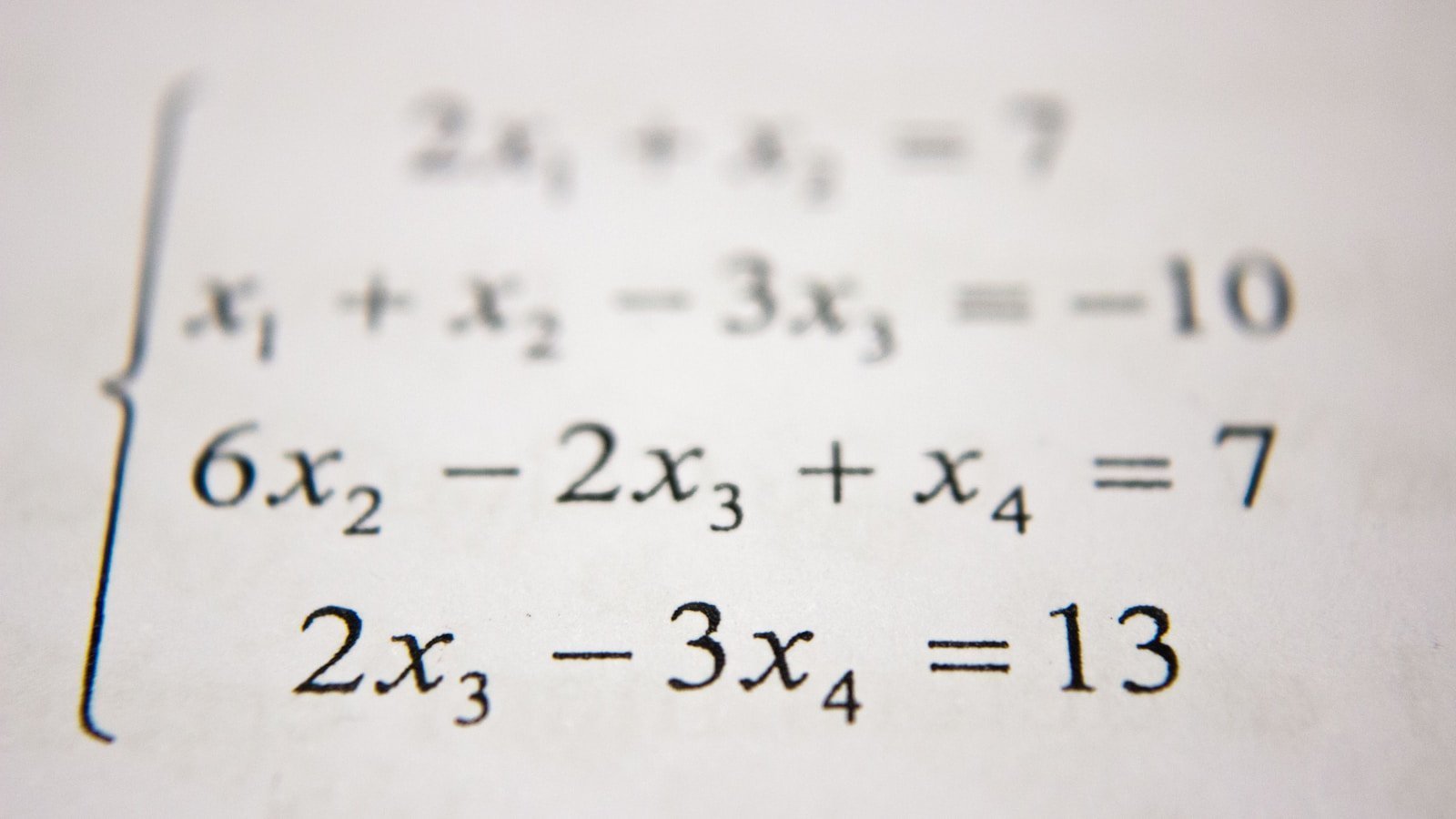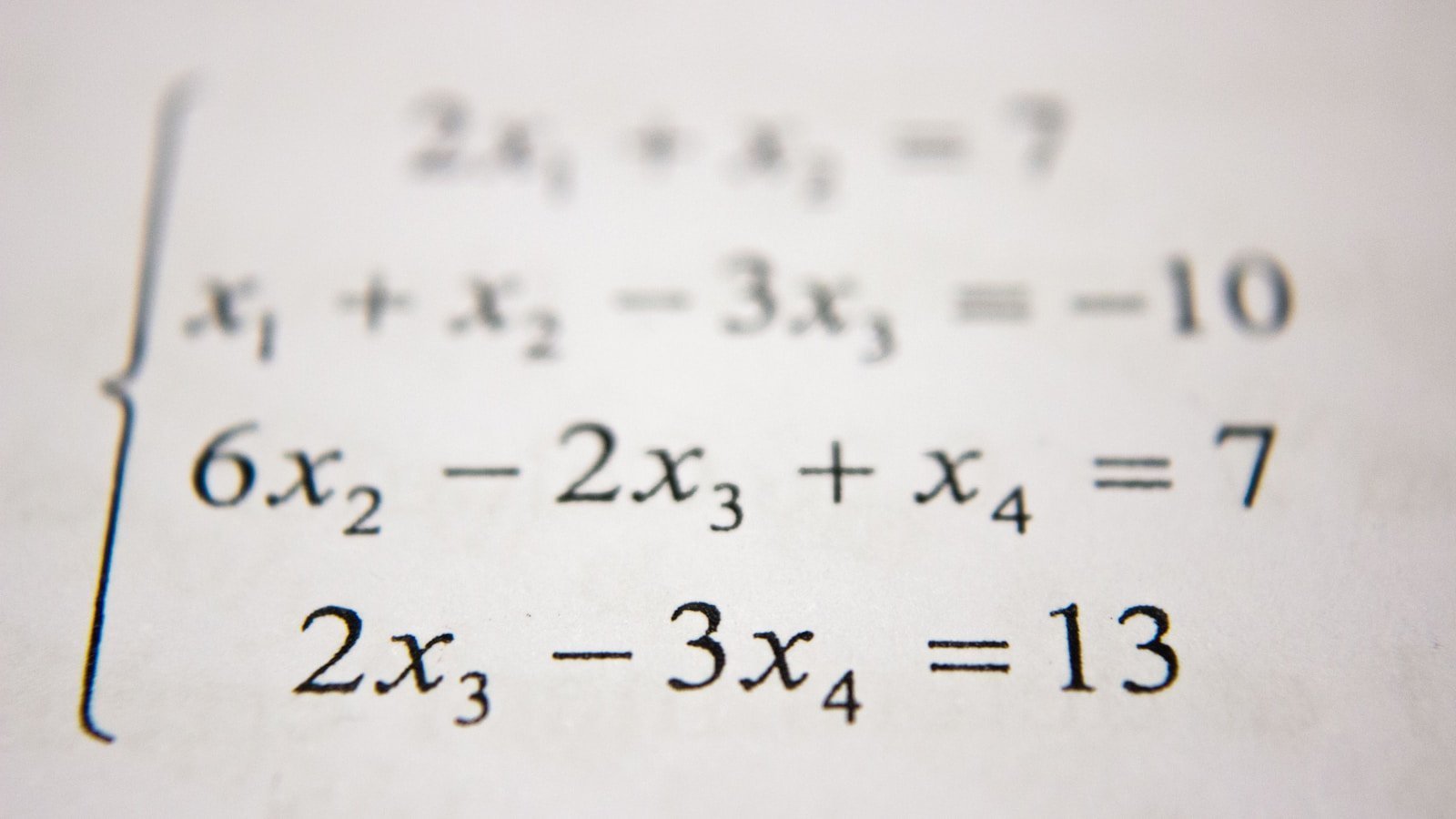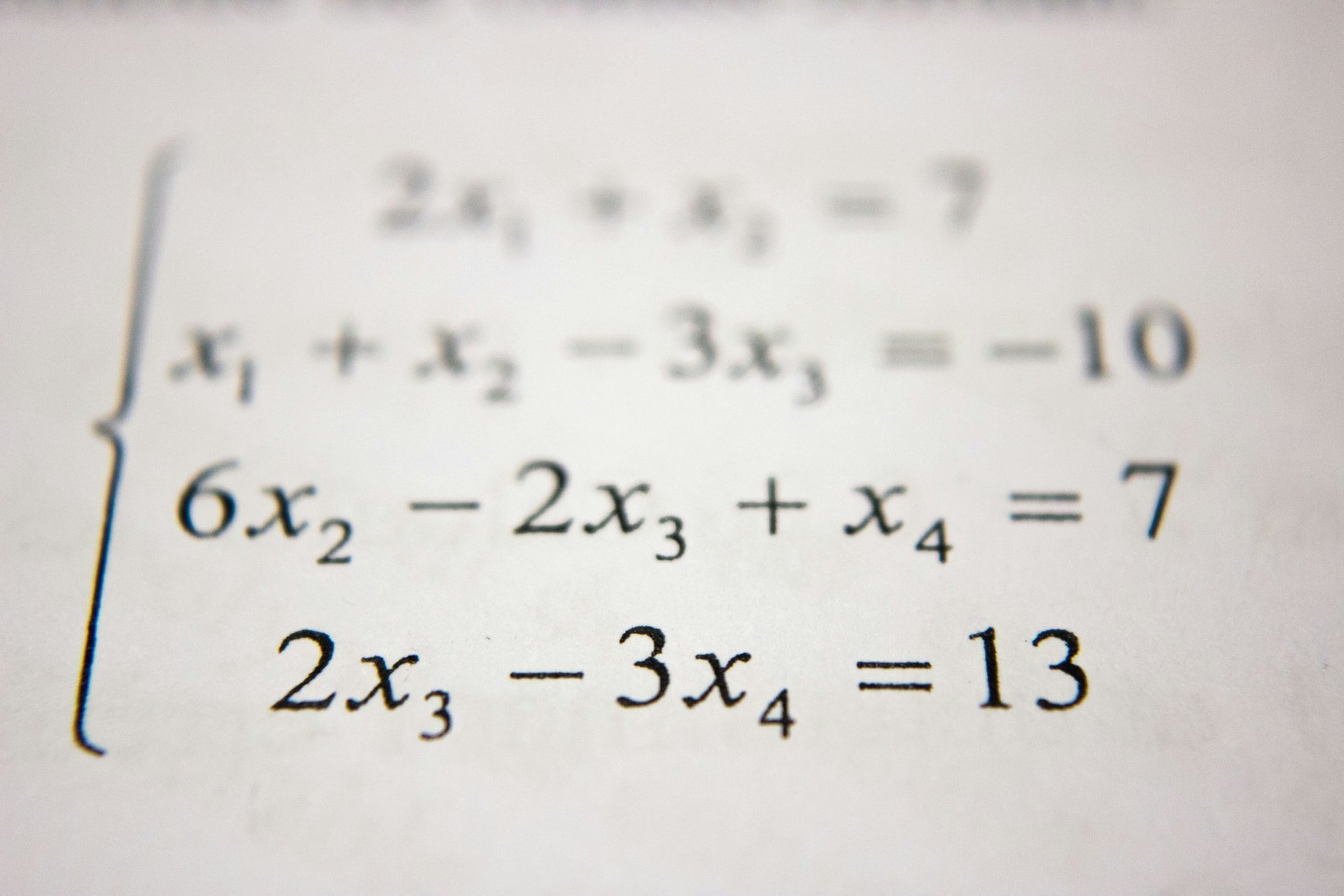
信息几何:在概率空间中寻找最短路径
引言:当概率成为空间上的点 想象一下,你站在一个巨大的画廊里。墙上挂着无数幅画,每一幅画都是一张概率分布的直方图。如果你要量化两幅画之间的"距离",你会怎么做?直接比较每个柱子的高度差异?还是考虑某种更本质的、统计学意义上的距离? 这个问题触及了统计学的核心:如何量化两个概率分布之间的差异。传统的做法是使用 KL 散度或互信息,但这些度量缺乏几何直观——它们不是真正的"距离",也不满足三角不等式。 信息几何给出了一种全新的视角:将所有概率分布看作一个黎曼流形,每个分布是流形上的一个点,Fisher 信息矩阵定义了这个流形上的度量张量。在这个框架下,我们可以谈论"两点之间的最短路径"(测地线),可以计算"梯度"(自然梯度),可以定义"曲率"(统计流形的曲率)。 这个领域的诞生可以追溯到 1945 年,印度统计学家 C. R. Rao 提出了 Fisher 信息度量可以作为微分几何的度量张量。此后,法国数学家 Amari 系统性地发展了信息几何的理论,并将其与神经网络、优化算法相结合。 在这篇文章中,我们将从基础概念开始,系统性地介绍信息几何的核心理论,探讨其在深度学习中的应用,并对未来的发展方向做出展望。 第一章:几何概率空间 1.1 概率分布作为流形 考虑一个简单的例子:所有零均值、单位方差的一维高斯分布 $\mathcal{N}(0, \sigma^2)$ 可以用一个参数 $\sigma$ 来表示。但如果我们考虑所有可能的高斯分布 $\mathcal{N}(\mu, \sigma^2)$,这就变成了一个二维的空间。 更一般地,考虑一个参数族 $\mathcal{P} = {p(x \mid \theta) : \theta \in \Theta}$,其中 $\theta \in \mathbb{R}^n$ 是参数。这个参数族可以看作一个 $n$ 维的流形——这就是统计流形。 关键洞察:每个概率分布不是孤立的对象,而是镶嵌在无穷维分布空间中的一个点。信息几何的任务就是给这个流形装备一个自然的几何结构。 1.2 Fisher 信息度量 1945 年,C. R. Rao 发现了一个重要的事实:Fisher 信息矩阵可以定义一个黎曼度量。 定义:对于参数族 $p(x \mid \theta)$,Fisher 信息矩阵定义为: $$ I(\theta){ij} = \mathbb{E}{p(x \mid \theta)}\left[\frac{\partial \log p(x \mid \theta)}{\partial \theta_i} \frac{\partial \log p(x \mid \theta)}{\partial \theta_j}\right] $$ ...