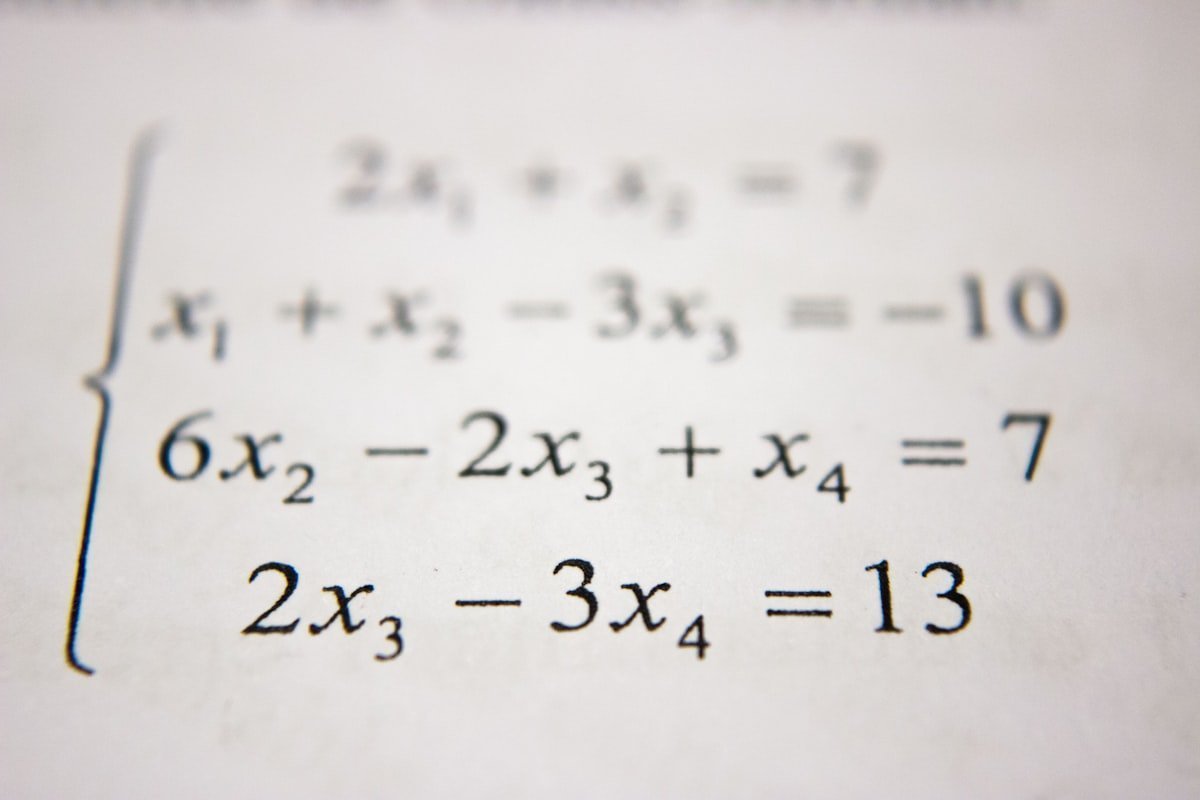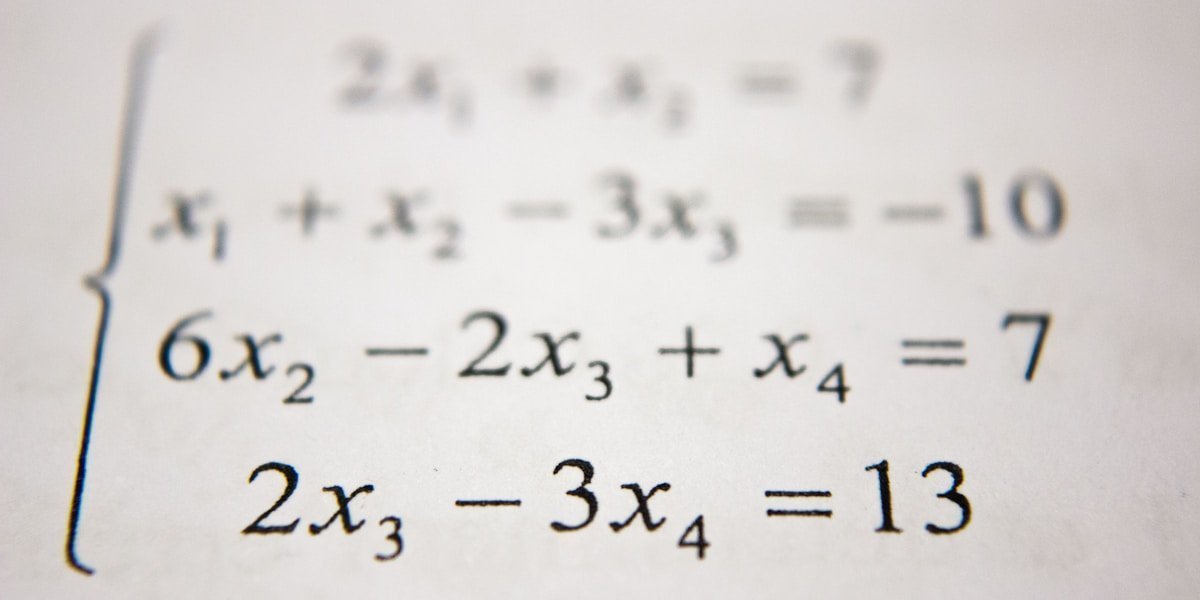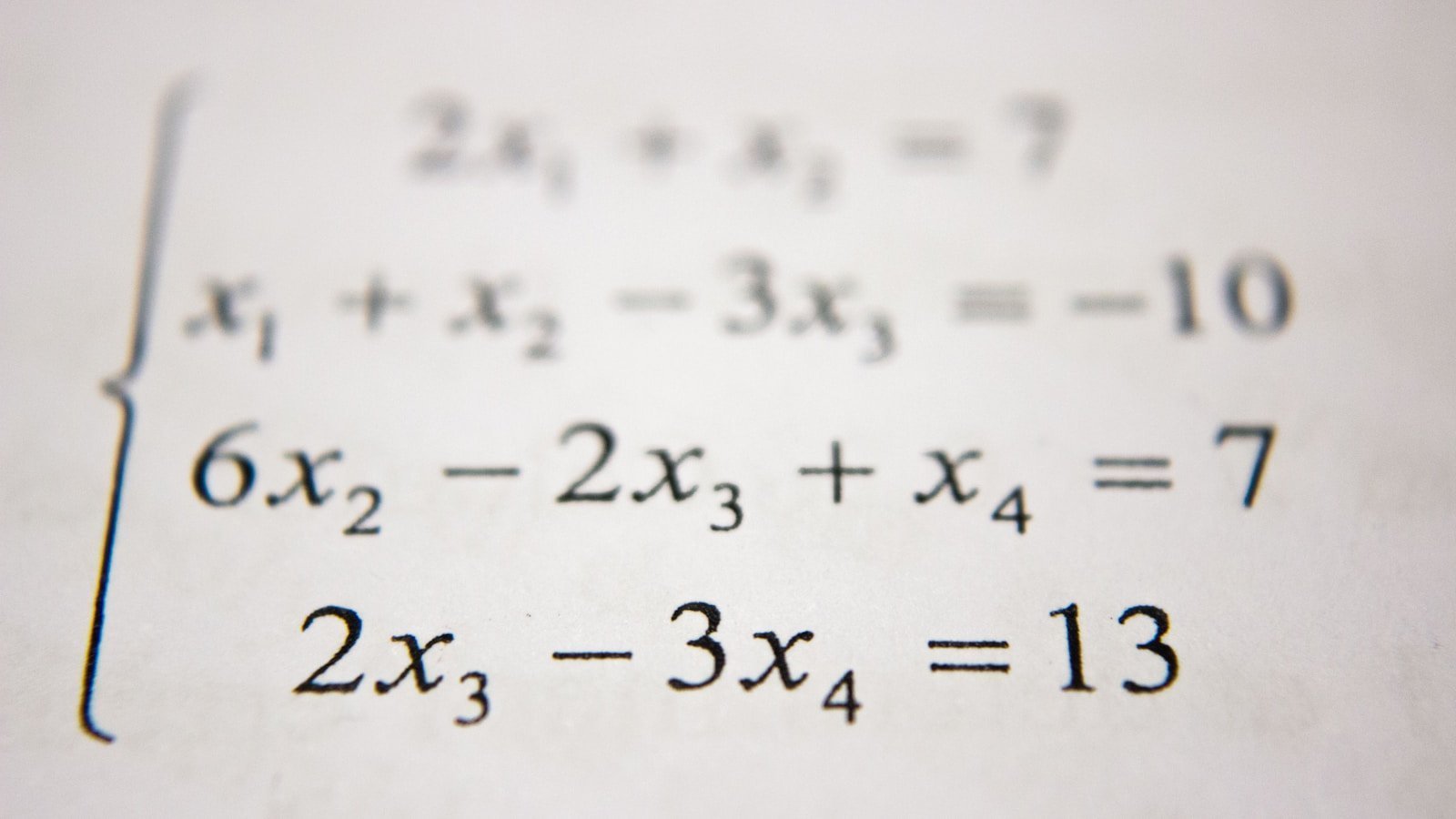
微分几何与深度学习:从流形假设到几何深度学习
引言:当深度学习遇见弯曲的空间 2012年,AlexNet 在 ImageNet 竞赛中以压倒性优势获胜,深度学习正式进入大众视野。此后,神经网络在各种任务上展现出惊人能力:图像识别、语音识别、机器翻译、游戏对战……但有一个问题始终困扰着研究者:为什么神经网络能够如此有效地学习? 答案或许藏在数据的本质结构中。想象你正在看一张人脸照片——1000 $\times$ 1000 像素的图像意味着这是一个百万维的空间中的点。但所有人脸照片都分布在这个百万维空间的一个极小子集上。为什么?因为真实的人脸受到物理规律的约束:两只眼睛在鼻子两侧,嘴巴在鼻子下方,等等。 这个子集不是随机的散点集合,而是一个流形(manifold)——一个局部看起来像欧几里得空间,但整体上可能弯曲、扭转的几何对象。 流形假设(Manifold Hypothesis)是连接微分几何与深度学习的桥梁: 真实世界的高维数据往往分布在一个低维流形上。 这个假设解释了为什么深度学习能够成功,也指明了改进的方向。从流形学习的早期算法,到现代的几何深度学习,微分几何正在成为理解神经网络本质的重要语言。 让我们从最基本的流形概念开始,逐步揭开这层神秘的面纱。 第一章:流形假设——数据的几何本质 1.1 什么是流形? 在正式定义之前,让我们从一个直观的例子开始。 想象一只蚂蚁生活在地球表面。对于这只蚂蚁来说,地面看起来是平的——它可以向前、向后、向左、向右移动。只有当它旅行了很长距离后,才会意识到这个世界是弯曲的(比如绕地球一圈回到原点)。 流形正是这种"局部平坦,整体弯曲"的空间。数学上,一个 $n$ 维流形 $\mathcal{M}$ 是一个拓扑空间,其中每一点 $p \in \mathcal{M}$ 都有一个邻域,同胚于 $\mathbb{R}^n$。 关键特性: 局部坐标:在任何小区域内,我们可以用 $n$ 个坐标 $(x^1, x^2, \ldots, x^n)$ 描述位置 过渡函数:不同坐标系统之间的变换必须是光滑的 全局结构:局部坐标片可以"缝合"成复杂的整体结构 图1:流形学习的核心思想——高维数据(如瑞士卷)实际上分布在一个低维流形上,学习的目标就是"展开"这个流形,发现其内在的低维结构。 1.2 数据流形:从高维到低维 现在回到深度学习。考虑以下例子: MNIST 手写数字:每个图像是 $28 \times 28 = 784$ 维的向量。但所有"3"的图像并不随机分布在 784 维空间中——它们形成了一个高度结构化的集合。写下"3"的方式虽然变化多端,但受到人体解剖学和书写习惯的约束。 人脸图像:如引言所述,人脸图像分布在由身份、表情、光照、角度等参数控制的低维流形上。这些参数可能有几十个,但远小于百万级的像素维度。 词向量:自然语言处理中的词嵌入将词汇映射到连续向量空间。语义相近的词在向量空间中也相近,形成某种几何结构。 流形维数的估计:如何确定数据流形的维数?这是一个活跃的研究领域。常用方法包括: 主成分分析(PCA):线性估计 本征维数估计:基于最近邻距离的统计方法 分形维数:对于复杂结构的数据 1.3 为什么流形结构重要? 理解数据的流形结构对深度学习有多方面的意义: 1. 维度灾难的缓解 在 $d$ 维欧几里得空间中,要覆盖单位立方体到精度 $\epsilon$,需要 $O(\epsilon^{-d})$ 个样本。这就是维度灾难。 ...