引言:预测的艺术
想象你是一位气象学家,面对一个看似简单却极具挑战性的问题:明天的气温会是多少?你拥有大量的历史数据——过去几年的气温记录、湿度、气压、风速等。但仅仅知道历史的平均气温是远远不够的。如果今天是炎热潮湿的夏日午后,那么明天的气温很可能与寒冷冬日的平均气温相差甚远。
这时,你需要一种更精细的预测方法:在给定今天天气状况的条件下,预测明天的气温。这就是条件期望(Conditional Expectation)的核心思想——不是做无条件的平均,而是在已知某些信息的条件下,做出最优的预测。
条件期望是现代概率论和统计学的基石概念之一。从卡尔·皮尔逊(Karl Pearson)在19世纪末对回归分析的开拓性工作,到柯尔莫哥洛夫(Andrey Kolmogorov)在1933年建立概率论的公理化体系,再到今天深度学习中变分自编码器(VAE)的潜在空间建模,条件期望始终扮演着核心角色。
本文将深入浅出地介绍条件期望的完整理论体系:从严格的数学定义出发,推导其关键性质,展示其在统计推断中的威力,最终揭示它如何在现代机器学习和深度学习中被广泛应用。
第一章:条件期望的直观理解
1.1 从条件概率到条件期望
让我们从更简单的概念——条件概率开始。假设你正在玩一副标准的52张扑克牌。抽到一张红桃的概率是多少?
$$P(\text{红桃}) = \frac{13}{52} = \frac{1}{4}$$
现在,假设有人告诉你这张牌是红色的(红桃或方块)。在这个条件下,抽到红桃的概率变为:
$$P(\text{红桃} \mid \text{红色}) = \frac{13}{26} = \frac{1}{2}$$
条件概率回答了"某事件发生的概率是多少"的问题。而条件期望则进一步回答:“在某条件下,某个随机变量的期望值是多少?”
例子:假设 $X$ 表示掷一个公平骰子的结果,$Y$ 表示结果的奇偶性($Y=1$ 表示奇数,$Y=0$ 表示偶数)。那么:
- 无条件期望:$E[X] = \frac{1+2+3+4+5+6}{6} = 3.5$
- 条件期望(已知是奇数):$E[X \mid Y=1] = \frac{1+3+5}{3} = 3$
- 条件期望(已知是偶数):$E[X \mid Y=0] = \frac{2+4+6}{3} = 4$
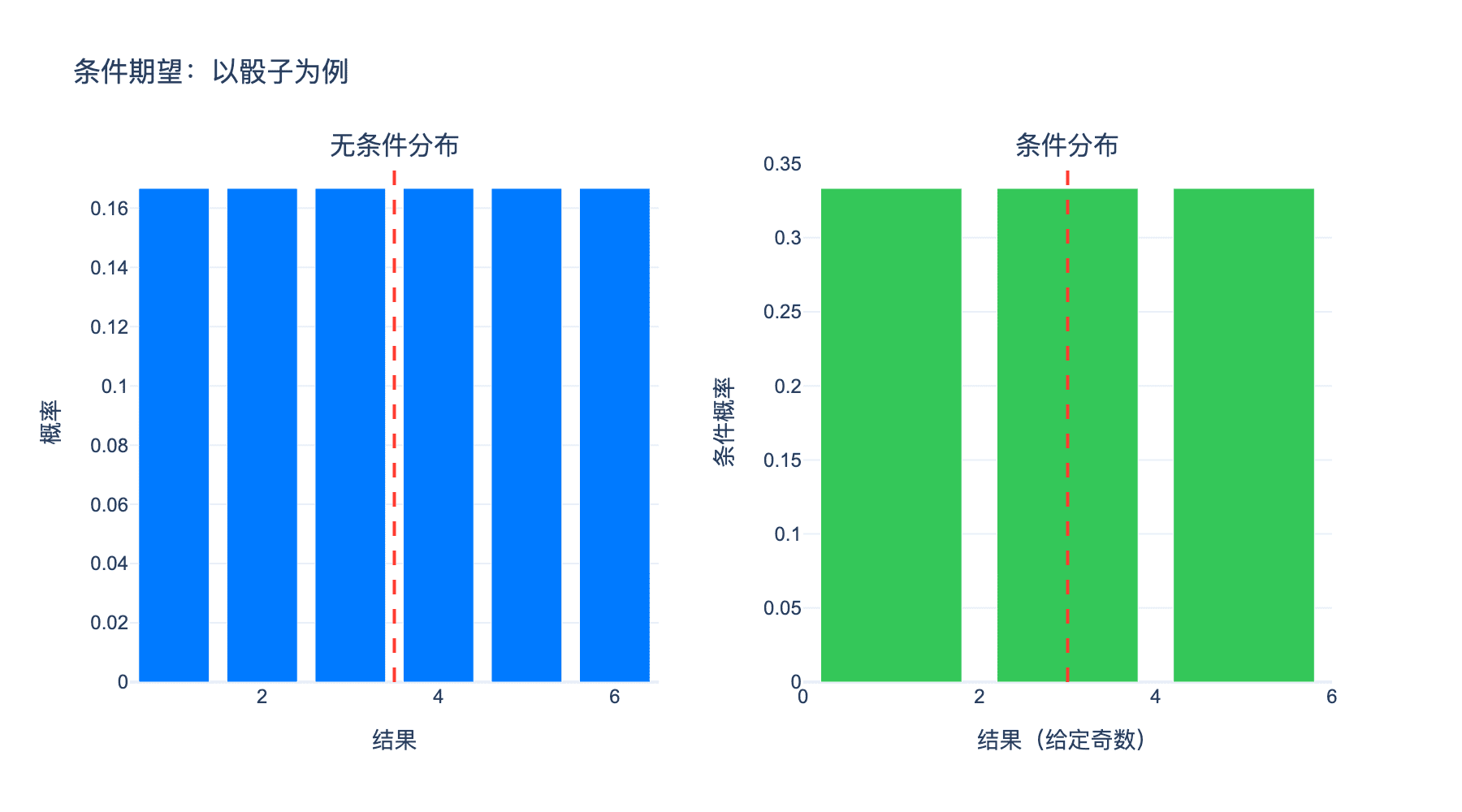
上图展示了这一例子:左图显示所有可能结果的分布,右图显示在奇偶条件下的条件分布及其期望值。
1.2 条件期望作为最优预测
条件期望有一个深刻的最优性解释:在给定信息的条件下,条件期望是最小化均方误差的预测。
假设你想用某个可观测的随机变量 $X$ 来预测另一个随机变量 $Y$。你希望找到一个函数 $g(X)$,使得预测误差 $Y - g(X)$ 在某种意义下最小。
定理:在所有 $X$ 的函数中,条件期望 $E[Y \mid X]$ 最小化均方误差:
$$E[Y \mid X] = \arg\min_{g} E[(Y - g(X))^2]$$
这个定理揭示了条件期望的本质:它是在已知信息下的最优预测。这也是为什么条件期望在统计学和机器学习中如此重要的原因——它提供了一种系统性的方法,从已有信息中提取对未来最有价值的预测。
第二章:条件期望的严格定义
2.1 离散情形的定义
设 $X$ 和 $Y$ 是两个离散随机变量。给定 $X = x$ 时,$Y$ 的条件期望定义为:
$$E[Y \mid X = x] = \sum_{y} y \cdot P(Y = y \mid X = x)$$
其中条件概率 $P(Y = y \mid X = x) = \frac{P(X = x, Y = y)}{P(X = x)}$(假设 $P(X = x) > 0$)。
例子:设 $(X, Y)$ 的联合分布如下表:
| $Y=1$ | $Y=2$ | $Y=3$ | |
|---|---|---|---|
| $X=1$ | 0.1 | 0.2 | 0.1 |
| $X=2$ | 0.15 | 0.25 | 0.2 |
则:
- $P(X=1) = 0.4$,$P(X=2) = 0.6$
- $E[Y \mid X=1] = 1 \cdot \frac{0.1}{0.4} + 2 \cdot \frac{0.2}{0.4} + 3 \cdot \frac{0.1}{0.4} = 2$
- $E[Y \mid X=2] = 1 \cdot \frac{0.15}{0.6} + 2 \cdot \frac{0.25}{0.6} + 3 \cdot \frac{0.2}{0.6} = 2.083$
2.2 连续情形的定义
对于连续随机变量,求和变为积分:
$$E[Y \mid X = x] = \int_{-\infty}^{\infty} y \cdot f_{Y \mid X}(y \mid x) , dy$$
其中 $f_{Y \mid X}(y \mid x) = \frac{f_{X,Y}(x,y)}{f_X(x)}$ 是条件概率密度函数。
正态分布的例子:若 $(X, Y)$ 服从二元正态分布,则:
$$E[Y \mid X = x] = \mu_Y + \rho \frac{\sigma_Y}{\sigma_X}(x - \mu_X)$$
这是一条直线——正是线性回归的理论基础。
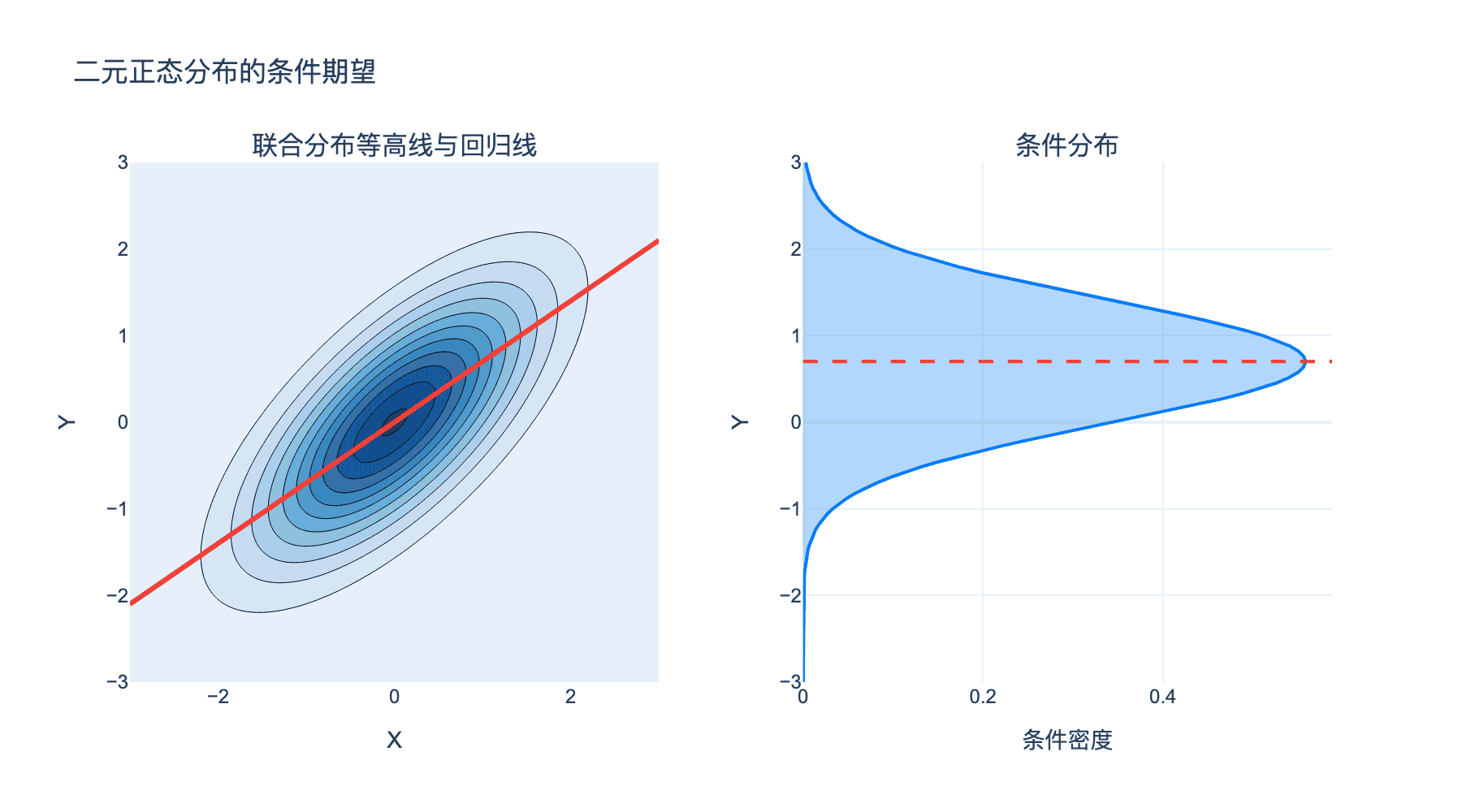
上图展示了二元正态分布的条件期望:左图显示联合分布的等高线,红线表示 $E[Y \mid X = x]$;右图显示给定 $X = x_0$ 时 $Y$ 的条件分布。
2.3 测度论视角:柯尔莫哥洛夫的抽象定义
1933年,柯尔莫哥洛夫在他的《概率论基础》中给出了条件期望的抽象定义。这个定义适用于一般概率空间,不要求条件变量的概率质量非零。
定义:设 $(\Omega, \mathcal{F}, P)$ 是概率空间,$\mathcal{G} \subseteq \mathcal{F}$ 是一个子$\sigma$-代数,$X$ 是可积随机变量。$X$ 关于 $\mathcal{G}$ 的条件期望 $E[X \mid \mathcal{G}]$ 是一个满足以下条件的随机变量:
可测性:$E[X \mid \mathcal{G}]$ 是 $\mathcal{G}$-可测的
积分性质:对所有 $A \in \mathcal{G}$,有
$$\int_A E[X \mid \mathcal{G}] , dP = \int_A X , dP$$
这个定义看似抽象,但它统一了离散和连续情形,并为更复杂的条件期望(如条件于连续随机变量取特定值)提供了严格的数学基础。
第三章:条件期望的核心性质
3.1 基本性质
条件期望具有以下关键性质:
线性性:对任意常数 $a, b$,
$$E[aX + bY \mid \mathcal{G}] = aE[X \mid \mathcal{G}] + bE[Y \mid \mathcal{G}]$$
全期望公式(Tower Property):
$$E[E[X \mid \mathcal{G}]] = E[X]$$
这表明"先取条件期望再取期望"等于直接取期望。
提取已知信息:若 $X$ 是 $\mathcal{G}$-可测的,则
$$E[XY \mid \mathcal{G}] = X \cdot E[Y \mid \mathcal{G}]$$
这是因为 $X$ 在给定 $\mathcal{G}$ 的条件下是"已知"的。
独立性:若 $X$ 与 $\mathcal{G}$ 独立,则
$$E[X \mid \mathcal{G}] = E[X]$$
独立性意味着 $\mathcal{G}$ 中的信息对预测 $X$ 没有帮助。
3.2 方差分解与信息价值
条件期望与方差分解有密切联系:
全方差公式:
$$\text{Var}(Y) = E[\text{Var}(Y \mid X)] + \text{Var}(E[Y \mid X])$$
这个公式将 $Y$ 的总方差分解为两部分:
- 组内方差(Within-group variance):$E[\text{Var}(Y \mid X)]$
- 组间方差(Between-group variance):$\text{Var}(E[Y \mid X])$
方差缩减:若用 $E[Y \mid X]$ 作为 $Y$ 的预测,则预测误差的方差为 $E[\text{Var}(Y \mid X)]$,比原始方差 $\text{Var}(Y)$ 减少了 $\text{Var}(E[Y \mid X])$。
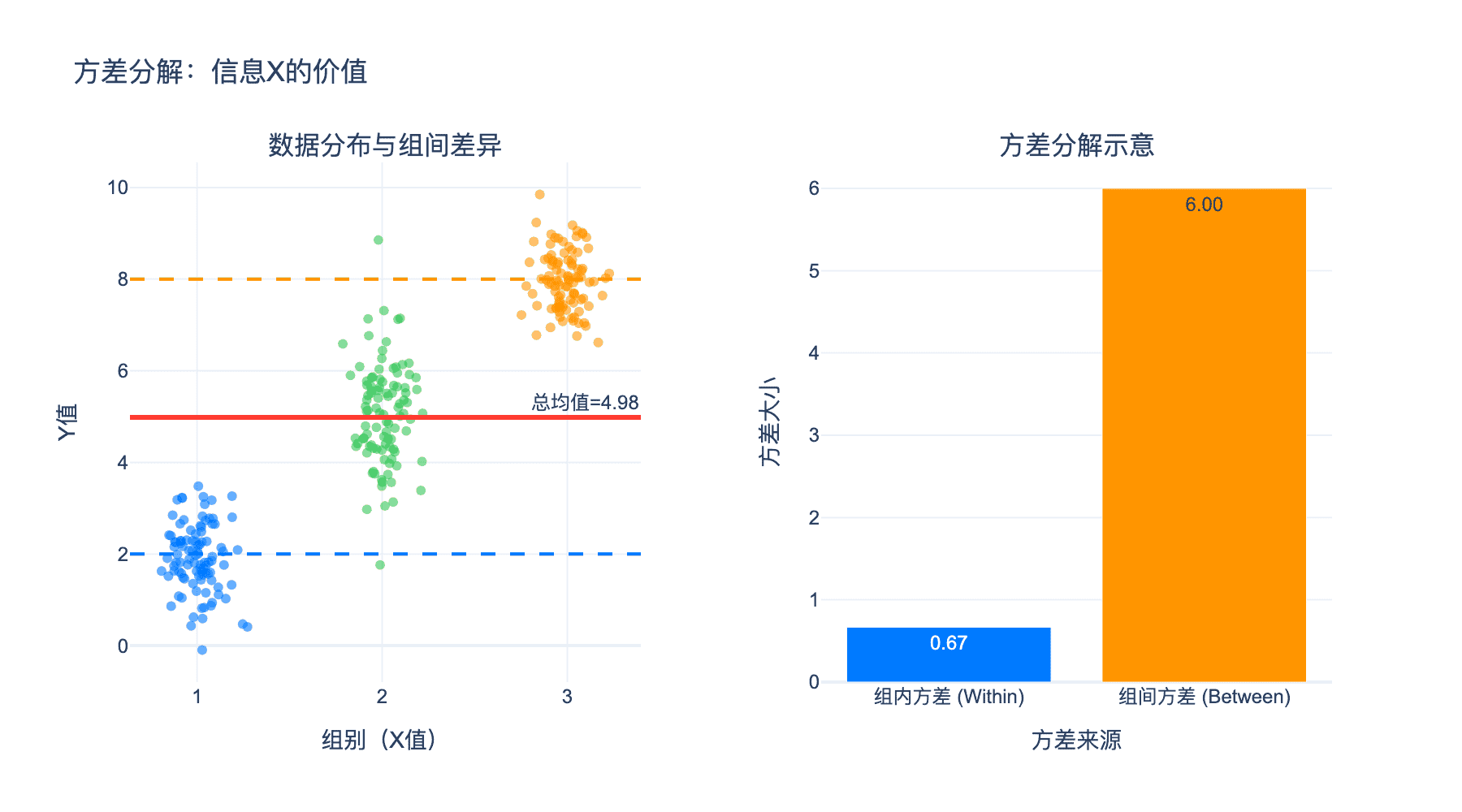
上图展示了方差分解:总方差被分解为组间方差和组内方差,信息 $X$ 的价值体现在方差的缩减上。
3.3 Jensen 不等式与条件形式
Jensen 不等式指出,对凸函数 $\phi$:
$$\phi(E[X]) \leq E[\phi(X)]$$
条件版本同样成立:
$$\phi(E[X \mid \mathcal{G}]) \leq E[\phi(X) \mid \mathcal{G}]$$
这个不等式在信息论、统计物理学和金融数学中有广泛应用。
第四章:条件期望在统计推断中的应用
4.1 充分统计量与 Rao-Blackwell 定理
充分统计量是包含样本中关于参数全部信息的统计量。Rao-Blackwell 定理告诉我们如何利用条件期望改进估计量。
定理:设 $\hat{\theta}$ 是参数 $\theta$ 的任意无偏估计,$T$ 是充分统计量。定义
$$\hat{\theta}^{\ast} = E[\hat{\theta} \mid T]$$
则 $\hat{\theta}^{\ast}$ 也是无偏的,且方差不大于 $\hat{\theta}$:
$$\text{Var}(\hat{\theta}^{\ast}) \leq \text{Var}(\hat{\theta})$$
直观理解:条件期望提取了充分统计量中的信息,消除了原始估计量中的"噪声"。
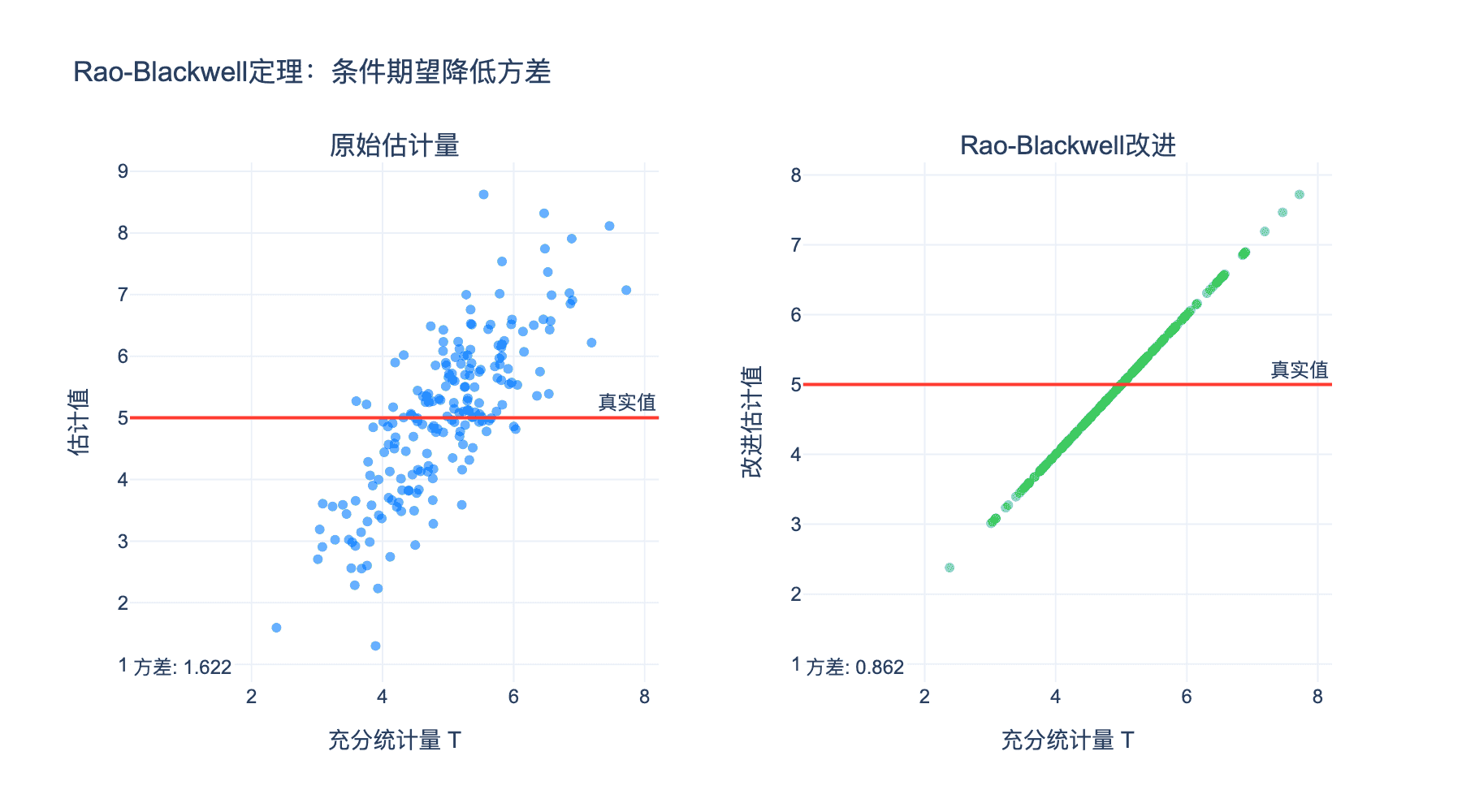
上图展示了 Rao-Blackwell 定理的效果:原始估计量(散点)通过对充分统计量取条件期望,得到更集中的改进估计量。
4.2 贝叶斯推断中的后验期望
在贝叶斯框架中,参数 $\theta$ 也被视为随机变量。给定观测数据 $X$,参数的后验分布为:
$$p(\theta \mid X) = \frac{p(X \mid \theta) \cdot p(\theta)}{p(X)}$$
贝叶斯估计通常使用后验期望:
$$\hat{\theta}_{\text{Bayes}} = E[\theta \mid X] = \int \theta \cdot p(\theta \mid X) , d\theta$$
这个估计量最小化后验期望平方损失,是贝叶斯决策理论中的最优估计。
4.3 缺失数据处理:EM 算法
期望最大化(EM)算法是处理缺失数据的重要工具。设观测数据为 $X$,缺失数据为 $Z$,完整数据为 $(X, Z)$。
EM 算法迭代执行两个步骤:
E 步(期望步):计算在给定当前参数估计 $\theta^{(t)}$ 下,完整数据对数似然的条件期望
$$Q(\theta \mid \theta^{(t)}) = E_{Z \mid X, \theta^{(t)}}[\log L(\theta; X, Z)]$$
M 步(最大化步):最大化 $Q$ 函数得到新的参数估计
$$\theta^{(t+1)} = \arg\max_{\theta} Q(\theta \mid \theta^{(t)})$$
EM 算法的核心正是条件期望——它通过对缺失变量取条件期望,将不完整数据问题转化为完整数据问题。
第五章:条件期望在机器学习中的应用
5.1 回归分析:学习条件期望
回归分析的核心目标是学习条件期望函数 $E[Y \mid X = x]$。
线性回归假设:
$$E[Y \mid X = x] = \beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p$$
最小二乘估计等价于最小化经验均方误差:
$$\hat{\beta} = \arg\min_{\beta} \sum_{i=1}^n (y_i - \beta^T x_i)^2$$
非参数回归(如核回归、样条回归)不假设函数形式,直接估计条件期望:
$$\hat{E}[Y \mid X = x] = \frac{\sum_{i=1}^n K_h(x - x_i) y_i}{\sum_{i=1}^n K_h(x - x_i)}$$
其中 $K_h$ 是核函数。这是 Nadaraya-Watson 核回归估计量,本质上是局部加权平均。
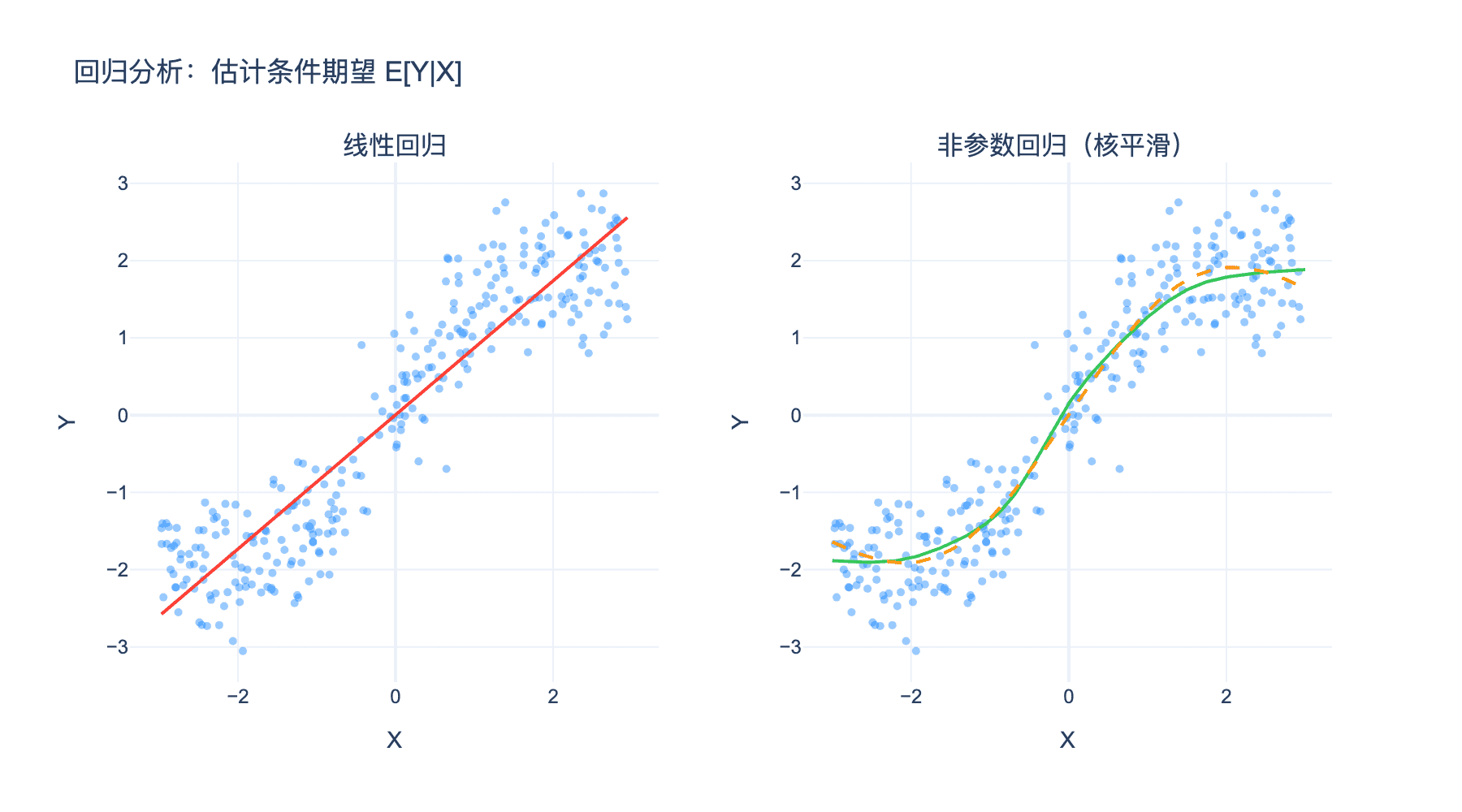
上图展示了回归的本质:左图是线性回归拟合的条件期望,右图是非参数回归(核平滑)对复杂条件期望函数的估计。
5.2 高斯过程回归
高斯过程(Gaussian Process, GP)是定义在函数空间上的概率分布。GP 回归不仅给出条件期望预测,还给出预测的不确定性。
给定训练数据 $(X, y)$,对新输入 $x_{\ast}$ 的预测为:
$$f_{\ast} \mid X, y, x_{\ast} \sim \mathcal{N}(\mu_{\ast}, \sigma_{\ast}^2)$$
其中:
$$\mu_{\ast} = E[f_{\ast} \mid X, y, x_{\ast}] = k_{\ast}^T K^{-1} y$$
这里 $k_{\ast}$ 是新点与训练点的协方差向量,$K$ 是训练点的核矩阵。
GP 回归的条件期望形式优雅地结合了先验知识和观测数据,是贝叶斯非参数方法的代表。
5.3 集成学习与条件期望
随机森林和梯度提升树等集成方法也可以从条件期望的角度理解。
在随机森林中,每棵树给出预测 $\hat{f}_b(x)$,最终预测是它们的平均:
$$\hat{f}(x) = \frac{1}{B} \sum_{b=1}^B \hat{f}_b(x)$$
这可以看作是对 Bootstrap 样本取条件期望的蒙特卡洛近似。
梯度提升则通过迭代拟合残差(当前预测与真实值之差)来学习条件期望:
$$F_{m}(x) = F_{m-1}(x) + \eta \cdot E[Y - F_{m-1}(X) \mid X = x]$$
其中 $\eta$ 是学习率。每一轮都在估计给定当前模型的条件下,残差的条件期望。
第六章:条件期望在深度学习中的应用
6.1 变分自编码器(VAE)
变分自编码器是深度生成模型的里程碑。VAE 的核心是变分推断,它通过优化证据下界(ELBO)来学习:
$$\text{ELBO} = E_{q_{\phi}(z \mid x)}[\log p_{\theta}(x \mid z)] - D_{\text{KL}}(q_{\phi}(z \mid x) , | , p(z))$$
第一项是重构项,它是条件对数似然的期望:
$$E_{q_{\phi}(z \mid x)}[\log p_{\theta}(x \mid z)] = \int \log p_{\theta}(x \mid z) \cdot q_{\phi}(z \mid x) , dz$$
这正是在变分分布 $q_{\phi}(z \mid x)$ 下的条件期望。
VAE 的编码器 $q_{\phi}(z \mid x)$ 学习后验分布的近似,而解码器 $p_{\theta}(x \mid z)$ 定义了条件期望 $E[x \mid z]$。
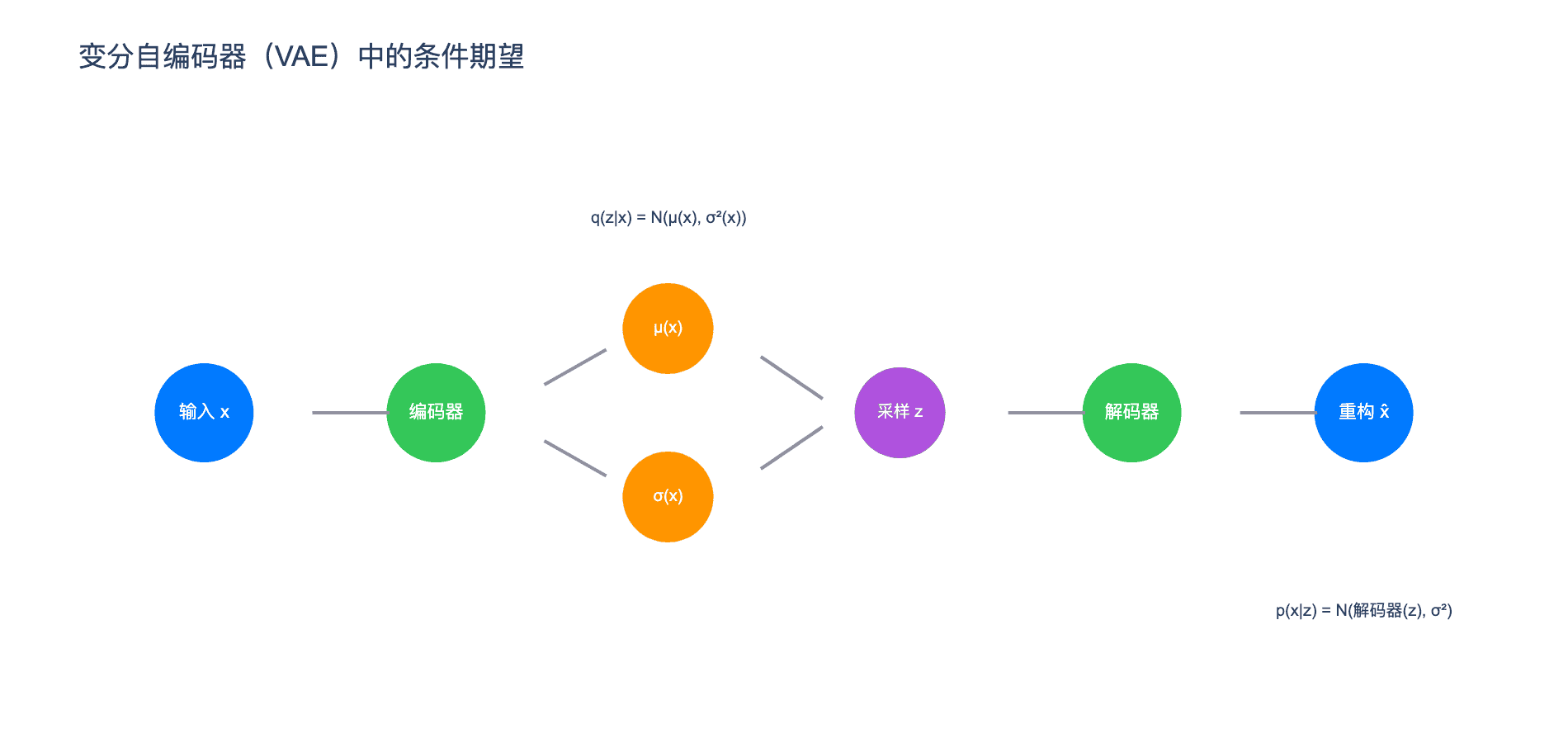
上图展示了 VAE 的结构:编码器输出变分分布 $q(z \mid x)$(条件期望的参数),解码器重构输入(条件期望本身)。
6.2 注意力机制:软条件选择
注意力机制可以看作是软条件期望。
给定查询 $q$ 和一组键值对 ${(k_i, v_i)}_{i=1}^n$,注意力输出为:
$$\text{Attention}(q, K, V) = \sum_{i=1}^n \text{softmax}\left(\frac{q^T k_i}{\sqrt{d_k}}\right) v_i$$
这可以重写为:
$$\text{Attention}(q, K, V) = E_{i \sim p(i \mid q)}[v_i]$$
其中 $p(i \mid q) \propto \exp(q^T k_i / \sqrt{d_k})$ 是在给定查询 $q$ 下对位置 $i$ 的分布。
因此,注意力机制计算的是以注意力权重为条件的值向量的条件期望。
6.3 扩散模型:逆过程的条件期望
扩散模型(如 DDPM)通过逆转前向加噪过程来生成数据。
给定前向过程中加噪的样本 $x_t$,逆过程学习从 $x_t$ 预测 $x_{t-1}$。最优预测是条件期望:
$$\mu_{\theta}(x_t, t) \approx E[x_{t-1} \mid x_t]$$
或者等价地,预测噪声:
$$\epsilon_{\theta}(x_t, t) \approx E[\epsilon \mid x_t]$$
扩散模型的训练目标正是最小化预测噪声与真实噪声之间的均方误差——这正是条件期望的最优性的直接应用。
6.4 强化学习中的值函数
在强化学习中,值函数是条件期望的核心应用。
状态值函数:
$$V^{\pi}(s) = E_{\pi}\left[\sum_{t=0}^{\infty} \gamma^t r_{t+1} , \middle| , S_0 = s\right]$$
这是在策略 $\pi$ 下,从状态 $s$ 开始的期望累积回报。
动作值函数:
$$Q^{\pi}(s, a) = E_{\pi}\left[\sum_{t=0}^{\infty} \gamma^t r_{t+1} , \middle| , S_0 = s, A_0 = a\right]$$
这是在策略 $\pi$ 下,从状态 $s$ 执行动作 $a$ 后的期望累积回报。
深度 Q 网络(DQN)使用神经网络来近似这个条件期望:
$$Q^{\pi}(s, a) \approx Q_{\theta}(s, a)$$
通过最小化贝尔曼误差来学习:
$$\min_{\theta} E[(r + \gamma \max_{a’} Q_{\theta}(s’, a’) - Q_{\theta}(s, a))^2]$$
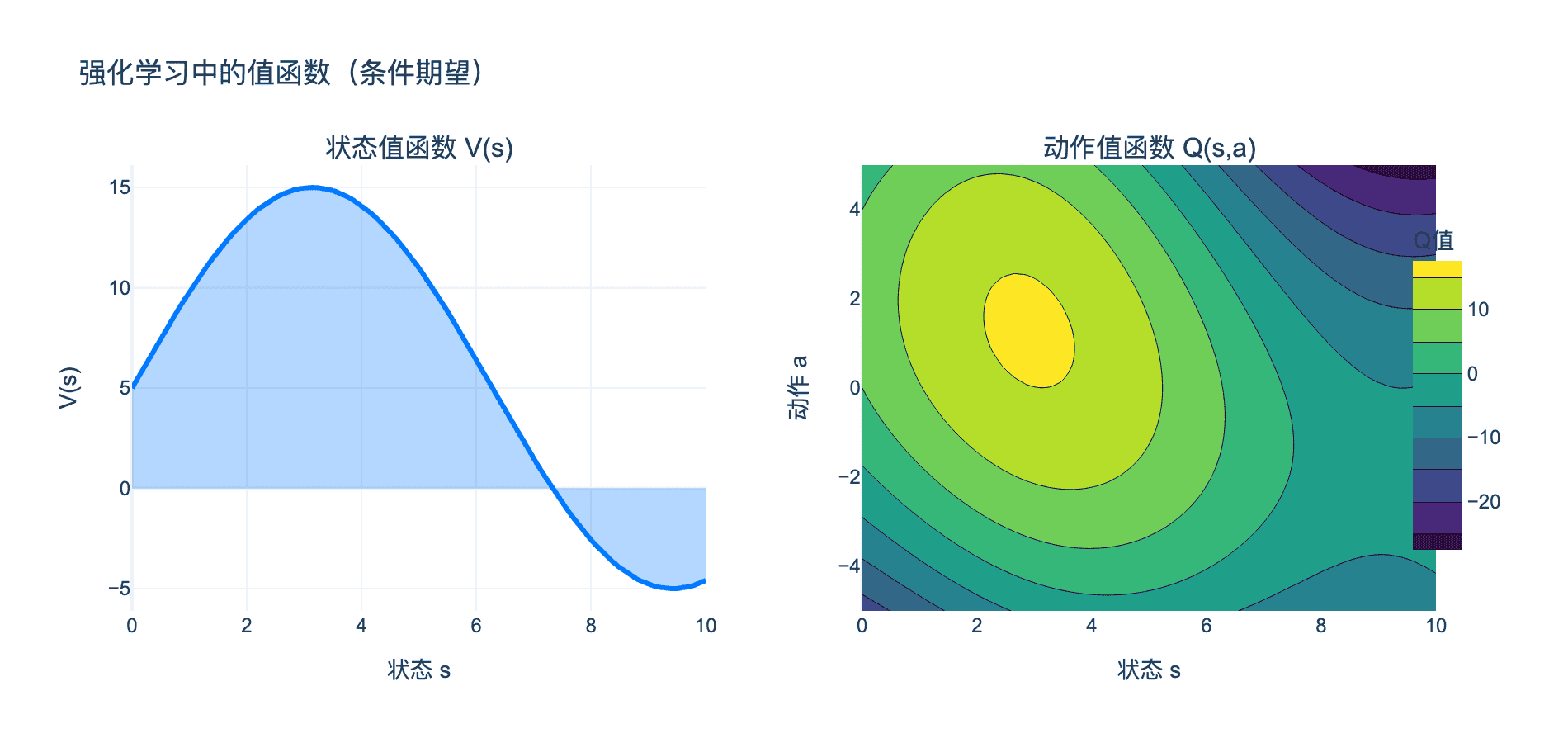
上图展示了强化学习中的值函数:左图是状态值函数 $V(s)$(给定状态的条件期望),右图是动作值函数 $Q(s, a)$(给定状态和动作的条件期望)。
第七章:条件期望的估计方法
7.1 蒙特卡洛估计
当条件期望无法解析计算时,蒙特卡洛方法提供了通用的近似方案:
$$E[Y \mid X = x] \approx \frac{1}{n} \sum_{i=1}^n y_i$$
其中 $(x_i, y_i)$ 是满足 $x_i \approx x$ 的样本,或者是从条件分布 $Y \mid X = x$ 中抽取的样本。
重要性采样:
若无法直接从 $Y \mid X = x$ 采样,可以从提议分布 $q$ 采样并加权:
$$E[Y \mid X = x] = \int y \cdot \frac{p(y \mid x)}{q(y)} q(y) , dy \approx \frac{1}{n} \sum_{i=1}^n y_i \cdot \frac{p(y_i \mid x)}{q(y_i)}$$
7.2 变分推断中的证据下界
在变分推断中,我们需要计算对数边际似然的期望:
$$\log p(x) = \log E_{z}[p(x \mid z)]$$
直接计算困难,我们转而优化 ELBO:
$$\text{ELBO} = E_{q(z)}[\log p(x \mid z)] - D_{\text{KL}}(q(z) , | , p(z))$$
第一项是条件对数似然的变分期望,通过蒙特卡洛采样和重参数化技巧来估计。
7.3 神经网络的函数近似
深度神经网络可以看作是通用函数逼近器,用于学习复杂的条件期望:
$$f_{\theta}(x) \approx E[Y \mid X = x]$$
通过反向传播和梯度下降,网络学习最小化经验损失:
$$\min_{\theta} \frac{1}{n} \sum_{i=1}^n \ell(y_i, f_{\theta}(x_i))$$
当损失函数为平方损失时,最优解就是条件期望。
结语:条件期望的普适之美
从19世纪皮尔逊的回归分析,到20世纪柯尔莫哥洛夫的公理化理论,再到21世纪的深度学习,条件期望始终是概率统计的核心概念。它提供了一个统一的框架:
在已知信息的条件下,如何做出最优的预测和决策。
让我们回顾本文的核心要点:
数学基础:条件期望是在给定信息下的最优均方预测,具有线性性、全期望公式、方差分解等关键性质。
统计应用:从 Rao-Blackwell 定理到贝叶斯推断,从 EM 算法到充分统计量,条件期望提供了强大的理论工具。
机器学习:回归分析本质上是在学习条件期望;高斯过程提供了概率化的条件期望估计;集成方法从多个角度逼近条件期望。
深度学习:VAE 通过变分推断学习潜在变量的条件期望;注意力机制计算软条件期望;扩散模型逆转加噪过程的条件期望;强化学习的值函数是累积回报的条件期望。
条件期望的普适性源于一个基本事实:在不确定性中进行推断和决策,是人类智能和人工智能共同面临的核心问题。而条件期望,正是这个问题的数学答案。
正如柯尔莫哥洛夫在建立概率论公理体系时所展现的深刻洞察,最简单的数学概念往往蕴含着最广泛的应用。条件期望,这个看似简单的"给定信息下的平均",实则是连接统计推断、机器学习与人工智能的数学桥梁。
延伸阅读:
- Kolmogorov, A.N. (1933). Foundations of the Theory of Probability.
- Williams, D. (1991). Probability with Martingales. Cambridge University Press.
- Durrett, R. (2019). Probability: Theory and Examples. Cambridge University Press.
- Murphy, K.P. (2022). Probabilistic Machine Learning: An Introduction. MIT Press.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
学习路径建议:
- 基础阶段:掌握离散和连续情形下条件期望的计算,理解全期望公式和方差分解
- 进阶阶段:学习测度论视角的条件期望,理解其在统计推断中的应用(Rao-Blackwell、EM 算法)
- 应用阶段:将条件期望与机器学习算法联系起来,理解回归、VAE、注意力机制背后的条件期望原理
- 深入阶段:研究信息几何、变分推断、强化学习中条件期望的进阶应用
愿你在概率与期望的数学世界中,发现推断与预测的深刻之美。