
“You shall know a word by the company it keeps.” — John Rupert Firth
引言:从符号到语义
想象一下,你正在阅读一篇关于"苹果"的文章。在"乔布斯推出了划时代的苹果产品"这句话中,“苹果"显然指的是一家公司;而在"我喜欢吃新鲜的苹果"中,它则是一种水果。人类能够毫不费力地根据上下文理解这种歧义,但对于计算机而言,这曾是一个巨大的挑战。
在 Word2Vec 出现之前,自然语言处理主要依赖独热编码(One-Hot Encoding):每个词都被表示为一个高维稀疏向量,向量中只有对应位置为 $1$,其余全为 $0$。“苹果"可能是 $[0, 0, 1, 0, \ldots, 0]$,“香蕉"是 $[0, 0, 0, 1, \ldots, 0]$。这种方法的问题显而易见:任意两个词之间的余弦相似度都是 $0$,模型完全无法捕捉"苹果"和"香蕉"都是水果这一语义关系。
2013 年,Tomas Mikolov 等人在 Google 提出了 Word2Vec,这是一种能够从大规模语料库中学习词向量表示的浅层神经网络。其核心思想简单却深刻:语义相近的词,其上下文也相似。这一方法不仅在多项语义和语法任务上取得了当时最先进的性能,更开启了深度学习在自然语言处理领域的广泛应用。
本文将带你深入理解 Word2Vec 的数学原理,从神经概率语言模型出发,完整推导 CBOW 和 Skip-gram 两种架构,并探讨其在现代 NLP 中的深远影响。
第一章:从词袋到神经语言模型
1.1 统计语言模型的演进
语言模型的核心任务是计算一个句子出现的概率。对于包含 $n$ 个词的句子
其联合概率可以分解为:
这个分解基于链式法则,但直接估计这些条件概率面临维度灾难——历史词的组合数是指数级的。
n-gram 模型通过马尔可夫假设简化了这个问题:假设一个词只依赖于前 $n-1$ 个词。当 $n=2$ 时,就是二元模型(Bigram):
n-gram 模型简单高效,但存在明显缺陷:
- 数据稀疏性:很多合理的词组合在训练语料中从未出现
- 无法捕捉长距离依赖:“虽然……但是……“这样的结构超出窗口范围
- 语义鸿沟:“猫"和"狗"在模型中是完全无关的符号
1.2 分布式假说与词向量
1957 年,英国语言学家 J.R. Firth 提出了著名的分布式假说(Distributional Hypothesis):“You shall know a word by the company it keeps.” 这句话揭示了一个深刻洞见——词的语义可以通过其上下文分布来刻画。
想象你在一本被涂抹了部分文字的书中阅读。当看到"我每天早上都会喝____来提神”,即使最后一个词被遮挡,你也能推断出它可能是"咖啡”、“茶"或"可乐”。这说明词的语义确实蕴藏在上下文关系中。
词向量(Word Embedding)正是基于这一思想的数学实现:
- 将每个词映射到一个低维稠密向量 $\mathbf{v} \in \mathbb{R}^d$(通常 $d = 50 \sim 300$)
- 语义相似的词在向量空间中距离相近
- 向量可以捕捉丰富的语义关系
1.3 神经概率语言模型
2003 年,Yoshua Bengio 提出了神经概率语言模型(Neural Probabilistic Language Model, NPLM),首次用神经网络学习词向量。模型结构如下:
输入层 $\to$ 投影层(词向量查表)$\to$ 隐藏层($\tanh$)$\to$ 输出层(Softmax)
对于给定的上下文词
模型预测目标词 $w_i$ 的概率:
其中 $y_w$ 是输出层对应词 $w$ 的得分。
NPLM 的革命性在于:词向量作为模型的副产品被学习得到,相似的词会拥有相似的向量表示。但 NPLM 的计算复杂度很高,主要是因为:
- 隐藏层和输出层的全连接计算
- Softmax 需要遍历整个词汇表
这限制了它在更大规模数据上的应用。
第二章:Word2Vec 的架构
Word2Vec 是对 NPLM 的简化与优化。Mikolov 等人发现,去除隐藏层不仅降低了计算复杂度,反而提高了词向量的质量。这一反直觉的发现源于:NPLM 的主要任务(语言建模)和学习词表示的目标并不完全一致。
Word2Vec 提出了两种对称的架构:
- CBOW(Continuous Bag-of-Words):用上下文预测中心词
- Skip-gram:用中心词预测上下文
2.1 CBOW:上下文合成语义
CBOW 的核心思想是:一个词的语义由其周围词的语义"合成"而来。
模型结构
图例说明:
- 🔵 蓝色节点:上下文输入词($w_{i-2}, w_{i-1}, w_{i+1}, w_{i+2}$)
- 🟢 绿色节点:投影层平均操作($\mathbf{h} = \frac{1}{4}\sum \mathbf{v}_{w_k}$)
- 🟠 橙色节点:预测目标(中心词 $w_i$)
设窗口大小为 $c$(上下文词数),词汇表大小为 $V$,词向量维度为 $d$。
输入:上下文词的独热编码
投影层:词向量查表并求平均
其中 $\mathbf{W} \in \mathbb{R}^{V \times d}$ 是输入词向量矩阵,$\mathbf{v}_{w_k}$ 是词 $w_k$ 的输入向量。
输出层:Softmax 预测中心词概率
其中 $\mathbf{U} \in \mathbb{R}^{V \times d}$ 是输出词向量矩阵,$\mathbf{u}_w$ 是词 $w$ 的输出向量。
数学推导
CBOW 的目标函数是最大化对数似然:
其中 $T$ 是训练语料的总词数。
对于单个训练样本,损失函数为负对数似然:
其中 $w_O$ 是输出词(中心词),$w_{I,1}, \ldots, w_{I,2c}$ 是输入词(上下文)。
定义
则:
其中 $Z = \sum_{w=1}^{V} \exp(z_w)$ 是配分函数。
损失函数对 $z_w$ 的梯度:
这是一个漂亮的解释:梯度正比于预测概率与真实分布(one-hot)的差异。
对输出向量 $\mathbf{u}_w$ 的梯度:
对输入向量 $\mathbf{v}{w{I,k}}$ 的梯度:
参数更新规则(学习率 $\eta$):
2.2 Skip-gram:中心词辐射语义
Skip-gram 是 CBOW 的镜像:它用中心词预测周围的上下文词。直觉上,这迫使模型将更多信息编码到每个词的向量中。
模型结构
图例说明:
- 🟠 橙色节点:中心词输入($w_i$)
- 🔵 蓝色节点:独立预测的上下文词($w_{i-2}, w_{i-1}, w_{i+1}, w_{i+2}$)
输入:中心词的独热编码 $\mathbf{x} \in {0, 1}^V$
投影层:词向量查表
输出层:对每个上下文位置独立预测
假设上下文窗口为 $c$,Skip-gram 假设给定中心词时,各个上下文词的出现是条件独立的:
其中每个条件概率为:
数学推导
目标函数:
对于单个上下文词 $w_O$,损失函数:
对 $\mathbf{v}_{w_I}$ 的梯度:
对 $\mathbf{u}_w$ 的梯度:
2.3 CBOW vs Skip-gram
| 特性 | CBOW | Skip-gram |
|---|---|---|
| 训练方向 | 上下文 $\to$ 中心词 | 中心词 $\to$ 上下文 |
| 训练速度 | 更快 | 较慢 |
| 对罕见词效果 | 一般 | 更好 |
| 对高频词效果 | 更好 | 一般 |
| 适用于 | 大规模语料 | 小规模语料 |
Mikolov 等人的实验表明:Skip-gram 在处理罕见词和捕捉精细语义关系方面表现更好,而 CBOW 训练速度更快,对高频词建模更平滑。
第三章:训练优化策略
原始的 Softmax 需要遍历整个词汇表计算归一化因子,这对于大规模语料($V \sim 10^5 \sim 10^7$)是不可接受的。Word2Vec 提出了两种优化策略:
3.1 层次 Softmax(Hierarchical Softmax)
层次 Softmax 利用二叉树结构(通常是哈夫曼树)将计算复杂度从 $O(V)$ 降低到 $O(\log V)$。
哈夫曼树构建
- 每个词对应一个叶节点,权重为词频
- 高频词离根节点更近,路径更短
- 构建 Huffman 树,平均路径长度最小化
概率计算
在二叉树中,从根到叶节点的路径上的每个内部节点代表一个二分类决策。设 $n(w, j)$ 是从根到词 $w$ 的路径上第 $j$ 个节点,$L(w)$ 是路径长度。
其中:
$\sigma(x) = \frac{1}{1 + e^{-x}}$ 是 sigmoid 函数
$[![ n(w, j+1) = \text{ch}(n(w, j)) ]!]$ 是指示函数:
$\mathbf{v}’_{n(w,j)}$ 是内部节点 $n(w,j)$ 的向量表示
$\mathbf{v}_{w_I}$ 是输入词 $w_I$ 的向量
这样,计算 $P(w \mid w_I)$ 只需要遍历路径上的 $O(\log V)$ 个节点,而非全部 $V$ 个词。
3.2 负采样(Negative Sampling)
负采样是另一种更简单的近似方法,也是实际应用中最常用的策略。
核心思想
将多分类问题转化为二分类问题:
- 正样本:真实的目标词对 $(w_I, w_O)$,标签为 $1$
- 负样本:从噪声分布中采样的词对 $(w_I, w_{\text{neg}})$,标签为 $0$
目标函数
其中:
- $k$ 是负样本数量(通常 $5 \sim 20$)
- $P_n(w)$ 是噪声分布,通常取 $P_n(w) \propto f(w)^{3/4}$,$f(w)$ 是词频
- $3/4$ 的幂次是为了降低高频词的采样概率,增加罕见词的采样机会
为什么负采样有效?
负采样可以看作是对 Softmax 的近似,其理论基础是噪声对比估计(Noise Contrastive Estimation, NCE)。它将密度估计问题转化为区分真实数据和噪声数据的二分类问题。
与层次 Softmax 相比,负采样的优势:
- 实现更简单
- 对于小数据集和罕见词效果更好
- 训练速度更快(每次更新只需要处理 $k+1$ 个词)
3.3 子采样(Subsampling)
除了优化输出层的计算,Word2Vec 还对高频词进行了子采样。像"的”、“是”、“在"这样的词出现频率极高,但信息含量很低,而且会拖慢训练。
子采样策略:以概率 $P(w_i)$ 丢弃词 $w_i$:
其中 $f(w_i)$ 是词频,$t$ 是阈值(通常 $10^{-5}$)。当 $f(w_i) > t$ 时,词被丢弃的概率随词频增加而增加。
第四章:词向量的奇妙性质
训练完成后,Word2Vec 学到的词向量展现出令人惊叹的线性关系。
4.1 语义关系的向量算术
Mikolov 等人发现,词向量能够捕捉各种语义和语法关系:
图:词向量空间中的语义关系,king - man + woman ≈ queen
这个经典例子表明:词向量不仅编码了词的语义,还编码了词之间的关系。“国王"减去"男人"加上"女人"约等于"女王”,这意味着向量空间中捕捉到了性别这一语义维度。
类似的例子还包括:
首都-国家:
时态:
单复数:
比较级:
4.2 为什么词向量有这种性质?
这种线性关系的出现并非偶然,而是分布式假说的数学体现。考虑 Skip-gram 的目标:预测上下文词。如果"国王"和"女王"在相似的上下文中出现(”____统治着这个国家”),它们的向量就会相似。
更重要的是,词向量编码了语义差异。“国王"和"女王"的差向量大致等于"男人"和"女人"的差向量,因为它们都与"性别"这一概念相关。
从几何角度看,Word2Vec 学习到的向量空间将语义关系编码为方向。每一个重要的语义维度(性别、时态、单复数等)对应向量空间中的一个方向。
4.3 余弦相似度与词语类比
衡量词向量相似度的标准方法是余弦相似度:
两个向量的夹角越小(方向越接近),余弦值越接近 $1$,表示语义越相似。
词语类比任务(Word Analogy)是评估词向量的标准任务:
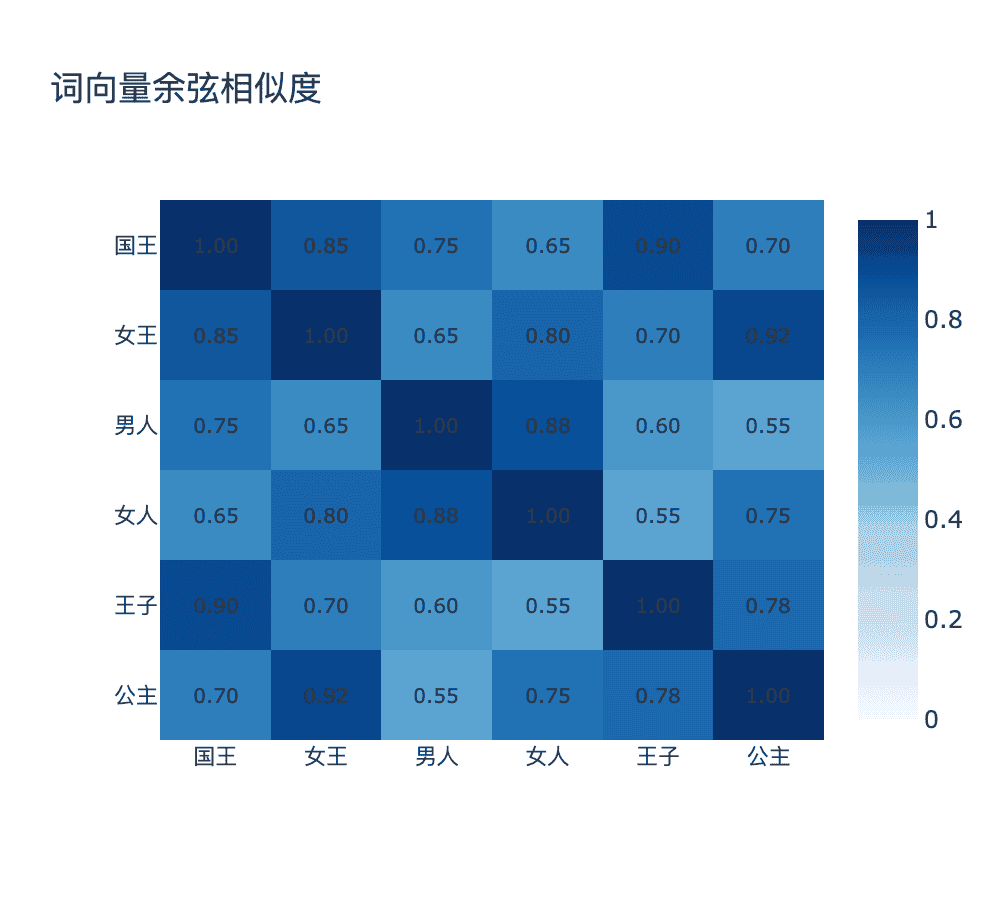
图:词向量余弦相似度矩阵,展示语义相近词的关联程度
对于关系"A 之于 B,如同 C 之于 D”,寻找 D 等价于:
Mikolov 等人报告,在包含 $1.6$ 亿词的训练数据上,Skip-gram 模型在语义类比任务上达到了 $55%$ 的准确率,在语法类比任务上达到了 $59%$ 的准确率。
第五章:实现与实战
5.1 伪代码实现
以下是 Skip-gram 负采样的简化伪代码:
# 初始化
V = vocabulary_size
d = embedding_dim
W_input = random(V, d) # 输入词向量矩阵
W_output = random(V, d) # 输出词向量矩阵
# 训练
for sentence in corpus:
for i, target in enumerate(sentence):
# 获取上下文窗口
context = sentence[max(0, i-window):i] + sentence[i+1:i+window+1]
for context_word in context:
# 正样本更新
z = sigmoid(dot(W_output[target], W_input[context_word]))
g = (z - 1) * learning_rate
W_output[target] -= g * W_input[context_word]
W_input[context_word] -= g * W_output[target]
# 负样本更新
for _ in range(negative_samples):
negative = sample_from_noise_distribution()
z = sigmoid(dot(W_output[negative], W_input[context_word]))
g = z * learning_rate
W_output[negative] -= g * W_input[context_word]
W_input[context_word] -= g * W_output[negative]
5.2 超参数选择
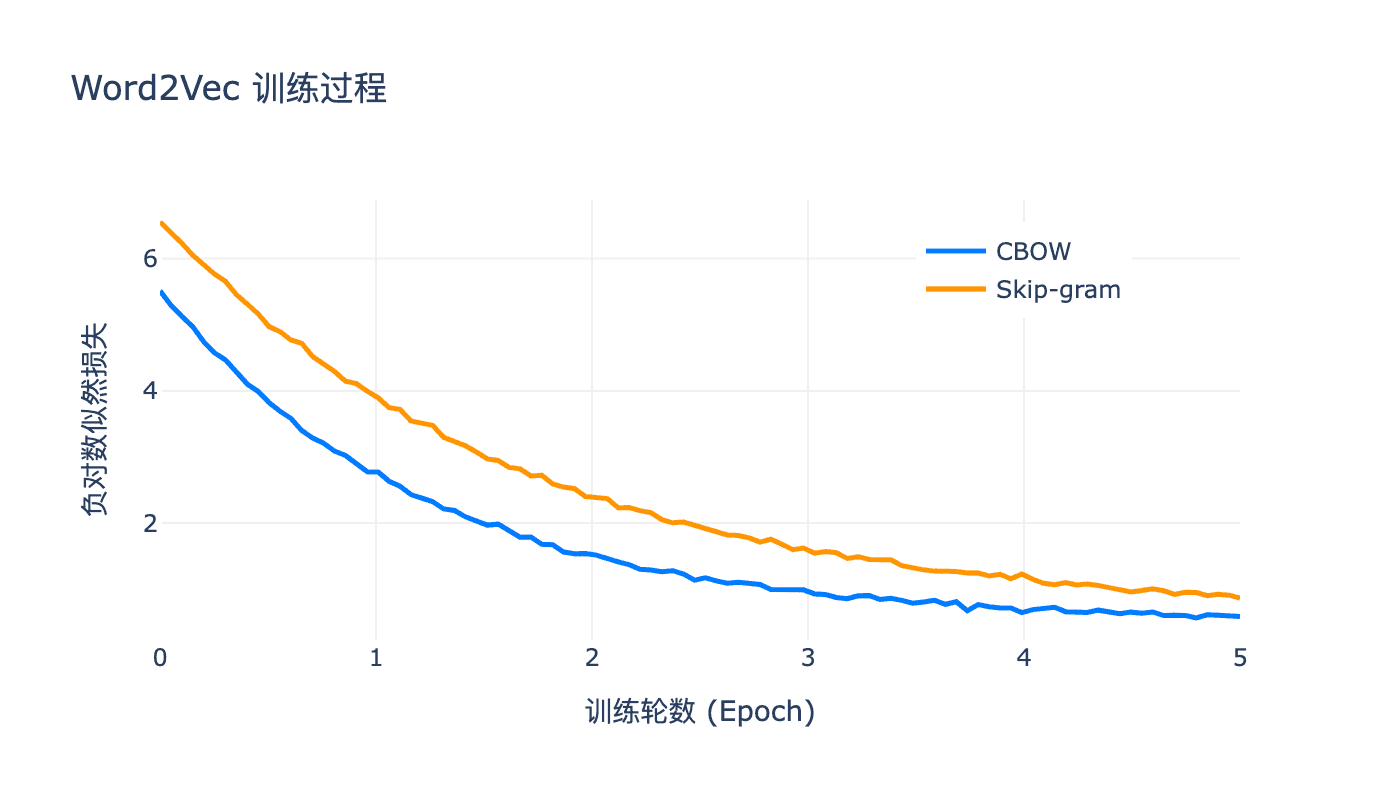
图:CBOW 与 Skip-gram 训练过程中损失函数的变化
| 超参数 | 推荐值 | 说明 |
|---|---|---|
| 词向量维度 $d$ | $100 \sim 300$ | 维度越高表达能力越强,但也更容易过拟合 |
| 上下文窗口 $c$ | $5 \sim 10$ | Skip-gram 可用较小窗口,CBOW 可用较大窗口 |
| 负采样数 $k$ | $5 \sim 20$ | 小数据集用大值,大数据集用小值 |
| 学习率 $\eta$ | $0.01 \sim 0.025$ | 常用线性衰减策略 |
| 子采样阈值 $t$ | $10^{-5}$ | 控制高频词的丢弃率 |
| 最小词频 | $5 \sim 10$ | 过滤罕见词,减少噪声 |
5.3 使用 Gensim 训练
实际应用中,我们通常使用成熟的库如 Gensim:
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
# 准备语料(分词后的句子列表)
sentences = [
["我", "喜欢", "自然", "语言", "处理"],
["机器", "学习", "是", "人工智能", "的", "分支"],
# ... 更多句子
]
# 训练模型
model = Word2Vec(
sentences=sentences,
vector_size=100, # 词向量维度
window=5, # 上下文窗口
min_count=5, # 最小词频
workers=4, # 并行线程数
sg=1, # 1=Skip-gram, 0=CBOW
negative=5, # 负采样数
sample=1e-5, # 子采样阈值
epochs=5 # 训练轮数
)
# 获取词向量
vector = model.wv["机器学习"]
# 找最相似的词
similar = model.wv.most_similar("人工智能", topn=5)
# 词语类比
result = model.wv.most_similar(
positive=["女王", "男人"],
negative=["国王"],
topn=1
)
第六章:影响与演进
6.1 Word2Vec 的革命性意义
Word2Vec 的提出标志着自然语言处理进入了深度学习时代。它的影响可以从以下几个维度理解:
1. 技术范式转变
- 从符号到连续:将离散的词符号转化为连续的向量表示
- 从手工特征到自动学习:无需语言学知识,自动从数据中学习语义
- 从稀疏到稠密:低维稠密向量计算更高效,泛化能力更强
2. 工业应用落地
Word2Vec 训练速度快、实现简单,很快在工业界广泛应用:
- 搜索引擎:查询扩展、语义匹配
- 推荐系统:物品/用户向量表示
- 广告系统:关键词定向、受众画像
- 机器翻译:语义对齐、双语词典构建
3. 学术影响
截至 2024 年,Mikolov 的 Word2Vec 论文被引用超过 $50{,}000$ 次,是 NLP 领域最具影响力的论文之一。
6.2 后续发展
Word2Vec 开创了词嵌入的先河,后续研究在多个方向上进行拓展:
GloVe(Global Vectors)
Pennington 等人在 2014 年提出 GloVe,结合了全局统计信息(共现矩阵)和局部上下文信息(窗口)。其目标函数直接优化共现矩阵与词向量内积的关系:
GloVe 在某些任务上表现优于 Word2Vec,且训练更稳定。
FastText
2016 年,Facebook 提出 FastText,将词表示为字符 n-gram 的组合:
这种方法能够处理未登录词(OOV),并捕捉词的形态信息。
Contextualized Embeddings
Word2Vec 是静态词向量:每个词只有一个固定的向量表示。这无法处理一词多义问题(如"苹果"公司 vs 水果)。
2018 年前后,ELMo、GPT、BERT 等模型提出动态词向量(Contextualized Embeddings),根据上下文为每个词实例生成不同的表示:
这标志着 NLP 进入了预训练语言模型时代,但 Word2Vec 奠定的分布式语义基础依然适用。
6.3 跨领域应用
Word2Vec 的核心思想——将离散符号嵌入连续向量空间——已被推广到众多领域:
| 领域 | 应用 |
|---|---|
| 图神经网络 | Node2Vec, DeepWalk(节点嵌入) |
| 生物信息学 | BioVec, ProtVec(蛋白质/DNA 序列) |
| 社交网络 | DeepWalk, LINE(用户/社区嵌入) |
| 知识图谱 | TransE, RotatE(实体/关系嵌入) |
| 代码分析 | Code2Vec, CodeBERT(代码嵌入) |
| 推荐系统 | Item2Vec, Prod2Vec(商品嵌入) |
结语:一个词嵌入的时代
Word2Vec 不仅是一个算法,更是一种思想的胜利:语言的语义可以通过分布式的统计规律来捕捉。
从 2013 年 Mikolov 等人的开创性论文,到今天动辄千亿参数的语言模型,词嵌入始终是自然语言处理的核心技术。无论是简单的文本分类,还是复杂的对话系统,将语言符号转化为机器可理解的向量表示都是不可或缺的第一步。
回顾 Word2Vec 的发展历程,我们可以得到几点启示:
简单即美:去除隐藏层的简化反而提升了性能,说明架构设计应当服务于目标任务。
数据即知识:Word2Vec 不需要人工标注,从海量无标注文本中自动学习语义,体现了无监督学习的威力。
几何即语义:词的语义关系编码在向量空间的几何结构中,这一洞见影响了后续所有表示学习研究。
正如 Mikolov 在论文结尾所言:“我们的工作表明,简单的模型训练海量数据,往往能击败复杂的模型训练小量数据。” 这一哲学贯穿于深度学习的发展历程,从 Word2Vec 到 GPT-4,从未改变。
“The meaning of a word is its use in the language.” — Ludwig Wittgenstein
参考资料
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. NIPS.
Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. JMLR.
Pennington, J., Socher, R., & Manning, C. (2014). GloVe: Global Vectors for Word Representation. EMNLP.
Rong, X. (2014). word2vec Parameter Learning Explained. arXiv preprint arXiv:1411.2738.