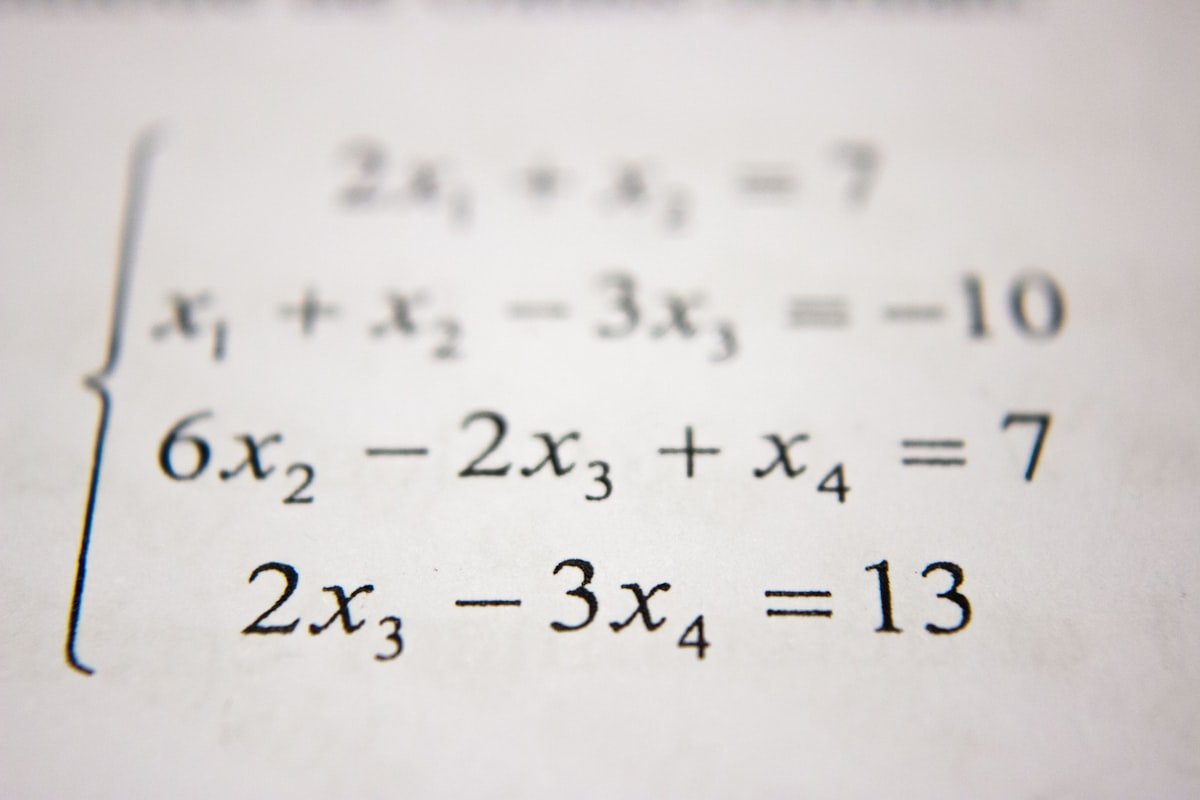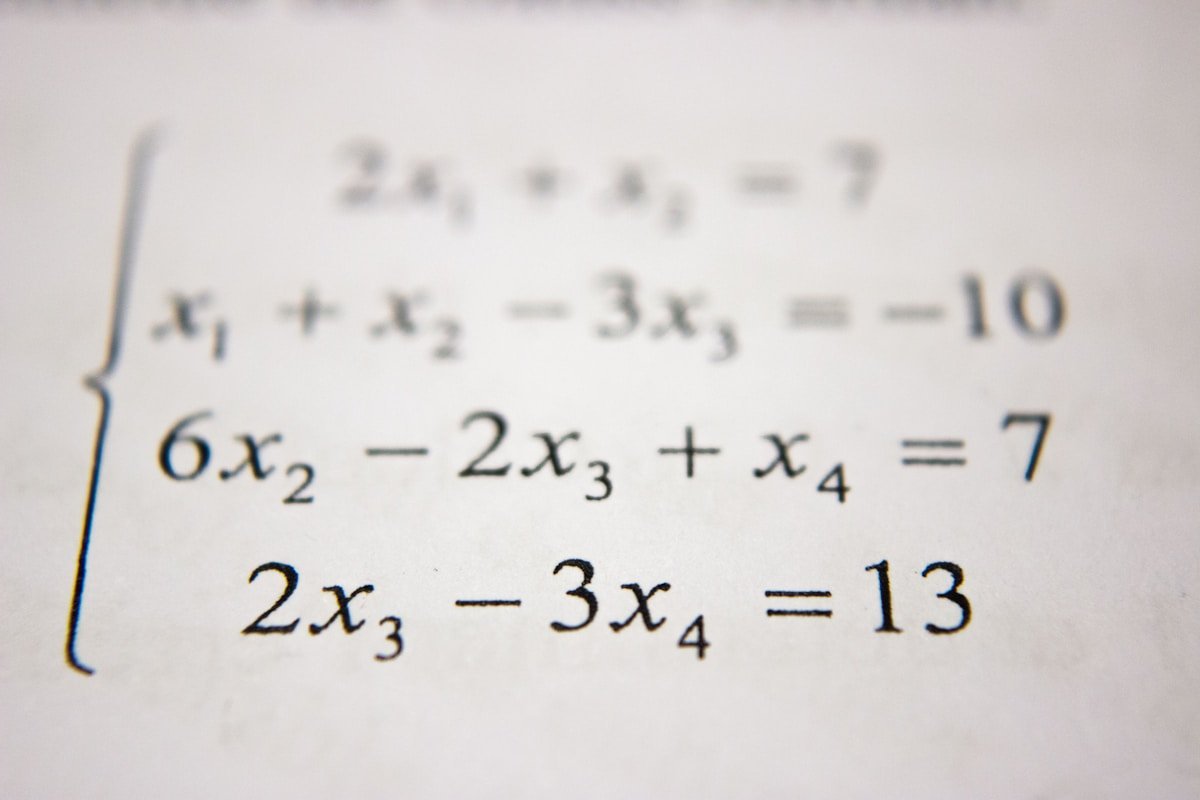
Poincaré的洞察:体积元的定向与外微分形式的诞生
引言:一个看似平凡的发现 1890年代末,巴黎的学术圈正沉浸在分析学的繁荣之中。法国数学家亨利·庞加莱(Henri Poincaré, 1854-1912)坐在书桌前,凝视着多重积分的变换公式。在旁人看来,这只是一个技术性的细节问题——如何计算曲面积分、体积分在坐标变换下的行为? 然而,Poincaré敏锐地意识到一个被前人忽视的事实:多重积分的体积元应该有一个正负定向。 这一看似平凡的看法使得多重积分在坐标变换下原来有些拖泥带水的变换公式,有了一个精练的形式,并使Newton-Leibniz公式的推广,步入了坦途。 这一发现看似微不足道——不过是给积分测度加上一个正负号而已——但它却如同一把钥匙,打开了通往现代微分几何的大门。它直接催生了外微分形式(differential forms)的概念,为Stokes定理、de Rham上同调、甚至是现代物理学中的规范场论奠定了基础。 让我们循着历史的足迹,探寻这一发现的来龙去脉。 第一章:Poincaré之前的多重积分 1.1 单变量的辉煌与局限 让我们先回到单变量微积分的美好时代。Newton和Leibniz在17世纪末创立的微积分基本定理告诉我们: $$ \int_a^b f’(x) , dx = f(b) - f(a) $$ 这个公式之所以优美,在于它将区间 $[a,b]$ 上的积分与边界 ${a, b}$ 上的函数值联系起来。更妙的是,它暗示了积分具有某种"定向"的性质:从 $a$ 到 $b$ 的积分,与从 $b$ 到 $a$ 的积分差一个负号: $$ \int_b^a f(x) , dx = -\int_a^b f(x) , dx $$ 然而,当数学家们尝试将这一框架推广到多变量时,他们遇到了意想不到的困难。 1.2 早期的多重积分变换 考虑一个二重积分: $$ I = \iint_D f(x,y) , dx , dy $$ 假设我们进行坐标变换 $(x,y) \mapsto (u,v)$,其中 $x = x(u,v)$,$y = y(u,v)$。在18、19世纪,数学家们知道变换公式涉及雅可比行列式(Jacobian determinant): ...