
什么是 AI 味,怎么去 AI 味
AI 写作痕迹识别与去除完全指南
可能很多人对 AI 写的文章有意见。读几句就能感觉不对劲,但又说不上具体哪里有问题。
这种味道不是凭空而来的。它背后有一套严格的数学机制在运作,而理解这套机制,是去除 AI 味的起点。
AI 味(AI Writing Tropes):大型语言模型(LLM)在生成文本时表现出的可识别模式。这些模式源于模型的统计预测本质,表现为过度使用某些词汇、句式和结构,使文本读起来机械化、模板化。
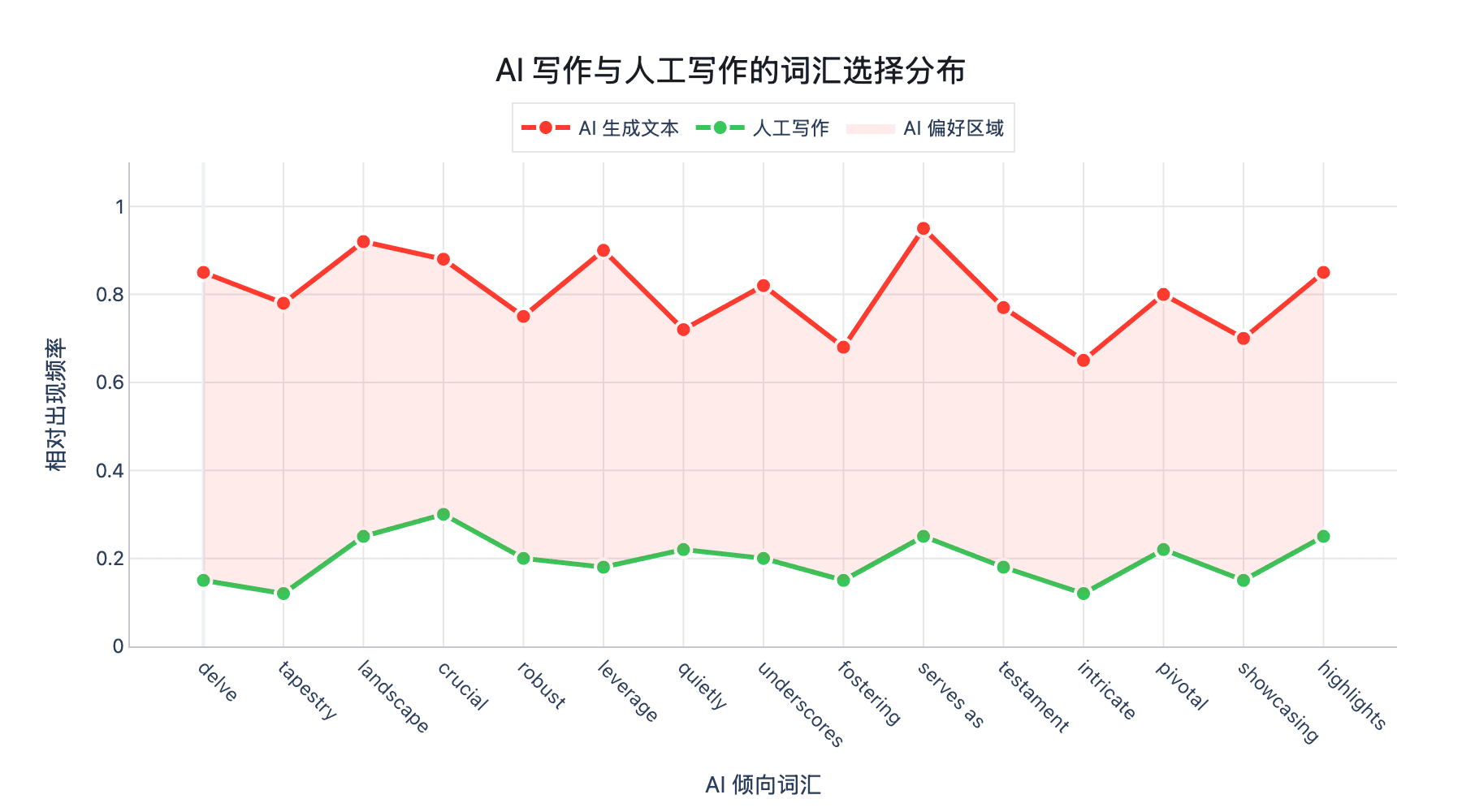
图 1:AI 生成文本的词汇选择分布与人工写作的差异。横轴为词汇的"AI 倾向指数",纵轴为出现频率。可以看到 AI 文本在某些特定词汇上出现明显的峰值。
第一章:AI 味的本质
要理解 AI 味,我们需要暂时离开文字本身,去看看那些生成文字的模型是如何工作的。
想象你在玩一个猜词游戏。朋友给你看一句话的前半部分,让你猜下一个词是什么。比如:“我今天早上吃了一碗______"。你可能会猜"面条”、“粥”、“麦片”。这三个答案都不错,但直觉告诉你,“面条"和"粥"比"麦片"更符合中文语境。
大型语言模型(LLM, Large Language Model):基于 Transformer 架构的神经网络,通过预测序列中下一个词的概率分布来生成文本。可以把它想象成一个超级猜词游戏玩家,它见过数以亿计的句子,对每个词出现在特定位置的可能性都有精细的估计。
LLM 本质上就是这样一个猜词机器。它接收一段文字,计算每个可能的后续词的概率,然后选择其中一个作为输出。这个过程循环往复,直到生成完整的段落。
这里有一个关键问题:当模型面对多个"都不错"的选择时,它会怎么决定?
答案藏在它的训练目标里。LLM 被训练来最大化训练数据的似然概率,也就是说,它倾向于选择"在训练数据中最常见"的表达。这就好比一个人在陌生的城市里,总是本能地走向人最多的那条街。
但这里有个微妙的扭曲。模型还有一个"重复惩罚"机制。如果它刚刚用过某个词,这个词在下一步的概率会被刻意压低。这就像是一个试图展现词汇量的考生,刻意避免连续使用同一个词。结果呢?模型开始寻找同义词、近义词,甚至是更"花哨"的替代方案。
重复惩罚(Repetition Penalty):LLM 生成过程中施加的一种约束,用于降低近期已出现词汇的采样概率。原本是为了避免单调重复,却导致模型过度追求词汇变化,产生不自然的同义词替换。
再加上 RLHF(基于人类反馈的强化学习)训练,模型被进一步引导去生成"看起来不错"的文本。它学会了人类的某些偏好,比如喜欢有结构的开头、平衡的正反面论述、以及乐观向上的结尾。这些偏好本身没有错,但当它们被机械地执行时,就产生了那种 unmistakable 的 AI 感。
RLHF(Reinforcement Learning from Human Feedback):一种训练技术,通过人类评分者的偏好反馈来微调模型。可以想象成让模型参加一场持续的考试,每次生成后都由人类老师打分,模型逐渐学会什么样的答案能得高分。
所以,AI 味的本质是什么?它是统计学最可能结果的堆砌,是避免重复的强迫症的产物,是 RLHF 训练留下的指纹。当你读到"此外”、“值得注意的是”、“深入探讨"这些词时,你听到的其实是模型在低声说:“根据我的计算,这是最安全的下一个词。”
第二章:AI 味的六大类别
现在让我们进入实战环节。社区已经识别出几十个典型的 AI 写作模式。我将其归纳为六大类别,每一类都有其独特的"症状"和"治疗方案”。
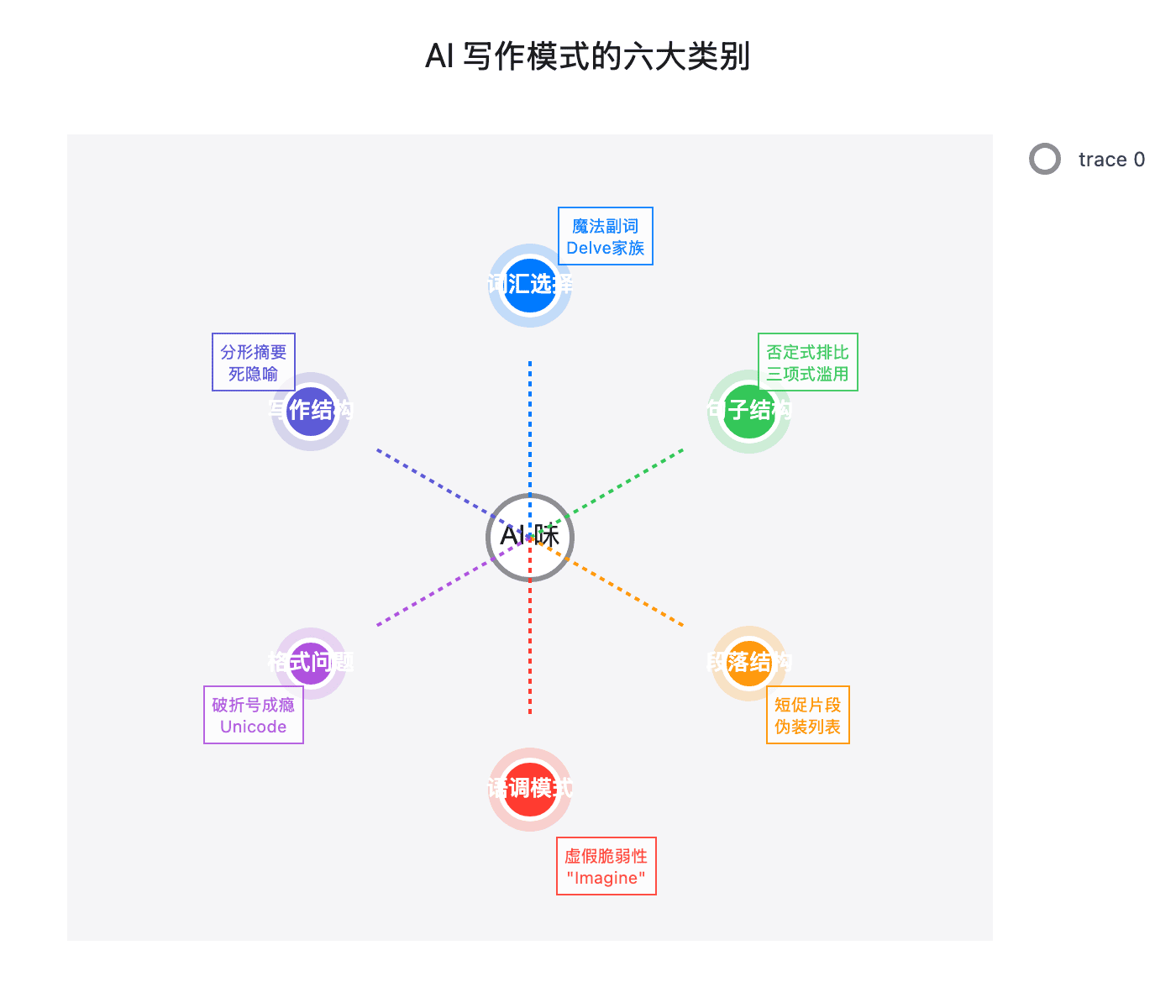
图 2:AI 写作模式的六大类别及其相互关系。这些模式相互交织,形成复杂的"AI 味"网络。
2.1 词汇选择:那些"过于正确"的词
AI 有一种奇特的能力,总能选出"最符合场合"的词汇。但问题恰恰在这里。人类写作会犯错,会有偏好的词,会有突然的词不达意。AI 不会。它的词汇选择像是一个永远穿着正装的人,在任何场合都无可挑剔,也因此显得格格不入。
魔法副词家族
“Quietly”(悄悄地)是一个典型的例子。在 AI 生成的文本中,这个词的出现频率远高于普通英语写作。
改写前:这个系统正在 quietly 编排工作流程,在后台 quietly 运行。 改写后:这个系统在后台管理工作流程。
“Quietly”、“deeply”、“fundamentally”、“remarkably”、“arguably”——这些副词被 AI 用来给平凡的描述增加重要感。它们就像调味料,偶尔使用能提鲜,但 AI 似乎每道菜都要撒一把。
Delve 家族
如果说有一个词能瞬间暴露 AI 身份,那可能就是"delve"(深入探讨)。这个词在 2023 年前的英语写作中并不常见,但在 AI 生成文本中却泛滥成灾。
改写前:让我们 delve into 这个主题。Delving deeper,我们会发现…… 改写后:让我们看看这个主题。进一步分析,我们会发现……
同样的还有 leverage(利用,作为动词)、robust(强大的)、streamline(精简)、harness(驾驭)。这些词本身没有错,但它们的组合出现往往是 AI 的签名。
织锦与格局(Tapestry and Landscape)
AI 喜欢用"tapestry"(织锦)来描述任何相互关联的事物,用"landscape"(格局/图景)来描述任何领域。
改写前:人类经验的丰富 tapestry。驾驭现代 AI 的复杂 landscape。 改写后:人类经验。现代 AI 领域。
这些华丽的抽象名词就像是模型的"安全词"——当它们不确定具体该说什么时,就会诉诸这些听起来很学术的概念。
“作为"回避(The “Serves As” Dodge)
AI 有一种奇怪的抵触,不愿意直接使用简单的"is"或"are”。它更倾向于说"serves as"(作为……发挥作用)、“stands as”(代表着)、“marks”(标志着)。
改写前:这座建筑 serves as 城市遗产的见证。 改写后:这座建筑见证了城市的遗产。
这种回避源于模型的重复惩罚机制。“Is"是一个高频词,模型担心重复,于是刻意寻找替代方案。但结果往往是让简单的话变得复杂。
2.2 句子结构:那些精心设计的套路
如果说词汇是 AI 味的调料,那么句式结构就是它的骨架。AI 似乎对某种特定的句法节奏情有独钟。
否定式排比(Negative Parallelism)
这可能是 AI 写作中最具辨识度的模式。“It’s not X — it’s Y”(这不是 X,而是 Y)。这个句式在 AI 文本中的出现频率,远超人类自然写作。
改写前:这不是大胆,而是倒退。喂养不是营养,而是透析。 改写后:这种做法实际上是倒退。喂养和营养是两回事。
AI 喜欢这种句式,因为它创造了一种"重新定义"的效果,给人一种洞察感。但当这种"洞察"被批量生产时,它就失去了力量。
“不是 X。不是 Y。只是 Z。”
这是否定式排比的变体,通过连续否定来制造戏剧性的紧张感。
改写前:不是一个 bug。不是一个功能。只是一个根本性的设计缺陷。 改写后:这是一个根本性的设计缺陷。
人类偶尔也这样写,但 AI 把它变成了默认设置。
自问自答(“The X? A Y.")
AI 喜欢提出一个修辞性问题,然后立即回答。这种问题往往是读者没想过的,回答也往往平淡无奇。
改写前:**结果?**毁灭性的。**最糟糕的部分?**没人预料到。 改写后:结果是毁灭性的。没人预料到最糟糕的部分。
这种句式制造了一种虚假的节奏感,就像是预先设计好的笑点,但往往并不好笑。
首语重复(Anaphora Abuse)
在连续的句子中重复相同的开头,形成一种排比效果。
改写前:他们假设用户会付费……他们假设开发者会构建……他们假设…… 改写后:他们对用户付费、开发者构建都做了假设。
适当的首语重复是修辞技巧,但 AI 倾向于过度使用,让它变成机械的重复。
三项式滥用(Tricolon Abuse)
人类喜欢三项列举,因为它们有节奏感。AI 也学会了这一点,但它做得太过分了。
改写前:产品打动人;平台赋能人。产品解决问题;平台创造世界。产品线性扩展;平台指数扩展。 改写后:平台比产品更能赋能用户、创造价值并实现指数级扩展。
一个三项式是优雅的,三个连续的三项式就是 AI 味。
2.3 段落结构:那些刻意的节奏
段落层面的 AI 味往往更隐蔽,因为它涉及更大尺度的文本组织。
短促有力片段(Short Punchy Fragments)
AI 喜欢使用非常短的句子或句子片段作为独立段落,制造人为的强调效果。
改写前:他发表了这篇文章。公开地。在一本书里。作为一名牧师。 改写后:他作为一名牧师,公开在一本书里发表了这篇文章。
这种写法源自"为可读性而写"的训练目标,模型试图通过减少每句话的信息密度来"帮助"读者。但结果是文本失去了自然的流动感。
伪装列表(Listicle in a Trench Coat)
当 AI 被要求不要生成列表时,它往往会把列表伪装成散文。
改写前:第一道墙是缺乏免费的限定范围 API……第二道墙是缺乏委托访问……第三道墙…… 改写后:存在几个障碍:缺乏免费的限定范围 API、委托访问和限定范围权限。
这种伪装往往比直接的列表更难阅读,因为读者需要额外的工作来识别列表结构。
2.4 语调模式:那些过于热情的姿态
AI 在语调上有一种奇特的属性:它总是显得过于积极、过于 helpful、过于 eager to please。
“Here’s the kicker”(关键是)
这类短语承诺一个揭示,但往往只是引出一个平淡无奇的观察。
改写前:Here’s the kicker(你猜怎么着)。Here’s where it gets interesting(这里开始变得有趣)。 改写后:(直接陈述观点)
“Imagine a world…"(想象一个世界……)
AI 特别喜欢这种邀请式的开头,尤其是在讨论未来或技术时。
改写前:想象一个世界,你使用的每个工具——日历、收件箱、文档——背后都有一个安静的智能…… 改写后:AI 正在被集成到各种工具中,包括日历、收件箱和文档。
这种写法试图通过唤起画面来建立情感连接,但往往显得陈词滥调。
虚假脆弱性(False Vulnerability)
AI 偶尔会尝试"坦诚"或"自我反思”,但这种脆弱性往往是表演性的。
改写前:是的,我公开热爱平台模式。是的,既然我们坦诚相待:我在看着你,OpenAI、Google、Anthropic、Meta。 改写后:我支持平台模式。大型科技公司在这个领域占据主导地位。
真正的脆弱性是具体的、有风险的;AI 的脆弱性是抛光的、安全的。
编造概念标签(Invented Concept Labels)
AI 喜欢创造听起来分析性但实际上没有明确定义的复合标签。
改写前:监督悖论(supervision paradox)。加速陷阱(acceleration trap)。工作负载蔓延(workload creep)。 改写后:监督中的矛盾。加速带来的问题。工作负载的增长。
这些标签听起来像是学术术语,但往往是模型的即兴发挥,缺乏严谨的定义。
2.5 格式问题:那些视觉上的痕迹
AI 味的视觉痕迹往往比文字内容更容易识别。
破折号成瘾(Em-Dash Addiction)
人类作家可能在一篇文章中使用 2-3 个破折号,AI 会使用 20+。
改写前:问题 —— 这是没人谈论的部分 —— 是系统性的。 改写后:问题是系统性的,尤其是没人谈论的那些方面。
破折号在 AI 文本中被用来制造戏剧性的停顿、括号式的旁白和转折。
粗体开头项目符号(Bold-First Bullets)
在 Claude 和 ChatGPT 的输出中极为常见:每个项目符号都以粗体短语开头。
改写前:安全性:基于环境的配置……性能:延迟加载…… 改写后:安全性:基于环境的配置……性能:延迟加载……
这种格式在人类手写文档中几乎看不到。
Unicode 装饰(Unicode Decoration)
AI 喜欢使用特殊字符,如 unicode 箭头(→)、智能引号(""),这些在标准键盘上不易输入。
改写前:输入 → 处理 → 输出。 改写后:输入 -> 处理 -> 输出。
2.6 写作结构:那些大尺度的套路
在文章和章节的尺度上,AI 也表现出可识别的模式。
分形摘要(Fractal Summaries)
“我要告诉你什么;我正在告诉你什么;我刚告诉了你什么”——这种结构被应用到文档的每一个层级。
改写前:在本节中,我们将探索……[3000 字后]……正如我们在本节中看到的。 改写后:(删除重复总结,保留核心内容)
死隐喻(The Dead Metaphor)
AI 会抓住一个隐喻,然后在整篇文章中反复使用,直到它失去所有活力。
改写前:生态系统需要生态系统来构建生态系统价值。墙和门在同一篇文章中使用了 30+ 次。 改写后:(引入隐喻后,使用一次然后继续前进)
历史类比堆砌(Historical Analogy Stacking)
快速连续列出历史公司或技术革命来建立虚假权威。
改写前:Apple 没有构建 Uber。Facebook 没有构建 Spotify。Stripe 没有构建 Shopify。AWS 没有构建 Airbnb。 改写后:大型科技公司通常不会构建在其平台上成长起来的成功产品。
单点稀释(One-Point Dilution)
提出一个论点,然后以 10 种不同的方式在数千字中重述它。
改写前:相同的观点,在 4000 字中以八种方式重述。 改写后:(压缩为一个清晰的论点陈述)
标志性的结论(The Signposted Conclusion)
用"In conclusion”、“To sum up”、“In summary"明确地宣布结论。
改写前:总之,AI 的未来取决于……总结一下,我们探讨了三个关键主题…… 改写后:(直接陈述结论,不需要标记)
第三章:去除 AI 味的核心原则
识别 AI 味只是第一步。真正难的是去除它。五条原则:
3.1 删除填充短语
AI 喜欢在进入正题之前进行"预热”。这些预热短语包括:
- “值得注意的是……”
- “重要的是……”
- “有趣的是……”
- “在这个时间点上……”
- “为了实现这一目标……”
改写前:值得注意的是,数据显示性能有了显著提升。 改写后:数据显示性能显著提升。
这些短语就像是演讲者在台上清嗓子。偶尔一次可以容忍,反复出现就会让人厌烦。
3.2 打破公式结构
AI 喜欢对称、平衡、成对出现。但现实世界的思想很少如此整齐。
改写前:我们不仅需要考虑技术可行性,还需要考虑伦理影响,同时兼顾用户体验和长期维护成本。 改写后:技术可行性、伦理影响、用户体验——这三者经常打架。你需要在不同的情况下做不同的取舍。
人类可以接受不平衡。事实上,不平衡往往更有趣。
3.3 变化节奏
AI 生成的文本往往有一种机械的节拍感。句子长度相似,结构相似,结尾方式相似。
打破这种节奏的方法很简单:刻意制造变化。
- 一个短句。然后是一个需要好几行才能说完的长句,带着各种从句和插入语,就像一个话痨在酒吧里跟你聊天。
- 再然后又是一个词。
这种变化让读者保持警觉。它模拟了人类思维的跳跃性。
3.4 信任读者
AI 有一种低估读者的倾向。它会解释隐喻,会铺垫背景,会手把手引导。
改写前:这就像在暴风雨中驾驶一艘船——换句话说,你需要时刻保持警觉并做出快速调整。 改写后:这就像在暴风雨中驾驶一艘船。
相信读者能理解隐喻,能跟上思路,不需要你牵着走。
3.5 删除金句
如果一句话听起来像是可以在 Twitter 上被疯狂转发的"金句”,删掉它,重写。
改写前:在这个快速变化的世界里,唯一不变的就是变化本身。 改写后:技术变化的速度让人难以跟上。去年的最佳实践今年可能就过时了。
真正的洞察很少以格言的形式出现。它们通常是具体的、有瑕疵的、难以提炼的。
第四章:注入灵魂的具体方法
去除 AI 味不只是删除不良模式。 sterile, voiceless writing 和机器生成的内容一样糟糕。好的写作背后有一个人。六个方法:
4.1 有观点
不要只是报告事实。要对它们做出反应。
改写前:实验产生了有趣的结果。智能体生成了 300 万行代码。一些开发者印象深刻,另一些则持怀疑态度。 改写后:我真的不知道该怎么看待这件事。300 万行代码,在人类大概睡觉的时候生成的。开发社区有一半人疯了,另一半人在解释为什么这不算数。
“我真的不知道该怎么看待这件事”——这句话没有任何信息价值,但它告诉你:这里有一个真实的人在思考。
4.2 变化节奏
短促有力的句子。然后是需要时间慢慢展开的长句,带着各种修饰和插入,就像一个话痨在酒吧里跟你聊天。
改写前:系统性能良好。它处理请求速度快。内存使用在可接受范围内。响应延迟低。 改写后:系统跑得不错。平均响应时间 23 毫秒——足够快,让用户感觉不到等待。内存占用?稳定在 4GB 左右,不会突然飙升把你半夜叫起来救火。
4.3 承认复杂性
真实的人有复杂的感受。
改写前:这个新技术令人印象深刻,代表了行业的重大突破。 改写后:这个新技术令人印象深刻,但也让人有点不安。我不知道我们是否真的准备好了。
“但是"后面的内容,往往比前面的更有价值。
4.4 使用"我”
第一人称不是不专业。它是诚实。
改写前:人们可能会认为这种方法存在局限性。 改写后:我觉得这种方法行不通。至少在我的经验里,它总是导致灾难。
“我觉得"比"人们可能会认为"更有力量,因为它来自一个具体的位置。
4.5 允许混乱
完美的结构感觉像算法。跑题、题外话、半成型的想法——这些是人性的体现。
改写前:本文将按照以下结构展开:第一节介绍背景,第二节讨论方法,第三节分析结果,第四节总结。 改写后:我本来只想讲讲方法,但写的时候发现背景也很重要。所以先啰嗦几句背景——如果你已经熟悉这块,直接跳到第二节也无妨。
这种"混乱"让读者感到放松。它说:这里有一个真实的人在组织这些想法,而不是一个机器在执行模板。
4.6 对感受要具体
不是"这令人担忧”,而是:
改写后:凌晨三点,你躺在床上,突然想到服务器还在那里自己跑着,没有人看着。那种感觉很奇怪。
具体的感受比抽象的形容词更有说服力。
第五章:实战改写示例
让我们来看几个完整的改写案例。
示例 1:技术文档
改写前(AI 味道):
AI 辅助编程作为大型语言模型变革性潜力的持久证明,标志着软件发展演变史上的关键时刻。在当今快速发展的技术格局中,这些开创性的工具—— nestled 在研究与实践的交汇处——正在重塑工程师构思、迭代和交付的方式,凸显了它们在现代工作流中的重要作用。
其核心,价值主张是明确的:精简流程、增强协作、促进一致性。这不仅仅是关于自动补全;它是关于大规模释放创造力,确保组织能够保持敏捷,同时向用户交付无缝、直观和强大的体验。
行业观察者指出,采用已经从爱好者实验加速到企业级推广,从个人开发者到跨职能团队。该技术已被《纽约时报》、Wired 和 The Verge 报道。
改写后(人性化):
AI 编程助手确实能加快一些任务的完成速度。Google 在 2024 年的一项研究中,使用 Codex 的开发者在简单函数上比对照组快 55%,但在调试或架构决策上没有改进。
这些工具擅长处理样板代码:配置文件、测试脚手架、重复的重构。它们不擅长的是知道自己什么时候错了。我曾经批量接受那些编译通过、通过了 lint、但仍然做错了的建议,因为我在使用它们的时候停止了思考。
Mira,一家金融科技创业公司的工程师,告诉我她把 Copilot “当成无聊代码的自动补全”,但每行都审查后才提交。Jake,一家大公司的资深开发者,在它不断建议一个已弃用的内部库的模式后关闭了它。
生产力声明很难验证。GitHub 说 Copilot 用户 “接受 30% 的建议”,但接受不等于正确,正确不等于有价值。2024 年 Uplevel 的研究发现,有和没有 AI 助手的团队,在 pull request 吞吐量上没有统计学显著差异。
改动分析:
- 删除了"作为……证明"、“标志着”、“格局”、“作用"等夸大性词汇
- 用具体的研究(Google 2024、Uplevel 2024)替代了"行业观察者指出”
- 用具体的人(Mira、Jake)替代了抽象的"用户"
- 删除了三段式列举(“无缝、直观和强大”)
- 删除了媒体名称的堆砌
示例 2:产品介绍
改写前(AI 味道):
坐落在埃塞俄比亚贡德尔地区令人叹为观止的区域内,Alamata Raya Kobo 是一座充满活力的城镇,拥有丰富的文化遗产和迷人的自然美景。该镇拥有每周集市和 18 世纪教堂,见证了该地区的历史意义,为埃塞俄比亚文化多样性做出了重要贡献。
改写后(人性化):
Alamata Raya Kobo 是埃塞俄比亚贡德尔地区的一座城镇。每周四有集市,主要卖 livestock 和谷物。镇上有一座 18 世纪的教堂,石墙上的壁画已经褪色斑驳,但 still recognizable 是圣乔治屠龙的场景。
改动分析:
- 删除了"坐落在……令人叹为观止的区域内"、“充满活力”、“丰富的文化遗产”、“迷人的自然美景"等宣传性语言
- 删除了"见证了”、“做出了……贡献"等夸大其词的表述
- 用具体的细节(周四集市、livestock 和谷物、褪色的壁画)替代了泛泛而谈
示例 3:个人随笔
改写前(AI 味道):
在这个快速变化的世界里,适应是成功的关键。值得注意的是,技术变革正在重塑我们生活的方方面面。然而,尽管存在这些挑战,人类精神继续蓬勃发展,寻找新的创新方式来应对不断演变的格局。
改写后(人性化):
我上周把手机掉进了水里。不是掉进马桶那种——是掉进了河里,去捞的时候滑了一跤,整个人都湿了。手机当然报废了。但奇怪的是,那三天没有手机的日子,我居然睡得比之前几个月都好。
改动分析:
- 删除了"在这个快速变化的世界里”、“值得注意的是”、“然而”、“尽管存在这些挑战”、“蓬勃发展”、“不断演变的格局"等 AI 词汇和公式化表达
- 用一个具体的故事(掉手机)替代了抽象的观察
- 用个人的感受(睡得更好)替代了泛泛的结论
第六章:快速检查清单
在你交付任何文字之前,运行一下这个检查清单:
句子层面:
- 连续三个句子长度相同?打断其中一个
- 使用了"此外"“然而"“值得注意的是”?考虑删除
- 有"作为……“回避?改用"是”
- 有"不是……而是……"?考虑直接陈述
- 有自问答(“X?Y。")?改为陈述句
- 使用了"想象"“关键是"“让我们分解”?删除这些设置语
段落层面:
- 段落以简洁的单行结尾?变换结尾方式
- 三段式列举?改为两项或四项
- 使用了粗体开头的项目符号?改为普通格式
结构层面:
- 有破折号?考虑减少到 2-3 个
- 使用了"In conclusion”?删除
- 相同的隐喻重复出现?保留一次,删除其余
- 有"从 X 到 Y"的虚假范围?检查 X 和 Y 是否真有尺度关系
灵魂检查:
- 我表达了观点吗?还是只是中立报道?
- 有"我"出现吗?
- 句子长度有变化吗?
- 有具体的细节吗?还是都是抽象概念?
- 读起来像是我会说的吗?还是像机器人说的?
结语:写作为人
去除 AI 味的过程,本质上是一场回归。回归到写作最原始的目的:一个人向另一个人传达思想。
AI 写作的问题不在于它"错了”。它太"对"了——太平均、太安全、太无懈可击。它像是在一个巨大的房间里,用最大的声音说着最稳妥的话。
但人类的交流不是这样的。我们说话时会犹豫、会跑题、会突然想到一个奇怪的例子、会承认"我不知道”。这些"不完美"让交流更有效,因为它们建立了信任。它们告诉听众:这里有一个真实的人,带着真实的局限,在尝试传达真实的想法。
所以,当你下次写作时,想象你对面坐着一个具体的人。比如你曾经的酒友,或者你尊重但不必讨好的同事。你会怎么跟他说话?你会用哪些词?你会怎么组织你的句子?
那个声音,就是你真正的声音。找到它,用它写作,AI 味自然就消失了。
参考资料
本文的完成离不开开源社区的贡献。以下是本文参考和引用的主要资源:
核心资源
Wikipedia: Signs of AI writing
- 链接:https://en.wikipedia.org/wiki/Wikipedia:Signs_of_AI_writing
- 维护者:WikiProject AI Cleanup
- 贡献:这是 AI 写作痕迹识别领域最权威的参考文档之一,由数千名维基志愿者基于实际观察编纂而成。
tropes.fyi
- 链接:https://tropes.fyi
- 维护者:Ossama Ismail (ossama.is)
- 贡献:提供了详尽的 AI 写作模式分类和示例,是本文"六大类别"框架的主要来源。
Claude Code Skills
humanizer (英文版)
- 作者:Blader
- 功能:去除 AI 写作痕迹的 Claude Code Skill
- 特点:基于 Wikipedia 指南,提供了完整的英文 AI 模式识别与改写指南
humanizer-zh (中文版)
- 原作者:Blader
- 中文适配:基于 hardikpandya/stop-slop 和 tropes.fyi 进行了深度优化
- 特点:针对中文 AI 写作模式进行了本土化调整,包含 45 个具体模式
stop-slop
- 作者:Hardik Pandya
- 链接:https://github.com/hardikpandya/stop-slop
- 贡献:提供了"去除 AI 味"的核心原则框架
关键洞察
“LLM 使用统计算法来猜测接下来应该是什么。结果倾向于适用于最广泛情况的统计上最可能的结果。”
正是这个"最广泛适用"的倾向,产生了我们所说的 AI 味。