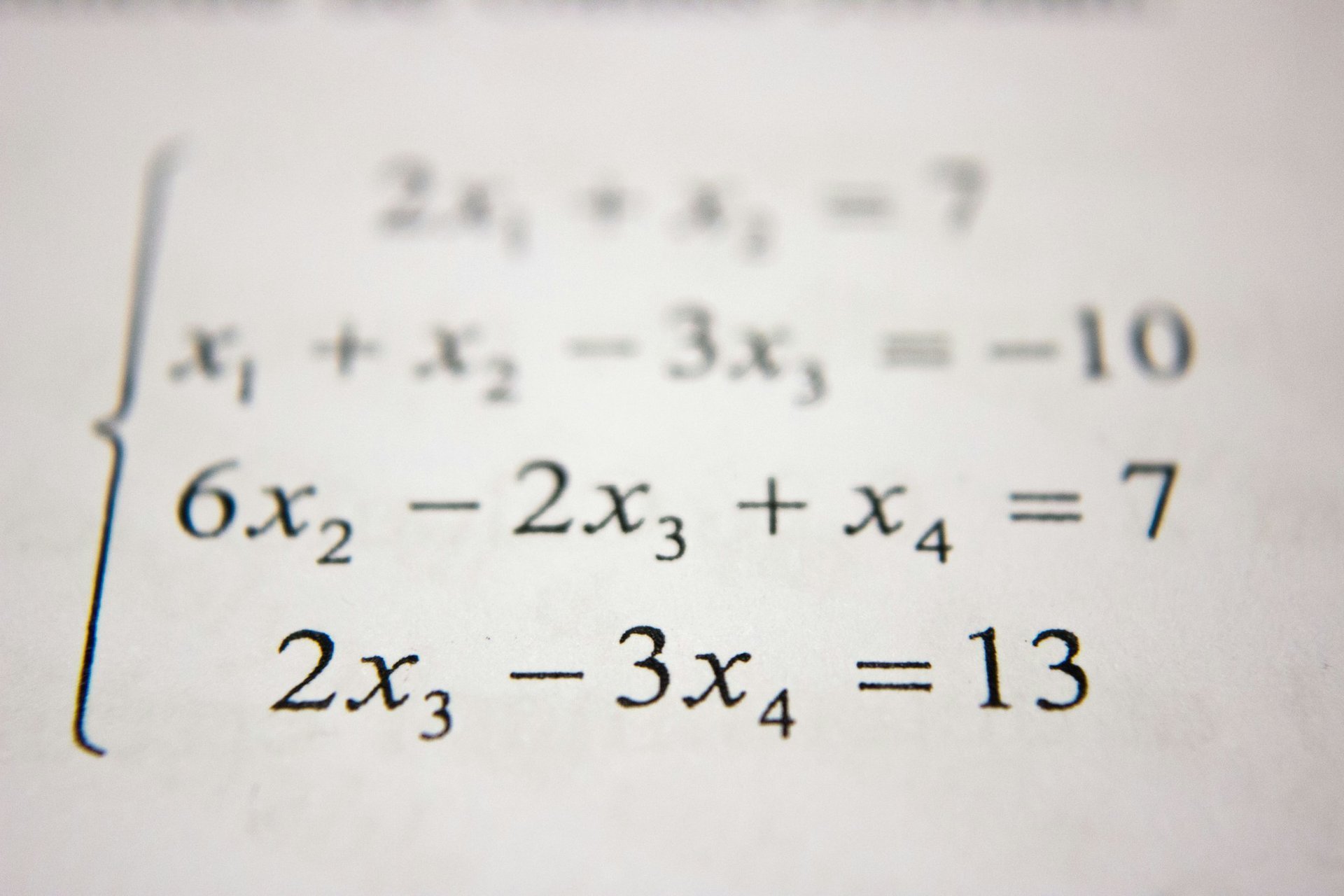
线性代数:从理论到 AI 应用的完整旅程
引言:为什么线性代数如此重要? 想象你站在一个开阔的平原上,手中拿着一支箭。这支箭可以指向任何方向,可以伸长或缩短,可以与另一支箭相加。这就是向量的原始概念——一个既有方向又有大小的量。从这样简单的直观出发,人类发展出了一整套描述空间、变换和数据结构的数学语言:线性代数。 线性代数的美妙之处在于它的简洁性和普遍性。在二维平面上,一个点可以用两个坐标 $(x, y)$ 表示;在三维空间中,需要三个坐标 $(x, y, z)$;而在机器学习中处理的数据可能有一千维、一万维,甚至更高。线性代数提供了一套统一的工具来处理这些高维空间,而且它的规律在任意维数下都保持不变。 更令人惊讶的是,当你使用 ChatGPT、看 Netflix 推荐、或在 Google 搜索时,背后都有线性代数的身影。深度学习的神经网络本质上就是一系列线性变换和非线性激活的交替组合;推荐系统中的矩阵分解技术直接源自奇异值分解;而搜索引擎的 PageRank 算法则是特征值问题的经典应用。 在这篇文章中,我们将踏上一段从理论到应用的完整旅程。我们会从向量空间的几何直观出发,理解线性变换的本质,然后逐步深入到机器学习和深度学习的核心算法中。我们不仅会学习"怎么做",更重要的是理解"为什么"——为什么奇异值分解如此强大?为什么梯度下降会收敛?为什么注意力机制能够工作? 让我们开始这段旅程。 第一部分:线性代数基础理论 1. 向量空间的本质 1.1 从几何到抽象 在二维平面上,我们习惯用坐标表示向量。向量 $\mathbf{v} = (3, 2)$ 表示从原点出发,沿 $x$ 轴移动 3 个单位,再沿 $y$ 轴移动 2 个单位。但向量的概念远不止于此。 向量空间的抽象定义只需要 8 条公理: 加法封闭性: $\mathbf{u} + \mathbf{v}$ 仍在空间中 加法交换律: $\mathbf{u} + \mathbf{v} = \mathbf{v} + \mathbf{u}$ 加法结合律: $(\mathbf{u} + \mathbf{v}) + \mathbf{w} = \mathbf{u} + (\mathbf{v} + \mathbf{w})$ 零向量存在: $\mathbf{0} + \mathbf{v} = \mathbf{v}$ 负向量存在: $\mathbf{v} + (-\mathbf{v}) = \mathbf{0}$ 数乘封闭性: $c\mathbf{v}$ 仍在空间中 数乘分配律: $c(\mathbf{u} + \mathbf{v}) = c\mathbf{u} + c\mathbf{v}$ 数乘结合律: $c(d\mathbf{v}) = (cd)\mathbf{v}$ 这个定义看似抽象,但它统一了各种不同的对象: ...