
引言
1951年,两位美国科学家发表了一篇看似不起眼的论文,提出了一个度量概率分布之间"差异"的新方法。这两位科学家是所罗门·库尔贝克(Solomon Kullback)和理查德·莱布勒(Richard Leibler),而他们提出的度量今天被称为KL散度(Kullback-Leibler Divergence),又称相对熵(Relative Entropy)。
KL散度可能是现代统计学和机器学习中应用最广泛的概念之一。从变分自编码器(VAE)的潜在空间正则化,到强化学习中的策略优化;从假设检验的最优决策,到贝叶斯推断中的后验近似——KL散度无处不在。然而,尽管它如此重要,KL散度的本质却常常被误解:它不是一个距离度量(distance metric),因为它不满足对称性;它是一个散度(divergence),度量的是用一个分布近似另一个分布时的"信息损失"。
本文将深入探讨KL散度的数学本质和统计意义。我们将看到,KL散度不仅是信息论的核心概念,更与Fisher信息矩阵、统计流形几何、以及统计推断的最优性有着深刻的内在联系。无论你是想理解变分推断的原理,还是想掌握强化学习中的TRPO算法,亦或是单纯对信息论的数学之美感兴趣,本文都将为你提供系统而深入的知识。
第一章:KL散度的起源与动机
1.1 信息论的黄金时代
1951年的论文《On Information and Sufficiency》发表在《Annals of Mathematical Statistics》上。当时,香农的信息论刚刚诞生不久(香农的经典论文《A Mathematical Theory of Communication》发表于1948年),整个学术界都在探索"信息"的数学本质。
库尔贝克和莱布勒的工作是在香农熵的基础上进行的。香农熵 $H(P) = -\sum_i p_i \log p_i$ 度量了一个分布的"不确定性",但它没有回答:当我们用一个分布 $Q$ 来近似另一个分布 $P$ 时,会产生多少"信息损失"?
这个问题的答案就是KL散度。
1.2 核心问题:近似的代价
假设你正在设计一个数据压缩算法。真实数据的分布是 $P$,但由于 $P$ 太复杂,你决定用一个更简单的分布 $Q$ 来建模。如果你基于 $Q$ 来设计编码方案,压缩数据时会损失多少效率?
或者,在变分推断中,我们想要近似复杂的后验分布 $p(\mathbf{z} | \mathbf{x})$,但计算困难。于是我们用一个简单的变分分布 $q(\mathbf{z})$ 来近似。这个近似有多"好"?我们如何量化近似带来的误差?
KL散度就是为回答这些问题而生的。
1.3 直观理解
在形式化定义之前,让我们先建立直观理解。
假设 $P$ 和 $Q$ 是两个离散分布。对于某个事件 $x$,如果 $p(x)$ 很大(在 $P$ 下很可能发生),但 $q(x)$ 很小(在 $Q$ 下不太可能发生),那么用 $Q$ 来"预测" $P$ 在这个事件上就会犯大错。
KL散度就是对所有这样的"预测错误"进行加权平均,权重由真实分布 $P$ 决定:
如果对数比率 $\log \frac{p(x)}{q(x)}$ 为正($p(x) > q(x)$),说明 $Q$ 低估了 $x$ 的概率;如果为负($p(x) < q(x)$),说明 $Q$ 高估了 $x$ 的概率。KL散度就是所有这些"偏差"的加权平均。
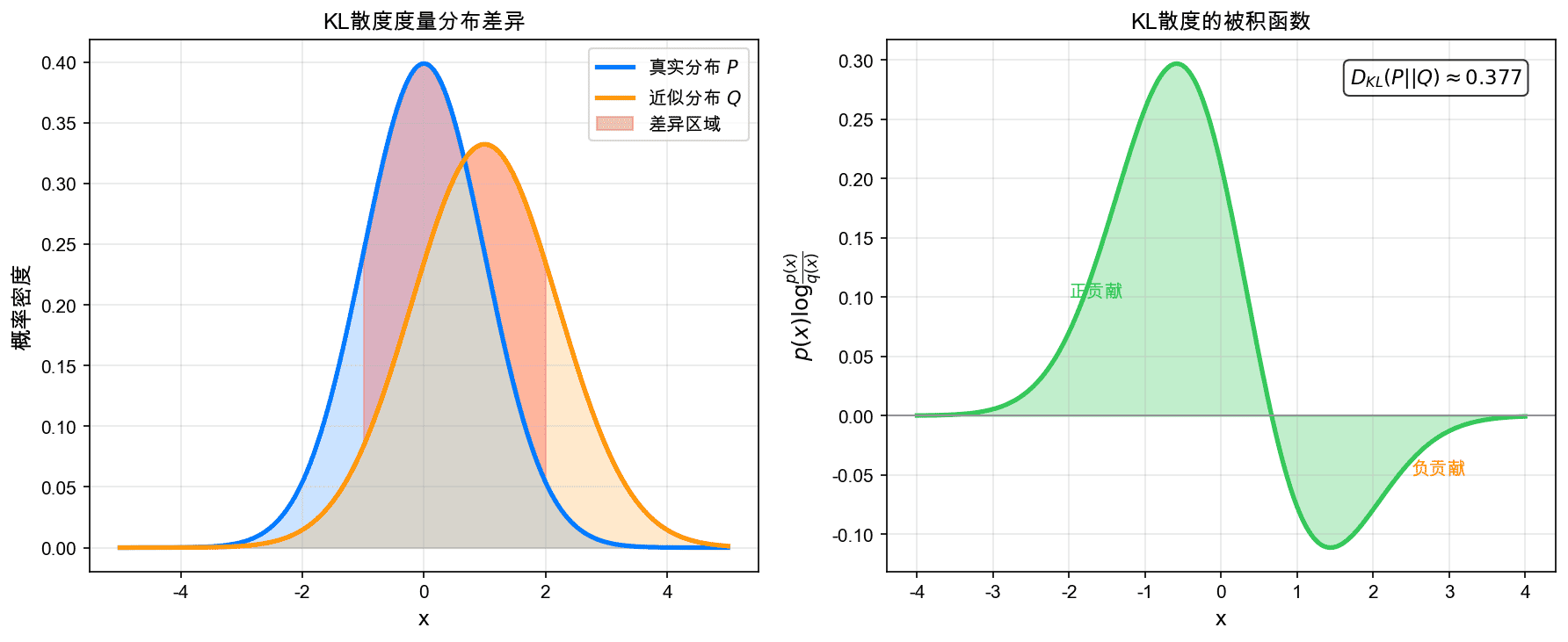
左图展示了两个正态分布 $P$(蓝色)和 $Q$(橙色),红色阴影区域表示差异较大的地方。右图展示了KL散度的被积函数 $p(x) \log \frac{p(x)}{q(x)}$,其积分就是 $D_{KL}(P||Q)$。
第二章:KL散度的数学定义与推导
2.1 离散情形的定义
设 $P$ 和 $Q$ 是定义在同一可数样本空间 $\mathcal{X}$ 上的两个概率分布。
定义(KL散度):$Q$ 相对于 $P$ 的KL散度(或 $P$ 相对于 $Q$ 的相对熵)定义为:
这里约定:
- 如果 $p(x) = 0$,对应项为 $0$(因为 $\lim_{t \to 0} t \log t = 0$)
- 如果 $p(x) > 0$ 但 $q(x) = 0$,则 $D_{KL}(P || Q) = +\infty$
对数的底通常是 $e$(自然对数),此时KL散度的单位是奈特(nats);如果使用底数为 $2$ 的对数,单位是比特(bits)。
2.2 连续情形的定义
对于连续分布,求和变为积分:
其中 $p(x)$ 和 $q(x)$ 是概率密度函数。
2.3 熵与交叉熵的视角
KL散度可以用熵和交叉熵重新表达。
熵(Entropy):
交叉熵(Cross-Entropy):
关系:
这个表达式揭示了KL散度的本质:交叉熵减去熵。交叉熵 $H(P, Q)$ 是用 $Q$ 来编码来自 $P$ 的数据所需的平均比特数;熵 $H(P)$ 是用最优编码(基于 $P$)所需的平均比特数。两者的差就是编码效率的损失。
2.4 对数似然比的期望
另一种重要的表达方式是:
这是对数似然比 $\log \frac{p(X)}{q(X)}$ 在分布 $P$ 下的期望。对数似然比在统计假设检验中扮演核心角色:它是区分 $P$ 和 $Q$ 的最优检验统计量。
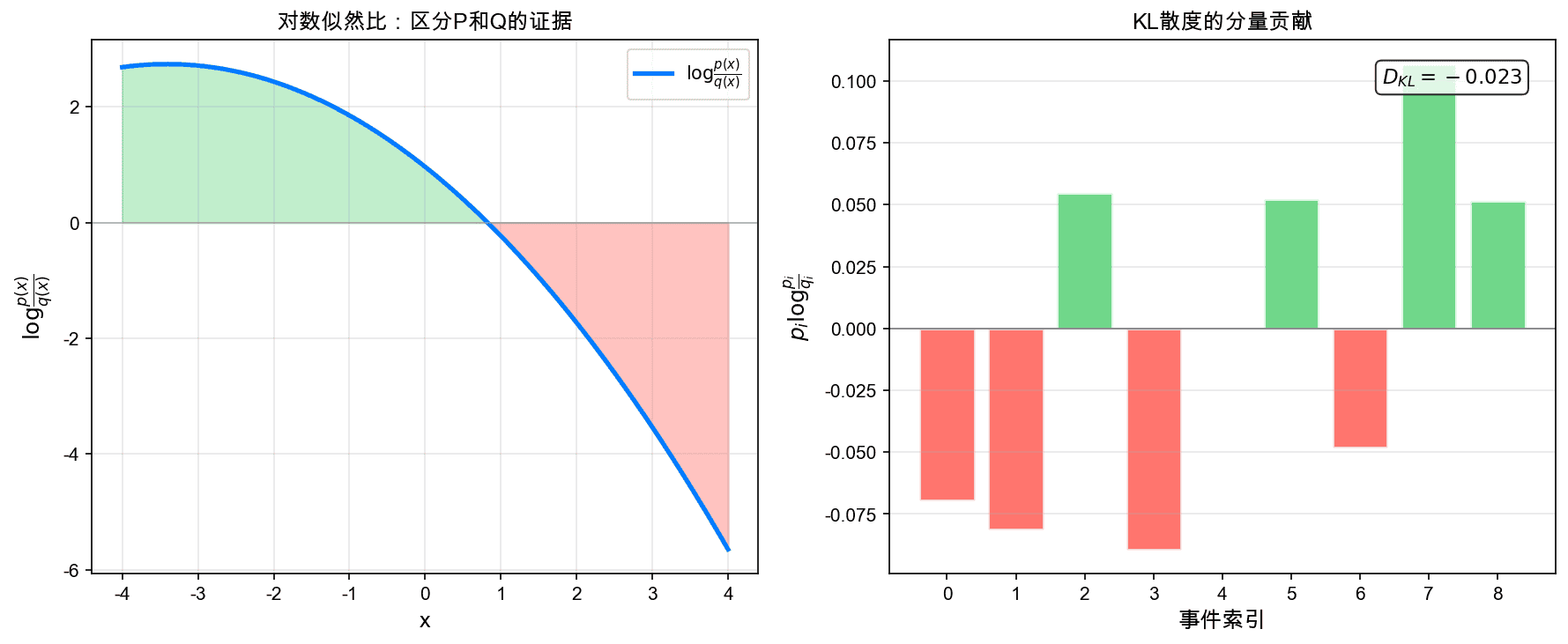
左图展示了对数似然比 $\log \frac{p(x)}{q(x)}$,它度量了在每个点 $x$ 处,数据支持 $P$ 而非 $Q$ 的证据强度。右图展示了离散分布KL散度的各分量贡献。
第三章:KL散度的核心性质
3.1 非负性(Gibbs不等式)
定理(Gibbs不等式):$D_{KL}(P || Q) \geq 0$,且等号成立当且仅当 $P = Q$(几乎处处)。
证明:利用Jensen不等式和对数函数的凹性。
等号成立当且仅当 $\frac{q(x)}{p(x)}$ 为常数(几乎处处),即 $P = Q$。
意义:KL散度的非负性告诉我们,用任何不同于 $P$ 的分布 $Q$ 来近似 $P$,都会产生正的"信息损失"。只有当 $Q = P$ 时,损失为零。
3.2 非对称性
性质:一般情况下,$D_{KL}(P || Q) \neq D_{KL}(Q || P)$。
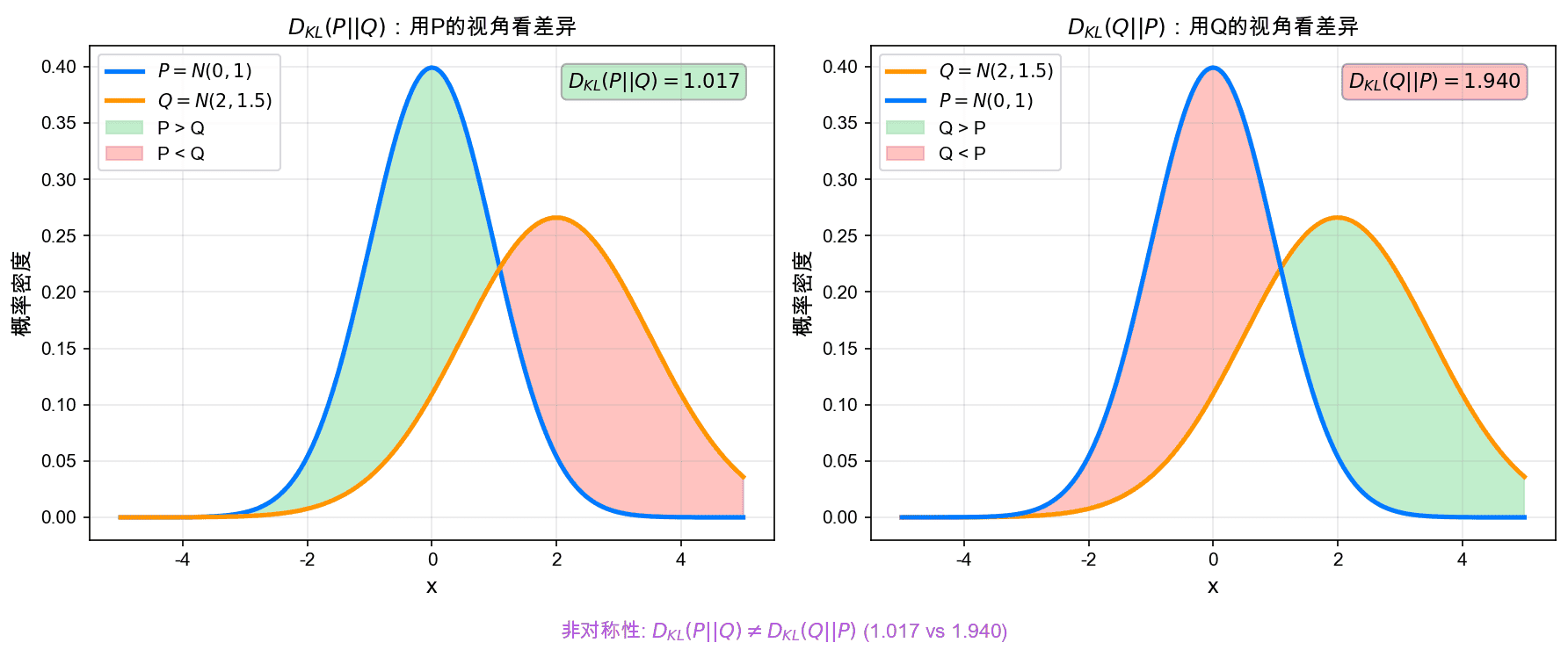
上图展示了两个正态分布之间的KL散度。$D_{KL}(P||Q)$(左图)用 $P$ 的视角度量差异,关注 $P$ 概率质量大但 $Q$ 概率质量小的区域;$D_{KL}(Q||P)$(右图)则相反。两者的数值不同。
直观解释:
- $D_{KL}(P || Q)$:从 $P$ 的角度看,$Q$ 有多"错"?(模式覆盖视角)
- $D_{KL}(Q || P)$:从 $Q$ 的角度看,$P$ 有多"错"?(均值匹配视角)
在变分推断中,最小化 $D_{KL}(Q || P)$(反向KL)会导致 $Q$ 寻找 $P$ 的一个模式(mode),而最小化 $D_{KL}(P || Q)$(正向KL)会导致 $Q$ 覆盖 $P$ 的所有支持区域。
3.3 凸性
定理:$D_{KL}(P || Q)$ 关于 $(P, Q)$ 是联合凸的。
即,对于任意 $\lambda \in [0, 1]$:
意义:凸性保证了基于KL散度的优化问题具有良好的数学性质,有利于寻找全局最优解。
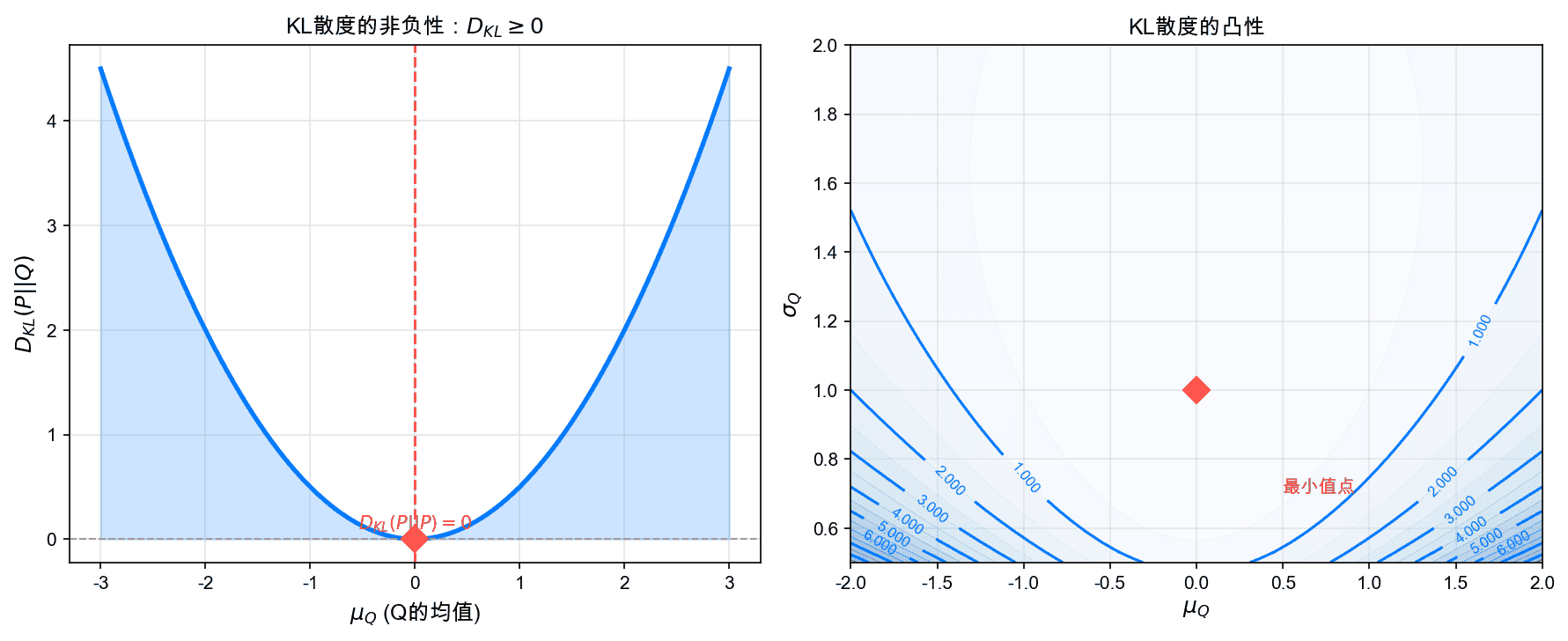
左图展示了KL散度的非负性:只有当两个分布相同时,KL散度才为零。右图展示了KL散度在参数空间中的等高线,反映了其凸性。
3.4 链式法则与可加性
链式法则:对于联合分布,
这个性质在分析复杂模型时非常有用,允许我们将整体的KL散度分解为边缘分布和条件分布的贡献。
第四章:KL散度与统计推断
4.1 最大似然估计的等价形式
给定数据 $x_1, \ldots, x_n$ 来自真实分布 $P_{\text{data}}$,考虑参数化模型族 ${P_{\theta} : \theta \in \Theta}$。
最大似然估计(MLE)最大化对数似然:
当 $n \to \infty$ 时,由大数定律:
因此,MLE等价于:
深刻洞察:MLE等价于最小化真实数据分布与模型分布之间的KL散度。这就是MLE的"正确设定"(well-specified)假设:如果真实分布属于模型族,MLE能够找到它;否则,MLE找到的是模型族中与真实分布KL散度最小的成员。
4.2 假设检验与Chernoff-Stein引理
在二元假设检验中,我们有:
- $H_0$:数据来自 $P$
- $H_1$:数据来自 $Q$
Neyman-Pearson引理告诉我们,似然比检验是最优的。而似然比的期望对数正是KL散度。
Chernoff-Stein引理:考虑序列检验,设错误概率 $\alpha_n \to 0$。最小的第二类错误概率 $\beta_n$ 满足:
意义:$D_{KL}(P || Q)$ 决定了我们能够以多快的指数速率区分 $P$ 和 $Q$。KL散度越大,区分越容易。
4.3 贝叶斯推断与后验近似
在贝叶斯推断中,我们希望计算后验分布:
但对于复杂模型,后验难以计算。变分推断(Variational Inference)用一个简单的分布 $q(\theta)$ 来近似后验,通过最小化KL散度:
展开KL散度:
其中 $\text{ELBO}(q) = \mathbb{E}q[\log p(\mathbf{x} | \theta)] - D{KL}(q || p(\theta))$ 是证据下界(Evidence Lower BOund)。最小化KL散度等价于最大化ELBO。
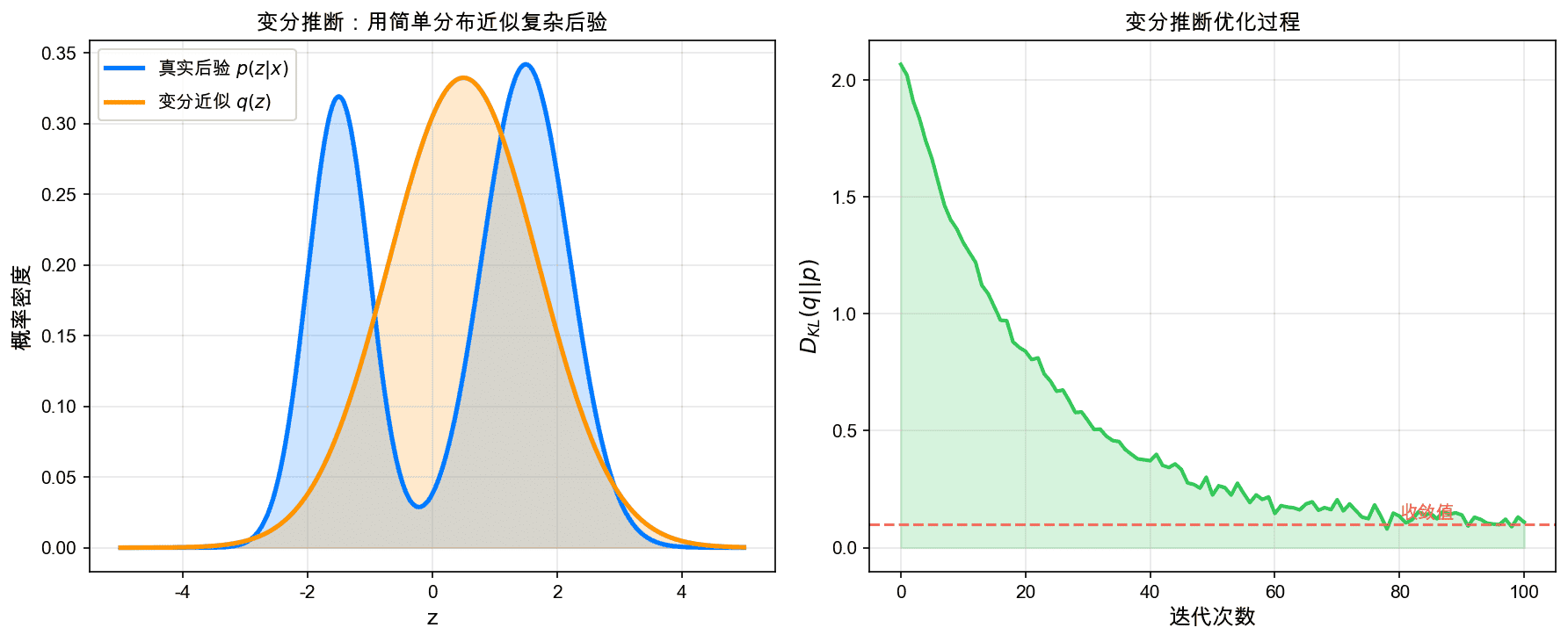
左图展示了用简单分布(橙色)近似复杂后验(蓝色)的问题。右图展示了变分推断的优化过程:KL散度随迭代逐渐下降,最终收敛。
第五章:信息几何视角
5.1 KL散度与Fisher信息的关系
在第三章中,我们介绍了Fisher信息矩阵 $\mathcal{I}(\theta)$。KL散度与Fisher信息之间存在深刻的关系。
考虑参数空间中的两个邻近点 $\theta$ 和 $\theta + d\theta$。对 $D_{KL}(P_{\theta} || P_{\theta + d\theta})$ 进行二阶泰勒展开:
意义:在小邻域内,KL散度是Fisher度量下的"距离"的一半。这揭示了KL散度的局部几何结构:Fisher信息矩阵定义了参数空间的黎曼度量。
5.2 统计流形上的测地线
在统计流形(由概率分布构成的流形)上,Fisher度量定义了最短路径(测地线)。而KL散度则提供了一种"大尺度"的距离度量。
有趣的是,对于某些分布族(如指数族),存在对偶平坦结构(dually flat structure),使得KL散度具有特殊的分解性质。这是信息几何的核心理论,由甘利俊一(Shun-ichi Amari)系统发展。
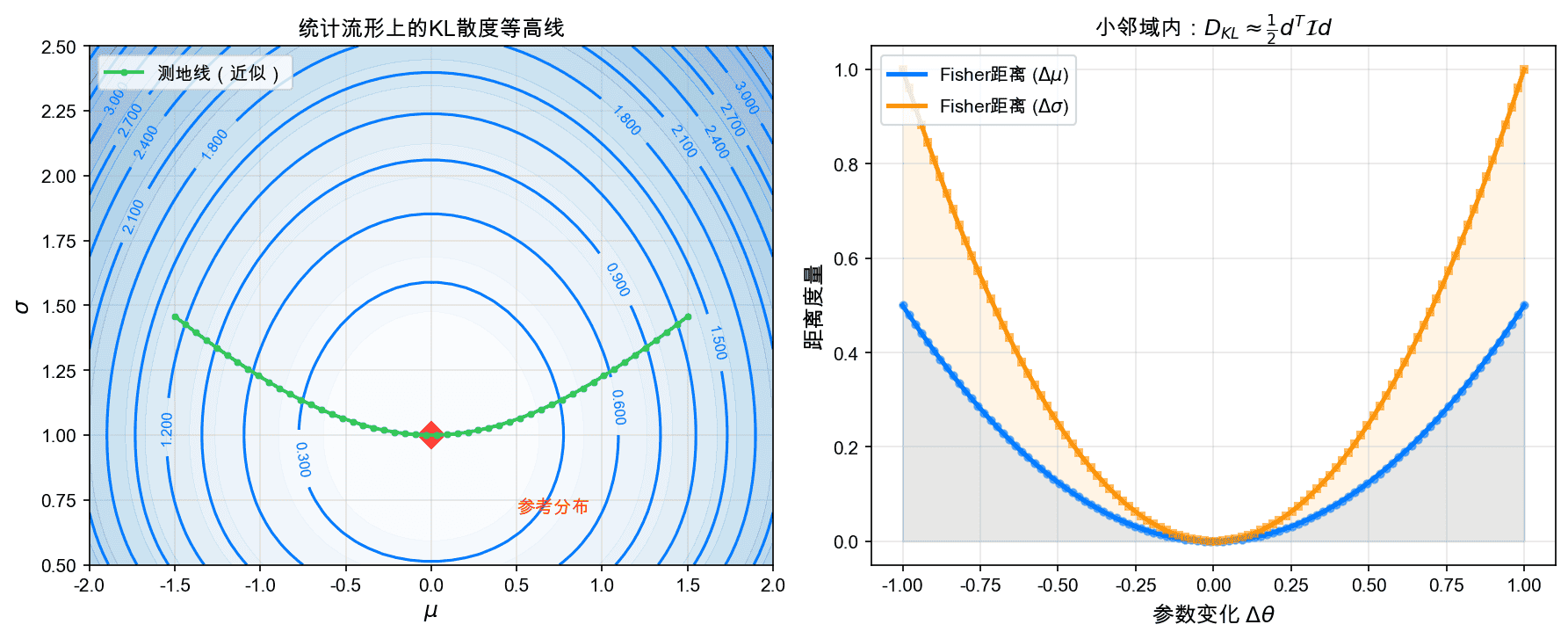
左图展示了正态分布族统计流形上的KL散度等高线。右图展示了在小邻域内,KL散度与Fisher度量的关系:$D_{KL} \approx \frac{1}{2} d^T \mathcal{I} d$。
5.3 Bregman散度的一般化
KL散度是Bregman散度(Bregman divergence)的特例。Bregman散度由凸函数 $\phi$ 定义:
对于负熵函数 $\phi(p) = \sum_i p_i \log p_i$,对应的Bregman散度就是KL散度。
Bregman散度具有许多良好的性质,包括非负性、凸性、以及唯一的投影定理。这为KL散度的应用提供了更广泛的数学框架。
第六章:KL散度在机器学习中的应用
6.1 变分自编码器(VAE)
VAE是一种生成模型,结合了深度学习和变分推断。其损失函数包含两项:
KL正则化项迫使后验近似 $q_\phi(\mathbf{z} | \mathbf{x})$ 接近先验 $p(\mathbf{z})$(通常是标准正态分布)。这有两个作用:
- 正则化:防止潜在空间过度复杂
- 连续性:确保潜在空间的插值有意义
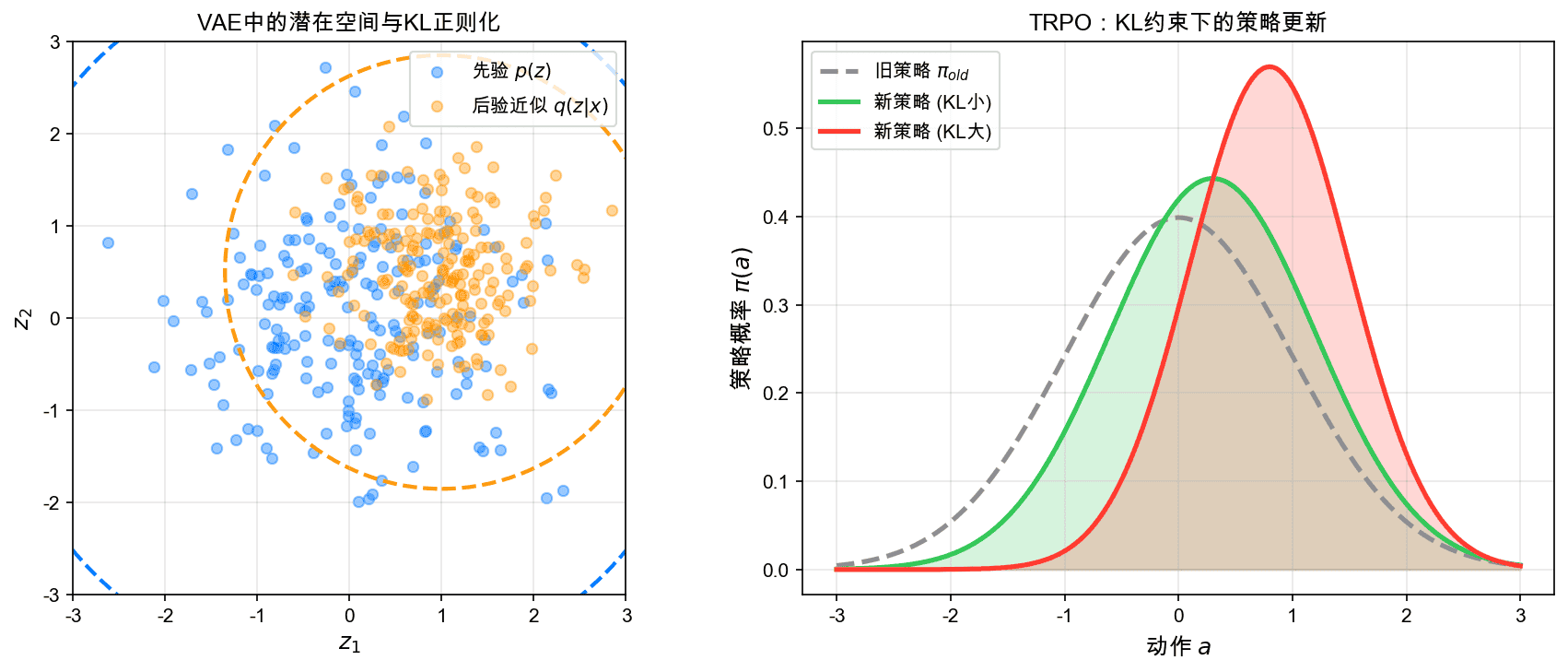
左图展示了VAE中潜在空间的正则化效果:后验分布(橙色)被拉向先验(蓝色)。右图展示了强化学习中TRPO的策略更新:KL约束确保策略不会变化过大。
6.2 强化学习中的信任区域方法
在强化学习中,策略梯度方法可能不稳定,因为策略的大幅更新可能导致性能崩溃。信任区域策略优化(Trust Region Policy Optimization, TRPO)通过约束新旧策略之间的KL散度来解决这个问题:
KL约束确保策略更新在"信任区域"内进行,保证学习的稳定性。
6.3 知识蒸馏
知识蒸馏是一种模型压缩技术,其中大型"教师"模型的知识被转移到小型"学生"模型。优化目标通常包含:
其中 $\mathbf{z}_T$ 和 $\mathbf{z}_S$ 分别是教师和学生的logits,$\tau$ 是温度参数。KL散度确保学生模仿教师的"软"预测,而不仅仅是硬标签。
6.4 生成对抗网络(GAN)
虽然标准GAN使用Jensen-Shannon散度(JS散度),但许多变体使用KL散度或其变体。例如,f-GAN框架将GAN推广到任意f-散度,包括KL散度。
结语
从1951年库尔贝克和莱布勒的论文,到今天机器学习领域的广泛应用,KL散度已经成为连接信息论、统计学和计算机科学的重要桥梁。
让我们回顾本文的核心要点:
KL散度 $D_{KL}(P || Q) = \mathbb{E}_P[\log \frac{P}{Q}]$ 度量了用 $Q$ 近似 $P$ 时的信息损失,等于交叉熵减去熵。
核心性质:非负性($D_{KL} \geq 0$,等号当且仅当 $P = Q$)、非对称性($D_{KL}(P||Q) \neq D_{KL}(Q||P)$)、凸性。
统计意义:MLE等价于最小化 $D_{KL}(P_{\text{data}} || P_{\theta})$;假设检验中,KL散度决定错误指数的衰减速率。
几何解释:在统计流形上,KL散度在小邻域内近似于Fisher度量下的距离;它是Bregman散度的特例。
现代应用:从VAE的潜在空间正则化,到TRPO的策略优化;从知识蒸馏,到变分推断——KL散度无处不在。
KL散度之所以如此强大,是因为它触及了一个根本问题:什么是一个"好"的近似?它告诉我们,好的近似不仅仅是匹配均值或方差,而是要最小化信息损失。这个视角不仅具有数学上的优雅,更在工程实践中展现出巨大的价值。
正如香农在信息论的开创性工作中所展示的,信息是可以被度量、被压缩、被传输的。KL散度则将这种度量能力扩展到了分布之间的比较,为我们提供了一个统一的框架来思考近似、推断和学习。
延伸阅读:
- Kullback, S. & Leibler, R.A. (1951). On information and sufficiency. Annals of Mathematical Statistics, 22(1), 79-86.
- Cover, T.M. & Thomas, J.A. (2006). Elements of Information Theory (2nd ed.). Wiley.
- Murphy, K.P. (2022). Probabilistic Machine Learning: An Introduction. MIT Press.
- Bishop, C.M. (2006). Pattern Recognition and Machine Learning. Springer.
学习路径建议:
- 基础阶段:理解KL散度的定义,能计算常见分布(高斯、伯努利、范畴分布)之间的KL散度
- 进阶阶段:掌握KL散度的核心性质,理解其与熵、交叉熵、似然的关系
- 深入阶段:理解信息几何视角,掌握KL散度在变分推断中的应用
- 拓展阶段:研究KL散度在强化学习、生成模型等前沿领域的应用
愿你在信息、概率与近似的交织中,发现数据背后的深刻规律。