
引言
1922年,一位英国统计学家发表了一篇划时代的论文,提出了一种度量数据"信息量"的全新方法。这位统计学家就是罗纳德·艾尔默·费希尔(Ronald Aylmer Fisher),而这种方法就是今天我们所熟知的Fisher信息(Fisher Information)。
在那个统计学尚处于萌芽时代的20世纪初,Fisher正在努力解决一个根本性问题:给定一组观测数据,我们能从中提取多少关于未知参数的信息?这个问题的答案不仅对参数估计的精度有直接影响,更揭示了统计学与微分几何之间深刻的内在联系。
Fisher信息的单参数版本我们已经熟知:它量化了数据关于单个参数的"敏感度",并直接决定了Cramér-Rao下界——任何无偏估计量的方差都不能低于Fisher信息的倒数。但当参数变为多个时,情况变得更加丰富和复杂。Fisher信息矩阵(Fisher Information Matrix)不仅描述了每个参数的信息量,还刻画了参数之间的相互关系和依赖性。
更令人惊讶的是,Fisher信息矩阵可以被理解为一种黎曼度量(Riemannian metric)。在由概率分布构成的统计流形上,Fisher信息矩阵定义了参数空间中的"距离"。这一发现开创了信息几何(Information Geometry)这一新兴学科,将微分几何的工具引入统计学,为理解统计推断提供了全新的视角。
本文将深入浅出地介绍Fisher信息矩阵的完整体系:从历史背景到严格定义,从统计解释到几何意义,从经典应用到现代机器学习。无论你是统计学研究者、机器学习工程师,还是对数学之美感兴趣的读者,相信都能从中获得深刻的洞见。
第一章:Fisher信息的历史与动机
1.1 费希尔与统计学的黄金时代
罗纳德·费希尔(1890-1962)被广泛认为是20世纪最伟大的统计学家之一。他的贡献遍布统计学的各个角落:最大似然估计、方差分析、实验设计、Fisher精确检验……而Fisher信息则是他最深刻的理论贡献之一。
1922年,费希尔发表了题为《On the Mathematical Foundations of Theoretical Statistics》的论文,系统地阐述了统计推断的理论框架。在这篇论文中,他提出了"信息"的概念,试图量化观测数据包含的关于未知参数的"知识量"。
费希尔的动机很直接:如果我们要比较两个不同的估计量,或者判断一个估计量是否"最优",就需要一个客观的标准。方差是一个自然的选择——方差越小,估计越精确。但方差本身并不能告诉我们:给定数据,最好的可能结果是什么?这就是Fisher信息要回答的问题。
1.2 从直观到形式化
让我们从直观开始。假设你有一枚可能有偏的硬币,正面朝上的概率是 $\theta$。你抛了100次,观察到60次正面。你如何估计 $\theta$?
如果硬币是公平的($\theta = 0.5$),观察到60次正面的概率是多少?如果 $\theta = 0.6$,这个概率又是多少?通过比较这些概率,我们可以判断哪个参数值更"可能"。
这就是似然(likelihood)的直观思想。Fisher的关键洞察是:对数似然函数在最大值附近的"尖锐程度",决定了我们估计参数的精度。函数越尖锐,不同参数值产生的数据越容易区分,估计就越准确。
如何量化"尖锐程度"?数学上,这就是曲率(curvature)。而对数似然函数的曲率,正是Fisher信息的核心。
1.3 单参数回顾
在深入多参数的Fisher信息矩阵之前,让我们快速回顾单参数情况。
设 $X_1, \ldots, X_n$ 是来自分布 $f(x; \theta)$ 的独立同分布样本,对数似然函数为:
得分函数(score function)是对数似然的导数:
Fisher信息定义为得分函数的方差:
在正则条件下,这等价于:
这就是曲率解释的来源:Fisher信息等于对数似然函数期望曲率的负值。
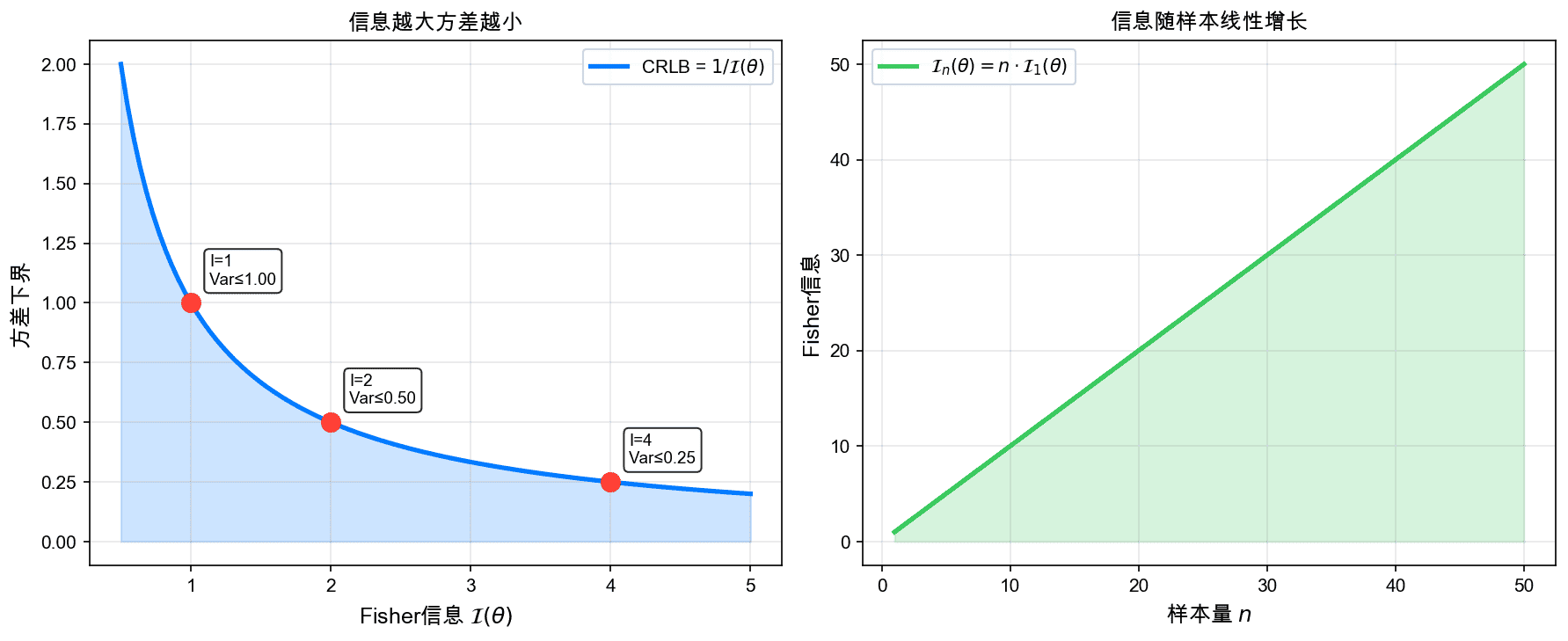
左图展示了Fisher信息与方差下界的反比关系:信息越大,方差下界越小。右图展示了Fisher信息随样本量线性增长的特点。
第二章:Fisher信息矩阵的定义与计算
2.1 多参数情形的挑战
当模型包含多个参数时,情况变得更加复杂。考虑一个简单的线性回归模型:
这里有三个参数:$\beta_0$(截距)、$\beta_1$(斜率)、$\sigma^2$(误差方差)。
单参数Fisher信息告诉我们每个参数单独的信息量,但它无法回答:
- 截距和斜率的估计是否相互影响?
- 如果一个参数估计不准,会如何影响另一个参数?
- 如何同时优化多个参数的估计?
这就需要Fisher信息矩阵(Fisher Information Matrix)。
2.2 正式定义
设 $\theta = (\theta_1, \ldots, \theta_p)^T$ 是 $p$ 维参数向量。对数似然函数 $\ell(\theta)$ 是 $\theta$ 的标量函数。
得分向量(score vector)是对数似然的梯度:
Fisher信息矩阵定义为得分向量的协方差矩阵:
其 $(i, j)$ 元素为:
2.3 基于二阶导数的等价形式
在正则条件下(积分与微分可交换),Fisher信息矩阵有另一种重要形式:
即Fisher信息矩阵等于对数似然函数Hessian矩阵期望的负值。
证明:
注意到:
取期望:
2.4 独立同分布样本的性质
对于i.i.d.样本,$\ell(\theta) = \sum_{k=1}^n \log f(X_k; \theta)$,因此:
即总Fisher信息矩阵等于样本量乘以单样本Fisher信息矩阵。这说明:
- Fisher信息随样本量线性增长
- 每个样本贡献相同的信息量
- 信息累积没有边际递减效应
第三章:几何解释与统计流形
3.1 统计流形的概念
考虑一个参数化的概率分布族 ${P_{\theta} : \theta \in \Theta}$。例如,正态分布族 $N(\mu, \sigma^2)$ 由两个参数 $(\mu, \sigma^2)$ 索引。
这个分布族可以看作一个统计流形(statistical manifold):每个点对应一个概率分布,参数空间提供了局部坐标。
关键问题:在这个流形上,如何定义"距离"?两个分布 $P_{\theta}$ 和 $P_{\theta + d\theta}$ 有多"接近"?
3.2 Fisher信息作为黎曼度量
答案由Fisher信息矩阵给出。在统计流形上,Fisher信息矩阵定义了一个黎曼度量(Riemannian metric):
这被称为Fisher度量(Fisher metric)或Fisher-Rao度量。
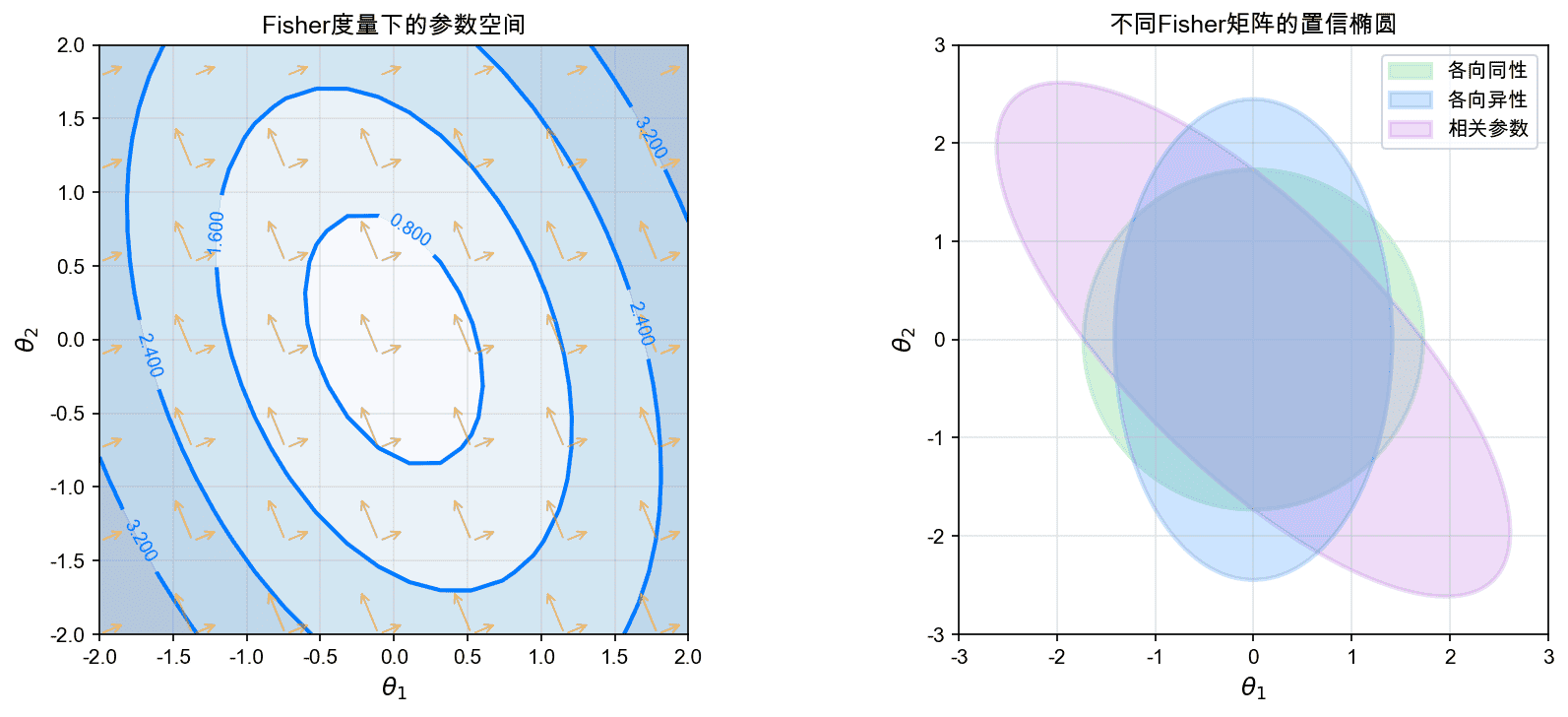
左图展示了Fisher度量下的参数空间:等高线表示等距的点,向量的长度和方向由Fisher矩阵决定。右图展示了不同Fisher矩阵对应的置信椭圆:各向同性(绿色)、各向异性(蓝色)、相关参数(紫色)。
3.3 几何解释的意义
Fisher度量为统计学提供了深刻的几何洞察:
距离的定义:在Fisher度量下,“距离"反映了分布之间的可区分性。两个分布的Fisher距离越大,越容易通过数据区分它们。
最短路径(测地线):连接两个分布的最短路径(测地线)对应于统计族中的"自然"插值。
曲率:统计流形的曲率反映了分布族的"非线性程度”,与统计推断的复杂性相关。
体积元:$\sqrt{\det \mathcal{I}(\theta)} d\theta$ 定义了参数空间上的自然体积元,与Jeffreys先验有关。
3.4 信息几何的应用
信息几何这一由C.R. Rao和Harald Cramér开创、由Shun-ichi Amari发展的领域,已在多个领域找到应用:
- 机器学习:自然梯度下降、变分推断
- 神经科学:神经网络的几何分析
- 信号处理:盲源分离、独立成分分析
- 量子力学:量子Fisher信息、量子计量学
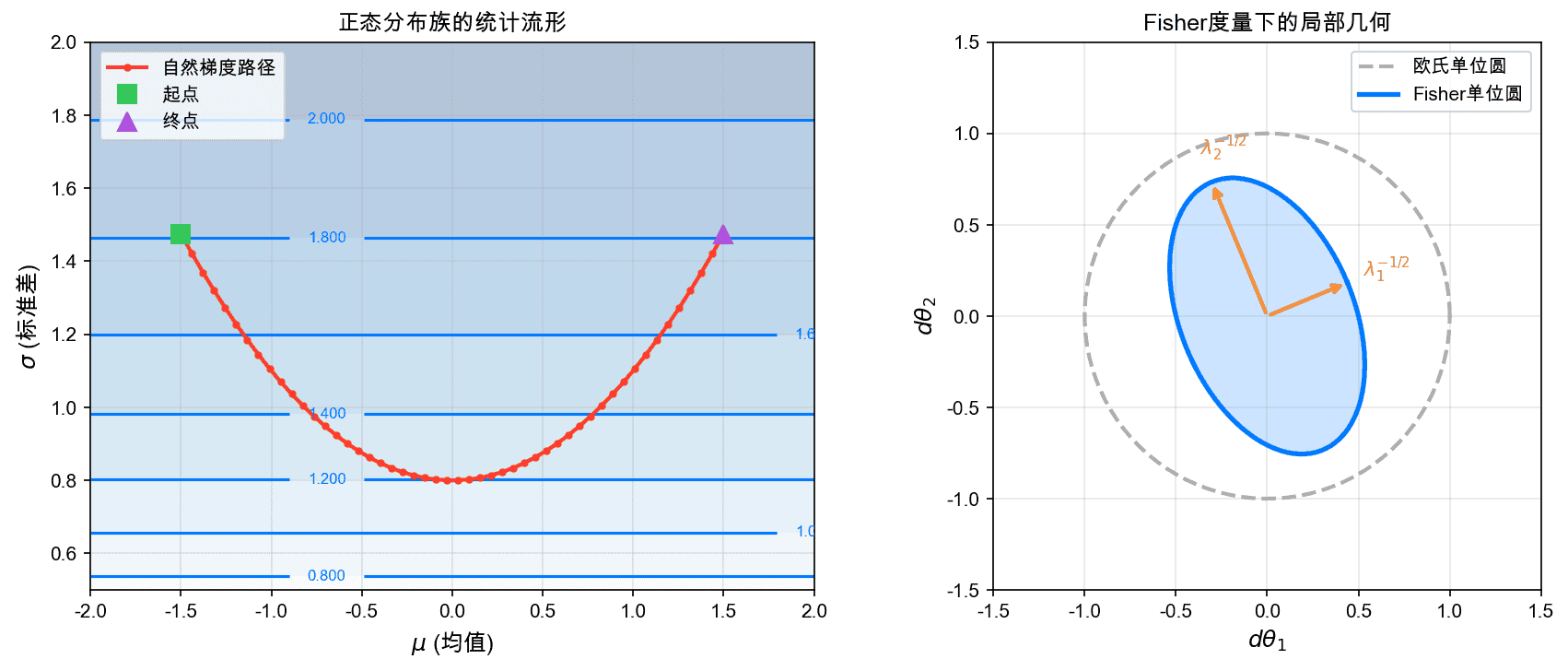
左图展示了正态分布族的统计流形:$(\mu, \sigma)$ 平面上的每个点对应一个正态分布,等高线表示熵的水平。红线表示自然梯度下降的路径。右图展示了Fisher度量下的局部几何:Fisher矩阵将欧氏单位圆(虚线)映射为椭圆(实线)。
第四章:多元Cramér-Rao下界
4.1 协方差矩阵的下界
单参数Cramér-Rao下界告诉我们:无偏估计量的方差不能小于Fisher信息的倒数。在多参数情况下,这个结论推广为:
多元Cramér-Rao下界:设 $\hat{\theta}$ 是 $\theta$ 的无偏估计,则:
其中 “$\succeq$” 表示矩阵的Löwner序:$A \succeq B$ 当且仅当 $A - B$ 是半正定的。
这意味着 $\text{Cov}(\hat{\theta}) - \mathcal{I}(\theta)^{-1}$ 是半正定矩阵。
4.2 对角元与边缘下界
由半正定矩阵的性质,多元CRLB蕴含了每个参数的边缘下界:
注意:这里的下界是逆矩阵的对角元,不等于单变量Fisher信息的倒数!
一般来说:
等号成立当且仅当 $\theta_i$ 与其他参数"正交"(即 $\mathcal{I}(\theta)_{ij} = 0$ 对所有 $j \neq i$)。
4.3 参数相关性的影响
Fisher信息矩阵的非对角元反映了参数之间的相关性。这种相关性会影响每个参数的估计精度。
直观上,如果两个参数高度相关(例如,在简单线性回归中,如果所有 $x_i$ 都是正数,截距和斜率会正相关),那么同时估计两个参数会比单独估计更困难。这就是为什么逆矩阵的对角元通常大于单变量信息的倒数。
例子:二维正态分布
设 $(\theta_1, \theta_2)$ 的Fisher信息矩阵为:
则:
因此:
当 $|\rho| \to 1$ 时,方差下界趋于无穷大!这说明当参数高度相关时,估计变得非常困难。
第五章:应用实例
5.1 线性回归中的Fisher信息
考虑线性模型 $\mathbf{y} = \mathbf{X}\beta + \epsilon$,其中 $\epsilon \sim N(\mathbf{0}, \sigma^2 \mathbf{I})$。
对数似然函数:
Fisher信息矩阵(关于 $\beta$):
这是设计矩阵 $\mathbf{X}$ 的Gram矩阵缩放后的版本。
意义:
- $\mathbf{X}^T \mathbf{X}$ 的对角元反映每个预测变量的"信息量"
- 非对角元反映预测变量之间的相关性
- 好的实验设计应该使 $\mathbf{X}^T \mathbf{X}$ 接近对角(预测变量正交)
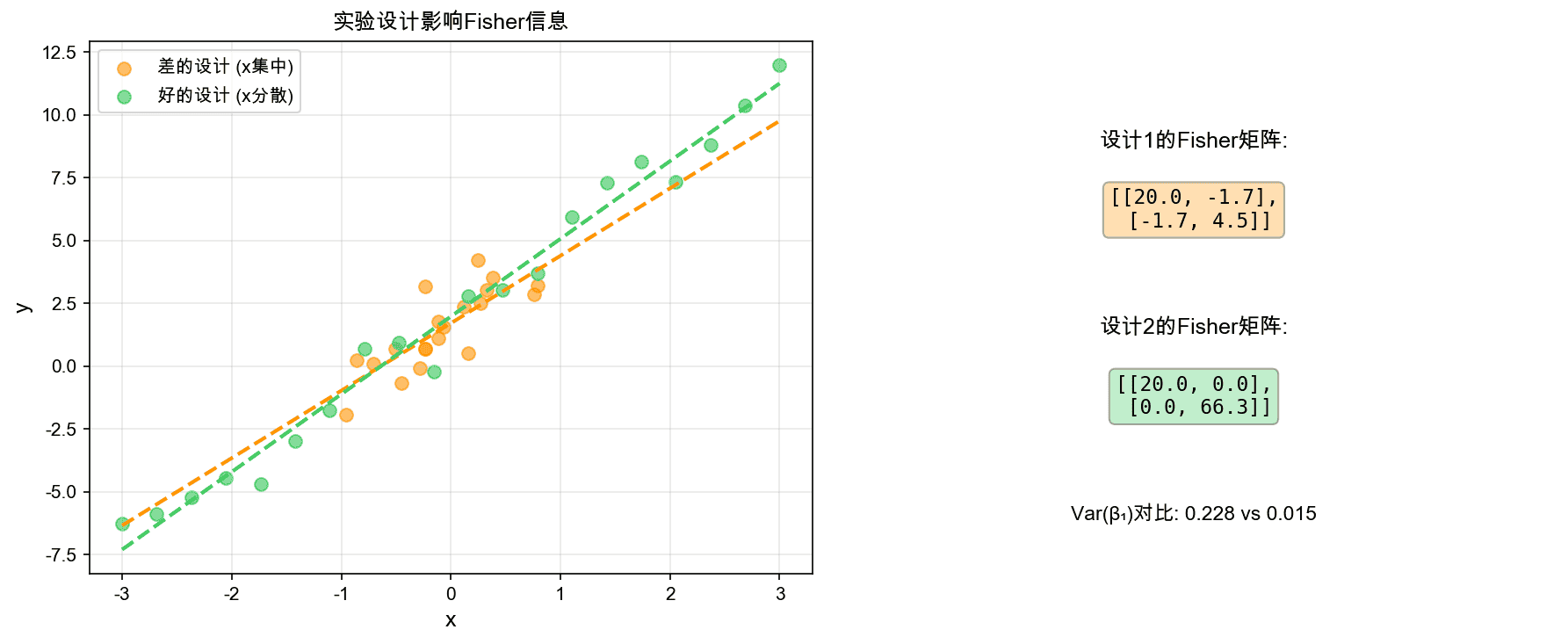
左图展示了两种实验设计:差的设计(x集中在均值附近,橙色)和好的设计(x分散,绿色)。右图展示了对应的Fisher信息矩阵和斜率估计的方差。
5.2 指数族分布
指数族分布具有特别简洁的Fisher信息形式。
指数族的定义:
其中 $\mathbf{T}(x)$ 是充分统计量,$A(\theta)$ 是对数配分函数。
Fisher信息矩阵:
即Fisher信息矩阵就是对数配分函数的Hessian矩阵!
例子:多元正态分布
对于 $N(\mu, \Sigma)$,Fisher信息矩阵与协方差矩阵的逆密切相关。这解释了为什么在高斯模型中,精度矩阵(协方差矩阵的逆)在推断中起核心作用。
5.3 观测Fisher信息与期望Fisher信息
在实际应用中,我们有时使用观测Fisher信息矩阵(observed Fisher information):
这与期望Fisher信息矩阵(expected Fisher information)$\mathcal{I}(\theta)$ 不同:前者基于实际观测的数据,后者是理论期望。
在MLE $\hat{\theta}$ 处,观测信息矩阵 $\mathcal{J}(\hat{\theta})$ 常用于:
- 计算标准误:$\widehat{\text{SE}}(\hat{\theta}i) = \sqrt{[\mathcal{J}(\hat{\theta})^{-1}]{ii}}$
- 构造置信区间
- 似然比检验的近似
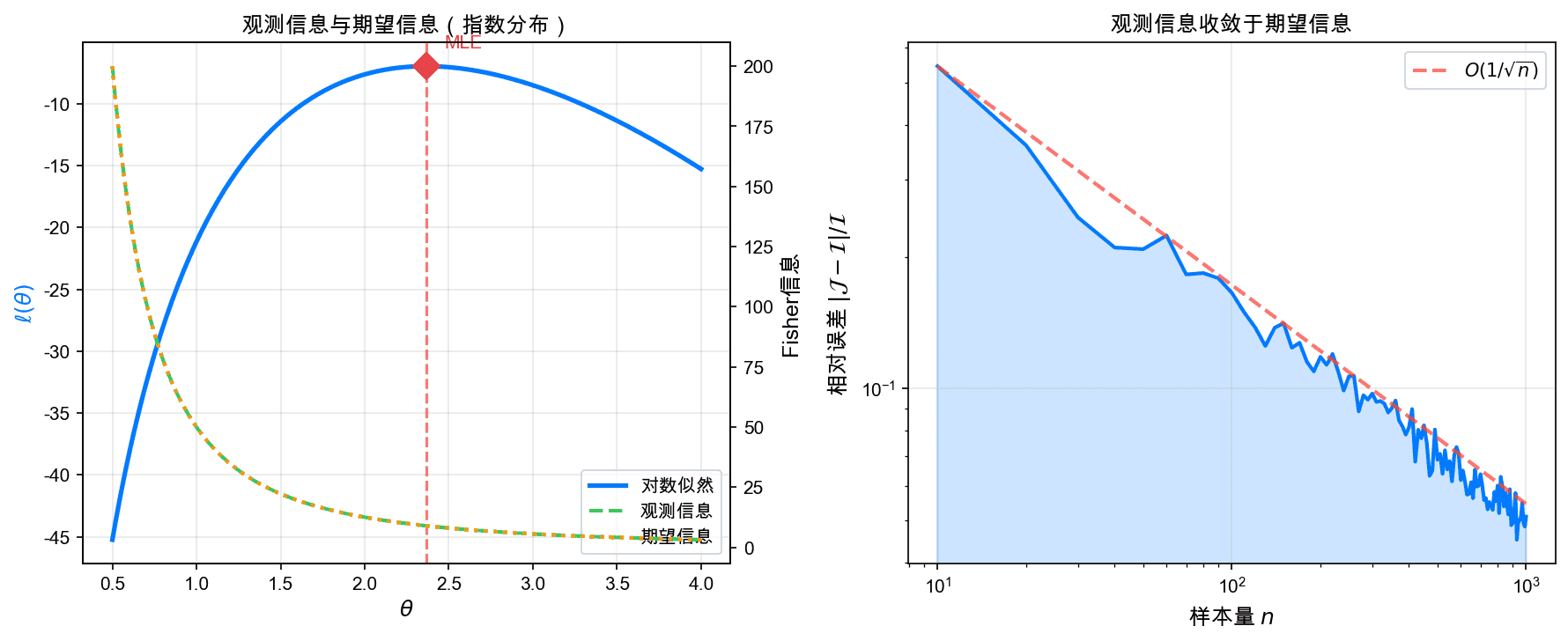
左图展示了指数分布的观测信息和期望信息随参数变化的曲线。右图展示了随着样本量增加,观测信息收敛于期望信息。
第六章:现代应用
6.1 自然梯度下降
在机器学习特别是深度学习中,参数空间的维度可能达到数百万甚至数十亿。传统的梯度下降使用欧氏梯度:
但欧氏梯度忽略了参数空间的内在几何结构。
自然梯度下降(Natural Gradient Descent)由Amari提出,使用Fisher信息矩阵定义最速下降方向:
自然梯度具有以下优点:
- 参数化不变性:不依赖于参数的具体选择
- 更快的收敛:考虑了参数空间的曲率
- 更好的稳定性:自动调整每个参数的学习率
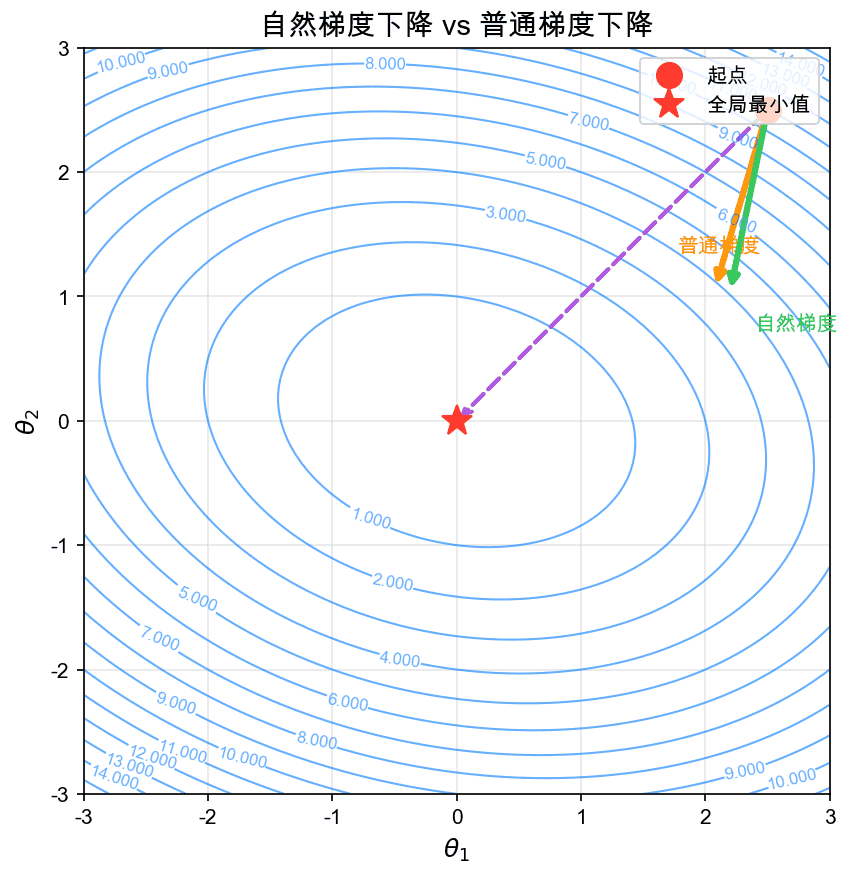
上图展示了自然梯度(绿色)与普通梯度(橙色)的比较。自然梯度直接指向全局最小值的方向,而普通梯度可能走弯路。
6.2 变分推断
在变分推断中,我们用简单的分布 $q(\mathbf{z}; \theta)$ 逼近复杂的后验分布 $p(\mathbf{z} | \mathbf{x})$。优化目标是最小化KL散度:
Fisher信息矩阵在这里扮演了重要角色:
- 自然梯度变分推断(NGVI)使用Fisher信息加速优化
- Fisher散度提供了另一种衡量分布差异的度量
- 信息几何视角帮助设计更好的变分族
6.3 主动学习与实验设计
Fisher信息矩阵在主动学习和最优实验设计中有直接应用。
最优实验设计的目标是选择观测点 $\mathbf{x}_1, \ldots, \mathbf{x}_n$,使得参数估计的精度最高。这等价于最大化Fisher信息矩阵的某种标量函数:
- D-最优:最大化 $\det \mathcal{I}(\theta)$(置信椭球的体积最小)
- A-最优:最小化 $\text{tr}(\mathcal{I}(\theta)^{-1})$(参数方差之和最小)
- E-最优:最大化 $\lambda_{\min}(\mathcal{I}(\theta))$(最坏情况最好)
在深度学习的主动学习中,Fisher信息也被用来选择最有价值的样本进行标注。
6.4 贝叶斯推断
在贝叶斯框架下,Fisher信息矩阵与Jeffreys先验密切相关:
Jeffreys先验是一种无信息先验(uninformative prior),它在参数重新参数化下保持不变。这种不变性正是由Fisher信息矩阵的几何性质保证的。
结语
Fisher信息矩阵是数理统计学中最优雅的概念之一。它不仅是Cramér-Rao下界的核心组成部分,更揭示了统计学与微分几何之间深刻的内在联系。
让我们回顾本文的核心要点:
Fisher信息矩阵 $\mathcal{I}(\theta)$ 量化了数据包含的关于多维参数的信息,其元素由得分向量的协方差给出。
几何解释:Fisher信息矩阵定义了统计流形上的黎曼度量,参数空间中的"距离"反映了分布之间的可区分性。
多元CRLB:任何无偏估计量的协方差矩阵都以Fisher信息矩阵的逆为下界。
参数相关性:Fisher信息矩阵的非对角元反映了参数之间的相互影响,高度相关的参数难以同时准确估计。
现代应用:从自然梯度下降到变分推断,从实验设计到贝叶斯先验,Fisher信息矩阵在现代统计学和机器学习中无处不在。
费希尔在1922年的论文中写道:“统计学的目的是从数据中提取所有可用的信息。“一个世纪后的今天,Fisher信息矩阵仍然是实现这一目标最强大的工具之一。它不仅告诉我们能做什么,更从根本上阐明了什么是"信息”,以及如何在不确定性中进行最优推断。
正如信息几何的奠基人甘利俊一(Shun-ichi Amari)所言:“统计推断的本质是几何。“Fisher信息矩阵正是连接统计与几何的桥梁,它让我们能够以全新的视角审视数据、参数和不确定性之间的深刻关系。
延伸阅读:
- Fisher, R.A. (1922). On the mathematical foundations of theoretical statistics. Philosophical Transactions of the Royal Society, 222, 309-368.
- Rao, C.R. (1945). Information and the accuracy attainable in the estimation of statistical parameters. Bulletin of the Calcutta Mathematical Society, 37, 81-91.
- Amari, S. (2016). Information Geometry and Its Applications. Springer.
- Martens, J. (2020). New insights and perspectives on the natural gradient method. Journal of Machine Learning Research, 21, 1-76.
学习路径建议:
- 基础阶段:掌握单参数Fisher信息的定义和计算,理解其与Cramér-Rao下界的关系
- 进阶阶段:学习Fisher信息矩阵的定义,能计算常见多参数模型的信息矩阵
- 深入阶段:理解信息几何的基本概念,掌握自然梯度的原理和实现
- 拓展阶段:研究Fisher信息在深度学习、强化学习等前沿领域的应用
愿你在信息、几何与统计的交织中,发现数据背后的真理与美。