
几个先撂在这儿的结论

AI 越强,知识浪费越严重。
以前一天产出几千字文档,现在和 AI 对话轻松上万字。但这些"对话态"的知识,绝大多数产生之后就蒸发了——窗口一关,就不再看了。
记住一切等于什么都没记住。筛选和遗忘,才是记忆的精髓。
这是我搭建知识系统过程中悟到的。不是要把所有东西都存下来,而是让系统知道什么该记住、什么该放手。
我已经好多年没用过纸质笔记本了。
虽然到现在还会忍不住买精美的本子和笔,买完往书架上一放,供着。但真要记东西,我不会去翻那些本子。写在纸上的内容,写完那一刻就开始沉睡了。
BTW,这篇文章基于我自己搭建的一套记忆系统实践,有代码、有踩坑经验,不是纯理论空谈。
你的知识,散落在哪里?

你的知识现在大概分布在这些地方:
- Obsidian/Notion/飞书/语雀 里的笔记(如果你有坚持写的话)
- 散落各处的项目文件夹(可能叫
project_v2_final_真的最终版) - 和 AI 的聊天记录(窗口一关,灰飞烟灭)
- 纸质笔记本里面
- 大脑里(众所周知,这个存储介质的可靠性不太行)
这些知识之间基本是孤岛状态。上周和 Claude 讨论的细节,这周换个 session 就得从头解释。去年踩过的坑写的复盘,今年遇到类似场景,完全想不起来那份文档存在哪里。
这就是我们要解决的问题:Agent 时代,个人知识管理到底该怎么搞?
第一章:为什么现在必须重视知识管理
知识管理不是新鲜话题。
那为什么到了 2025、2026 这个节点,这事又变得有意思起来了?
因为 AI Agent 既是知识的消费大户,也是生产大户。
以前你写一份技术方案,可能就自己看看、存个档。现在不一样了——你和 Agent 之间一天可能产生上万字的交互。这些对话里藏着你的偏好、决策逻辑、踩过的坑,全是有价值的东西。
但 Agent 默认不会帮你留住这些。关掉窗口,一切归零。
这就是问题所在:Agent 越强,知识浪费越严重。
举个例子:我最近在探索智能知识管理,和大模型讨论了几十上百个 session。每个 session 里都有重要的技术决策:为什么选择 Pinecone 而不是 Milvus、向量维度从 768 调到 1024 的理由、混合检索的权重参数怎么设……
如果这些东西没有系统性地沉淀下来,三个月后再维护这个系统,我得重新和 AI 解释一遍所有背景。这就是巨大的隐性成本。
第二章:传统知识管理的三个死穴
在聊怎么做之前,先看看传统方案哪里不行。
2.1 文件夹模式:人能记住,机器搜不到
最原始的方式:按项目、按日期建文件夹,文档往里扔。
这个方案的最大问题是检索靠记忆。你知道三个月前写过一份PPT,但记不清放在哪个目录的哪个子文件夹里。搜文件名?关键词可能没对上。全文搜索?几万个文件扫一遍,跳出来一堆不相关的结果。
更要命的是跨项目复用几乎不可能。A 项目总结的经验教训,B 项目需要时,你压根不知道它存在。
这种方案在几十个文件的时候挺好用。一旦积累到成百上千个文件,就开始崩了。
2.2 笔记软件:写得舒服,但成了孤岛
Obsidian、Notion 这类工具体验确实好。双向链接、标签系统、全文搜索,看起来什么都有了。
问题出在使用习惯上。大多数人记笔记的模式是"想起来就记一笔",然后就再也不看了。笔记越积越多,但能被检索到的比例越来越低——因为写的时候没考虑将来怎么被找到。
没有结构化的笔记,和没有索引的图书馆差不多。书是都在,但你找不着。
另一个问题是 AI Agent 和笔记软件之间天然有一堵墙。Agent 不会主动去翻你的 Obsidian。知识停留在那里,和 AI 之间是断开的。
2.3 人工维护的配置文件:起点很好,但注定腐烂
有些 AI 框架鼓励用户维护一份"上下文文件",类似于自我介绍:告诉 AI 你是做什么的、偏好什么、项目背景是什么。
这个思路是对的。但让人手动维护这种文件,注定有问题:
| 时间跨度 | 文件状态 | 有效信息比 |
|---|---|---|
| 第 1 周 | 精心编写的简介 | 90% |
| 第 1 月 | 补了些新内容 | 60% |
| 第 3 月 | 早就忘了更新 | 30% |
| 第 6 月 | 又长又旧,懒得看 | 10% |
文件只会越来越长、越来越陈旧。人是不擅长做持续维护的。你会每次对话后去更新一份配置文件吗?大概率不会。
这三个问题的共同点是:都依赖人的主动维护。这在知识量小的时候还能应付,一旦你是个每天和多个 AI Agent 高频交互的重度用户,纯手动方案就崩了。
第三章:新范式——让机器帮你记
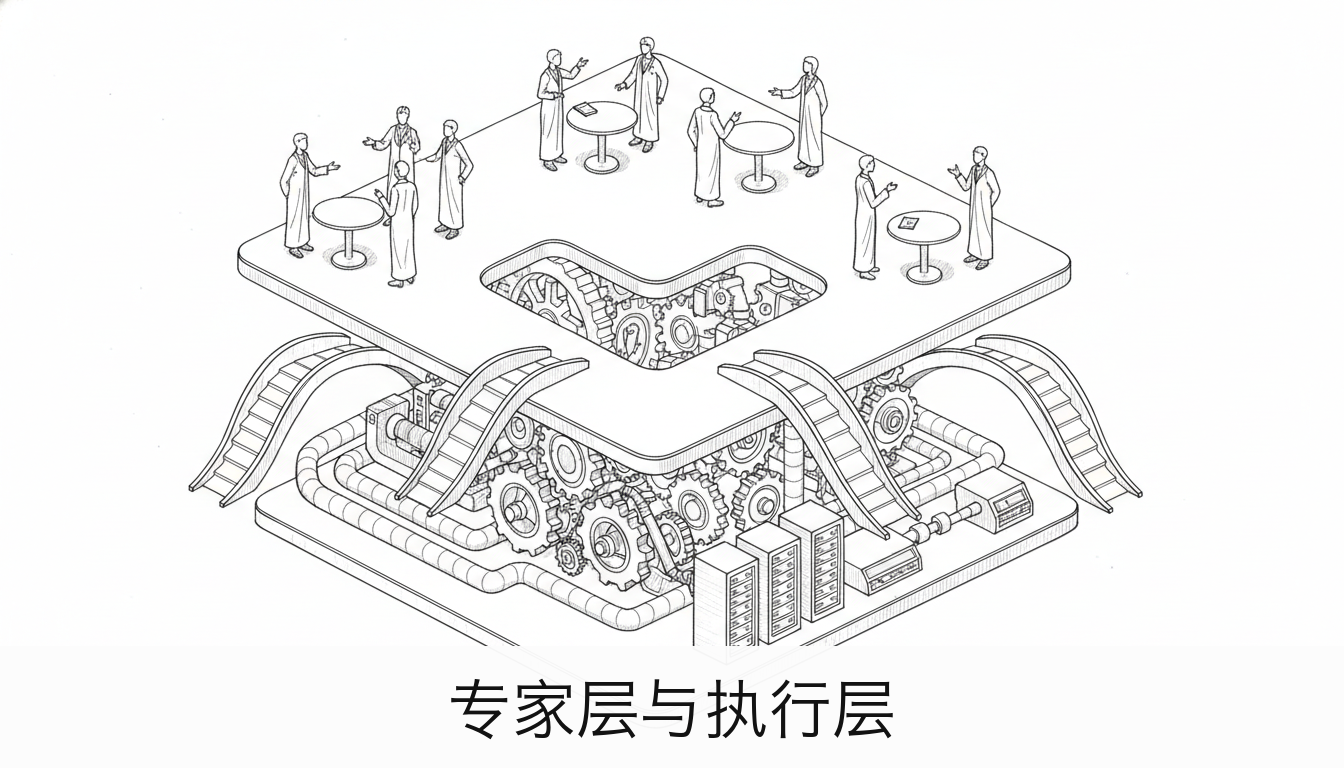
传统方案的共同缺陷是一个字:手动。
靠人去整理、靠人去归类、靠人去维护。这在知识量小的时候还能应付,一旦你是个每天和多个 AI Agent 高频交互的重度用户,纯手动方案就崩了。
新范式的核心思路是把"记忆"这件事也交给系统来做。
3.1 “专家层 + 执行层"的架构
经过几轮迭代,我心中的智能知识管理系统是这个样子的:
专家层(Expert Layer):定义"知道什么"和"怎么想”。
- 包含你的专业方法论、分析框架、判断规则
- 比如:你做合规分析,优先考虑什么法规?风险评估走哪几步?遇到冲突怎么裁决?
- 这些是你多年积累的专业经验,不会频繁变化
执行层(Engine Layer):负责"怎么存"和"怎么找"。
- 数据的摄入和索引、混合检索、证据提取、报告生成
- 每条结论都关联到具体的来源路径和置信度评分
- 置信度低于阈值的结论不允许直接输出,必须进入人工审核队列
这种分层的好处是,当你需要更新方法论的时候,改"专家层"就行,不用碰"执行层"。执行层负责脏活累活——切分文档、生成向量、做相似度匹配。两层各管各的,互不干扰。
举个实际的例子。专家层可能长这样(JSON 配置):
{
"expertise": {
"risk_assessment": {
"priority_rules": ["ISO 26262", "ISO 21448", "EU AI Act"],
"evaluation_steps": ["hazard_identification", "risk_analysis", "mitigation_strategy"]
},
"output_preferences": {
"language": "zh-CN",
"detail_level": "technical",
"evidence_required": true
}
}
}
而执行层关心的是:用什么 embedding 模型、向量维度多少、检索算法用什么、缓存策略怎么设。两边完全解耦。
3.2 向量检索:从"关键词匹配"到"语义搜索"
传统搜索靠关键词匹配。问题很明显:“我喜欢 Python"和"我偏好 Python 而非 JavaScript"在关键词搜索眼里是两回事,但语义上几乎一样。
向量检索解决的就是这个问题。
Embedding(向量嵌入):把一段文字转换成高维空间中的向量(一串数字)。语义接近的文字在向量空间中距离就近。就像地图上,“北京"和"天津"挨得近,“北京"和"纽约"离得远。
数学上,这相当于找到一个映射函数 $f: \text{text} \rightarrow \mathbb{R}^d$,使得:
$$\text{similarity}(f(t_1), f(t_2)) \approx \text{semantic similarity}(t_1, t_2)$$
把你的知识文档全部 embedding 之后,搜索就变成了在向量空间里找"邻居”。你问"上次关于性能优化的讨论”,它能找到那篇标题叫"数据库查询加速方案"的笔记——因为语义上它们是一回事。
我在实践中发现,纯向量检索也有短板。BM25 等传统关键词检索在精确匹配方面仍然很有竞争力,比如搜标准号"ISO 8800”,拼写一分不差的关键词匹配反而更准。
所以最终方案是混合检索(Hybrid Search):
def hybrid_search(query, documents, alpha=0.7):
"""
alpha: 向量检索权重,(1-alpha): 关键词检索权重
"""
# 1. 关键词检索(BM25)
keyword_scores = bm25_search(query, documents)
# 2. 向量检索
query_embedding = embed(query)
doc_embeddings = [embed(d) for d in documents]
vector_scores = cosine_similarity(query_embedding, doc_embeddings)
# 3. 融合排序
final_scores = alpha * normalize(vector_scores) + (1-alpha) * normalize(keyword_scores)
return rank_documents(final_scores)
两条腿走路,各取所长。
3.3 分层存储:不是所有记忆都需要同等对待
你回忆一件事的时候,大脑不是翻出完整的录像带重播。它先想到一个模糊印象,然后逐步回忆更多细节。
知识系统可以学这个思路。我把存储分成三层:
| 层级 | 内容 | 用途 | 大小 |
|---|---|---|---|
| L0(摘要层) | 10-20 词的极简概括 | 快速匹配 | ~50 tokens |
| L1(结构层) | 带分类和标签的结构化概要 | 注入 Agent 上下文 | ~200 tokens |
| L2(完整层) | 原始完整记录 | 深度参考 | 无限制 |
日常使用只需要在 L0 层做向量匹配。匹配到了,按需加载 L1 或 L2 的详细内容。这样既不会因为全量加载撑爆上下文窗口,也不会丢失细节。
实际实现中,L0 层可以用类似这样的结构:
{
"memory_id": "mem_20250309_001",
"l0_summary": "用户偏好 Python,讨厌 Java,重视代码可读性",
"embedding": [0.023, -0.156, 0.891, ...],
"timestamp": "2026-03-09T14:30:00Z",
"source": "CLAUDE.md analysis session"
}
3.4 知识的自动沉淀:对话完成不等于知识归档
这是很多人忽略的一步。和 AI 对完话就关窗口,然后那些讨论内容就散落在聊天记录里,再也找不到了。
好的知识系统应该在对话结束后,自动做几件事:
- 提取有价值的信息:识别对话中的偏好表达(“我更倾向于方案 A”)、事实性记录(“我们决定用 PostgreSQL”)和经验教训(“上次缓存策略失效是因为 TTL 设太短了”)
- 去重合并:如果之前已经记录过类似的信息,就更新已有条目而不是新增一条重复的
- 打标分类:自动归类到相应的知识域(技术、管理、偏好等)
我现在的 workflow 是每次 session 结束后,运行一个提取脚本:
# 自动提取对话中的知识片段
python scripts/extract_knowledge.py \
--session-id $SESSION_ID \
--output-format markdown \
--auto-merge-duplicates
这个脚本会输出一个 markdown 文件,包含提取出的知识条目。我花 30 秒快速扫一眼,确认无误就归档到知识库。
3.5 证据链:每条结论都得有出处
这一点在很多场景下是刚需。AI 告诉你一个结论,你问它"依据是什么",它说"根据行业最佳实践"——这跟没说一样。
我的做法是,系统输出的每条结论都必须携带"证据链"信息:
@dataclass
class Evidence:
source_type: str # "regulation", "internal_doc", "conversation"
source_path: str # 文件路径或对话 ID
locator: str # 具体位置(页码、段落、时间戳)
confidence: float # 0-1 之间的置信度
@dataclass
class Conclusion:
statement: str
evidence: List[Evidence]
confidence_threshold: float = 0.85
def is_verified(self) -> bool:
return all(e.confidence >= self.confidence_threshold for e in self.evidence)
如果置信度低于 0.85,结论自动进入审核队列,等人工确认后才能作为正式输出。
这个机制听起来死板,但在涉及对准确性要求很高的场景里,它就是命脉。
第四章:怎么动手——实战建议
说了半天架构,落地怎么搞?我把自己踩过的坑和验证过的经验列一列。
4.1 先电子化,再结构化
我已经好多年没用过纸质笔记本了。虽然到现在还会忍不住买漂亮的本子和笔,买完往书架上一放,心满意足地看着。但真要记东西,我不会去翻那些本子。
我很早就强迫自己把主要内容都搬到了电子端。这个转变看起来不起眼,但它是后面一切的前提。
最重要的一步:把一切都变成文字。
开会的讨论、电话里的决定、脑子里闪过的灵感——如果不变成文字记录,它们就会蒸发。
这里有个实用技巧:靠语音大量输出。
打字慢、写文档烦?直接开个语音转文字工具,边想边说。一分钟能输出两三百字,比打字快好几倍。我现在很多工作复盘、需求描述、问题记录都是"说"出来的。说完之后,让 AI 帮忙整理成结构化的笔记就行了。
成本接近于零,收益巨大。
你吃完午饭回工位的路上,掏出手机说两分钟"今天上午那个会的要点是……",到了工位就自动变成一份可检索的会议纪要了。
BTW,现在的 AI 语音输入法其实已经蛮好用的了,准确率够高,支持中英文混合识别。苹果的语音备忘录也行,就是后期整理需要多一步。
4.2 建立你的个人向量知识库
听起来很高大上,但实际操作没那么复杂。
第一步:选择存储方案。 对个人用户来说,不需要什么分布式数据库。一个 SQLite 文件加上本地 Embedding 模型就够了。推荐这个组合:
# 轻量级个人知识库方案
# embedding: sentence-transformers/all-MiniLM-L6-v2 (本地运行,无需 API)
# storage: SQLite + faiss-cpu (纯本地,隐私安全)
from sentence_transformers import SentenceTransformer
import sqlite3
import faiss
import numpy as np
# 加载模型 (只有 80MB,CPU 就能跑得飞快)
model = SentenceTransformer('all-MiniLM-L6-v2')
# 创建向量索引
dimension = 384 # MiniLM 的输出维度
index = faiss.IndexFlatIP(dimension) # 内积相似度
所有数据都在你自己的机器上,不存在隐私泄露的问题。这个方案我跑了几个月,处理了几千篇文档,毫无压力。
第二步:决定知识来源。 把你日常产出的内容接进来:
- 笔记软件导出的 Markdown 文件
- 与各种 AI 助手的对话历史
- 项目文档(PDF、Word、PPT)
- 会议纪要和工作日志
第三步:设定更新节奏。 可以定时自动扫描(比如每天跑一次),也可以触发式更新(每次完成一轮对话就自动提取)。关键是不要让这件事依赖你的自律——自动化一切能自动化的。
4.3 分领域组织知识库
与其把所有知识扔进一口大锅,不如按领域拆成多个子库。类似于图书馆的分区。
举个例子,我自己的知识体系大致分了这些区域(简单示例):
| 子库 | 内容 | 典型查询场景 |
|---|---|---|
| 技术标准 | EU AI Act 相关条文和解读 | “AI 的风险评估步骤是什么” | |
| 项目交付 | 历史项目报告、模板、复盘 | “上次类似项目的交付周期是多久” |
| 客户沟通 | 客户画像、沟通要点、反馈记录 | “XX 客户最关注什么指标” |
分区的好处是,当你做特定领域的分析时,可以精确地只搜索相关子库,避免被无关内容干扰。
而且不同知识来源的可信度和用途不同,应该区别对待:
- 法规原文和行业标准:可作为正式证据引用,置信度高
- 竞品分析和新闻:只能作为"背景参考",不能作为结论依据
- 个人工作记录:纯粹是上下文信息,辅助理解而已
这种"信息分级"的思路很容易被忽视,但在专业场景下非常关键。
4.4 给 AI Agent 装上"记忆模块"
目前主流的 AI Agent 框架(Claude、Gemini、ChatGPT 等)都开始提供"记忆"功能,但方式各不相同。
有些依赖上下文文件(比如 CLAUDE.md),有些有内置的记忆系统,有些支持外挂知识库。
选择哪种方案不太重要,重要的是确保 Agent 能接触到你积累的知识。方式可以很朴素——把你的知识库摘要定期同步到 Agent 的上下文文件里就行了。
<!-- CLAUDE.md 示例片段 -->
## 我的技术偏好
- 编程语言: Python > Perl > Shell
- 向量数据库: 目前用 Qdrant,之前试过 Milvus 但部署太复杂
- Embedding 模型: all-MiniLM-L6-v2(本地)用于个人项目
## 当前项目上下文
- 正在搭建一套智能分析系统
- 已完成: 数据接入层、向量索引层
- 进行中: RAG 检索优化、置信度评分机制
- 踩过的坑: 向量维度从 768 调到 1024 后召回率提升 15%
更高级的玩法是用 RAG(Retrieval-Augmented Generation):Agent 收到问题后,先去你的知识库里搜索相关信息,把搜到的内容拼到提示词里,再生成回答。
RAG(Retrieval-Augmented Generation,检索增强生成):让 AI 先"查书"再"答题"的技术。就像考试前翻一翻笔记本,而不是全凭脑子里记住的东西。
4.5 定期做知识清理
知识管理最容易犯的错误就是"只增不减"。
信息过了保鲜期照样堆在那里,影响检索质量。三年前某个项目的临时方案,两年前某个已废弃的技术栈的笔记——这些东西还混在你的知识库里,占着空间、干扰搜索。
解决办法和人脑的"遗忘机制"很像:
- 按访问频率打分。长期没被引用的条目自动降低优先级
- 设置过期提醒。超过一定时间未被回顾的知识条目,提示你决定保留还是归档
- 定期生成知识体检报告,看看哪些领域更新及时、哪些领域开始变得陈旧
我每个月会跑一个脚本,生成这样的报告:
知识库健康度报告 (2026-03-01)
================================
总条目数: 1,247
近 30 天活跃: 89 (7.1%)
近 90 天活跃: 234 (18.8%)
从未被检索: 412 (33.0%) ← 需要关注
建议归档的领域:
- 2024 年 Q1 的临时项目文档 (23 条)
- 已废弃的技术栈笔记 (15 条)
记住一切等于什么都没记住。筛选和遗忘,才是记忆的精髓。
第五章:哪些地方还能做得更好

坦白说,这个系统也有很多不完善的地方。写出来作为反思,也给有类似需求的人做个参考!
5.1 语音输入的利用率还是太低
前面说了语音输出是很好的知识采集手段,但我自己实际使用的频率远没有达到理想状态。很多碎片化的想法和非正式讨论(比如走路时想到的点子、和同事闲聊中冒出的灵感),还是"说完就忘"了。
改进方向:养成随时开启语音备忘录的习惯。哪怕只是 30 秒的片段,积少成多也是宝贵的素材。关键是降低启动成本——让"录一段话"这件事变得像喝口水一样自然。
5.2 跨系统打通还没做好
我有好几个知识来源:笔记软件里有一堆,项目文档散落在不同目录,邮件和聊天记录又是另一个世界。它们之间基本是孤立的。
严格来说,我已经做了一些整合工作(比如统一由一套文件管理系统接收和整理所有新文件),但还远没有达到"无缝打通"的程度。每次切换系统还是要人工衔接,摩擦成本不小。
理想状态是:所有系统的知识都流入同一个管道,统一索引、统一检索。这个还在建设中。
5.3 和 Agent 的记忆协同还处于初级阶段
虽然说了很多 RAG 和向量检索,但实际和日常 AI 助手的整合深度还不够。Agent 能搜到知识库里的内容了,但"什么时候搜、搜多少、怎么排优先级"这些策略还比较粗糙。
经常出现两种情况:
- 要么搜出来一堆不那么相关的东西,干扰了回答质量
- 要么关键信息没被检索到,Agent 还是在胡说
这个问题本质上是一个 relevance tuning 的问题,需要大量实践来调整参数。我还在摸索。
5.4 学习闭环还没跑起来
系统能记录对话、提取知识,但"从经验中学习并改进"的闭环还很弱。
理想状态是:系统记录 AI 的每次输出和用户的反馈,统计哪些建议被采纳了、哪些被否了,然后自动调整后续输出的方向。
目前我已经在系统里加了反馈采集的机制(输出后可以标记"好/不好"),从对话日志中提炼经验教训的功能也有了雏形,但还没有形成完整的自动迭代链路。
这是一个长期工程。汪汪。
第六章:实用行动清单
如果你也想开始搞知识管理,不用一步到位。按优先级来:
今天就能做的:
- 找一个语音转文字工具,试试用"说"的方式记录想法
- 把手头最重要的三个项目文档集中到一个目录里
- 开始保存有价值的 AI 对话记录(至少复制粘贴到一个文档里)
一周内能搞定的:
- 选一个笔记工具(Obsidian、Notion、飞书 等),建立基本的分类体系
- 按领域整理现有的知识材料,能打标签的打标签
- 给你常用的 AI 助手写一份上下文文件(CLAUDE.md 或类似的东西)
一个月内可以尝试的:
- 搭建一个简易的本地向量知识库(用 sentence-transformers + SQLite 就行)
- 把笔记和文档接入知识库,试试语义搜索的效果
- 设计一套定期更新和清理的机制,哪怕只是每周花半小时手动过一遍
长期目标:
- 实现知识采集、索引、检索、复用的半自动化流程
- 打通多个系统之间的数据流,减少人工搬运
- 建立学习闭环,让系统越用越准
不用追求完美,先跑起来再说。很好用,汪汪。
结语:别让知识蒸发

我们可能正处在知识管理发生质变的窗口期。
过去三十年,知识管理一直是一件"知道很重要但怎么都落不了地"的事。现在 AI Agent 的爆发,同时带来了挑战和机会:一方面,知识的产生速度空前加快;另一方面,管理和利用知识的工具也从未如此强大。
回到开头那个场景。当你下次和 AI 助手聊完一个方案,关掉窗口之前,想一想:这段对话里有什么值得留下来的东西?
也许以后的系统会帮你自动做这一步。但在那一天到来之前,多花五分钟整理一下,就是最好的投资。
那些散落在聊天记录里的灵感、那些口头讨论中蹦出来的好主意、那些"想起来再说吧"然后就忘了的经验——它们都值得被好好保存。
知识不应该只在你脑子里存一份,手动靠自己记。它应该变成可搜索、可复用、越积越值钱的资产。
你可以从今天开始。
Play with data and have fun!
参考与延伸阅读
- Anthropic. (2024). Model Context Protocol (MCP) Specification. modelcontextprotocol.io
- OpenAI. (2024). Text Embedding Models. platform.openai.com/docs/guides/embeddings
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019.
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- Robertson, S., & Zaragoza, H. (2009). The Probabilistic Relevance Framework: BM25 and Beyond. Foundations and Trends in Information Retrieval.
- Ebbinghaus, H. (1885). Über das Gedächtnis(论记忆). 经典记忆研究。