
引言
在统计学的世界里,我们面临一个永恒的问题:给定一组观测数据,如何尽可能准确地估计某个未知参数?无论是估计一个物理常数、预测股票价格,还是训练机器学习模型,我们都需要回答这个问题。
假设你是一位实验物理学家,正在测量电子的电荷量。你进行了 $n$ 次独立实验,得到数据 $x_1, x_2, \ldots, x_n$。你计算了样本均值 $\bar{x}$ 作为电荷量的估计。但一个自然的问题浮现在脑海:这个估计有多好?它的精度能否进一步提高?是否存在一个理论极限,无论如何改进实验方法都无法超越?
1945年和1946年,两位瑞典统计学家哈拉尔德·克拉默(Harald Cramér)和卡利安普迪·拉奥(Calyampudi Radhakrishna Rao)独立地给出了这个问题的答案。他们证明了一个深刻的定理:任何无偏估计量的方差都有一个下界,这个下界由Fisher信息量决定。这就是著名的Cramér-Rao下界(Cramér-Rao Lower Bound,简称CRLB)。
CRLB不仅是理论统计学的基石,更在现代机器学习、信号处理、计量经济学等领域有着广泛应用。它告诉我们:
- 什么时候一个估计量是"最优"的?
- 给定数据集,我们能期望达到的最好精度是多少?
- 如何设计实验以最大化信息量?
本文将深入浅出地介绍Cramér-Rao下界的完整理论体系,从历史背景到严格推导,从直观理解到实际应用,带你领略这一数理统计重要定理的深刻魅力。
第一章:参数估计的基础问题
1.1 估计量的评价标准
在统计学中,参数估计(parameter estimation)的核心任务是:给定来自某个概率分布的样本,推断该分布的未知参数。设 $X_1, X_2, \ldots, X_n$ 是独立同分布(i.i.d.)的随机变量,其概率密度函数为 $f(x; \theta)$,其中 $\theta \in \Theta$ 是待估计的未知参数。
估计量(estimator)是样本的函数 $\hat{\theta} = \hat{\theta}(X_1, \ldots, X_n)$,用于估计 $\theta$。评价一个估计量的好坏,我们需要以下标准:
无偏性(Unbiasedness):估计量的期望等于真实参数值
$$ \mathbb{E}[\hat{\theta}] = \theta $$
如果 $\mathbb{E}[\hat{\theta}] \neq \theta$,称估计量是有偏的,偏差为 $\text{Bias}(\hat{\theta}) = \mathbb{E}[\hat{\theta}] - \theta$。
有效性(Efficiency):在无偏估计量中,方差越小越有效
$$ \text{Var}(\hat{\theta}) = \mathbb{E}[(\hat{\theta} - \mathbb{E}[\hat{\theta}])^2] $$
均方误差(Mean Squared Error,MSE):综合考虑偏差和方差
$$ \text{MSE}(\hat{\theta}) = \mathbb{E}[(\hat{\theta} - \theta)^2] = \text{Var}(\hat{\theta}) + [\text{Bias}(\hat{\theta})]^2 $$
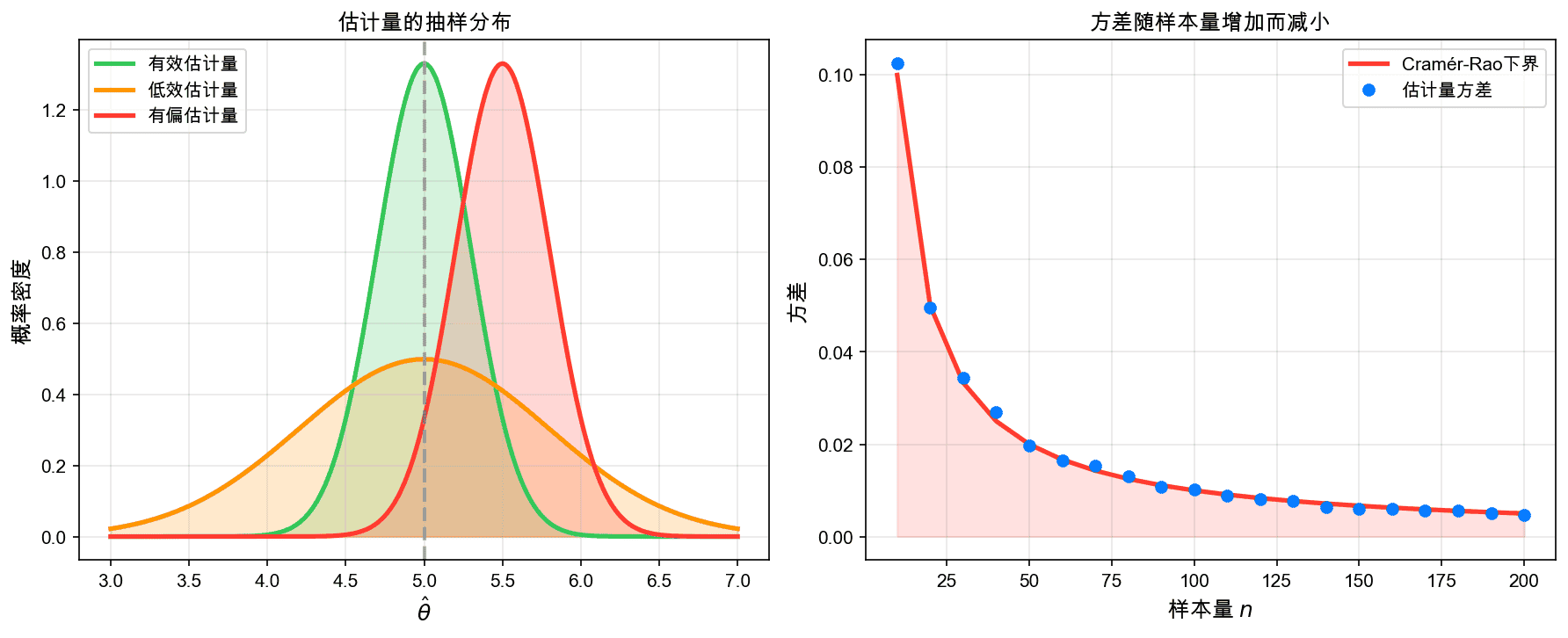
上图展示了不同类型的估计量的抽样分布。有效估计量(绿色)方差小且中心位于真值;低效估计量(橙色)虽然无偏但方差大;有偏估计量(红色)虽然方差小但存在系统性偏差。
1.2 一致性与渐近理论
随着样本量 $n \to \infty$,我们希望估计量能收敛到真值。这就是一致性(consistency):
$$ \hat{\theta}_n \xrightarrow{P} \theta \quad \text{或} \quad \hat{\theta}_n \xrightarrow{a.s.} \theta $$
但一致性只保证大样本时的收敛,不告诉我们有限样本下的精度。这就引出了一个更精细的问题:对于有限样本 $n$,估计量的方差可以有多小?
直觉告诉我们:
- 样本量越大,信息越多,方差应该越小
- 数据质量越高(噪声越小),估计应该越精确
- 参数本身的"可识别性"会影响估计难度
Cramér-Rao下界正是对这些直觉的严格数学表述。
第二章:Fisher信息——数据的"信息量"
2.1 似然函数与对数似然
要理解Cramér-Rao下界,首先需要理解Fisher信息(Fisher Information)。这是统计学中最重要的概念之一,量化了数据包含的关于参数的信息。
给定样本 $X_1, \ldots, X_n$ 和参数 $\theta$,似然函数(likelihood function)定义为:
$$ L(\theta; x_1, \ldots, x_n) = \prod_{i=1}^n f(x_i; \theta) $$
由于连乘运算不方便,我们通常使用对数似然函数:
$$ \ell(\theta) = \log L(\theta) = \sum_{i=1}^n \log f(x_i; \theta) $$
最大似然估计(Maximum Likelihood Estimation,MLE)就是寻找使似然函数(或对数似然)最大的参数值:
$$ \hat{\theta}{\text{MLE}} = \arg\max{\theta} \ell(\theta) $$
2.2 得分函数
对数似然函数关于参数的导数称为得分函数(score function):
$$ S(\theta) = \frac{\partial \ell(\theta)}{\partial \theta} = \sum_{i=1}^n \frac{\partial \log f(x_i; \theta)}{\partial \theta} $$
得分函数有一个重要性质:在真实参数 $\theta_0$ 处,其期望为零:
证明:
$$ \begin{align} \mathbb{E}\left[\frac{\partial \log f(X; \theta)}{\partial \theta}\right] &= \int \frac{\partial \log f(x; \theta)}{\partial \theta} f(x; \theta) , dx \ &= \int \frac{1}{f(x; \theta)} \frac{\partial f(x; \theta)}{\partial \theta} f(x; \theta) , dx \ &= \int \frac{\partial f(x; \theta)}{\partial \theta} , dx \ &= \frac{\partial}{\partial \theta} \int f(x; \theta) , dx = \frac{\partial}{\partial \theta}(1) = 0 \end{align} $$
2.3 Fisher信息的定义
Fisher信息(Fisher Information)定义为得分函数的方差:
对于i.i.d.样本,由于 $\ell(\theta) = \sum_{i=1}^n \log f(x_i; \theta)$,有:
其中 $\mathcal{I}_1(\theta)$ 是单样本的Fisher信息。这说明:样本量越大,Fisher信息越大,且呈线性增长。
在正则条件下,Fisher信息还有另一种等价形式:
这个公式揭示了一个直观的几何解释:Fisher信息等于对数似然函数曲率的期望(取负号)。
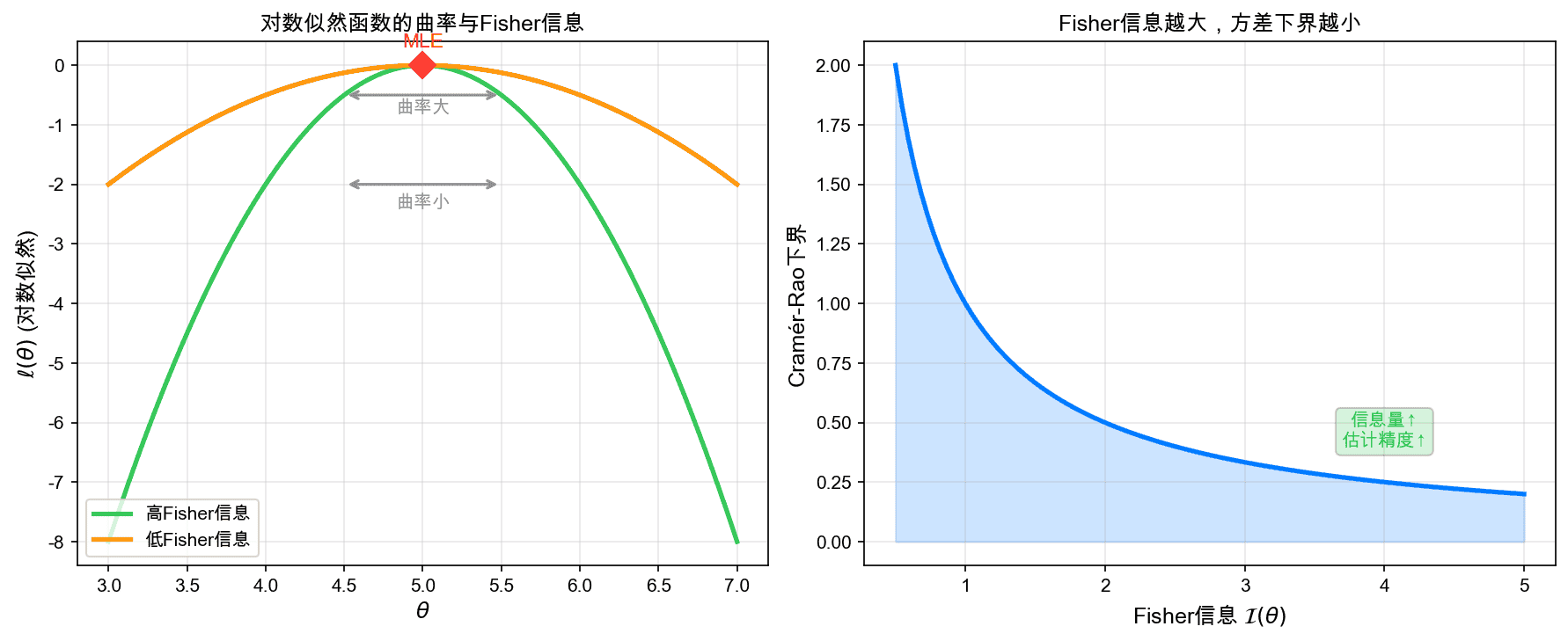
左图展示了对数似然函数的曲率。曲率越大(绿色曲线),函数在最大值附近越"尖锐",参数越容易被精确估计;曲率越小(橙色曲线),函数越"平坦",估计越困难。右图展示了Fisher信息与方差下界的反比关系。
2.4 Fisher信息的直观理解
Fisher信息可以用多种方式理解:
曲率解释:对数似然函数在MLE附近的曲率越大,数据对参数的"约束力"越强,估计越精确。
敏感性解释:Fisher信息度量了概率分布 $f(x; \theta)$ 对参数 $\theta$ 变化的敏感程度。如果分布随参数变化剧烈,不同参数值产生的数据明显不同,则参数容易被识别。
熵的解释:Fisher信息与统计流形上的度量相关,可以看作参数空间的"度量张量"。
例子:正态分布 $N(\mu, \sigma^2)$ 的均值估计
对数似然:$\log f(x; \mu) = -\frac{1}{2}\log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}$
得分函数:$\frac{\partial \log f}{\partial \mu} = \frac{x - \mu}{\sigma^2}$
Fisher信息:
这表明:方差越小,Fisher信息越大,均值估计越精确。这符合直觉:数据越集中,均值越容易确定。
第三章:Cramér-Rao下界的严格推导
3.1 定理的陈述
Cramér-Rao下界定理:设 $X_1, \ldots, X_n$ 是来自分布 $f(x; \theta)$ 的i.i.d.样本,$\hat{\theta}$ 是 $\theta$ 的任意无偏估计量。在一定的正则条件下:
等号成立当且仅当:
此时 $\hat{\theta}$ 是有效估计量(efficient estimator)。
3.2 证明思路
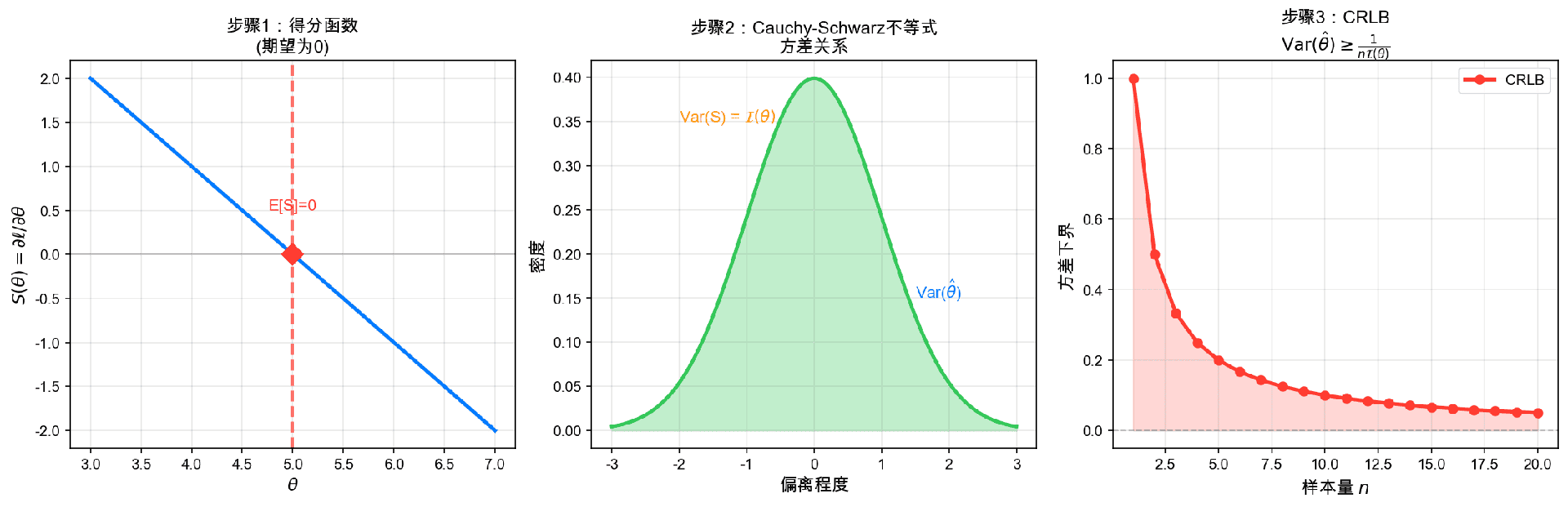
CRLB的证明核心工具是Cauchy-Schwarz不等式。我们将证明估计量 $\hat{\theta}$ 与得分函数 $S(\theta)$ 的协方差满足特定关系。
步骤1:计算协方差
由于 $\hat{\theta}$ 无偏,$\mathbb{E}[\hat{\theta}] = \theta$。
利用 $\frac{\partial \ell}{\partial \theta} = \frac{1}{L(\theta)} \frac{\partial L}{\partial \theta}$:
因此:$\text{Cov}(\hat{\theta}, S(\theta)) = 1$
步骤2:应用Cauchy-Schwarz不等式
由Cauchy-Schwarz不等式:
代入:
因此:
这就是Cramér-Rao下界。
3.3 等号成立的条件
Cauchy-Schwarz不等式等号成立当且仅当 $X$ 和 $Y$ 线性相关,即存在常数 $a, b$ 使得 $Y = aX + b$(几乎处处)。
应用到CRLB:$S(\theta) = a \hat{\theta} + b$
由 $\mathbb{E}[S(\theta)] = 0$ 和 $\mathbb{E}[\hat{\theta}] = \theta$:
因此:$S(\theta) = a(\hat{\theta} - \theta)$
由 $\text{Var}(S(\theta)) = a^2 \text{Var}(\hat{\theta}) = \mathcal{I}(\theta)$ 和 CRLB:
因此等号成立条件为:
3.4 有偏估计量的推广
对于一般的有偏估计量,设 $b(\theta) = \mathbb{E}[\hat{\theta}] - \theta$ 为偏差,推广的CRLB为:
当偏差为常数($b’(\theta) = 0$)时,如果 $b \neq 0$,下界反而比无偏情况更小。这说明有偏估计量可能具有更小的方差,这也是偏差-方差权衡的理论基础。
第四章:多元参数与Fisher信息矩阵
4.1 多元参数估计
当参数是向量 $\theta = (\theta_1, \ldots, \theta_p)^T$ 时,Fisher信息推广为Fisher信息矩阵(Fisher Information Matrix):
4.2 多元CRLB
对于任意无偏估计量 $\hat{\theta}$,其协方差矩阵满足:
其中 “$\succeq$” 表示矩阵的Löwner序,即 $\text{Cov}(\hat{\theta}) - \mathcal{I}(\theta)^{-1}$ 是半正定矩阵。
特别地,对于每个分量:
4.3 参数相关的复杂性
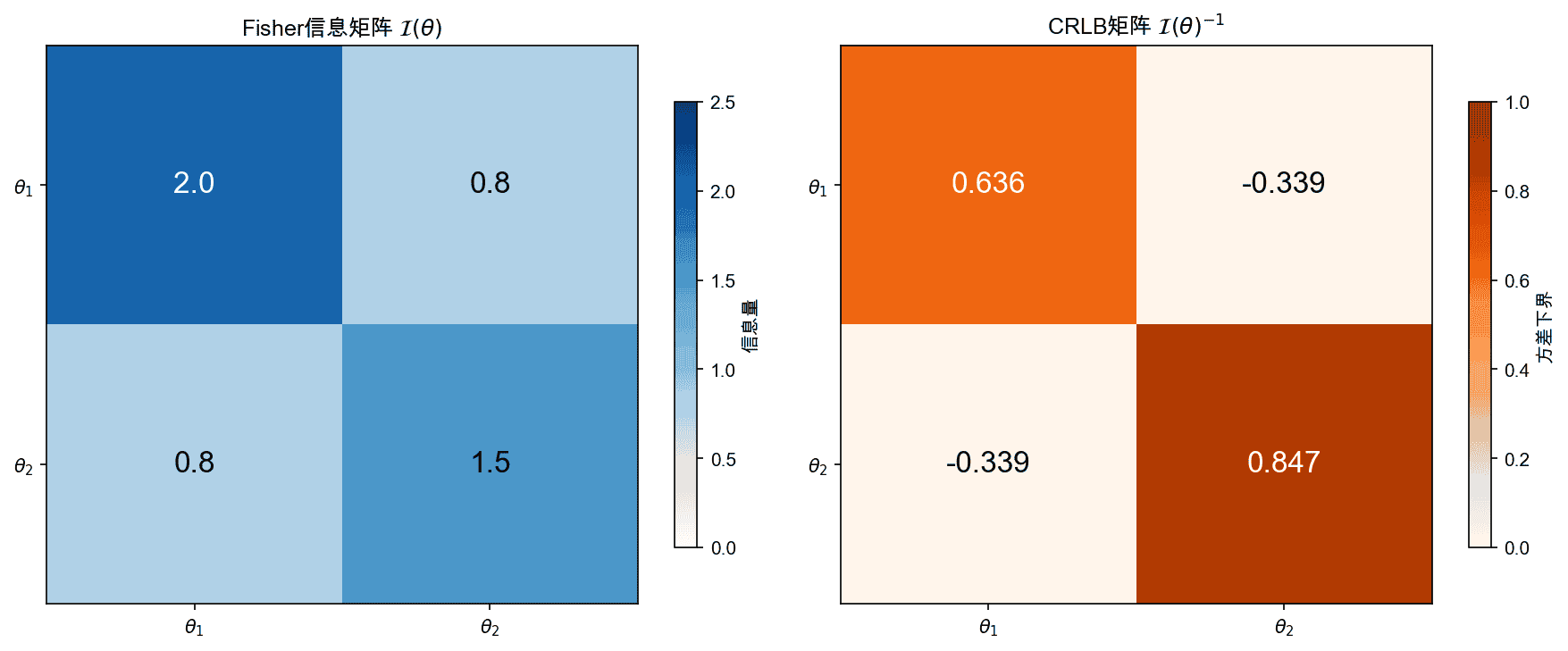
当参数相关时(Fisher信息矩阵非对角),一个有趣的 phenomenon 出现:联合估计的方差下界可能小于单独估计时的下界。这是因为参数之间的相关性提供了额外信息。
例如,对于二维参数,即使 $\mathcal{I}(\theta){11}$ 和 $\mathcal{I}(\theta){22}$ 固定,非对角元 $\mathcal{I}(\theta)_{12}$ 的变化会影响逆矩阵的对角元,从而改变CRLB。
第五章:应用与实例
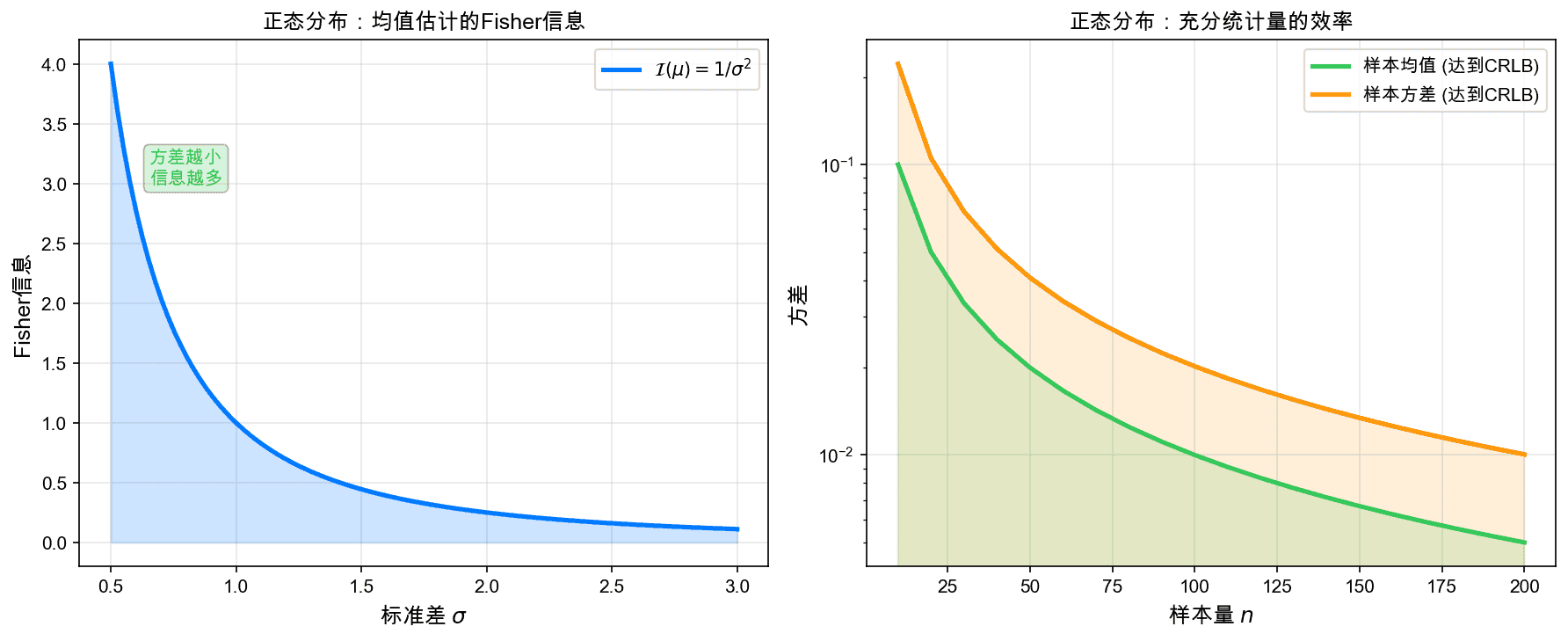
5.1 正态分布的例子
例1:估计均值(方差已知)
设 $X_1, \ldots, X_n \sim N(\mu, \sigma^2)$,$\sigma^2$ 已知。前面已计算:
因此CRLB为:
样本均值 $\bar{X} = \frac{1}{n}\sum_{i=1}^n X_i$ 的方差正好是 $\frac{\sigma^2}{n}$,因此样本均值是有效估计量。
例2:估计方差(均值已知)
设 $\mu = 0$ 已知,估计 $\sigma^2$。对数似然:
计算Fisher信息:
CRLB为:
估计量 $\widehat{\sigma^2} = \frac{1}{n}\sum_{i=1}^n X_i^2$ 的方差正好是 $\frac{2\sigma^4}{n}$,因此也是有效的。
5.2 指数分布的例子
设 $X_1, \ldots, X_n \sim \text{Exp}(\lambda)$,密度 $f(x; \lambda) = \lambda e^{-\lambda x}$,$x > 0$。
对数似然:
得分函数:
Fisher信息:
CRLB:
MLE为 $\hat{\lambda} = \frac{n}{\sum_{i=1}^n X_i} = \frac{1}{\bar{X}}$。由于这是非线性变换,它是有偏的,但渐近无偏且渐近达到CRLB。
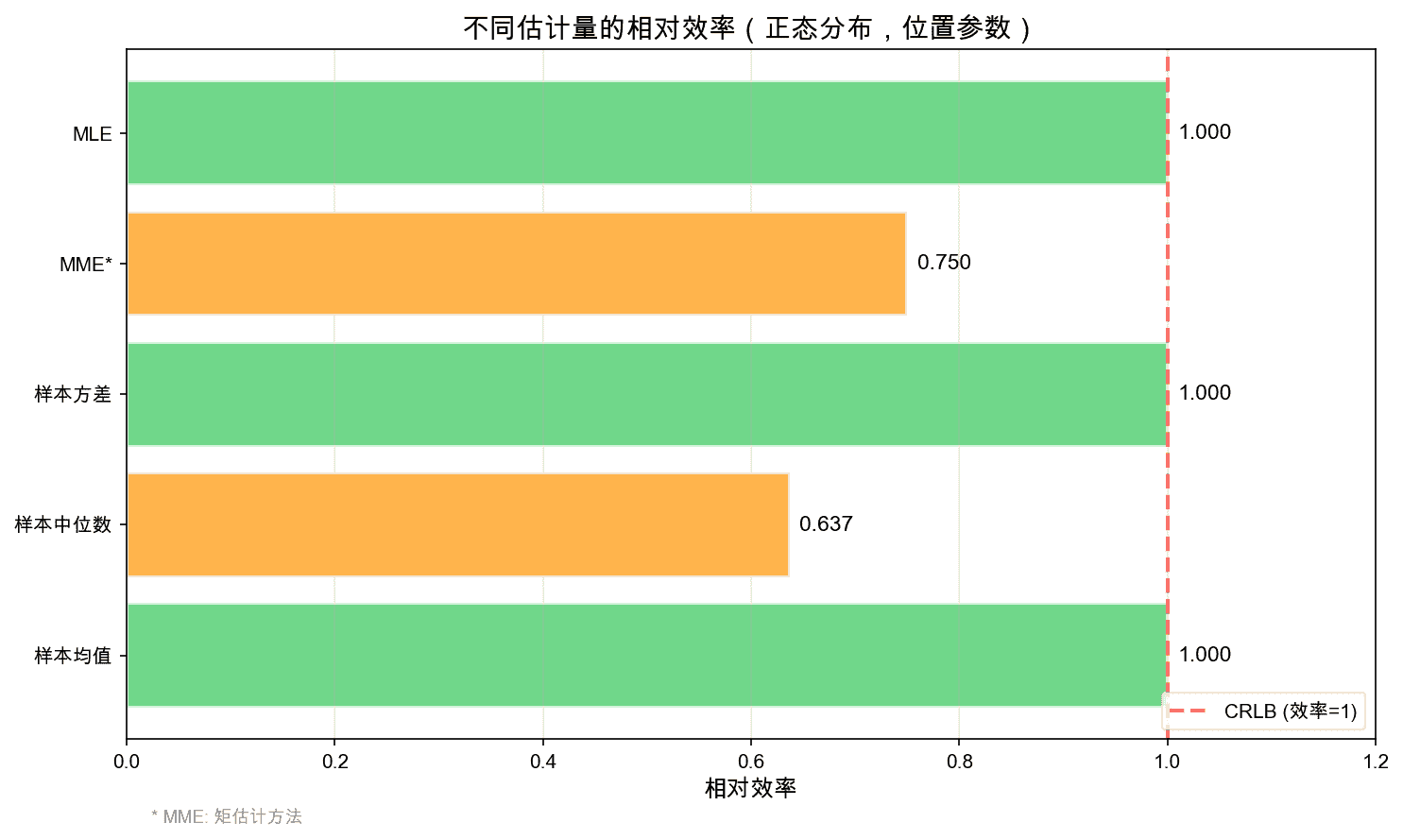
5.3 估计量的效率比较
相对效率(Relative Efficiency)定义为:
效率为1的估计量称为有效估计量(efficient estimator)。
在正态分布的位置参数估计中:
- 样本均值:效率 = 1(有效)
- 样本中位数:效率 = $\frac{2}{\pi} \approx 0.637$
这说明样本均值比中位数更有效地利用了数据信息。
第六章:与充分统计量和Rao-Blackwell定理的联系
6.1 充分统计量
充分统计量(Sufficient Statistic)包含了样本中关于参数的全部信息。形式上,$T(X)$ 是充分的,如果条件分布 $X \mid T(X)$ 不依赖于 $\theta$。
因子分解定理:$T(X)$ 是充分的当且仅当:
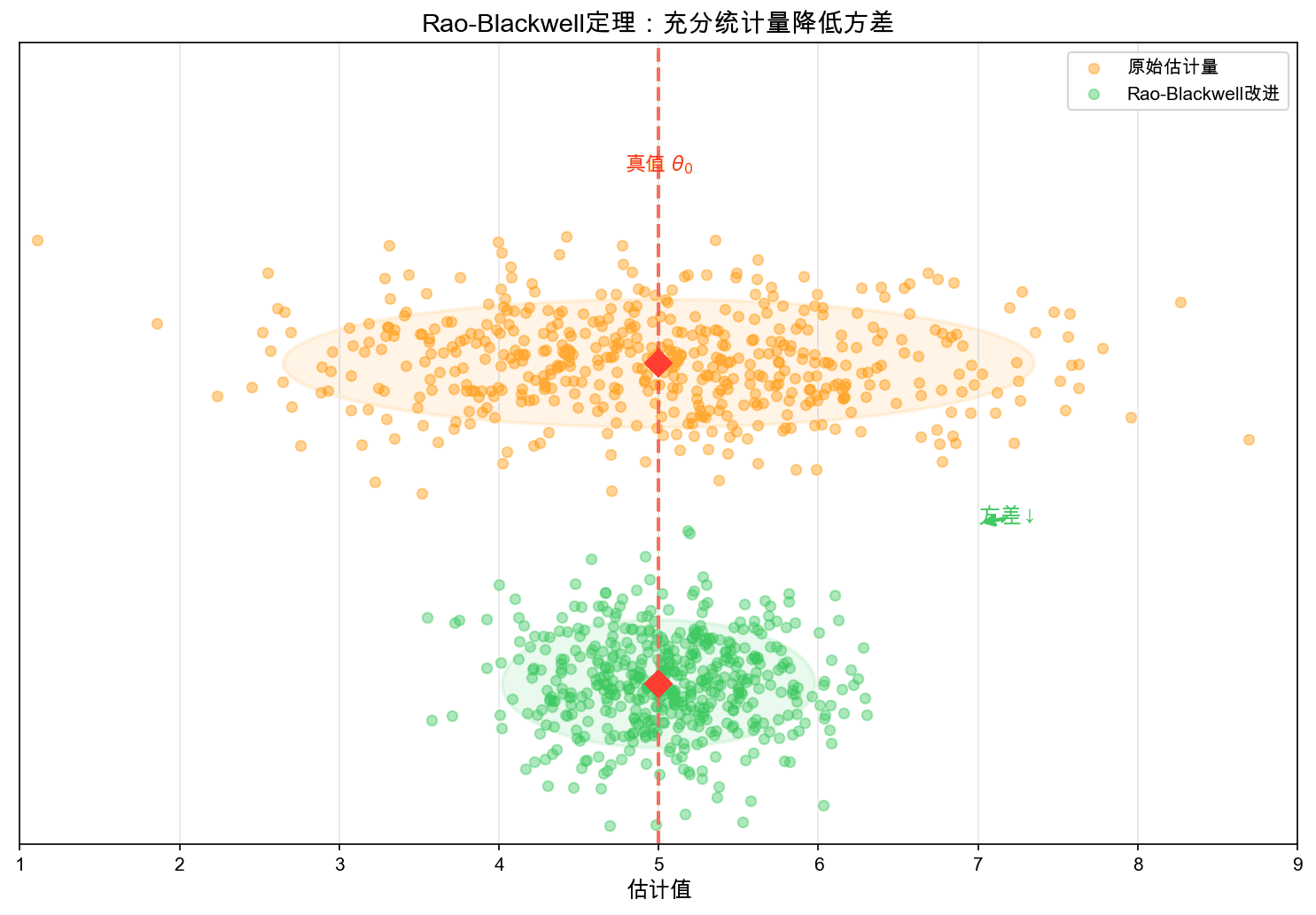
6.2 Rao-Blackwell定理
Rao-Blackwell定理:设 $\tilde{\theta}$ 是 $\theta$ 的任意无偏估计,$T$ 是充分统计量。定义:
则 $\hat{\theta}$ 也是无偏的,且 $\text{Var}(\hat{\theta}) \leq \text{Var}(\tilde{\theta})$。
这说明:对充分统计量进行条件期望可以降低方差。
6.3 完备性与Lehmann-Scheffé定理
完备统计量(Complete Statistic)是指:如果对所有的 $\theta$ 都有 $\mathbb{E}[g(T)] = 0$,则 $g(T) = 0$ 几乎处处成立。
Lehmann-Scheffé定理:如果 $T$ 是完备充分统计量,则 $\mathbb{E}[\tilde{\theta} \mid T]$ 是唯一的最小方差无偏估计量(UMVUE),且达到CRLB(如果存在有效估计量)。
这给出了寻找最优估计量的系统方法:
- 找到完备充分统计量 $T$
- 构造任意无偏估计 $\tilde{\theta}$
- 计算 $\hat{\theta} = \mathbb{E}[\tilde{\theta} \mid T]$,这就是UMVUE
第七章:现代应用与扩展
7.1 在机器学习中的应用
在机器学习理论中,CRLB有多个重要应用:
样本复杂度分析:CRLB给出了参数估计的最小方差,从而可以推导达到特定精度所需的样本量下界。
主动学习:通过最大化Fisher信息,可以设计最优的采样策略,在有限标注预算下最大化模型性能。
神经网络的可学习性:在神经网络的理论分析中,Fisher信息矩阵被用来研究参数空间的局部几何结构,以及梯度下降的收敛性。
7.2 贝叶斯Cramér-Rao下界
在贝叶斯框架下,参数 $\theta$ 也有先验分布。此时有Van Trees不等式(贝叶斯CRLB):
其中 $\mathcal{I}(\pi)$ 是先验分布的信息。
7.3 量子Cramér-Rao下界
在量子参数估计中,经典CRLB被推广为量子Cramér-Rao下界:
其中 $\mathcal{F}_Q$ 是量子Fisher信息,与量子态的Bures度量相关。这在量子计量学中有重要应用,如引力波探测中的干涉仪设计。
结语
Cramér-Rao下界是数理统计学中最优美的定理之一。它告诉我们:在给定数据的情况下,参数估计的精度存在不可逾越的理论极限,这个极限由数据的Fisher信息决定。
从克拉默和拉奥在1940年代的开创性工作,到现代在机器学习、量子计算等领域的广泛应用,CRLB始终是统计推断理论的基石。它不仅是一个数学结果,更是一种思维方式:用信息量的视角理解统计估计的本质。
让我们回顾本文的核心要点:
Fisher信息量化了数据包含的关于参数的信息,由对数似然函数的曲率决定。
Cramér-Rao下界给出了任何无偏估计量的方差下界:$\text{Var}(\hat{\theta}) \geq \frac{1}{\mathcal{I}(\theta)}$。
有效估计量达到CRLB,样本均值在正态分布下是有效的典型例子。
充分统计量包含全部信息,Rao-Blackwell定理告诉我们如何利用它降低方差。
Lehmann-Scheffé定理给出了寻找最优估计量的系统方法。
CRLB的意义不仅在于提供了一个下界,更在于它建立了信息量与估计精度之间的深刻联系。当我们面对一个新的估计问题,CRLB告诉我们:最好的可能结果是什么?我们离最优还有多远?
正如拉奥本人所说:“统计学的美妙之处在于,它不仅能告诉我们什么是可能的,还能告诉我们什么是不可能的。“Cramér-Rao下界正是这种"不可能性"的完美体现。
定理证明练习:
证明泊松分布 $P(\lambda)$ 中,样本均值是 $\lambda$ 的有效估计量。
对于二项分布 $B(n, p)$,证明样本比例 $\hat{p} = X/n$ 的方差达到CRLB。
推导线性回归模型中最小二乘估计量的CRLB,并与实际方差比较。
延伸阅读:
- Cramér, H. (1946). Mathematical Methods of Statistics. Princeton University Press.
- Rao, C.R. (1945). Information and the accuracy attainable in the estimation of statistical parameters. Bulletin of the Calcutta Mathematical Society, 37, 81-91.
- Lehmann, E.L. & Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer.
- Kay, S.M. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice Hall.
学习路径建议:
- 基础阶段:理解似然函数、对数似然、得分函数的基本概念
- 进阶阶段:掌握Fisher信息的计算,能独立推导常见分布的CRLB
- 深入阶段:理解完备性、充分性,能应用Lehmann-Scheffé定理
- 拓展阶段:学习贝叶斯CRLB、量子CRLB等现代扩展
愿你在统计推断的数学世界中,体会到理论与应用交织的美妙。