引言:如何在不确定中做最优决策
想象你是一名雷达操作员,屏幕上突然出现一个光点。是敌机还是飞鸟?这个判断必须在几秒钟内做出,而且代价巨大:如果误判为飞鸟,可能错失拦截敌机的最佳时机;如果误判为敌机,可能引发不必要的冲突。
这就是假设检验面临的经典困境。我们有两种可能的"假设":
- 零假设 $H_0$:屏幕上的是飞鸟(无害)
- 备择假设 $H_1$:屏幕上的是敌机(危险)
基于观测数据(雷达回波),我们需要决定是否拒绝 $H_0$。但无论选择什么策略,都可能犯错:
- 第一类错误(假阳性):把飞鸟当成敌机
- 第二类错误(假阴性):把敌机当成飞鸟
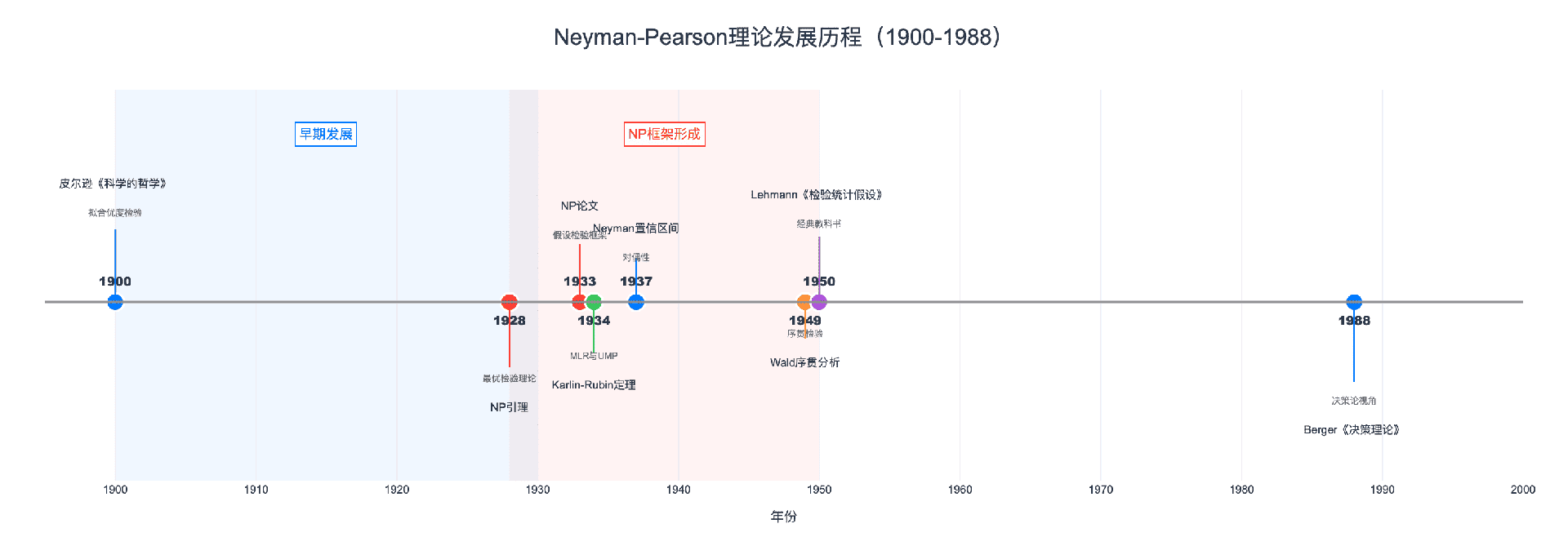
1928年,两位年轻数学家耶日·内曼(Jerzy Neyman)和埃贡·皮尔逊(Egon Pearson)提出了一种革命性的方法:在控制第一类错误概率的前提下,最小化第二类错误概率。这就是著名的Neyman-Pearson引理,它为统计假设检验奠定了坚实的数学基础。
本文将带你深入理解这一重要定理的历史背景、数学本质和实际应用。
历史发展:从卡尔·皮尔逊到Neyman-Pearson框架
早期拟合优度检验(1900年前后)
假设检验的思想可以追溯到18世纪,但现代形式的假设检验始于卡尔·皮尔逊(Karl Pearson)。1900年,皮尔逊发表了著名的卡方拟合优度检验,用于检验观测数据是否符合某个理论分布。
皮尔逊的方法本质上是计算观测值与期望值之间的"距离",然后根据卡方分布判断这个距离是否"过大"。然而,皮尔逊的框架有一个重要缺陷:它没有明确考虑备择假设,只是检验数据是否"拟合"某个分布。
Neyman-Pearson引理的诞生(1928)
1928年,卡尔·皮尔逊的学生埃贡·皮尔逊与波兰数学家耶日·内曼合作,发表了题为《关于统计假设有效性的问题》的论文。这篇论文提出了一个简单却深刻的原理:
在所有显著性水平为 $\alpha$ 的检验中,似然比检验具有最大的功效。
这就是Neyman-Pearson引理,它首次给出了"最优检验"的数学定义和构造方法。
Neyman-Pearson理论的完善(1933-1960)
1933年,内曼和皮尔逊发表了系列论文《论统计假设检验中最有效检验的问题》,系统建立了假设检验的数学框架,包括:
- 显著性水平 $\alpha$ 的正式定义
- 功效函数(power function)的概念
- 一致最优势检验(UMP)的理论
- 对偶性原理(检验与置信区间的对偶)
1934年,萨缪尔·卡尔林(Samuel Karlin)和赫尔曼·鲁宾(Herman Rubin)证明了Karlin-Rubin定理,将Neyman-Pearson引理推广到复合假设情形,为一致最优势检验提供了判定准则。
1949年,亚伯拉罕·瓦尔德(Abraham Wald)发展了序贯概率比检验(SPRT),将NP框架扩展到序贯分析领域。
1950年,埃里希·莱曼(Erich Lehmann)出版了《检验统计假设》,这部经典著作系统总结了NP理论,成为几代统计学家的标准教材。
第一章:假设检验的基本概念
1.1 统计假设与检验
统计假设是关于总体分布或参数的陈述。在假设检验中,我们通常有两个对立的假设:
- 零假设(Null Hypothesis)$H_0$:通常表示"无效应"、“无差异"或现状
- 备择假设(Alternative Hypothesis)$H_1$:表示研究者想要证明的效应或差异
例子:
- 药物试验:$H_0$: 新药与安慰剂效果相同;$H_1$: 新药效果更好
- 质量检测:$H_0$: 产品合格;$H_1$: 产品不合格
- 雷达检测:$H_0$: 无目标;$H_1$: 有目标
检验(Test)是基于样本数据做出决策的规则。形式上,检验是一个函数 $\phi(x)$:
$$\phi(x) = \begin{cases} 1 & \text{拒绝 } H_0 \ 0 & \text{接受 } H_0 \end{cases}$$
或者用拒绝域表示:若样本 $x \in R$,则拒绝 $H_0$。
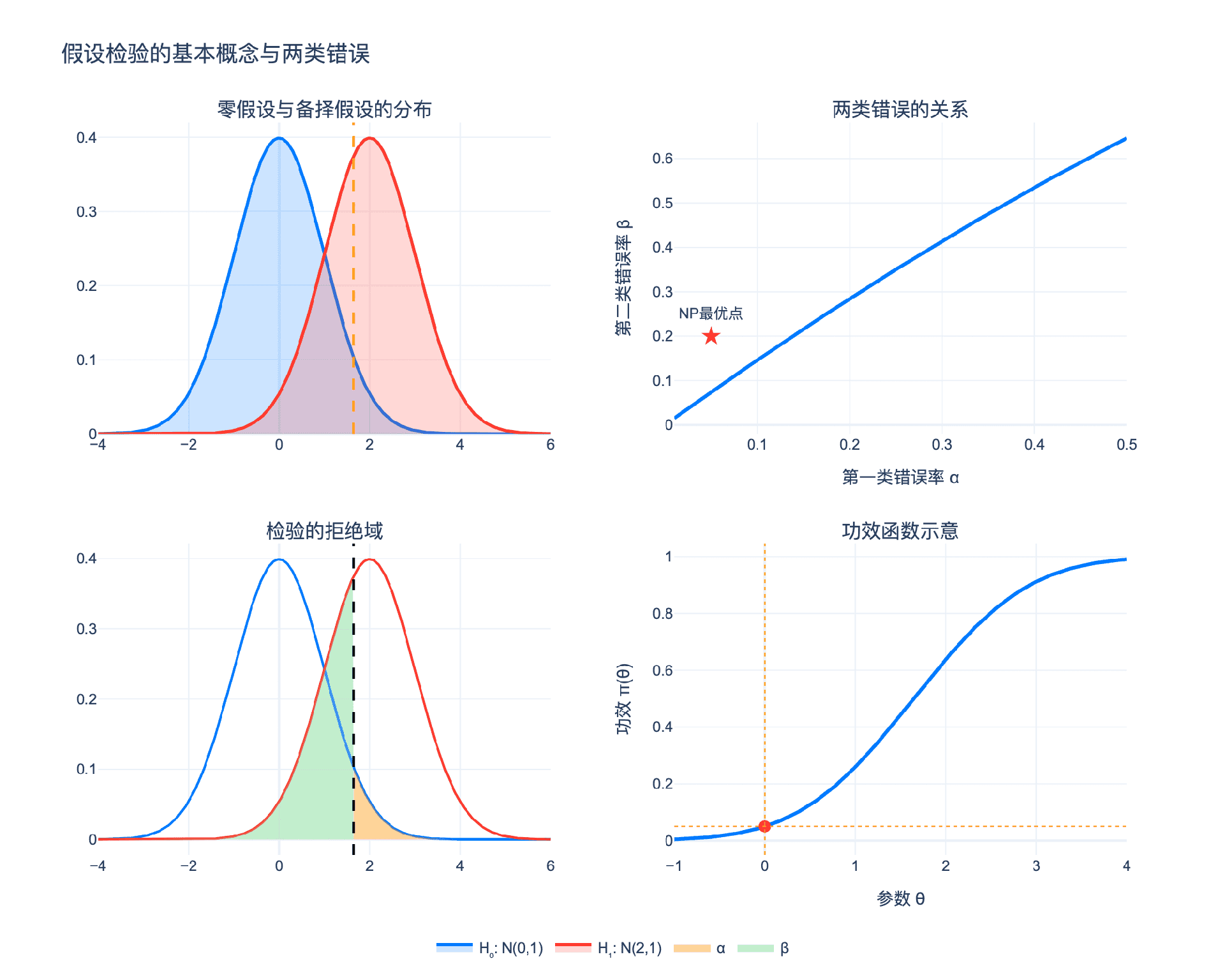
1.2 两类错误
由于样本的随机性,检验可能犯两类错误:
| 实际情况 \ 决策 | 接受 $H_0$ | 拒绝 $H_0$ |
|---|---|---|
| $H_0$ 为真 | ✓ 正确 | ✗ 第一类错误(假阳性) |
| $H_1$ 为真 | ✗ 第二类错误(假阴性) | ✓ 正确 |
第一类错误概率(显著性水平):
$$\alpha = P(\text{拒绝 } H_0 \mid H_0 \text{ 为真})$$
第二类错误概率:
$$\beta = P(\text{接受 } H_0 \mid H_1 \text{ 为真})$$
功效(Power):
$$\pi = 1 - \beta = P(\text{拒绝 } H_0 \mid H_1 \text{ 为真})$$
关键问题:如何权衡这两类错误?
直观上,我们希望同时最小化 $\alpha$ 和 $\beta$。但这两者之间存在权衡:降低 $\alpha$ 会使拒绝域变小,从而增加 $\beta$;反之亦然。
1.3 Neyman-Pearson范式
Neyman和Pearson提出了一个明智的解决方案:
首先控制第一类错误概率不超过某个水平 $\alpha$(如0.05),然后在此约束下最大化功效(最小化 $\beta$)。
这就是Neyman-Pearson范式,它解决了假设检验中的基本权衡问题。
数学上,这是一个约束优化问题:
$$\max_{\phi} \pi(\phi) \quad \text{s.t.} \quad \alpha(\phi) \leq \alpha_0$$
Neyman-Pearson引理告诉我们如何求解这个问题。
1.4 功效函数
对于简单假设 $H_0: \theta = \theta_0$ vs $H_1: \theta = \theta_1$,功效是常数。但对于复合假设,我们需要考虑功效函数。
设参数空间为 $\Theta$,零假设 $H_0: \theta \in \Theta_0$,备择假设 $H_1: \theta \in \Theta_1$。
功效函数定义为:
$$\pi(\theta) = P_\theta(\text{拒绝 } H_0)$$
功效函数描述了检验在不同参数值下的表现:
- 当 $\theta \in \Theta_0$ 时,$\pi(\theta)$ 应该小(不超过 $\alpha$)
- 当 $\theta \in \Theta_1$ 时,$\pi(\theta)$ 应该大(接近1)
一致最优势(Uniformly Most Powerful, UMP):若检验 $\phi^{\ast}$ 对所有 $\theta \in \Theta_1$ 的功效都不小于任何其他水平 $\alpha$ 检验的功效,则称 $\phi^{\ast}$ 是UMP检验。
第二章:Neyman-Pearson引理
2.1 似然比:证据的强度
假设我们观测到样本 $\mathbf{x} = (x_1, \ldots, x_n)$,其概率密度(或质量)函数为 $f(\mathbf{x}; \theta)$。
在 $H_0: \theta = \theta_0$ 下的似然为 $L(\theta_0; \mathbf{x}) = f(\mathbf{x}; \theta_0)$。
在 $H_1: \theta = \theta_1$ 下的似然为 $L(\theta_1; \mathbf{x}) = f(\mathbf{x}; \theta_1)$。
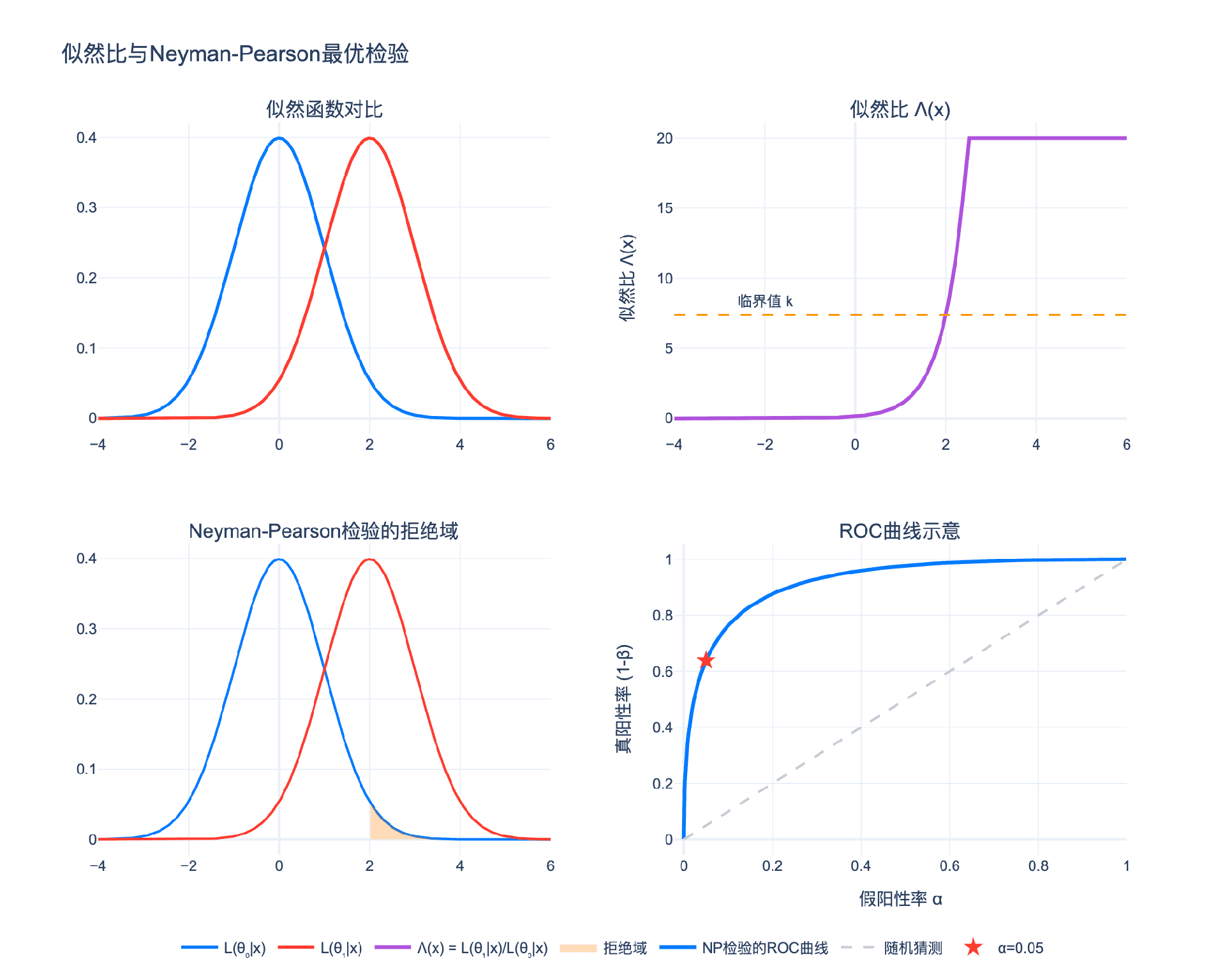
似然比(Likelihood Ratio)定义为:
$$\Lambda(\mathbf{x}) = \frac{L(\theta_1; \mathbf{x})}{L(\theta_0; \mathbf{x})}$$
直观解释:
- $\Lambda(\mathbf{x}) > 1$:数据在 $H_1$ 下更可能出现,支持拒绝 $H_0$
- $\Lambda(\mathbf{x}) < 1$:数据在 $H_0$ 下更可能出现,支持接受 $H_0$
- $\Lambda(\mathbf{x}) = 1$:数据对两个假设支持程度相同
因此,似然比是衡量"证据强度"的自然统计量。
2.2 Neyman-Pearson引理的陈述
定理(Neyman-Pearson引理):考虑检验简单假设
$$H_0: \theta = \theta_0 \quad \text{vs} \quad H_1: \theta = \theta_1$$
设似然比 $\Lambda(\mathbf{x}) = L(\theta_1; \mathbf{x}) / L(\theta_0; \mathbf{x})$。
定义似然比检验(Likelihood Ratio Test, LRT):
$$\phi(\mathbf{x}) = \begin{cases} 1 & \text{if } \Lambda(\mathbf{x}) > k \ \gamma & \text{if } \Lambda(\mathbf{x}) = k \ 0 & \text{if } \Lambda(\mathbf{x}) < k \end{cases}$$
其中 $k \geq 0$ 和 $\gamma \in [0,1]$ 由约束条件 $E_{\theta_0}[\phi(\mathbf{x})] = \alpha$ 确定。
则:
- 最优性:在显著性水平为 $\alpha$ 的所有检验中,LRT具有最大的功效
- 唯一性(几乎必然):若存在另一个水平 $\alpha$ 检验 $\phi’$ 具有相同功效,则 $\phi’ = \phi$ a.s. $[P_{\theta_0} + P_{\theta_1}]$
2.3 引理的证明
证明(简化版,使用Neyman-Pearson基本引理):
设 $\phi$ 是上述定义的LRT,$\phi^{\ast}$ 是任意其他水平 $\alpha$ 检验。我们需要证明:
$$E_{\theta_1}[\phi(\mathbf{x})] \geq E_{\theta_1}[\phi^{\ast}(\mathbf{x})]$$
关键步骤:
考虑差值:
$$\int (\phi - \phi^{\ast})(L_1 - kL_0) d\mu$$
其中 $L_0 = L(\theta_0; \mathbf{x})$,$L_1 = L(\theta_1; \mathbf{x})$。
根据LRT的定义:
- 当 $L_1 > kL_0$ 时,$\phi = 1 \geq \phi^{\ast}$,所以 $(\phi - \phi^{\ast}) \geq 0$ 且 $(L_1 - kL_0) > 0$
- 当 $L_1 < kL_0$ 时,$\phi = 0 \leq \phi^{\ast}$,所以 $(\phi - \phi^{\ast}) \leq 0$ 且 $(L_1 - kL_0) < 0$
- 当 $L_1 = kL_0$ 时,被积函数为0
因此:
$$(\phi - \phi^{\ast})(L_1 - kL_0) \geq 0 \quad \text{对所有 } \mathbf{x}$$
积分得:
$$\int (\phi - \phi^{\ast})(L_1 - kL_0) d\mu \geq 0$$
展开:
$$\int (\phi - \phi^{\ast})L_1 d\mu \geq k \int (\phi - \phi^{\ast})L_0 d\mu$$
左边是 $E_{\theta_1}[\phi - \phi^{\ast}]$,右边是 $k \cdot E_{\theta_0}[\phi - \phi^{\ast}]$。
由于 $\phi$ 和 $\phi^{\ast}$ 都是水平 $\alpha$ 检验,$E_{\theta_0}[\phi] = E_{\theta_0}[\phi^{\ast}] = \alpha$,所以右边为0。
因此:
$$E_{\theta_1}[\phi] \geq E_{\theta_1}[\phi^{\ast}]$$
证毕。
证明的关键思想:似然比检验将样本空间划分为"证据支持 $H_1$"($\Lambda > k$)和"证据支持 $H_0$"($\Lambda < k$)两个区域。任何偏离这个划分都会降低功效。
2.4 充分统计量与数据简化
因子分解定理(Neyman-Pearson):若 $T(\mathbf{x})$ 是 $\theta$ 的充分统计量,则基于 $T$ 的检验与基于原始数据 $\mathbf{x}$ 的检验具有相同的功效。
这是因为:
$$L(\theta; \mathbf{x}) = g(T(\mathbf{x}), \theta) \cdot h(\mathbf{x})$$
因此:
$$\Lambda(\mathbf{x}) = \frac{g(T(\mathbf{x}), \theta_1)}{g(T(\mathbf{x}), \theta_0)} = \Lambda(T(\mathbf{x}))$$
似然比仅依赖于充分统计量。这解释了为什么在许多情况下,我们可以用低维统计量(如样本均值)代替原始数据进行检验。
第三章:一致最优势检验与复合假设
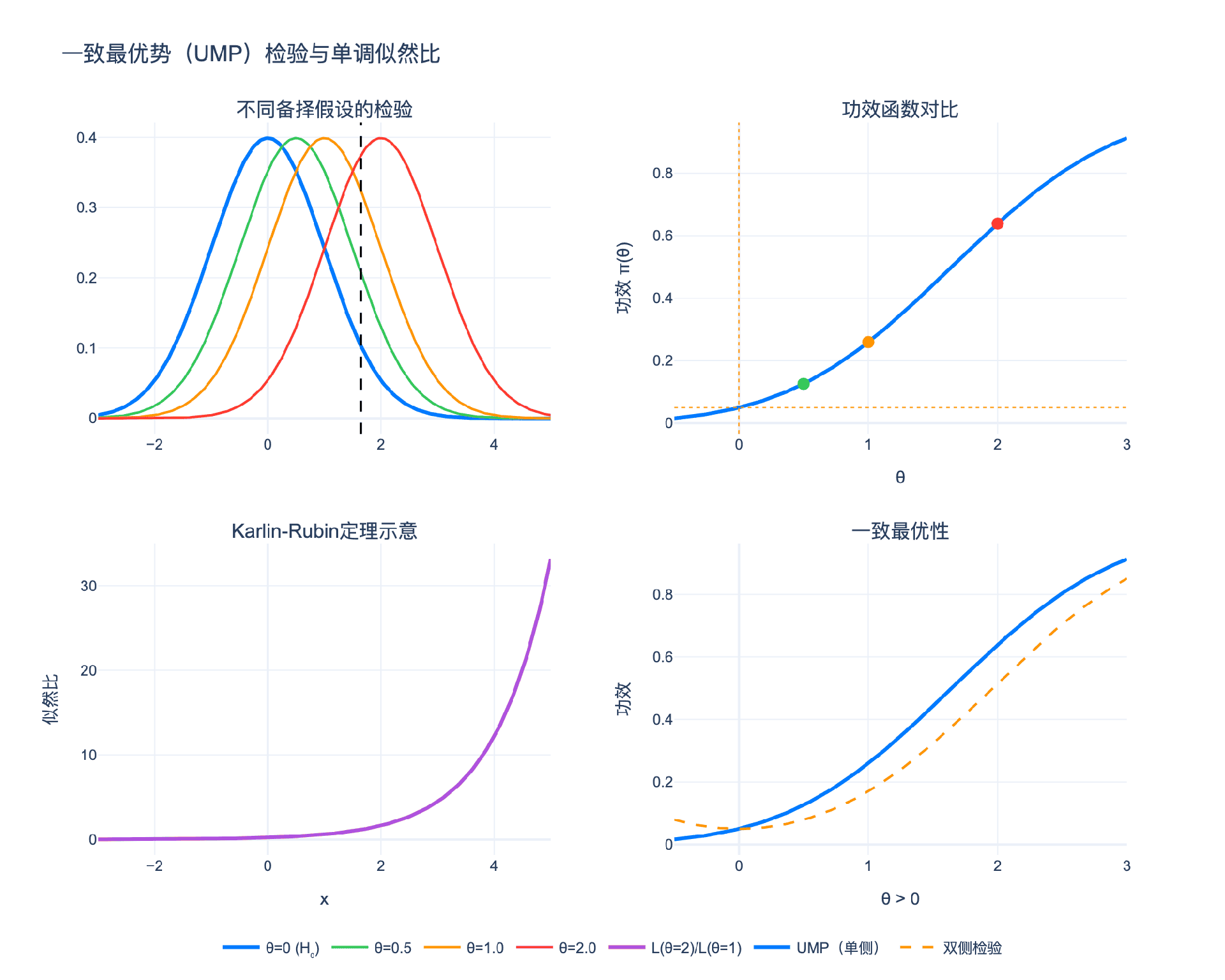
3.1 从简单假设到复合假设
Neyman-Pearson引理处理的是简单假设对简单假设的情形。但实际中更常见的是复合假设:
- $H_0: \theta \in \Theta_0$ vs $H_1: \theta \in \Theta_1$
- 单侧检验:$H_0: \theta \leq \theta_0$ vs $H_1: \theta > \theta_0$
- 双侧检验:$H_0: \theta = \theta_0$ vs $H_1: \theta \neq \theta_0$
问题:对于复合备择假设,是否存在UMP检验?
一般来说,不存在!因为对于不同的 $\theta \in \Theta_1$,最优检验可能不同。
3.2 单调似然比(MLR)
定义:分布族 ${f(x; \theta): \theta \in \Theta}$ 具有单调似然比(Monotone Likelihood Ratio, MLR),如果存在统计量 $T(x)$,使得对任意 $\theta_1 < \theta_2$,似然比
$$\Lambda(x) = \frac{f(x; \theta_2)}{f(x; \theta_1)}$$
是 $T(x)$ 的非减函数。
具有MLR的分布族:
- 单参数指数族(如正态、二项、泊松)
- 位置族、尺度族
3.3 Karlin-Rubin定理
定理(Karlin-Rubin):设 ${f(x; \theta)}$ 具有关于 $T(x)$ 的MLR。则对于检验
$$H_0: \theta \leq \theta_0 \quad \text{vs} \quad H_1: \theta > \theta_0$$
检验
$$\phi(x) = \begin{cases} 1 & \text{if } T(x) > c \ 0 & \text{if } T(x) \leq c \end{cases}$$
是水平 $\alpha$ 的UMP检验,其中 $c$ 满足 $P_{\theta_0}(T(X) > c) = \alpha$。
证明思路:
- 对于任意 $\theta_1 > \theta_0$,NP引理给出基于 $\Lambda(x) = f(x;\theta_1)/f(x;\theta_0)$ 的最优检验
- 由于MLR,$\Lambda(x)$ 是 $T(x)$ 的增函数
- 因此 $\Lambda(x) > k$ 等价于 $T(x) > c$
- 这个检验不依赖于具体的 $\theta_1$,因此对所有 $\theta_1 > \theta_0$ 都是最优的
3.4 常见分布的UMP检验
正态分布,已知方差:
- $H_0: \mu \leq \mu_0$ vs $H_1: \mu > \mu_0$
- UMP检验:拒绝当 $\bar{X} > \mu_0 + z_\alpha \sigma/\sqrt{n}$
二项分布:
- $H_0: p \leq p_0$ vs $H_1: p > p_0$
- UMP检验:拒绝当 $X > c$
指数分布:
- $H_0: \lambda \leq \lambda_0$ vs $H_1: \lambda > \lambda_0$
- UMP检验:拒绝当 $\sum X_i < c$
3.5 双侧检验与无偏检验
对于双侧检验 $H_0: \theta = \theta_0$ vs $H_1: \theta \neq \theta_0$,一般不存在UMP检验。
例子:正态分布 $N(\mu, 1)$
- 对于 $H_1: \mu > \mu_0$,最优检验拒绝当 $\bar{X} > c$
- 对于 $H_1: \mu < \mu_0$,最优检验拒绝当 $\bar{X} < c'$
- 没有一个检验能同时对两侧最优
解决方案:引入无偏性约束。要求检验的功效在备择假设下至少为 $\alpha$:
$$\pi(\theta) \geq \alpha \quad \text{对所有 } \theta \in \Theta_1$$
在这些检验中寻找最优的,得到一致最优势无偏检验(UMPU)。
第四章:实际应用
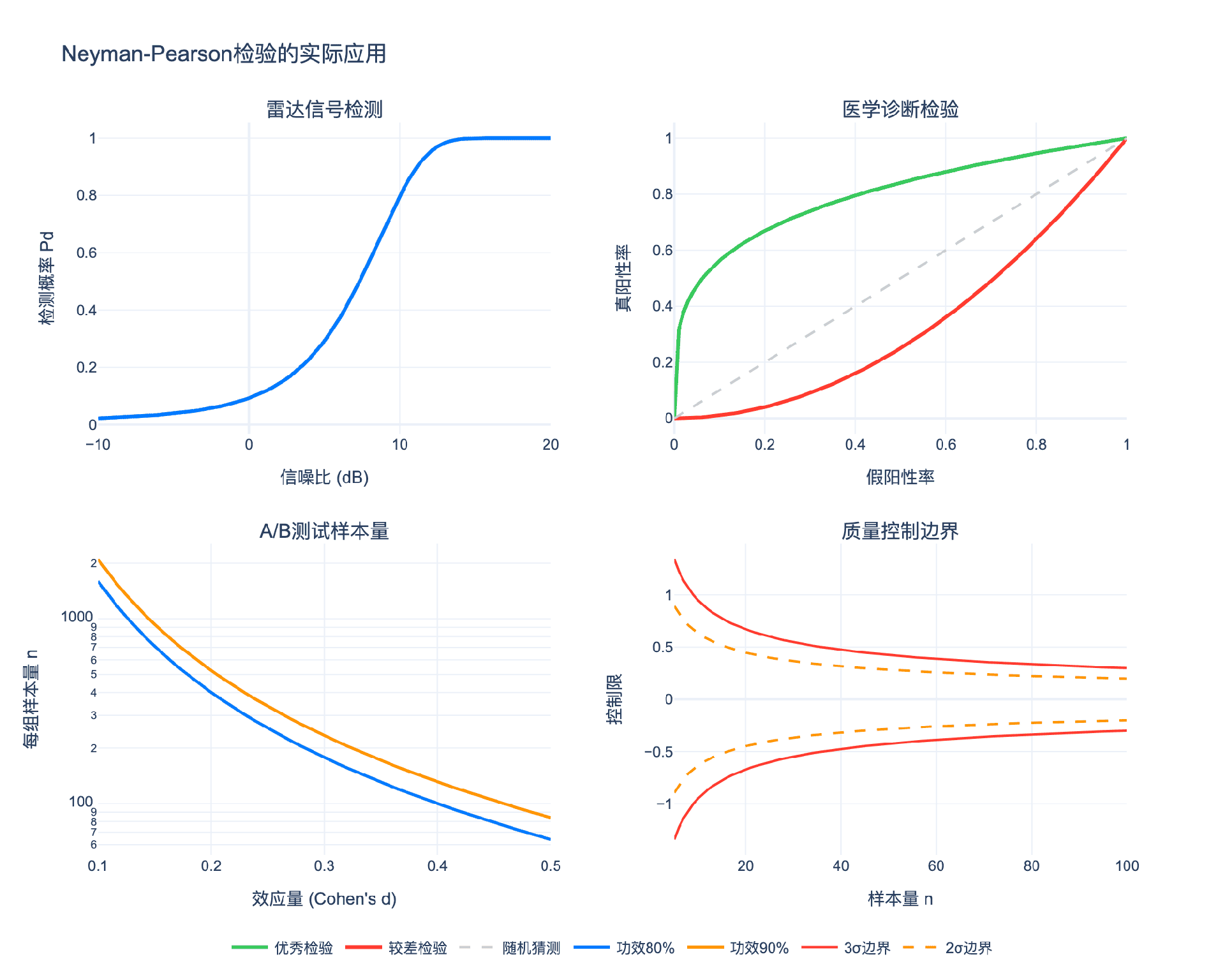
4.1 雷达与通信信号检测
在雷达系统中,接收信号可以建模为:
$$X = \begin{cases} \text{噪声} & H_0 \ \text{信号} + \text{噪声} & H_1 \end{cases}$$
假设噪声是高斯的,信号是已知的(相干检测),则:
- $H_0: X \sim N(0, \sigma^2)$
- $H_1: X \sim N(s, \sigma^2)$
似然比:
$$\Lambda(x) = \exp\left(\frac{sx - s^2/2}{\sigma^2}\right)$$
NP检验:拒绝当 $X > c$(或等价地,$sx > c’$)。
这就是匹配滤波器,它在最大化检测概率的同时控制虚警概率。
检测概率与虚警概率:
$$P_{FA} = P(X > c \mid H_0) = 1 - \Phi(c/\sigma)$$
$$P_D = P(X > c \mid H_1) = 1 - \Phi((c-s)/\sigma)$$
根据NP引理,这是给定 $P_{FA}$ 下 $P_D$ 最大的检验。
4.2 医学诊断检验
在医学检验中:
- $H_0$:患者健康
- $H_1$:患者患病
检验结果是一个连续变量(如某种生物标志物的浓度)。
ROC曲线(Receiver Operating Characteristic):
- 横轴:假阳性率($\alpha$)
- 纵轴:真阳性率(功效 $1-\beta$)
根据NP引理,对于每个 $\alpha$,LRT给出最大的 $1-\beta$。因此,LRT的ROC曲线在所有检验的ROC曲线的上方。
AUC(Area Under Curve)衡量检验的整体性能。NP检验最大化AUC。
4.3 A/B测试
互联网公司广泛使用A/B测试比较两个版本(如网页设计)的效果。
设版本A的转化率为 $p_A$,版本B为 $p_B$。
$$H_0: p_B \leq p_A \quad \text{vs} \quad H_1: p_B > p_A$$
基于NP框架,可以:
- 确定显著性水平 $\alpha$(如0.05)
- 计算达到特定功效(如0.8)所需的样本量
- 构造LRT并进行检验
样本量计算:
为了在效应量 $\delta = p_B - p_A$ 下达到功效 $\pi$,每组样本量约为:
$$n \approx \frac{(z_\alpha + z_{1-\pi})^2 \cdot 2p(1-p)}{\delta^2}$$
其中 $p \approx (p_A + p_B)/2$。
4.4 质量控制
在制造业中,需要监控产品质量是否偏离标准。
设产品质量指标 $X \sim N(\mu, \sigma^2)$,标准值为 $\mu_0$。
$$H_0: \mu = \mu_0 \quad \text{vs} \quad H_1: \mu \neq \mu_0$$
控制图基于NP原理:
- 计算样本均值 $\bar{X}$
- 若 $|\bar{X} - \mu_0| > k \cdot \sigma/\sqrt{n}$,则报警
控制限 $k$ 由期望的误报率(第一类错误)确定。
4.5 机器学习中的假设检验
在机器学习中,NP框架用于:
特征选择:检验特征与标签是否独立
模型比较:检验模型A是否显著优于模型B
异常检测:$H_0$:数据正常;$H_1$:数据异常
Neyman-Pearson分类:传统分类最小化总体错误率,但在某些应用中(如医疗诊断),假阴性的代价远高于假阳性。NP框架允许直接控制假阳性率,同时最小化假阴性率。
第五章:NP框架的扩展与深化
5.1 贝叶斯视角
从贝叶斯观点看,假设检验涉及计算后验概率:
$$P(H_1 \mid \mathbf{x}) = \frac{P(\mathbf{x} \mid H_1) P(H_1)}{P(\mathbf{x})}$$
贝叶斯因子:
$$BF_{10} = \frac{P(\mathbf{x} \mid H_1)}{P(\mathbf{x} \mid H_0)}$$
这与似然比密切相关。区别在于贝叶斯方法需要指定先验概率 $P(H_0)$ 和 $P(H_1)$。
联系:
- NP检验的拒绝域对应于贝叶斯因子大于某个阈值
- 当先验概率相等时,贝叶斯决策规则与NP检验一致
5.2 复合假设的贝叶斯方法
对于复合假设 $H_1: \theta \in \Theta_1$,贝叶斯方法通过对参数积分:
$$P(\mathbf{x} \mid H_1) = \int_{\Theta_1} P(\mathbf{x} \mid \theta) \pi(\theta) d\theta$$
这对应于加权似然比或贝叶斯预测似然。
5.3 序贯检验
瓦尔德的序贯概率比检验(SPRT)将NP框架扩展到序贯分析:
不是固定样本量,而是逐个观测样本,直到有足够证据做出决策。
停止规则:
- 若 $\Lambda_n < A$,接受 $H_0$
- 若 $\Lambda_n > B$,拒绝 $H_0$
- 若 $A \leq \Lambda_n \leq B$,继续抽样
其中 $A$ 和 $B$ 由期望的 $\alpha$ 和 $\beta$ 确定。
SPRT在满足特定误差率的条件下,期望样本量最小。
5.4 NP引理的局限性
尽管NP引理是统计推断的基石,但它也有局限性:
简单假设限制:对于复杂模型(如机器学习中的深度神经网络),似然比可能难以计算
先验知识缺失:NP框架不利用参数空间的结构信息(如光滑性)
高维问题:在高维设置中,UMP检验往往不存在,且LRT的渐近理论复杂
稳健性:NP检验可能对分布假设敏感,需要发展稳健检验方法
结语:最优检验的数学之美
Neyman-Pearson引理以其简洁和深刻,成为数理统计中最优美的结果之一。它告诉我们:在随机性的迷雾中,存在最优的决策路径。
这个引理的核心洞见——似然比是证据的最优度量——不仅在统计学中具有根本意义,也深刻影响了信息论(互信息)、机器学习(分类器设计)和信号处理(最优检测)等领域。
Neyman-Pearson框架的魅力在于它将统计推断转化为一个清晰的优化问题:在控制一类错误的前提下,最小化另一类错误。这种"约束优化"的思想在科学和工程中无处不在。
然而,NP框架也提醒我们:“最优"总是相对于特定标准而言的。在实际应用中,选择显著性水平、确定样本量、权衡两类错误,都需要领域知识和实际考量。数学给出工具,但智慧在于使用。
正如内曼所言:“统计推断的目标不是发现’真理’,而是在不确定性中做出最优决策。“Neyman-Pearson引理正是实现这一目标的数学基石。
参考文献:
Neyman, J., & Pearson, E. S. (1928). On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference. Biometrika, 20A(3/4), 175-240.
Neyman, J., & Pearson, E. S. (1933). On the Problem of the Most Efficient Tests of Statistical Hypotheses. Philosophical Transactions of the Royal Society A, 231, 289-337.
Lehmann, E. L., & Romano, J. P. (2005). Testing Statistical Hypotheses (3rd ed.). Springer.
Berger, J. O. (1985). Statistical Decision Theory and Bayesian Analysis (2nd ed.). Springer.
Casella, G., & Berger, R. L. (2002). Statistical Inference (2nd ed.). Duxbury.
Wald, A. (1947). Sequential Analysis. Wiley.
陈希孺. (2009). 《数理统计学简史》. 湖南教育出版社.
茆诗松, 王静龙, 濮晓龙. (2006). 《高等数理统计》 (2nd ed.). 高等教育出版社.