
引言:翻译的困境
想象一下,你正在学习一门外语。当你听到一句法语 “Bonjour le monde” 时,你的大脑是如何将其转化为英语 “Hello world” 的?
这不是简单的逐词替换。“Bonjour” 对应 “Hello”,但 “le monde” 是 “the world” 的倒序。词序不同,语法结构不同,甚至可能一个词对应多个词。传统的机器翻译系统使用基于规则的方法或统计模型,需要大量的人工特征工程和复杂的对齐算法。
2014年,Ilya Sutskever、Oriol Vinyals 和 Quoc Le 在 Google 发表了一篇改变游戏规则的论文:“Sequence to Sequence Learning with Neural Networks”。他们提出的 Seq2Seq 架构,用一个统一的神经网络模型取代了复杂的流水线,让机器翻译的准确率跃升到了新的高度。
但这篇论文的意义远不止于翻译。它开创了序列转导(Sequence Transduction)这一全新的学习范式,为后来的注意力机制、Transformer 乃至大语言模型奠定了基础。
第一章:序列转导问题
1.1 什么让序列数据特殊
在深入 Seq2Seq 之前,让我们先理解序列数据的本质。
传统的机器学习任务,比如图像分类或房价预测,输入和输出的维度是固定的。一张图片永远是 $224 \times 224 \times 3$ 的像素矩阵,一套房子的特征永远是卧室数、面积、位置等固定字段。
但序列数据不同:
- 一句话可能有 5 个词,也可能有 50 个词
- 源语言和目标语言的词序可能不同
- 一个概念可能用一个词表达,也可能用多个词
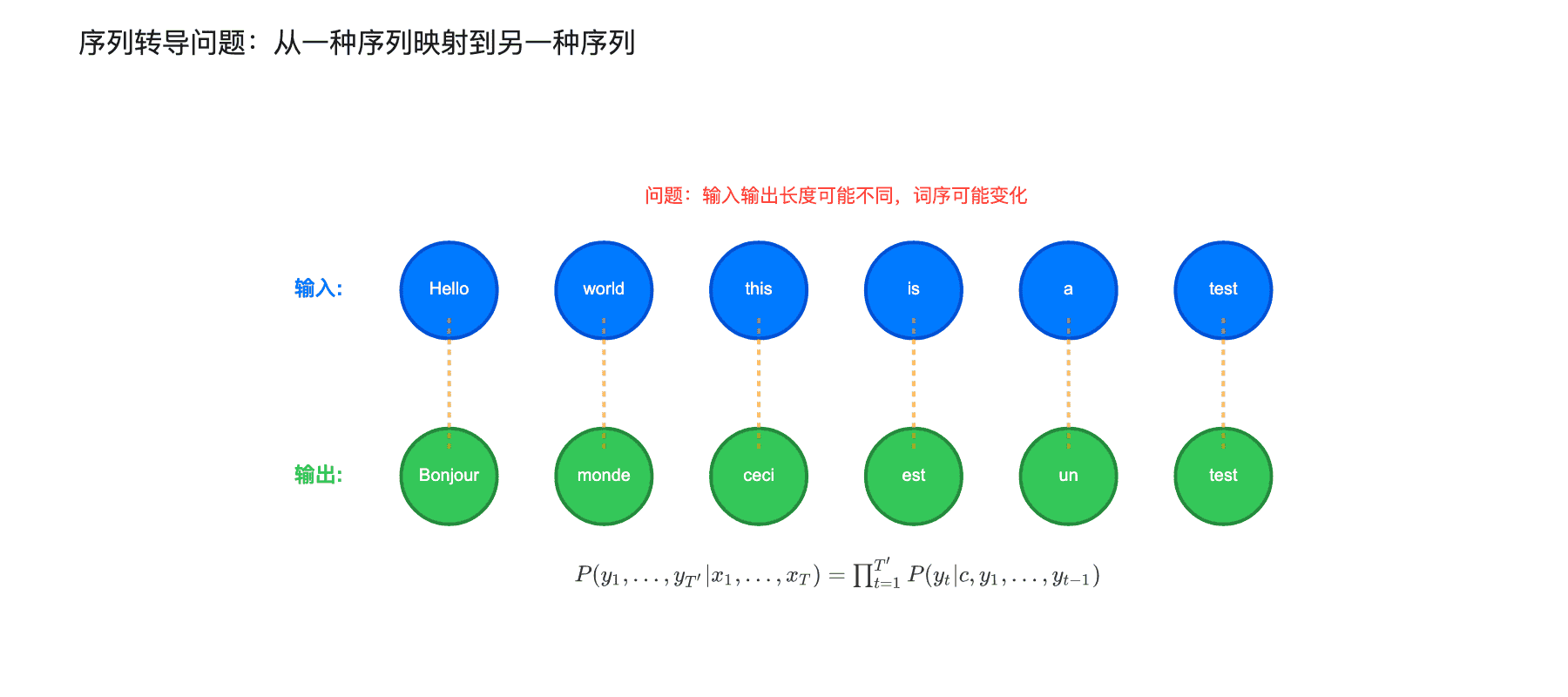
上图展示了一个典型的机器翻译场景。输入序列 “Hello world this is a test” 需要被转换为 “Bonjour monde ceci est un test”。注意两个关键挑战:
挑战一:长度不匹配
输入和输出的长度可能不同。在更复杂的语言对中,比如英语到德语,这种差异更明显。
挑战二:结构不对齐
“this is” 对应 “ceci est”,词序相同,但这是幸运的情况。英语中的 “not only… but also” 在中文里可能需要完全重组语序。
数学上,序列转导问题可以形式化为:给定输入序列 $\mathbf{x} = (x_1, x_2, \ldots, x_T)$,找到最可能的输出序列 $\mathbf{y} = (y_1, y_2, \ldots, y_{T’})$,其中 $T$ 和 $T’$ 可以不同。
我们要求的是条件概率:
$$P(y_1, y_2, \ldots, y_{T’} \mid x_1, x_2, \ldots, x_T)$$
根据链式法则,这个联合概率可以分解为:
$$P(\mathbf{y} \mid \mathbf{x}) = \prod_{t=1}^{T’} P(y_t \mid y_1, \ldots, y_{t-1}, \mathbf{x})$$
这意味着,生成第 $t$ 个输出词时,我们需要考虑:
- 已经生成的所有前面的词 $y_1, \ldots, y_{t-1}$(自回归性质)
- 整个输入序列 $\mathbf{x}$(条件性质)
1.2 RNN 的局限
循环神经网络(RNN)似乎是为序列数据而生的。它们通过隐藏状态 $h_t$ 传递历史信息:
$$h_t = f(W_{hh} h_{t-1} + W_{xh} x_t + b)$$
其中 $f$ 是激活函数(通常是 $\tanh$ 或 ReLU),$W_{hh}$ 和 $W_{xh}$ 是权重矩阵,$b$ 是偏置。
但标准 RNN 有两个致命弱点:
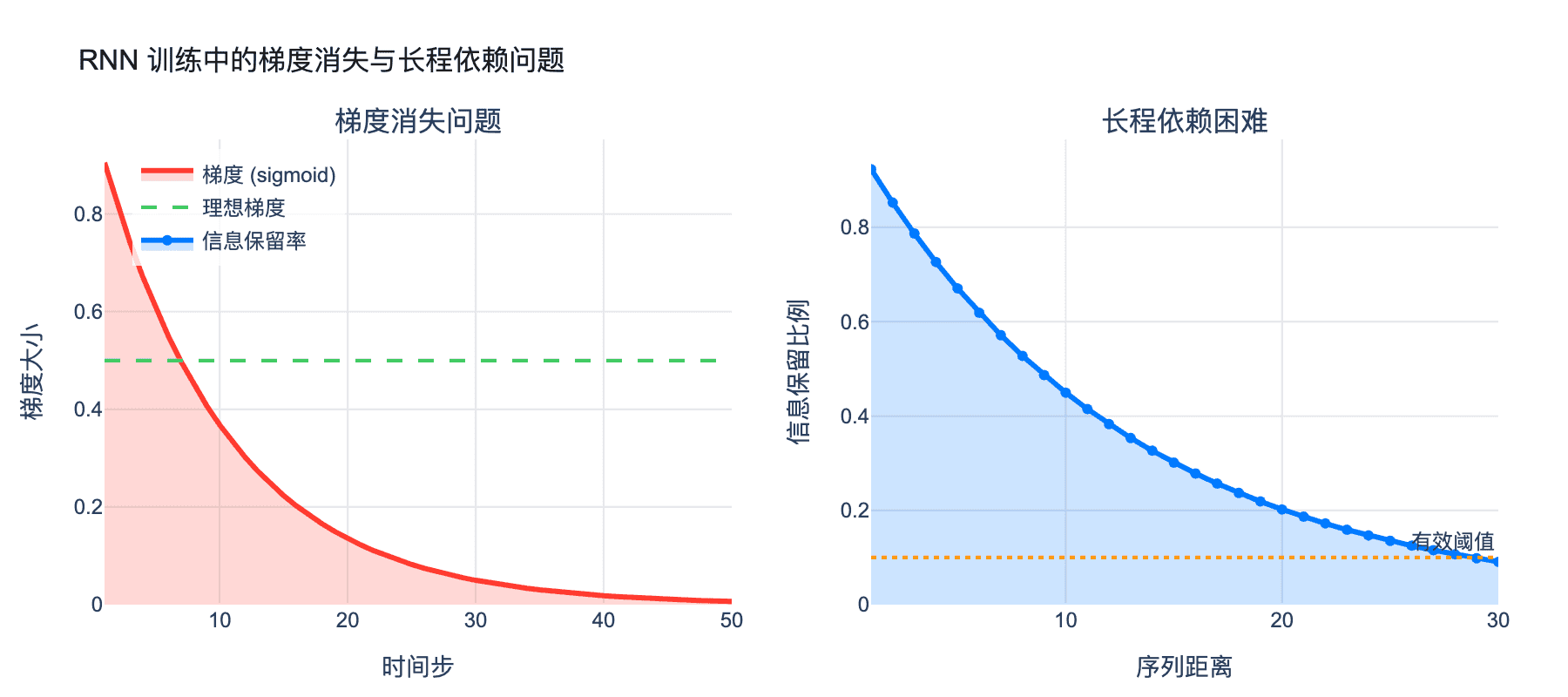
梯度消失
当序列很长时,反向传播的梯度需要经过很多时间步的连乘。如果激活函数的导数小于 1,梯度会指数级衰减。如左图所示,梯度在时间步 20 时已经衰减到接近零,这意味着模型几乎学不到远距离的依赖关系。
数学上,损失函数 $L$ 对早期隐藏状态的梯度为:
$$\frac{\partial L}{\partial h_1} = \frac{\partial L}{\partial h_T} \prod_{t=2}^{T} \frac{\partial h_t}{\partial h_{t-1}}$$
如果每个 Jacobian 矩阵的范数小于 1,这个乘积会随着 $T$ 增大而指数衰减。
长程依赖困难
右图展示了信息保留率随序列距离的衰减。当两个相关词相距超过 20 个词时,模型能保留的信息已经不足 20%。这对于理解长文档或保持对话一致性是致命的。
1.3 LSTM:为长序列而生
长短期记忆网络(LSTM)通过引入门控机制解决了这些问题。不再让每个隐藏状态都直接参与计算,LSTM 引入了一个专门的细胞状态(Cell State)$C_t$ 来传递长期信息。
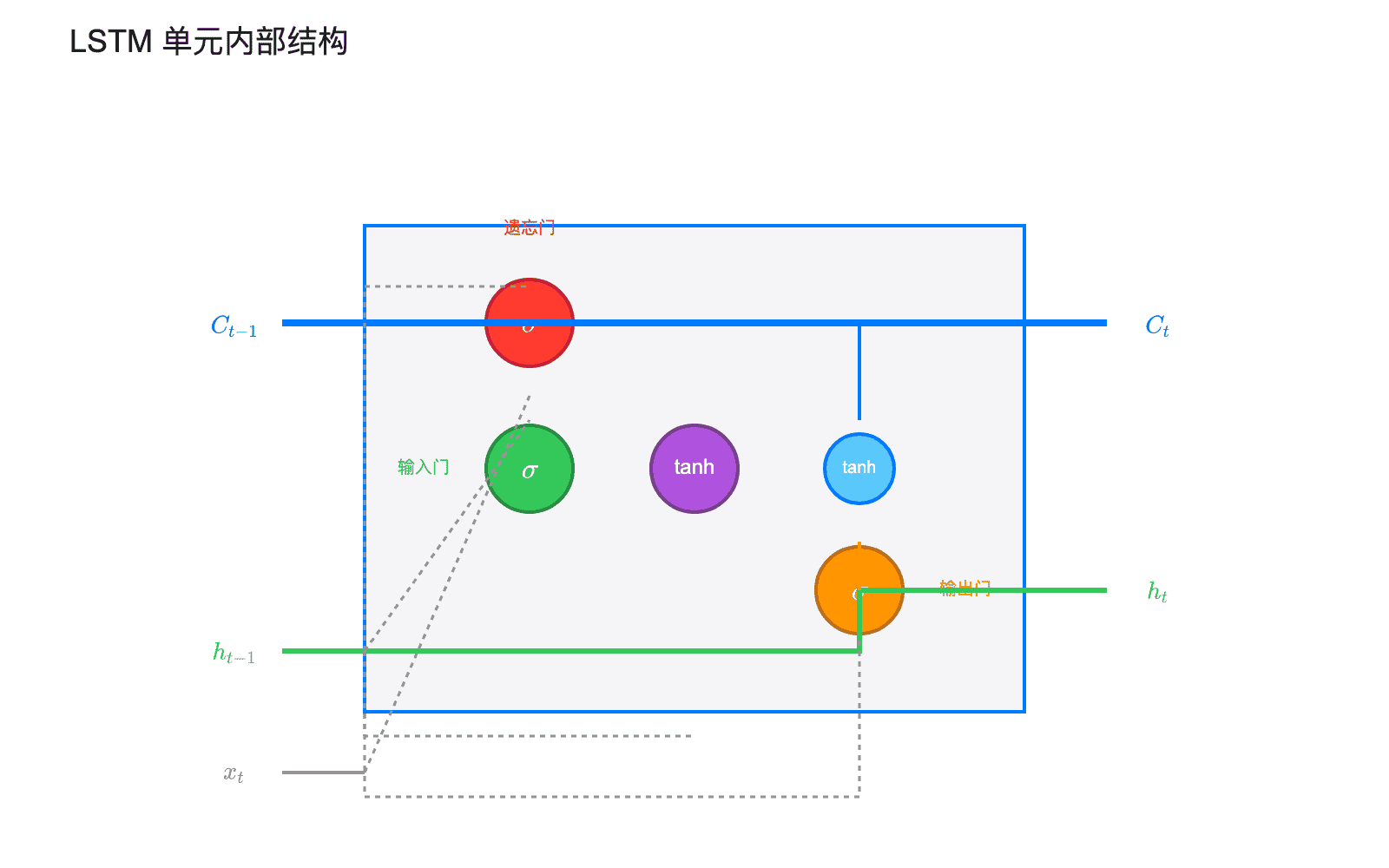
LSTM 的核心是三个门:
遗忘门 $f_t$:决定从细胞状态中丢弃什么信息 $$f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)$$
输入门 $i_t$:决定什么新信息存入细胞状态 $$i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)$$
候选状态 $\tilde{C}_t$:生成新的候选值 $$\tilde{C}t = \tanh(W_C \cdot [h{t-1}, x_t] + b_C)$$
更新细胞状态: $$C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t$$
其中 $\odot$ 表示逐元素乘法(Hadamard 积)。
输出门 $o_t$:决定基于细胞状态输出什么 $$o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)$$
$$h_t = o_t \odot \tanh(C_t)$$
关键突破在于:细胞状态的更新几乎是线性的(只有逐元素乘法和加法),梯度可以更容易地反向传播,有效缓解了梯度消失问题。
第二章:编码器-解码器架构
2.1 思想的突破
面对序列转导问题,Seq2Seq 的核心洞察是:将一个可变长度的序列压缩成一个固定维度的向量,再从这个向量解码出另一个可变长度的序列。
这就像一个口译员:先听完一整段话(编码),理解其含义,然后用另一种语言复述出来(解码)。
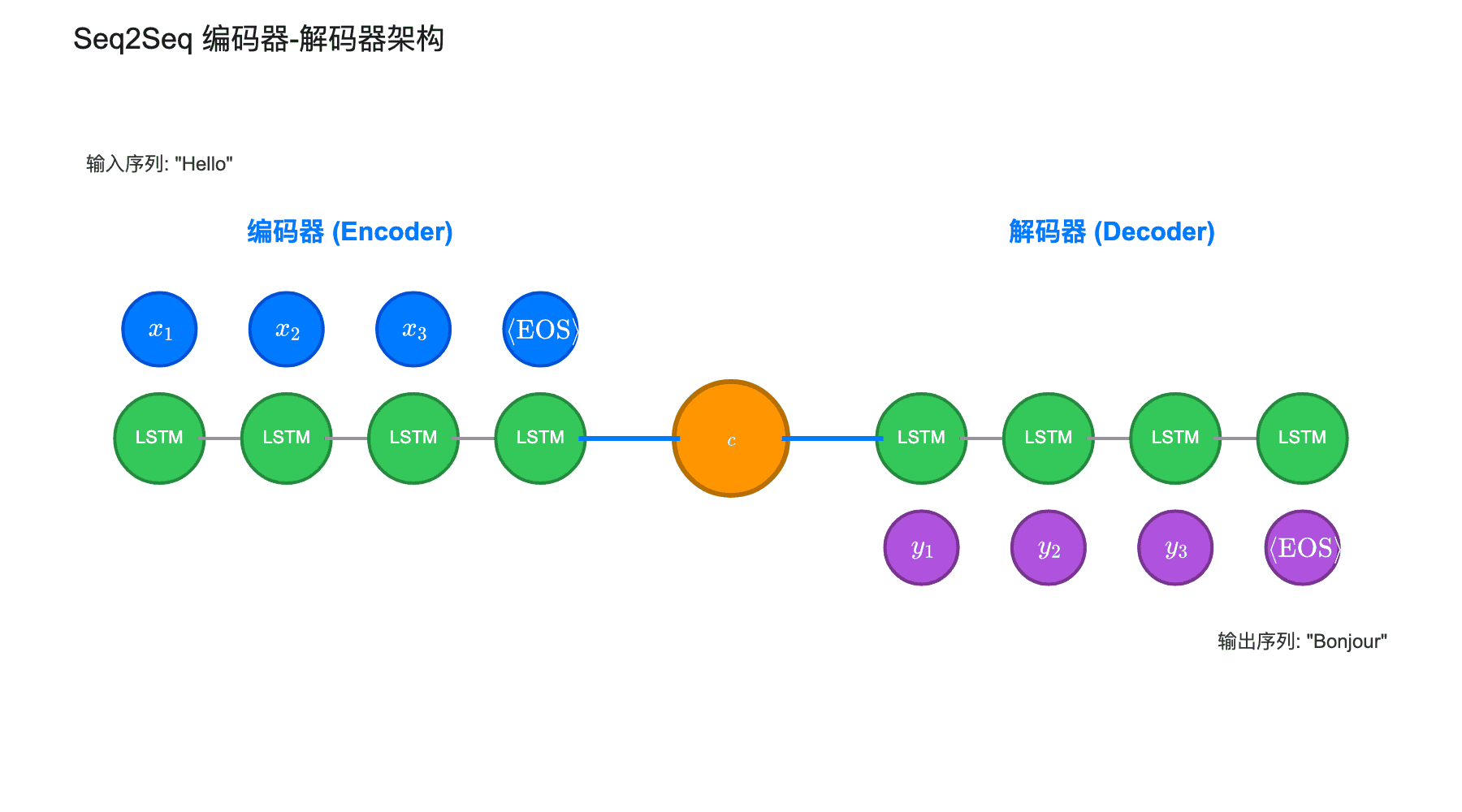
上图展示了 Seq2Seq 的基本架构,分为三个部分:
编码器(Encoder):由多层 LSTM 组成,从左到右(或从右到左)读取输入序列。每个时间步 $t$,编码器读取一个词 $x_t$,更新其隐藏状态。最终,最后一个隐藏状态(或最后一个细胞状态)被用作整个输入序列的上下文向量(Context Vector)$c$。
上下文向量:固定维度的向量 $c \in \mathbb{R}^d$,编码了整个输入序列的语义信息。它是连接编码器和解码器的桥梁。
解码器(Decoder):另一个 LSTM(通常是独立的参数集合),以上下文向量 $c$ 为初始状态,逐词生成输出序列。每个时间步,解码器输出一个词 $y_t$,并将其作为下一个时间步的输入,直到生成特殊的结束标记 $\langle\text{EOS}\rangle$。
2.2 数学形式化
让我们用数学语言精确描述这个过程。
编码器:
对于输入序列 $\mathbf{x} = (x_1, \ldots, x_T)$,编码器 LSTM 计算:
$$h_t^{\text{enc}} = \text{LSTM}{\text{enc}}(h{t-1}^{\text{enc}}, x_t), \quad t = 1, \ldots, T$$
上下文向量通常取最后一个隐藏状态:
$$c = h_T^{\text{enc}}$$
解码器:
解码器以 $c$ 为初始状态,逐词生成输出:
$$h_t^{\text{dec}} = \text{LSTM}{\text{dec}}(h{t-1}^{\text{dec}}, y_{t-1}), \quad h_0^{\text{dec}} = c$$
输出词的概率分布通过 Softmax 获得:
$$P(y_t \mid y_{<t}, \mathbf{x}) = \text{Softmax}(W_{\text{out}} h_t^{\text{dec}} + b_{\text{out}})$$
训练时,我们使用教师强制(Teacher Forcing):解码器的输入不是它自己上一时刻的预测,而是真实的标签 $y_{t-1}^*$。这加速了训练收敛。
损失函数是交叉熵:
$$\mathcal{L} = -\sum_{t=1}^{T’} \log P(y_t^* \mid y_{<t}^*, \mathbf{x})$$
2.3 输入反转的技巧
论文中有一个看似奇怪但极其有效的技巧:将输入序列的词序反转。
例如,不是输入 “A B C D”,而是输入 “D C B A”。
为什么这有效?
考虑从法语 “Je vais à l’école” 翻译到英语 “I go to school”。如果不反转:
- 编码器先看到 “Je”,它的最后隐藏状态(编码整个句子的向量)距离 “Je” 很远
- 解码器需要先生成 “I”,但 “I” 对应的是 “Je”,而 “Je” 的信息在上下文向量中已经"稀释"了
反转后:
- 编码器最后看到的是 “Je”(现在是第一个词)
- 解码器首先生成 “I”,上下文向量中保留了更多关于 “Je” 的信息
这种简单的技巧在 WMT'14 英法语翻译任务上将 BLEU 分数从 25.9 提升到 30.6,提升了近 5 个点!
第三章:训练与推理
3.1 大规模训练
Seq2Seq 的成功离不开大规模训练。论文使用了两组配置:
深层 LSTM:4 层编码器 + 4 层解码器,每层 1000 个隐藏单元。这比当时常用的 1-2 层 RNN 深得多。
词嵌入:输入词被映射为 1000 维的稠密向量。这些嵌入与网络一起端到端训练。
正则化:
- Dropout:在输入到 LSTM 的循环连接上应用 0.2 的 Dropout
- 梯度裁剪:将梯度范数限制在 5 以内,防止梯度爆炸
优化:
- 使用 SGD 带动量(初始学习率 0.7,每轮衰减)
- 批量大小 128
- 训练 7.5 轮(约 3.5 天在 8 块 NVIDIA K80 GPU 上)
3.2 束搜索解码
训练时,我们知道真实的标签,可以使用教师强制。但推理时,我们需要模型自己生成整个序列。
贪婪解码:每一步选择概率最高的词。简单但可能陷入局部最优——早期的错误会传播到后续。
束搜索(Beam Search):维护 $k$ 个最可能的候选序列($k$ 是束宽,通常 5-10)。
算法流程:
- 初始化:只有一个候选(开始标记),分数为 0
- 每一步:
- 对每个候选,扩展出词汇表中所有可能的下一个词
- 计算新分数:$\text{score} + \log P(y_t \mid y_{<t}, \mathbf{x})$
- 保留分数最高的 $k$ 个候选
- 当候选生成结束标记时,将其加入最终候选集
- 返回分数最高的完整序列
束搜索允许模型在早期"探索"不同的路径,避免贪婪策略的短视。论文中使用束宽 2 就显著提升了翻译质量。
3.3 实验结果
在 WMT'14 英语到法语翻译任务上,Seq2Seq 取得了突破性结果:
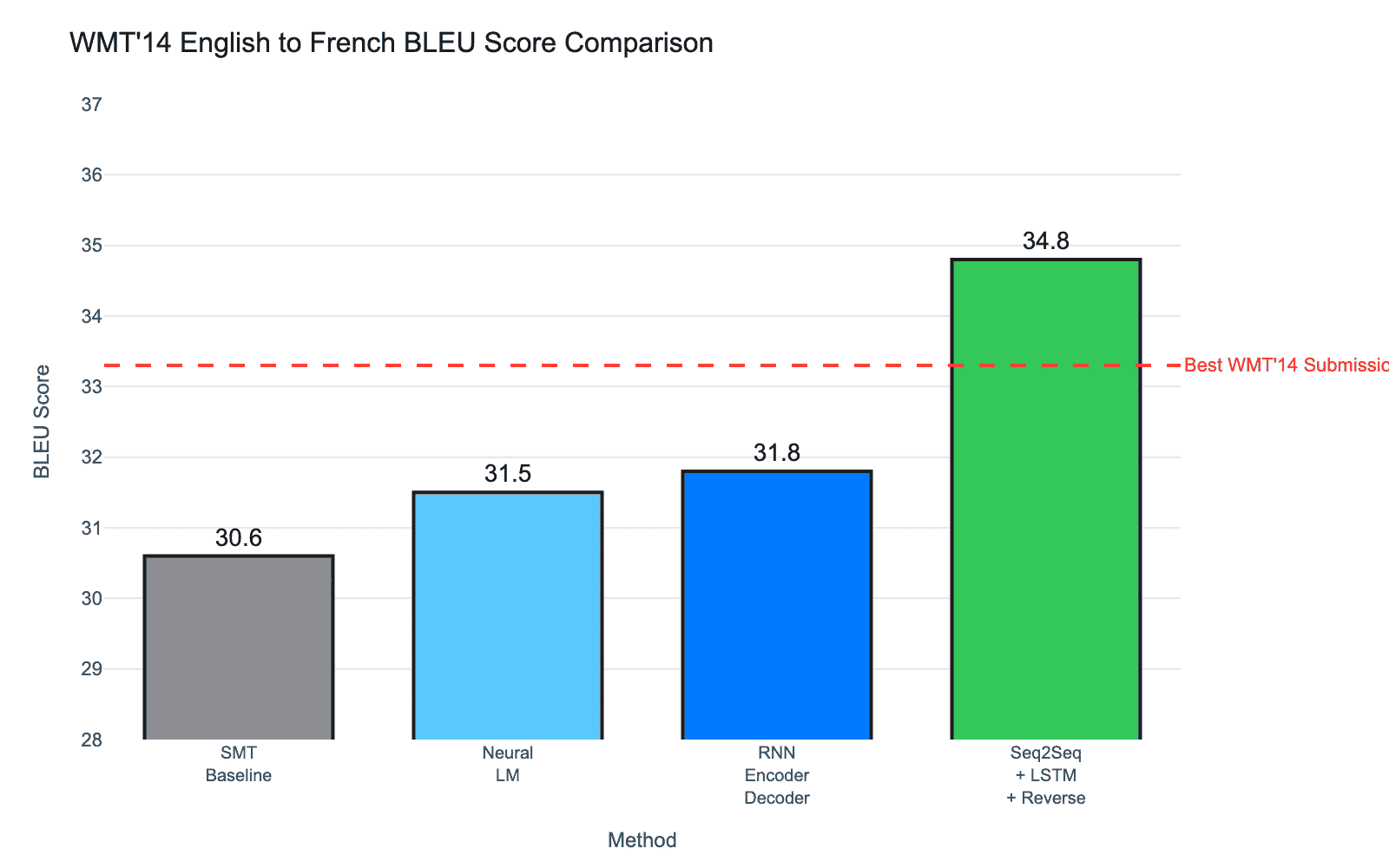
- SMT Baseline:30.6 BLEU(当时的统计机器翻译系统)
- Neural LM:31.5 BLEU(仅使用神经语言模型)
- RNN Encoder-Decoder:31.8 BLEU(浅层 RNN)
- Seq2Seq + LSTM + Reverse:34.8 BLEU
最值得注意的是,简单的 Seq2Seq 模型(34.8 BLEU)已经超过了 WMT'14 比赛的最佳提交(33.3 BLEU),后者是复杂的集成系统,使用了大量人工特征。
当使用集成学习(5 个独立训练的模型投票)时,分数进一步提升到 36.5 BLEU。
第四章:注意力的黎明
4.1 信息瓶颈
Seq2Seq 有一个根本性的限制:上下文向量 $c$ 的维度是固定的,无论输入序列多长,都被压缩成同样大小的向量。
这就像让一个人听一整本书,然后只凭记忆复述。对于短段落可能还行,但对于长篇大论,信息必然丢失。
4.2 注意力机制的引入
2015年,Dzmitry Bahdanau 等人提出了注意力机制(Attention Mechanism),解决了这个问题。
核心思想:解码器在生成每个词时,动态地"关注"输入序列的不同部分。
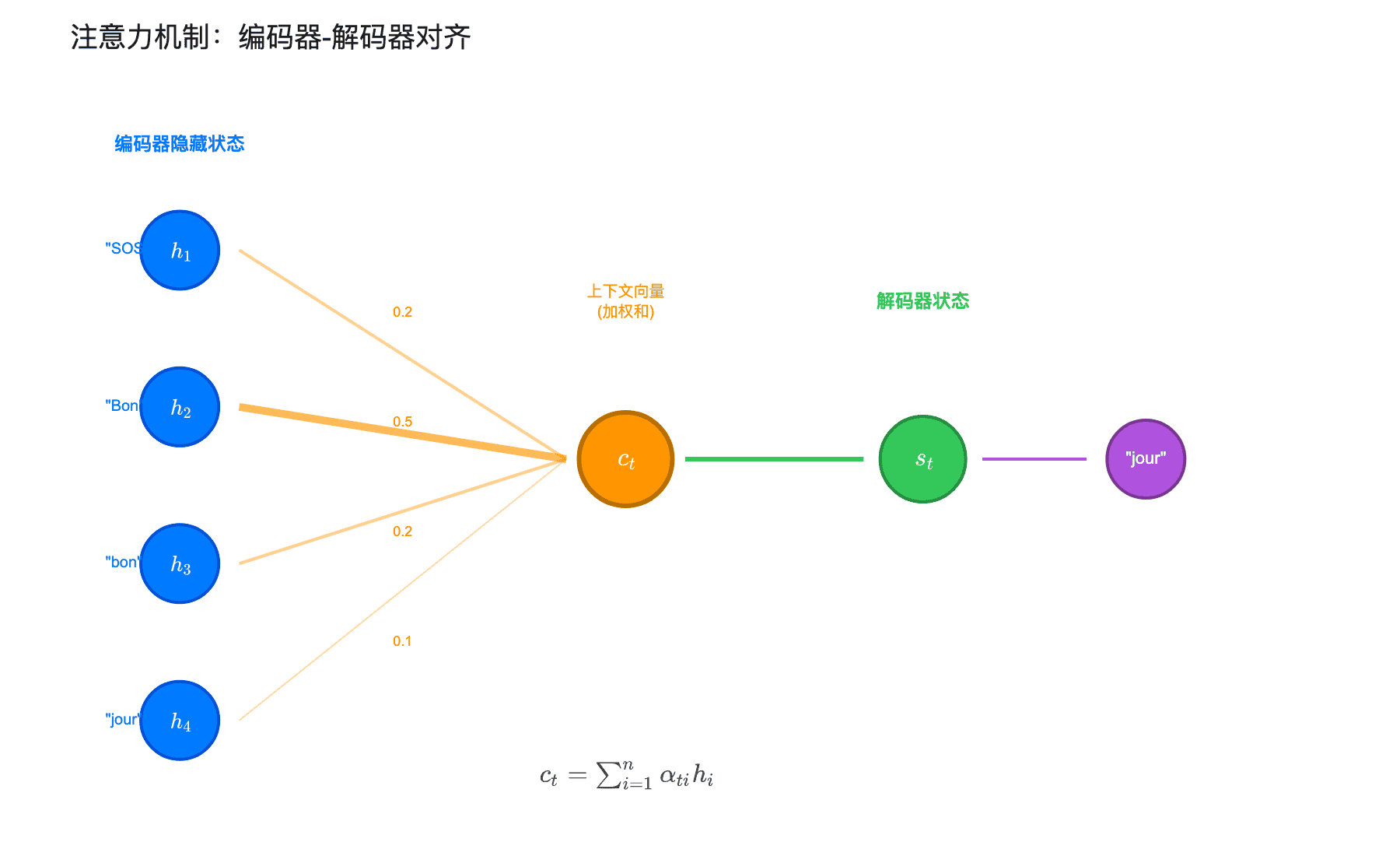
上图展示了解码器生成 “jour” 时的注意力分布。编码器隐藏状态 $h_1, \ldots, h_4$ 分别对应输入词 “SOS”, “Bon”, “bon”, “jour”。注意力权重 $\alpha_{ti}$ 表示生成第 $t$ 个输出词时,应该给予第 $i$ 个输入隐藏状态多少关注。
上下文向量的计算:
不再是固定的 $c = h_T^{\text{enc}}$,而是对每个解码步骤 $t$ 动态计算:
$$c_t = \sum_{i=1}^{T} \alpha_{ti} h_i^{\text{enc}}$$
注意力权重:
$$\alpha_{ti} = \frac{\exp(e_{ti})}{\sum_{j=1}^{T} \exp(e_{tj})}$$
其中 $e_{ti}$ 是对齐分数(Alignment Score),衡量解码器状态 $s_{t-1}$ 与编码器隐藏状态 $h_i$ 的"匹配程度":
$$e_{ti} = v_a^{\top} \tanh(W_s s_{t-1} + W_h h_i)$$
这被称为加性注意力(Additive Attention)或 Bahdanau 注意力。
解码器更新:
现在解码器的输入不仅包含上一时刻的预测,还包含注意力加权后的上下文:
$$s_t = \text{LSTM}{\text{dec}}(s{t-1}, [y_{t-1}; c_t])$$
其中 $[\cdot; \cdot]$ 表示向量拼接。
4.3 注意力的可视化
注意力机制的一个美妙之处在于可解释性。通过可视化注意力权重矩阵,我们可以看到模型是如何"对齐"源语言和目标语言的。
例如,在翻译 “the cat sat on the mat” 到法语时:
- 生成 “le” 时,注意力集中在 “the”(第一个)
- 生成 “chat” 时,注意力集中在 “cat”
- 生成 “tapis” 时,注意力集中在 “mat”
这种软对齐(Soft Alignment)比传统统计机器翻译的硬对齐(Hard Alignment)更加灵活,能够处理词序差异和一对多映射。
第五章:Seq2Seq 的遗产
5.1 超越机器翻译
Seq2Seq 架构很快被应用到各种序列转导任务:
语音识别:将声学特征序列(语音)转录为文本序列。DeepSpeech、Listen, Attend and Spell 等系统都基于 Seq2Seq。
文本摘要:将长文档压缩为简短摘要。注意力机制帮助模型识别原文中的关键句子。
对话系统:生成自然语言回复。编码器理解用户输入,解码器生成回复。
代码生成:将自然语言描述转换为程序代码。GitHub Copilot 的早期版本就使用了 Seq2Seq。
5.2 通向 Transformer
Seq2Seq + 注意力为 2017 年的 Transformer 奠定了基础。Transformer 进一步革新了:
自注意力(Self-Attention):不再只是解码器关注编码器,序列内的每个位置都可以关注其他所有位置。
并行化:RNN/LSTM 必须顺序处理序列,而自注意力可以并行计算,大大加速了训练。
多头注意力:使用多组注意力机制,捕捉不同类型的依赖关系。
Transformer 的提出催生了 BERT、GPT 系列,最终引领我们进入了大语言模型的时代。
5.3 核心洞见回顾
Seq2Seq 论文之所以经典,在于它简洁而深刻的核心思想:
- 统一框架:用一个端到端的神经网络替代复杂的流水线
- 编码器-解码器:将可变输入压缩为固定向量,再扩展为可变输出
- 深度与容量:更深的网络(4 层 LSTM)配合大规模数据,释放神经网络的潜力
- 为序列设计:LSTM 的门控机制专门解决序列建模的梯度问题
这些洞见不仅适用于 2014 年的机器翻译,也适用于今天的大语言模型。从 Seq2Seq 到 GPT-4,我们始终在解决同一个问题:如何让机器理解并生成人类语言。Seq2Seq 是这段旅程的重要里程碑。
结语
当我们今天与 ChatGPT 对话,或使用 Google 翻译阅读外文文献时,很少会想起 2014 年的那篇论文。但正是 Seq2Seq 开创的编码器-解码器范式,让神经网络真正开始理解序列数据的本质。
从固定长度的上下文向量,到动态注意力,再到完全基于注意力的 Transformer,这是一条清晰的技术演进路线。每一步都建立在前一步的基础之上,每一代模型都解决了前一代的局限。
Seq2Seq 告诉我们:有时候,突破性的想法并不需要复杂的数学。将输入反转、使用更深的网络、端到端训练——这些看似简单的技巧,组合在一起就能产生惊人的效果。
在深度学习的历史长河中,Seq2Seq 是一颗璀璨的明珠。它不仅解决了机器翻译的问题,更开启了一个新时代:序列到序列学习的时代。
参考文献
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems, 27.
Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural machine translation by jointly learning to align and translate. International Conference on Learning Representations.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30.