
引言
在统计学的世界里,有一个问题始终萦绕在研究者心头:当我们对某个随机现象知之甚少时,应该如何做出最合理的假设?如果只知道一些基本的约束条件——比如均值和方差——我们应该选择什么样的概率分布来建模?
1850年代,德国数学家卡尔·弗里德里希·高斯在研究误差理论时发现,如果假设测量误差的均值为零且方差有限,那么使似然函数最大化的分布恰好是正态分布。然而,高斯并没有回答一个更根本的问题:为什么误差应该服从正态分布?
一个多世纪后,美国物理学家埃德温·杰恩斯(Edwin T. Jaynes)给出了深刻的答案。1957年,杰恩斯提出了最大熵原理(Principle of Maximum Entropy):在满足所有已知约束的条件下,我们应该选择使熵最大化的概率分布。这个选择是"最无偏"的,因为它假设了最少的信息——除了已知的约束,不做任何额外的假设。
杰恩斯证明了一个惊人的结果:在已知均值和方差的条件下,使熵最大化的分布正是高斯分布(正态分布)。这一结果不仅解释了为什么高斯分布在自然界中如此普遍,更揭示了一个深刻的数学真理:高斯分布是"最随机"的分布——在已知有限的约束下,它保留了最大的不确定性。
本文将深入探讨最大熵原理的数学基础,严格证明高斯分布在给定均值和方差条件下的最大熵性质,并揭示这一结果在统计物理、信息论和机器学习中的广泛应用。
第一章:熵的定义与直观理解
1.1 香农熵的诞生
1948年,克劳德·香农发表了《通信的数学理论》,奠定了信息论的基础。在这篇论文中,香农提出了熵(Entropy)的概念,用于度量一个随机变量的"不确定性"或"信息量"。
对于一个离散随机变量 $X$,其概率分布为 $P(X = x_i) = p_i$,香农熵定义为:
对于连续随机变量,微分熵(Differential Entropy)定义为:
熵的直观含义是:描述随机变量 $X$ 所需的平均信息量。熵越大,不确定性越大;熵越小,不确定性越小。
1.2 熵的基本性质
非负性:对于离散分布,$H(X) \geq 0$。当且仅当某个 $p_i = 1$(其他为0)时,$H(X) = 0$。
最大值:对于具有 $n$ 个可能取值的离散分布,熵的最大值为 $\log n$,在均匀分布 $p_i = 1/n$ 时达到。
可加性:对于独立的随机变量,$H(X, Y) = H(X) + H(Y)$。
凹性:熵是概率分布的凹函数。这意味着混合两个分布会增加熵:
1.3 连续分布的熵
连续分布的微分熵与离散熵有一些重要区别:
微分熵可以为负值(例如,当分布非常集中时)。
微分熵不是坐标变换不变的。如果 $Y = f(X)$,则 $H(Y) \neq H(X)$(除非 $f$ 是线性变换)。
然而,对于给定的方差,不同分布的熵可以比较。
例子:标准正态分布 $N(0, 1)$ 的微分熵为:
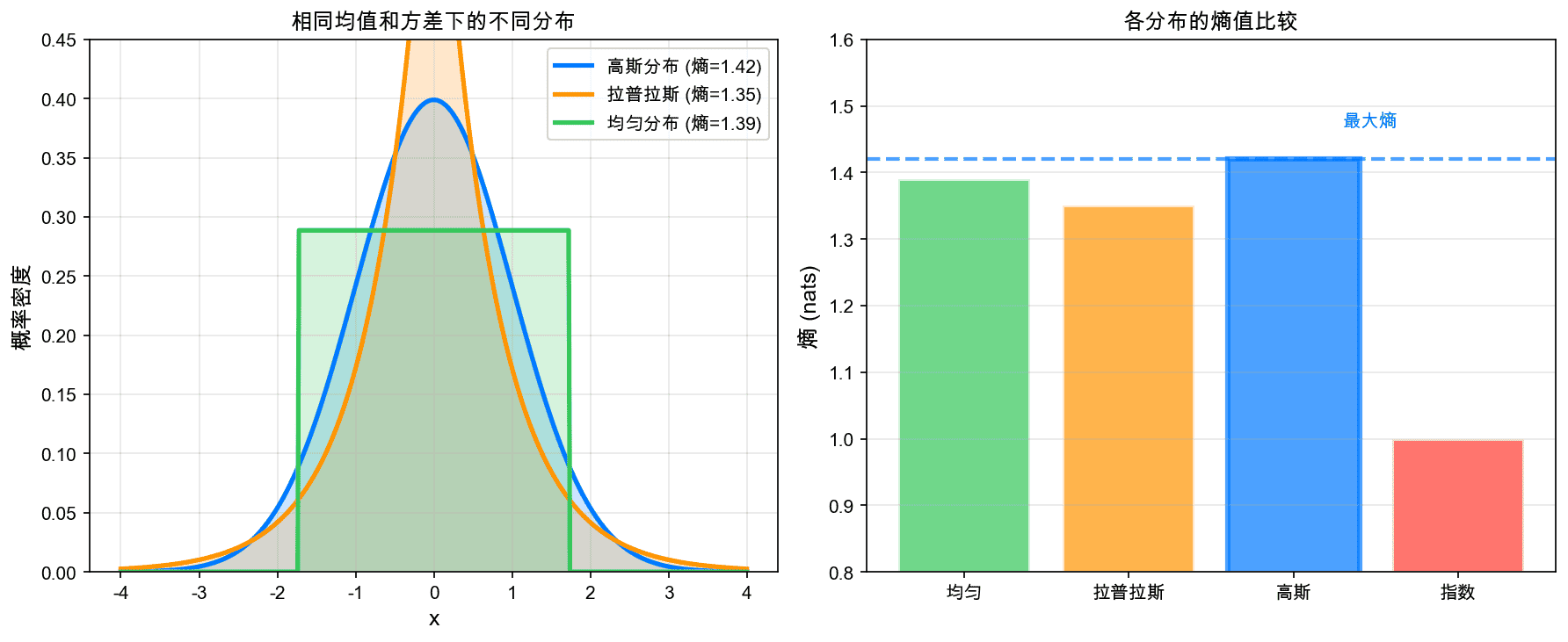
左图展示了具有相同均值(0)和方差(1)的三种分布:高斯(蓝色)、拉普拉斯(橙色)、均匀(绿色)。右图比较了它们的熵值,高斯分布的熵最大。
第二章:最大熵原理的提出
2.1 杰恩斯的洞察
1957年,埃德温·杰恩斯在《信息论与统计力学》一文中提出了最大熵原理。这个原理可以表述为:
在满足所有已知约束的条件下,选择使熵最大化的概率分布。
杰恩斯的洞见源于统计力学。在统计物理中,玻尔兹曼分布(Boltzmann distribution)可以通过最大熵原理推导出来——在给定平均能量的约束下,最大熵分布就是玻尔兹曼分布。
杰恩斯将这一思想推广到一般统计推断:当我们对某个现象了解有限时,最合理的假设是选择"最不确定"的分布,即最大熵分布。这样做的好处是:
- 客观性:不引入任何主观假设
- 鲁棒性:避免过拟合
- 一致性:与统计物理的结果一致
2.2 约束的作用
最大熵原理的关键在于"约束"。不同的约束导致不同的最大熵分布:
| 约束条件 | 最大熵分布 |
|---|---|
| 有限支撑 $[a, b]$ | 均匀分布 |
| 正半轴,给定均值 | 指数分布 |
| 给定均值和方差 | 高斯分布 |
| 给定均值(离散) | 泊松分布 |
这个表格揭示了一个深刻的模式:最大熵分布的形式由约束决定。
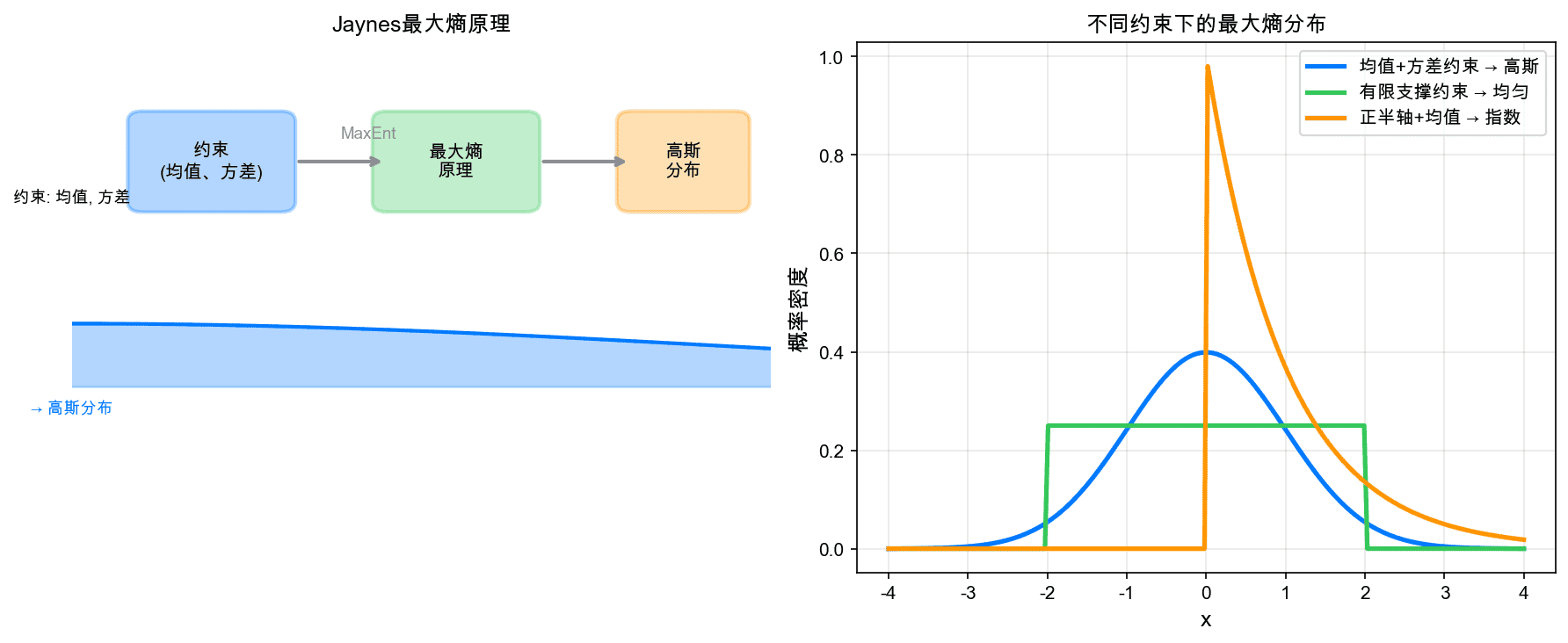
左图展示了最大熵原理的工作流程:从约束条件出发,通过最大化熵,得到最优分布。右图展示了不同约束条件下的最大熵分布。
2.3 为什么最大熵是"最无偏"的
直观上,最大熵分布是"最无偏"的,因为它假设了最少的信息。考虑以下思想实验:
假设你知道一枚硬币是有偏的,正面朝上的概率 $p > 0.5$,但不知道具体值。你应该选择什么分布?
- 如果你选择 $p = 0.6$,你假设了额外的信息
- 如果你选择均匀分布(如果可能),你违反了已知的约束
- 最大熵方法会选择在给定约束下熵最大的分布
这种"不做多余假设"的原则被称为杰恩斯剃刀(Jaynes’ Razor),类似于奥卡姆剃刀在模型选择中的作用。
第三章:最大熵定理的严格证明
3.1 问题设定
考虑连续随机变量 $X$,已知:
- 归一化约束:$\int_{-\infty}^{\infty} p(x) , dx = 1$
- 均值约束:$\int_{-\infty}^{\infty} x , p(x) , dx = \mu$
- 方差约束:$\int_{-\infty}^{\infty} (x - \mu)^2 , p(x) , dx = \sigma^2$
目标:找到使熵 $H[p] = -\int p(x) \log p(x) , dx$ 最大化的 $p(x)$。
3.2 变分法求解
这是一个带约束的变分优化问题。使用拉格朗日乘子法,构造拉格朗日函数:
对 $p(x)$ 求变分导数并令其为零:
解得:
令 $\lambda_2 = -\frac{1}{2\sigma^2}$(必须为负以保证归一化),并确定其他常数,得到:
这正是高斯分布!
3.3 严格证明(Gibbs不等式方法)
另一种更严谨的证明使用Gibbs不等式。
定理:在所有具有均值 $\mu$ 和方差 $\sigma^2$ 的概率分布中,高斯分布 $N(\mu, \sigma^2)$ 使熵最大化。
证明:
设 $p(x)$ 是任意满足约束的分布,$q(x) = N(\mu, \sigma^2)$ 是高斯分布。
考虑KL散度:
展开:
注意 $\log q(x) = -\frac{1}{2}\log(2\pi\sigma^2) - \frac{(x-\mu)^2}{2\sigma^2}$,因此:
代回不等式:
等号成立当且仅当 $p = q$。证毕。
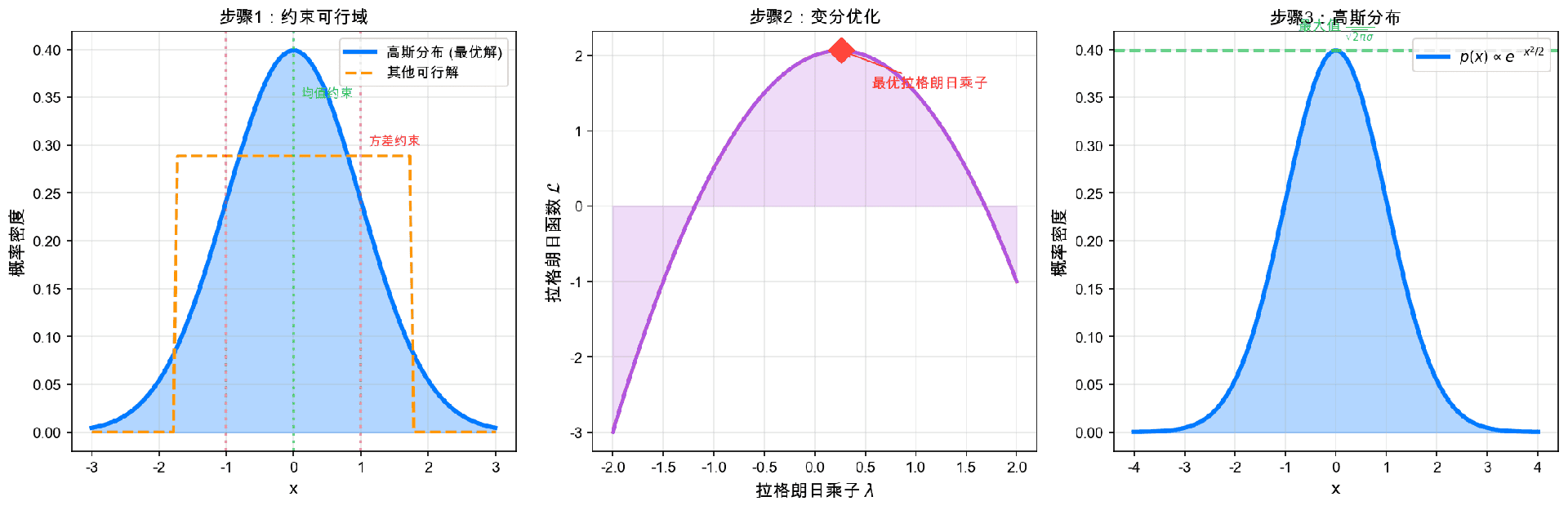
上图展示了证明的关键步骤:左图是约束可行域,中图是变分优化过程,右图是得到的高斯分布结果。
3.4 计算最大熵值
对于 $N(\mu, \sigma^2)$,熵为:
这个公式表明:
- 熵只依赖于方差,与均值无关
- 方差越大,熵越大(不确定性越大)
- 当 $\sigma^2 \to 0$ 时,$H \to -\infty$(确定性的极端)
第四章:为什么高斯分布是"自然"的
4.1 中心极限定理的联系
最大熵原理与中心极限定理(CLT)有密切联系。
中心极限定理:独立同分布随机变量之和(在适当标准化后)收敛于高斯分布。
最大熵解释:
- 当我们把许多小的独立随机效应相加时,我们只关心总和的均值和方差
- 根据最大熵原理,在这些约束下,最合理的假设是高斯分布
- 因此,CLT可以从最大熵的角度理解:大量独立效应叠加"最大化"了熵
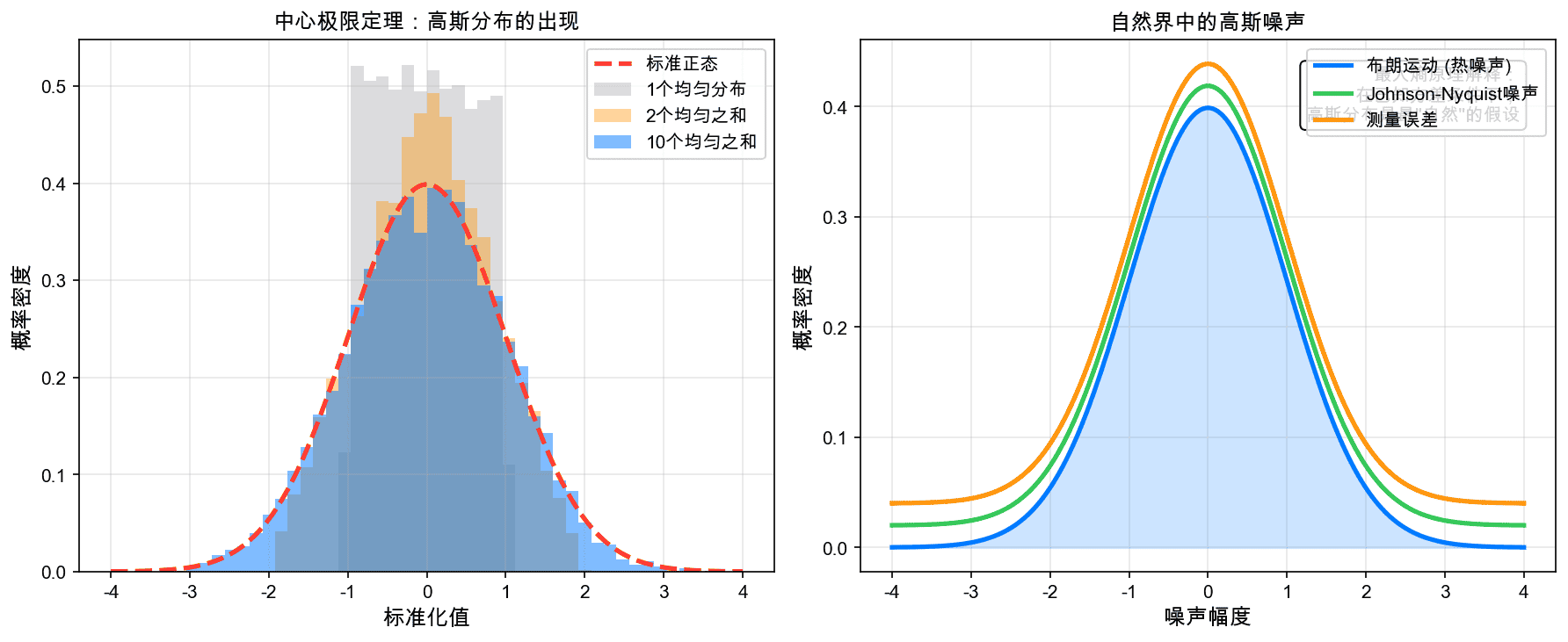
左图展示了中心极限定理:从均匀分布开始,随着独立随机变量数量的增加,和的分布逐渐接近高斯分布。右图展示了自然界中常见的高斯噪声现象。
4.2 自然界的例子
高斯分布在自然界中无处不在,最大熵原理提供了深刻的解释:
热噪声(Johnson-Nyquist噪声):
电阻中的电子热运动产生电压涨落。由于涨落由大量独立电子碰撞引起,根据CLT和最大熵原理,电压噪声服从高斯分布。
测量误差:
精密测量中的误差通常服从高斯分布。这是因为误差由许多小的独立来源(仪器精度、环境波动、读数误差等)叠加而成。
生物统计:
身高、体重等生物测量值通常近似服从对数正态分布(对数后为正态)。这反映了多因素独立作用的生物过程。
布朗运动:
悬浮在流体中的微粒受到大量随机碰撞,其位置随时间的变化服从高斯分布。这是最大熵原理在物理中的经典体现。
4.3 “最随机"的解释
高斯分布被称为"最随机"的分布,因为在给定的方差约束下,它保留了最大的不确定性(熵)。
相比之下:
- 均匀分布虽然有较高的熵,但它在有限支撑外概率为零,引入了额外的结构
- 拉普拉斯分布(双指数)比高斯更"尖峰厚尾”,熵更低
- 柯西分布虽然看起来更"随机",但其方差无限,不在我们的约束框架内
这种"最大随机性"解释了为什么高斯分布是"默认"的噪声模型:如果我们只知道噪声的方差,不做任何其他假设,高斯分布是最合理的选择。
第五章:最大熵原理的应用
5.1 统计物理
最大熵原理在统计物理中有着根本性的作用。
玻尔兹曼分布:
考虑一个热力学系统,微观状态 $i$ 的能量为 $E_i$。给定平均能量 $\langle E \rangle = U$,最大熵分布为:
其中 $Z = \sum_i e^{-\beta E_i}$ 是配分函数,$\beta = 1/(k_B T)$ 是逆温度。
这就是著名的玻尔兹曼分布,它是统计力学的基石。
麦克斯韦-玻尔兹曼速度分布:
对于理想气体,给定平均动能(即温度),分子速度的最大熵分布是高斯分布。这解释了为什么气体分子的速度服从高斯分布。
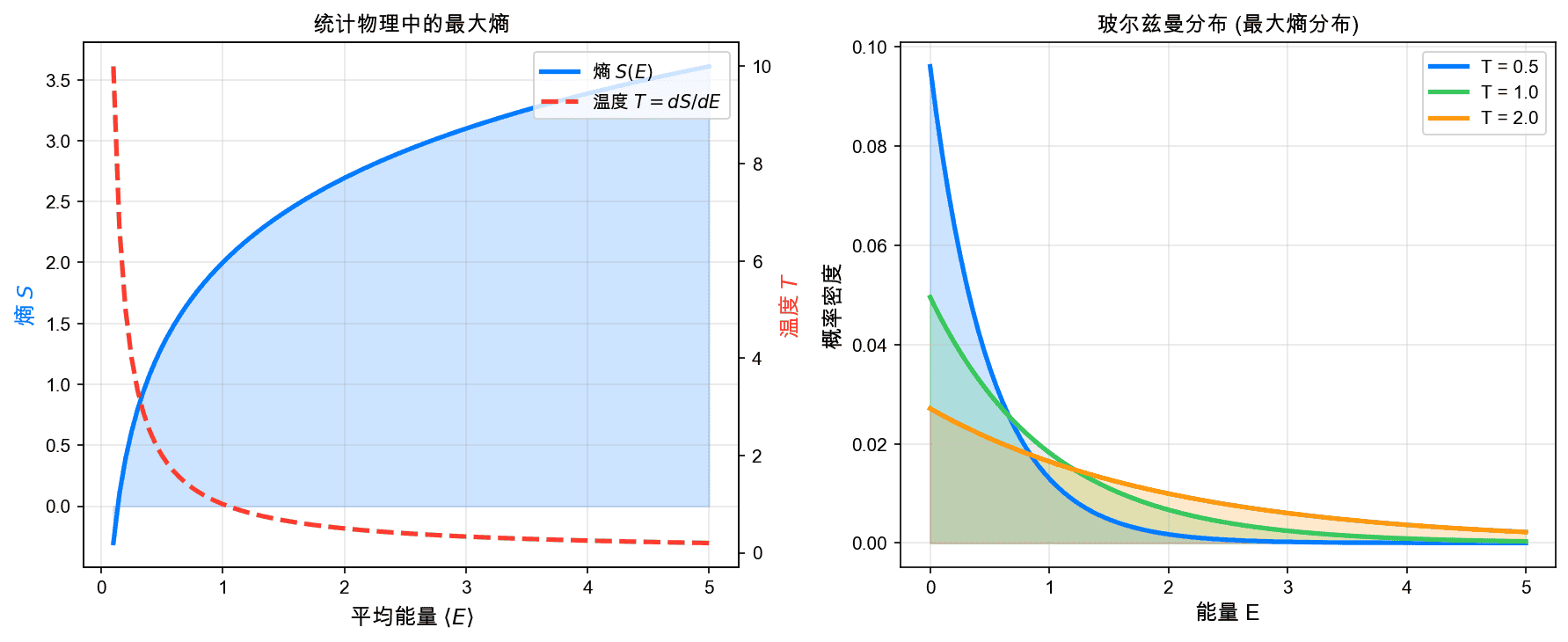
左图展示了统计物理中的熵-能量关系。右图展示了不同温度下的玻尔兹曼分布。
5.2 机器学习
最大熵模型(MaxEnt模型):
在自然语言处理中,最大熵模型(也称为对数线性模型)广泛用于文本分类、序列标注等任务。这些模型在满足特征约束的条件下最大化熵。
Dropout作为高斯近似:
在神经网络中,Dropout可以看作是对网络输出的高斯近似。这与最大熵原理一致:在给定一阶和二阶统计量的约束下,高斯分布是最合理的近似。
变分推断:
在变分自编码器(VAE)中,潜在变量的先验通常选择标准正态分布。这可以解释为最大熵选择:在零均值、单位方差的约束下,标准正态使熵最大化。
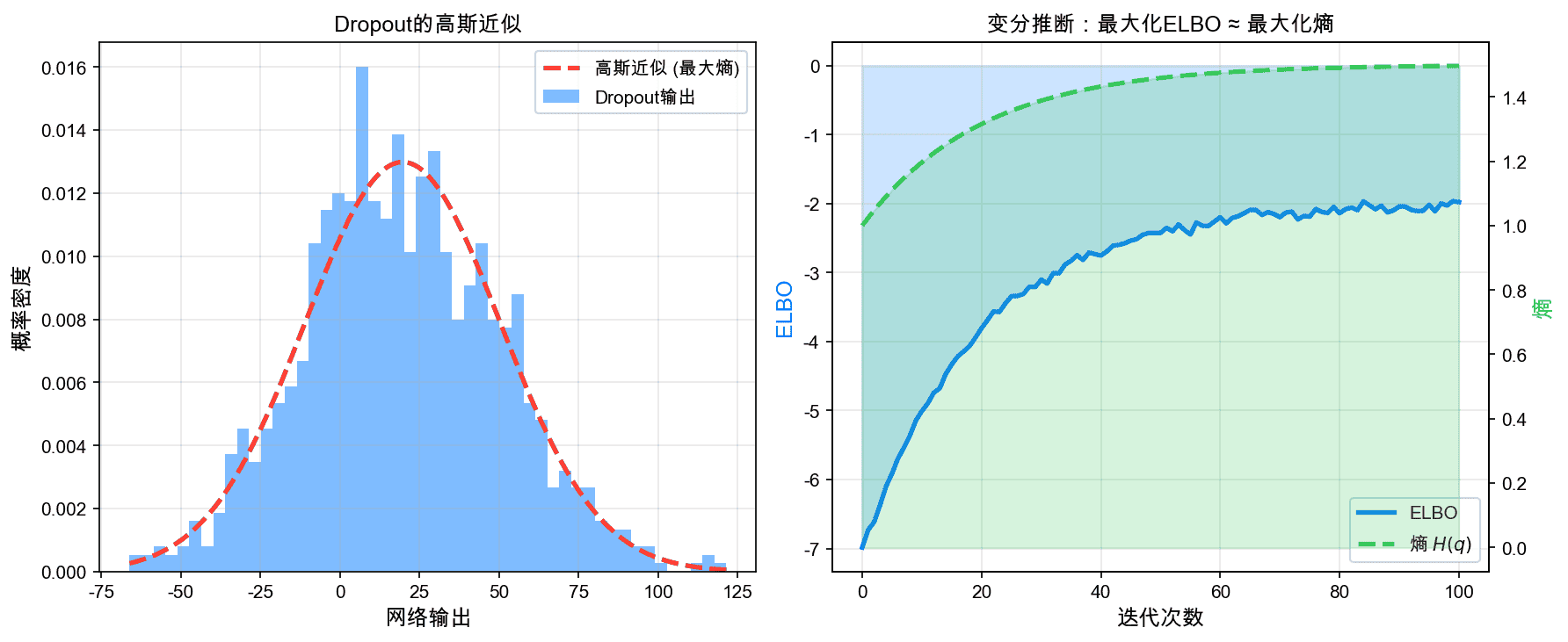
左图展示了Dropout输出的高斯近似。右图展示了变分推断中ELBO与熵的关系。
5.3 信号处理
谱估计:
在功率谱估计中,伯格最大熵谱估计(Burg’s Maximum Entropy Spectral Estimation)利用最大熵原理从有限的时间序列数据中估计功率谱。
图像重建:
在医学成像(如CT、MRI)中,最大熵方法用于从有限的投影数据中重建图像。这在数据不完整或噪声较大的情况下特别有用。
5.4 经济学与金融学
资产定价:
在衍生品定价中,最大熵方法用于从市场观测价格中推断风险中性概率分布。这提供了比传统Black-Scholes模型更灵活的定价框架。
投资组合优化:
最大熵原理可用于构建先验分布,结合贝叶斯方法进行稳健的投资组合优化。
第六章:推广与变体
6.1 Tsallis熵与q-高斯分布
Tsallis熵是香农熵的推广:
当 $q \to 1$ 时,Tsallis熵退化为香农熵。
最大化Tsallis熵(给定方差约束)得到q-高斯分布,它在金融时间序列分析、复杂系统研究中有广泛应用。
6.2 Rényi熵
Rényi熵是另一种推广:
Rényi熵在量子信息论、密码学中有重要应用。
6.3 相对熵与最小交叉熵
最小交叉熵原理(Minimum Cross-Entropy Principle)是最大熵原理的推广:给定先验分布 $q(x)$,在满足约束的条件下,选择与 $q(x)$ 交叉熵最小的分布 $p(x)$。
这等价于最小化 $D_{KL}(p || q)$。当先验 $q$ 是均匀分布时,退化为最大熵原理。
结语
最大熵原理是数理统计学中最优雅的定理之一。它告诉我们:在已知有限的约束条件下,高斯分布是"最自然"的选择——它保留了最大的不确定性,假设了最少的信息,不做任何多余的推断。
这一结果不仅解释了为什么高斯分布在自然界中如此普遍,更为统计推断提供了一个坚实的理论基础。从热噪声到测量误差,从布朗运动到生物统计,高斯分布无处不在,而最大熵原理揭示了其背后的深刻原因。
让我们回顾本文的核心要点:
最大熵原理:在满足已知约束的条件下,选择使熵最大化的概率分布。这是"最无偏"的选择。
高斯分布的最大熵性质:在给定均值和方差的条件下,高斯分布使熵最大化。其最大熵值为 $H = \frac{1}{2}\log(2\pi e \sigma^2)$。
证明方法:可以使用变分法(拉格朗日乘子)或Gibbs不等式严格证明这一结果。
自然界的选择:高斯分布的普遍性可以通过中心极限定理和最大熵原理理解:大量独立效应叠加"最大化"了熵,导致高斯分布。
广泛应用:从统计物理的玻尔兹曼分布,到机器学习的Dropout和变分推断;从信号处理的谱估计,到金融学的资产定价——最大熵原理无处不在。
正如杰恩斯所言:“最大熵原理不是一条物理定律,而是一种推理规则。它告诉我们如何在不完全信息下进行最优推断。“在数据和不确定性无处不在的世界里,这个规则显得尤为重要。
延伸阅读:
- Jaynes, E.T. (1957). Information theory and statistical mechanics. Physical Review, 106(4), 620.
- Shannon, C.E. (1948). A mathematical theory of communication. Bell System Technical Journal, 27(3), 379-423.
- Cover, T.M. & Thomas, J.A. (2006). Elements of Information Theory (2nd ed.). Wiley.
- MacKay, D.J. (2003). Information Theory, Inference, and Learning Algorithms. Cambridge University Press.
学习路径建议:
- 基础阶段:理解香农熵的定义和基本性质,熟悉高斯分布的熵计算公式
- 进阶阶段:掌握最大熵原理的直观理解,能独立推导不同约束下的最大熵分布
- 深入阶段:理解最大熵原理与统计物理的联系,掌握变分法和拉格朗日乘子的应用
- 拓展阶段:研究Tsallis熵、Rényi熵等推广形式,探索最大熵方法在机器学习中的应用
愿你在信息、概率与推断的交织中,发现数学与自然之间深刻的和谐。