引言
假设你是一个医生。一位患者走进诊室,告诉你他有发烧和咳嗽的症状。你会怎么做?
直觉上,你可能会想:“发烧加咳嗽,可能是感冒,也可能是流感,或者更严重一点是肺炎。” 这个简单的推理过程,其实蕴含了深刻的数学原理——你在根据观察到的证据(症状),推断潜在的原因(疾病)。这正是概率推理的核心。
但问题在于,现实世界远非这么简单。如果患者还告诉你他刚从高原旅行回来呢?如果他还有吸烟史呢?如果有十个、二十个相关因素呢?你如何在这些复杂的因素之间建立联系,做出准确的判断?
这正是贝叶斯网络(Bayesian Network)诞生的原因。它为我们提供了一种优雅的方式来表示复杂的概率关系,让我们能够在不确定的世界中,进行理性的推理和决策。
第一章:为什么要发明贝叶斯网络?
1.1 不确定性是世界的常态
让我们从一个简单的场景开始。假设你有一个朋友,某天你看到他带着一把雨伞出门。你可能会想:“他带伞,是因为今天会下雨吗?”
这个推理看起来理所当然,但仔细想想,其实包含了多层不确定性:
- 他可能知道今天会下雨(看了天气预报)
- 他可能只是习惯带伞
- 他可能要用伞遮阳
- 他可能不知道天气,但天上乌云密布让他有所警觉
不确定性无处不在。 我们无法百分之百确定任何事情——天气预报可能不准,仪器测量会有误差,人的决策充满随机性。传统数学擅长处理确定的、因果关系明确的问题,但在面对不确定性时,我们需要新的工具。
1.2 概率论:处理不确定性的语言
早在 17 世纪,数学家们就开始系统研究不确定性。概率论应运而生,为我们描述"某事发生的可能性"提供了精确的语言。
最基本的概率概念是:事件 $A$ 发生的概率记为 $P(A)$,取值在 0 到 1 之间。0 表示不可能发生,1 表示必然发生,0.5 表示一半对一半。
但真正革命性的突破来自 18 世纪的一位英国牧师——托马斯·贝叶斯(Thomas Bayes)。他在去世后(1763 年)发表的一篇论文中,提出了一个看似简单却影响深远的公式:
$$P(H|E) = \frac{P(E|H) \cdot P(H)}{P(E)}$$
这就是著名的贝叶斯定理。其中:
- $P(H)$ 是先验概率(Prior):在看到证据之前,我们对假设 $H$ 的相信程度
- $P(E|H)$ 是似然(Likelihood):如果假设 $H$ 成立,观察到证据 $E$ 的概率
- $P(H|E)$ 是后验概率(Posterior):在看到证据 $E$ 之后,我们对假设 $H$ 的更新相信程度
这个公式告诉我们:信念是可以随着证据而更新的。 这正是人类推理的核心——我们不断根据新信息修正自己的看法。
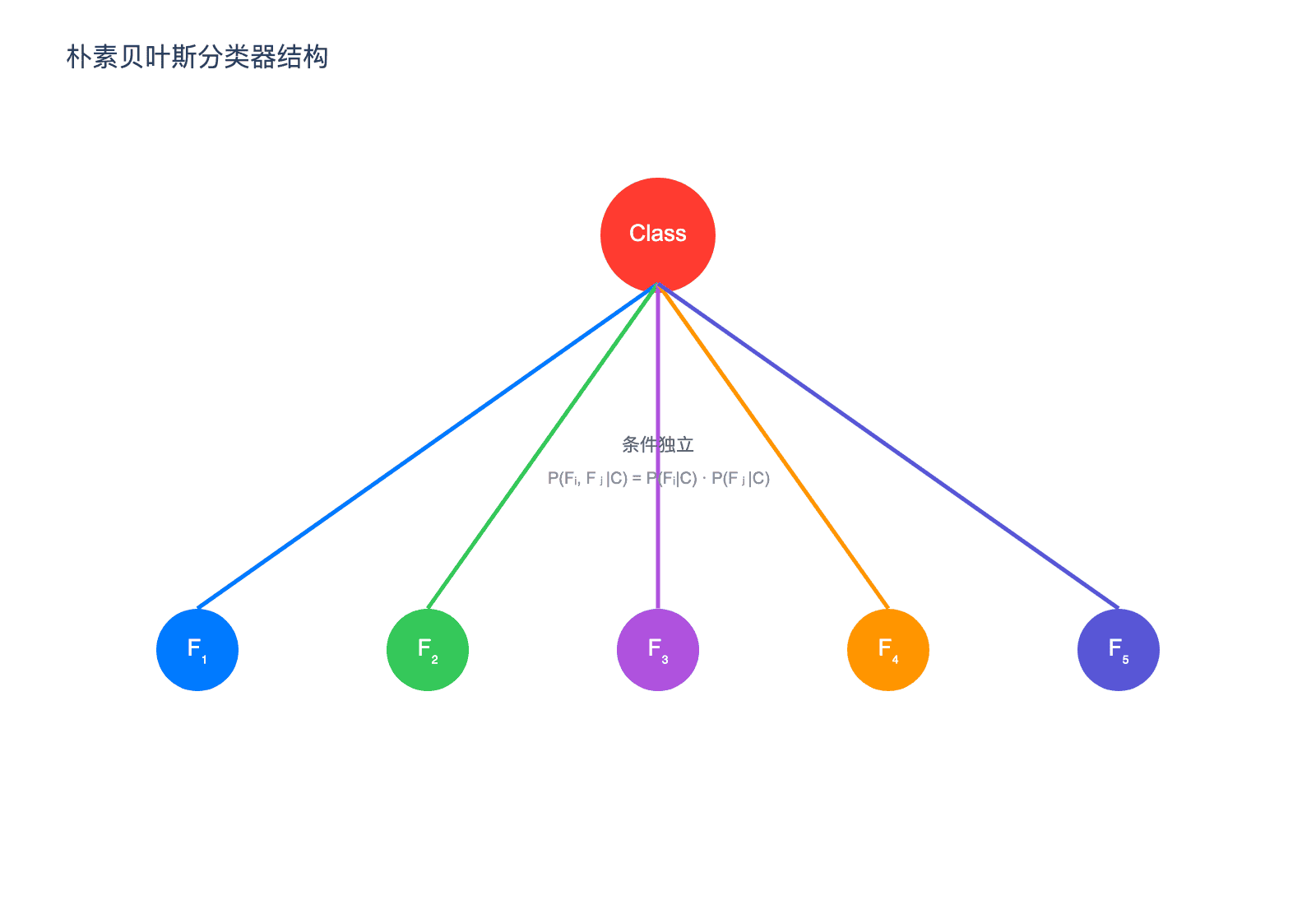
1.3 朴素贝叶斯:一个简单但有缺陷的起点
贝叶斯定理如此优雅,自然让人们想用它来解决实际问题。其中最简单、最著名的应用就是朴素贝叶斯分类器。
假设我们要根据邮件中的词语来判断它是不是垃圾邮件。设 $C$ 表示邮件类别(垃圾/正常),$F_1, F_2, …, F_n$ 表示邮件中出现的各种特征(词语)。
根据贝叶斯定理:
$$P(C|F_1, F_2, …, F_n) = \frac{P(F_1, F_2, …, F_n|C) \cdot P(C)}{P(F_1, F_2, …, F_n)}$$
问题在于:计算 $P(F_1, F_2, …, F_n|C)$ 需要知道所有特征之间的联合分布,这在特征很多时是不可能的——如果有 1000 个词语,每个词语出现或不出现,就有 $2^{1000}$ 种组合!
朴素贝叶斯做了一个大胆的简化假设:假设所有特征在给定类别下条件独立。也就是说:
$$P(F_1, F_2, …, F_n|C) = P(F_1|C) \cdot P(F_2|C) \cdot … \cdot P(F_n|C)$$
这个假设看起来很不合理(词语之间显然有关联),但令人惊讶的是,朴素贝叶斯在很多实际任务中表现非常好,尤其是在文本分类、垃圾邮件过滤等应用中。
但"朴素"这个名字已经说明了一切——这个假设太简单了。在现实世界中,变量之间往往存在复杂的依赖关系。我们需要更强大的工具来建模这些关系。
1.4 维数灾难与联合分布的困境
让我们更深入地理解为什么直接建模联合分布是不可行的。
假设我们有一个医疗诊断系统,需要考虑 20 个症状和 10 种疾病。如果每个变量是二元的(是/否),那么完整的联合分布表将有 $2^{30} \approx 10^9$ 个条目——整整 10 亿个概率值!这不仅存储困难,更需要天文数字的数据来准确估计这些概率。
这就是所谓的维数灾难(Curse of Dimensionality):随着变量数量增加,问题的复杂度呈指数级增长。
但人类似乎并没有这个困扰。一个经验丰富的医生可以在几分钟内完成复杂的诊断,而不需要记忆 10 亿个概率值。这说明什么?
说明很多变量之间其实是条件独立的。 知道患者发烧后,“头痛"和"肌肉酸痛"可能有相关性;但如果已经确诊是流感,这些症状的相关性就大大降低了——它们都是由流感引起的。
这正是贝叶斯网络的核心洞察:利用条件独立性,将复杂的联合分布分解为简单的局部关系。
第二章:贝叶斯网络的核心思想
2.1 一个有向图的故事
1985 年,加州大学洛杉矶分校的计算机科学家 Judea Pearl 提出了置信度网络(Belief Network)的概念,后来被称为贝叶斯网络。
Pearl 的关键洞察是:概率依赖关系可以用一张图来表示。
让我们回到"洒水器-草地湿润"的经典例子。假设我们想建立一个系统来判断草地为什么湿了。可能的原因有:
- 昨晚下雨了
- 洒水器开了
- 两者都有
这些因素之间存在关系:
- 如果多云,更可能下雨,也更有可能开洒水器(因为不需要浪费水)
- 草地湿可能是因为下雨,可能是因为洒水器,也可能两者都有
我们可以用下面的图来表示这些关系:
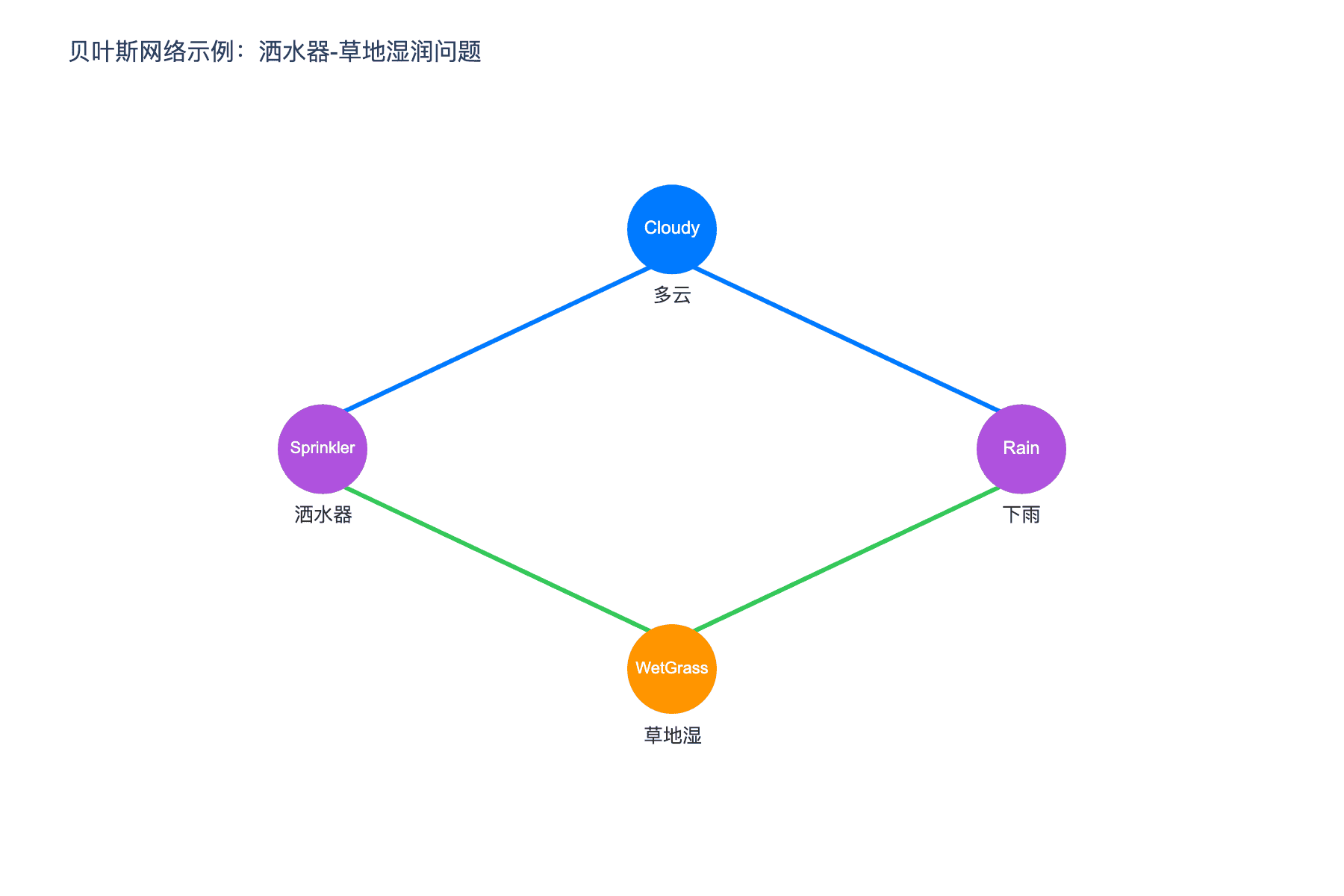
在这个图中:
- 节点(圆圈)代表随机变量:Cloudy(多云)、Sprinkler(洒水器)、Rain(下雨)、WetGrass(草地湿)
- 有向边(箭头)代表因果关系或影响关系
- 箭头的方向表示因果方向:多云影响下雨,下雨影响草地湿
这张图告诉我们一个关键信息:每个变量只依赖于它的父节点。
2.2 条件独立性的图表示
贝叶斯网络的核心优势在于它能直观地表达条件独立性。
考虑图中的 Cloudy → Sprinkler → WetGrass 这条路径。直观上,“多云"和"草地湿"是相关的——如果我知道今天多云,草地湿的概率会增加。但这种关系是间接的,完全通过"洒水器"这个中间变量传递。
这意味着什么呢?如果我们已经知道洒水器是否开了,那么"多云"和"草地湿"就不再相关了!
用数学语言说:$\text{WetGrass} \perp \text{Cloudy} \mid \text{Sprinkler}$
这就是条件独立——给定某些信息后,两个变量变得相互独立。
贝叶斯网络通过图结构自动捕捉这些条件独立性。我们不需要手动列举,只需要看图的拓扑结构就能判断哪些变量是条件独立的。这大大减少了需要指定的概率数量。
2.3 链式法则与分解
让我们看看贝叶斯网络如何实现这种分解。
对于任意一组随机变量 $X_1, X_2, …, X_n$,根据概率论的链式法则,它们的联合分布可以写成:
$$P(X_1, X_2, …, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_1, X_2) \cdot … \cdot P(X_n|X_1, …, X_{n-1})$$
在没有其他信息的情况下,每个变量可能依赖于所有前面的变量。
但如果我们知道变量之间的依赖结构(即贝叶斯网络),就可以大大简化。假设每个变量 $X_i$ 的父节点集合为 $\text{Pa}(X_i)$,那么:
$$P(X_1, X_2, …, X_n) = \prod_{i=1}^{n} P(X_i | \text{Pa}(X_i))$$
这就是贝叶斯网络的分解定理。它告诉我们:联合分布可以分解为每个变量给定其父节点的条件概率的乘积。
在"洒水器"例子中:
$$P(C, S, R, W) = P(C) \cdot P(S|C) \cdot P(R|C) \cdot P(W|S, R)$$
我们只需要指定:
- $P(C)$:多云的概率(1 个值)
- $P(S|C)$:给定是否多云时洒水器的概率(2 个值)
- $P(R|C)$:给定是否多云时下雨的概率(2 个值)
- $P(W|S, R)$:给定洒水器和下雨状态时草地湿的概率(4 个值)
总共只需要 9 个概率值,而不是 16 个!
随着变量数量增加,这种节省会更显著。对于 $n$ 个二元变量,联合分布需要 $2^n - 1$ 个值,而贝叶斯网络通常只需要 $O(n)$ 或 $O(n^2)$ 个值。
第三章:深入理解网络结构
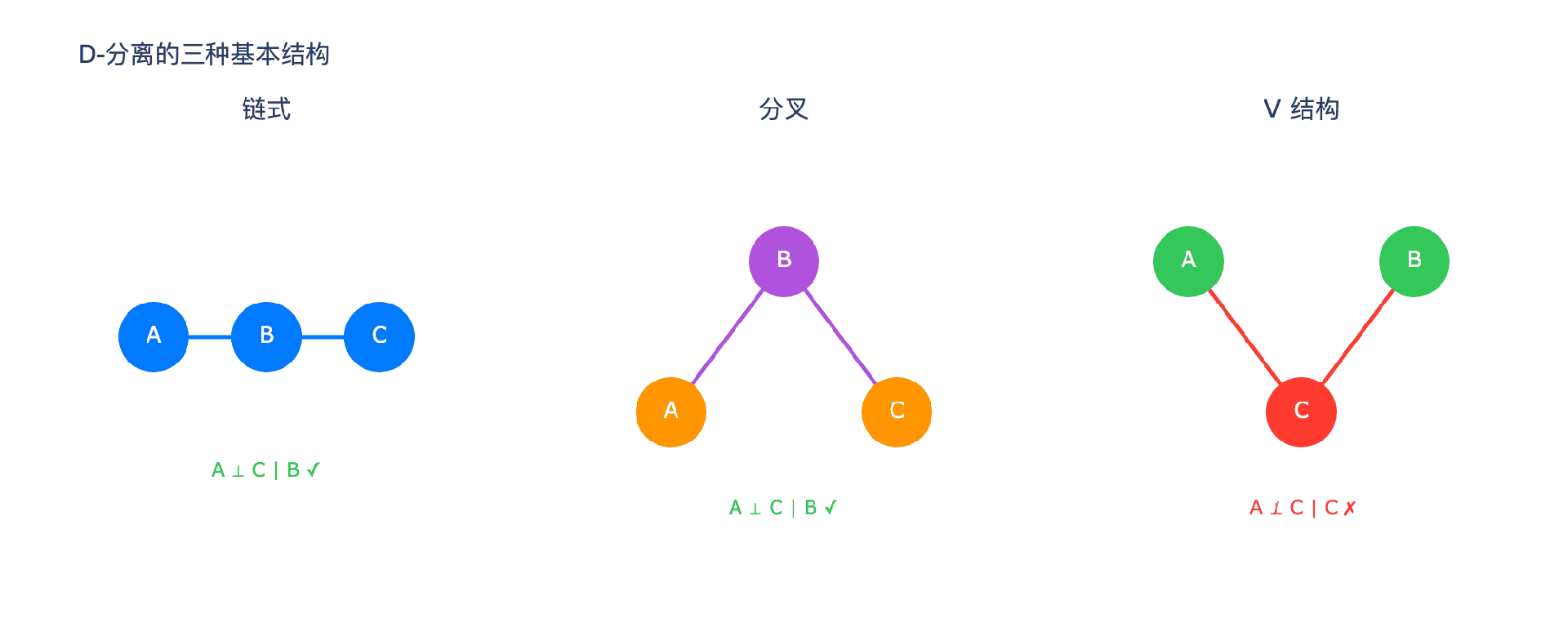
3.1 三种基本结构
任何贝叶斯网络都由三种基本结构组合而成。理解这三种结构,就理解了网络中信息流动的规律。
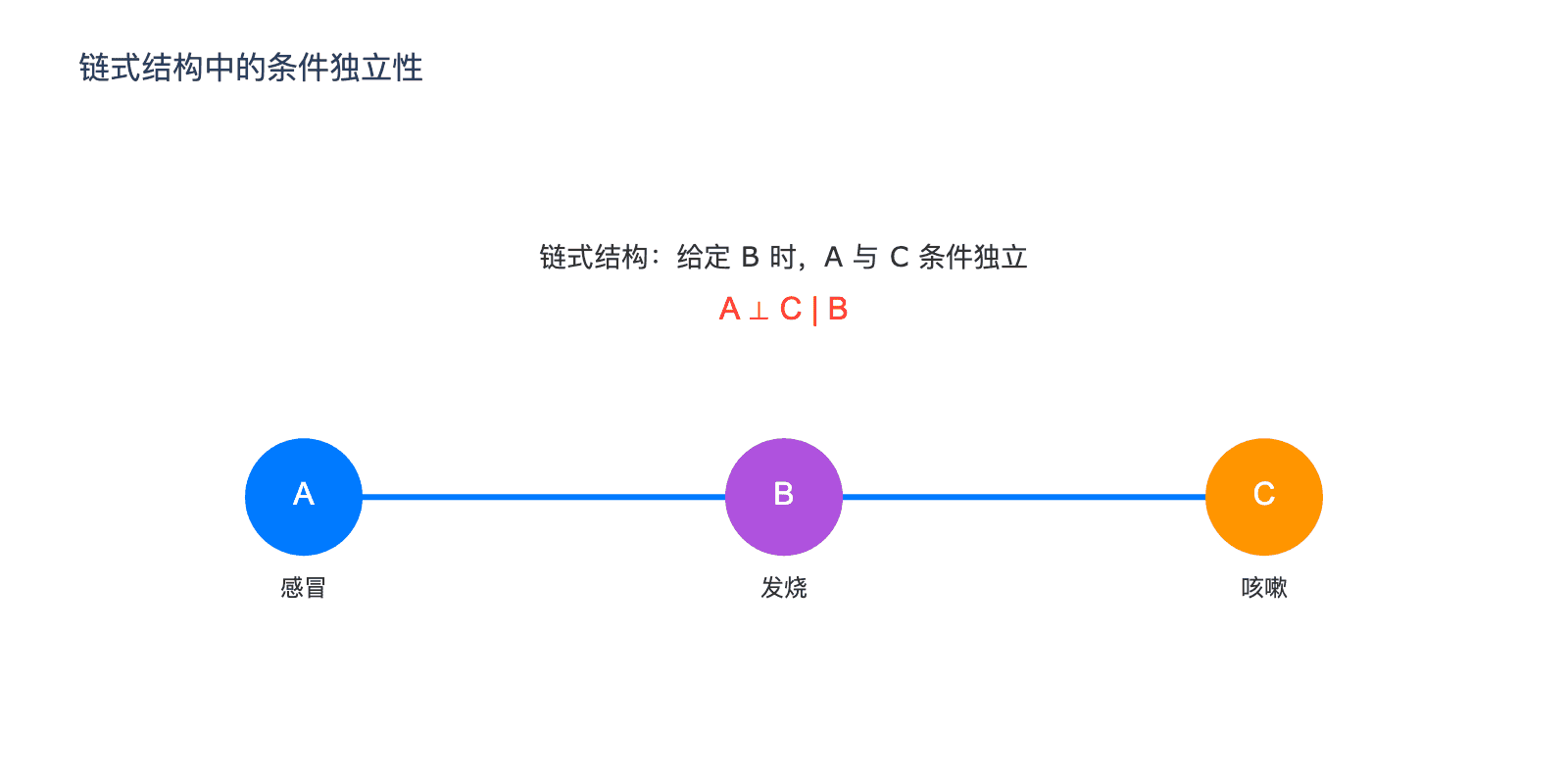
结构一:链式(Chain)
$$A \rightarrow B \rightarrow C$$
这是最简单的结构。$A$ 影响 $B$,$B$ 影响 $C$。
关键性质:给定 $B$ 时,$A$ 和 $C$ 条件独立。
直觉上:如果你已经知道一个人发烧了($B$),那么知道他是感冒($A$)并不能给你关于他是否咳嗽($C$)的额外信息——发烧已经解释了从感冒到咳嗽的全部因果链。
结构二:分叉(Fork)
$$B \leftarrow A \rightarrow C$$
$A$ 是共同的原因,同时影响 $B$ 和 $C$。
例子:季节变化($A$)同时影响温度($B$)和湿度($C$)。在不知道季节的情况下,温度和湿度是相关的——冬天通常既冷又干。但如果我们知道季节,温度和湿度就独立了。
关键性质:给定 $A$ 时,$B$ 和 $C$ 条件独立。
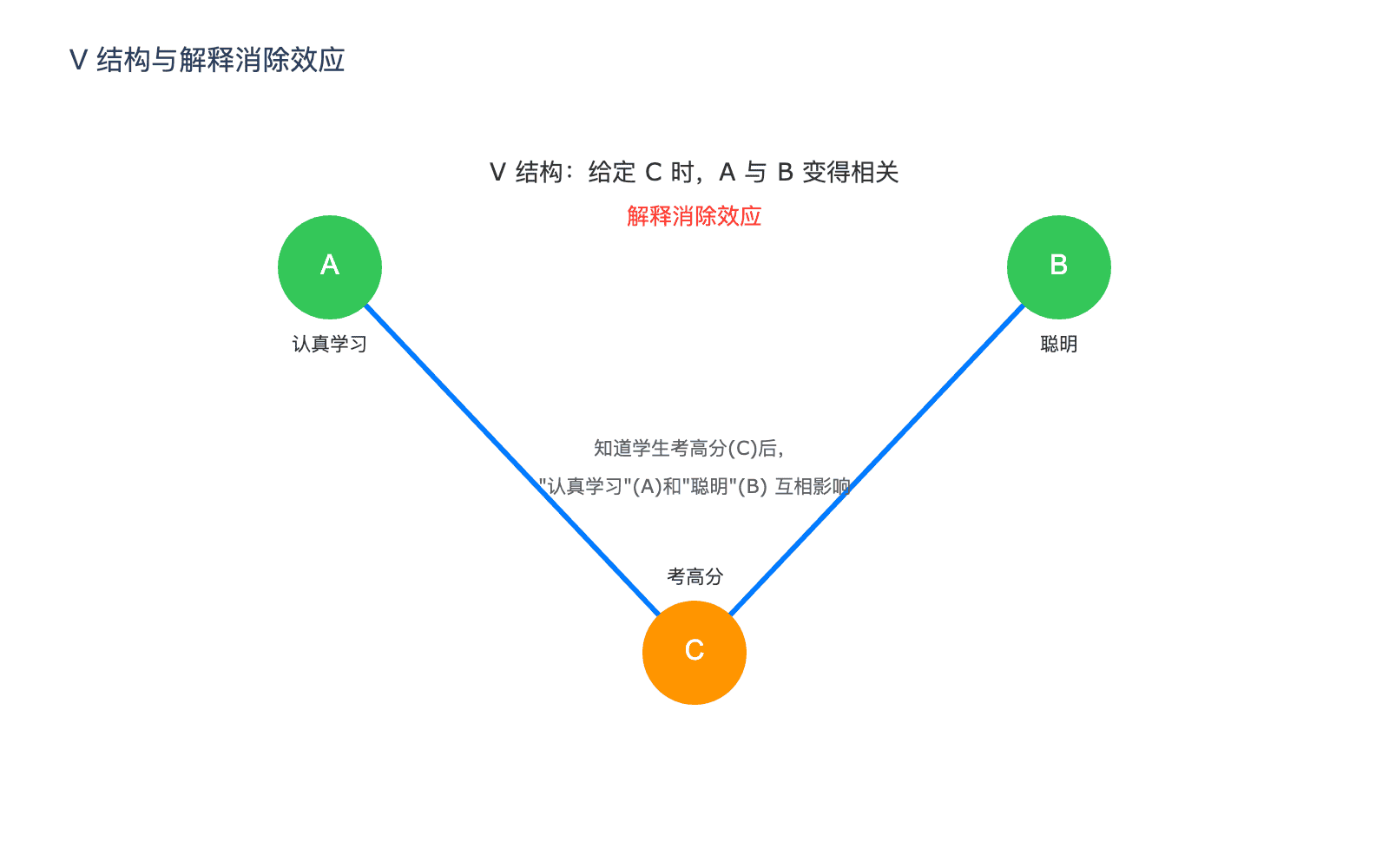
结构三:V-结构(或碰撞结构)
$$A \rightarrow C \leftarrow B$$
$A$ 和 $B$ 都影响 $C$,但 $A$ 和 $B$ 之间没有直接关系。
这是最有趣的结构。在没有任何信息的情况下,$A$ 和 $B$ 是独立的——它们没有直接联系。但是,如果我们知道 $C$ 的值,$A$ 和 $B$ 就变得相关了!
例子:一个学生考高分($C$)可能是因为认真学习($A$),也可能是因为聪明($B$)。如果我们不知道考了多少分,“认真学习"和"聪明"是两个独立的品质。但如果我们知道学生考了高分,这两个原因就开始互相影响——如果我们发现他并不聪明,我们就会推断他一定学习很努力;反之亦然。
这种现象被称为解释消除(Explaining Away)。
3.2 D-分离:判断独立性的图算法
Judea Pearl 提出了一个优美的图算法来判断任意两个变量在给定证据下是否独立,这就是D-分离(D-Separation)。
定义:如果两个节点之间的所有路径都被"阻断"了,我们就说这两个节点被 D-分离,它们在给定证据下条件独立。
路径阻断规则:
链式 $A \rightarrow B \rightarrow C$ 或 分叉 $B \leftarrow A \rightarrow C$:如果中间节点 $B$ 被观测(在给定集合中),路径被阻断。
V-结构 $A \rightarrow C \leftarrow B$:如果中间节点 $C$ 及其任何后代都未被观测,路径被阻断。
这个算法的美妙之处在于:你只需要看图的拓扑结构,不需要进行任何概率计算,就能判断条件独立性。
3.3 直观理解 D-分离
让我们用信息流的角度来理解 D-分离。
想象图中的边是"管道”,信息可以在管道中流动。我们想知道:给定某些观测变量后,两个变量之间是否还有信息流动?
链式和分叉:中间节点就像"阀门”。如果不观测中间节点,信息可以流过;如果观测了,阀门关闭,信息停止。
V-结构:这里有个奇怪的"反向阀门”。在正常情况下,两个原因之间没有信息流动。但当结果被观测后,阀门打开,两个原因开始互相"解释"对方。
这就是为什么 V-结构如此重要——它是激活信息流动的关键。
第四章:概率推理的三种类型
贝叶斯网络建立后,我们可以进行各种推理。根据证据和查询变量的位置关系,推理可以分为三种类型。
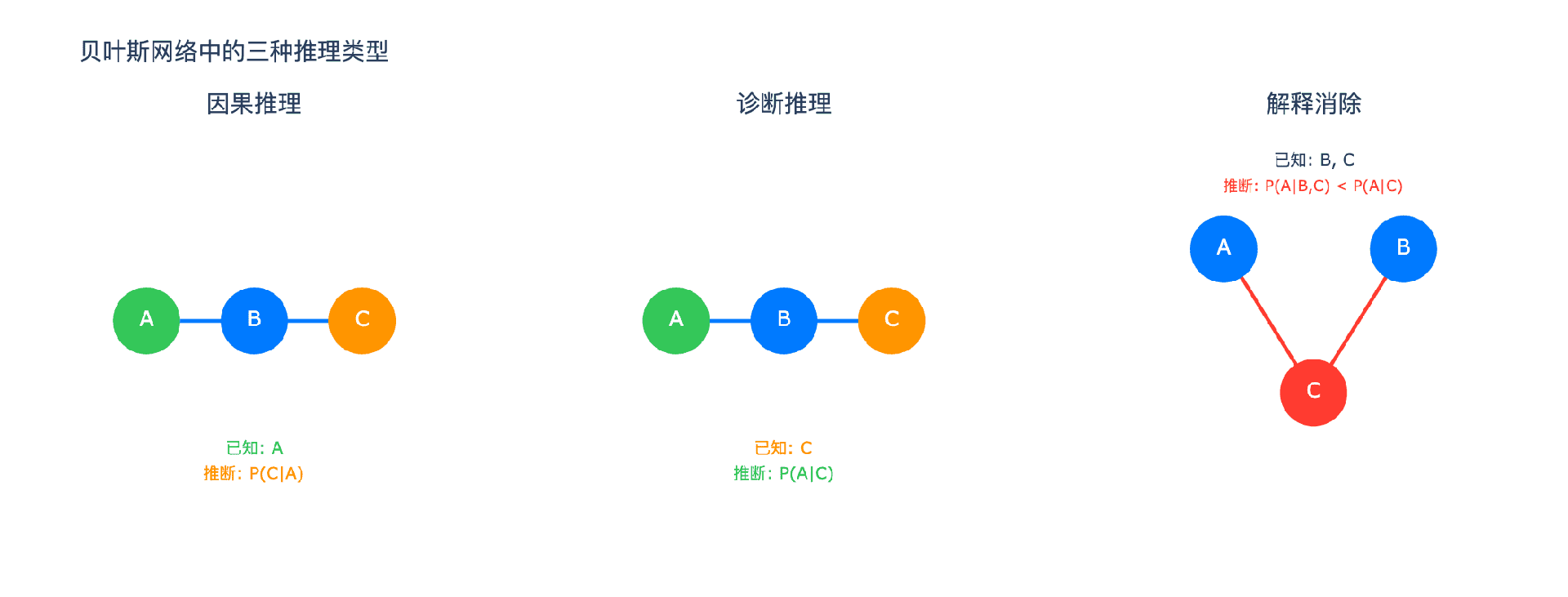
4.1 因果推理(预测)
场景:从原因推向结果。已知某个原因发生了,推测结果的可能性。
例子:
- 医学:已知患者感染了流感病毒(原因),预测他出现发烧症状(结果)的概率
- 工程:已知某个零件有缺陷(原因),预测设备故障(结果)的概率
数学上,这是计算 $P(\text{结果} | \text{原因})$。
这是最简单的推理类型,因为顺着因果方向,就是网络中边的自然方向。
4.2 诊断推理(溯因)
场景:从结果反推原因。观察到某些症状,推断最可能的病因。
例子:
- 医学:观察到患者发烧(结果),推断他最可能患了什么病(原因)
- 故障排查:设备报错(结果),找出故障部件(原因)
数学上,这是计算 $P(\text{原因} | \text{结果})$,正是贝叶斯定理的应用场景。
有趣的是,诊断推理在某种意义上比因果推理更"自然"——这正是医生日常所做的。从数学上看,它需要从叶节点向根节点传递信息,逆着网络中的边。
4.3 解释消除
场景:多个可能的原因解释一个结果。当知道其中某个原因成立时,对其他原因的相信程度会降低。
例子:
- 你看到草地湿了。可能是下雨,也可能是洒水器开了。
- 如果你发现确实下雨了,你对"洒水器开了"的相信程度会降低(虽然不是降到零,因为可能两者都发生了)。
这正是 V-结构产生的效应。解释消除在日常生活中无处不在,但很多人并不自觉地运用它。
4.4 精确推理:变量消除算法
如何在贝叶斯网络中进行实际的计算呢?最简单的方法是变量消除(Variable Elimination)。
基本思想:通过逐步消去不相关的变量,计算边缘分布。
假设我们想计算 $P(X | E=e)$,其中 $E$ 是观测到的证据。根据贝叶斯定理:
$$P(X | E=e) = \frac{P(X, E=e)}{P(E=e)}$$
分母是归一化常数,确保概率和为 1。关键是计算分子 $P(X, E=e)$。
利用贝叶斯网络的分解:
$$P(X, E=e) = \sum_{Y} \prod_{i} P(X_i | \text{Pa}(X_i))$$
其中 $Y$ 是所有未观测的非查询变量,求和是对它们所有可能取值的求和。
变量消除的技巧在于:选择求和的顺序。如果我们聪明地安排计算顺序,可以避免重复计算,大大提高效率。
举个简单例子:
$$\sum_X \sum_Y P(X) P(Y|X) P(Z|Y)$$
如果我们先对 $Y$ 求和,会得到一个关于 $X$ 和 $Z$ 的中间因子,然后再对 $X$ 求和。但如果我们改变网络结构,可能找到更高效的顺序。
寻找最优的消除顺序是一个 NP-hard 问题,但在实践中,启发式方法通常能给出不错的结果。
4.5 近似推理:采样方法
对于大型网络,精确推理可能仍然太慢。这时候我们可以使用近似推理方法,其中最常见的是蒙特卡洛采样。
基本思想:与其精确计算概率分布,不如从这个分布中生成大量样本,然后用样本的统计来近似真实分布。
最简单的算法是逻辑采样(Logic Sampling):
- 按照拓扑顺序,从根节点开始
- 对于每个节点,根据其父节点的取值,从条件概率表中采样
- 重复生成大量样本
- 用满足证据条件的样本中查询变量的分布,来近似后验分布
更高级的算法如吉布斯采样(Gibbs Sampling)和似然加权采样(Likelihood Weighting)可以更高效地处理证据变量。
这些采样方法的优点是:它们可以处理任意复杂的网络,而且随着样本量增加,近似结果会收敛到真实分布。
第五章:从理论到实践
5.1 贝叶斯网络的应用领域
贝叶斯网络被广泛应用于各个领域:
医学诊断
- Pathfinder 系统:用于淋巴结病理诊断,性能达到专家水平
- MYCIN:早期的医学专家系统,虽然不使用严格的贝叶斯网络,但采用了类似的概率推理思想
- 现代医疗 AI 系统大量使用概率图模型进行疾病预测和诊断支持
自然语言处理
- 隐马尔可夫模型(HMM):可以看作是一种特殊的贝叶斯网络,广泛应用于语音识别、词性标注
- 条件随机场(CRF):与贝叶斯网络密切相关,用于序列标注任务
计算机视觉
- 图像分割、场景理解中的概率模型
- 马尔可夫随机场(MRF):贝叶斯网络在无向图上的推广
风险评估与决策支持
- 金融风险管理
- 生态风险评估
- 工程安全分析
推荐系统
- 用户偏好建模
- 协同过滤的概率方法
5.2 学习贝叶斯网络
构建一个贝叶斯网络涉及两个步骤:
1. 结构学习(Structure Learning)
确定网络的图结构——哪些变量之间有关系,方向是什么?
基于专家知识:由领域专家手工构建。优点是可以利用专业知识,缺点是耗时且可能有遗漏。
基于数据学习:从数据中学习最优结构。常用算法包括:
- 评分搜索方法:定义一个评分函数(如 BIC、BDeu),衡量结构与数据的拟合程度,然后搜索得分最高的结构
- 约束方法:使用条件独立性检验(如 PC 算法)来确定边的存在与否
结构学习是一个具有挑战性的问题,因为可能的图结构数量是超指数级的。
2. 参数学习(Parameter Learning)
给定网络结构,学习每个条件概率表(CPT)的参数。
最大似然估计(MLE):简单的计数方法 $$P(X=x | \text{Pa}(X)=\pi) = \frac{\text{计数}(X=x, \text{Pa}(X)=\pi)}{\text{计数}(\text{Pa}(X)=\pi)}$$
贝叶斯估计:引入先验分布,避免零概率问题
- 使用狄利克雷先验,结合数据得到后验分布
5.3 贝叶斯网络与机器学习
贝叶斯网络与机器学习有着深刻的联系:
朴素贝叶斯本质上是一种极其简化的贝叶斯网络——所有特征节点都直接连接到类别节点,特征之间没有连接。
隐马尔可夫模型是贝叶斯网络在时序数据上的应用——状态形成链式结构,每个状态生成一个观测。
深度生成模型,如变分自编码器(VAE),可以被理解为连续的、大规模的贝叶斯网络——编码器推断潜在变量的后验,解码器从潜在变量生成数据。
这种联系告诉我们:理解贝叶斯网络的基本原理,对理解更复杂的机器学习模型大有裨益。
第六章:深入思考
6.1 因果性与相关性
贝叶斯网络中最微妙也最重要的问题是:箭头的方向意味着什么?
严格来说,贝叶斯网络只要求图是有向无环图(DAG),边的方向最初是为了正确分解联合分布。但在实际应用中,我们通常希望边的方向反映因果关系。
这引出了因果推断这一深刻课题。Judea Pearl 后来发展了因果图(Causal Diagram)理论,使用do-演算(do-calculus)来从观测数据中推断因果效应。
核心洞见:
- 相关性不等于因果性
- 但如果我们知道正确的因果结构(或能部分识别它),就可以从相关性推断因果性
- 混杂变量(Confounder)是混淆因果推断的主要原因
6.2 贝叶斯网络与因果发现
一个令人兴奋的研究方向是因果发现(Causal Discovery):能否从纯观测数据中自动学习因果关系?
一些重要的结果:
- PC 算法:利用条件独立性检验逐步构建因果骨架
- ICA 方法:利用非高斯性识别因果方向
- 加性噪声模型:假设噪声以特定方式进入系统,可以识别因果方向
这些方法都有各自的假设和限制,但展示了从数据中发现因果规律的可能性。
6.3 贝叶斯网络的局限性
尽管强大,贝叶斯网络也有局限:
1. 计算复杂度
- 精确推理在一般网络上是 NP-hard 的
- 近似推理在某些情况下也可能失效
2. 结构学习困难
- 寻找最优结构是组合爆炸问题
- 数据不足时难以可靠学习
3. 表达能力限制
- 只能表示特定类型的依赖关系(通过 DAG)
- 对于连续变量,通常需要做出分布假设(如高斯分布)
4. 因果方向的困难
- 从纯数据中学习因果方向非常困难
- 往往需要领域知识或额外的假设
6.4 贝叶斯网络与神经网络
在当今深度学习盛行的时代,贝叶斯网络似乎有些"过时"。但实际上,它们代表了两种不同的思路:
| 特性 | 贝叶斯网络 | 神经网络 |
|---|---|---|
| 可解释性 | 高(明确的概率语义) | 低(黑盒模型) |
| 数据需求 | 较少(可利用先验知识) | 大量数据 |
| 表达能力 | 受结构限制 | 极高(万能逼近定理) |
| 推理能力 | 内置概率推理 | 需要额外设计 |
| 训练难度 | 结构学习困难 | 梯度下降成熟 |
实际上,两者正在融合。神经概率模型、深度贝叶斯网络等方向结合了两者的优势。
结语
贝叶斯网络为我们提供了一种在不确定世界中理性思考的工具。它告诉我们:
复杂问题可以分解。利用条件独立性,我们可以将指数级的复杂问题分解为可管理的局部计算。
概率是一种信念。贝叶斯方法的核心是:概率不仅描述客观随机性,更反映我们对世界的主观认知,这种认知会随着新证据而更新。
结构就是知识。贝叶斯网络中的图结构编码了领域知识——什么影响什么,什么在什么条件下独立。这种显式的知识表示使模型具有可解释性。
因果是根本。相关性只是表象,因果才是本质。理解因果,才能真正理解世界,做出有效的干预和决策。
Judea Pearl 因为在贝叶斯网络和因果推断方面的开创性工作获得了 2011 年的图灵奖。他开创的这套框架,至今仍是人工智能领域最重要的基础理论之一。
对于想要深入学习的读者,推荐阅读 Pearl 的经典著作《Probabilistic Reasoning in Intelligent Systems》以及更通俗的《The Book of Why》。
贝叶斯网络不只是一个数学工具,更是一种思维方式——在不确定中寻求确定,在复杂中寻找简洁,在现象背后发现因果。这种思维方式,在这个充满不确定性的时代,显得尤为珍贵。
延伸阅读:
- Judea Pearl. “Probabilistic Reasoning in Intelligent Systems.” Morgan Kaufmann, 1988.
- Judea Pearl and Dana Mackenzie. “The Book of Why: The New Science of Cause and Effect.” Basic Books, 2018.
- Koller, D., & Friedman, N. “Probabilistic Graphical Models: Principles and Techniques.” MIT Press, 2009.
- Barber, D. “Bayesian Reasoning and Machine Learning.” Cambridge University Press, 2012.
关键概念总结:
- 贝叶斯定理:$P(H|E) = \frac{P(E|H) P(H)}{P(E)}$
- 条件独立:$X \perp Y | Z$ 表示给定 $Z$ 时 $X$ 和 $Y$ 独立
- 链式法则分解:$P(X_1, …, X_n) = \prod_i P(X_i | \text{Pa}(X_i))$
- D-分离:通过图结构判断条件独立性的算法
- 三种推理:因果推理、诊断推理、解释消除