情境:想象你正在和一个聪明的助手合作一个持续数月的项目。每次开启新会话,你都需要重新交代背景:“我们用 Python 开发”、“上次讨论的那套错误处理方案”、“别忘了我的代码风格偏好”。
这就是当前大多数 AI 助手的真实处境——它们拥有海量知识,却缺乏对你个人的长期记忆。
第一章:NanoClaw 原有的记忆机制——文件即记忆
要理解我们为什么要重构记忆系统,必须先看清现状。
NanoClaw 是一款基于容器隔离的 AI 助手框架,它的核心设计哲学是极简与安全:每个工作群组拥有独立的文件系统沙盒,Agent 在完全隔离的容器中运行,通过挂载机制访问受限的资源。
在这种架构下,记忆被实现为一种文件中心式的朴素方案:
1.1 CLAUDE.md:人工维护的静态记忆
每个群组目录下都有一个 CLAUDE.md 文件,这是 NanoClaw 最初唯一的持久化记忆载体。

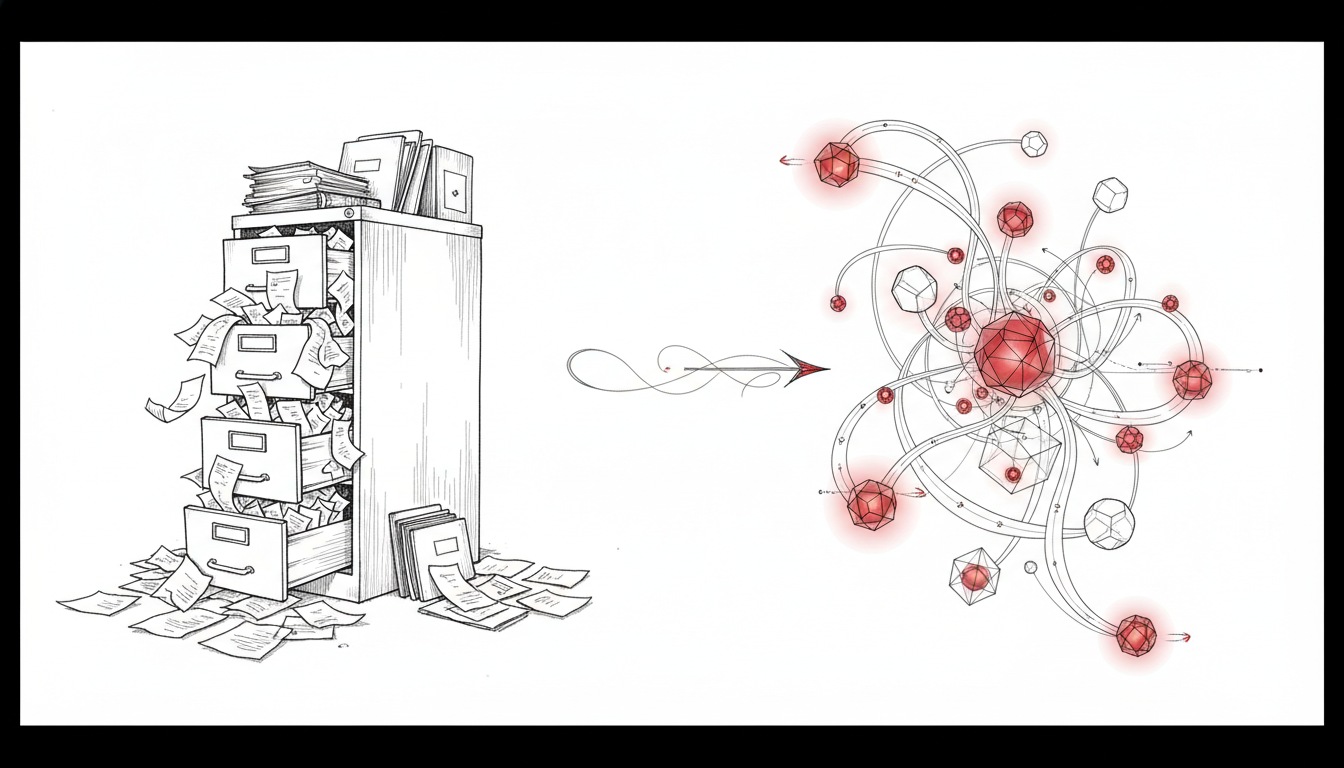
图1:V1 架构下,记忆完全依赖人工编辑的 Markdown 文件。用户需要手动整理项目背景、编码规范、历史决策,Agent 被动读取。
它的工作方式极其直白:系统启动容器时,将 CLAUDE.md 的内容完整注入系统提示词。这意味着:
- 人工维护负担重:用户必须主动整理和更新文件内容
- 无法自动沉淀:对话中产生的新知识、新偏好不会自动被记录
- 全量加载浪费:无论当前任务是否需要,整个文件都会被塞进上下文
1.2 SQLite 消息库:仅存的对话痕迹
NanoClaw 确实记录了所有对话消息,存储在本地 SQLite 数据库中。但查看 src/db.ts 的实现会发现:
// 消息仅被原样存储,无任何结构化提取
export function storeMessage(msg: NewMessage): void {
const sql = `
INSERT INTO messages (chat_jid, sender_jid, content, timestamp, is_from_me)
VALUES (?, ?, ?, ?, ?)
`;
db.prepare(sql).run(
msg.chatJid,
msg.senderJid,
msg.content,
msg.timestamp,
msg.isFromMe ? 1 : 0
);
}
这些消息只是流水账式的存档,没有被转化为可检索、可关联的结构化记忆。当 Agent 需要回顾历史时,它面临的是成千上万条未经整理的原始对话,而不是精炼的知识条目。
1.3 触发机制的缺失
更关键的是,原有的 NanoClaw 完全没有自动化的记忆提取流程。
查看 src/ipc.ts 的消息处理逻辑:
// 消息进来,只是存库,然后直接送给 Agent 处理
const channelOpts = {
onMessage: (_chatJid: string, msg: NewMessage) => storeMessage(msg),
// ... 其他回调
};
没有后台任务分析对话内容,没有提取用户偏好,没有归纳技术决策。所有可能值得记住的信息,都随着对话结束而被埋没在消息库的深处。
第二章:四大痛点——为什么要重构?
基于源码分析和实际运行观察,原有记忆机制存在四个结构性缺陷:
2.1 记忆不会自动生长
痛点:AI 助手在对话中学到了你的偏好,但下次见面时它全忘了。
这是最根本的问题。原有架构依赖用户手动编辑 CLAUDE.md 来更新记忆。但人是不擅长这种维护工作的——你会记得每次对话后去更新一份配置文件吗?
结果是:AI 永远停留在你上次手动编辑文件时的认知状态,而不是随着每一次交互持续进化。
2.2 检索效率低下
痛点:当群组运行数月后,历史消息堆积如山,Agent 却只能在最近的几轮对话中打转。
SQLite 中的消息记录是纯文本的线性存储。当 Agent 需要参考过去的信息时,它面临两个选择:
- 加载最近 N 条消息:可能遗漏关键背景
- 关键词搜索:缺乏语义理解,无法处理"那次关于数据库优化的讨论"这类模糊查询
没有向量索引,没有语义相似度,没有分层摘要。Agent 就像在图书馆里只能看到最近归还的几本书,而更早的藏书虽然存在,却无法被有效发现。
2.3 上下文膨胀与成本失控
痛点:
CLAUDE.md越写越长,每次对话的 API 成本线性增长,但有效信息密度却越来越低。
这是文件中心式记忆的根本矛盾:
| 时间 | CLAUDE.md 大小 | 每次加载 Token 数 | 有效信息占比 |
|---|---|---|---|
| 第 1 周 | 500 字 | ~800 | 90% |
| 第 1 月 | 3000 字 | ~4500 | 60% |
| 第 3 月 | 10000 字 | ~15000 | 30% |
文件只会单向增长,因为没有遗忘机制来清理过时的信息,也没有分层存储来区分核心原则与临时细节。
2.4 知识孤岛效应
痛点:群组 A 中总结的宝贵经验,无法被群组 B 利用。
NanoClaw 的安全隔离设计本意是保护隐私,但也造成了意外的副作用。当多个群组处理同一项目的不同方面时(如前端组、后端组、DevOps 组),每个群组的 CLAUDE.md 都是独立的。
结果是:
- 通用的代码规范需要在每个群组重复声明
- 跨领域的问题解决思路无法共享
- 群体智慧的涌现被物理隔离阻断
第三章:解决方案——向量记忆与分层提取
针对上述痛点,我们设计了新一代记忆系统。核心思路是将被动文件存储转变为主动向量提取。
说明:以下描述的架构和代码实现基于 NanoClaw 源码仓库(
~/git/Agents/NanoClaw/src/memory/)的实际代码,这些功能已经实现并可以运行。
3.1 架构概览:从文件到向量
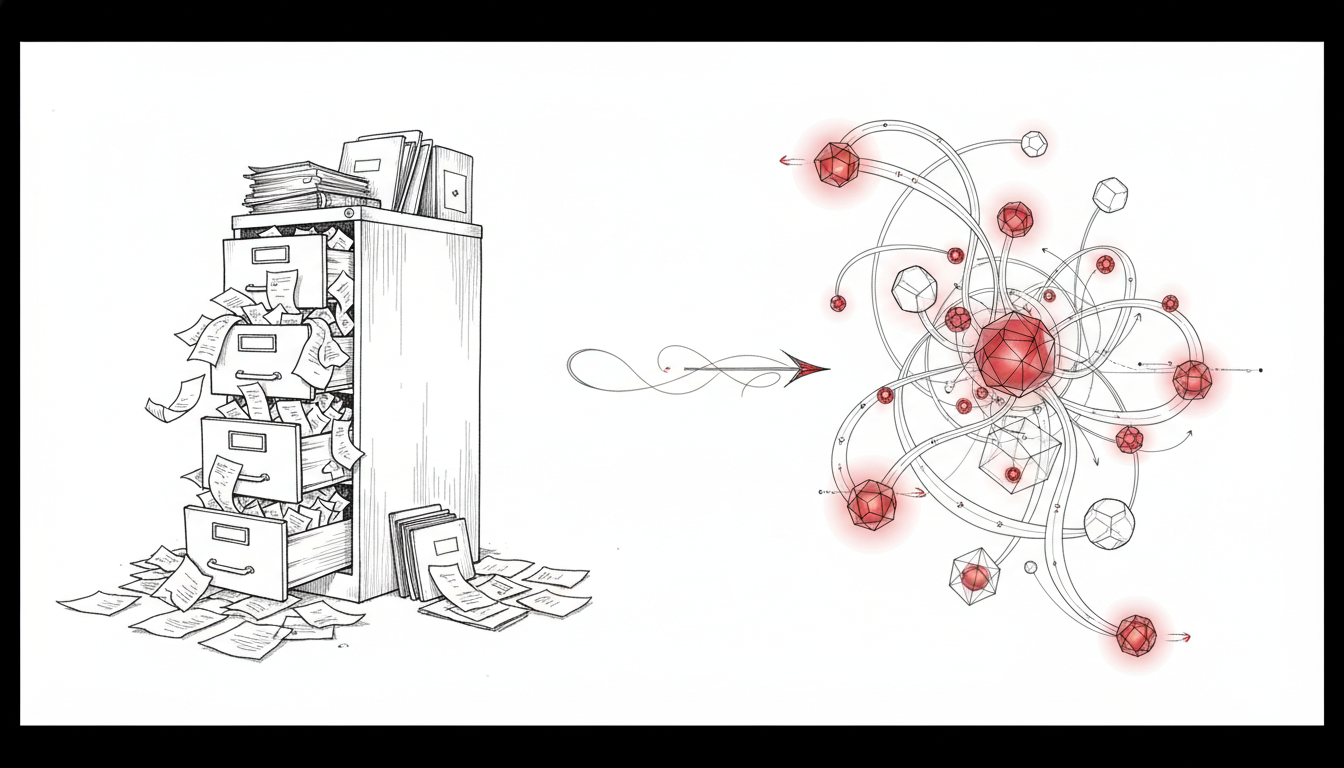
图2:架构演进对比。V1 依赖人工维护的 Markdown 文件;V2 引入自动化的记忆提取管线,将对话转化为结构化的向量记忆。
新架构引入以下关键组件:
- 记忆提取器(Memory Extractor):使用 Embedding 模型将对话转化为向量表示
- 分层存储(Tiered Storage):L0 极简摘要用于快速检索,L2 完整叙事供深度参考
- 去重与合并(Deduplication):自动检测相似记忆,合并更新而非简单追加
- 定时触发机制(Periodic Trigger):定期自动提取,无需人工干预
3.2 记忆提取:对话到向量的转化
关键在于理解什么值得记住。并非每句话都需要存储,我们需要识别出具有长期价值的事实型信息:
- 用户偏好(“我喜欢用 Python 而非 JavaScript”)
- 技术决策(“我们选择了 PostgreSQL 作为主数据库”)
- 问题解决记录(“上次通过添加索引解决了性能问题”)
- 项目背景(“这是面向 B 端的企业 SaaS 产品”)
实现上,我们在 src/memory/extractor.ts 中定义了提取管线:
// 记忆类型定义
export type MemoryType = 'fact' | 'preference' | 'skill' | 'goal' | 'context';
// 提取结果接口
export interface ExtractionResult {
memories: Array<{
type: MemoryType;
content: string;
confidence: number;
}>;
predictedIntents: PredictedIntent[];
summary: string;
}
// 记忆提取器使用 LLM 识别对话中的有价值信息
export class MemoryExtractor {
async extractFromConversation(
messages: Array<{ role: string; content: string }>,
groupFolder: string
): Promise<ExtractionResult> {
// 1. 格式化对话历史
// 2. 调用 LLM 识别有价值的信息
// 3. 返回结构化记忆列表
}
}
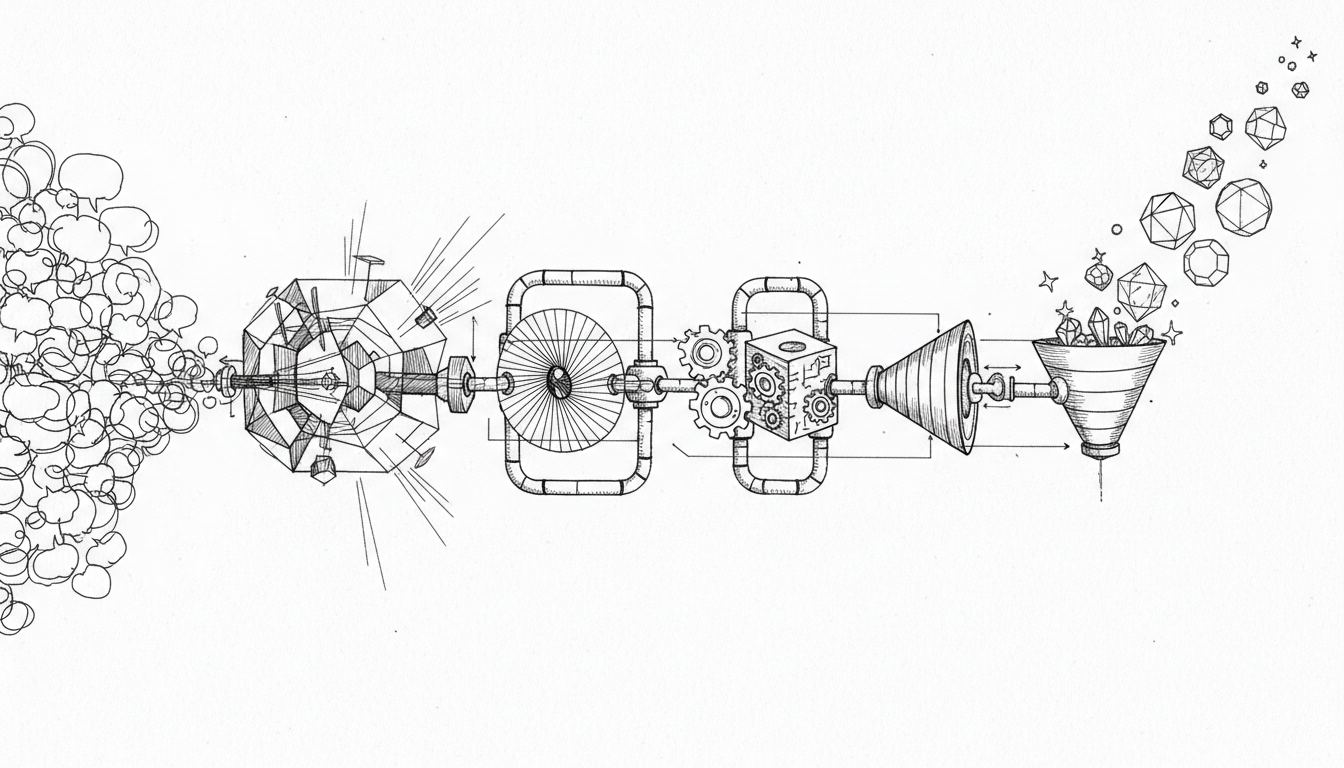
图3:记忆提取管线将原始对话转化为结构化知识。左侧的原始对话经过多层过滤和提炼,最终形成右侧的晶体化知识结构。
3.3 去重与合并:避免记忆膨胀
提取出新记忆后,更大的挑战是如何处理重复。如果用户三次提到"我喜欢 Python",我们应该有三条记录,还是一条不断更新置信度的记录?
答案是后者。我们实现了基于向量相似度的去重机制:
export interface DeduplicationResult {
decision: 'CREATE' | 'MERGE' | 'SKIP';
existingMemoryId?: string;
similarityScore: number;
}
// 流程:
// 1. 计算新记忆的 Embedding
// 2. 在现有记忆中搜索相似向量(余弦相似度 > 0.85)
// 3. 如果找到相似记忆,使用 LLM 判断是否合并
// 4. 如果是补充信息则 MERGE,如果是完全重复则 SKIP
这解决了 V1 架构中文件单向膨胀的问题。记忆库会收敛到一组精炼、无冗余的核心知识,而不是无限增长。
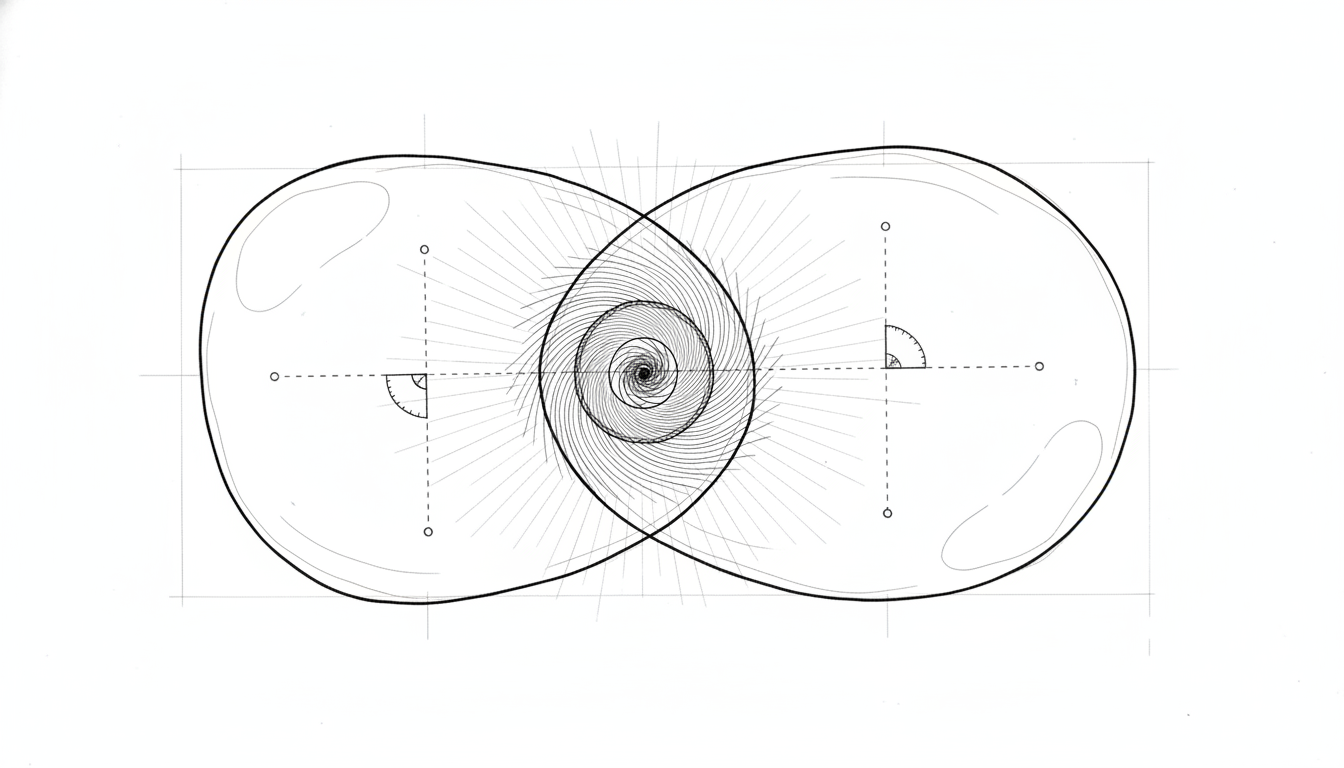
图4:去重与合并机制。相似的记忆会自动融合为一个统一的知识条目,而不是重复堆积。重叠区域代表合成后的新知识。
3.4 定时触发:让记忆自动生长
V1 架构的最大缺陷是缺乏触发机制。我们在 src/index.ts 中新增了定时提取逻辑:
// 配置:每 10 分钟检查一次是否需要提取
const MEMORY_TRIGGER_INTERVAL_MINUTES = 10;
setInterval(async () => {
const groups = getAllRegisteredGroups();
for (const [jid, group] of Object.entries(groups)) {
const sinceTimestamp = getLatestGroupTimestamp(group.folder);
await triggerMemoryExtraction(group.folder, sinceTimestamp);
}
}, MEMORY_TRIGGER_INTERVAL_MINUTES * 60 * 1000);
同时,我们保留了基于事件的触发(当 Agent 容器完成任务后触发 _close 信号),形成双轨触发策略:
- 定时触发:捕获普通聊天中的有价值信息
- 事件触发:在 Agent 完成复杂任务后立即提取经验
3.5 分层存储:L0/L1/L2 的实用主义
受 epro-memory 启发,我们实现了分层记忆结构:
| 层级 | 内容 | 用途 | 存储方式 |
|---|---|---|---|
| L0 | 10-20 词的极简摘要 | 向量检索、快速匹配 | 存储为记录的 L0 字段 |
| L1 | 结构化概要 | 注入系统提示 | 存储为记录的 L1 字段 |
| L2 | 完整叙事与上下文 | 深度参考、溯源 | 存储为记录的 L2 字段 |
这种设计平衡了检索效率与信息完整性:
- 日常对话只需要匹配 L0 层的向量相似度
- 当需要详细信息时,通过 L0 中的指针定位到 L2 的完整记录
- L1 层作为中间态,定期生成可读的项目概览

图5:L0/L1/L2 三级存储抽象。顶层是极简摘要用于快速检索,底层是完整叙事供深度参考,中间层是结构化概要。
第四章:工程实现中的关键决策
4.1 为什么选择 Embedding + 向量检索?
Embedding 技术的核心价值在于语义理解。
传统关键词搜索无法理解"我喜欢 Python"和"我偏好 Python 而非 JavaScript"是同一意图。而 Embedding 将文本映射到高维向量空间,语义相近的句子在这个空间中距离很近。
这使得 Agent 能够:
- 理解同义表达(“我喜欢” ≈ “我偏好”)
- 处理模糊查询(“上次说的那个优化方案”)
- 发现隐性关联(“数据库性能问题"与"索引优化”)
4.2 本地 SQLite 还是专用向量数据库?
我们选择了扩展 SQLite 而非引入专用向量数据库(如 Pinecone、Milvus)。
理由:
- 最小化依赖:NanoClaw 的哲学是轻量级、少外部依赖
- 数据主权:所有数据保留在本地,可选择使用本地embedding模型
- 架构一致性:复用现有的 SQLite 基础设施
实现上:
- 向量生成:支持云端API(智谱AI)或本地模型(
@xenova/transformers+ ONNX Runtime) - 向量运算:余弦相似度等计算使用纯JavaScript实现
- 对于个人/小团队的规模完全足够
4.3 隐私边界:什么可以跨群组共享?
解决"知识孤岛"问题的同时,必须坚守隐私底线。我们定义了严格的记忆分级策略:
局部记忆(Local):
- 具体代码实现细节
- 私密凭证与配置
- 用户个人隐私信息
- 禁止跨群组共享
全局记忆(Global):
- 通用编程范式与最佳实践
- 去标识化的问题解决模式
- 技术栈偏好(不涉及具体业务)
- 经脱敏后可共享
通过 is_global 标记和人工审核机制,确保只有真正通用的知识才能进入全局记忆池。
第五章:从规划到落地——实施路线图
当前实现包含核心的记忆提取、去重和分层存储功能。完整的记忆系统演进分为四个阶段:
阶段一:基础提取与存储(✅ 已完成)
当前已实现的功能:
- ✅ 记忆提取器(
MemoryExtractor):使用 LLM 识别对话中的有价值信息 - ✅ Embedding 向量生成:调用智谱AI embedding API
- ✅ 去重与合并逻辑(
MemoryDeduplicator):基于向量相似度(>0.85)和关键词匹配 - ✅ 定时触发机制:每 10 分钟自动检查并提取记忆
- ✅ 分层存储(
HierarchicalMemoryManager):L0/L1/L2 三级压缩 - ✅ SQLite 存储:向量索引和元数据存储
阶段二:检索增强与上下文注入(🔄 进行中)
正在开发的功能:
- 🔄 基于相似度的记忆检索
- 🔄 智能上下文装配(只加载相关记忆到提示词)
- 🔄 记忆热度排序(优先展示高频引用的知识)
阶段三:仿生遗忘与记忆巩固(⏳ 设计中)
计划中的功能:
- ⏳ 访问频率追踪(
accessCount和lastAccessed字段已定义) - ⏳ 时间衰减算法(陈旧记忆自动降级)
- ⏳ 记忆投影:定期生成可读的 Markdown 摘要
阶段四:群体认知与自举进化(⏳ 远期愿景)
概念验证阶段:
- ⏳ 跨群组知识广播(经审核的通用模式共享)
- ⏳ 高阶模式自举:从经验自动提炼技能草稿
- ⏳ 离线回放评测:基于 LoCoMo 等基准测试记忆效果
结语:记忆是认知的基础设施
从 CLAUDE.md 的手动维护,到自动化的向量提取;从单向膨胀的文件,到收敛精炼的记忆库;从孤立群组的各自为战,到可控共享的群体认知——NanoClaw 的记忆系统演进,本质上是在解决一个核心问题:
如何让 AI 助手真正"记住"与你的每一次交互,并在未来的交互中持续受益?
技术细节终将过时,但工程背后的认知洞察具有长期价值:
- 自动优于手动:记忆系统必须主动提取,不能依赖用户维护
- 语义优于语法:向量检索比关键词匹配更接近人类记忆的联想方式
- 分层优于扁平:不同场景需要不同粒度的记忆,没有一劳永逸的表示
- 遗忘优于堆砌:记忆的精髓在于筛选,记住一切等于什么都没记住
今天的实现还远非完美,但方向已经清晰。当时间成为朋友而非敌人,当每次对话都建立在之前所有对话的积累之上,AI 助手才能真正成为那个"越来越懂你"的数字伙伴。
延伸阅读: