
引言
在编程语言的谱系中,Scala 占据着一个独特的位置。它的名字源于 “Scalable Language”(可扩展的语言),这个命名本身就蕴含了设计者的雄心——创造一门能够随需求增长而扩展的语言。Scala 由 Martin Odersky 于 2001 年开始设计,2004 年正式发布,它成功地将面向对象编程(OOP)与函数式编程(FP)两种范式融合在一门语言之中。
Scala 设计哲学:"简单优于复杂,但表达力不应因此受限"。这意味着语言应该提供强大的抽象能力,同时保持代码的简洁性。可以想象成 Scala 是一把瑞士军刀——功能丰富但体积紧凑,每个工具都经过精心设计。
与 Java 的冗长相比,Scala 提供了更简洁的语法;与纯函数式语言如 Haskell 相比,Scala 保留了面向对象的灵活性。这种平衡使 Scala 成为大数据处理(Apache Spark)、分布式系统(Akka)和并发编程的理想选择。
本文将沿着时间线追溯 Scala 的演进历程,剖析其核心语法与特性,探讨这门语言如何在保持学术严谨性的同时,成功应用于工业级系统。
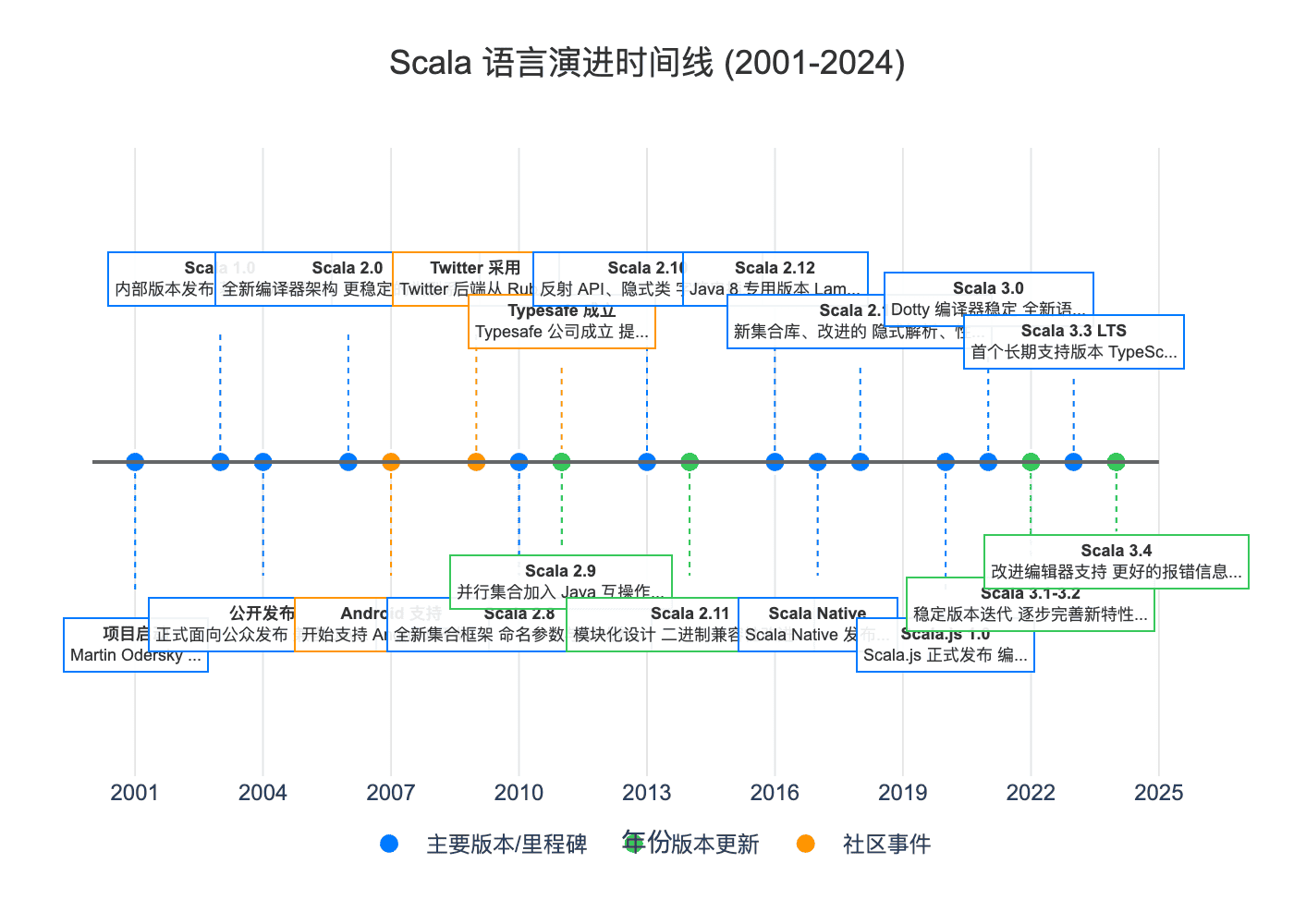
第一章:诞生与早期探索 (2001-2006)
1.1 2001-2003:从 Funnel 到 Scala
Martin Odersky 是瑞士洛桑联邦理工学院(EPFL)的教授,在此之前,他曾参与 Java 泛型的设计和 Sun 公司 Java 编译器(javac)的开发工作。这些经历让他深刻理解了 Java 的优势与局限。
2001 年,Odersky 开始设计 Scala。这个项目源于对 Funnel 语言的研究——一种结合了函数式编程和 Petri 网的实验性语言。Funnel 的学术价值很高,但实用性不足。Odersky 希望创造一门既保持理论优雅,又能在工业环境中实用的语言。
Scala 的核心设计目标:
- 与 Java 无缝互操作(运行于 JVM)
- 融合面向对象和函数式编程
- 通过类型推断减少代码冗余
- 提供强大的模式匹配和代数数据类型
1.2 2004 年:首次公开发布
2004 年 1 月 20 日,Scala 正式向公众发布。第一个公开版本(1.1.0)展示了以下核心特性:
// Scala 1.x 风格代码
object HelloWorld {
def main(args: Array[String]): Unit = {
println("Hello, World!")
}
}
// 基本的函数式特性
val numbers = List(1, 2, 3, 4, 5)
val doubled = numbers.map(x => x * 2) // List(2, 4, 6, 8, 10)
val sum = numbers.reduce(_ + _) // 15
1.3 2006 年:Scala 2.0 的革命
2006 年 3 月发布的 Scala 2.0 是一次重大重构:
- 全新设计的编译器架构
- 更稳健的类型系统实现
- 改进的 Java 互操作性
这一时期,Scala 开始吸引学术界的关注,同时也进入了工业界的视野。
第二章:工业化与生态建设 (2006-2013)
2.1 2009 年:Twitter 的背书
2009 年 4 月,Twitter 宣布将其核心后端系统从 Ruby 迁移到 Scala。这是一个里程碑事件——它证明了 Scala 能够支撑大规模、高并发的生产环境。
Twitter 的迁移动机:
- Ruby 的性能无法满足增长需求
- Java 生态成熟但过于冗长
- Scala 提供了性能与简洁的完美平衡
2.2 2010 年:Scala 2.8 的集合框架革新
Scala 2.8(2010 年 7 月)引入了全新的集合框架,这被认为是 Scala 标准库最重要的改进之一:
// 统一的集合接口
val list = List(1, 2, 3)
val set = Set(1, 2, 3)
val map = Map("a" -> 1, "b" -> 2)
// 高阶函数操作
val result = list
.filter(_ > 1) // 过滤
.map(_ * 2) // 映射
.take(2) // 取前两个
// 结果: List(4, 6)
// 命名参数和默认参数
def greet(name: String, greeting: String = "Hello"): String =
s"$greeting, $name!"
greet("Alice") // "Hello, Alice!"
greet("Bob", "Hi") // "Hi, Bob!"
greet(name = "Charlie") // "Hello, Charlie!"
2.3 2011 年:Typesafe 公司成立
2011 年 5 月,Martin Odersky 与合作伙伴创立了 Typesafe 公司(后更名为 Lightbend),为 Scala 提供商业支持、培训和服务。Greylock Partners 投资了 300 万美元,这标志着 Scala 正式进入企业级市场。
同年发布的 Scala 2.9 引入了并行集合(Parallel Collections):
import scala.collection.parallel.CollectionConverters._
val numbers = (1 to 1000000).toList
// 串行处理
val serialSum = numbers.map(x => x * x).sum
// 并行处理 - 自动利用多核
val parallelSum = numbers.par.map(x => x * x).sum
2.4 2013 年:Scala 2.10 的现代化
Scala 2.10(2013 年 1 月)带来了多项重要特性:
字符串插值:
val name = "Alice"
val age = 30
println(s"$name is $age years old") // "Alice is 30 years old"
println(s"Next year: ${age + 1}") // "Next year: 31"
隐式类(Extension Methods):
implicit class IntOps(val n: Int) extends AnyVal {
def squared: Int = n * n
def isEven: Boolean = n % 2 == 0
}
5.squared // 25
4.isEven // true
反射 API 和宏(实验性):
import scala.reflect.runtime.universe._
def getTypeTag[T: TypeTag](obj: T): TypeTag[T] = typeTag[T]
val tpe = getTypeTag(List(1, 2, 3))
println(tpe.tpe) // List[Int]
第三章:成熟与多平台扩展 (2013-2020)
3.1 2014-2016:模块化与 Java 8 时代
Scala 2.11(2014 年 4 月)采用了模块化设计,将标准库拆分为多个独立模块,减小了依赖体积。
Scala 2.12(2016 年 11 月)是一个专为 Java 8 设计的版本:
- 完全利用 JVM 的 invokedynamic 指令
- Scala 函数直接编译为 Java 8 Lambda
- 与 Java 8 Stream API 的无缝互操作
// Scala 2.12+ 中,Scala 函数就是 Java Lambda
val scalaFunc: Int => Int = x => x * 2
// 可直接传递给 Java 方法
java.util.Arrays.asList(1, 2, 3)
.stream()
.mapToInt(x => x)
.map(scalaFunc) // 直接复用 Scala 函数
.sum()
3.2 2017 年:Scala Native 的突破
Scala Native 项目于 2017 年 3 月发布 0.1 版本,它基于 LLVM 将 Scala 代码编译为原生可执行文件:
- 无需 JVM,生成独立可执行文件
- 更快的启动时间
- 更小的内存占用
- 支持直接调用 C 库
import scala.scalanative.libc.stdio._
object HelloNative {
def main(args: Array[String]): Unit = {
fprintf(stdout, c"Hello from Scala Native!\n")
}
}
3.3 2018-2019:Scala 2.13 与 Scala.js 成熟
Scala 2.13(2019 年 6 月)带来了新的集合库实现:
- 改进的性能特性
- 更清晰的类层次结构
- 更好的延迟求值支持
Scala.js 于 2015 年宣布稳定,2018 年发布 1.0.0-M1,使 Scala 能够编译为 JavaScript:
// Scala.js - 在浏览器中运行的 Scala
import org.scalajs.dom
import org.scalajs.dom.document
def appendPar(text: String): Unit = {
val parNode = document.createElement("p")
parNode.textContent = text
document.body.appendChild(parNode)
}
// 操作 DOM,事件处理
import org.scalajs.dom.ext._
document.getElementById("click-me").onclick = { e =>
appendPar("Clicked!")
}
第四章:Scala 3 时代——Dotty 的重生 (2020-至今)
4.1 2021 年:Scala 3.0 (Dotty) 发布
经过八年的开发,Scala 3(代号 Dotty)于 2021 年 5 月 13 日发布。这是 Scala 历史上最重要的版本更新,重新设计了编译器架构和语言特性。
显著的新语法(可选缩进风格)
// Scala 3: 可选的缩进风格(无需花括号)
object Hello:
def main(args: Array[String]): Unit =
println("Hello, Scala 3!")
if args.length > 0 then
println(s"Args: ${args.mkString(", ")}")
else
println("No args")
// 枚举类型
enum Color:
case Red, Green, Blue
case RGB(r: Int, g: Int, b: Int)
// 透明类型别名
opaque type UserId = Long
object UserId:
def apply(id: Long): UserId = id
extension (id: UserId) def value: Long = id
全新的类型系统特性
// 给定型(Given)—— 替代隐式参数
trait Ord[T]:
def compare(x: T, y: T): Int
// 使用 given 定义实例
given intOrd: Ord[Int] with
def compare(x: Int, y: Int): Int = x - y
// 使用 using 声明上下文参数
def sort[T](xs: List[T])(using ord: Ord[T]): List[T] =
xs.sorted(ord.compare)
// 类型类派生(自动派生)
enum Tree[T] derives Eq, Show:
case Leaf(value: T)
case Node(left: Tree[T], right: Tree[T])
4.2 2022-2023:稳定化与 LTS 版本
Scala 3.2(2022 年)进一步完善了编译器性能和 IDE 支持。
Scala 3.3 LTS(2023 年 5 月)是第一个长期支持版本,承诺提供多年的维护更新。这标志着 Scala 3 已经成熟到足以承担企业级应用。
4.3 2024 年:编辑器支持与工具链改进
最新的 Scala 3.4 版本专注于开发者体验:
- 改进的 Metals(Scala 语言服务器)支持
- 更好的错误提示信息
- 更快的编译速度
第五章:Scala 核心语法精粹
5.1 变量声明与类型推断
Scala 区分可变(var)和不可变(val)变量,鼓励使用不可变数据结构:
// 不可变变量(推荐)
val name: String = "Alice"
val age = 30 // 类型推断为 Int
// name = "Bob" // 编译错误!
// 可变变量
var counter = 0
counter += 1 // 允许修改
// 延迟求值
lazy val expensive = {
println("Computing...")
computeSomethingExpensive()
}
// expensive 只有在首次使用时才会计算
5.2 函数与一等公民
函数在 Scala 中是一等公民:
// 函数定义
val add: (Int, Int) => Int = (a, b) => a + b
// 更简洁的写法
val multiply = (a: Int, b: Int) => a * b
// 下划线简写(eta 扩展)
val square: Int => Int = math.pow(_, 2).toInt
// 高阶函数
def applyOp(a: Int, b: Int, op: (Int, Int) => Int): Int = op(a, b)
applyOp(3, 4, add) // 7
applyOp(3, 4, _ * _) // 12
applyOp(3, 4, _ + _ * 2) // 11
// 柯里化
def curriedAdd(a: Int)(b: Int): Int = a + b
val addFive = curriedAdd(5)_
addFive(3) // 8
// 部分应用函数
val addToTen = add(_, 10)
addToTen(5) // 15
5.3 模式匹配——强大的 switch 替代
Scala 的模式匹配远比传统 switch 语句强大:
// 基本模式匹配
def describe(x: Any): String = x match {
case i: Int if i > 0 => s"正整数: $i"
case i: Int => s"非正整数: $i"
case s: String => s"字符串: $s"
case List(a, b, _*) => s"至少两个元素的列表: $a, $b, ..."
case null => "空值"
case _ => "其他类型"
}
// 样例类与模式匹配
case class Person(name: String, age: Int)
case class Company(name: String, employees: List[Person])
val company = Company("TechCorp", List(
Person("Alice", 30),
Person("Bob", 25)
))
// 深度解构
company match {
case Company(name, Person(firstName, _) :: _) =>
println(s"$name 的第一个员工是 $firstName")
}
// 提取器(Extractor)
object Email {
def unapply(str: String): Option[(String, String)] = {
val parts = str.split("@")
if (parts.length == 2) Some((parts(0), parts(1))) else None
}
}
"user@example.com" match {
case Email(user, domain) => println(s"用户: $user, 域名: $domain")
case _ => println("不是有效邮箱")
}
5.4 集合操作与函数式编程
Scala 的集合库是函数式编程的典范:
val numbers = List(1, 2, 3, 4, 5)
// map, filter, reduce
val doubled = numbers.map(_ * 2) // List(2, 4, 6, 8, 10)
val evens = numbers.filter(_ % 2 == 0) // List(2, 4)
val product = numbers.reduce(_ * _) // 120
// flatMap - 扁平化映射
val nested = List(List(1, 2), List(3, 4))
val flat = nested.flatMap(_.map(_ * 2)) // List(2, 4, 6, 8)
// for 推导式(语法糖)
val combinations = for {
x <- List(1, 2, 3)
y <- List('a', 'b')
if x > 1
} yield (x, y)
// List((2,a), (2,b), (3,a), (3,b))
// 分组与聚合
val words = List("apple", "banana", "cherry", "apricot")
val byFirstLetter = words.groupBy(_.head) // Map(a -> ..., b -> ..., c -> ...)
val lengths = words.map(_.length).sum // 22
// 惰性集合
val infinite = Stream.from(1) // 无限序列
val fibonacci: Stream[Int] =
0 #:: 1 #:: fibonacci.zip(fibonacci.tail).map { case (a, b) => a + b }
fibonacci.take(10).toList // List(0, 1, 1, 2, 3, 5, 8, 13, 21, 34)
5.5 面向对象与 Trait
Scala 的面向对象特性在 Java 基础上进行了扩展:
// 抽象类
abstract class Animal(val name: String) {
def speak(): Unit
def move(): Unit = println(s"$name is moving")
}
// Trait(类似 Java 接口,但可以有实现)
trait Swimmer {
def swim(): Unit = println("Swimming...")
}
trait Flyer {
def fly(): Unit
}
// 多重继承
class Duck(name: String) extends Animal(name)
with Swimmer
with Flyer {
def speak(): Unit = println("Quack!")
def fly(): Unit = println("Flying like a duck")
}
// 单例对象
object Logger {
def log(msg: String): Unit = println(s"[${java.time.Instant.now}] $msg")
}
// 伴生对象(Companion Object)
class Circle(val radius: Double)
object Circle {
def apply(r: Double): Circle = new Circle(r)
def unit: Circle = new Circle(1.0)
implicit class CircleOps(c: Circle) {
def area: Double = math.Pi * c.radius * c.radius
}
}
val c = Circle(5.0)
println(c.area) // 78.54...
5.6 并发与 Future
Scala 提供了强大的并发编程抽象:
import scala.concurrent.{Future, ExecutionContext}
import scala.concurrent.duration._
import scala.util.{Success, Failure}
implicit val ec: ExecutionContext = ExecutionContext.global
// 异步计算
val futureResult: Future[Int] = Future {
Thread.sleep(1000) // 模拟耗时操作
42
}
// 组合 Future
val result = for {
a <- fetchUserId()
b <- fetchUserData(a)
c <- processData(b)
} yield c
result.onComplete {
case Success(value) => println(s"Result: $value")
case Failure(e) => println(s"Failed: ${e.getMessage}")
}
// 并行执行
val parallel = Future.sequence(List(
Future { compute(1) },
Future { compute(2) },
Future { compute(3) }
))
第六章:Scala 的应用场景与生态
6.1 大数据处理:Apache Spark
Scala 是 Apache Spark 的原生语言,Spark 的 API 设计充分体现了 Scala 的函数式特性:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
val spark = SparkSession.builder()
.appName("ScalaSparkExample")
.master("local[*]")
.getOrCreate()
import spark.implicits._
// DataFrame 操作
case class Person(name: String, age: Int, city: String)
val df = Seq(
Person("Alice", 30, "NYC"),
Person("Bob", 25, "SF"),
Person("Charlie", 35, "NYC")
).toDF()
// 函数式风格的转换
val result = df
.filter($"age" > 25)
.groupBy("city")
.agg(avg("age").alias("avg_age"), count("*").alias("count"))
.orderBy(desc("avg_age"))
result.show()
// 自定义 UDF
val upperCase = udf((s: String) => s.toUpperCase)
df.withColumn("name_upper", upperCase($"name")).show()
spark.stop()
6.2 分布式系统:Akka Actor 模型
Scala 的 Akka 库实现了 Actor 模型,简化了并发和分布式编程:
import akka.actor.typed.{ActorRef, ActorSystem, Behavior}
import akka.actor.typed.scaladsl.Behaviors
// 定义消息协议
sealed trait Command
final case class GetValue(replyTo: ActorRef[Int]) extends Command
final case class Increment(amount: Int) extends Command
// Actor 实现
def counter(count: Int): Behavior[Command] =
Behaviors.receive { (context, message) =>
message match {
case GetValue(replyTo) =>
replyTo ! count
Behaviors.same
case Increment(amount) =>
counter(count + amount)
}
}
// 使用 Actor
val system = ActorSystem(counter(0), "CounterSystem")
val probe = ActorTestProbe[Int]()
system ! Increment(5)
system ! GetValue(probe.ref)
probe.expectMessage(5)
system.terminate()
6.3 Web 开发:Play Framework
import play.api.mvc._
import play.api.libs.json._
import javax.inject._
case class User(id: Long, name: String, email: String)
object User {
implicit val format: OFormat[User] = Json.format[User]
}
@Singleton
class UserController @Inject()(cc: ControllerComponents)
extends AbstractController(cc) {
private var users = List(
User(1, "Alice", "alice@example.com"),
User(2, "Bob", "bob@example.com")
)
// GET /users
def list = Action {
Ok(Json.toJson(users))
}
// GET /users/:id
def get(id: Long) = Action {
users.find(_.id == id) match {
case Some(user) => Ok(Json.toJson(user))
case None => NotFound(Json.obj("error" -> "User not found"))
}
}
// POST /users
def create = Action(parse.json) { request =>
request.body.validate[User].fold(
errors => BadRequest(Json.obj("error" -> JsError.toJson(errors))),
user => {
users = user :: users
Created(Json.toJson(user))
}
)
}
}
6.4 类型安全的数据库访问:Slick
import slick.jdbc.H2Profile.api._
import scala.concurrent.{Future, ExecutionContext}
// 定义表映射
class UsersTable(tag: Tag) extends Table[User](tag, "users") {
def id = column[Long]("id", O.PrimaryKey, O.AutoInc)
def name = column[String]("name")
def email = column[String]("email")
def * = (id, name, email) <> (User.tupled, User.unapply)
}
val users = TableQuery[UsersTable]
// 类型安全的数据库操作
val db = Database.forConfig("h2mem1")
val setup = DBIO.seq(
users.schema.create,
users += User(1, "Alice", "alice@example.com"),
users += User(2, "Bob", "bob@example.com")
)
val query = users.filter(_.name === "Alice").result
// 编译时检查 SQL 正确性!
db.run(setup).flatMap { _ =>
db.run(query).map(println)
}
第七章:Scala 的前景与展望
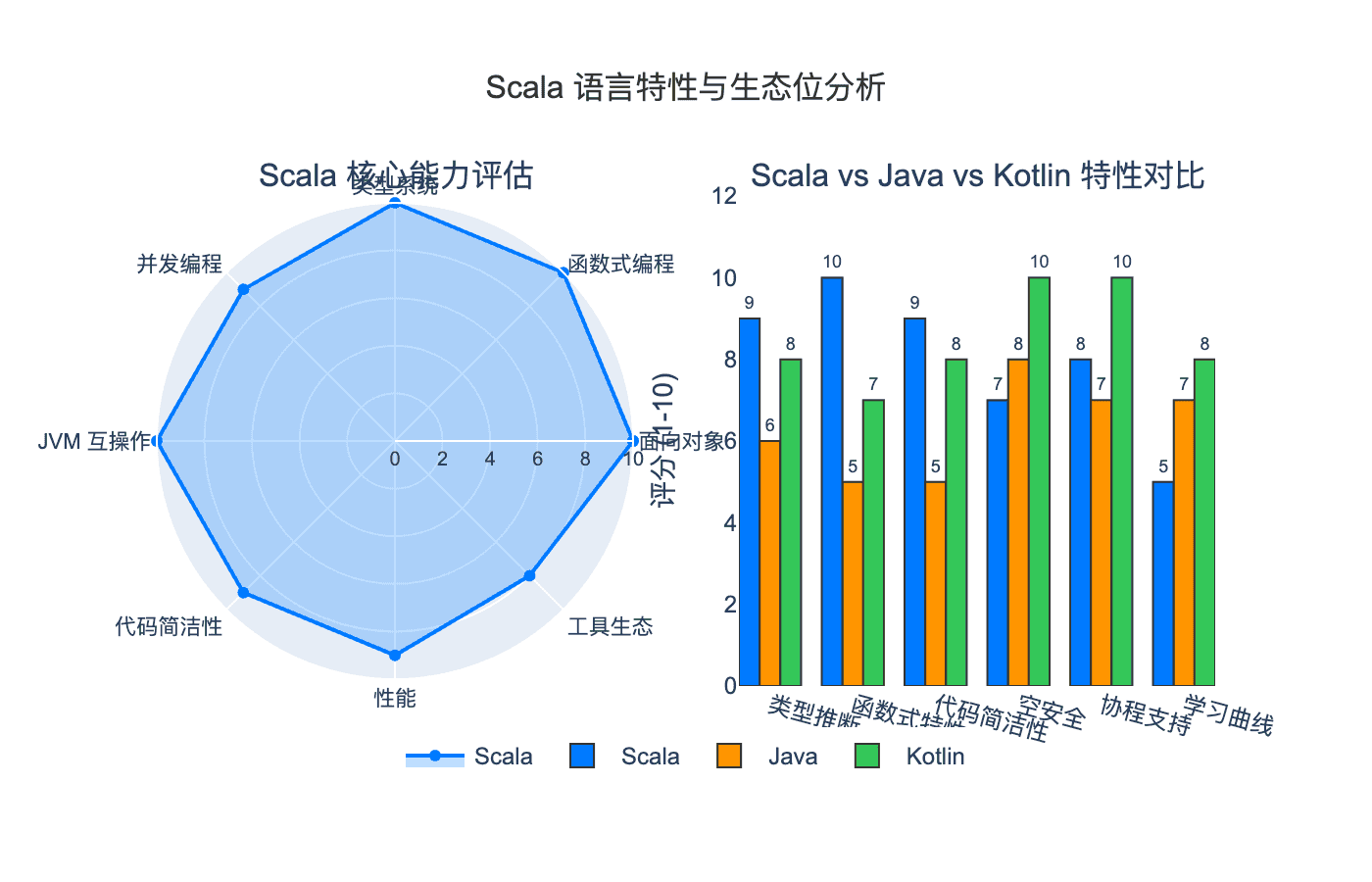
7.1 Scala 的生态定位
在当今编程语言的版图中,Scala 占据着一个独特的生态位:
| 领域 | 地位评估 | 代表应用 |
|---|---|---|
| 大数据处理 | ⭐⭐⭐⭐⭐ | Apache Spark、Apache Kafka |
| 分布式系统 | ⭐⭐⭐⭐⭐ | Akka、Lagom |
| 并发编程 | ⭐⭐⭐⭐ | Futures、Cats Effect、ZIO |
| Web 后端 | ⭐⭐⭐ | Play Framework、http4s |
| 前端开发 | ⭐⭐ | Scala.js |
| 原生应用 | ⭐⭐ | Scala Native |
7.2 优势与挑战
Scala 的核心优势:
- 融合 OOP 与 FP:既保留面向对象的结构化能力,又具备函数式的表达力
- 强大的类型系统:编译时捕获错误,同时保持代码简洁
- JVM 生态:无缝利用 Java 庞大的库生态
- 表达力与简洁性:用更少的代码表达更多的意图
- 成熟的大数据生态:Spark、Flink、Kafka 等核心项目
Scala 面临的挑战:
- 学习曲线陡峭:概念丰富,需要时间掌握
- 编译速度:相比 Java/Kotlin 仍较慢(Scala 3 已大幅改进)
- Kotlin 的竞争:JetBrains 的推广使 Kotlin 成为 JVM 生态的新宠
- 人才市场:相对 Java,Scala 开发者数量较少
7.3 未来展望
Scala 的未来发展可能呈现以下趋势:
Scala 3 的普及:随着 LTS 版本的发布,更多项目将迁移到 Scala 3,享受改进的语法和工具支持。
函数式编程的主流化:随着 Java 引入 Lambda、Stream API,以及 Kotlin 的流行,函数式编程理念正在被更广泛接受,Scala 的先发优势将更加明显。
Typelevel 生态的壮大:Cats、ZIO、fs2 等纯函数式库正在构建 Scala 的"下一代"生态,提供更强大的类型安全保证。
// ZIO: Scala 的下一代并发库
import zio._
import zio.console._
val program: ZIO[Console, Nothing, Unit] = for {
_ <- putStrLn("Hello")
name <- getStrLn
_ <- putStrLn(s"Hello, $name")
} yield ()
Runtime.default.unsafeRun(program)
多平台战略的深化:Scala.js 和 Scala Native 的成熟将使 Scala 真正跨平台——同一套代码运行于 JVM、浏览器和原生环境。
AI/ML 领域的机会:随着大数据与机器学习融合,Scala 在 Spark MLlib 等项目的积累可能带来新的增长点。
7.4 给开发者的建议
对于考虑学习或使用 Scala 的开发者:
如果你从事大数据/Spark 开发:Scala 是必学语言,Spark API 在 Scala 中最为自然。
如果你需要高并发系统:Akka、Cats Effect、ZIO 提供了业界领先的并发抽象。
如果你是 Java 开发者:Scala 3 的简化语法降低了入门门槛,可以渐进式采用。
如果你追求代码质量:Scala 的类型系统能在编译期捕获大量错误,适合对可靠性要求高的系统。
// Scala 3 简化的入门代码
@main def run(): Unit =
println("Welcome to Scala!")
val numbers = List(1, 2, 3, 4, 5)
val doubled = numbers.map(_ * 2)
println(s"原始: $numbers")
println(s"加倍: $doubled")
结语
Scala 二十年的演进史,是一部追求"表达力与实用性平衡"的历史。从 EPFL 的实验室到 Twitter 的生产环境,从学术原型到工业标准,Scala 证明了函数式编程与面向对象并非水火不容——它们可以优雅地共存,互相增强。
Scala 3 的发布标志着这门语言进入了新的成熟阶段。虽然它面临着 Kotlin 等新兴语言的竞争,但凭借其在大数据领域的深厚积累、强大的类型系统,以及活跃的函数式编程社区,Scala 仍将在特定领域保持不可替代的地位。
对于追求代码质量、需要处理大规模数据、或希望同时掌握 OOP 和 FP 范式的开发者来说,Scala 依然是一门值得深入学习的语言。正如 Martin Odersky 所言:“Scala 是一门成长型语言——它会随着你的需求而成长。”
参考资料
- Odersky, M., Spoon, L., & Venners, B. (2016). Programming in Scala (3rd ed.). Artima Inc.
- Bjarnason, R. (2015). Functional Programming in Scala. Manning Publications.
- Scala 官方文档
- Scala 3 Book
- Dotty 文档
- Scala Center
扩展阅读
相关文章:
推荐学习路径:Scala 基础 → 函数式编程 → Akka Actor → Spark 大数据 → Cats Effect/ZIO