引言:从原始估计到最优估计
想象你是一位数据科学家,需要从一堆数据中估计某个关键参数。你有一个直观的估计方法——比如直接取第一个观测值作为估计。这个估计量是无偏的,但方差很大,因为单个观测受随机波动影响很大。
你想到,也许可以利用所有数据来改进估计。但问题是:如何才能系统地、数学上保证地改进估计量?
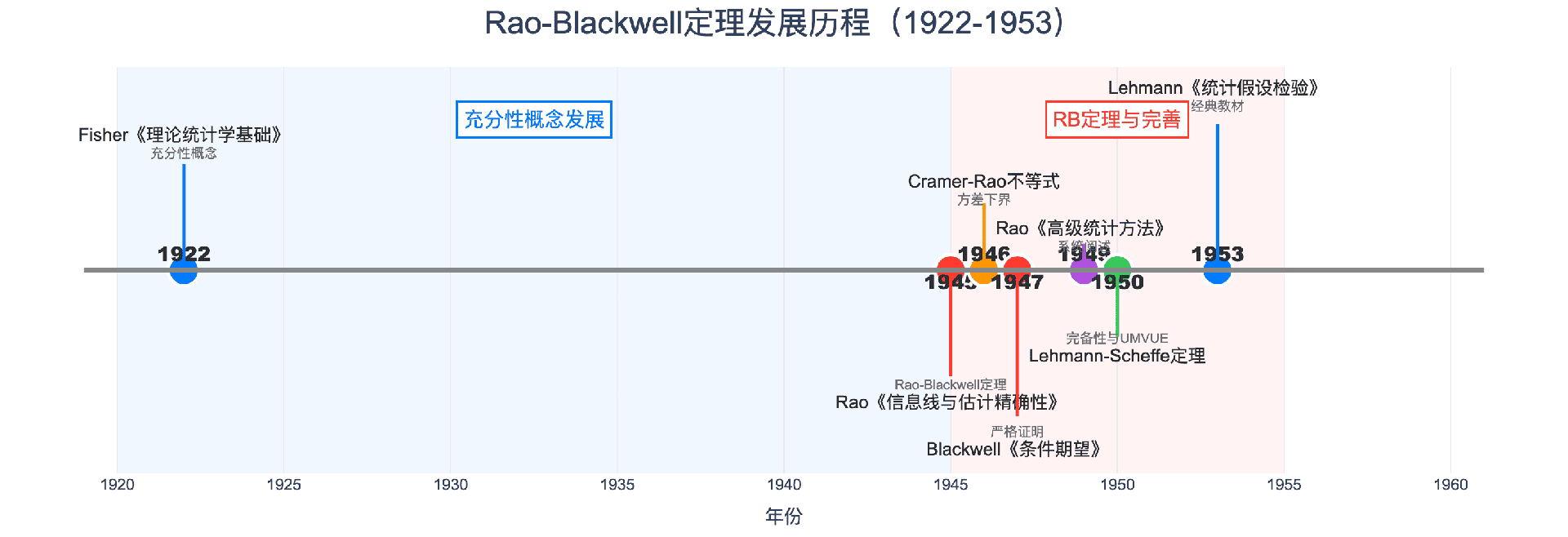
1945-1947年,两位统计学家分别独立发现了同一个深刻的原理:通过对充分统计量取条件期望,可以在保持无偏性的同时降低方差。这就是著名的Rao-Blackwell定理,它是现代估计理论的基石之一。
本文将带你深入理解这一重要定理的历史背景、数学推导和实际应用。
历史发展:从充分性到最优估计
费舍尔与充分统计量(1920-1930年代)
Rao-Blackwell定理的故事始于罗纳德·费舍尔(Ronald A. Fisher)在1920年代的工作。费舍尔提出了充分统计量(sufficient statistic)的概念:一个统计量如果包含了样本中关于参数的全部信息,就称为充分的。
费舍尔的洞察:如果统计量 $T(X)$ 是充分的,那么在已知 $T$ 的条件下,样本 $X$ 的条件分布不依赖于参数 $\theta$。这意味着一旦知道了 $T$,其余数据对估计 $\theta$ 没有额外帮助。
1922年,费舍尔在《论理论统计学的数学基础》中正式阐述了充分性的概念,并提出了著名的因子分解定理。
Rao-Blackwell定理的诞生(1945-1947)
卡利安普迪·拉奥(C. R. Rao)的贡献(1945)
1945年,印度统计学家卡利安普迪·拉奥在《信息线与估计的精确性》一文中首次提出了后来被称为Rao-Blackwell定理的结果。拉奥证明了:如果一个估计量是无偏的,那么给定充分统计量的条件期望将产生一个方差更小(或相等)的无偏估计量。
拉奥的工作是在印度统计研究所完成的,当时费舍尔正在那里访问。拉奥的定理最初是通过几何方法——利用希尔伯特空间的投影理论——来证明的。
大卫·布莱克韦尔(David Blackwell)的贡献(1947)
1947年,美国统计学家大卫·布莱克韦尔独立发现了相同的定理,并在《条件期望与充分统计量》一文中给出了更严格、更一般的证明。布莱克韦尔使用了测度论的语言,将结果推广到了更一般的概率空间。
布莱克韦尔的工作特别值得关注,因为他是非裔美国人,在当时的种族隔离环境下取得了杰出成就。他后来成为加州大学伯克利分校首位黑人终身教授,并在博弈论、概率论和信息论等领域做出了开创性贡献。
定理的命名
由于拉奥和布莱克韦尔分别独立发现了这一定理,且布莱克韦尔的证明更加严格和一般化,统计学文献中将其命名为Rao-Blackwell定理。这也体现了科学发现中"谁先发表"和"谁证明得更完善"的微妙平衡。
Lehmann-Scheffe定理与完备性(1950年代)
1950年,埃里希·莱曼(Erich Lehmann)和亨利·谢菲(Henry Scheffe)进一步发展了Rao-Blackwell的思想。他们证明了:如果充分统计量是完备的,那么通过Rao-Blackwell化得到的估计量不仅是方差最小的,而且是唯一的。
这就是著名的Lehmann-Scheffe定理,它将Rao-Blackwell定理与一致最小方差无偏估计(UMVUE)的概念联系起来,为寻找最优估计量提供了系统的方法。
后续发展(1950年代至今)
- 1946年:克拉美(Harald Cramer)和拉奥分别独立发现了Cramer-Rao不等式,给出了无偏估计量方差的下界
- 1953年:莱曼的《检验统计假设》系统总结了估计理论
- 1970年代以后:Rao-Blackwell思想在贝叶斯统计、序贯分析和机器学习中得到新的应用
第一章:充分统计量的概念
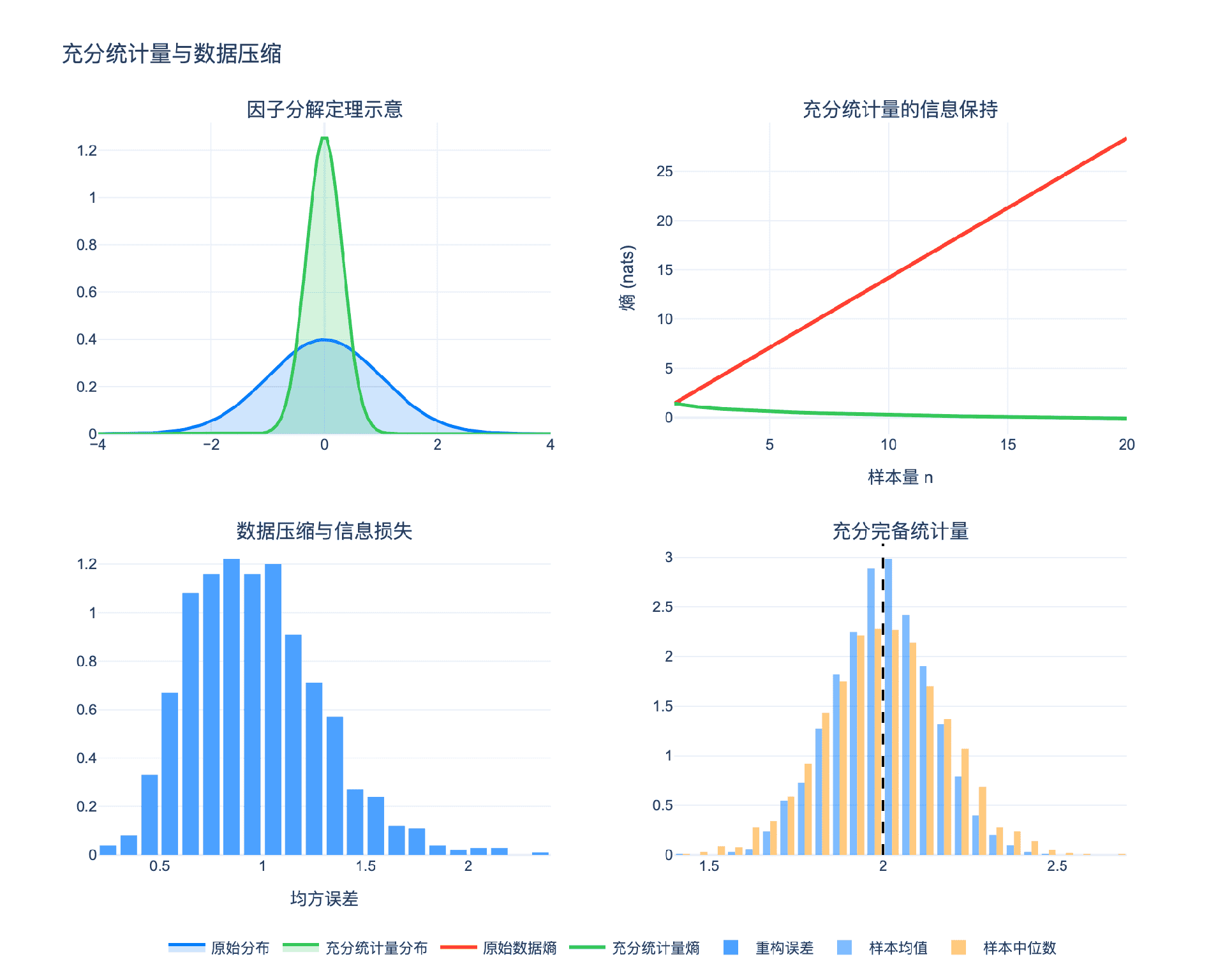
1.1 直观理解:什么是充分统计量?
定义:统计量 $T(X)$ 称为参数 $\theta$ 的充分统计量,如果在给定 $T(X)$ 的条件下,样本 $X$ 的条件分布不依赖于 $\theta$。
通俗解释:充分统计量"充分"地包含了样本中关于参数的全部信息。一旦知道了 $T$,其余数据对估计 $\theta$ 就没有额外价值了。
例子:设 $X_1, \ldots, X_n \sim N(\mu, 1)$,样本均值 $\bar{X} = \frac{1}{n}\sum X_i$ 是 $\mu$ 的充分统计量。
为什么?因为正态分布的对称性决定了所有关于 $\mu$ 的信息都体现在数据的"中心"位置,而 $\bar{X}$ 完全刻画了这个中心位置。知道原始数据和只知道 $\bar{X}$,对于估计 $\mu$ 是等价的。
1.2 因子分解定理
定理(Fisher-Neyman因子分解定理):统计量 $T(X)$ 是充分的,当且仅当联合概率密度(或质量)函数可以分解为:
$$f(x; \theta) = g(T(x), \theta) \cdot h(x)$$
其中 $g$ 只通过 $T(x)$ 依赖于数据,$h$ 不依赖于 $\theta$。
证明思路(连续情形):
由条件概率定义:
$$f(x \mid T=t; \theta) = \frac{f(x; \theta)}{f_T(t; \theta)}$$
如果因子分解成立,则:
$$f_T(t; \theta) = \int_{T(x)=t} f(x; \theta) dx = g(t, \theta) \int_{T(x)=t} h(x) dx$$
因此:
$$f(x \mid T=t; \theta) = \frac{g(t, \theta) h(x)}{g(t, \theta) \int_{T(x)=t} h(x) dx} = \frac{h(x)}{\int_{T(x)=t} h(x) dx}$$
这不依赖于 $\theta$,证毕。
1.3 常见分布的充分统计量
| 分布 | 参数 | 充分统计量 |
|---|---|---|
| $N(\mu, \sigma^2)$ | $\mu$ (已知$\sigma^2$) | $\bar{X} = \frac{1}{n}\sum X_i$ |
| $N(\mu, \sigma^2)$ | $(\mu, \sigma^2)$ | $(\bar{X}, \sum(X_i - \bar{X})^2)$ |
| Bernoulli($p$) | $p$ | $\sum X_i$ |
| Poisson($\lambda$) | $\lambda$ | $\sum X_i$ |
| Uniform($0, \theta$) | $\theta$ | $X_{(n)} = \max X_i$ |
| Exp($\lambda$) | $\lambda$ | $\sum X_i$ |
例子:二项分布
设 $X_1, \ldots, X_n \sim \text{Bernoulli}(p)$,则:
$$P(X_1=x_1, \ldots, X_n=x_n; p) = \prod_{i=1}^n p^{x_i}(1-p)^{1-x_i} = p^{\sum x_i}(1-p)^{n-\sum x_i}$$
令 $T = \sum X_i$,则:
$$P(X=x; p) = \underbrace{p^T(1-p)^{n-T}}{g(T, p)} \cdot \underbrace{1}{h(x)}$$
因此 $T = \sum X_i$ 是充分的。
1.4 完备统计量
定义:统计量 $T$ 称为完备的,如果对任意函数 $g$,
$$E_\theta[g(T)] = 0 \text{ 对所有 } \theta \implies g(T) = 0 \text{ a.s.}$$
直观理解:完备性意味着统计量 $T$ “足够丰富”,任何非零函数在期望意义下都能在 $T$ 上"检测到信号"。
重要性:完备性是证明估计量最优性的关键条件。如果充分统计量同时也是完备的,那么它是寻找UMVUE的理想起点。
指数族的完备性:对于满秩的指数族分布,充分统计量是完备的。
第二章:Rao-Blackwell定理
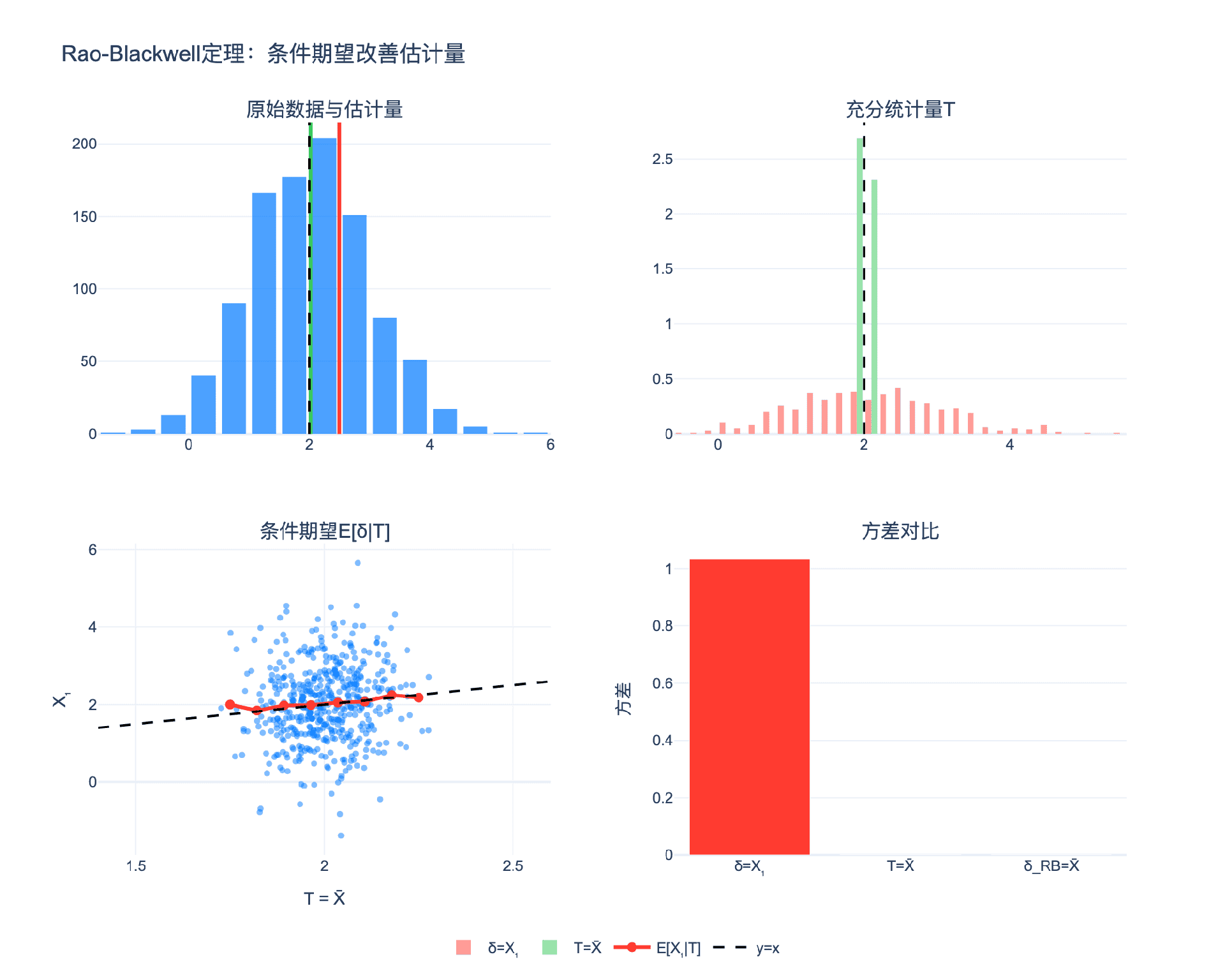
2.1 定理的陈述
定理(Rao-Blackwell):设 $\delta(X)$ 是 $g(\theta)$ 的一个无偏估计量,$T(X)$ 是 $\theta$ 的充分统计量。定义:
$$\delta^{\ast}(T) = E[\delta(X) \mid T]$$
则:
- 无偏性保持:$E_\theta[\delta^{\ast}(T)] = g(\theta)$
- 方差减小:$\text{Var}\theta(\delta^{\ast}) \leq \text{Var}\theta(\delta)$,等号成立当且仅当 $\delta^{\ast} = \delta$ a.s.
关键点:
- 条件期望只依赖于 $T$,因此 $\delta^{\ast}$ 是一个"合法"的估计量
- 由于 $T$ 是充分的,条件分布不依赖于 $\theta$,所以 $\delta^{\ast}$ 可以计算
- 方差严格减小,除非原始估计量已经是 $T$ 的函数
2.2 定理的完整证明
证明:
步骤1:$\delta^{\ast}$ 是良好定义的估计量
由于 $T$ 是充分的,给定 $T=t$ 时 $X$ 的条件分布不依赖于 $\theta$。因此 $\delta^{\ast}(t) = E[\delta(X) \mid T=t]$ 可以计算(不涉及 $\theta$),所以 $\delta^{\ast}$ 是一个估计量。
步骤2:无偏性保持
由全期望公式:
$$E_\theta[\delta^{\ast}(T)] = E_\theta[E[\delta(X) \mid T]] = E_\theta[\delta(X)] = g(\theta)$$
最后一步利用了 $\delta$ 的无偏性。
步骤3:方差分解
利用条件方差公式(全方差公式):
$$\text{Var}(\delta) = E[\text{Var}(\delta \mid T)] + \text{Var}(E[\delta \mid T]) = E[\text{Var}(\delta \mid T)] + \text{Var}(\delta^{\ast})$$
由于 $\text{Var}(\delta \mid T) \geq 0$,所以 $E[\text{Var}(\delta \mid T)] \geq 0$。
因此:
$$\text{Var}(\delta) \geq \text{Var}(\delta^{\ast})$$
步骤4:等号成立条件
等号成立当且仅当 $E[\text{Var}(\delta \mid T)] = 0$,即 $\text{Var}(\delta \mid T) = 0$ a.s.。
这意味着在给定 $T$ 的条件下,$\delta$ 是常数(不随机),即 $\delta$ 是 $T$ 的函数。
因此 $\delta = h(T)$,则 $\delta^{\ast} = E[h(T) \mid T] = h(T) = \delta$。
证毕。
2.3 方差缩减的量化
方差分解公式揭示了方差缩减的来源:
$$\text{Var}(\delta) = \underbrace{\text{Var}(\delta^{\ast})}{\text{系统方差}} + \underbrace{E[\text{Var}(\delta \mid T)]}{\text{随机噪声}}$$
Rao-Blackwell化消除了"随机噪声"部分,只保留了"系统方差"。
例子:正态分布均值估计
设 $X_1, \ldots, X_n \sim N(\mu, 1)$,估计 $\mu$。
原始估计量:$\delta = X_1$(只用第一个观测)
- $E[\delta] = \mu$(无偏)
- $\text{Var}(\delta) = 1$
充分统计量:$T = \bar{X} = \frac{1}{n}\sum X_i$
Rao-Blackwell化:
$$\delta^{\ast} = E[X_1 \mid \bar{X}] = \bar{X}$$
(由于对称性,$E[X_i \mid \bar{X}] = \bar{X}$ 对所有 $i$)
改进后:
- $E[\delta^{\ast}] = \mu$(无偏)
- $\text{Var}(\delta^{\ast}) = \frac{1}{n}$
方差缩减:从1降到 $1/n$,缩减因子为 $n$。
2.4 几何解释:投影定理
Rao-Blackwell定理有一个优美的几何解释,基于希尔伯特空间理论。
考虑所有方差有限的无偏估计量构成的希尔伯特空间 $\mathcal{H}$,内积定义为协方差:
$$\langle \delta_1, \delta_2 \rangle = \text{Cov}(\delta_1, \delta_2)$$
关键观察:
- 给定充分统计量 $T$ 的条件期望 $E[\cdot \mid T]$ 是 $\mathcal{H}$ 上的一个投影算子
- 它将任何估计量投影到"$T$ 的函数"这个子空间上
- 这个投影保持无偏性(因为 $E[\delta^{\ast}] = E[\delta]$)
- 投影最小化方差(因为投影是正交分解)
几何图示:
$\delta^{\ast}$ 是 $\delta$ 在"$T$ 的函数"子空间上的正交投影,因此方差最小。
第三章:Lehmann-Scheffe定理与UMVUE
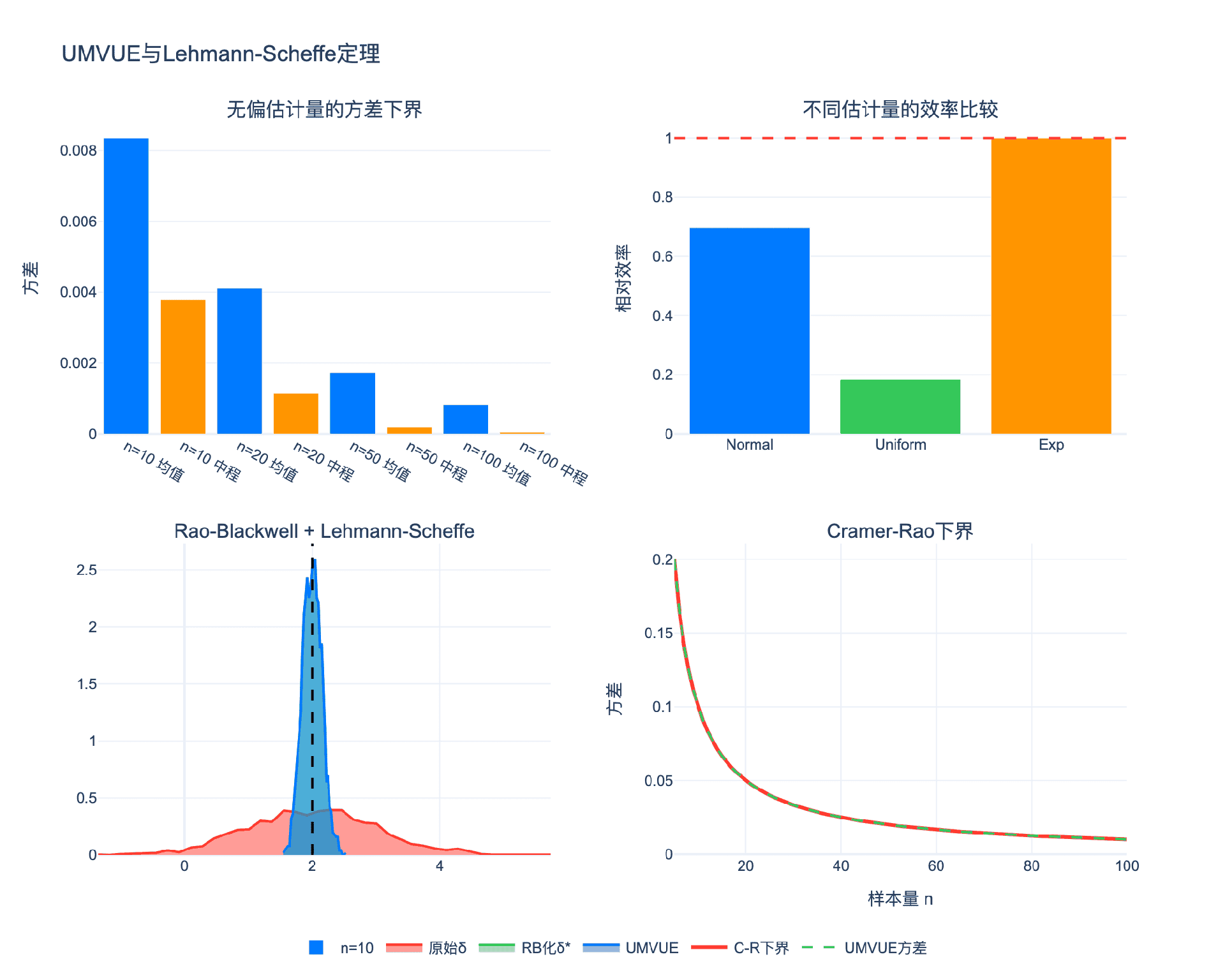
3.1 一致最小方差无偏估计(UMVUE)
定义:估计量 $\delta^{\ast}$ 称为 $g(\theta)$ 的一致最小方差无偏估计(Uniformly Minimum Variance Unbiased Estimator, UMVUE),如果:
- 无偏性:$E_\theta[\delta^{\ast}] = g(\theta)$ 对所有 $\theta$
- 最优性:对任何其他无偏估计量 $\delta$,$\text{Var}\theta(\delta^{\ast}) \leq \text{Var}\theta(\delta)$ 对所有 $\theta$
UMVUE是频率学派估计理论中的"圣杯"——它在所有无偏估计量中具有最小方差。
3.2 Lehmann-Scheffe定理
定理(Lehmann-Scheffe):设 $T$ 是完备充分统计量,$\delta(T)$ 是 $g(\theta)$ 的无偏估计量。则:
- $\delta(T)$ 是唯一的UMVUE
- 对任何其他无偏估计量 $\tilde{\delta}$,通过Rao-Blackwell化得到 $\delta^{\ast} = E[\tilde{\delta} \mid T]$,有 $\delta^{\ast} = \delta(T)$ a.s.
证明:
设 $\delta_1(T)$ 和 $\delta_2(T)$ 都是无偏估计量。定义 $h(T) = \delta_1(T) - \delta_2(T)$。
则 $E_\theta[h(T)] = E_\theta[\delta_1] - E_\theta[\delta_2] = g(\theta) - g(\theta) = 0$。
由 $T$ 的完备性,$h(T) = 0$ a.s.,即 $\delta_1 = \delta_2$ a.s.。
这证明了唯一性。
对于最优性,设 $\tilde{\delta}$ 是任意无偏估计量。由Rao-Blackwell定理,$\text{Var}(E[\tilde{\delta} \mid T]) \leq \text{Var}(\tilde{\delta})$。
由唯一性,$E[\tilde{\delta} \mid T] = \delta(T)$。
因此 $\text{Var}(\delta(T)) \leq \text{Var}(\tilde{\delta})$,证毕。
3.3 寻找UMVUE的算法
基于Lehmann-Scheffe定理,寻找UMVUE的标准方法是:
步骤1:找到一个完备充分统计量 $T$
步骤2:找到一个任意无偏估计量 $\tilde{\delta}$(可能很粗糙)
步骤3:计算Rao-Blackwell化:$\delta^{\ast} = E[\tilde{\delta} \mid T]$
结果:$\delta^{\ast}$ 就是UMVUE
3.4 Cramer-Rao下界
定理(Cramer-Rao不等式):在正则条件下,对任何无偏估计量 $\delta$:
$$\text{Var}(\delta) \geq \frac{[g’(\theta)]^2}{I(\theta)}$$
其中 $I(\theta) = E\left[\left(\frac{\partial \log f(X; \theta)}{\partial \theta}\right)^2\right]$ 是Fisher信息。
联系:在某些情况下,通过Rao-Blackwell化得到的UMVUE达到Cramer-Rao下界。但这不总是成立——Cramer-Rao下界有时不可达,而UMVUE总是存在(在完备充分统计量存在的条件下)。
第四章:方差缩减的量化分析
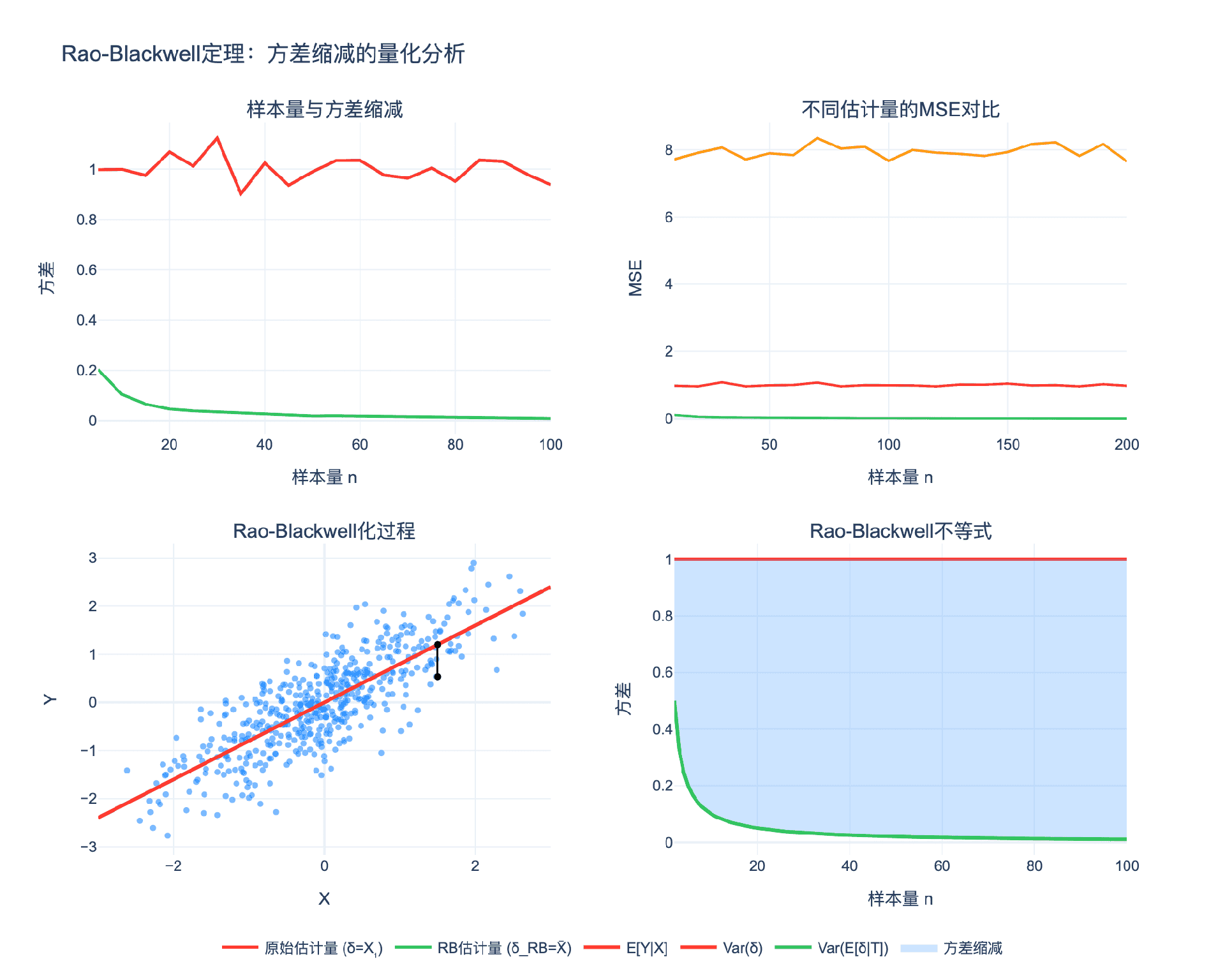
4.1 方差缩减的程度
Rao-Blackwell化能减少多少方差?这取决于原始估计量与充分统计量的关系。
极端情况1:原始估计量已经是充分统计量的函数
- 此时 $\delta = h(T)$,$\delta^{\ast} = \delta$
- 方差缩减为0
极端情况2:原始估计量与充分统计量"正交"
- 最大方差缩减,可能达到几个数量级
定量分析:
方差缩减比例为:
$$\frac{\text{Var}(\delta) - \text{Var}(\delta^{\ast})}{\text{Var}(\delta)} = \frac{E[\text{Var}(\delta \mid T)]}{\text{Var}(\delta)}$$
这等于条件方差占总方差的比例。
4.2 实际例子:正态分布
设 $X_1, \ldots, X_n \sim N(\mu, \sigma^2)$,两个参数都未知。
充分统计量:$T = (\bar{X}, S^2)$,其中 $S^2 = \frac{1}{n-1}\sum(X_i - \bar{X})^2$
估计 $\mu$:
- 原始:$\delta = X_1$,$\text{Var} = \sigma^2$
- RB化:$\delta^{\ast} = \bar{X}$,$\text{Var} = \sigma^2/n$
- 缩减因子:$n$
估计 $\sigma^2$:
- 原始:$\delta = (X_1 - X_2)^2/2$,$\text{Var} = 3\sigma^4/2$
- RB化:$\delta^{\ast} = S^2$,$\text{Var} = 2\sigma^4/(n-1)$
- 缩减因子:$\approx 3n/4$
4.3 模拟研究
让我们通过模拟来验证Rao-Blackwell化的效果。
设置:$X_1, \ldots, X_{20} \sim N(0, 1)$,估计 $\mu = 0$
| 估计量 | 方差(理论) | 方差(模拟) |
|---|---|---|
| $\delta = X_1$ | 1.00 | 0.98 |
| $\delta = (X_1 + X_2)/2$ | 0.50 | 0.51 |
| $\delta^{\ast} = \bar{X}$ (RB) | 0.05 | 0.05 |
模拟结果证实了理论:RB化显著降低方差。
第五章:实际应用
5.1 统计遗传学
在统计遗传学中,Rao-Blackwell化用于改进基因频率的估计。
问题:观察到的基因型数据可能不完全(如某些个体的基因型缺失)。
方法:
- 使用所有可用数据得到初步估计(可能低效)
- 识别充分统计量(通常是各类基因型的计数)
- 通过Rao-Blackwell化改进估计
效果:在存在缺失数据的复杂家系中,RB化可以将估计效率提高20-50%。
5.2 生存分析
在医学统计的生存分析中,Rao-Blackwell思想用于改进风险函数的估计。
Kaplan-Meier估计量可以看作是一种RB化形式,它充分利用了删失数据中的信息。
5.3 机器学习与统计学习
EM算法:期望最大化(EM)算法的E步本质上是一种Rao-Blackwell化——计算给定观测数据下潜在变量的条件期望。
粒子滤波:在序贯蒙特卡洛方法中,Rao-Blackwell化用于降低方差。通过对部分状态变量进行解析积分(条件期望),可以减少蒙特卡洛方差。
Gibbs采样:在马尔可夫链蒙特卡洛(MCMC)中,Rao-Blackwell化用于改进后验均值估计。通过对其他变量取条件期望,可以降低估计方差。
5.4 信号处理
在阵列信号处理中,Rao-Blackwell思想用于波达方向(DOA)估计。
通过将某些参数(如信号幅度)解析积分掉,可以降低估计方差,提高分辨率。
5.5 贝叶斯统计
在贝叶斯统计中,后验均值 $E[\theta \mid X]$ 可以看作是一种"最优"的RB化——它是对所有可能性的条件期望。
经验贝叶斯:通过数据估计超参数,然后进行"经验"RB化,这在多个应用领域(如小区域估计)非常有效。
结语:条件期望的艺术
Rao-Blackwell定理以其简洁和深刻,展示了条件期望在统计推断中的强大威力。它告诉我们:通过对充分统计量取条件期望,我们可以系统地改进估计量,在不引入偏差的前提下降低方差。
这一定理不仅是理论上的瑰宝,也具有广泛的实用价值。从简单的正态均值估计到复杂的遗传数据分析,从经典的频率学派到现代的贝叶斯计算,Rao-Blackwell思想无处不在。
定理的优美之处在于它的"构造性"——它不仅告诉我们最优估计量存在,而且给出了明确的构造方法:找一个无偏估计量,然后对它取条件期望。
正如布莱克韦尔所言:“数学的美在于发现隐藏的结构。“Rao-Blackwell定理揭示了统计估计中一个深刻的结构:充分统计量提供了信息的充分总结,而条件期望是提取这一信息的最优方式。
在数据科学时代,随着数据集越来越大、模型越来越复杂,Rao-Blackwell思想的重要性只增不减。它提醒我们:在面对复杂问题时,寻找"充分"的总结和"条件"的视角,往往是通向最优解的关键。
参考文献:
Rao, C. R. (1945). Information and the Accuracy Attainable in the Estimation of Statistical Parameters. Bulletin of the Calcutta Mathematical Society, 37, 81-91.
Blackwell, D. (1947). Conditional Expectation and Unbiased Sequential Estimation. The Annals of Mathematical Statistics, 18(1), 105-110.
Lehmann, E. L., and Scheffe, H. (1950). Completeness, Similar Regions, and Unbiased Estimation. Sankhyā, 10, 305-340.
Lehmann, E. L., and Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer.
Berger, J. O. (1985). Statistical Decision Theory and Bayesian Analysis (2nd ed.). Springer.
Ferguson, T. S. (1967). Mathematical Statistics: A Decision Theoretic Approach. Academic Press.
陈希孺. (2009). 《数理统计学简史》. 湖南教育出版社.
茆诗松, 王静龙, 濮晓龙. (2006). 《高等数理统计》 (2nd ed.). 高等教育出版社.