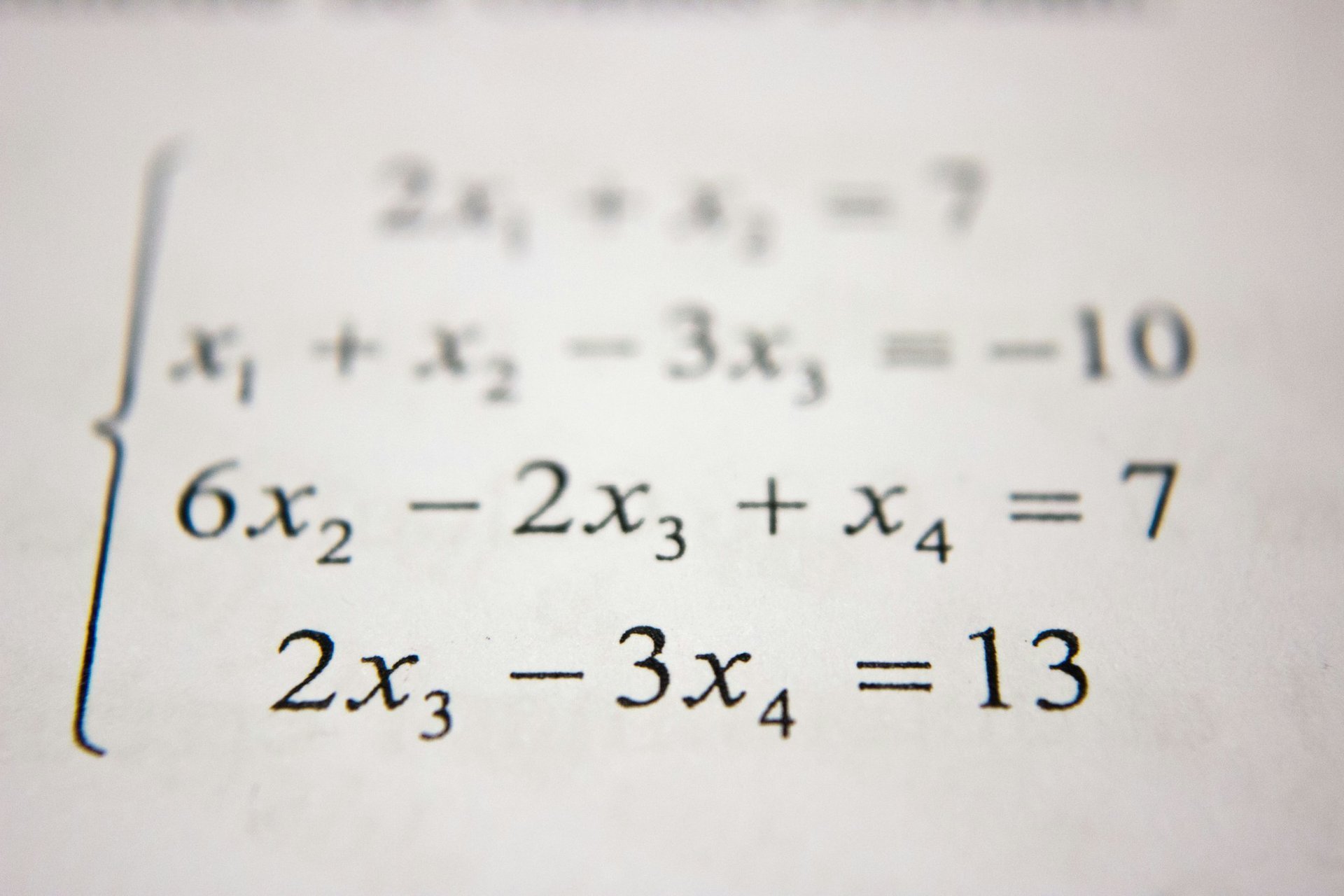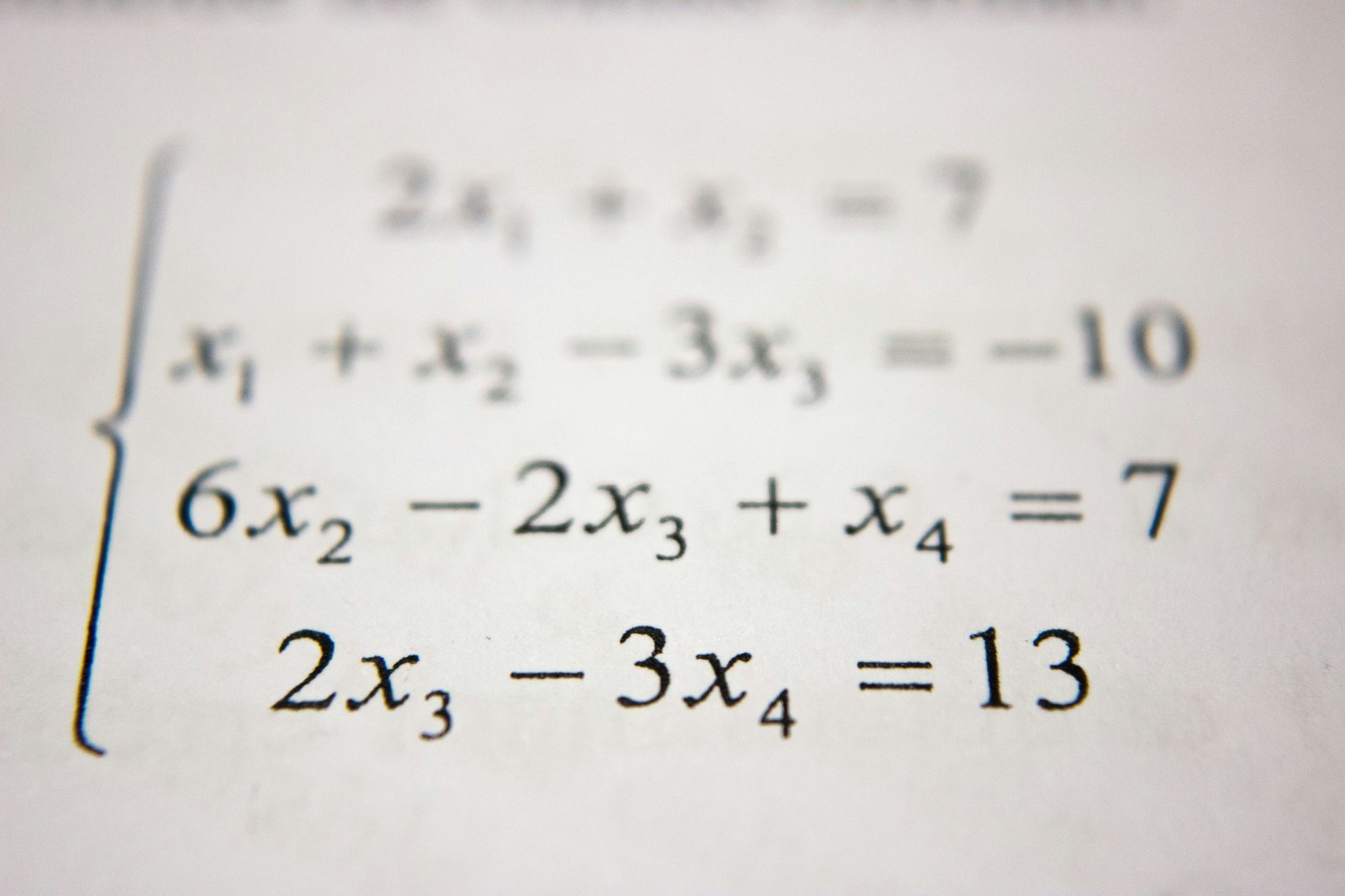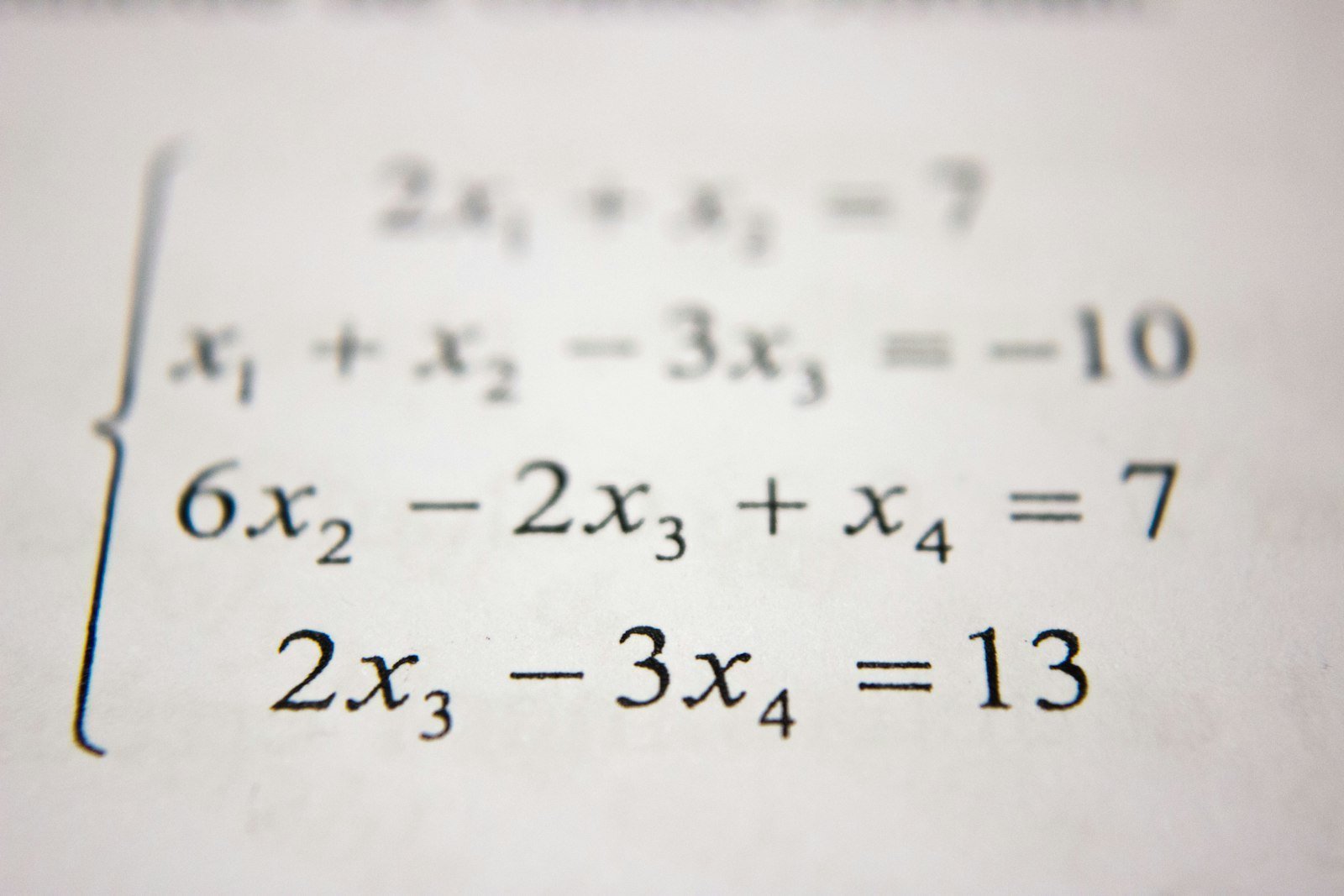
贝叶斯公式:从牧师遗作到人工智能基石
引言:从"上帝的视角"到"凡人的推断" 想象你是一名医生,患者刚刚做完某种疾病的筛查测试。测试结果是阳性。那么,这位患者真正患病的概率是多少? 如果你回答"既然测试准确率是95%,那么患病的概率就是95%",那你和大多数人的直觉一样——但也一样错了。 正确答案可能让你吃惊:哪怕测试准确率达到95%,如果这种疾病在人群中发病率只有1%,那么一个阳性结果意味着患者真正患病的概率可能只有16%左右。 这个反直觉的结果,正是贝叶斯公式的核心思想:我们的信念应该随着新证据的到来而更新,但更新的方式不是简单的替换,而是要结合我们已有的知识(先验信息)。 贝叶斯公式不仅是一个数学定理,更是一种思维方式。它告诉我们:在信息不完整的世界里,我们如何从有限的数据中学习,如何科学地调整我们的信念。从18世纪的一位英国牧师兼数学家,到21世纪的人工智能,贝叶斯的思想经历了一段跌宕起伏的旅程。 timeline title 贝叶斯公式发展历程 section 18世纪 1763年 : 贝叶斯遗作发表 1812年 : 拉普拉斯系统阐述 section 19-20世纪 20世纪初 : 频率学派占据主导 20世纪中叶 : 萨瓦奇、杰弗里斯复兴贝叶斯思想 1980年代 : MCMC方法实用化 section 21世纪 21世纪 : 贝叶斯方法成为AI核心 第一章:贝叶斯牧师的那篇遗作 1.1 托马斯·贝叶斯其人 托马斯·贝叶斯(Thomas Bayes,1701-1761)是18世纪英国的一位长老会牧师,同时也是一位业余数学家。他出生于英格兰的一个显赫家庭,父亲是非国教牧师乔舒亚·贝叶斯。托马斯在爱丁堡大学学习神学和逻辑学,后来接任父亲的教职,在坦布里奇韦尔斯(Tunbridge Wells)担任牧师。 尽管贝叶斯在世时并未在数学领域发表太多作品,但他对概率论有着深刻的思考。他最著名的著作《机会问题的求解方法》(An Essay towards solving a Problem in the Doctrine of Chances)在他去世后于1763年发表在《皇家学会哲学汇刊》上。这篇论文由他的朋友理查德·普莱斯(Richard Price)整理并提交。 1.2 问题的提出:从"已知原因求结果"到"已知结果求原因" 贝叶斯关注的是一个根本性的哲学和数学问题:如果我们观察到某个结果,如何推断导致这个结果的原因? 在贝叶斯之前,概率论主要处理"正向概率"问题:如果我们知道某种原因,可以计算它产生特定结果的概率。例如,如果一枚硬币是均匀的,那么抛掷得到正面的概率是50%。 但现实中我们经常面临"逆向概率"问题:我们观察到了结果,想要推断原因。例如,我们观察到病人有某种症状,想推断他患某种疾病的概率;或者我们观察到数据,想推断产生这些数据的参数。 贝叶斯的天才之处在于,他用条件概率建立了因果推断的数学框架。 ...