
引言:语言理解的瓶颈
2018年10月,Google AI Language 团队发布了一篇名为"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"的论文。这篇论文及其开源代码在 NLP 领域引发了一场革命。
在 BERT 出现之前,自然语言处理面临一个根本性难题:如何让机器真正理解语言的上下文含义?传统的语言模型只能从左到右(或从右到左)单向处理文本,就像阅读时只能看到当前词之前的所有词,却无法看到之后的词。这种"管中窥豹"的方式严重限制了模型的理解能力。
BERT 的核心突破在于它提出了深度双向表示的概念——通过一种新的预训练目标,让模型同时考虑词语的左右上下文,从而获得更丰富、更准确的语言理解能力。
本文将深入解读 BERT 的技术原理,从其核心思想出发,逐步揭示它如何改变了 NLP 的研究范式。
第一章:从上下文说起——为什么双向如此重要
1.1 一词多义的困境
自然语言的复杂性很大程度上源于一词多义。同一个词在不同的上下文中可能有完全不同的含义。考虑这两个句子:
“他在银行工作。"(金融机构) “河边的银行种满了柳树。"(河岸)
对于人类来说,区分这两个"银行"的含义轻而易举,因为我们能够同时看到这个词左右两侧的上下文。但对于单向语言模型来说,当它处理到"银行"这个词时,只能看到"他在"或"河边的”,无法获得足够的信息来做出准确判断。
1.2 传统语言模型的局限
传统的语言模型采用自回归(Autoregressive)方式建模,即基于前文预测下一个词:
$$ P(w_1, w_2, \ldots, w_n) = \prod_{i=1}^{n} P(w_i | w_1, \ldots, w_{i-1}) $$
GPT 等模型采用了这种从左到右的处理方式。虽然这种架构在生成任务(如机器翻译、文本摘要)中表现良好,但对于需要深度理解上下文的任务(如问答、情感分析)则存在天然的局限性。
另一种尝试是浅层双向,如 ELMo。它分别训练一个从左到右和一个从右到左的语言模型,然后将两者的表示拼接起来。这种方法虽然考虑了双向信息,但两个方向的表示是独立计算的,而非真正的深度交互。
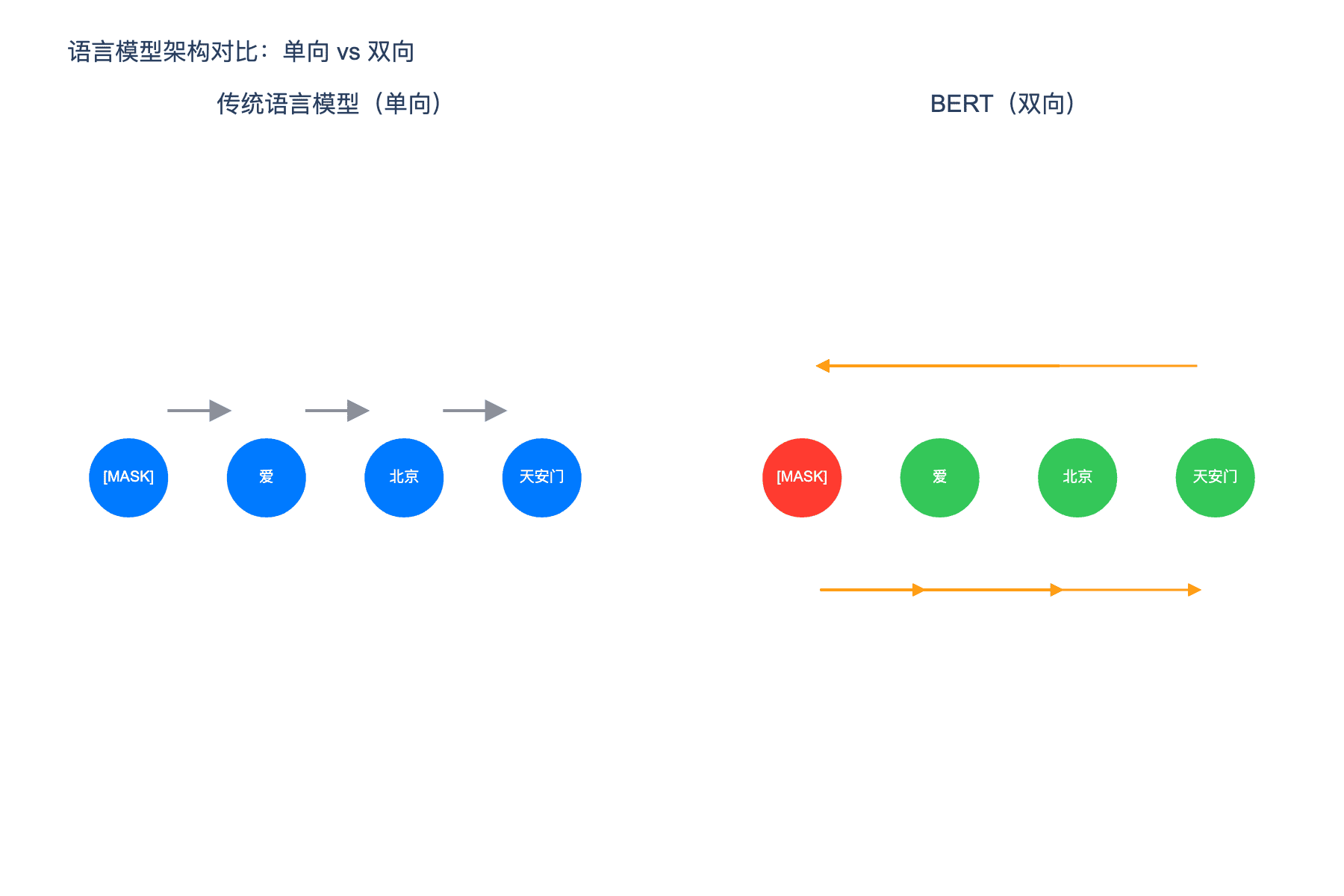
图 1:语言模型架构对比。左图为单向模型只能看到左侧上下文,右图为 BERT 双向模型可以看到完整上下文
第二章:Transformer——BERT 的基石
在深入 BERT 之前,我们需要理解它的基础架构:Transformer。BERT 完全基于 Transformer 的 Encoder 部分构建。
2.1 注意力机制的魔力
Transformer 的核心是自注意力机制(Self-Attention)。与传统的循环神经网络(RNN)不同,自注意力允许模型直接建模序列中任意两个位置之间的关系,无论它们相距多远。
自注意力的数学表达为:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
其中:
- $Q$(Query):查询矩阵,表示"我正在寻找什么信息”
- $K$(Key):键矩阵,表示"我包含什么信息"
- $V$(Value):值矩阵,表示"我的实际内容是什么"
- $d_k$:键向量的维度,用于缩放点积防止梯度消失
这个公式的直观解释是:对于序列中的每个位置,模型计算它与所有其他位置的"相关性得分"(通过 $QK^T$),然后用这些得分对所有位置的值进行加权求和。
2.2 多头注意力
BERT 使用的是多头注意力(Multi-Head Attention),即并行计算多组不同的 $(Q, K, V)$,然后将结果拼接:
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O $$
其中每个头的计算为:
$$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
BERT-Base 使用 12 个头,BERT-Large 使用 16 个头。这种设计允许模型在不同的"表示子空间"中捕获不同类型的关系。
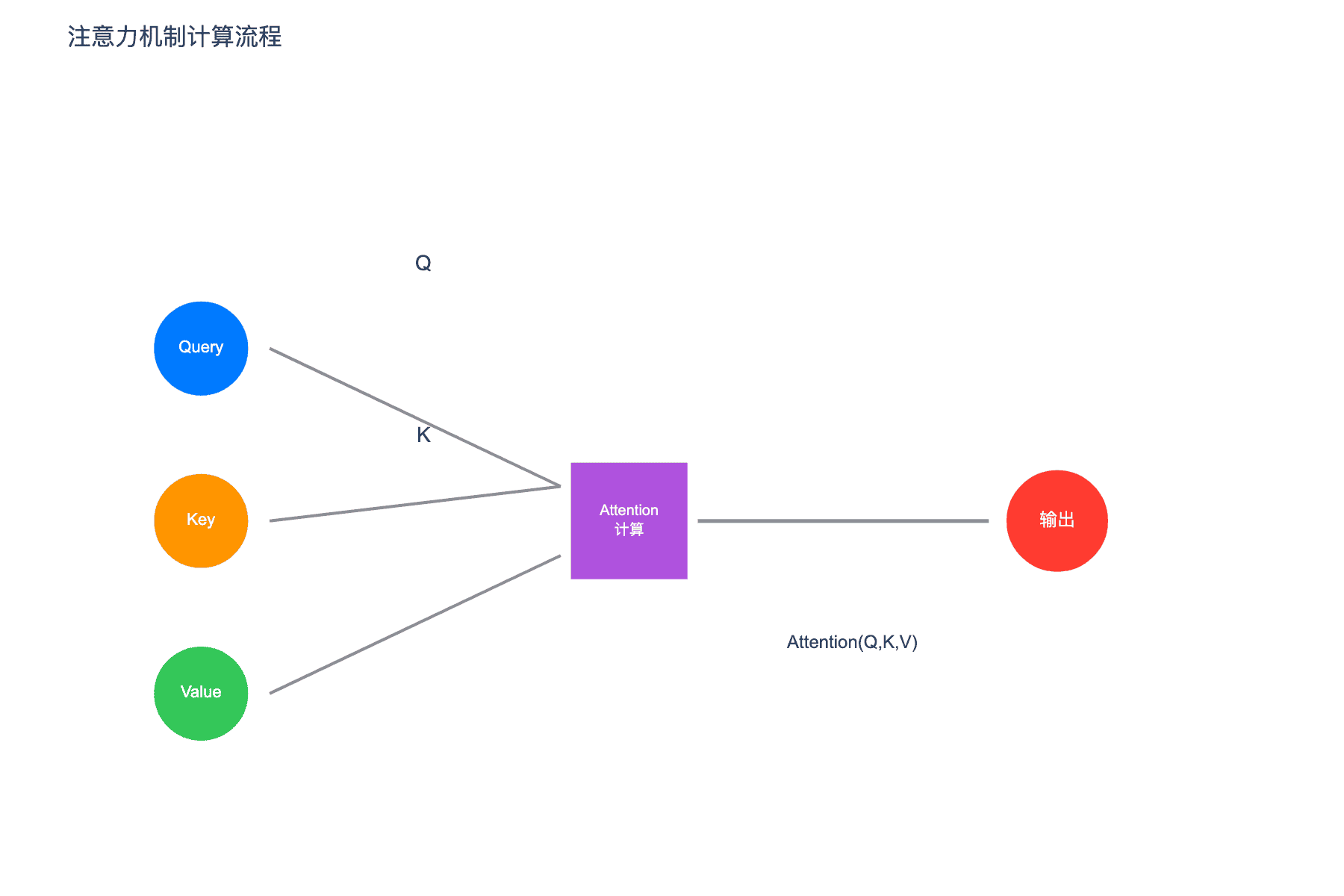
图 2:注意力机制计算流程。Query 和 Key 计算相关性权重,然后对 Value 进行加权求和得到输出
2.3 Transformer Encoder 结构
BERT 使用的是 Transformer 的 Encoder 部分,每个 Encoder 层包含两个子层:
- 多头自注意力子层:计算词与词之间的关系
- 前馈神经网络子层:对每个位置独立进行非线性变换
每个子层后都有残差连接和层归一化:
$$ \text{LayerNorm}(x + \text{Sublayer}(x)) $$
BERT-Base 由 12 层 Encoder 堆叠而成,BERT-Large 则是 24 层。
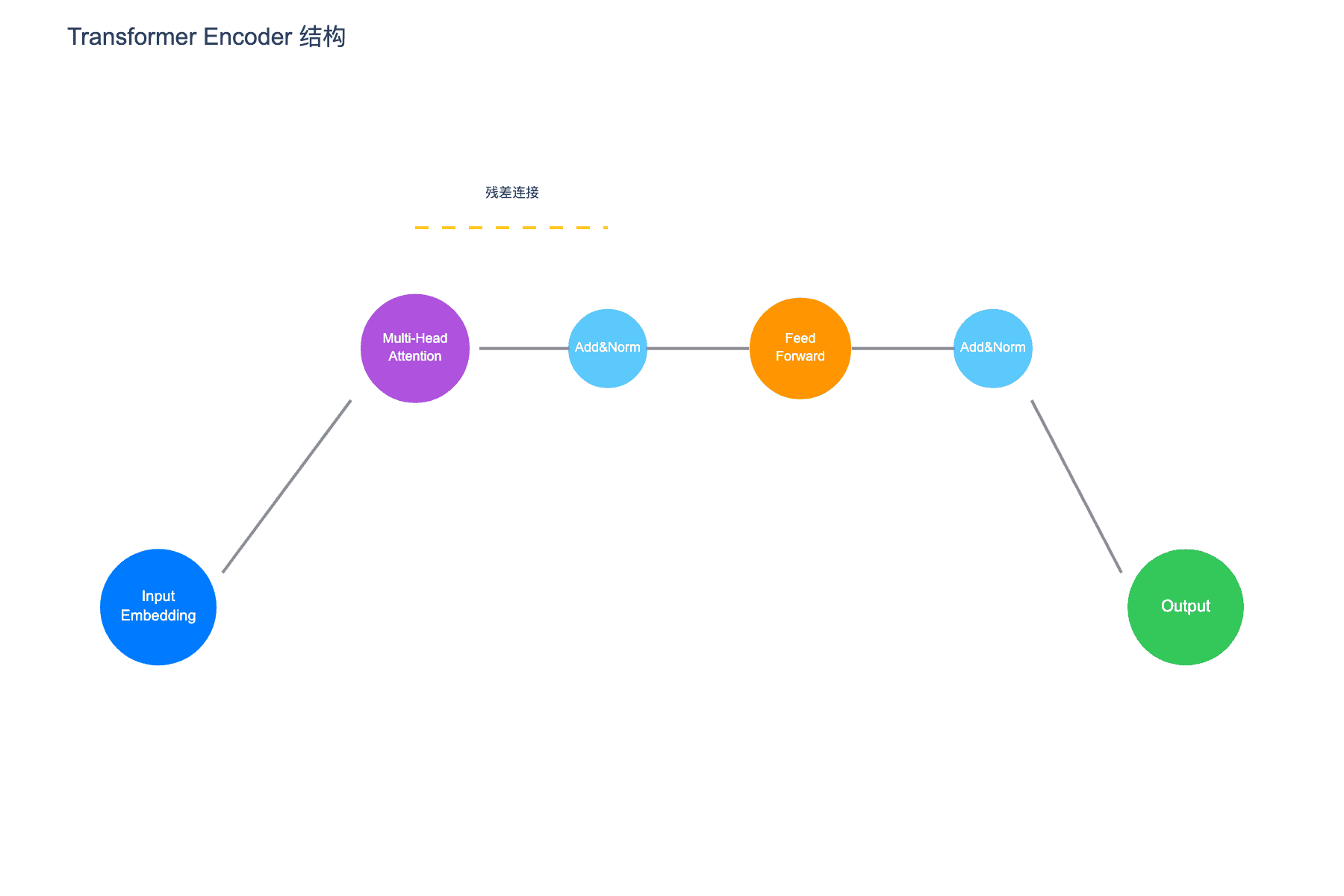
图 3:Transformer Encoder 结构。包含 Multi-Head Attention、Add & Norm、Feed Forward 等组件,黄色虚线表示残差连接
第三章:BERT 的创新——掩码语言模型
BERT 的核心创新在于它的预训练目标:掩码语言模型(Masked Language Model, MLM)。这个方法巧妙地解决了双向建模的难题。
3.1 掩码策略
MLM 的基本思想很简单:在输入句子中随机遮盖(mask)一些词,然后让模型预测这些被遮盖的词。
具体操作如下:
- 随机选择输入序列中 15% 的词元(token)
- 对于被选中的词元:
- 80% 的概率替换为特殊标记
[MASK] - 10% 的概率替换为随机词
- 10% 的概率保持不变
- 80% 的概率替换为特殊标记
例如,对于句子 “我爱北京天安门”,假设 “爱” 被选中:
- 80%:“我
[MASK]北京天安门” - 10%:“我 苹果 北京天安门”
- 10%:“我 爱 北京天安门”
3.2 为什么需要混合策略
这种看似奇怪的混合策略实际上经过精心设计:
80% 的 [MASK]:迫使模型真正依赖上下文进行预测,而不是仅仅复制输入。
10% 的随机词:引入噪声,防止模型过拟合到特定的掩码位置。
10% 保持不变:让模型知道并非所有词都需要预测,保持对真实数据的建模能力。
在微调阶段(Fine-tuning),输入中不会出现 [MASK] 标记。预训练时引入的少量"非掩码"样本确保模型能够处理这种不一致。
3.3 MLM 的损失函数
BERT 的 MLM 训练目标是最小化负对数似然:
$$ \mathcal{L}{\text{MLM}} = -\mathbb{E}{x \in \mathcal{X}} \log P(x | \hat{x}) $$
其中 $\hat{x}$ 是被掩码后的输入序列。由于只有被掩码的位置参与损失计算,每个训练样本只更新 15% 的词元预测,这使得训练比传统语言模型收敛更慢,但获得了双向建模的能力。
第四章:下一句预测——理解句子关系
除了 MLM,BERT 还引入了第二个预训练任务:下一句预测(Next Sentence Prediction, NSP)。
4.1 为什么需要 NSP
许多 NLP 任务(如问答、自然语言推断)需要理解两个句子之间的关系。MLM 只训练了词级别的理解,而 NSP 训练了句子级别的关系建模。
4.2 NSP 任务定义
NSP 是一个二分类任务:给定两个句子 A 和 B,判断 B 是否紧跟在 A 之后。
训练数据的构造:
- 50% 的样本:B 确实是 A 的下一句(标签为
IsNext) - 50% 的样本:B 是从语料库中随机采样的句子(标签为
NotNext)
例如:
[CLS]今天天气真好[SEP]我们一起去公园吧[SEP]→ IsNext[CLS]今天天气真好[SEP]量子力学是物理学分支[SEP]→ NotNext
4.3 输入表示
BERT 的输入设计巧妙地支持了 NSP 任务。每个输入样本由两个句子拼接而成,用特殊标记分隔:
[CLS]:位于序列开头,其最终隐藏状态用于分类任务[SEP]:用于分隔句子 A 和句子 B- 句子嵌入(Segment Embedding):区分词元属于哪个句子(A 或 B)
- 位置嵌入(Position Embedding):标记词元在序列中的位置
最终的输入表示是三种嵌入的求和:
$$ E = E_{\text{token}} + E_{\text{segment}} + E_{\text{position}} $$
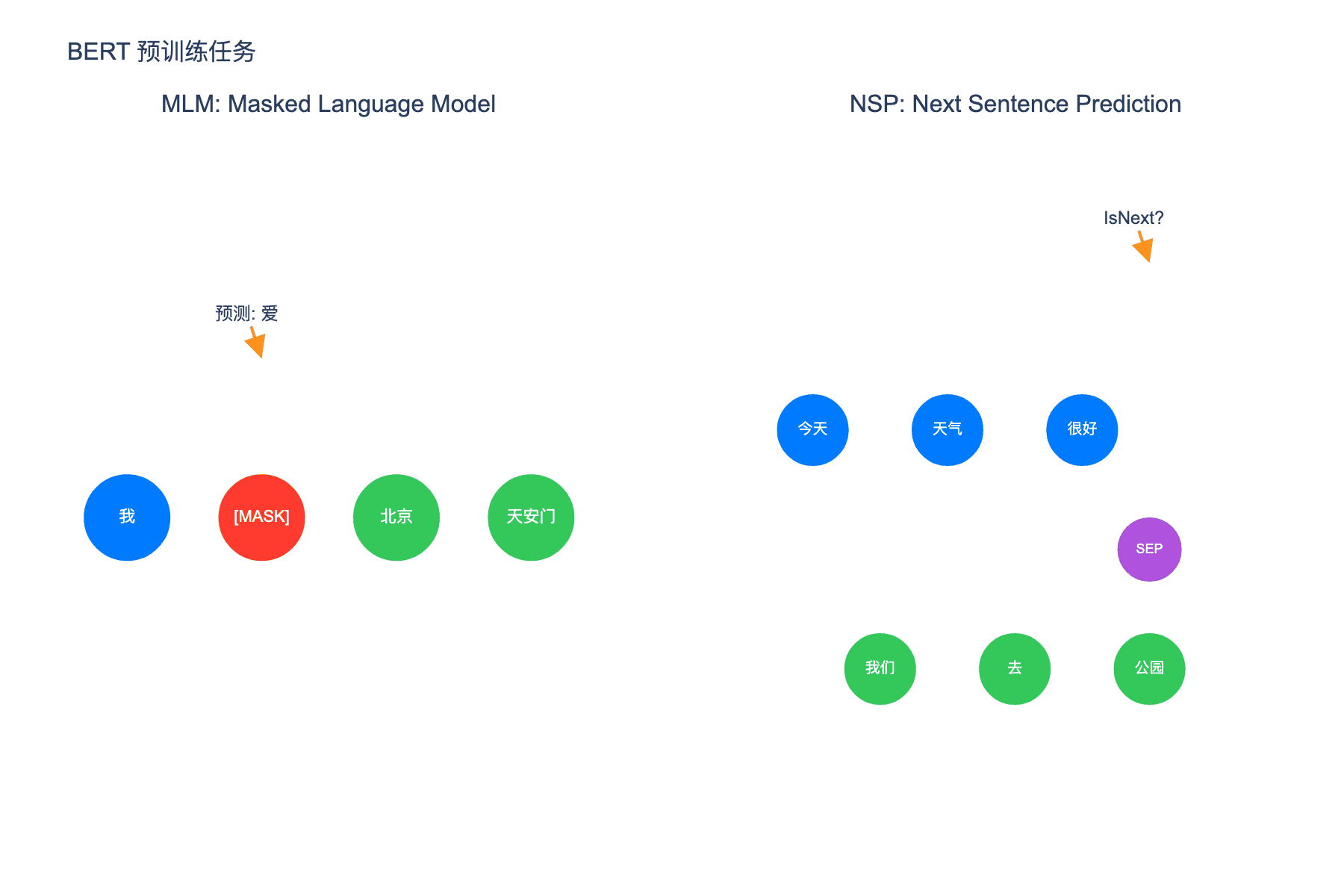
图 4:BERT 预训练任务。左图为 MLM 任务预测被掩码的词,右图为 NSP 任务判断句子关系
第五章:预训练与微调——BERT 的范式
BERT 的成功不仅在于其架构设计,更在于它确立了预训练 + 微调(Pre-training + Fine-tuning)的范式。
5.1 大规模预训练
BERT 在大规模无标注文本上进行预训练:
- 语料:BooksCorpus(8亿词)+ 英文维基百科(25亿词)
- 训练时间:BERT-Base 在 4 块 Cloud TPUs 上训练 4 天;BERT-Large 在 16 块 TPUs 上训练 4 天
- 批量大小:256 个序列 × 512 个词元 = 131,072 个词元/批次
- 优化器:AdamW,学习率预热 10,000 步后线性衰减
5.2 任务特定的微调
预训练完成后,BERT 可以通过简单的输出层适配到各种下游任务:
句子分类(如情感分析):使用 [CLS] 标记的输出,接一个全连接层 + softmax
词元分类(如命名实体识别):每个词元的输出独立分类
问答(如 SQuAD):引入开始向量 $S$ 和结束向量 $E$,答案范围由 $\text{softmax}(S \cdot T_i)$ 和 $\text{softmax}(E \cdot T_i)$ 确定
句子对分类(如自然语言推断):直接使用 [CLS] 的输出,NSP 预训练为此提供了良好的初始化
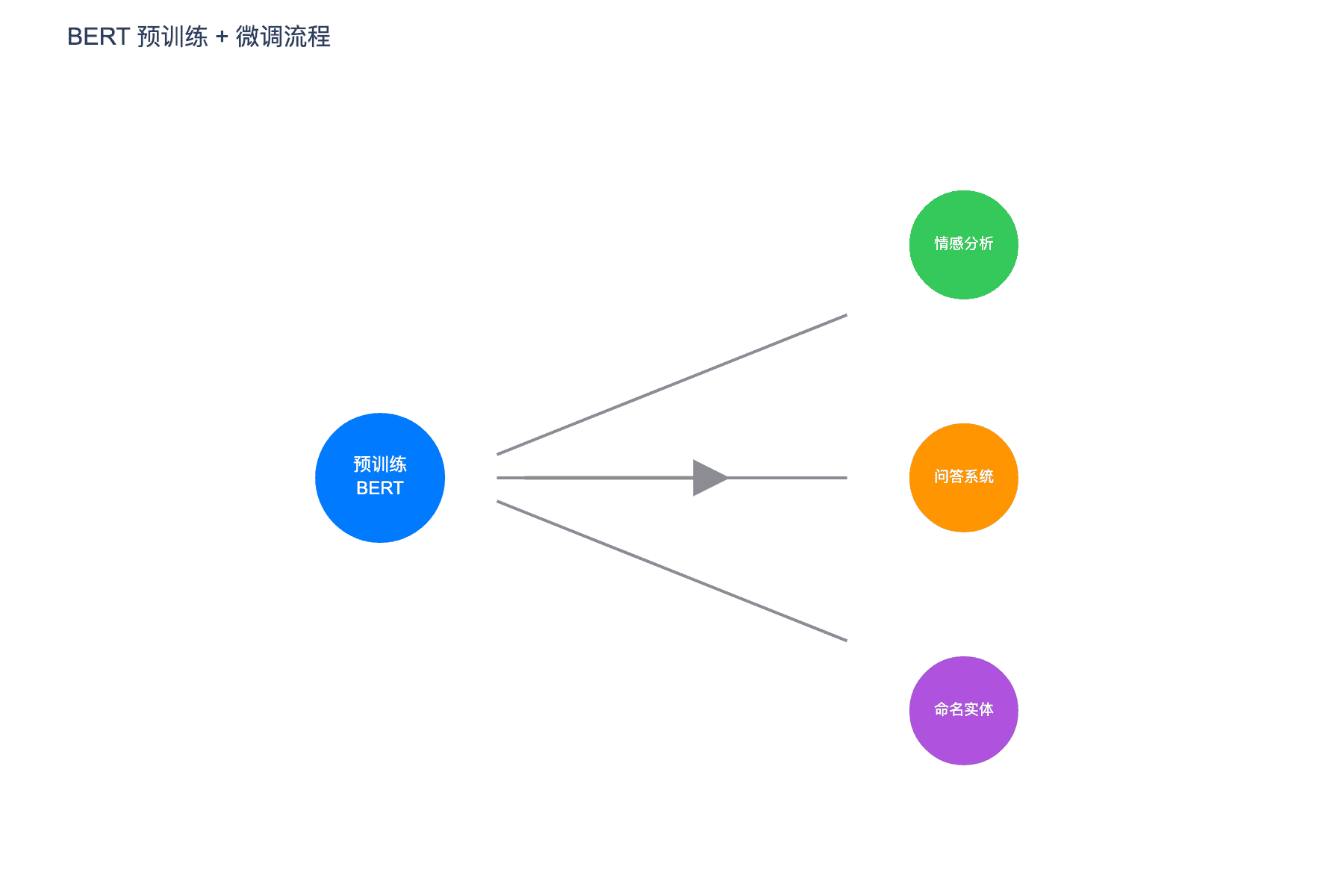
图 5:BERT 预训练 + 微调流程。预训练后的 BERT 模型可以通过添加简单的输出层适配到多种下游任务
第六章:GLUE 基准测试——横扫千军
为了验证 BERT 的效果,作者在 GLUE(General Language Understanding Evaluation)基准测试上进行了评估。GLUE 包含 9 个不同的 NLP 任务,涵盖句子分类、句子相似度、自然语言推断等。
6.1 实验结果
BERT-Large 在 GLUE 上的平均得分为 80.5,比之前的最佳结果(OpenAI GPT)提升了 7.7 个百分点。更令人惊讶的是,BERT 在 11 个 NLP 任务上取得了当时的最佳性能,包括:
- SQuAD 1.1(阅读理解):F1 得分 93.2
- SQuAD 2.0(包含无法回答的问题):F1 得分 83.1
- SWAG(常识推理):准确率 86.3
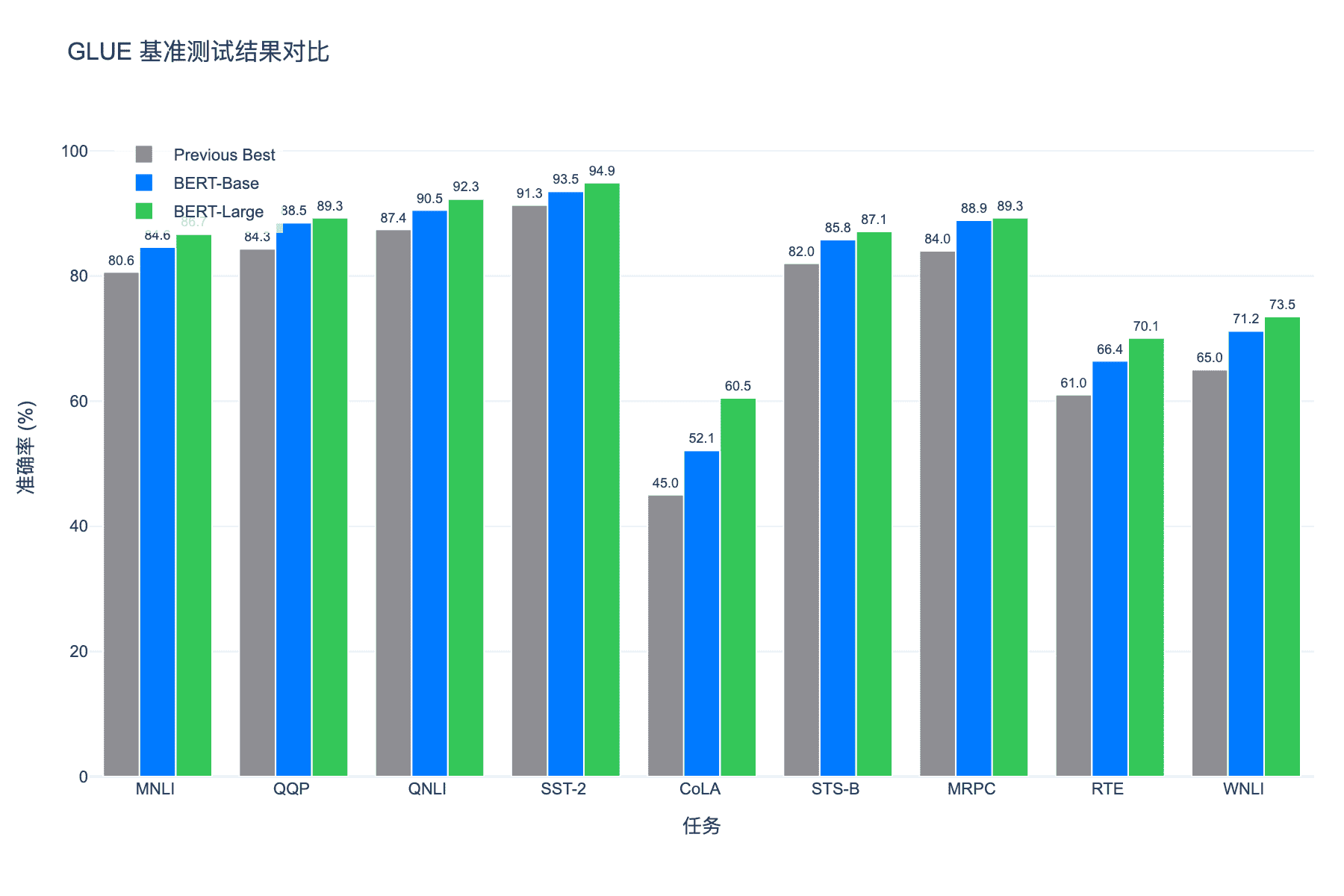
图 6:GLUE 基准测试结果对比。BERT-Large 相比之前最佳结果有显著提升
6.2 消融实验
论文还进行了详细的消融实验,验证了各个设计决策的重要性:
MLM vs. LTR(Left-to-Right):双向模型比单向模型在 MNLI 上提升 5.2 个百分点,证明双向建模的关键作用。
模型规模:从 BERT-Base(110M 参数)增加到 BERT-Large(340M 参数),性能持续提升,说明大规模预训练的重要性。
训练步数:训练 1M 步比 500K 步平均提升 1.0 个百分点。
去掉 NSP:移除 NSP 任务后,QNLI(问答自然语言推断)下降 3.2 个百分点,说明句子级预训练的价值。
第七章:BERT 的影响与后续发展
7.1 技术影响
BERT 的发表标志着 NLP 进入了预训练模型时代。它的影响力体现在几个方面:
范式转变:从"为每个任务训练独立模型"转变为"预训练通用模型 + 微调特定任务"
规模竞赛:证明了模型规模与性能的正相关,催生了 GPT-2、GPT-3、T5 等更大规模的模型
双向表示:确立了深度双向建模的重要性,后续模型如 RoBERTa、ALBERT 都在此基础上改进
7.2 后续变体
BERT 的成功催生了一系列改进版本:
RoBERTa(Facebook,2019):优化了训练策略,移除了 NSP,使用更大的批次和更多数据。
ALBERT(Google,2019):通过参数共享和因式分解嵌入层,大幅减少了参数量。
SpanBERT(2020):将掩码从单个词扩展到连续的词片段,更好地建模实体和短语。
DistilBERT(Hugging Face,2019):通过知识蒸馏,将 BERT 压缩为更小的模型,保持 97% 性能但推理速度快 60%。
ELECTRA(Google,2020):将 MLM 替换为替换词检测任务,提高训练效率。
7.3 应用领域
BERT 及其变体被广泛应用于:
- 搜索引擎:Google 从 2019 年开始使用 BERT 改进搜索结果理解
- 智能客服:理解用户意图和情感
- 医疗文本处理:电子病历分析、医学文献挖掘
- 金融分析:财报情感分析、风险事件检测
- 内容审核:识别有害内容、虚假信息
结语:理解语言的里程碑
BERT 的论文以一个简单的理念为基础:真正的语言理解需要同时考虑左右上下文。通过巧妙的掩码策略和大规模预训练,BERT 证明了机器可以学习到深层的语言表示。
从更广阔的视角看,BERT 代表了人工智能研究的一个重要趋势:
从特征工程到表示学习,从监督学习到自监督学习。
BERT 不需要人工设计的语言特征,它从原始文本中自动学习最优的表示。它不需要大量标注数据,通过自监督预训练就能从海量无标注文本中获得知识。
回顾 NLP 的发展历程:
- 2013 年:Word2Vec 让词嵌入成为标配
- 2017 年:Transformer 架构彻底改变了序列建模
- 2018 年:BERT 开启了预训练模型的新纪元
BERT 不仅是一个模型,更是一种范式。它告诉我们:当拥有足够的计算资源和数据时,让机器自己学习往往比人工设计规则更有效。这种思想延续到了 GPT-3、PaLM、LLaMA 等后续的大语言模型中。
正如论文标题所言,BERT 实现了"Language Understanding"的突破。而对于 AI 研究者来说,这只是一个开始——通向真正理解人类语言的人工智能的道路,还有很长的距离要走。
参考文献
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. (Published in NAACL 2019)
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 5998-6008.
Radford, A., et al. (2018). Improving language understanding by generative pre-training.OpenAI Technical Report.
Peters, M. E., et al. (2018). Deep contextualized word representations. NAACL, 2227-2237.
Liu, Y., et al. (2019). RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692.
Lan, Z., et al. (2019). ALBERT: A lite BERT for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
本文是 AI 论文解读系列的第二篇,第一篇介绍了 AlphaGo 的深度学习与树搜索技术。