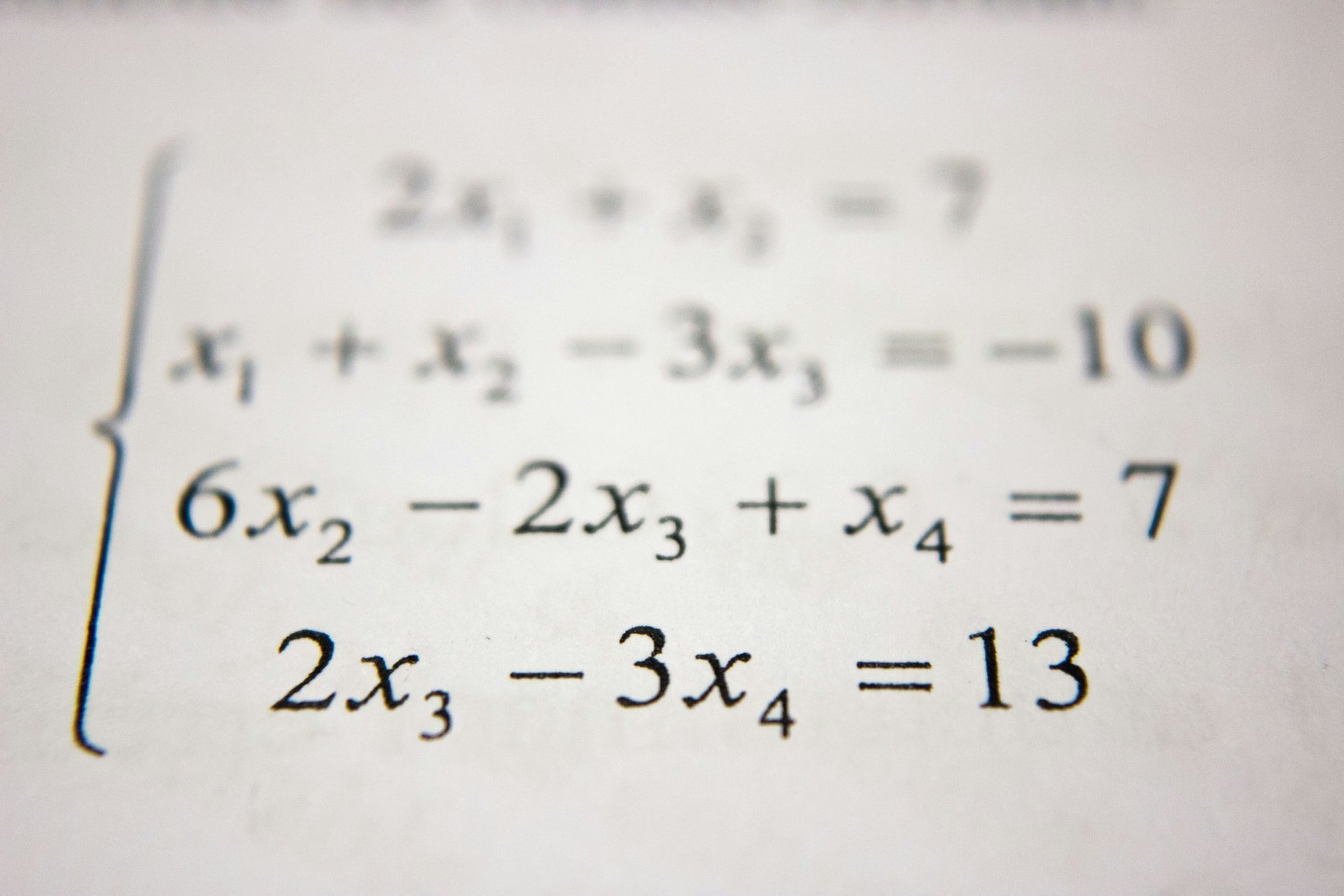弯曲的道路,智能的决策:微分几何如何赋能自动驾驶
引言:当数学遇见自动驾驶 想象你正在驾驶一辆汽车行驶在蜿蜒的山路上。前方是一个急转弯,你需要减速、打方向、保持车道——这一系列看似简单的动作,实际上涉及复杂的几何判断:道路的曲率如何?转弯半径是多少?轮胎与地面的摩擦力能否提供足够的向心力? 现在,把驾驶员换成自动驾驶系统。它没有了人类的直觉和经验,必须依靠数学模型来理解这个世界。微分几何——这门研究曲线、曲面和弯曲空间的数学分支,正是自动驾驶系统的"眼睛"和"大脑"背后的理论基础。 从古希腊欧几里得研究直线和平面,到高斯发现曲面可以"内蕴地"研究,再到黎曼建立起 $n$ 维弯曲空间的一般理论,微分几何经历了两千多年的发展。而今天,这门古老的数学正以全新的方式赋能现代科技:它帮助自动驾驶汽车理解道路的几何结构,规划平滑的行驶轨迹,感知周围环境的三维形态。 本文将带你走进微分几何与自动驾驶的交汇点,看看抽象的数学概念如何在现实世界中大放异彩。 第一章:微分几何的核心概念回顾 1.1 曲线:道路的一维模型 一条道路可以抽象为三维空间中的一条参数曲线: $$ \mathbf{r}(t) = (x(t), y(t), z(t)) $$ 其中 $t$ 是参数,可以是时间,也可以是弧长。对于自动驾驶而言,我们最关心的是曲线的两个几何量:切向量和曲率。 切向量告诉我们道路在每一点的"方向": $$ \mathbf{T}(t) = \frac{d\mathbf{r}/dt}{\lVert d\mathbf{r}/dt \rVert} $$ 汽车的前进方向应该与切向量对齐,这是最基本的控制要求。 曲率则告诉我们道路弯曲的程度。对于以弧长 $s$ 参数化的曲线,曲率定义为: $$ \kappa(s) = \left\lVert \frac{d\mathbf{T}}{ds} \right\rVert = \left\lVert \frac{d^2\mathbf{r}}{ds^2} \right\rVert $$ 曲率的倒数 $\rho = 1/\kappa$ 称为曲率半径。当汽车以速度 $v$ 通过曲率为 $\kappa$ 的路段时,所需的向心加速度为 $a = v^2 \kappa$。这就是为什么急转弯需要减速——曲率越大,所需的向心力越大。 1.2 曲面:路面的二维模型 实际的道路不是一个简单的曲线,而是一个曲面。我们可以用参数方程描述: $$ \mathbf{r}(u, v) = (x(u, v), y(u, v), z(u, v)) $$ ...