引言:当随机遇见确定
在赌场里,单个赌徒的输赢完全是随机的——有人一夜暴富,有人倾家荡产。但如果你站在赌场老板的视角,看到的是完全不同的景象:无论今天哪个赌徒赢了多少钱,长期来看,赌场总是稳赚不赔。这不是运气,而是数学。
这种"随机中的确定性"正是概率论研究的核心。而在这座数学大厦的基石上,矗立着两座丰碑:大数定律(Law of Large Numbers)和中心极限定理(Central Limit Theorem)。它们一个告诉我们"均值会收敛到哪里",一个告诉我们"收敛的速度和分布形态"。
这两个定理不仅是统计学的理论基础,更是现代科学的支柱。从民意调查到机器学习,从金融风控到量子物理,它们无处不在。本文将带你深入理解这两个定理的数学本质、历史脉络和实际应用。
历史发展:从赌徒问题到现代概率论
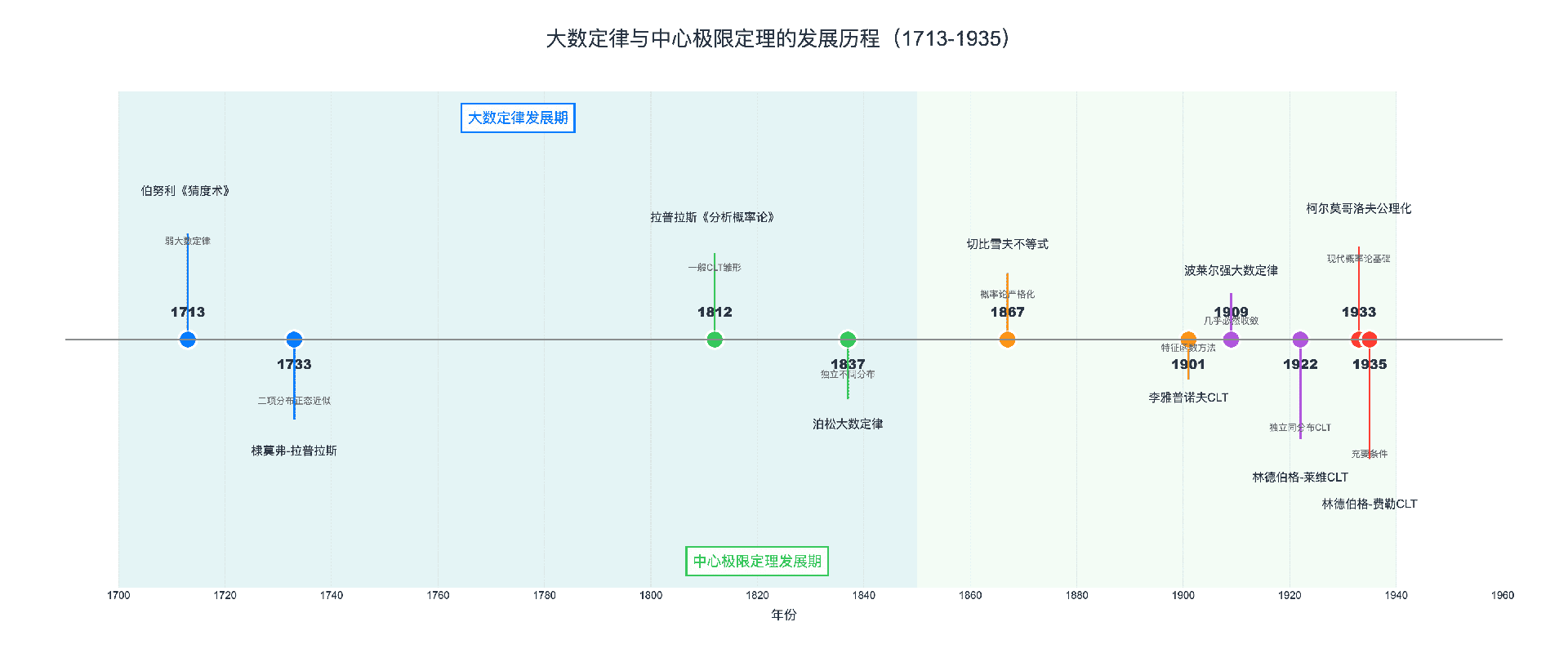
大数定律的历史演进
雅各布·伯努利与《猜度术》(1713)
大数定律的故事始于瑞士巴塞尔的伯努利家族。1713年,雅各布·伯努利(Jacob Bernoulli)的巨著《猜度术》(Ars Conjectandi)在他去世后出版。在这部著作中,伯努利证明了弱大数定律的第一个版本:如果我们反复抛一枚公平的硬币,正面出现的频率会收敛到 $1/2$。
伯努利的证明是革命性的。在那个时代,人们虽然直觉上相信"大样本能消除随机性",但没有人能严格证明这一点。伯努利用二项分布和复杂的级数运算,首次给出了数学上的严格证明。他在书中兴奋地写道:“即使最愚蠢的人,凭借某种本能,也清楚地知道,观测次数越多,观察结果与真实比率相符的可能性就越大。”
泊松的推广(1837)
1837年,法国数学家西莫恩·德尼·泊松(Siméon Denis Poisson)将大数定律推广到了更一般的情形。他证明了,即使试验不是相同分布的,只要满足一定条件,样本均值仍然会收敛到期望值的加权平均。这就是泊松大数定律。
切比雪夫与概率论的严格化(1867)
1867年,俄国数学家帕夫努季·切比雪夫(Pafnuty Chebyshev)发表了具有里程碑意义的论文。他提出了著名的切比雪夫不等式:
$$P(|X - \mu| \geq k\sigma) \leq \frac{1}{k^2}$$
这个不等式虽然简单,却极其强大。它不需要知道随机变量的具体分布,就能给出偏离均值的概率上界。利用这个不等式,切比雪夫给出了大数定律的一个简洁证明,将概率论推向了新的严格化高度。
波莱尔的强大数定律(1909)
1909年,法国数学家埃米尔·波莱尔(Émile Borel)证明了强大数定律:硬币正面频率不仅依概率收敛到 $1/2$,而且几乎必然(almost surely)收敛。这意味着,不收敛的情况发生的概率为零。
波莱尔的工作引入了测度论的语言,为现代概率论奠定了基础。
柯尔莫哥洛夫的公理化(1933)
1933年,俄国数学家安德雷·柯尔莫哥洛夫(Andrey Kolmogorov)发表了《概率论基础》,将概率论严格建立在测度论的基础上。在这套体系中,大数定律有了最一般的表述形式,适用于各种随机变量序列。
中心极限定理的探索之路
棣莫弗与拉普拉斯的发现(1733-1812)
1733年,法国数学家亚伯拉罕·棣莫弗(Abraham de Moivre)在研究二项分布时发现了惊人的现象:当试验次数很大时,二项分布的形状会越来越像一个"钟形曲线"。
具体来说,如果 $X \sim \text{Binomial}(n, p)$,那么当 $n \to \infty$ 时:
$$\frac{X - np}{\sqrt{np(1-p)}} \xrightarrow{d} N(0, 1)$$
1812年,皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace)在《分析概率论》中系统发展了这一理论,将其推广到了更一般的情形。这就是著名的棣莫弗-拉普拉斯定理。
李雅普诺夫的关键突破(1901)
1901年,俄国数学家亚历山大·李雅普诺夫(Alexander Lyapunov)引入了特征函数方法,证明了更一般的中心极限定理。他的方法优雅而强大,成为证明CLT的标准工具。
特征函数 $\varphi_X(t) = E[e^{itX}]$ 完全刻画了随机变量的分布。李雅普诺夫证明,独立随机变量之和的特征函数会收敛到正态分布的特征函数,从而证明了CLT。
林德伯格-莱维定理(1922)
1922年,芬兰数学家约尔马·林德伯格(Jarl Waldemar Lindeberg)和法国数学家保罗·皮埃尔·莱维(Paul Pierre Lévy)独立证明了独立同分布情形下的中心极限定理:
设 $X_1, X_2, \ldots$ 是独立同分布的随机变量,$E[X_i] = \mu$,$\text{Var}(X_i) = \sigma^2 < \infty$,则
$$\frac{\bar{X}_n - \mu}{\sigma/\sqrt{n}} \xrightarrow{d} N(0, 1)$$
林德伯格-费勒定理(1935)
1935年,林德伯格和美国人威廉·费勒(William Feller)证明了CLT的充要条件——林德伯格条件:
$$\lim_{n \to \infty} \frac{1}{s_n^2} \sum_{k=1}^n E[(X_k - \mu_k)^2 \cdot \mathbf{1}_{|X_k - \mu_k| > \varepsilon s_n}] = 0$$
这个条件给出了CLT成立的最弱假设,标志着经典CLT理论的完善。
第一章:大数定律——均值收敛的数学保证
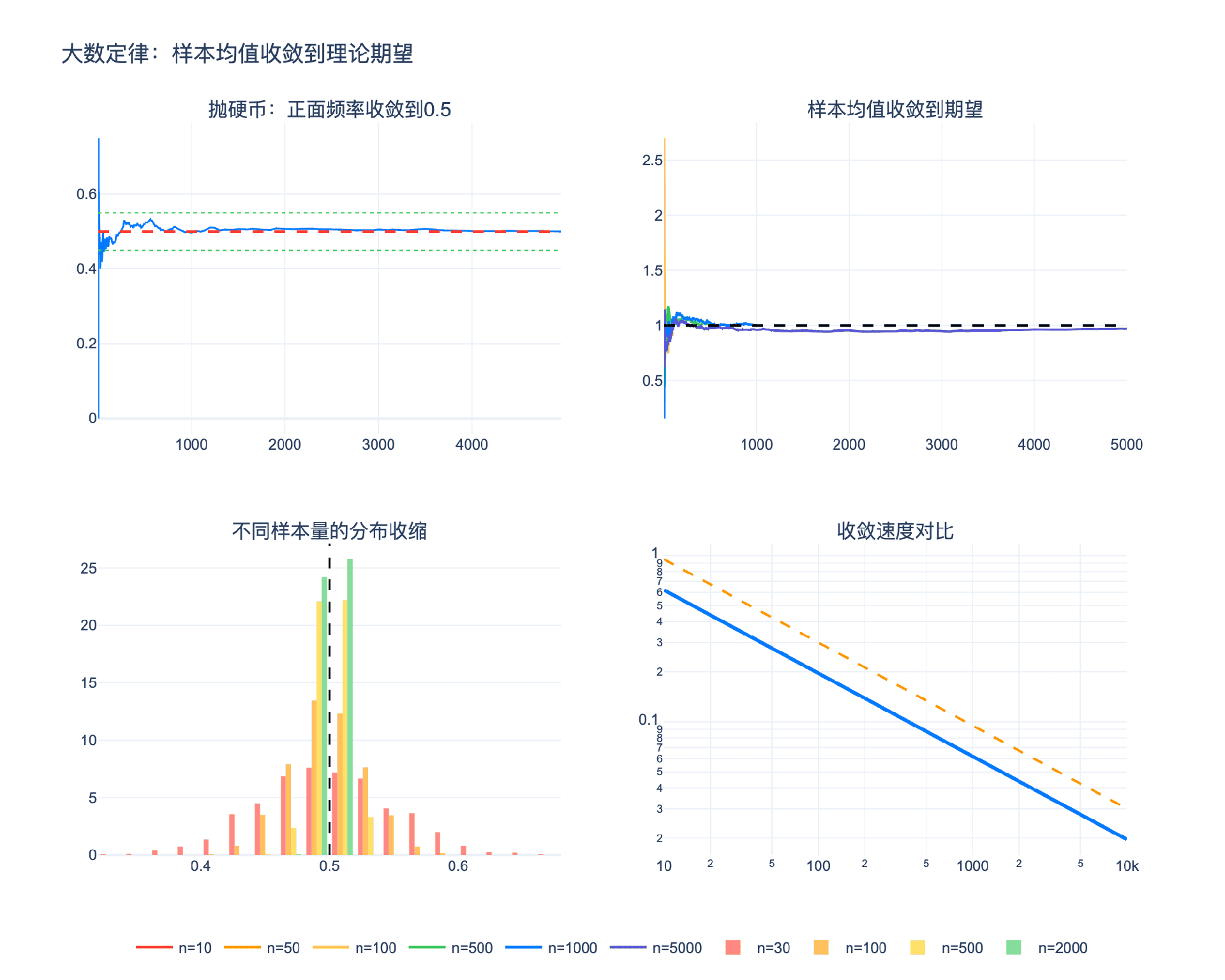
1.1 直观理解:频率的稳定性
想象你在抛一枚公平的硬币。前10次抛掷可能很不均衡——比如7次正面、3次反面。但随着抛掷次数增加到100次、1000次、10000次,正面出现的比例会越来越接近 $50%$。
这不是巧合,而是大数定律在起作用。它告诉我们:当样本量足够大时,样本均值会以很高的概率接近理论期望。
更精确地说,设 $X_1, X_2, \ldots, X_n$ 是独立同分布的随机变量,$E[X_i] = \mu$。定义样本均值:
$$\bar{X}n = \frac{1}{n}\sum{i=1}^n X_i$$
大数定律断言:$\bar{X}_n \to \mu$(在某种意义下)。
1.2 弱大数定律(WLLN)
定理(弱大数定律):设 $X_1, X_2, \ldots$ 是独立同分布随机变量,$E[X_i] = \mu$,$\text{Var}(X_i) = \sigma^2 < \infty$。则对任意 $\varepsilon > 0$:
$$\lim_{n \to \infty} P(|\bar{X}_n - \mu| \geq \varepsilon) = 0$$
记作 $\bar{X}_n \xrightarrow{P} \mu$(依概率收敛)。
证明(使用切比雪夫不等式):
首先计算 $\bar{X}_n$ 的期望和方差:
$$E[\bar{X}n] = E\left[\frac{1}{n}\sum{i=1}^n X_i\right] = \frac{1}{n}\sum_{i=1}^n E[X_i] = \mu$$
$$\text{Var}(\bar{X}n) = \text{Var}\left(\frac{1}{n}\sum{i=1}^n X_i\right) = \frac{1}{n^2}\sum_{i=1}^n \text{Var}(X_i) = \frac{\sigma^2}{n}$$
应用切比雪夫不等式:
$$P(|\bar{X}_n - \mu| \geq \varepsilon) \leq \frac{\text{Var}(\bar{X}_n)}{\varepsilon^2} = \frac{\sigma^2}{n\varepsilon^2}$$
当 $n \to \infty$ 时,右边趋于0,得证。
关键点:弱大数定律只要求方差有限,条件相当宽松。收敛速度是 $O(1/n)$,这意味着样本量需要增加4倍才能将误差减半。
1.3 强大数定律(SLLN)
弱大数定律告诉我们,偏离期望的概率趋于0。但它没有排除这样一种可能:偶尔(虽然概率越来越小)会出现很大的偏离。
强大数定律给出了更强的结论:样本均值几乎必然收敛到期望。
定理(柯尔莫哥洛夫强大数定律):设 $X_1, X_2, \ldots$ 是独立同分布随机变量,$E|X_i| < \infty$,$E[X_i] = \mu$。则
$$P\left(\lim_{n \to \infty} \bar{X}_n = \mu\right) = 1$$
记作 $\bar{X}_n \xrightarrow{a.s.} \mu$(几乎必然收敛)。
直观区别:
- WLLN:对于任意固定的 $\varepsilon$,$|\bar{X}_n - \mu| \geq \varepsilon$ 的概率趋于0
- SLLN:$\bar{X}_n$ 的序列本身几乎一定收敛到 $\mu$,大偏离几乎不会发生
证明思路(简化版):
强大数定律的证明需要更精细的工具,如波莱尔-坎泰利引理和柯尔莫哥洛夫三级数定理。核心思想是:证明偏离事件的总概率有限,从而根据波莱尔-坎泰利引理,偏离事件几乎必然只发生有限次。
1.4 大数定律的收敛速度
大数定律告诉我们样本均值会收敛,但没有告诉我们收敛有多快。了解收敛速度对实际应用至关重要。
切比雪夫界限:
从弱大数定律的证明中,我们得到:
$$P(|\bar{X}_n - \mu| \geq \varepsilon) \leq \frac{\sigma^2}{n\varepsilon^2}$$
反过来,如果我们希望 $|\bar{X}_n - \mu| < \varepsilon$ 的概率至少为 $1-\alpha$,需要:
$$n \geq \frac{\sigma^2}{\alpha\varepsilon^2}$$
这就是切比雪夫样本量公式。
实际意义:要使估计误差在 $\pm 0.01$ 以内(以95%的置信度),如果总体方差 $\sigma^2 = 1$,需要样本量:
$$n \geq \frac{1}{0.05 \times 0.01^2} = 200{,}000$$
这个样本量相当大!幸运的是,如果我们知道更多关于分布的信息(如使用中心极限定理),可以得到更精确的估计。
第二章:中心极限定理——分布收敛的普遍规律
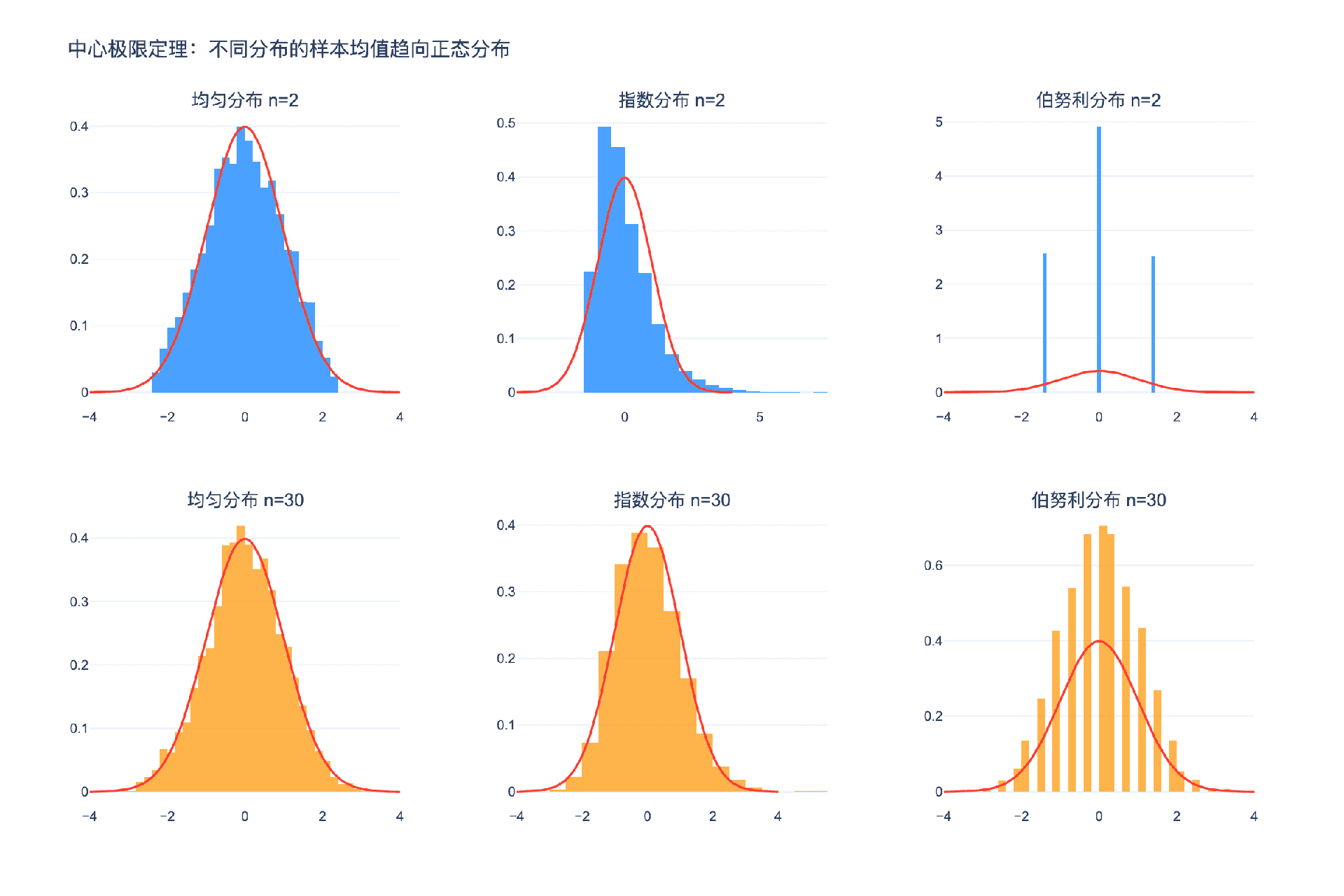
2.1 直观理解:钟形曲线的普遍性
中心极限定理可能是概率论中最令人惊奇的定理。它告诉我们:无论原始分布是什么形状,只要样本量足够大,样本均值的分布都会趋向于正态分布。
这解释了为什么正态分布(高斯分布、钟形曲线)在自然界中如此普遍:
- 人的身高、体重受众多随机因素影响,它们的综合效果趋向正态
- 测量误差由无数微小因素叠加而成,趋向正态
- 金融市场的收益率由无数交易者的决策叠加而成,近似正态
CLT的深刻之处在于:它不要求我们知道原始分布的具体形式,只要独立同分布、方差有限,结论就成立。
2.2 经典中心极限定理
定理(林德伯格-莱维中心极限定理):设 $X_1, X_2, \ldots$ 是独立同分布随机变量,$E[X_i] = \mu$,$\text{Var}(X_i) = \sigma^2 < \infty$。定义标准化样本均值:
$$Z_n = \frac{\bar{X}n - \mu}{\sigma/\sqrt{n}} = \frac{\sum{i=1}^n X_i - n\mu}{\sigma\sqrt{n}}$$
则当 $n \to \infty$ 时,$Z_n$ 的分布收敛到标准正态分布:
$$Z_n \xrightarrow{d} N(0, 1)$$
即对任意实数 $z$:
$$\lim_{n \to \infty} P(Z_n \leq z) = \Phi(z) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^z e^{-t^2/2}dt$$
证明(使用特征函数):
设 $\varphi_X(t) = E[e^{itX}]$ 是 $X$ 的特征函数。由于 $E[X] = \mu$,$\text{Var}(X) = \sigma^2$,有:
$$\varphi_X(t) = 1 + it\mu - \frac{t^2(\sigma^2 + \mu^2)}{2} + o(t^2)$$
设 $Y_i = X_i - \mu$,则 $E[Y_i] = 0$,$\text{Var}(Y_i) = \sigma^2$。我们需要分析:
$$Z_n = \frac{1}{\sigma\sqrt{n}}\sum_{i=1}^n Y_i$$
$Z_n$ 的特征函数为:
$$\varphi_{Z_n}(t) = E\left[\exp\left(\frac{it}{\sigma\sqrt{n}}\sum_{j=1}^n Y_j\right)\right] = \left[\varphi_Y\left(\frac{t}{\sigma\sqrt{n}}\right)\right]^n$$
对于小 $t$,利用泰勒展开:
$$\varphi_Y(t) = 1 - \frac{\sigma^2 t^2}{2} + o(t^2)$$
因此:
$$\varphi_{Z_n}(t) = \left[1 - \frac{t^2}{2n} + o\left(\frac{1}{n}\right)\right]^n \to e^{-t^2/2}$$
这正是标准正态分布的特征函数!根据连续性定理(莱维),特征函数的收敛蕴含分布的收敛,证毕。
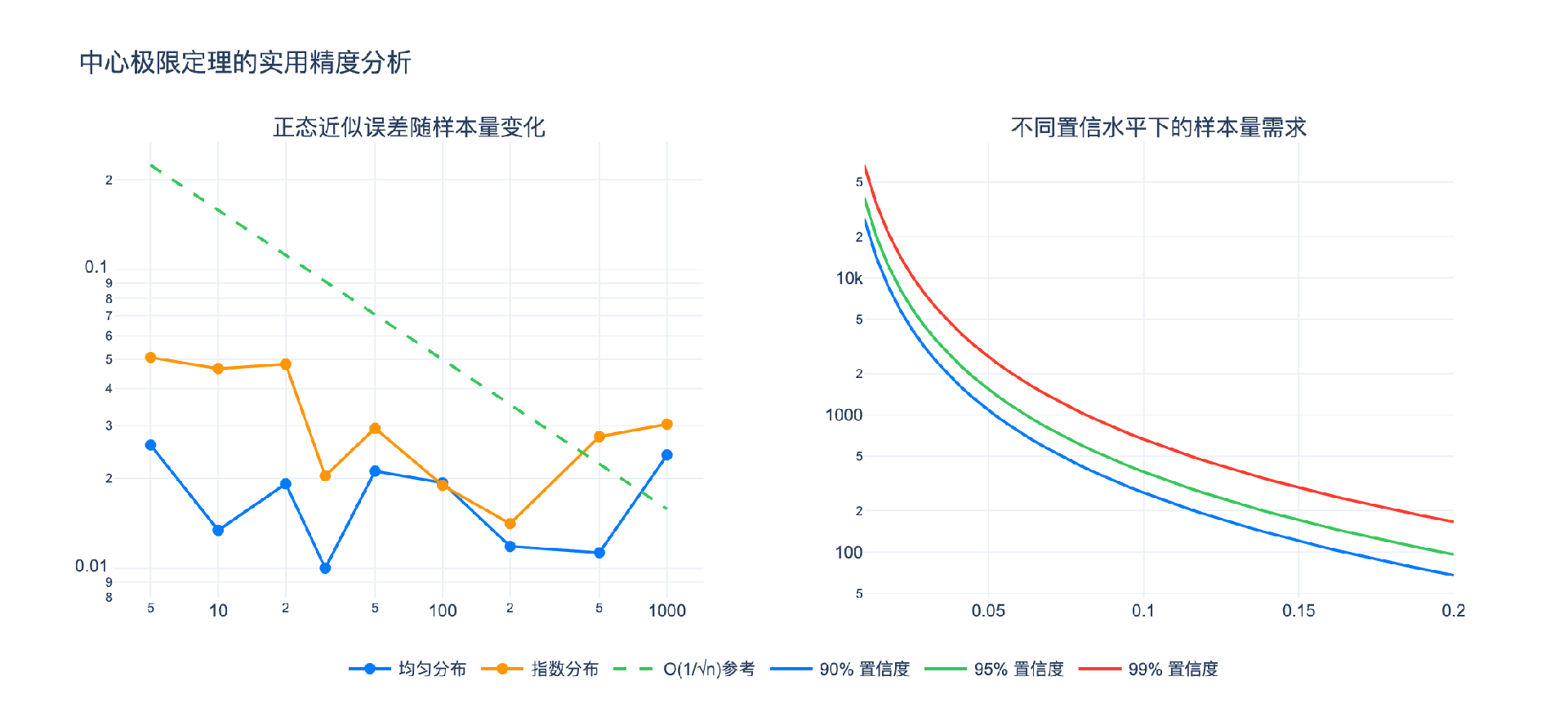
2.3 不同分布的CLT收敛速度
虽然CLT保证了渐近正态性,但"渐近"有多快取决于原始分布的性质。
良好情况:对称、单峰、轻尾的分布
- 均匀分布:$n \approx 10$ 就相当正态
- 三角分布:$n \approx 5$ 就很接近
困难情况:偏斜、重尾或多峰的分布
- 指数分布:需要 $n \approx 50$ 或更大
- 柯西分布:不满足CLT,因为方差无穷大
- 伯努利分布($p$ 接近0或1):需要较大 $n$
Berry-Esseen定理给出了CLT收敛速度的定量界限:
$$\sup_{z \in \mathbb{R}} |P(Z_n \leq z) - \Phi(z)| \leq \frac{C \rho}{\sigma^3 \sqrt{n}}$$
其中 $\rho = E|X - \mu|^3$ 是三阶绝对矩,$C$ 是常数(约为0.4748)。
2.4 CLT的几种形式
棣莫弗-拉普拉斯定理(二项分布的特殊情形):
设 $X \sim \text{Binomial}(n, p)$,则
$$\frac{X - np}{\sqrt{np(1-p)}} \xrightarrow{d} N(0, 1)$$
这是历史上第一个CLT,也是二项分布正态近似的基础。
李雅普诺夫CLT(非同分布情形):
设 $X_1, X_2, \ldots$ 独立但不必同分布,$E[X_i] = \mu_i$,$\text{Var}(X_i) = \sigma_i^2$。若对某个 $\delta > 0$:
$$\frac{\sum_{i=1}^n E|X_i - \mu_i|^{2+\delta}}{\left(\sum_{i=1}^n \sigma_i^2\right)^{(2+\delta)/2}} \to 0$$
则CLT成立。
林德伯格-费勒定理(最一般形式):
CLT成立的充要条件是林德伯格条件:对任意 $\varepsilon > 0$,
$$\lim_{n \to \infty} \frac{1}{s_n^2} \sum_{k=1}^n E[(X_k - \mu_k)^2 \cdot \mathbf{1}_{|X_k - \mu_k| > \varepsilon s_n}] = 0$$
其中 $s_n^2 = \sum_{k=1}^n \sigma_k^2$。
林德伯格条件的直观意义是:没有单个随机变量对总和的贡献过大。
第三章:两个定理的关系与互补性
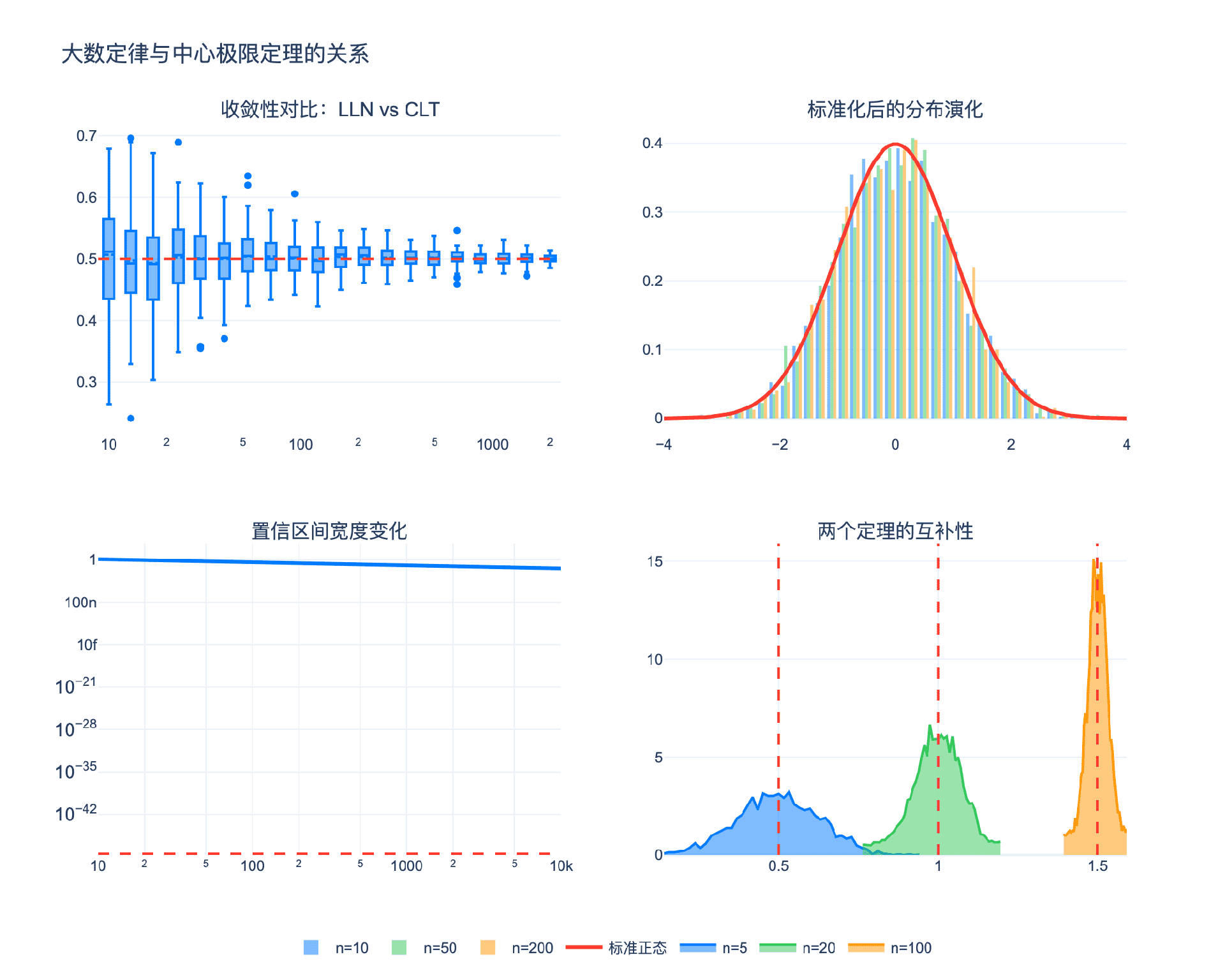
3.1 收敛层次的区别
大数定律和中心极限定理都研究样本均值的渐近行为,但它们回答的是不同层次的问题:
| 特性 | 大数定律 (LLN) | 中心极限定理 (CLT) |
|---|---|---|
| 收敛对象 | 常数(期望 $\mu$) | 分布(标准正态) |
| 收敛类型 | 依概率/几乎必然 | 依分布 |
| 信息层次 | 一阶(位置) | 二阶(波动) |
| 尺度 | 原始尺度 | 标准化尺度 $\sqrt{n}$ |
| 速度信息 | 粗略($O(1/n)$) | 精确($O(1/\sqrt{n})$) |
数学关系:
CLT蕴含WLLN。因为若
$$\frac{\bar{X}_n - \mu}{\sigma/\sqrt{n}} \xrightarrow{d} N(0, 1)$$
则分母趋于无穷,分子必须依概率趋于0,即 $\bar{X}_n \xrightarrow{P} \mu$。
但反过来不成立:LLN成立时CLT可能不成立(如柯西分布,LLN不成立,CLT也不成立;但存在LLN成立而CLT不成立的例子)。
3.2 尺度变换的奥秘
为什么CLT需要考虑 $\sqrt{n}$ 的尺度?这是理解两个定理关系的关键。
设 $S_n = \sum_{i=1}^n X_i$。根据LLN:
$$\frac{S_n}{n} \to \mu$$
即 $S_n \approx n\mu$。这个近似的误差是多少?
定义 离差 $D_n = S_n - n\mu = \sum_{i=1}^n (X_i - \mu)$。
由中心极限定理:
$$\frac{D_n}{\sigma\sqrt{n}} \xrightarrow{d} N(0, 1)$$
即 $D_n = O_p(\sqrt{n})$。离差的增长速度是 $\sqrt{n}$,而不是 $n$。
关键洞察:
- 总和 $S_n$ 的主导项是 $n\mu$(线性增长)
- 波动 $D_n$ 是 $O(\sqrt{n})$(次线性增长)
- 因此 $\frac{S_n}{n} = \mu + \frac{D_n}{n} = \mu + O_p(1/\sqrt{n}) \to \mu$
这就是大数定律的微观机制:随机波动相对于总体增长可以忽略。
3.3 从两个定理到区间估计
结合LLN和CLT,我们可以构建样本均值的置信区间。
由CLT:
$$P\left(-z_{\alpha/2} \leq \frac{\bar{X}n - \mu}{\sigma/\sqrt{n}} \leq z{\alpha/2}\right) \to 1 - \alpha$$
重新整理:
$$P\left(\bar{X}n - z{\alpha/2}\frac{\sigma}{\sqrt{n}} \leq \mu \leq \bar{X}n + z{\alpha/2}\frac{\sigma}{\sqrt{n}}\right) \to 1 - \alpha$$
这就是渐近置信区间:
$$\bar{X}n \pm z{\alpha/2} \frac{\sigma}{\sqrt{n}}$$
置信区间的宽度 $2z_{\alpha/2}\sigma/\sqrt{n}$ 告诉我们估计的精度:
- 要减半误差,需要4倍样本
- 要十分之一的误差,需要100倍样本
这就是统计学的平方根法则。
第四章:实际应用场景
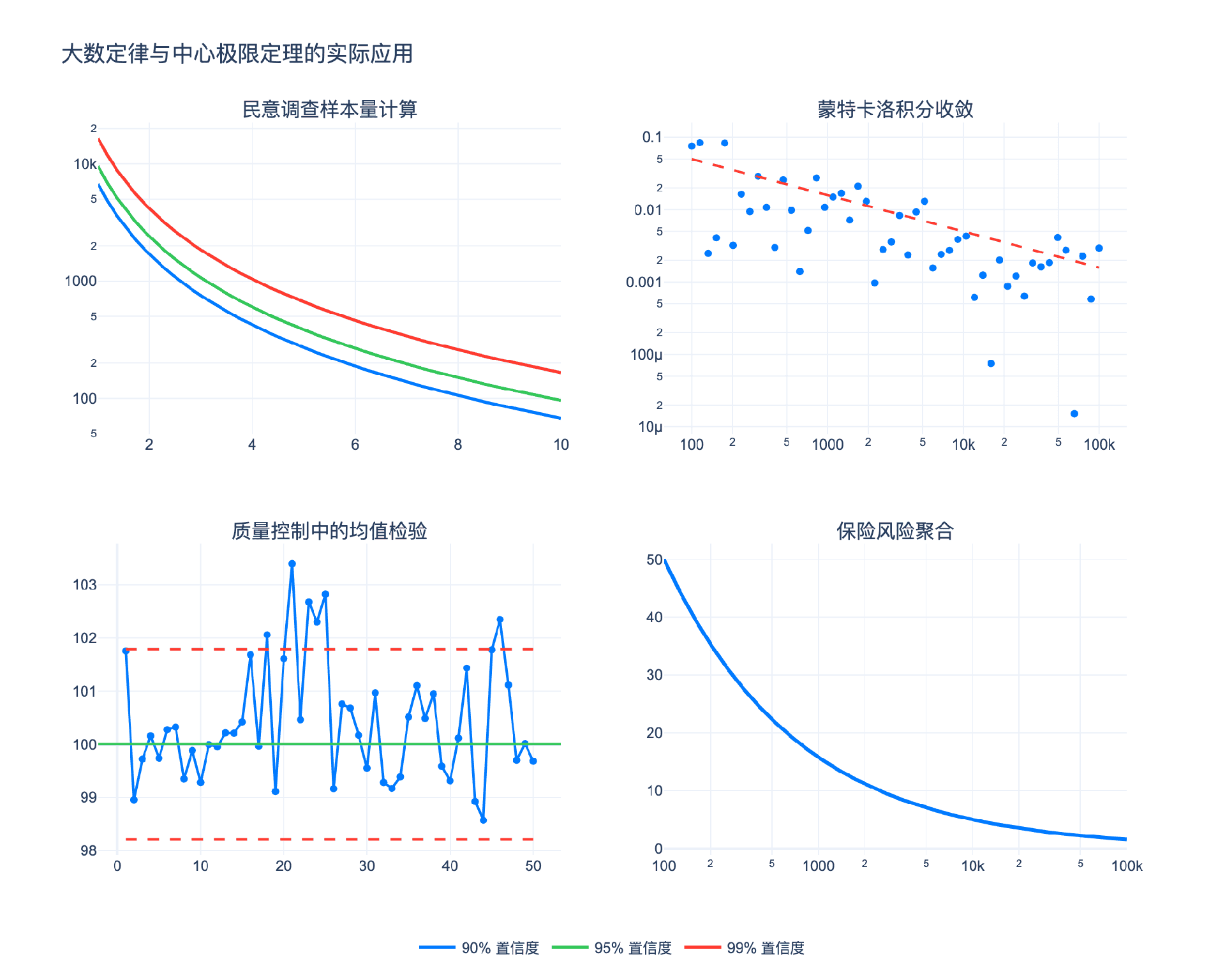
4.1 民意调查与样本量设计
新闻媒体经常报道:“本次调查的误差范围为 $\pm 3%$,置信度为95%。“这个结论如何得出?
假设我们要估计某候选人的支持率 $p$。调查 $n$ 个人,支持人数 $X \sim \text{Binomial}(n, p)$。样本比例 $\hat{p} = X/n$。
由CLT:
$$\frac{\hat{p} - p}{\sqrt{p(1-p)/n}} \approx N(0, 1)$$
95%置信区间为:
$$\hat{p} \pm 1.96\sqrt{\frac{p(1-p)}{n}}$$
保守估计:$p(1-p) \leq 1/4$(当 $p = 1/2$ 时取等)。因此误差界限:
$$\text{Margin of Error} \leq \frac{1.96}{2\sqrt{n}} = \frac{0.98}{\sqrt{n}}$$
若要求误差 $\leq 0.03$(3%):
$$n \geq \left(\frac{0.98}{0.03}\right)^2 \approx 1067$$
这就是为什么大多数民意调查的样本量在1000-2000之间。
4.2 蒙特卡洛积分
大数定律为蒙特卡洛方法提供了理论基础。
假设要计算定积分 $I = \int_0^1 f(x)dx$。生成 $n$ 个独立的均匀随机数 $U_1, \ldots, U_n \sim \text{Uniform}(0,1)$,则
$$\hat{I}n = \frac{1}{n}\sum{i=1}^n f(U_i) \xrightarrow{a.s.} E[f(U)] = \int_0^1 f(x)dx = I$$
由CLT,误差为:
$$\hat{I}_n - I \approx N\left(0, \frac{\sigma_f^2}{n}\right)$$
其中 $\sigma_f^2 = \text{Var}(f(U))$。
收敛速度:$O(1/\sqrt{n})$,与维度无关!
这使得蒙特卡洛方法在高维积分中具有优势。传统数值积分(如辛普森法则)的误差通常是 $O(n^{-k/d})$,其中 $d$ 是维度。当 $d$ 很大时,蒙特卡洛方法更优。
4.3 质量控制与过程监控
制造业中,控制图(Control Chart)利用CLT监控生产过程的稳定性。
假设某零件的设计尺寸为 $\mu = 100$mm,过程标准差 $\sigma = 2$mm。每批抽取 $n = 5$ 个样本,计算样本均值 $\bar{X}$。
由CLT,$\bar{X} \approx N(\mu, \sigma^2/n) = N(100, 0.8)$。
控制限通常设为 $\mu \pm 3\sigma/\sqrt{n}$:
- 上控制限 (UCL):$100 + 3 \times 2/\sqrt{5} \approx 102.68$
- 下控制限 (LCL):$100 - 3 \times 2/\sqrt{5} \approx 97.32$
若 $\bar{X}$ 落在控制限之外,说明过程可能失控(出现可归属原因)。
大数定律的作用:长期看,样本均值的平均值应接近 $\mu$。若持续偏离,说明过程存在系统误差。
4.4 保险与风险管理
保险公司承保大量独立(或弱相关)的风险。设第 $i$ 份保单的赔付为 $X_i$,$E[X_i] = \mu$,$\text{Var}(X_i) = \sigma^2$。
总赔付:$S_n = \sum_{i=1}^n X_i$
由LLN:$\frac{S_n}{n} \to \mu$,即每份保单的平均赔付趋于期望。
由CLT:$S_n \approx N(n\mu, n\sigma^2)$。
风险分散效应:
- 绝对风险(标准差):$\sqrt{n}\sigma$,随 $\sqrt{n}$ 增长
- 相对风险(变异系数):$\frac{\sqrt{n}\sigma}{n\mu} = \frac{\sigma}{\mu\sqrt{n}}$,随 $1/\sqrt{n}$ 衰减
因此,承保的保单越多,相对风险越小。这就是大数定律在保险中的核心作用:通过承保大量独立风险,保险公司可以准确预测总赔付,从而合理定价。
4.5 机器学习中的随机梯度下降
在机器学习中,随机梯度下降(SGD)利用LLN和CLT的理论基础。
设损失函数为 $L(\theta) = \frac{1}{N}\sum_{i=1}^N \ell_i(\theta)$。精确梯度下降需要计算所有 $N$ 个样本的梯度,计算量大。
SGD每步只采样一个小批量(mini-batch)$\mathcal{B}$,使用
$$\hat{g}(\theta) = \frac{1}{|\mathcal{B}|}\sum_{i \in \mathcal{B}} \nabla \ell_i(\theta)$$
由LLN,$\hat{g}(\theta) \approx \nabla L(\theta)$。由CLT,梯度估计的误差为 $O(1/\sqrt{|\mathcal{B}|})$。
权衡:
- 批量越大,梯度估计越准,收敛越稳定
- 批量越小,计算越快,但噪声越大
实践中,通常选择批量大小时在32-512之间。
第五章:常见误解与注意事项
5.1 “大数定律保证短期平衡”
误解:如果前10次抛硬币都是正面,第11次出现反面的概率会更高,以"平衡"频率。
真相:硬币没有记忆!每次抛掷都是独立的,正面概率始终是 $1/2$。大数定律说的是长期频率会趋于 $1/2$,而不是说短期会自我修正。
这种误解被称为赌徒谬误(Gambler’s Fallacy)。事实上,根据CLT,前 $n$ 次的结果之和偏离 $n/2$ 的量级是 $\sqrt{n}$,这个偏离不会被后续的抛掷"纠正”。
5.2 “CLT适用于任何样本量”
误解:只要有样本,CLT就能给出准确的正态近似。
真相:CLT是渐近定理,只有在 $n$ 足够大时才成立。“多大算大"取决于原始分布:
- 对称单峰分布:$n \geq 30$ 通常足够
- 强偏斜分布:可能需要 $n \geq 100$ 或更大
- 重尾分布(如 $t$ 分布自由度小):CLT收敛很慢
经验法则:检查样本的偏度和峰度。若偏度 $< 2$ 且峰度 $< 7$,CLT通常适用。
5.3 “CLT要求独立同分布”
误解:CLT只适用于i.i.d.情形。
真相:虽然经典CLT要求i.i.d.,但存在多种推广:
- 独立但不同分布:林德伯格-费勒CLT
- 弱相关序列:鞅差序列CLT、混合序列CLT
- 时间序列:在适当条件下,自相关序列也满足CLT
实际应用中,只要相关性不太强,CLT往往仍适用。
5.4 忽视重尾分布
危险:对于方差无穷大的重尾分布(如柯西分布、自由度 $\leq 2$ 的 $t$ 分布),CLT不适用。
在这种情况下:
- 样本均值不会收敛到正态
- 大数定律可能不成立(柯西分布的样本均值仍是柯西分布,不收敛)
检验方法:绘制QQ图检查正态性,或使用重尾稳健的统计方法。
结语:随机性的秩序
大数定律和中心极限定理揭示了随机现象背后隐藏的深刻秩序。
大数定律告诉我们:在随机性的海洋中,均值是一座稳定的灯塔。无论个体行为多么不可预测,群体的平均行为遵循确定的规律。这为科学实验、统计推断和风险管理提供了理论基础。
中心极限定理则进一步揭示:随机波动的形态也有普适规律。无论微观机制如何复杂,宏观波动总是趋向同一种优美的钟形曲线。这解释了为什么正态分布在自然界中如此普遍,也为统计推断提供了强大的工具。
这两个定理共同构成了概率论的基石,连接着微观随机与宏观确定、个体无序与群体有序。它们不仅是数学的瑰宝,更是人类理解不确定性的智慧结晶。
正如概率论先驱波莱尔所言:“概率论是理性的指南,它教会我们在不确定的世界中做出明智的决策。“大数定律和中心极限定理,正是这指南中最明亮的灯塔。
参考文献:
- Durrett, R. (2019). Probability: Theory and Examples (5th ed.). Cambridge University Press.
- Billingsley, P. (2012). Probability and Measure (Anniversary ed.). Wiley.
- Feller, W. (1968, 1971). An Introduction to Probability Theory and Its Applications, Vol. 1 & 2. Wiley.
- Le Cam, L. (1986). The Central Limit Theorem Around 1935. Statistical Science, 1(1), 78-91.
- 李贤平. (2010). 《概率论基础》 (3rd ed.). 高等教育出版社.
- 钟开莱. (2001). 《概率论教程》. 机械工业出版社.
- 陈希孺. (2009). 《数理统计学简史》. 湖南教育出版社.