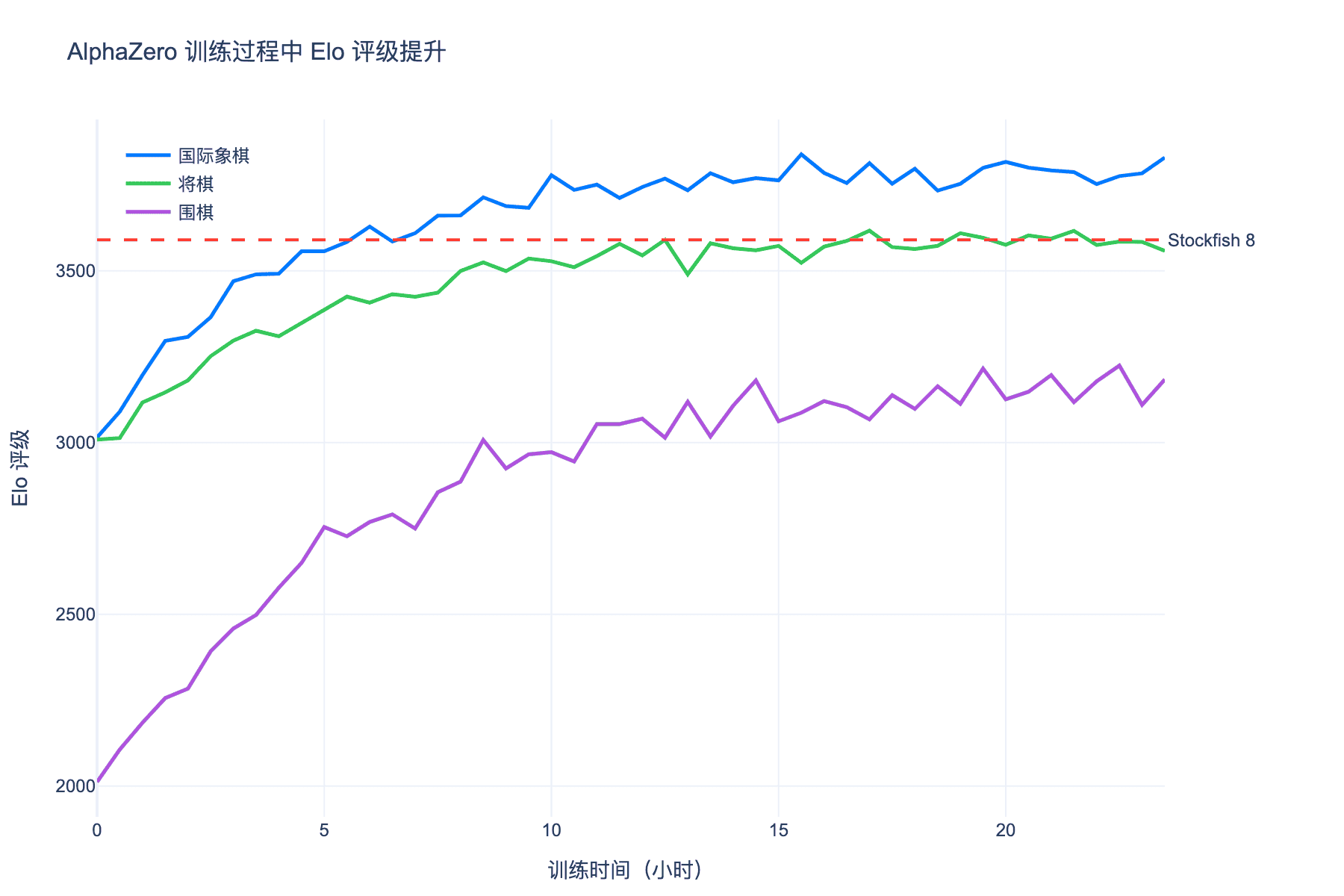
图 5:AlphaZero 训练过程中 Elo 评级提升曲线。在 24 小时内达到并超越世界顶级程序水平
第五章:三种游戏,一种算法
AlphaZero 最令人惊叹的特性之一是它的通用性。同一个算法,仅通过调整游戏规则,就在三种完全不同的棋类游戏中达到了超人类水平。
5.1 三种游戏的复杂度对比
| 游戏 | 分支因子 | 平均步数 | 复杂度($10^x$) |
|---|---|---|---|
| 国际象棋 | 35 | 80 | $10^{123}$ |
| 将棋 | 80 | 115 | $10^{226}$ |
| 围棋 | 250 | 150 | $10^{360}$ |
将棋的分支因子高达 80(远超国际象棋的 35),因为 captured 棋子可以被放回棋盘(“持驹"规则)。围棋虽然分支因子最高,但 AlphaZero 通过之前击败李世石的 AlphaGo Zero 已经积累了丰富的围棋经验。
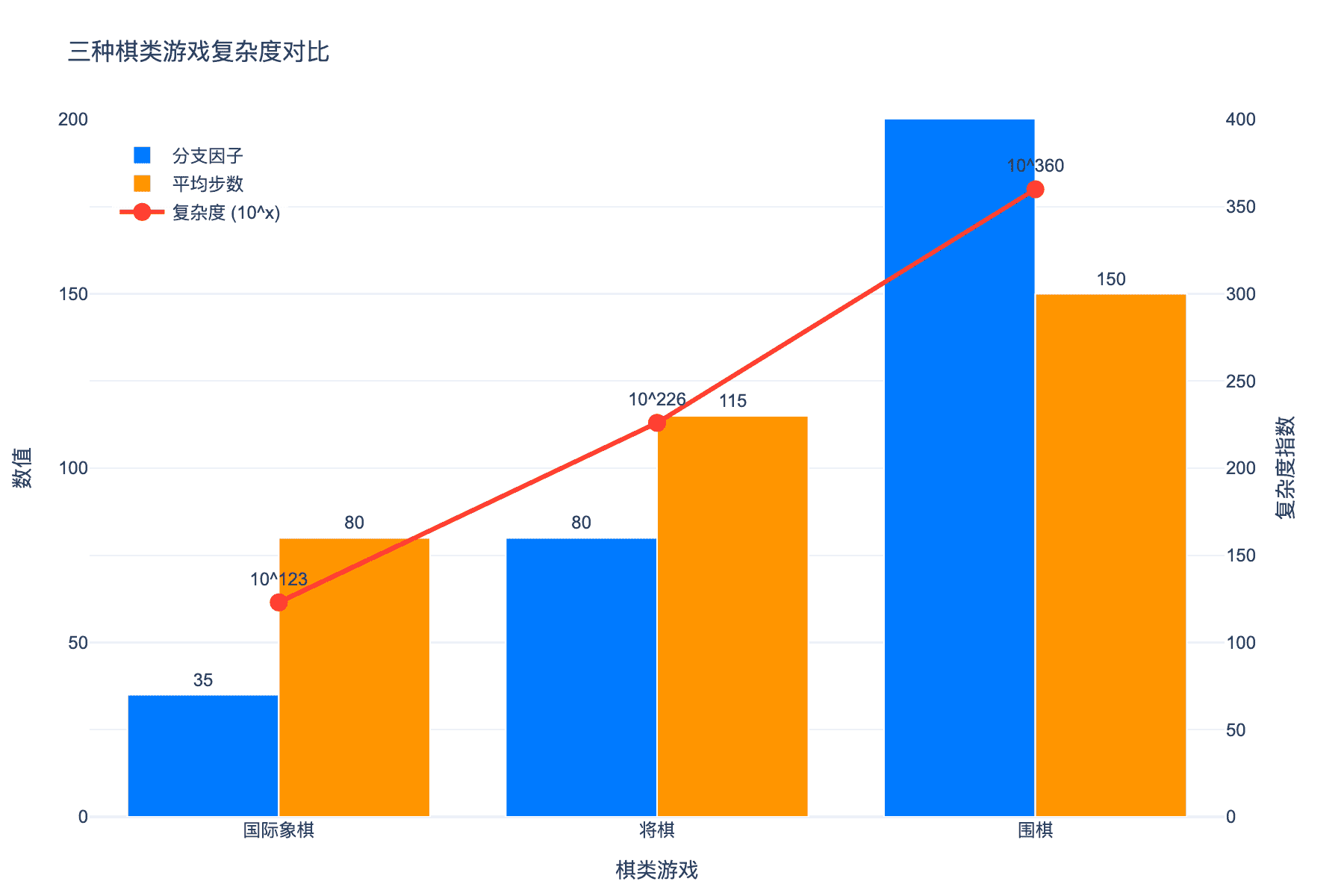
图 6:三种棋类游戏复杂度对比。围棋具有最高的分支因子和复杂度,国际象棋相对较低,将棋介于两者之间
5.2 跨领域迁移
AlphaZero 的架构设计体现了极强的通用性:
输入表示:将棋盘编码为 $8 \times 8 \times k$ 或 $19 \times 19 \times k$ 的张量
- 国际象棋:$k$ 包含棋子类型、颜色、历史走法等信息
- 围棋:$k$ 包含当前棋子位置、历史落子等
网络架构:除输入输出层维度外,ResNet 架构保持不变
搜索算法:MCTS 和 PUCT 完全相同,仅根据游戏规则改变合法动作集合
这种通用性证明了一个重要观点:智能的核心可能在于学习算法本身,而非特定领域的知识。
第六章:与传统引擎的较量
6.1 比赛结果
AlphaZero 与当时世界顶级的专用棋类程序进行了比赛:
国际象棋 vs Stockfish 8:
- 100 局比赛,AlphaZero 以 28 胜 72 平 0 负获胜
- 每方思考时间:1 分钟/步
- Stockfish 每步搜索 7000 万个位置
- AlphaZero 每步仅搜索 8 万个位置
将棋 vs Elmo:
- 100 局比赛,AlphaZero 以 90 胜 9 平 1 负获胜
- 每方思考时间:2 分钟/步
围棋 vs AlphaGo Zero:
- 经过完整训练的 AlphaZero 击败了训练 3 天的 AlphaGo Zero
- 证明了算法在围棋上的持续优化能力
6.2 效率对比
最令人震惊的是 AlphaZero 的搜索效率。以国际象棋为例:
- Stockfish:每步搜索 7000 万个位置
- AlphaZero:每步搜索 8 万个位置
AlphaZero 仅需传统引擎千分之一的搜索量就能达到相同(甚至更高)水平。这说明神经网络提供了强大的"直觉"能力,能够迅速聚焦于最有希望的分支,而不需要穷举所有可能性。
6.3 棋风分析
与传统引擎相比,AlphaZero 展现出了独特的棋风:
国际象棋:
- 愿意主动牺牲子力换取长期战略优势
- 更注重王的安全性和棋子活动性
- 展现出类似人类直觉的"局面感觉”
将棋:
- 展现出了精妙的"持驹"(被吃棋子重用)战术
- 善于构建缓慢但稳步的优势
- 防守和反击的转换非常灵活
围棋:
- 更倾向于全局性、战略性的下法
- 在人类看来"厚实"但"低效"的棋风,实际效果显著
第七章:技术贡献与影响
7.1 核心贡献
AlphaZero 论文的技术贡献主要包括:
完全无监督的预训练:证明深度学习可以从随机初始化达到超人类水平
神经网络与搜索的统一框架:神经网络提供先验,MCTS 进行精炼,两者相互增强
通用游戏算法:同一个架构在三种不同游戏中达到顶级水平
高效搜索:神经网络大幅减少了搜索需求,提升了计算效率
7.2 对 AI 研究的影响
AlphaZero 的成功推动了多个研究方向:
MuZero(2019):扩展到不知道游戏规则的情况,通过模型学习环境的动态
GPT 系列:证明了"规模定律"——更大的模型和更多数据带来更好的性能
多模态学习:从游戏领域扩展到图像、视频、文本等多种模态
科学计算:类似的思想被应用到蛋白质折叠(AlphaFold)、数学定理证明等领域
7.3 哲学启示
AlphaZero 的成功引发了关于智能本质的思考:
知识 vs 学习:传统 AI 依赖人类编码知识,AlphaZero 证明机器可以自己发现知识
直觉 vs 计算:AlphaZero 展示了神经网络如何模拟人类直觉,与符号计算相结合
通用 vs 专用:一个通用算法可以超越为特定任务精心设计的专用算法
结语:通用人工智能的曙光
AlphaZero 的故事是一个关于突破的故事。它突破了人类知识的限制,突破了专用算法的局限,突破了我们对机器学习的想象。
从 AlphaGo 到 AlphaZero,DeepMind 展示了一条通往通用人工智能的可能路径:
不是让机器模仿人类,而是让机器发展出自己的理解方式。
AlphaZero 在国际象棋中的下法,被国际象棋大师描述为"来自外星人的风格"。它不走人类已知的开局,不遵循人类总结的原则,却能达到更高的水平。这提示我们:智能的形式可能比人类经验更加多样。
当然,AlphaZero 仍然局限于完全信息、确定性、可模拟的环境中。真实世界的复杂性远超棋盘游戏。但 AlphaZero 提供的思路——自我博弈、神经网络指导搜索、通用架构——正在启发新一代的 AI 系统。
从围棋到蛋白质折叠,从游戏到数学定理,AlphaZero 的思想正在改变我们解决复杂问题的方式。而对于 AI 研究来说,这只是开始。
参考文献
Silver, D., Hubert, T., Schrittwieser, J., et al. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419), 1140-1144.
Silver, D., et al. (2017). Mastering the game of Go without human knowledge. Nature, 550(7676), 354-359.
Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484-489.
Schrittwieser, J., et al. (2020). Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. Nature, 588(7839), 604-609.
Kocsis, L., & Szepesvári, C. (2006). Bandit based Monte-Carlo planning. European Conference on Machine Learning, 282-293.
Coulom, R. (2006). Efficient selectivity and backup operators in Monte-Carlo tree search. International Conference on Computers and Games, 72-83.
本文是 AI 论文解读系列的第三篇,第一篇介绍了 AlphaGo 的深度学习与树搜索技术,第二篇介绍了 BERT 的预训练双向 Transformer。