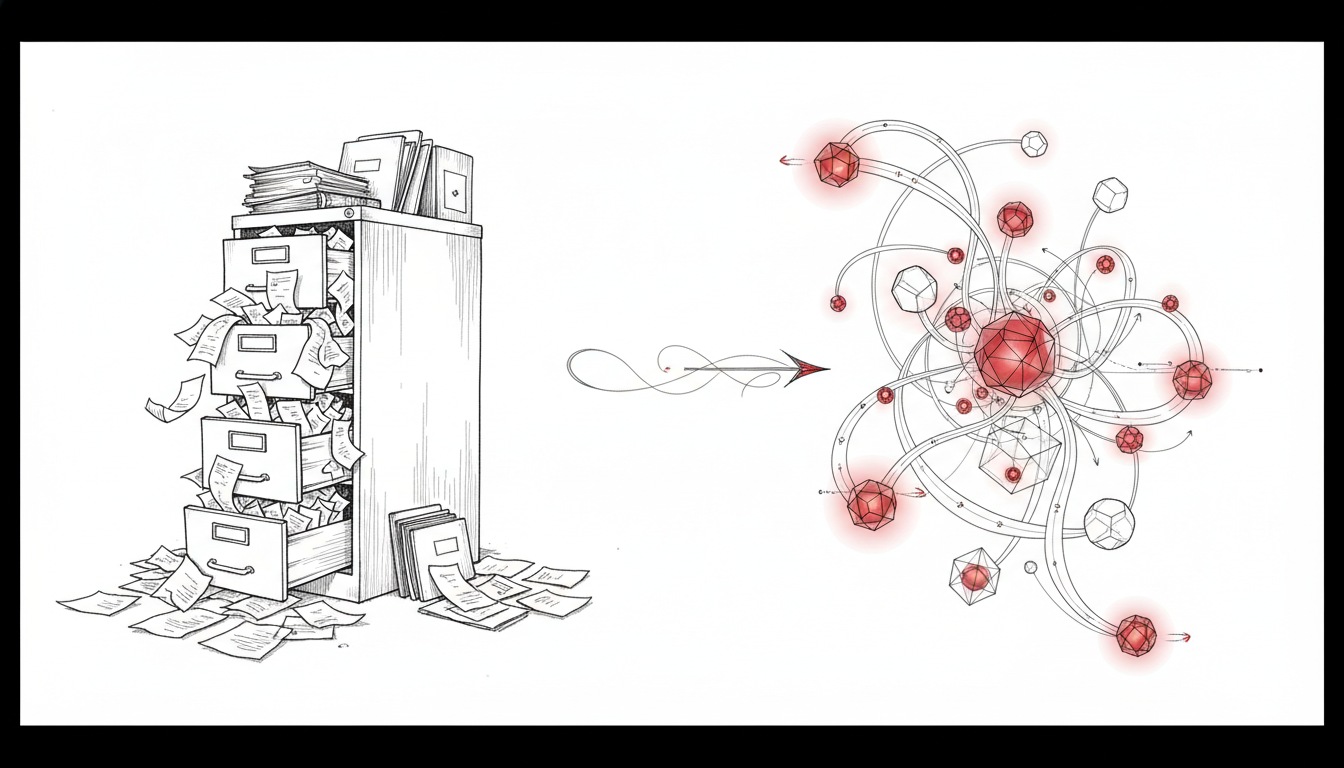
从文件日记到向量记忆:NanoClaw 记忆系统的工程化重构
情境:想象你正在和一个聪明的助手合作一个持续数月的项目。每次开启新会话,你都需要重新交代背景:“我们用 Python 开发”、“上次讨论的那套错误处理方案”、“别忘了我的代码风格偏好”。 这就是当前大多数 AI 助手的真实处境——它们拥有海量知识,却缺乏对你个人的长期记忆。 第一章:NanoClaw 原有的记忆机制——文件即记忆 要理解我们为什么要重构记忆系统,必须先看清现状。 NanoClaw 是一款基于容器隔离的 AI 助手框架,它的核心设计哲学是极简与安全:每个工作群组拥有独立的文件系统沙盒,Agent 在完全隔离的容器中运行,通过挂载机制访问受限的资源。 在这种架构下,记忆被实现为一种文件中心式的朴素方案: 1.1 CLAUDE.md:人工维护的静态记忆 每个群组目录下都有一个 CLAUDE.md 文件,这是 NanoClaw 最初唯一的持久化记忆载体。 图1:V1 架构下,记忆完全依赖人工编辑的 Markdown 文件。用户需要手动整理项目背景、编码规范、历史决策,Agent 被动读取。 它的工作方式极其直白:系统启动容器时,将 CLAUDE.md 的内容完整注入系统提示词。这意味着: 人工维护负担重:用户必须主动整理和更新文件内容 无法自动沉淀:对话中产生的新知识、新偏好不会自动被记录 全量加载浪费:无论当前任务是否需要,整个文件都会被塞进上下文 1.2 SQLite 消息库:仅存的对话痕迹 NanoClaw 确实记录了所有对话消息,存储在本地 SQLite 数据库中。但查看 src/db.ts 的实现会发现: // 消息仅被原样存储,无任何结构化提取 export function storeMessage(msg: NewMessage): void { const sql = ` INSERT INTO messages (chat_jid, sender_jid, content, timestamp, is_from_me) VALUES (?, ?, ?, ?, ?) `; db.prepare(sql).run( msg.chatJid, msg.senderJid, msg.content, msg.timestamp, msg.isFromMe ? 1 : 0 ); } 这些消息只是流水账式的存档,没有被转化为可检索、可关联的结构化记忆。当 Agent 需要回顾历史时,它面临的是成千上万条未经整理的原始对话,而不是精炼的知识条目。 ...