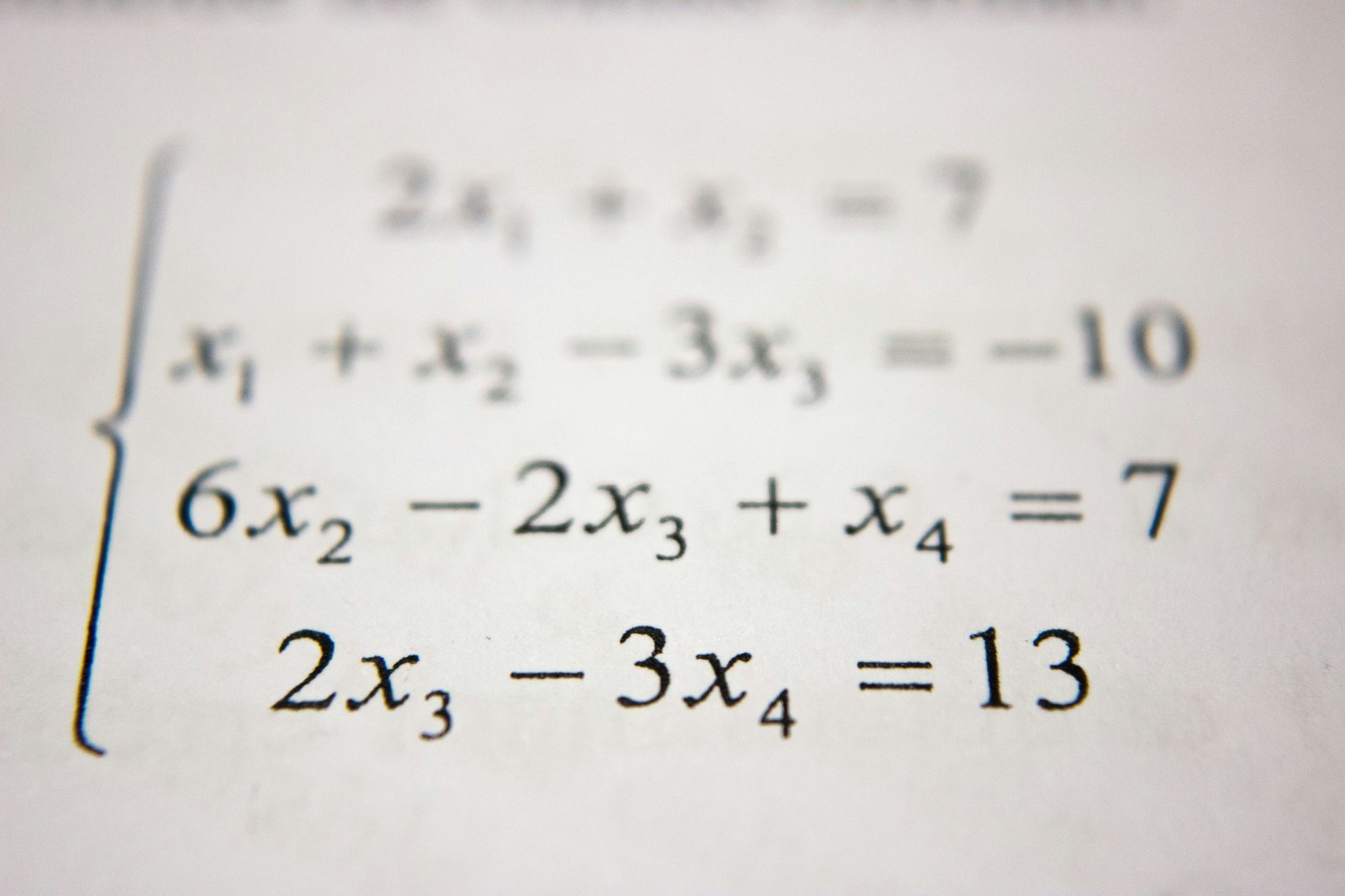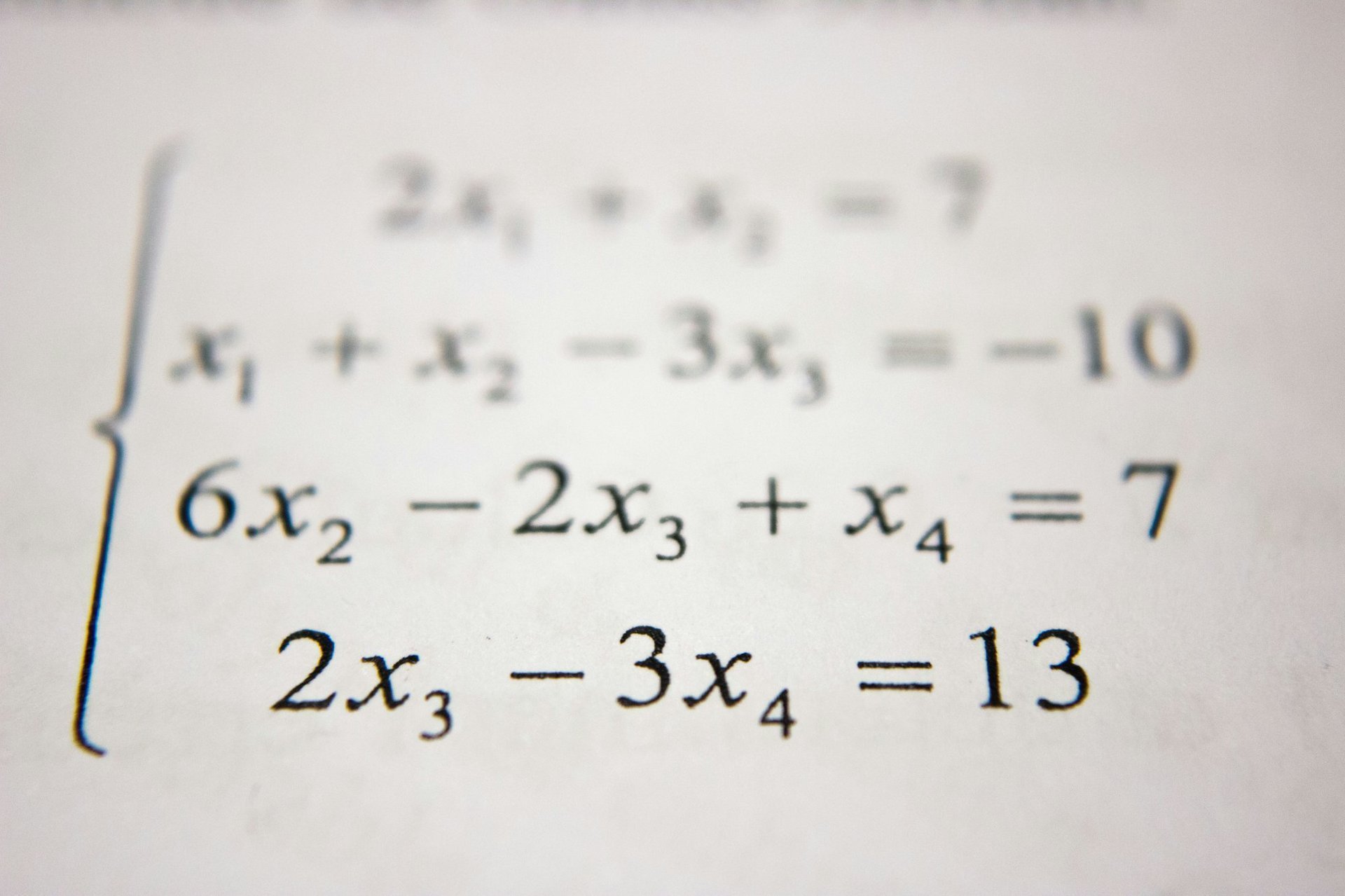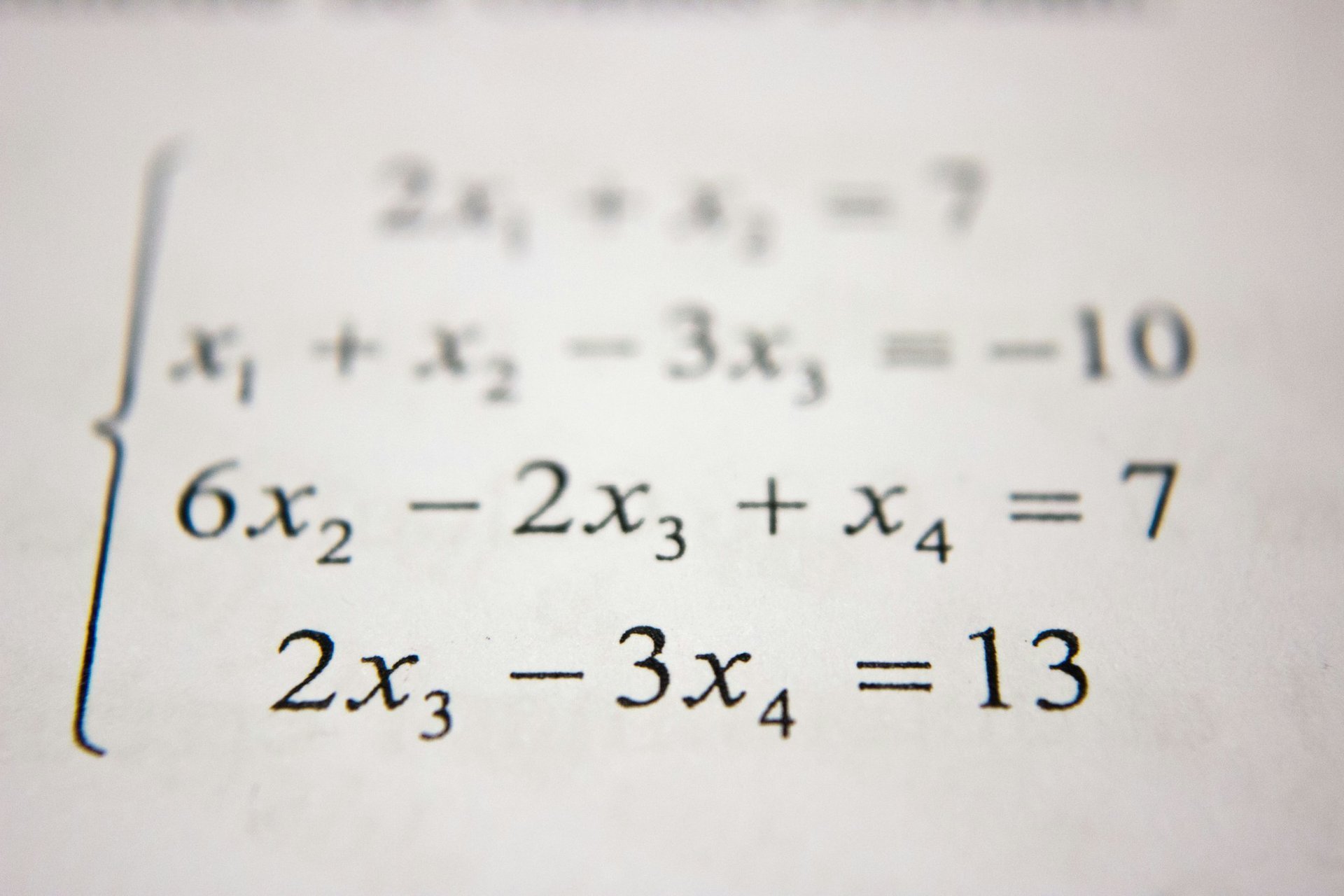
泰勒公式:用简单近似复杂的艺术
引言:从曲线到直线 想象你站在一座山上,想知道脚下的山坡有多陡。你不需要知道整个山脉的形状,只需要知道你所在位置的局部斜率。这是微积分最基本的思想——用局部信息推断全局行为。 更进一步,如果山坡弯曲了怎么办?这时不仅需要知道斜率,还需要知道弯曲的程度。这就是泰勒公式的核心思想:用最简单的函数(多项式)来近似复杂的函数,而近似的质量取决于我们使用多少局部信息(导数)。 泰勒公式被誉为"数学家最有力的工具之一"。它不仅连接了离散与连续、局部与整体,更在数值计算、物理建模和现代人工智能中扮演着不可替代的角色。今天,让我们深入探索这个既古老又常新的数学宝藏。 一、历史回顾:从牛顿到泰勒 泰勒公式的思想可以追溯到牛顿和莱布尼茨创立微积分的时期。牛顿在他的《流数术》中已经隐含了将函数展开为无穷级数的想法。 布鲁克·泰勒(Brook Taylor,1685-1731)在1715年发表了他的开创性论文《增量法及其逆运算》,首次系统地阐述了用多项式级数逼近函数的方法。有趣的是,泰勒本人并没有意识到他发现的公式的全部潜力,余项的研究(拉格朗日余项、柯西余项等)是后来由拉格朗日等数学家完善的。 麦克劳林(Colin Maclaurin)发现了泰勒公式在零点展开的特例,即麦克劳林级数。这个形式在实际计算中更为常用,因为计算起来更加方便。 二、一元函数的泰勒公式 基本形式 假设函数 $f(x)$ 在点 $a$ 处足够光滑(即具有各阶导数),那么我们可以构造一个多项式 $P_n(x)$ 来近似 $f(x)$: $$ P_n(x) = f(a) + f’(a)(x-a) + \frac{f’’(a)}{2!}(x-a)^2 + \cdots + \frac{f^{(n)}(a)}{n!}(x-a)^n $$ 泰勒公式告诉我们: $$ f(x) = P_n(x) + R_n(x) $$ 其中 $R_n(x)$ 是余项,表示近似误差。 余项的几种形式 理解余项对于掌握泰勒公式至关重要,因为它告诉我们近似在什么范围内可靠。 拉格朗日余项: $$ R_n(x) = \frac{f^{(n+1)}(\xi)}{(n+1)!}(x-a)^{n+1} $$ 其中 $\xi$ 是 $a$ 和 $x$ 之间的某个值。 积分余项: $$ R_n(x) = \frac{1}{n!} \int_a^x f^{(n+1)}(t)(x-t)^n , dt $$ 直观理解 让我们通过一个简单的例子来理解泰勒公式。考虑 $f(x) = e^x$ 在 $a = 0$ 处的泰勒展开(即麦克劳林级数): ...