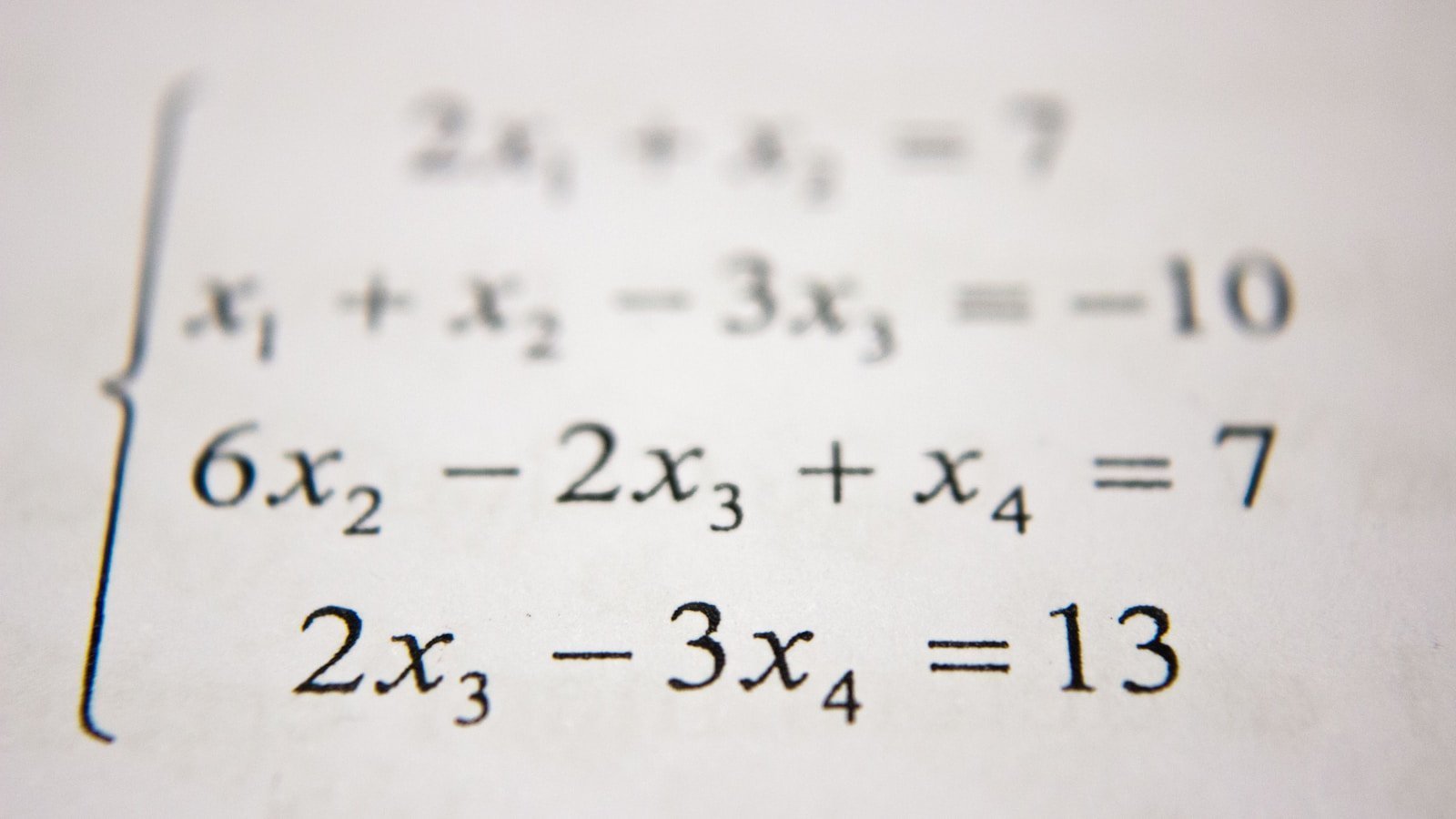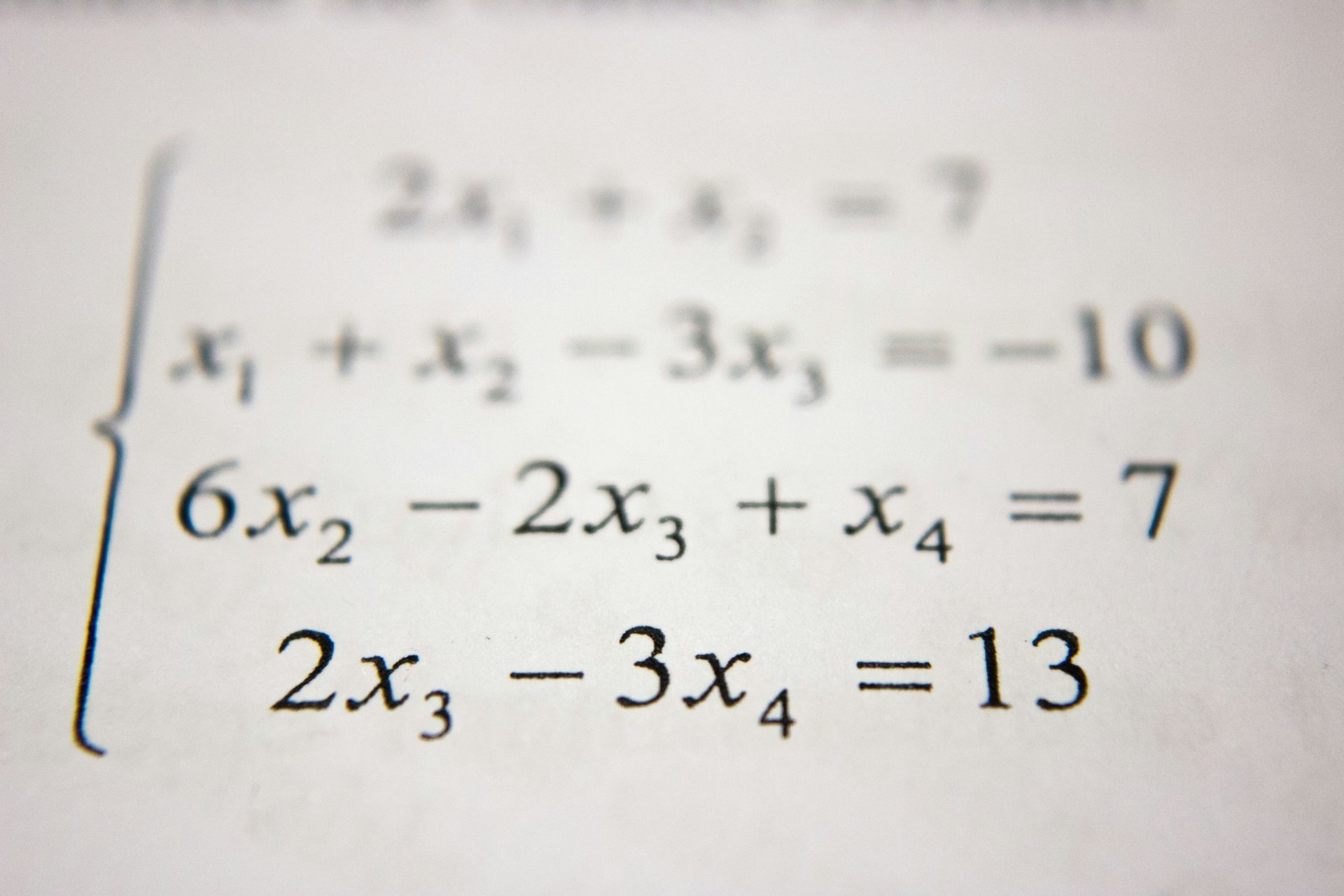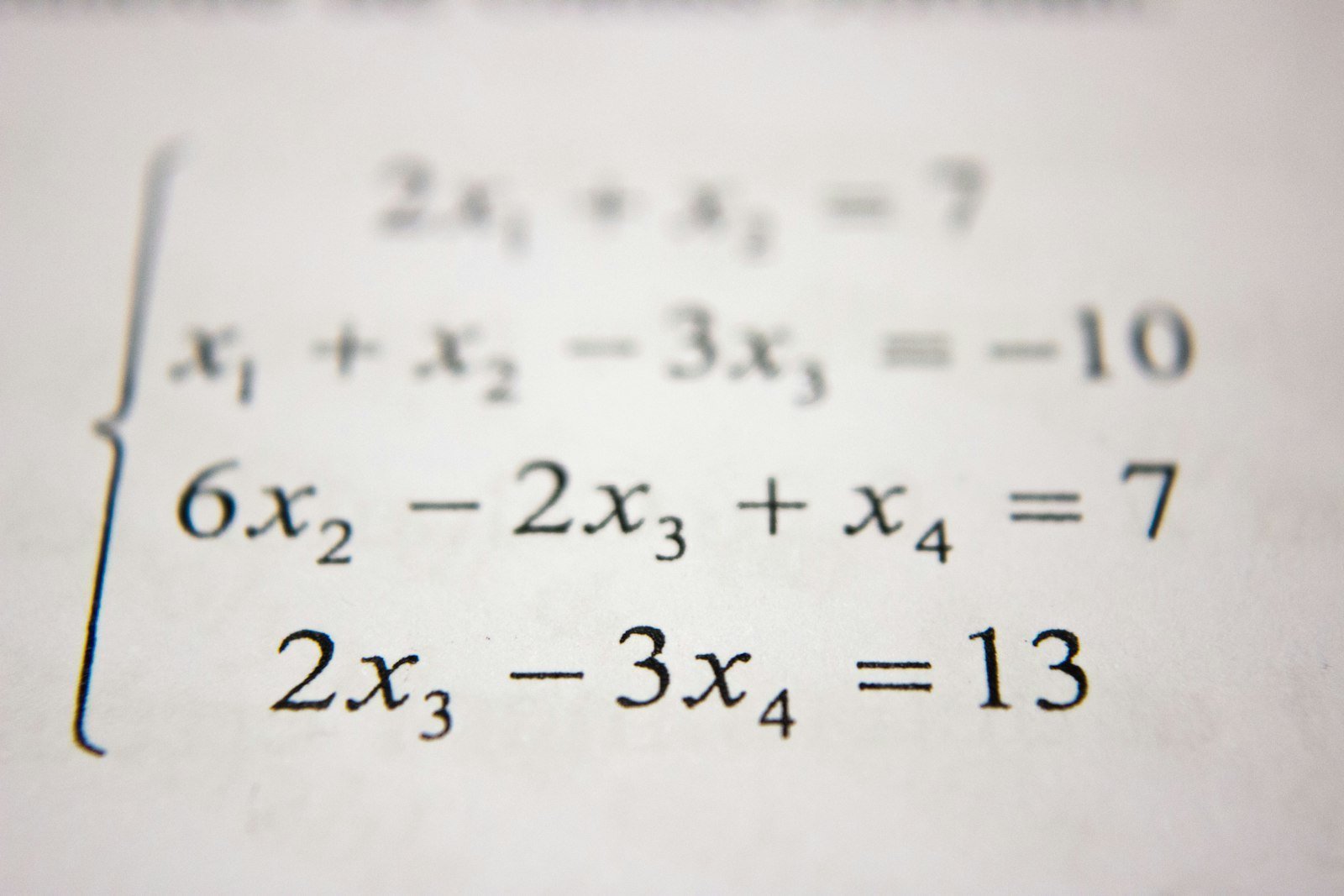
数理统计重要定理系列:大数定律与中心极限定理的深度解读
引言:当随机遇见确定 在赌场里,单个赌徒的输赢完全是随机的——有人一夜暴富,有人倾家荡产。但如果你站在赌场老板的视角,看到的是完全不同的景象:无论今天哪个赌徒赢了多少钱,长期来看,赌场总是稳赚不赔。这不是运气,而是数学。 这种"随机中的确定性"正是概率论研究的核心。而在这座数学大厦的基石上,矗立着两座丰碑:大数定律(Law of Large Numbers)和中心极限定理(Central Limit Theorem)。它们一个告诉我们"均值会收敛到哪里",一个告诉我们"收敛的速度和分布形态"。 这两个定理不仅是统计学的理论基础,更是现代科学的支柱。从民意调查到机器学习,从金融风控到量子物理,它们无处不在。本文将带你深入理解这两个定理的数学本质、历史脉络和实际应用。 历史发展:从赌徒问题到现代概率论 大数定律的历史演进 雅各布·伯努利与《猜度术》(1713) 大数定律的故事始于瑞士巴塞尔的伯努利家族。1713年,雅各布·伯努利(Jacob Bernoulli)的巨著《猜度术》(Ars Conjectandi)在他去世后出版。在这部著作中,伯努利证明了弱大数定律的第一个版本:如果我们反复抛一枚公平的硬币,正面出现的频率会收敛到 $1/2$。 伯努利的证明是革命性的。在那个时代,人们虽然直觉上相信"大样本能消除随机性",但没有人能严格证明这一点。伯努利用二项分布和复杂的级数运算,首次给出了数学上的严格证明。他在书中兴奋地写道:“即使最愚蠢的人,凭借某种本能,也清楚地知道,观测次数越多,观察结果与真实比率相符的可能性就越大。” 泊松的推广(1837) 1837年,法国数学家西莫恩·德尼·泊松(Siméon Denis Poisson)将大数定律推广到了更一般的情形。他证明了,即使试验不是相同分布的,只要满足一定条件,样本均值仍然会收敛到期望值的加权平均。这就是泊松大数定律。 切比雪夫与概率论的严格化(1867) 1867年,俄国数学家帕夫努季·切比雪夫(Pafnuty Chebyshev)发表了具有里程碑意义的论文。他提出了著名的切比雪夫不等式: $$P(|X - \mu| \geq k\sigma) \leq \frac{1}{k^2}$$ 这个不等式虽然简单,却极其强大。它不需要知道随机变量的具体分布,就能给出偏离均值的概率上界。利用这个不等式,切比雪夫给出了大数定律的一个简洁证明,将概率论推向了新的严格化高度。 波莱尔的强大数定律(1909) 1909年,法国数学家埃米尔·波莱尔(Émile Borel)证明了强大数定律:硬币正面频率不仅依概率收敛到 $1/2$,而且几乎必然(almost surely)收敛。这意味着,不收敛的情况发生的概率为零。 波莱尔的工作引入了测度论的语言,为现代概率论奠定了基础。 柯尔莫哥洛夫的公理化(1933) 1933年,俄国数学家安德雷·柯尔莫哥洛夫(Andrey Kolmogorov)发表了《概率论基础》,将概率论严格建立在测度论的基础上。在这套体系中,大数定律有了最一般的表述形式,适用于各种随机变量序列。 中心极限定理的探索之路 棣莫弗与拉普拉斯的发现(1733-1812) 1733年,法国数学家亚伯拉罕·棣莫弗(Abraham de Moivre)在研究二项分布时发现了惊人的现象:当试验次数很大时,二项分布的形状会越来越像一个"钟形曲线"。 具体来说,如果 $X \sim \text{Binomial}(n, p)$,那么当 $n \to \infty$ 时: $$\frac{X - np}{\sqrt{np(1-p)}} \xrightarrow{d} N(0, 1)$$ 1812年,皮埃尔-西蒙·拉普拉斯(Pierre-Simon Laplace)在《分析概率论》中系统发展了这一理论,将其推广到了更一般的情形。这就是著名的棣莫弗-拉普拉斯定理。 李雅普诺夫的关键突破(1901) 1901年,俄国数学家亚历山大·李雅普诺夫(Alexander Lyapunov)引入了特征函数方法,证明了更一般的中心极限定理。他的方法优雅而强大,成为证明CLT的标准工具。 特征函数 $\varphi_X(t) = E[e^{itX}]$ 完全刻画了随机变量的分布。李雅普诺夫证明,独立随机变量之和的特征函数会收敛到正态分布的特征函数,从而证明了CLT。 ...