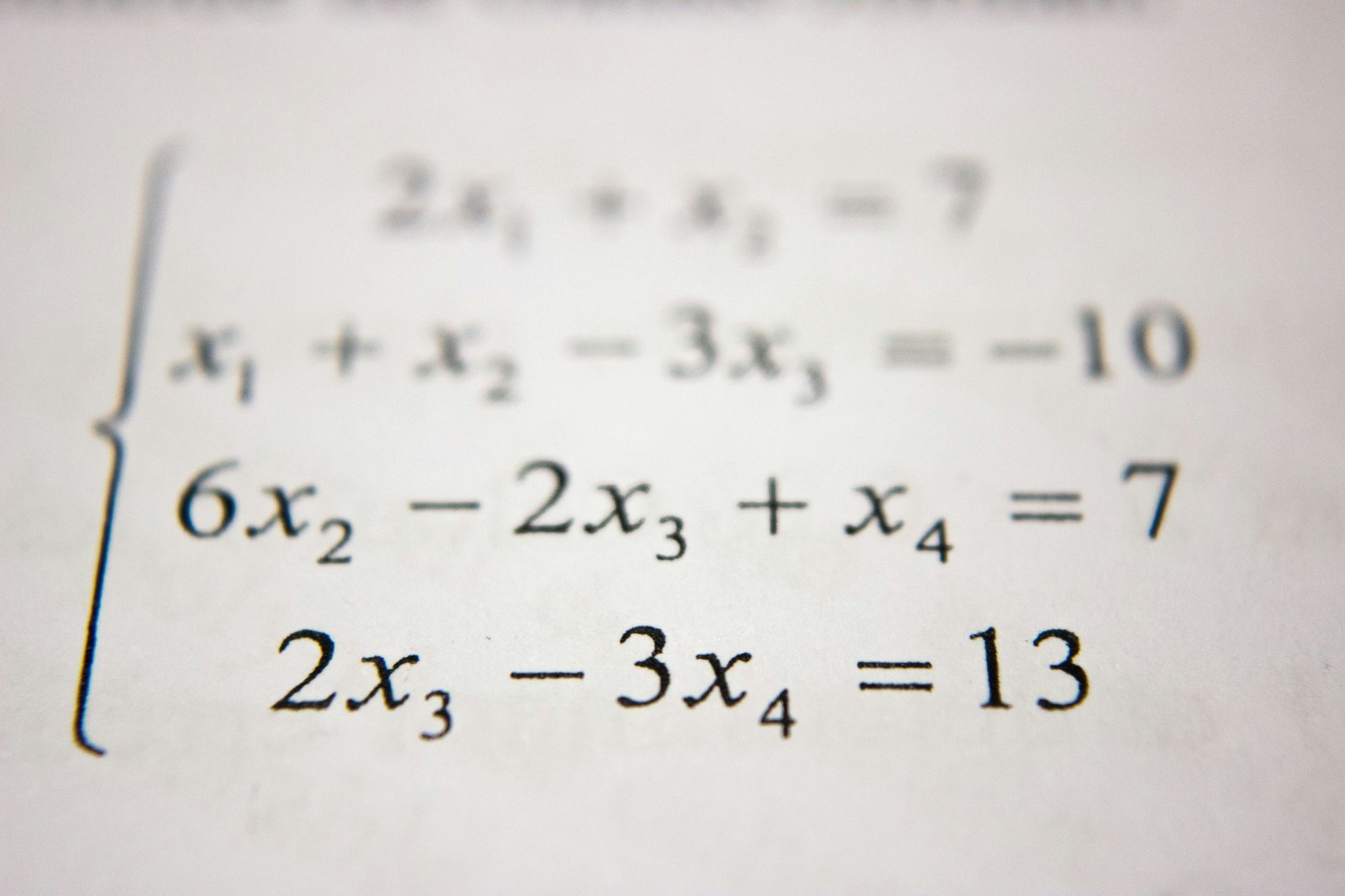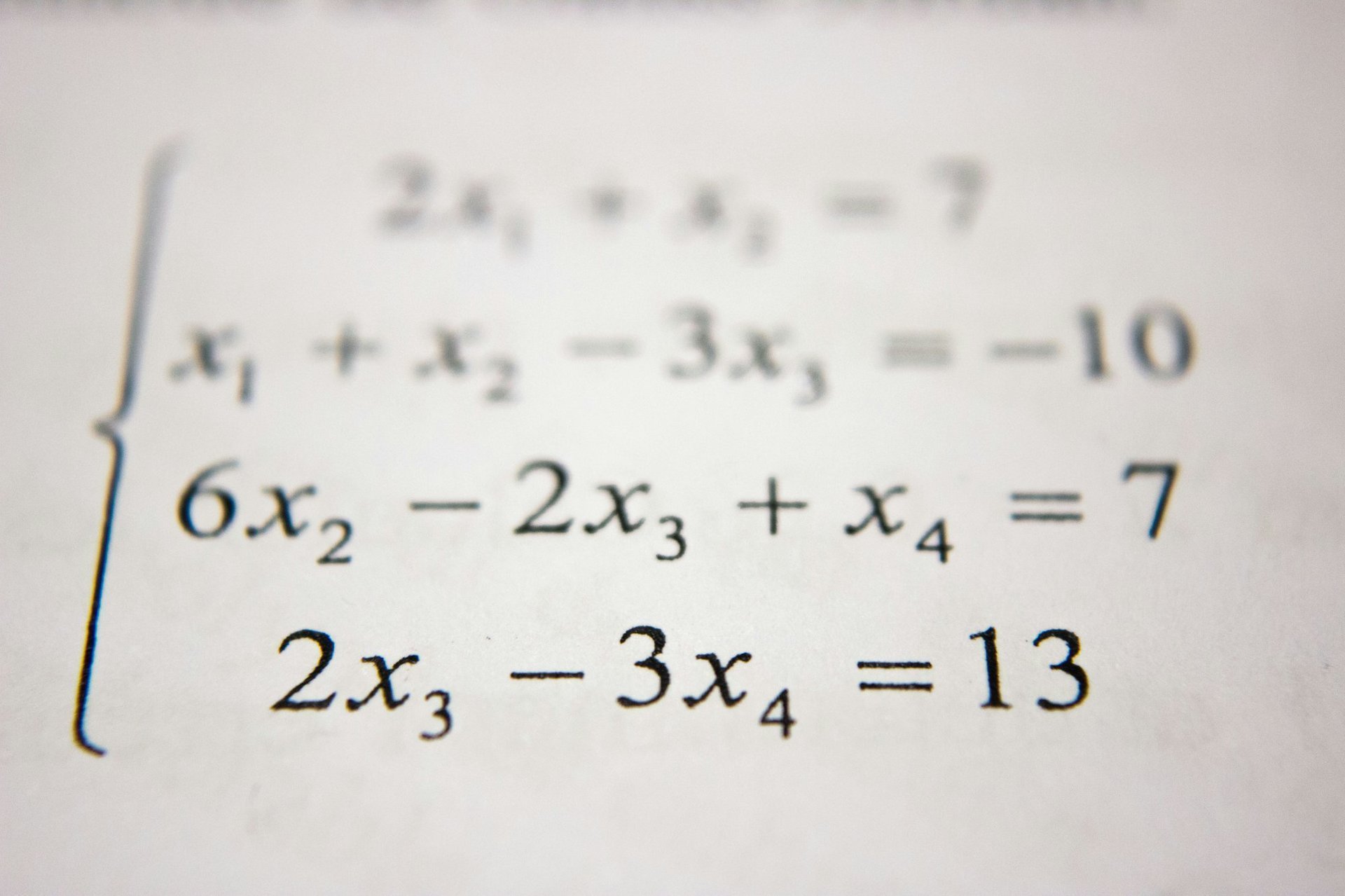
拉普拉斯方程:数学物理中的优雅平衡
引言:一片平静的水面 想象一个平静的水面,没有风,没有涟漪。如果我们在水面上轻轻滴一滴墨水,墨水会如何扩散?这背后隐藏着一个深刻的数学原理。 再想象一个均匀导热的金属板,边缘保持恒定温度。时间足够长后,板内部的温度分布会达到一种稳定状态。有趣的是,这种稳定状态有一个共同的数学描述。 这就是拉普拉斯方程的魔法所在。它描述的是一种完美的"平衡"状态——系统中每一点的数值都与其周围邻居的平均值相等。这个简单的条件,却蕴含着自然界中无数现象的精髓。 一、历史的足迹 皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace,1749-1827)是法国数学家、天文学家和物理学家。他在研究天体力学和引力问题时,首次系统地研究了这个以他名字命名的方程。 但拉普拉斯方程的发现并非孤立的。在此之前,欧拉(Euler)和达朗贝尔(d’Alembert)已经在流体力学和波动方程的研究中涉及了类似的思想。拉普拉斯的贡献在于他系统性地研究了这个方程,并将其推广到多个变量,使其成为研究各种物理现象的统一框架。 二、从一维开始:最简单的平衡 让我们从最简单的一维情况开始理解拉普拉斯方程。 一维拉普拉斯方程 在一维情况下,拉普拉斯方程的形式异常简洁: $$ \frac{d^2 u}{dx^2} = 0 $$ 其中 $u(x)$ 是我们要找的函数。 这个方程说的是什么呢?它的意思是函数的二阶导数为零。在微积分中我们知道,如果二阶导数为零,那么一阶导数必须是常数: $$ \frac{du}{dx} = C_1 $$ 再积分一次,我们得到: $$ u(x) = C_1 x + C_2 $$ 这告诉我们,在一维情况下,满足拉普拉斯方程的函数只能是线性函数(直线)。 物理意义 想象一根均匀的导热棒,两端分别保持不同的温度。当热传导达到稳定状态时,温度分布会是怎样的? 如果棒长为 $L$,左端温度为 $T_1$,右端温度为 $T_2$,那么温度分布 $u(x)$ 满足: $$ \frac{d^2 u}{dx^2} = 0, \quad u(0) = T_1, \quad u(L) = T_2 $$ 解这个方程,我们得到: $$ u(x) = T_1 + \frac{T_2 - T_1}{L} x $$ ...